基于JSP的MVC框架实现的图书推荐系统展示平台网站
摘 要
推荐系统是目前互联网中最常见的一种智能产品形式。由于网络中信息量的快速增长以及图书出版行业出版量的攀升,人们需要一种办法,来解决信息过载的问题。此外,用户访问网络是为了获取信息,但并不是所有的访问都有很强的目的性,所以对于这些没有明确的目的的访问,就需要智能系统把一些用户可能感兴趣的信息推送给用户。基于这些需求,图书网站的推荐功能就变得非常重要。
本文首先对图书推荐系统的发展历史做了介绍,然后对开发图书推荐系统所需的项目管理工具(Maven、Git)、数据持久化工具(MyBatis,Spring MVC框架)和Bootstrap前端开发框架进行了简单分析,在此基础上,设计并开发了一套基于Web的图书推荐系统展示平台,主要工作可概括为四个方面。
-
对图书推荐系统的结构进行了重新设计。主要是在Spring MVC框架的基础上,将系统分为了三层:Web层、服务与模块层、数据层,并对每层的结构与需要完成的功能做了定义。
-
基于MySQL数据库管理系统,设计并建立了图书推荐系统所需的数据库,该数据库的数据共分为三个部分:原始数据、清洗后数据和用户数据。
-
从便于操作和使用的角度出发,设计了图书推荐系统的页面,主要包括首页、搜索、展示、登录、注册等页面。
-
对整个开发过程以及系统组成的三个主要类:控制器类、模块类与视图类进行了分析。
经过后期的数据库优化与功能测试,系统与同类网站相比,性能良好。
关键词 :基于Web的图书推荐系统;展示平台;MVC框架;Web系统设计
Abstract
Recommender system is one of the most common intelligent productform in the internet recently. Since the growth of the information in thenetwork as well as the growth of the amount of books, people need to solve theproblem of information overload. Meanwhile, the users access to the network toobtain information, but not all have a strong purpose. So the system must pushsome information that user might be interested in to who accesses the websitewithout strong purpose. That is why it is important for website to providerecommendation information.
First of all, we described the history of book recommender system.Then, made an introductory of the tool and frameworks used in development:Maven, the project management tool, Git, the version control system, MyBatis,the SQL Mapping Framework for Java, Spring MVC framework and Bootstrap, thefront-end framework. Finally, designed and developed a display platform ofweb-based book recommender system on that. The main work is as follows.
-
Made redesign of the structureof the book recommendation system. Divided the system into three levels: theweb level, the service and model level and the data level based on the SpringMVC framework. Made the definition of the structure and functions to be done oneach layer.
-
Designed and built the databaseof the book recommender system based on the MySQL database management system.Database is divided into three parts: Original data, washed data and user data.
-
From the perspective of the easeof operation and use, designed the pages of the book recommender system. Pageshave been divided into index, search, display and login and register parts.
-
Made analyses of the wholeprocess of development and the three main classes: controller, model and view.
After database optimization and functional testing, system performsgood compared with similar sites.
Key Words :Web-based BookRecommender System;Display Platform;MVC Framework;Web System Design
引 言
图书推荐功能在图书馆网站,图书销售网站,以及图书分享网站中都占有很重要的地位。它可以根据长尾理论挖掘图书数据,改善用户体验,增加用户的粘性,解决信息过载问题。
本论文的目的就是要构建一个图书推荐系统的展示平台,将图书信息以及推荐内容,显示在页面之上。并且支持用户的注册登录,用来提供数据,使得推荐算法可以依照此数据来计算出用户喜好,进而向用户推送推荐信息。
在推荐系统领域,最为成功的该属亚马逊网站,在亚马逊的收入中,有20%~30%的都来自于推荐系统。而在图书馆等非盈利性网站,图书推荐系统也对优化用户的浏览体验以及均衡每本书的借阅率,都有促进作用。
系统后台是基于Java的Spring MVC框架与Tomcat服务器,前台基于浏览器、HTML与jQuery页面展示技术,数据库基于MySQL开源数据库。利用MVC框架,可以方便地构建出健壮、扩展性强的应用。MySQL数据库,作为最热门的开源数据库,提供了完整的关系数据库支持与成熟的数据存储解决方案。浏览器展示技术,使用户不需要在操作系统中安装独立的应用,并且使得系统的访问不局限于某个操作系统,适用面变得更广。系统提供推荐内容的展示,图书排行的展示,图书搜索,图书详细内容展示,用户登录注册等基本的图书推荐系统所具有的功能。界面使用Bootstrap框架,布局对用户更加友好。
整个系统通过实现一个轻量的框架,来提供完整的图书推荐功能,后续的功能可以方便地在此基础上扩展。相对于其它的系统,有小巧、灵活的优点,并且本系统全部采用开源软件,因此几乎为零成本。在引用第三方库的过程中,不对其源码进行修改,减少耦合,使得之后第三方库的升级也不会对系统有大的影响。系统在一台机器上部署,并且在同一网段的另一台机器上访问测试后,性能表现良好。
1 文献综述
如今,推荐系统无处不在。在网上逛商城,购物,在音乐网站听歌,在社交网站发表自己的感受以及分享照片,网站服务提供商都会收集用户的访问记录以及用户的喜好,对用户的行为进行分析并且根据用户喜好以及用户群体统计信息,给用户提供相似物品的推荐以及广告推送,进而增加商家的销量,提高网站质量。
一般认为,推荐系统这个研究领域源于协同过滤算法的提出。从它的诞生到现在20多年中,很多学者和公司对推荐系统的发展做出了重要的贡献。随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代走入了信息过载的时代[1]。而图书出版物等作为一个传统的信息载体,在人类发展的过程中不断增多,一些大的互联网公司与网络图书销售商,比如谷歌、亚马逊等,也一直在为图书的数字化做着贡献。从2004年谷歌宣布他的图书搜索服务之后,到2012年,共有两千万本图书扫描、经由光学字符识别并存储于数字化数据库中作为搜索数据[2]。这些数据为图书推荐提供了丰富的基础。
本系统采用BS结构,对数据库中的图书内容进行查询、处理,对查询结果进行展示,并且提供用户注册登录以及采集用户访问记录的功能。在服务器端采用Spring MVC框架与对象持久化技术对图书信息进行处理,在客户端使用浏览器技术对数据进行展示与交互,最终完成图书通过WEB平台展示、推荐与相关图书搜索的功能。
1.1 课题背景
1.1.1 图书推荐系统发展背景
随着互联网的快速发展,网络中的图书信息量迅速增长,图书种类也日趋繁多,用户通过互联网要获得自己感兴趣的图书文章需要花费越来越多的时间。由此催生了图书推荐系统。图书推荐系统的基本作用是依据用户的访问记录,特定行为,分析用户的喜好,主动向用户推荐可能喜欢的图书与文献给用户,供用户参考[3]。推荐系统满足了用户个性化的需求,节省了用户搜寻信息的时间,获得和用户喜好相关的最热门最新的图书。在许多商务网站,社交网站中,都使用推荐系统来向用户推荐商品。
在线售卖领域,亚马逊拥有最好的图书推荐系统。在过去的十多年里,亚马逊投入了大量的精力去建立一个包含大众推荐和个人记录的高效个人推荐系统,其最显著特点就是所有的推荐都建立在对顾客以往的浏览记录和购买记录之上[4]。
亚马逊可以向用户精确的投放畅销书以及经典书推荐信息,每月有评有畅销书排行榜,通过简洁美观的介绍与醒目的导航,引导读者阅读与购买。另外,在畅销书的介绍中,还有本书在相关的分类栏目中的排名,并且有链接指向此分类的畅销排行榜,读者可以方便的查询同类书中最畅销的书籍。在书籍介绍底端还有购买过此书的人还购买了的书籍,购买的比例,以及同类书籍的推荐信息。在首页还有促销书的推荐,用于吸引没有明确目的,而想要以优惠的价格购书的消费者。在经典书方面,亚马逊推出年度畅销图书排行,年度编辑推荐100本畅销书等手段,依据惯性定律,进一步推动图书的销售。其中排序规则还根据用户的评价,人气、出版日期等,迎合不同人的喜好。
1.1.2 主要技术发展背景
Spring框架是一个开源的应用框架,基于Java平台的控制反转容器。第一个版本是Rod Johnson在他2002年十月出版的《ExpertOne-on-One J2EE Design and Development》书中发布的。第一次在Apache 2.0 license下发布是在2003年六月,在2004年三月,发布了第一个里程碑:1.0版本。在2006年,Spring框架1.2.6版本获得了Jolt productivity award和JAX Innovation Award。当前的版本3.2.2是在2013年三月发布的。
Spring Framework的核心特性可以被用于任何的Java应用。尽管SpringFramework没有强加任何特殊的编程模块,它依旧在Java社区变得流行,并且有取代EnterpriseJavaBean模块的趋势。
在2001年,Clinton Begin开始一个叫做iBATIS的项目,刚开始,开发的重点是一个加密的软件解决方案。iBATIS项目发布的第一个软件名字叫做Secrets,一个个人的数据加密和登录工具。Secrets完全的用Java实现,并且在开源协议下发布。
2002年,Clinton开发了一个应用叫做JPetStore来展示Java可以比.NET更高效,JPetStore 1.0影响很大,并且其中用到的数据库层吸引了社区的注意。很快,iBATISDatabase Layer 1.0项目启动了,其中包括两个组件:iBATIS DAO和iBATIS SQL Maps。2004年,iBATIS 2.0发布,它是在保持原有特性上的全新设计。Clinton将iBATIS这个名字和源代码都捐献给了Apache SoftwareFundation,这个项目在ASF一直持续了六年。最终,iBATIS DAO被抛弃了,因为有更好的DAO框架的出现,比如Spring Framework。
在2010年5月19日,iBATIS 3.0发布了,同时,开发团队决定将项目转移到Google Code。由于iBATIS这个名称已经捐赠给了ASF,所以项目改用了新名称MyBatis。
jQuery是一个多浏览器的JavaScript库,目的是简化客户端的HTML脚本编程。John Resig在2006年一月发布,目前有一个Dave Methvin领导的开发小组进行开发。在一万个最热门的网站中,他被65%的网站使用。jQuery是目前最流行的JavaScript库。
MySQL是世界最广泛使用的开源关系数据库管理系统。它作为一个系统服务,允许多用户访问多个数据库。
MySQL开发项目将代码依照GNUGeneral Public License发布。MySQL被一家瑞典的公司MySQLAB拥有并且提供赞助,这家公司现在隶属于Oracle。
1.2 开展研究的意义
图书推荐系统web平台用于支持图书内容的获取和图书推荐的展示。如果没有此平台,那么图书推荐系统就无法收集用户行为,统计用户喜好,展示推荐结果以及实现推荐系统的原有意义[5]。任何一个推荐系统都需要网络或者客户端平台来展示[6]。而构建这样一个后台服务器与浏览器客户端共同协作展示的平台,对于图书推荐系统具有重要的意义。
1.3 论文研究内容
本课题意图开发一套轻量、扩展性强、功能完善,性能良好的图书推荐系统。系统的最终目标是实现对图书内容进行展示、查询、用户登录注册,还有推荐信息的展示功能。用户通过浏览器与后台系统的Java Servlet、数据库交互,完成展示、查询与用户管理的目的。
研究的着重点在于通过现有流行的开源系统、框架,来搭建轻量级的目标Web系统,在实现过程中更注重于代码结构与开发方法,所以并不追求功能的繁杂冗余。系统中数据来源于豆瓣,数据的抓取不是本课题研究的内容。为了使数据适用于Web系统,重新构建了表,并对数据进行了二次清洗。由于是展示平台,并不涉及图书推荐算法的实现与搜索功能的完善,所以搜索结果由数据库查询获得。但是在开发过程中为图书推荐与社会化图书搜索预留了接口,可以方便的加入这些功能。
1.4 论文的组织结构
- 第一章,文献综述。先讲了课题的背景,从图书推荐历史和技术发展史两个方面介绍,之后介绍了开展研究的意义,最后明确了研究的工作重点。
- 第二章,框架与工具介绍。对Maven、Git等项目管理工具,Spring MVC、MyBatis、Bootstrap、jQuery等开发框架进行了介绍。
- 第三章,基于Web的图书推荐系统展示平台的设计。对此Web系统所用到的数据库结构、页面原型、模块组成、总体的功能进行了论述。
- 第四章,基于Web的图书推荐系统展示平台的实现。介绍了对数据的二次清洗、数据库的创建、数据的导入、工程的搭建、模块的开发以及测试等。并介绍了测试过程中做的一些性能优化工作。
- 最后,结论。对本系统的优缺点做了一个总结,展望了一下未来的发展方向。
2 框架与工具介绍
2.1 Maven介绍
2.1.1 Maven概述
Maven是一个主要用于Java项目的自动化构建工具。Maven与Apache Ant工具具有相似的目的,但是他们是基于不同的理念并且以不同的方式来工作。Ant还可以用来构建和管理C#,Ruby,Scala以及其他的语言开发的项目,但是Maven原生并不支持这些。Maven项目由Apache Software Fundation托管,之前是Jakarta Project项目的一个部分[7]。
Maven使用XML文件来描述需要构建的软件项目、项目的依赖模块和组件、构建顺序、目录结构以及需要的插件。他具有预定义的目标来实现确切的任务,比如编译源码并打包。
Maven动态地从一个或多个库中下载Java库和Maven插件,比如Maven 2 Central Repository,并且将下载的内容保存到本地的缓存中。这个本地的下载缓存可以被本地项目更新,公共的库也可以被更新。
Maven使用基于插件的体系来构建,他允许通过标准的输入控制任何的应用。理论上说,这将允许任何人为任何语言来在这个平台上编写插件。实际上,支持和使用除Java外其它语言的插件数量已经微乎其微。目前,只有支持.NET框架以及一个C/C++的原生插件还在被维护。
2.1.2 Maven概念
项目对象模型(POM):一个项目对象模型提供一个项目的所有配置属性。一般配置包括项目名称,owner和它的依赖。也可以通过插件,配置构建过程的各个阶段。比如说,用户可以配置编译插件,让它使用Java 1.5来编译,或者指定在一些单元测试失败以后,依旧打包工程。大的项目应该分成几个模块或者子项目,每个模块拥有自己的POM。用户可以编写一个根POM,通过这个根POM来使用一条命令来编译所有的模块。POM也可以从其它POM文件继承配置信息。所有的POM文件默认继承自Super POM。Super POM提供默认的配置,比如默认源代码目录、默认插件,等等。
插件:大部分Maven的功能是通过插件来实现的。插件提供一组目标,并且可以通过以下的语法来执行:
java
mvn [plugin-name]:[goal-name]
比如说,一个Java项目可以使用compiler-plugin的complile-goal来编译:
mvn compiler:compile
Maven插件提供构建、测试、源码控制管理、运行web服务、生成Eclipse项目文件等等功能。插件由pom.xml文件中的
然而,如果构建、测试、打包一个软件项目需要手动运行下面每条goal,那么,它将会变得非常笨重:
mvn compiler:compile
mvn surefire:test
mvn jar:jar
Maven的生命周期概念处理这类问题。
插件是扩展Maven的主要方式。可以通过继承org.apache.maven.plugin.AbstractMojo类来开发Maven插件。
构建生命周期:构建生命周期是一个用来给出为了达到goal所执行语句顺序的列表。Maven的一个标准生命周期叫做“默认生命周期”,它包括以下语句:
- process-resources
- compile
- process-test-resources
- test-compile
- test
- package
- install
- deploy
插件提供的goal可以与不同的生命周期阶段相关联。比如说,默认情况下,“compiler:compile”的goal与编译阶段有关,而goal“surefire:test”与测试阶段有关。考虑下面的命令:
mvn test
当以上的命令被执行,Maven运行所有的在test语句之前的goal,直到test语句。在这种情况下,Maven运行“resources:resources”goal,然后是“compiler:compile”,等等,直到最终运行“surefire:test”goal。
Maven也有标准用来清理项目和生成项目站点的语句。如果清理是默认生命周期的一部分,那么项目将在每次构建的时候被清理,这显然不是想要的。所以,清理有它自己的生命周期。
标准的生命周期允许新用户能够通过一个简单的语句准确的构建、测试和安装每个Maven项目:
mvn install
依赖:Maven的依赖处理机制围绕一个坐标系统识别单个软件库或者模块。比如说,一个项目需要Hibernate库,仅仅需要在POM文件中声明Hibernate项目,Maven将自动下载依赖和Hibernate自身的依赖,并且把它们存储在本地的仓库中。Maven 2 CentralRepository是默认的用来搜索的库,但是也可以在POM文件中自定义仓库。
还有一些其他的搜索引擎,比如说Maven Central,可以被用来去不同的开源库和框架中寻找模块。
在同一个机器上开发的项目之间可以通过本地仓库来互相依赖对方。本地仓库是一个简单的目录结构,充当下载的依赖包的缓存与本地构建的项目的集中存储的地方。Maven命令mvn install构建一个项目,并且把它的二进制文件放到本地仓库中。然后其它的项目可以通过在POM文件中添加项目来引用这个工程。
2.2 Git介绍
2.2.1 Git概述
Git是一个分布式的版本控制系统和源代码管理系统。它最初是Linus Torvalds为Linux内核开发而设计开发的,从那以后,Git就被许多其它的项目用来管理代码[8]。每个Git工作目录都是一个完整的仓库,保存着完整的历史和全部的版本跟踪能力,不需要依赖于网络连接或者一个中央服务器。Git是基于GNU GeneralPublic License version 2的开源软件。
Git设计灵感来自于BitKeeper和Monotone。Git最初被设计成一个底层的版本控制系统引擎,在它上方其他人可以编写前端,比如说Cogito和StGIT。然而,核心的Git项目最终变成一个可以直接使用的完整的版本控制系统。由于受BitKeeper的严重影响,Torvalds故意地试着避免传统的方法,最终实现了一个独一无二的设计。
2.2.2 Git特性
Git的设计来源于Torvalds在开发Linux过程中积累的管理大的分布式项目的经验和对文件系统性能的知识,以及在短期内构建一个可以工作的系统的需求。这些影响导致了以下实现方案:
1.对非线性开发的强大支持
Git支持快速的分支和合并操作,并且包含专门的工具用来可视化和导航一个非线性的开发历史。Git的一个核心设想是:由于项目被分给好多个人来完成,修改会更多的被合并,而不是被写入。在Git中,分支是非常轻量的:一个分支仅仅是一次提交的关联,通过其父提交历史,整个分支结构就可以创建出来。
2.分布式开发
就像Darcs、BitKeeper、Mercurial、SVK、Bazaar和Monotone,Git给每个开发者一份整个开发历史的本地副本,并且修改记录会从一个这样的本地仓库复制给另一个。这些修改作为附加的开发分支导入进来,并且可以合并到本地的开发分支中。
3.兼容已存在的系统和协议
仓库可以通过HTTP、FTP、rsync或者通过建立在纯socket、ssh、或HTTP上的Git协议来推送。Git还有一个CVS服务器模拟,用来让使用CVS客户端和IDE插件的用户来使用Git仓库。Subversion和SVK仓库可以直接使用git-svn。
4.高效处理大型项目
Torvalds描述Git处理速度非常快、可扩展,并且Mozilla对其做的测试显示,它比一些版本控制系统快一个数量级,从本地存储的仓库获取比从远程服务器快一百倍。Git甚至在项目历史变得很大的时候速度依旧不会减慢。
5.历史记录加密认证
Git历史记录以这样一种方式存储:某次提交的id号取决于之前的完整的开发历史。一旦被发布了,就不可能再去修改旧的版本而不产生记录。这种结构就像一个hash树,但是在每个节点和叶子上,都有附加的数据。
6.基于工具的设计
Git是C语言程序,它有一些shell脚本来对其进行封装。尽管大部分的脚本为了提升速度和可移植性,已经用C语言重写过,但是依旧有一些并且很容易的就可以将组件和Git连接起来。
7.可控的合并机制
作为工具设计的一部分,Git具有对不能完成的合并有良好的定义模块,并且它还具有多种算法来完成合并。不能自动合并的部分它会最终提示用户,并且由用户来手动编辑。
8.垃圾回收机制
放弃等操作会在数据库中留下无用的对象。这是基本上是逐渐增长的历史记录的一个小碎片。Git将会在足够多的松散对象积累够之后,自动的进行垃圾回收。垃圾回收也可以使用git gc –prune命令来调用。
9.定期对象包装
Git将每个新创建的对象作为一个独立的文件来保存,尽管每个都会压缩,但是这依旧会占用大量的空间并且降低效率。这个问题是用一种叫做packfile的单一文件存储大量的对象在一个包中来解决的。每个packfile创建一个对应的索引文件,用来表示packfile中的每个对象的偏移地址。新创建的对象依旧独立存储,定期的打包,以保持空间利用率。打包仓库的过程会非常消耗计算机资源。相对于允许对象松散的存在于仓库中,git允许在空闲时间花费较大的开销来将他们打包。Git会定期的自动重新打包对象,不过,也可以使用git gc命令来手动打包。为了保证文件的完整性,每个packfile和它的索引内部都有SHA-1校验码,并且packfile的文件名包含一个SHA-1校验码。输入git fsck命令即可验证完整性。
2.3 MVC模式与SpringFramework框架
2.3.1 MVC模式
MVC模式是软件工程中的一种软件架构模式,把软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。
MVC模式的目的是实现一种动态的程序设计,使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。除此之外,此模式通过对复杂度的简化,使程序结构更加直观[9]。软件系统通过对自身基本部分分离的同时也赋予了各个基本部分应有的功能。组件合作关系如图2.1所示。
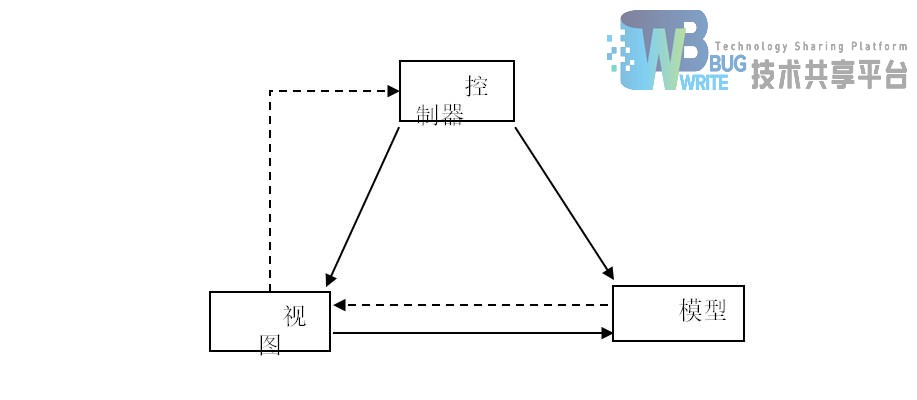
模型(Model): “数据模型”用于封装与应用程序的业务逻辑和数据处理相关的方法。“模型”有对数据直接访问的权力,例如对数据库的访问。“模型”不依赖于“视图”和“控制器”,也就是说,模型不关心它会被如何显示或是如何被操作。但是模型中的数据的变化一般会通过一种刷新机制被公布。为了实现这种机制,那些用于监视此模型的视图必须事先在此模型上注册,从而,视图可以了解数据模型上发生的变化。
视图(View): 视图层能够实现数据有目的的显示(理论上,这不是必需的)。在视图中一般没有程序上的逻辑。为了实现视图上的刷新功能,视图需要访问它监视的数据模型(Model),因此应该事先在被它监视的数据那里注册。
控制器(Controller): 控制器起到不同层面间的组织作用,用于控制应用程序的流程。它处理事件并做出响应。“事件”包括用户的行为和数据模型上的改变。
2.3.2 Spring MVC框架
Spring Framework提供它自己的MVC web应用程序框架,这并不是开发之初计划的。由于当时流行的Jakarta Struts web框架的设计很糟糕,并且其他框架也有许多不足之处,Spring开发者决定去编写他们自己的web框架。最重要的一点,他们觉得在表现与请求处理层之间没有完整的分离,并且请求处理层和模块层也没有完全分离。
就像Struts,Spring MVC也是一个基于请求的框架。每个接口的目的是让Spring MVC用户能够清晰、容易的实现MVC框架的应用。所有的接口都是与Servlet API紧耦合的[10]。这个对Servlet API的紧耦合被某些开发者看做是Spring的失败,它不能提供一个高层次的对基于web的应用的抽象层。然而,这样耦合确保了Servlet API能够给开发者提供一个高度抽象的框架来使得开发变得容易[11]。
Spring MVC框架围绕一个核心servlet来给控制器分发请求并且提供一些其它的功能来方便web应用的开发,Spring的DispatcherServlet就是用来干这些的。它将Spring IoC容器完全集成在一起,这样你就可以使用所有其它的Spring特性。
Spring Web MVC DispatcherServlet的请求处理工作流如图2.2所示。DispatcherServlet是一种“Front Controller”设计模式的表现(这种设计模式在许多其它的web框架中也很常见)。
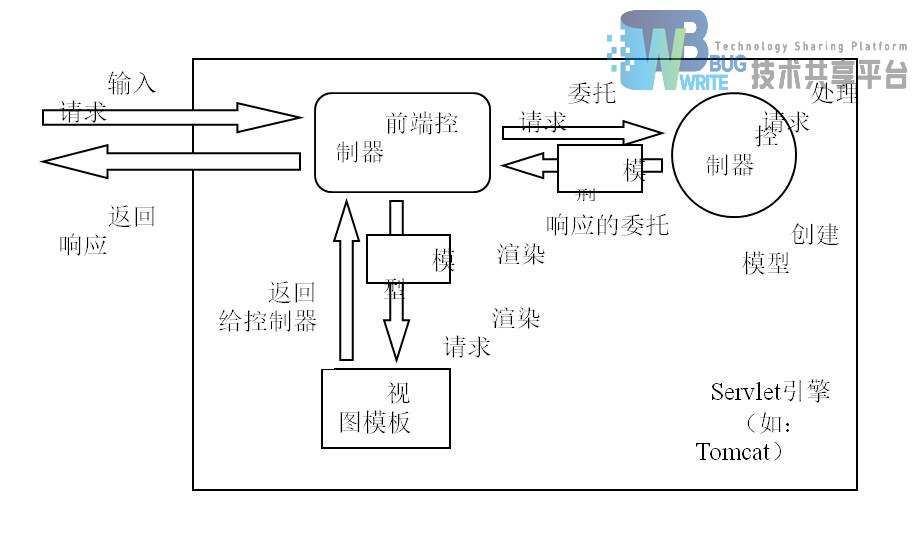
DispatcherServlet是一个真实存在的Servlet(它继承自HttpServlet基类),并且在web应用的web.xml文件中声明。那些你想要DispatcherServlet处理的请求必须在同一个web.xml文件中使用URL映射来映射到这个Servlet。这是标准的J2EE servlet配置。图2.3是对DispatcherServlet的声明和映射。

在上面的配置示例中,所有的以.form结尾的请求都会被”example” DispatcherServlet来处理。这仅仅是配置Spring Web MVC的第一步。
在Web MVC框架中,每个DispatcherServlet都有自己的WebApplicationContext,这个WebApplicationContext继承了根WebApplicationContext定义的所有的beans。图2.4为Spring Web MVC中的上下文层次关系。
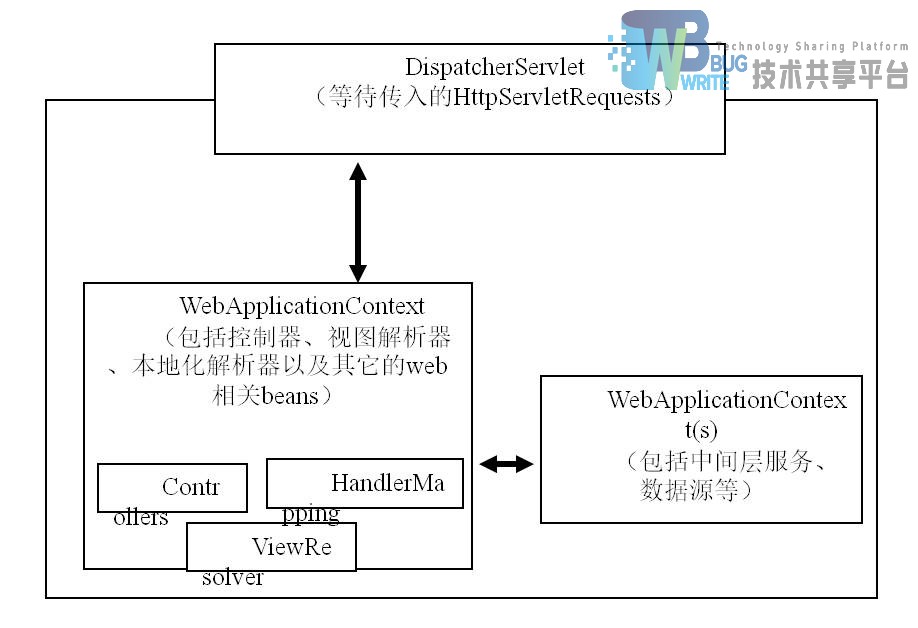
框架将会在初始化DispatcherServlet的时候,在你web应用的WEB-INF目录中寻找一个名字叫[servlet-name]-servlet.xml的文件,然后创建在那个文件里定义的beans。
WebApplicationContext是一个对单纯的ApplicationContext的扩展,对web应用增加了一些额外的特性。它区别于普通的ApplicationContext的地方是,它可以解析主题,并且它知道自己与哪个servlet相关联。
Spring DispatcherServlet有一些特定的beans来实现处理请求和获取正确的视图返回给用户。这些beans被包括在Spring框架中并且能在WebApplicationContext中配置,就像其它的beans一样的配置方式。
一些比较重要的接口定义以及他们的功能列举如下:
- HandlerMapping:选择对象来处理来自内部或者外部的请求。
- HandlerAdapter:对请求进行处理。
- Controller:介于Model和View之间来管理请求和返回合适的响应。他就像一个门,来对传入的请求进行处理。它从Model获取数据,传递给View并将View展现出来。
- View:用于向客户端返回数据。一些请求可能会直接请求到视图,而不经过模块部分,其它的请求三者都要经过。
- ViewResolver:根据逻辑名称为视图选择一个View。
- LocaleResolver:获取并且保存用户的位置信息。
- MultipartResolver:提供对文件上传的请求的封装。
以上的每个接口对整个框架都有重要的作用。这些接口提供的抽象层用处非常大,所有继承自这些接口的类都按照同样的特性建立在Servlet API之上。开发者可以自由的去编写他们的实现类。Spring MVC使用Java的java.util.Map接口作为数据Model,数据Model与View共同生成最终的返回页面[12]。
2.4 MyBatis介绍
MyBatis是一个在Java和.NET平台的持久层框架,它将SQL声明与存储过程使用XML描述[13]。MyBatis是一个自由软件,基于Apache License 2.0发布,它的原名为iBATIS[14]。
MyBatis允许你可以使用所有的数据库功能,比如存储过程、视图、任何复杂的查询,以及数据库厂商所专有的功能。它经常被用来处理遗留数据库、规范化的数据库或者是需要完全的控制SQL执行的时候。
它相对于JDBC简化了编码,SQL语句仅仅需要一行代码便可以执行。这样便节约了时间,避免了一些常见的失误,比如忘记关闭数据库连接、编写了一个错误的数据映射、超过了结果集的数量限制或者是查询结果不仅仅是一条。
MyBatis提供了一种映射引擎,将SQL结果映射到对象树中。SQL语句可以通过使用内置的有XML类似语法的语言来动态的建立,或者通过使用Velocity集成插件来使用Apache Velocity建立。MyBatis集成在Spring Framework和Google Guice中,这个特性可以允许自由的构建商业应用并且不需要调用任何的MyBatis接口。
MyBatis支持声明式的数据缓存。MyBatis集成了:OSCache,EHcache,Hazelcast和Memcached,并且支持集成自定义的缓存工具。
MyBatis提供一套自动生成代码的工具:MyBatis Generator。MyBatis Generator将会检查一个数据库表(或者许多表),然后生成MyBatis项目用来支持增删改查操作。
2.5 Bootstrap介绍
2.5.1 Bootstrap概述
Bootstrap是一个用来创建网站和web应用的工具集。它包含许多基于HTML和CSS的设计模板:排版、表单、按钮、图表、导航、其他的界面组件以及可选的JavaScript扩展。它是GitHub上最流行的项目,NASA和MSNBC网站都在使用此框架。
Bootstrap有相对不完整的对HTML 5和CSS 3的支持,但是它兼容所有的主流浏览器。从2.0版本开始,它开始支持响应式设计。这意味着网站页面的视图设计根据设备的特点来动态的调整。
Bootstrap是Twitter发布在GitHub上的开源软件。开发者可以参与项目并且对平台贡献自己的力量。
2.5.2 结构和功能
Bootstrap是模块化的,包含一系列的LESS样式,用来实现工具的不同部件。一个叫做bootstrap.less的样式表包含了组件的样式。开发者可以选择自己需要的组件来创建自己的bootstrap.less文件。使用LESS样式表语言允许用户使用变量、函数、运算符、嵌套选择器,以及所谓的mixins。
自从2.0版本开始,在Bootstrap网站上添加了自定义的配置选项。开发者可以在一个表单上选择想要的组件和调整参数,然后生成配置好的预编译CSS样式表。
1.栅格系统和响应式设计
Bootstrap默认支持940像素宽度的栅格布局。另外,开发者可以使用一个可变宽度的布局。工具集中有四个参数来使用不同的分辨率和设备类型:手机、竖屏、横屏格式、平板电脑、有低分辨率和高分辨率的电脑。页面会自动根据这些分辨率来调整列的宽度。
2.CSS样式表
Bootstrap提供一系列的样式表来为主要的HTML组件提供基本的样式定义。这样可以对不同的浏览器和不同宽度的设备提供一套统一的文字格式、表格、表单项目布局。
3.可重用的组件
除了常用的HTML元素,Bootstrap包含一些其它的样式元素:带有高级特性的按钮(比如按钮组、带有下拉选择的按钮、导航列表、横向、纵向的标签、面包屑导航、分页等等)、标签、高级的排版功能、缩略图、带格式的警告信息以及进度条。
4.JavaScript插件
JavaScript组件基于jQuery JavaScript库。它提供附加的用户界面元素,比如对话框、工具提示以及轮播。他们也扩展了一些已经存在的页面元素,包括:一个输入框自动完成的功能。
2.6 jQuery介绍
jQuery是一套跨浏览器的JavaScript库,简化HTML与JavaScript之间的操作。目前是由 Dave Methvin 领导的开发团队进行开发。全球前10000个访问最高的网站中,有59%使用了jQuery,是目前最受欢迎的JavaScript库[15]。
jQuery 是开源软件,使用MIT许可证授权。jQuery的语法设计使得许多操作变得容易,如操作文档对象、选择DOM元素、创建动画效果、处理事件、以及开发Ajax程序。jQuery 也提供了给开发人员在其上创建插件的能力。这使开发人员可以对底层交互与动画、高级效果和高级主题化的组件进行抽象化。模块化的方式使 jQuery 函数库能够创建功能强大的动态网页以及网络应用程序[16]。
jQuery有下列特色:
- 跨浏览器的DOM元素选择
- DOM巡访与更改:支持CSS 1-3
- 事件(Events)
- CSS操纵
- 特效和动画(移动显示位置、淡入、淡出)
- Ajax
- 延伸性(Extensibility)
- 工具:例如浏览器版本(已取消自带,改由jQuery Migrate plugin外挂提供)和each函数。
- JavaScript插件
- 轻量级
jQuery 1.8.0版时(自带Sizzle.js):
| 文件 | 行数(行) | 大小(KB) |
|---|---|---|
| jquery-1.8.0.min.js | 2 | 91 |
| jquery-1.8.0.js | 9228 | 254 |
- DHTML DOM选择器与链式语法
经由jQuery的DHTML DOM选择器,可以更容易的操作在复杂的树状HTML中的任何DHTML DOM对象,并可用链式语法对同一对象的不同属性进行操作。
例如:
javascript
$("p.surprise").addClass("ohmy").show("slow");
相当于:查找HTML的
标签,且其class为"surprise"的DHTML DOM对象,将其Class属性多加上一个"ohmy"(通常是配CSS的定义做显示时的配色修改),打开显示。
- CSS 1-3选择器:支持CSS选择器选定DOM对象。
- 跨浏览器:跨浏览器的AJAX解决方式,支持InternetExplorer 6.0+、Opera 9.0+、Firefox 2+、Safari 2.0+、Google Chrome 1.0+
- 简单:较其它JavaScript库更易于入门。
2.7 小结
本章简要介绍了开发过程中用到的几个比较重要的工具与框架。在项目创建和最后的部署过程中,Maven工具为项目的依赖的解决和编译打包提供了很好的解决方案。而在项目开发过程中,Git工具为代码管理、版本控制以及进度统计,都提供了很大的帮助[17]。
本章还介绍了四种框架:Spring MVC、MyBatis、Bootstrap和jQuery。前两者是后台框架,提供了一系列的类与接口,用于实现系统功能、简化与美化代码结构设计,并提供了一些工具来方便开发者实现相应的功能[18]。后两者为前台框架,简化了前台的开发过程,提供封装好的方法来让前台交互更加方便,界面更加友好。这四种框架为开发的核心框架,它们极大的提高了生产率,并且使最终的产品不仅内部结构,而且外部表现都健壮、美观。
3 基于Web的图书推荐系统展示平台设计
3.1 系统总体设计
3.1.1 总体功能描述
本课题是要开发一套轻量级、功能完善的基于Web的图书推荐系统展示平台。利用此平台,对图书信息进行展示与推荐,对用户提供注册与登录功能。由于原始数据为从豆瓣依照网站网页结构抓取得来,并不适用于系统直接读取,于是需要将原始数据表格进行重新设计,遍历分离所需数据存入新设计的表中,使其可以更便捷的查询与处理。开发过程需要考虑Spring MVC框架,将功能按照模块、视图、控制器三部分分离,模块与视图适度的模块化使其可以较好的重用。beans使用注解来注入,这样可以提高小的个人项目的开发效率。在开发开始,配置Maven来解决需要的依赖包,创建Git仓库,来控制版本。
3.1.2 系统模块组成
首先将系统在Spring MVC的基础上分为了三层,分别为:Web层,服务及模块层,数据层,而Web层中,分为Controller与View模块,View为Controller服务,按照预定义的格式来展示Controller的数据。Controller将数据访问与一些公共的逻辑算法交给Model来处理,Model将处理结果交还给Controller。而Model类就像前面Controller给他的任务,负责与界面无关的逻辑计算与数据库的访问、以及其它格式数据的获取。结构如图3.1所示。
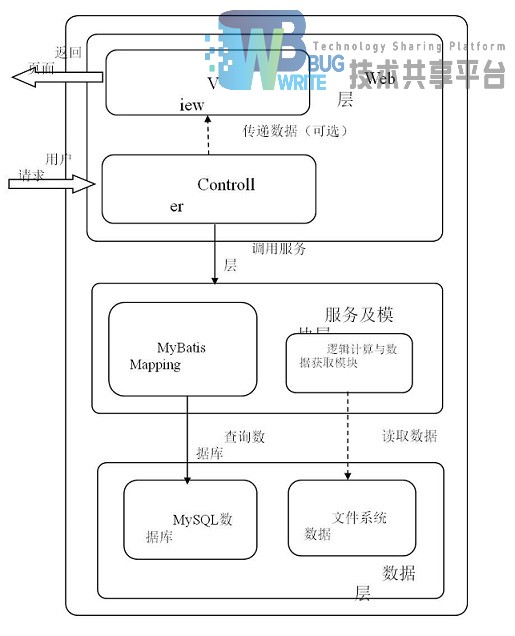
Web层负责处理用户的请求,其中Controller会接收DispatcherServlet分发过来的请求,Controller调用服务与模块层中的模块,进过逻辑计算,生成最终的数据,将数据通过键值对的方式,将视图通过字符串方式传递给DispatcherServlet,DispatcherServlet再读取对应的View,使用View作为模板,生成最终的页面,返回给用户。
服务与模块层负责逻辑计算与数据获取。其中MyBatis Mapping模块为通过MyBatis Generator自动生成的DAO类,以及自定义的DAO类,用于连接MySQL数据库并且执行增删改查操作。而逻辑计算与数据获取模块包含了公共方法类,某些特殊的算法计算,以及对配置文件的查询取值。
最底下的数据层,包括数据库系统与文件系统,是用来存储数据与配置的层。其中数据库采用MySQL数据库,配置文件使用Java自带的.properties文件。
三层之间是互相独立的,只有最近的两层之间可以访问:服务与模块层只可以访问数据层,而Web层只可以调用服务与模块层。其中,服务与模块层中的逻辑计算与数据获取模块,每个模块之间是相互独立的,模块与模块之间不可以互相访问,这样用来降低耦合性,每个模块完成一个完整的任务。由于Web请求的模式决定Web应用只能是被动接收请求,并且Web应用没有涉及费时的网络获取,在代码中没有回调函数,所以层与层之间的调用为单向的,即模块层只可调用数据层,让数据层来执行操作,然后返回数据给模块,Web层调用模块层,将一些逻辑计算与数据获取的过程交给模块来完成,结果返回给Web层,而不可能模块层主动的调用Web层,来对其中的值进行更改,而后返回给用户一个新的页面。在Web层中,View模块只负责对数据进行格式化,生成最终用户页面,因此,它只接收Controller模块的值,而与程序的其它层次模块之间不可以通信。这样,在编写Controller模块时,并不需要了解数据库的组织结构以及配置文件的具体文件名等,只需要知道调用哪个模块,将需要的参数传入模块,模块返回的值就是所需要的数据。而在编写View模块时,也不需要了解其它各个层次都有什么作用,只需要分析页面哪个部分的数据是动态获取的,然后将此部分数据安排给Controller,让Controller传过来就可以了,这样将不同模块之间的耦合性降到了最低。而Controller就像一个乐队的指挥,按照需求调用各个模块,让系统的各个部分井然有序的工作。
3.2 模块详细设计
3.2.1 数据库设计
1.原始数据库
原始数据库存储从豆瓣抓取下来的数据,分为三张表:book_author_info,book_online_info,book_publishing_info。
book_author_info表存储作者信息 ,分为图书编号、作者姓名、作者简介与介绍四列。作者简介内容包括作者的生平以及与此书和作者都有关的一些事件介绍,介绍列与前者相同。作者姓名列存储了各个作者加国籍的信息,需要进行清洗。
book_online_info表存储图书的一些社会化信息 ,分为图书编号、标签、访问次数、5星评价数量、4星评价数量、3星评价数量、2星评价数量、1星评价数量、想读用户数量、在读用户数量、已读用户数量、还想阅读的书 这十二列。其中标签列将所有的标签,带上打标签的次数都放到了同一个字符串中,需要对其清洗。
book_publishing_info表存储了图书的出版信息 ,分为图书编号、ISBN号、书名、作者姓名、图书描述、图书目录、包装类型、定价、总页数、出版社名称、出版时间以及图书封面缩略图名称这十二列。作者姓名与book_author_info表的作者姓名列重复,而定价、总页数等数据使用varchar来存储,出版社也没有构建序号,不便于检索,所以这些内容都需要清洗整理。
2.清洗后数据库
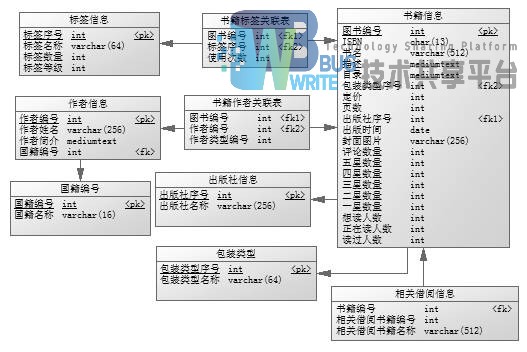
清洗后的数据库是可以直接拿来网站使用的,从原始数据库中数据清洗整合出来的数据,分为九张表:book_info,tag_info,book_tag_relation,author_info,book_author_relation,nationality_info,publisher_info,binding_type,book_relation,内容如表3.1-3.9所示。
book_info表内容
| 表名称 | 书籍详细信息表 |
|---|---|
| 列名称 | 图书编号、ISBN号、书名、书籍描述、书籍目录、包装类型序号、定价、页数、出版社序号、出版时间、封面图片名称、评论数量、5星评价数量、4星评价数量、3星评价数量、2星评价数量、1星评价数量、想读人数、正在读人数、已读人数 |
| 描述 | 其中书名数据类型由原来的text转换为varchar,便于构建索引,提高查询速度。将原先耦合在一起的包装、出版社数据独立出来,只在表中引入其序号,便于按不同类型来查询。将定价和页数的数据类型由varchar改为int,方便程序读取,提高查询速度。定价数据类型并没有采用double,因为它是固定的两位小数,精确到分即可,并没有必要采用比较大的double类型。 |
tag_info表内容
| 表名称 | 标签内容表 |
|---|---|
| 列名称 | 标签序号、标签名称、标签数量以及标签等级 |
| 描述 | 标签序号为自动生成的这个标签唯一的序号,用来识别标签。标签名称是清洗出的单个的标签,使用varchar存储,便于生成索引,提高搜索速度,标签数量为在所有图书的标签中,标签出现的次数。 |
book_tag_relation表内容
| 表名称 | 图书与标签关系表 |
|---|---|
| 列名称 | 图书编号、标签序号以及使用次数 |
| 描述 | 图书编号为book_info表中的主键,标签序号为tag_info表中的主键,使用次数为给这本书打这个标签的用户的数量。 |
author_info表内容
| 表名称 | 作者信息表 |
|---|---|
| 列名称 | 作者编号、作者姓名、作者简介内容、作者的国籍编号 |
| 描述 | 作者编号为自动生成,是表中的主键,作者姓名是将原始数据中的作者姓名清洗出单个的作者后,放入表中的。改用varchar存储,便于生成索引。国籍编号为nationality_info的主键。 |
book_author_relation表内容
| 表名称 | 书籍与作者关联表 |
|---|---|
| 列名称 | 图书编号、作者编号 |
| 描述 | 图书编号对应book_info表主键,作者编号对应author_info表主键。 |
nationality_info表内容
| 表名称 | 国籍信息表 |
|---|---|
| 列名称 | 国籍编号、国籍名称 |
| 描述 | 国籍编号为自动生成的主键,国籍名称为从作者信息中解析出来的作者的国籍。 |
publisher_info表内容
| 表名称 | 出版社信息表 |
|---|---|
| 列名称 | 出版社的序号、出版社名称 |
| 描述 | 出版社序号为自动生成的主键,出版社名称为从原始数据中清洗出来,转换为varchar格式的数据,方便生成索引以提高查询速度。 |
binding_type表内容
| 表名称 | 包装类型信息表 |
|---|---|
| 列名称 | 包装类型序号、包装类型名称 |
| 描述 | 包装类型序号为自动生成的主键,而包装类型名称为从原始数据中清洗出来,转换为varchar类型的数据。 |
book_relation表内容
| 表名称 | 相关借阅信息表 |
|---|---|
| 列名称 | 书籍编号、相关借阅书籍编号、相关借阅书籍名称 |
| 描述 | 书籍编号与相关书籍借阅编号都来自于book_info的主键。而相关借阅书籍名称为书籍的字符串名称,因为有部分相关借阅书籍可能不在数据库中,所以有必要将其字符串名称存于表中,可以拿去搜索或者进行其他一些操作。 |
3.用户数据
用户数据是用户的登陆注册以及访问记录的表。其中的数据为Web应用自己生成,而不是预先装入系统之中的,分为:user_info,user_visit_history,user_search_history,内容如表3.10-3.12所示。
user_info表内容
| 表名称 | 用户信息表 |
|---|---|
| 列名称 | 用户编号、用户名、密码、用户邮箱、用户状态、用户口令 |
| 描述 | 其中用户编号为自动生成的主键,用户名为用户注册时所起的名称,与密码一起用于登录。密码使用SHA算法加密,用户邮箱为注册时填写,用于激活账户与找回密码之用。用户状态分三种:0:已注册,未激活,1:注册并激活,2:密码已丢失,需要重新找回。用户口令取自第一次登录的session id,用于保持用户持久登录状态。 |
user_visit_history表内容
| 表名称 | 用户访问记录表 |
|---|---|
| 列名称 | 用户编号、用户访问图书编号、访问时间、访问来源、访问来源图书编号 |
| 描述 | 用户编号对应user_info表中的主键,用户访问图书编号为用户打开的图书介绍页面中图书的编号,访问时间为打开图书介绍页面的时间,访问来源分三类:0:首页,1:搜索结果,2:其它图书推荐,其中访问来源为2的,需要填写访问来源图书编号。 |
user_search_history表内容
| 表名称 | 用户搜索记录表 |
|---|---|
| 列名称 | 用户编号、用户搜索关键词、搜索时间 |
| 描述 | 用户编号对应user_info表中的主键,搜索关键词为用户在搜索框中输入的关键词,搜索时间为发生搜索事件的时间。 |
3.2.2 页面原型设计
使用快速原型工具Axure RP Pro,根据功能设计了需要实现的页面的原型:首页、搜索结果页、图书展示页、注册页面、登录页面。生成的首页原型效果如图3.2所示。
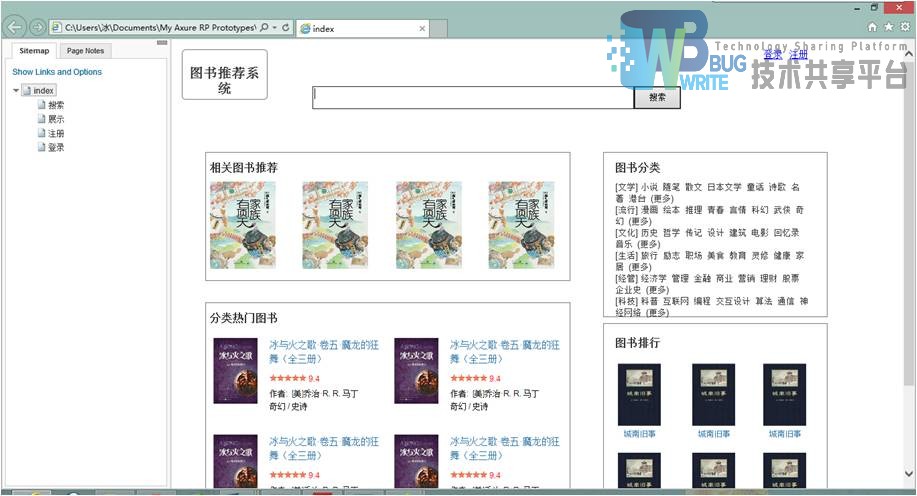
首页顶部包含一个logo,链接到本页;搜索框,提供对图书的搜索入口。以及登陆和注册链接,用于用户的注册与登录管理。正文部分分为四个大模块,名称分别为:相关图书推荐、分类热门图书、图书分类以及图书排行。图书推荐模块列出单本书的缩略图与简要介绍,而分类热门模块列出了几个大的图书分类,以及几本此分类下的比较热门的图书。图书分类模块列出了所有的图书分类,用户可以直接点入查看此分类下的所有图书。图书排行列出前九本最热门的图书。页脚部分注明页面版权信息,以及创建年份。
搜索页面页眉页脚与首页相同,正文部分为一个搜索结果列表,显示搜索结果中的15条记录,每条记录显示图书缩略图、书名、作者、出版社、出版日期、价格以及评分。正文底部是分页,列出了结果的页数,可通过点击来查看后面的搜索结果。右侧列出了热门图书列表,用于向用户推荐。
图书展示页面页眉页脚与首页也相同,正文部分分四大块,第一块为图书基本信息,包括标题、缩略图以及一些图书在版编目信息:作者、出版社、出版时间、页数、定价、装帧、ISBN号。同时还显示评分以及各个星评分数量。第二块为内容简介,是对书内容的简要介绍以及图书目录。第三块为作者简介,是对图书作者以及译者的简要介绍。第四块为相关推荐,展示阅读此书的人还阅读了的书籍。由于原始数据并不包含用户评论,因此用户评论的内容并没有加入展示。
注册页面和登录页面较为简单,用户填写用户名、邮箱、密码、确认密码,之后点击注册即可。登录时,用户输入用户名、密码,然后登录系统,会跳转到首页,首页右侧顶端登录注册不再显示,改为用户名与退出。
3.3 小结
本章介绍了本课题所研究的基于Web的图书推荐系统展示平台的系统总体设计与详细设计。总体设计主要讲述了系统设计的层次结构,并且规定了系统各层各模块之间的组织结构与通信规则。详细设计部分对数据库进行了设计,列出了各个表的结构与描述。并且使用页面原型工具构建了简单的页面,来作为之后页面开发与功能模块划分的依据。总体合计与详细设计在系统开发之前,对之后系统的结构与功能都起到非常重要的影响,结构的好坏直接影响到系统的性能。此章是下一步实现系统的必要步骤和重要依据。
4 基于Web的图书推荐系统展示平台实现
4.1 环境的搭建
4.1.1 数据库的建立与数据的导入
PowerDesigner创建一个物理数据模型,配置好数据库类型,添加表结构,将在详细设计中所设计的数据库信息与列信息、自增列属性输入到表结构中,生成如图4.1所示的物理结构设计图。
使用其自动生成工具,生成用于创建数据库的SQL脚本。之后,使用MySQL工具导入到数据库中。同时,将原始数据也使用MySQL工具导入到数据库中。
4.1.2 工程建立
使用Eclipse创建一个Spring MVC项目,系统会自动生成一套目录结构,如图4.2所示。
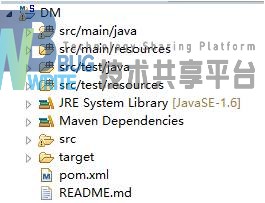
- src/main/java目录用来存放项目的主体部分的源代码,所有的Controller模块、Model模块,以及DAO的Java类,都放在这里,在发布的时候,这里的源码会在编译成class文件后,放入WEB-INF目录下的classes目录。
- src/main/resources目录用来存放项目的配置文件以及MyBatis的Mapping文件。在部署过程中,也会被放入WEB-INF目录下的classes目录中。
- src/test/java目录用来存放项目的测试类,src/test/resource目录用来存放项目的测试配置文件,这些都会在部署时,放入WEB-INF目录下的test-classes目录中。
- JRE System Library包含系统中安装的JRE的库,在项目创建时,可以选择版本。
- Maven Dependencies包含了在Maven的POM配置文件中所配置的依赖包,这些包在工程创建时,由Maven从Maven仓库中下载到本地缓存,并且链接到工程中。
- src目录分main和test,而main/webapp目录下有resources与WEB-INF目录,其中resources目录是在servlet-context.xml中配置的,用于存放页面中的资源的目录,分为css、img、js三个目录,WEB-INF目录分为classes、spring与views目录以及web.xml文件,web.xml文件为Java Servlet的标准配置文件,Spring就在这里配置进去。classes为应用发布时,.class文件的目录,spring目录为spring配置文件存放的目录,用于修改配置,添加beans用于注入等。views目录为视图模块存放的地方,使用jsp作为视图文件。
- target目录为自动编译的目录,目录中有所有类、测试类的编译结果.class文件,以及Maven的配置文件pom.xml。
- pom.xml文件为Maven的配置文件,它包含了项目的基本配置、依赖包以及插件配置。项目创建时,默认只有Spring MVC的基本配置。
4.1.3 版本控制
为了开发的方便,防止不必要的损失以及对进度的掌控,项目一开始便进行了版本控制,在GitHub网站创建了一个私有仓库,项目的根目录下初始化了Git本地仓库,配置好全局变量:用户名、邮箱以及SSH key,项目目录下加入远程的GitHub仓库,之后便可以添加文件、提交更改并且推送到远程服务器上。
修改提交的节点选择在每次一个功能完成之后或者是对之前的文件需要进行比较大的修改之前。功能完成之后提交,可以确保自己能够定期的跟踪到完整的可运行的项目,不至于两次提交之间项目变化过大,如果想要修改,那就不容易找到一个合适的检出时间点。进行比较大的修改之前提交,虽然可能一个功能并没有完成,但是修改过程中可能要参考到之前的部分功能,所以仍有必要将其保存提交。在修改完之后,最终确定了用新的方案,再次提交。
4.1.4 MyBatis配置
MyBatis官方提供了一个自动生成代码的工具:MyBatis Generator(MBG)。它会检测数据库的所有表,并且生成可以用来访问数据库表的代码。这样可以减轻最初访问数据库所需编写代码的工作量。MBG提供了所有常用的数据库操作:增删改查。对于单表的操作,只需要使用这一套生成的类即可,生成结果如图4.3所示。

在生成的文件中,dao为mapper接口,存放TableNameMapper.java文件,用来在配置中注入或者使用SqlSession来获取实例,对数据库表执行增删改查操作。model为表结构的类TableName.java和查询条件构造类TableNameExample.java,TableName.java用于存储对应表的响应条目值,用来实现update和insert操作,以及查询出结果的存储。TableNameExample.java用来构造where语句,用于执行select操作。在数据库中有多于两个列的类型为TEXT或者BLOB,那么除了生成TableName.java,还会生成一种TableNameWithBLOBs.java的文件,其中TableName.java负责存储一般的数据类型,TableNameWithBLOBs.java文件负责存储TableName.java中所有数据之外,还包括了TEXT和BLOB类型的数据。mapper目录存储xml配置文件,用于支持在TableNameMapper.java文件中定义的操作。
将代码和配置文件加入到工程中之后,会出现编译错误,显示一些引用的类不存在于工程中。查找原因,发现是因为项目中没有加入数据库与MyBatis的依赖,修改pom.xml配置文件,加入spring-jdbc、mybatis、mybatis-spring与mysql-connector-java依赖配置。
在src/main/resources加入mybatis-config.xml,用来为MyBatis提供连接数据库的配置与Mapper类集合的配置。创建Mysql.properties文件,将配置写入文件中以便复用。
4.2 数据的清洗
由于原始数据并不能直接拿来使用,因此需要按照之前设计的数据库,将三个表中的原始数据清洗后,存入新设计的表中,程序流程如图4.5所示。
程序会先定义起始和终止图书编号,之后,从第一个图书编号开始,通过主键,查询到图书的数据,将需要的值取出,比如作者信息。作者信息包括了作者国籍、作者姓名以及其它作者姓名,格式如图4.4所示。

开始打算通过一个完整的正则表达式来对作者信息进行解析,但是由于Java的正则表达式并不能够分辨出中文标点与中文文字,因此,先对字符串做初步的清理:将“编著”、“译者”、“主编”替换为英文斜杠“/”来区分不同的作者,将中英文逗号、中英文括号等内容都替换为英文分号“;”,用于区分国籍与作者。之后,使用将字符串按照斜杠来分割成一个字符串数组,数组中每个字符串代表一个可能带有国家信息的作者名称,使用正则表达式:”^(;([\u4e00-\u9fa5]+);)?([\w\u4e00-\u9fa5\.•]+)”来匹配,取出可能以分号加中文字符开头的,作为国籍,以英文字符或者中文字符组成的连续的词作为作者姓名。
之后,拿国籍信息去国籍信息表中查询,没有此项,则作为一个新的条目插入,有则不做处理。在有的数据清洗过程中,比如标签,它有一个统计数据,那么如果表中有这个标签,会将统计数据增加一个。作者姓名与国籍类似,采用相同的方法来存储。之后便查询下一条图书记录。
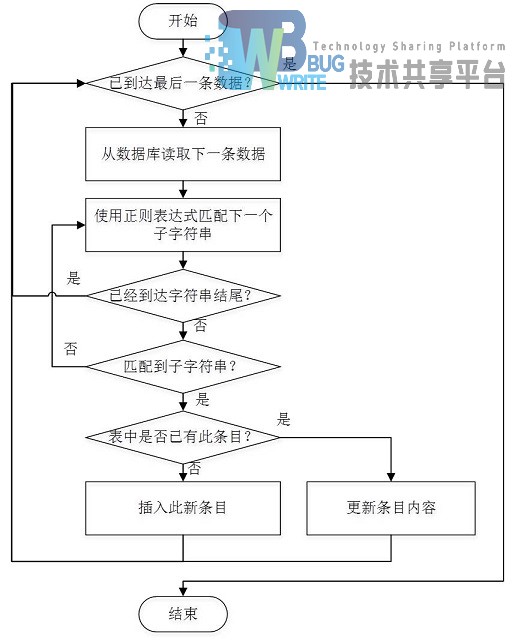
为了加快读取速度,每次的读取并不只是一条,而是多条图书数据一起读取出来,这样会一次将较多的数据调入内存,降低磁盘IO操作,加快速度。可是由于每本书有三到五个作者,每个作者和国籍都会在解析出来之后变为一个独立的需要插入到数据库中或者去数据库中查询的条目,随着数据条数的增多,同时提交的事务数量会加倍增长,MySQL系统就出现了session数量不足的错误。于是,将每次取出的条数减少,并且在每次操作完成一组数据后,提交并关闭数据库,在需要操作前,再打开数据库。这样就能够即时的关闭用完的session,不会出现由于大量已结束的事务占用session而报错的问题。
同样为了加快数据清洗速度,使用两台电脑,一台运行数据库系统,另一台运行Java程序,MySQL系统打开网络用户的访问权限和所在系统的防火墙3306端口,另一台连接并处理数据。由于数据库操作占比较大的时间,所以瓶颈依旧在运行数据库的系统中,不过相对与在同一个系统中,CPU占用和内存占用有一定程度的下降。
4.3 系统开发
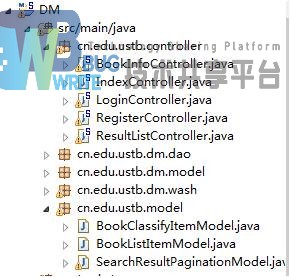
按照总体设计阶段的分层,将系统分为三个包:cn.edu.ustb.controller、cn.edu.ustb.dm、cn.edu.ustb.model。如图4.6所示。
4.3.1 控制器类
controller包为系统结构中的controller模块,根据功能,划分为了五个类:BookInfoController.java负责图书详细信息的展示,IndexController.java负责首页的视图内容获取展示,LoginController.java负责登录信息的处理,RegisterListController.java负责对注册信息的处理,ResultListController.java负责处理查询。
controller类将SqlSessionFactory使用注解的方式注入类中,并且使用注解来实现Controller类与请求映射。使用Log4j工具来输出日志。借鉴Objective-C的方式,使用setter/getter方法来获取变量,以便延迟加载以及提高利用率。代码结构如图4.7所示。

在最开始,Mapper都是使用注解来注入进来的,但是发现SqlSession的开启与关闭不受到控制,完全靠系统来自动完成,那么在并发数量过大之后,大量线程占用session,很容易出现session数量过多的问题,其他人访问不了网站。将Mapper的获取方法改为了使用SqlSession的getMapper方法来获取,这样就可以完全控制session开启时间、结束时间。在每次访问页面的时候,包括浏览器会话没有关闭时刷新,都会重新开启一个新的SqlSession,获取新的Mapper实例,然后执行数据库操作,最后,关闭数据库连接。这样,能够即时的回收过期的SqlSession,防止大量无用的session占用数据库资源。
在使用getter/setter方法时,刚开始将SqlSession的获取放到了getter中,这样会首先检测有没有实例,没有实例再创建,意图是为了延迟加载,在用到的地方才初始化它,并且防止每次使用都创建新实例。可是在实际中却发现,如果用户刷新页面,或者点击分页按钮,系统会抛出错误,说数据库已关闭,无法执行查询操作。原来每次访问,在浏览器没有结束会话时,Web容器会将Controller类的实例保存在内存中,而每次请求只会执行RequestMapping所指定的函数。于是修改SqlSession的获取方式,在浏览器每次发起请求时,通过SqlSessionFactory类的openSession函数来获取一个SqlSession实例。
Mapper的获取也受到了影响,因为每次访问都会创建一个新的SqlSession实例,那么Mapper如果不为null的话,就不会重新创建Mapper实例,这样,Mapper的SqlSession将是已经关闭的session,它不能够执行任何数据库操作。因此,在每次访问时,会将所有的Mapper都重置为null,以使其重新初始化。
4.3.2 模块类
模块类包含一些页面需要的数据结构,对数据的加工函数以及分页功能实现。其中,BookClassifyItemModel.java类为单纯的书籍按照分类来显示信息的模块,其中,借鉴了MyBatis的Example类的方法,添加了一个内部类,在父类中编写了创建内部类的函数,用于创建图书列表。
BookListItemModel.java类为图书的基本信息展示类,用在了图书推荐、图书排行、查询结果展示以及图书详细信息中。在类中提供了计算得分的函数,以及格式化日期的函数,用于在页面中显示。
SearchResultPaginationModel.java类为查询结果分页模块,用于支持查询的分页显示以及分页功能。由于数据量巨大,为了提高查询效率,分页查询并没有采用MyBatis的分页查询方法,MyBatis会在第一次查询时,将所有的符合条件的结果读入内存中,之后再根据分页条件来显示,这样,虽然会在页面跳转的时候很快,但在第一次查询时,会有大量的磁盘IO操作,在数据类大的情况下,会对系统性能造成很大的影响,而搜索结果大部分用户只是关注前几页,后面的结果访问量并不大,这样就有些得不偿失。分页查询采用数据库的limit条件,只在每次查询时获取每一页要显示的数据,在创建了索引以后,这个查询过程是非常迅速的,只将需要的数据读入内存。查询效率提高了,就需要自己来实现分页。
4.3.3 视图类
视图使用jsp作为页面,引入了JSTL的c库来辅助生成布局。视图文件如图4.8所示。
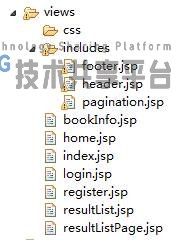
header.jsp为页面顶端的logo、搜索栏与登录注册按钮的部分。footer.jsp为页面底部版权信息的内容。pagination.jsp为分页,根据SearchResultPaginationModel.java的内容来生成分页。
bookInfo.jsp负责显示图书的详细内容,index.jsp负责首页内容的显示,login和register负责登录与注册页面,resultList为搜索结果,只是单纯的搜索结果列表,用于分页时,通过AJAX请求来局部刷新,减少流量。resultListPag为搜索结果页面,是页面的框架,其中引入了resultList,作为第一次访问时,搜索结果的展示。
每个页面都引入header.jsp与footer.jsp,用来引入所需要的布局文件与页面脚本,构建起基本的页面框架。页面导航栏的布局采用Bootstrap的导航栏样式,登录可以从导航栏上直接输入来登录。搜索条件分为标题、作者、出版社,可以对这三者进行查询。
采用JSTL的标准c标签库,方便的实现循环(c:forEach)、判断(c:if、c:when),
页面整体布局采用Bootstrap的响应式布局,首页、搜索结果页将正文部分分为左右两块,图书信息页面只有一个块。在首页中各个块中,每本书作为一个row类型,每个row又分为两个span,用于分割左右两块。一部分布局是由自定义的main.css文件来定制。而自定义的JavaScript也由在footer中引入的main.js来定制那些比如搜索按钮点击事件、分页按钮点击事件、登录等等。
分页按钮的样式采用了Bootstrap的分页按钮,参考Amazon查询结果的分页效果,在页数多于9页的情况下,翻到中部,则只显示部分挨着的页码,结合SearchResultPaginationModel类的结构,完成了查询的分页。
4.4 分析及调优
首页为所有页面中最为复杂的页面,需要查询四块内容,页面效果如图4.9所示。
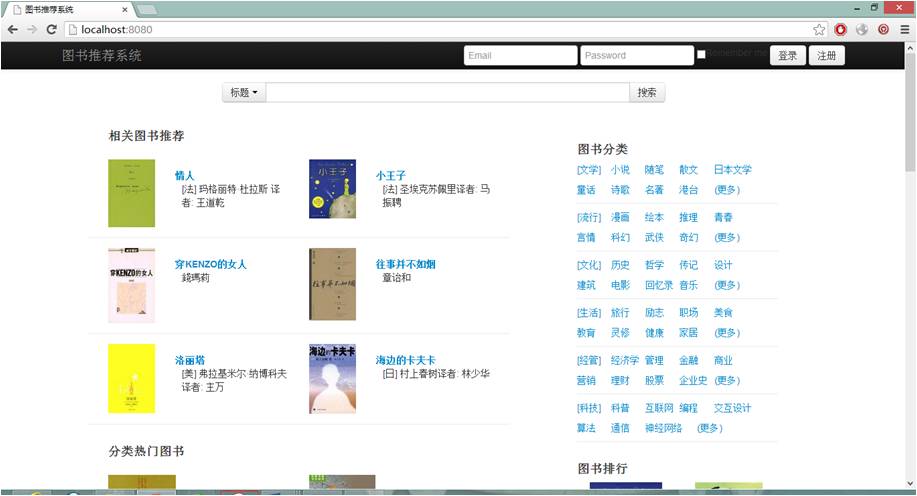
四块内容分别需要按照各自的查询条件来排序,然后取前几个符合条件的结果。在刚开始,没有对数据库优化之前,页面打开速度几乎需要3秒,对查询SQL进行分析,发现,大部分操作时间都消耗在了排序上,于是对排序条件创建了索引,首页的首次打开延迟变得小于1秒,并且由于在控制器中使用getter\setter,部分没有参数的数据会在查询之后一直留在内存中,不会进行第二次查询,所以刷新会返回304,页面内容没有改变。
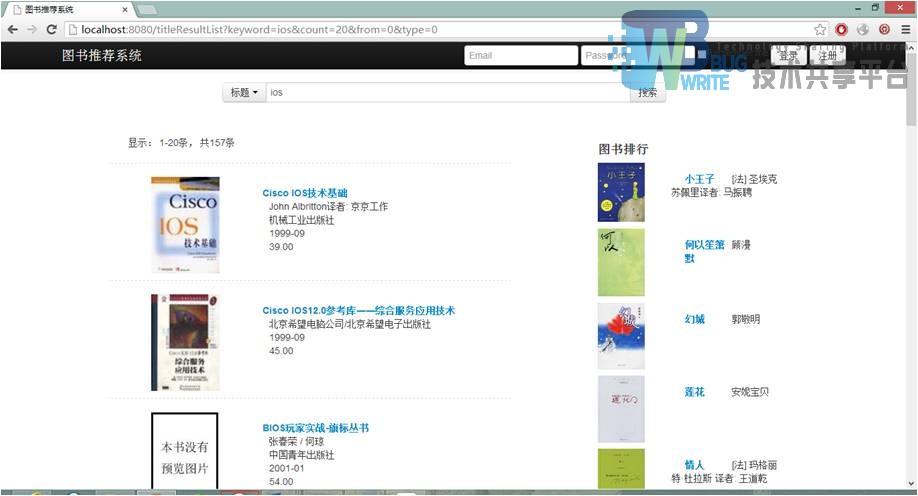
图4.10为查询结果页面。由于此平台不涉及搜索算法的研究,所以搜索结果为从数据库字符串中like出来的。考虑到数据库巨大,若不做处理,将会严重影响查询效率。于是按照查询特点,对图书标题、出版日期两列做了索引,查询速度有了成倍的提升。再加上每次查询使用limit,磁盘内存间的交换操作减少了许多。
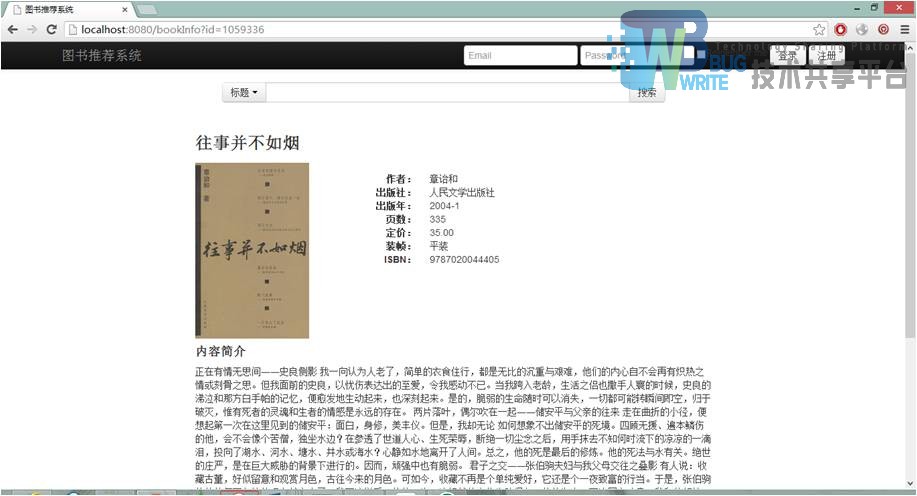
图4.11为图书信息的展示页面,对图书的缩略图、内容以及作者简介做了展示,还有登录失败后会跳转到的登录页面,注册按钮点击后跳转到的注册页面,相对于其它两个相对功能较单一,性能也没有太大的提升空间。
4.5 性能测试
使用Chrome浏览器的开发者工具来进行测试。结果如图4.12所示,首次加载首页需要等待6ms,其它静态的css与js文件几乎不需要时间,在统计结果中,显示为0。之后刷新,Tomcat会从内存中直接取得返回结果,统计如图4.13所示,由图可知,加载页面仅需要用时2ms。
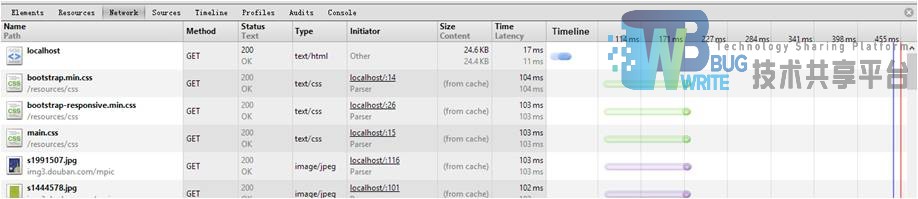
在查询结果页面,查询一个关键词“IOS”,页面的等待时间为223ms。同样由于缓存的作用,刷新的等待时长变为8ms。结果如图4.14与4.15所示。
4.6 小结
参考文献
- 基于B/S模式的网上书店交易平台系统的设计(山东大学·王一锋)
- 基于JSP的学生就业信息管理系统设计与实现(吉林大学·马骁)
- 基于JSP的学生就业信息管理系统设计与实现(吉林大学·马骁)
- 基于MVC设计模式的Web应用框架研究及其实例(吉林大学·王耀辉)
- 基于JSP的网上书店系统的设计与实现(吉林大学·马新)
- 基于J2EE和MVC模式的Web应用研究(武汉理工大学·刘继华)
- 电子商务中JSP技术的应用研究(吉林大学·王白石)
- 基于JSP的网上书店系统的设计与实现(吉林大学·马新)
- 基于JSP/Servlet的三层式网上书店的研究与实现(吉林大学·郭小雪)
- 基于JSP的购书系统的设计与实现(电子科技大学·况晶)
- 网上书店系统设计与实现(吉林大学·关键)
- 基于jsp技术网上书店系统的设计与实现(电子科技大学·胡朝斌)
- 基于B/S模式的网上书店交易平台系统的设计(山东大学·王一锋)
- 电子商务门户网站的研究与实现(大庆石油学院·戴庆)
- 基于JSP的网上购书系统(华东师范大学·王莉)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码客栈网 ,原文地址:https://m.bishedaima.com/yuanma/35423.html