基于springboot和elasticSearch实现的多用户在线论坛
1.项目简介
1.1 简介
随着现在科技的发展,论坛系统越来越多,本系统仿照CSDN做一个java学习论坛系统,开发一个社区讨论交流网站、社交网站。
1.2 技术架构
-
Spring Boot
-
Spring、Spring MVC、MyBatis - SSM
-
Kafka、Elasticsearch
-
Shiro、Spring Actuator
-
Swagger
2.数据库设计
2.1 设计方案
一个简单的论坛系统支持:
-
用户名
-
email
-
主页
-
电话
-
联系地址
-
发帖标题
-
发帖内容
-
回复标题
-
回复内容
-
每天论坛访问量300万左右
-
更新帖子10万左右
在项目的开发前,我思考过怎么去设计一个数据库,下面是我曾经假设过的几套方案:
方案一:发帖主题和回复信息存放在一张表,并在这个表中增加user_name字段
对数据库的操作而言,检索数据的性能基本不会对数据造成很大的影响(精确查找的情况下),而对表与表之间的连接却会产生巨大的影响, 特别在有巨量数据的表之间;因此对问题的定位基本可以确定:在显示和检索数据时,尽量减少数据库的连接以及表与表之间的连接。
- user:用户基本信息表
-
字段有:user_id,user_name,email,homepage,tel,add...
-
forum_item:主题和回复混合表
-
字段有:id,parent_id,user_id,user_name,title,content,....
- parent_id=0或者null表示是主题,否则=n表示是id=n那条帖子的回复
- UserName字段是冗余的,因此在用户修改UserName的时候就会产生同步数据的问题,这个需要程序来进行弥补
方案二:主题表和主题回复分开保存
- user:用户基本信息表
-
字段有:user_id,user_name,email,homepage,tel,add...
-
forum_topic:主题表
-
字段有:id,user_id,title,content,....
-
forum_topic_back:主题回复表
- 字段有:id,topic_id,user_id,title,content,....
方案三:主题表的内容单独设计成一个表
- user:用户基本信息表
-
字段有:user_id,user_name,email,homepage,tel,add...
-
forum_topic:主题表
-
字段有:id,user_id,title,....
-
forum_topic_content:主题内容表
-
字段有:id,topic_id,content
-
forum_topic_back:主题回复表
- 字段有:id,topic_id,user_id,title,content,....
方案四:用户信息分2个表保存,并对相关表进行分表处理
- 简单用户表 tb_user:
-
id , username
-
用户详细信息表 tb_userinfo
-
id,userid , email , homepage , phone , address ...
-
论坛主题表 tb_bbs
-
id , userid , title , ip , repleycount , replyuserid , createtime , lastreplytime
-
论坛内容标 tb_bbs_content (此表可按照bbsid进行分表存储)
-
id,bbsid , content;
-
论坛回复表 tb_bbs_reply (此表可按照bbsid进行分表存储)
- id , bbsid , userid , content , replytime , ip
方案五:增加一个主题缓存表,取每个区的前面100条记录
- 简单用户表 tb_user:
-
字段有:id , username
-
用户详细信息表 tb_userinfo
-
字段有:id,userid , email , homepage , phone , address ...
-
论坛主题表 tb_bbs
-
字段有:id , userid , title , ip , repleycount , replyuserid , createtime , lastreplytime
-
论坛内容标 tb_bbs_content (此表可按照bbsid进行分表存储)
-
字段有:id,bbsid , content;
-
论坛回复表 tb_bbs_reply (此表可按照bbsid进行分表存储)
-
字段有:id , bbsid , userid , content , replytime , ip
-
主题缓存表 tb_bbs_cache
- 字段有:id , userid , title , ip , repleycount , replyuserid , createtime , lastreplytime
下面是针对上面的方案展开的讨论:
-
方案一表面上看起来好像少查了一张表,但由于冗余,因为帖子数量极大,会占用大量的空间。这种数据量大,但是对实时和数据绝对安全性要求较低的应用,大量使用缓存的话可以极大提高处理能力
-
方案一这么设计的话,索引怎么建比较好呢,还有就是会不会造成这个表过热,还有…… 我觉得像论坛这样的系统,使用缓存可以大大降低数据库的负载
-
大家的意思是分成主题表、回复表等多个表? 还是合成一个表然后做物理分区? 哪种更好呢?
-
再这么高插入更新的频率下 索引就有些不实用了,创建索引会降低插入更新的速度而且访问量这么大的情况下,索引不建议采用
-
就这样的一个论坛,实时在更新、发帖、回帖。我觉得在数据库上建立索引不太好,但是如果不建立索引如何来提高查询等方面性能呢?
-
都是分布式数据库了。放在多个表中,直接关联一点都没问题。重要是横向切分
-
认同分表,分库,缓存的做法
问题分析
每天论坛访问量300万左右,更新帖子10万左右。
-
读写比例在30:1左右, 应向读取效率方面倾斜. 索引建立需参考常用读取的主关键字
-
每月数据在10W*30=300W. 可按月分表
-
每年帖子在300W*12=3600W, 推算数据不会小于30T. 可按年分库
结构
-
用户信息 :独立表,userid主键
-
发帖、回帖 :按月表存储,帖子唯一ID主键,日期索引
-
帖子内容明细 :按月存储,帖子唯一ID主键
举例 :一张500万条数据的表
-
更新的时候如果没有索引的话,更新时间大概需要30秒左右,指的是全表更新;而查询某单行记录 却需要10秒左右
-
而加入索引的话,更新时间差不多慢了一倍有余,而查询记录则缩减到毫秒级,快了百倍有余
孰重孰轻 自己选吧~
自己的一点经验
-
分表存储
-
建立索引,SQL按索引查询的速度还是很快的
-
避免整表扫描,先读取主题,在按照主题ID读取回复,再按照用户ID读取用户,而不要使用关联
-
使用缓存
需要分3张表,且建立索引
理由如下:
-
建立3张表可以避免冗余数据,维护起来方便
-
每天论坛访问量300万左右,可见主要的压力来自于查询,sql查询的效率在于避免全表扫描,可见建立索引是必须的
-
关于创建索引会降低插入更新的速度这个问题是不存在的。。。 因为,索引之所以会降低更新的速度的速度,是因为在更新完对应字段后还需要更新对应字段的索引
-
看到更新帖子10万左右,这句话是说,我们可能对发帖标题,发帖内容,回复标题,回复内容这4个字段做更新。。。需要注意的是,这四个字段并不是用来建立表连接的字段,为了优化查询速度我们不会在这四个字段上建立索引,所以从这道题目出发,我们建立的索引不会影响更新帖子的性能
所以,我认为最后的答案是建立3张表,在连接用到的字段上建立索引。
两个表,然后建一个视图是否可行?
视图也是很慢的。
-
每天就更新10万个帖子,每天访问那么多,肯定是不能把所有的主贴放在一个表里,大表分小表,建立常用字段的索引,然后配置缓存。级联关系最好不要配置,等需要的时候再查询
-
虽然题目中没有说明,但实际应用中,查阅帖子通常只会分页显示,而一页最多也就显示几十个帖子,那么实际上只要SQL语句构造得好,T_USER表其实只是跟一个只有几十行结果集的的子查询进行连接,应该基本不用担心出现性能问题。而且实际上,一个万行级的表简单关联百万行级的表(其实镇魂歌数量级在我看来其实也算不上很大的表),在数据库方面完全有很多优化方式,甚至可以通过提高硬件配置来改善性能,实在没有很大必要进行结构上的冗余。一旦结构有冗余,为了保证数据一致性,往往你还要消耗更多的资源,反而得不偿失
分表有垂直和水平分表
-
无论你拿多少记录(甚至是1条),如果两个大表关联都可能会产生非常大的中间值,如果你排序(排序字段没有用到索引),你都可能导致数据库采用各种各样的方式来计算
-
索引会导致插入、更新记录很慢,大家都是知道的
-
水平分表可以解决这个问题,只要你能保证每个表只存适合的记录数(例如100W一个表) (水平分区也可以解决IO的一些问题)
-
还有就读写分离,master是写,slave是读 (再加上cache,一般问题都还好了)
上面都是比较大的工作量,最好是保证你的数据库设计是合理的(范式是第一步,然后考虑反范式),基本上也能满足很多问题了。
方案四 把内容与其它信息分开的好处就是可以让每个表的文件最小化,对数据库操作压力会减小,操作速度会快,还可以搭配缓存,把内容根据情况进行缓存,可以尽量很少访问表数据。
-
对于上述分表方式也可以适用于分库操作,这样就降低了数据库单库的压力,把压力分散到各个机器
-
我的做法就是尽量避免表关联
-
再就是对于sql语句尽量都保证索引有效,不能索引的sql,尽量采用能索引的高效方式解决
外围的方案
-
读方面,生成静态页,或者缓存最新最热的帖子
-
写方面,估计主要是INSERT吧,这个可以异步操作的。所有的写贴操作放到一个队列然后批量执行插入数据库操作
方案四 比较靠谱,再加上定期转储,海量的cache,大型论坛就此搞定。
我觉得应该还是使用3张表比较合适
-
业务上说,很可能主贴跟回复贴拥有不同的扩展,比如附件什么的,都放在一张表里面,假如主贴跟回复存在个性需求,怎么办?无限加字段么?
-
主贴跟回复在同一张表里,会增大锁表的几率
-
索引的确会降低表更新的速度,但是带来的查询效率提升也是很可观的,因此我觉得,索引不能不用,但是要少用
-
建立表时,确实可以通过楼上某位仁兄回复所言,用水平分表的方式,其实原理就是用先算再查嘛
-
在前端表现上,可以使用ajax等方式,分步骤取数据,比如主贴的内容先取出来,然后再逐步加载回复信息等
提高速度的关键
-
建立索引并在查询时充分利用
-
避免使用关联,这样避免整表扫描;使用关联不如多次使用主键查询来的快
-
一些处理的功能尽可能放到内存中来做,比如组织主题和回复
-
使用静态页面也是个不错的做法
方案三 是延续了hibernate二级缓存的思想, 对于经常更新的数据都设计成单独表,这样可以最大程度的利用hibernate缓存。
没有fast=true的设置,有人说or比in好,exists比in好,索引比全表扫描好,分区能提高查询效率,但是分区要降低插入效率。我要说的是,没有fast=true的选项, 如果能找到一步,或者几步公式化的方法能提高效率,那么优化器自己就会做了,根本不用用户担心。假设or比in好,数据库优化器把in语法和or语法走的执行计划一样就可以了,何必折磨用户呢。
说点实际的,很多人张嘴就说,SQL优化就是避免全表扫描,不知道大家有没有了解过索引查找的原理。
索引查找数据有两步要做:
-
第一步是索引中快速查询,索引里只存储了对应表数据的rowid
-
第二步根据rowid去得到全部的数据
所以需要一次磁盘i/o, 不要小看磁盘I/O,通过索引查询出的结果比较多的时候,磁盘i/o的时间是非常大的,这个时候比全表扫描慢得多, 实际上,oracle 10g基于成本的优化器(CBO),选择性不高的索引,优化器根本不会使用,而自动采用全表扫描的方式来做。
这个量级的bbs我设计过,当时是这样做的(方案五)
共四个表:
-
用户表
-
主题表(包含最后回复信息,最后回复人,最后回复id等)
-
回复表
-
主题缓存表(这个取每个区的前面100条记录),一般来说负载最大的就是主题的第一页,所以缓存表是个小表
共3台app集群,1台web,2台oracle一主一备,运行下来速度还是可接受的。
不建议进行表的设计冗余,感觉就想重复代码一样,有坏味道
-
缓存常用的页面和数据
-
读写表或库分开(基于垂直分隔)
-
数据库可以进行垂直分隔(字段分到多个表中),再进行水平分隔(数据分到多个表中)
-
论坛功能可以进行分隔,不同的服务器负责不同的功能,如图片服务器,web服务器,邮件服务器等
总之,就是要细化分工。
支持方案三的设计
读取的操作:
-
显示帖子列表界面,如果主贴内容放在forum_topic表,那么这就是冗余的,假设都要获取100个帖子,一行的数据长度越大,数据库需要扫描的数据块就越多,性能也越差
-
在打开一个帖子时,读操作通过索引关联到两张表(forum_topic和forum_topic_content)性能消耗对整个数据库来说不多
写帖子的操作:
- 发表帖子,对标题表和内容表分别作一个插入
更新非索引列不会引起索引更新:
只要被索引的列(例如回复表的标题ID)不被频繁更新,即使索引所在地行的其它列被频繁update,索引也不会被更新从而产生性能消耗,一张表一天30万次的索引更新,因它引起的性能消耗小到即使数据库安装在奔腾3单核CPU下都能轻松承担下来, 为什么会有人对索引有这么大的误解呢?。对一个论坛(或者绝大部分的系统)来说,检索(SELECT)数据耗费的系统资源远远高于更新数据(INSERT/UPDATE)本身,而索引是专门为检索数据服务的,难道就为了节省更新数据的小小的性能消耗,付出检索100条数据时需要数据库扫描几千万上亿条数据进行数据匹配的代价?如果是这样的话,即使是有32核顶级CPU的数据库作并行查询都未必顶得住。
做数据库设计,还是多了解数据库的原理才好。
数据库切分是必须的
-
垂直切分:用户表、用户信息表、主题表、主题内容表、回复表
-
水平切分:主题1、主题2、主题3、...、主题n
-
缓存:缓存路由表
-
再配合数据库读写分离和集群吧
另:其实论坛修改标题、内容的概率是很小的。大部分都是新增。
最终得到了以下的数据库设计方案 :
2.2 表结构
bbs_user
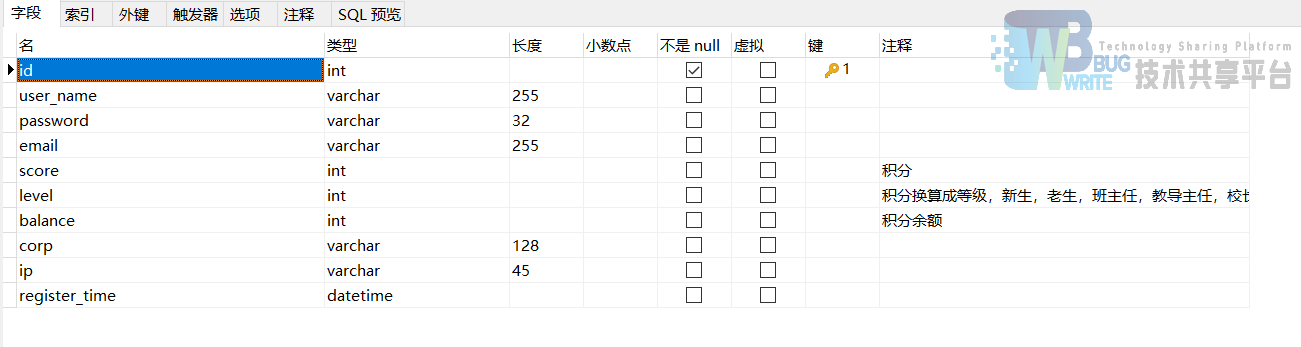
bbs_topic
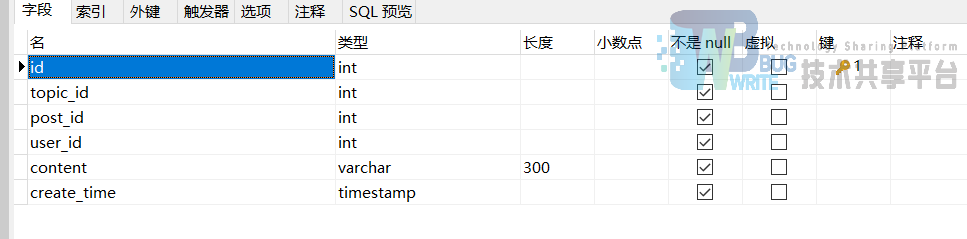
bbs_reply
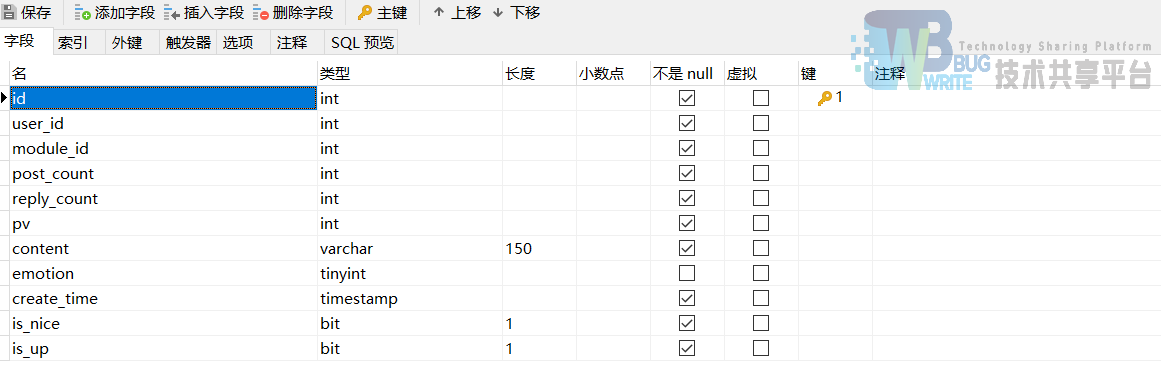
bbs_post
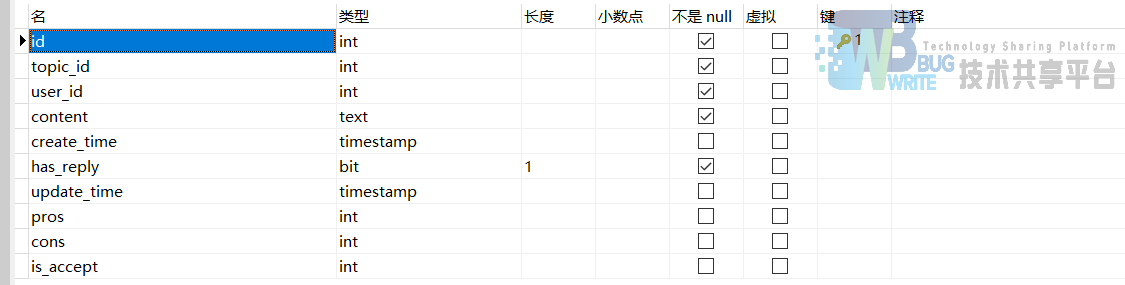
bbs_module
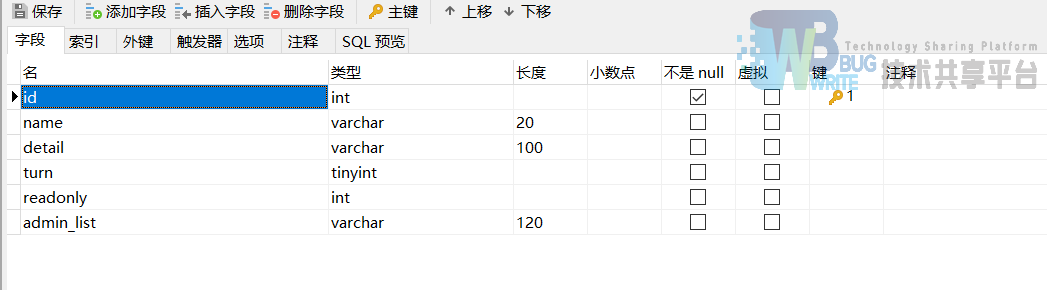
bbs_message

2.3 E-R图

2.4 建立存储过程
```sql
-- 某些模板只读
ALTER TABLE
bbs
.
bbs_module
ADD COLUMN
readonly
INT NULL DEFAULT 0 COMMENT '' AFTER
turn
,
ADD COLUMN
admin_list
VARCHAR(120) NULL COMMENT '' AFTER
readonly
;
-- 用户注册校验,发帖xss校验,验证码
ALTER TABLE
bbs
.
bbs_user
ADD COLUMN
ip
VARCHAR(45) NULL COMMENT '' AFTER
corp
,
ADD COLUMN
register_time
DATETIME NULL COMMENT '' AFTER
ip
;
```
3.项目实现
3.1 工具类
Hash算法加密类
java
public class HashKit {
private static java.security.SecureRandom random = new java.security.SecureRandom();
public static String md5(String srcStr) {
return hash("MD5", srcStr);
}
public static String sha1(String srcStr) {
return hash("SHA-1", srcStr);
}
public static String sha256(String srcStr) {
return hash("SHA-256", srcStr);
}
public static String sha384(String srcStr) {
return hash("SHA-384", srcStr);
}
public static String sha512(String srcStr) {
return hash("SHA-512", srcStr);
}
public static String hash(String algorithm, String srcStr) {
try {
StringBuilder result = new StringBuilder();
MessageDigest md = MessageDigest.getInstance(algorithm);
byte[] bytes = md.digest(srcStr.getBytes("utf-8"));
for (byte b : bytes) {
String hex = Integer.toHexString(b & 0xFF);
if (hex.length() == 1)
result.append("0");
result.append(hex);
}
return result.toString();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private static String toHex(byte[] bytes) {
StringBuilder result = new StringBuilder();
for (byte b : bytes) {
String hex = Integer.toHexString(b & 0xFF);
if (hex.length() == 1)
result.append("0");
result.append(hex);
}
return result.toString();
}
/**
* md5 128bit 16bytes sha1 160bit 20bytes sha256 256bit 32bytes sha384
* 384bit 48bites sha512 512bit 64bites
*/
public static String generateSalt(int numberOfBytes) {
byte[] salt = new byte[numberOfBytes];
random.nextBytes(salt);
return toHex(salt);
}
public static void main(String[] args) {
String passwd = "123456";
String md5 = HashKit.md5(passwd);
System.out.println(md5);
}
}
http请求工具类
java
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(
new InputStreamReader(conn.getInputStream()));
String line="";
String content = "";
while ((line = in.readLine()) != null) {
content += line+"\n";
}
result = content;
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
return null;
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (IOException ex) {
return null;
}
}
return result;
}
public static String get(String url, String param) {
return get(url+"?"+param);
}
public static void main(String[] args){
String url = "http://127.0.0.1:9000/api/resources?resource=my:beetlsql&metrics=ncloc,coverage";
String ret = get(url);
System.out.println(ret);
}
}
3.2 验证码实现
java
public class RandomCodeUtil {
private static int width = 90;// 定义图片的width
private static int height = 20;// 定义图片的height
private static int codeCount = 4;// 定义图片上显示验证码的个数
private static int xx = 15;
private static int fontHeight = 18;
private static int codeY = 16;
private static char[] codeSequence = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9'};
/**
* 生成一个map集合
* code为生成的验证码
* codePic为生成的验证码BufferedImage对象
*/
public static RandomCode generateCodeAndPic() {
// 定义图像buffer
BufferedImage buffImg = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
// Graphics2D gd = buffImg.createGraphics();
// Graphics2D gd = (Graphics2D) buffImg.getGraphics();
Graphics gd = buffImg.getGraphics();
// 创建一个随机数生成器类
Random random = new Random();
// 将图像填充为白色
gd.setColor(Color.WHITE);
gd.fillRect(0, 0, width, height);
// 创建字体,字体的大小应该根据图片的高度来定。
Font font = new Font("Fixedsys", Font.BOLD, fontHeight);
// 设置字体。
gd.setFont(font);
// 画边框。
gd.setColor(Color.BLACK);
gd.drawRect(0, 0, width - 1, height - 1);
// 随机产生40条干扰线,使图象中的认证码不易被其它程序探测到。
gd.setColor(Color.BLACK);
for (int i = 0; i < 30; i++) {
int x = random.nextInt(width);
int y = random.nextInt(height);
int xl = random.nextInt(12);
int yl = random.nextInt(12);
gd.drawLine(x, y, x + xl, y + yl);
}
// randomCode用于保存随机产生的验证码,以便用户登录后进行验证。
StringBuilder randomCode = new StringBuilder();
int red = 0, green = 0, blue = 0;
// 随机产生codeCount数字的验证码。
for (int i = 0; i < codeCount; i++) {
// 得到随机产生的验证码数字。
String code = String.valueOf(codeSequence[random.nextInt(36)]);
// 产生随机的颜色分量来构造颜色值,这样输出的每位数字的颜色值都将不同。
red = random.nextInt(255);
green = random.nextInt(255);
blue = random.nextInt(255);
// 用随机产生的颜色将验证码绘制到图像中。
gd.setColor(new Color(red, green, blue));
gd.drawString(code, (i + 1) * xx, codeY);
// 将产生的四个随机数组合在一起。
randomCode.append(code);
}
Map<String, Object> map = new HashMap<>();
//存放验证码
map.put("code", randomCode);
//存放生成的验证码BufferedImage对象
map.put("codePic", buffImg);
RandomCode code = new RandomCode(randomCode.toString(), buffImg);
return code;
}
public static void main(String[] args) throws Exception {
//创建文件输出流对象
OutputStream out = new FileOutputStream("target/code.jpg");
RandomCode code = RandomCodeUtil.generateCodeAndPic();
ImageIO.write((RenderedImage) code.getBuffImg(), "jpeg", out);
System.out.println("验证码的值为:" + code.getCode());
}
static class RandomCode {
String code;
BufferedImage buffImg;
public RandomCode(String code, BufferedImage buffImg) {
this.code = code;
this.buffImg = buffImg;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public BufferedImage getBuffImg() {
return buffImg;
}
public void setBuffImg(BufferedImage buffImg) {
this.buffImg = buffImg;
}
}
3.3 Elasticsearch实现
```java
/
* ES的切入点
*/
@Pointcut("@annotation(com.ibeetl.bbs.es.annotation.EsIndexType) || @annotation(com.ibeetl.bbs.es.annotation.EsIndexs)")
private void anyMethod() {}
@Around("anyMethod()")
public Object simpleAop(ProceedingJoinPoint pjp) throws Throwable {
try {
Signature sig = pjp.getSignature();
Object target = pjp.getTarget();//代理类
Method method = ((MethodSignature) sig).getMethod();//代理方法
EsIndexType[] types = method.getAnnotationsByType(EsIndexType.class);
Map
/*
* 获取方法的参数
*
* @param pjp
* @return
* @throws Exception
/
private Map
4.项目展示
登录
主页
个人中心
帖子详情
发表帖子
板块分类
Elasticsearch全局搜索
参考文献
- 基于SaaS的BBS系统的设计与实现(厦门大学·袁赟)
- 基于Spring Boot的多用户博客系统的设计研究(青海师范大学·罗涛)
- 基于SSH框架的企业内博客系统的设计与实现(山东大学·柳青)
- 一个通用论坛系统的设计与实现(山东大学·张正)
- 基于SSH框架的企业内博客系统的设计与实现(山东大学·柳青)
- 基于J2EE的企业论坛系统的设计与实现(电子科技大学·万廉)
- 学术会议线上交流平台设计与实现(大连理工大学·史尉欣)
- 公司管理中BBS信息系统的设计与实现(电子科技大学·赵正刚)
- 基于SpringBoot框架社交网络平台的设计与实现(湖南大学·刘敏)
- 基于SSH架构的个人空间交友网站的设计与实现(北京邮电大学·隋昕航)
- 基于SSH框架的博客用户分享平台的设计与实现(河北工业大学·刘磊)
- 基于SSH框架的企业内博客系统的设计与实现(山东大学·柳青)
- 基于SSH框架的企业内博客系统的设计与实现(山东大学·柳青)
- 基于Spring Boot的多用户博客系统的设计研究(青海师范大学·罗涛)
- 基于Web应用的Spring框架的分析与研究(西安建筑科技大学·吴桂兰)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码助手 ,原文地址:https://m.bishedaima.com/yuanma/35493.html