基于Vue+SpringCloud博客的设计与实现
一、摘 要
博客是用来分享自己的心情和动态拉近人与人之间的距离,它改变了人们的在网上的交流方式,也增强了互联网的趣味性。 “微服务”是最近两年开始流行起来,但是其实早在20年前都有专家提出过,只不过当时的用户量并不像现在那么高。例如:一个系统的功能越丰富就会导致技术债务越多,但是基于单体应用(一个war包)开发的代码库越来越臃肿,可维护性差,代码“不坏不修”。为此,引入“微服务”架构的方式可以改善这个状况,每个微服务中心均在独立的进程中负责每种功能的业务,由一系列独立运行的微服务中心共同构建整个系统。现在web的前后端分离是企业的一种趋势,前后端分离同样也是技术创新的一种体现。得益于开发分离的趋势,Vue与SpringCloud的组合方式在如今的Web网站开发中占据重要的位置。
关键字: 微服务,Vue,SpringCloud.
二、绪论
2.1 研究的背景
近些年,微服务开始在软件系统设计中开始流行,它是一种与往系统架构设计不同的风格,它完整地拆分了单体应用的功能,并分配到指定的模块中,这种模块化方式已经成为企业主流的设计方式。
Vue这几年在前端大放异彩,因为Vue是一个国产的可组件化JavaScrtipt库,所以Vue的上手程度相比其它JavaScript框架更容易些。Vue 的组件库使用了最新的MVVM设计模式,因此Vue只关注前端视图的变化,把控制层分离来模块化前端的设计,完全符合主流的软件设计方式。
SpringCloud是微服务其中一个代言词,能与SpringCloud抗衡也只有Dubbo,但是如今的SpringCloud更新速度是相当地快,它已经在微服务开发中的占据了显著地位。SpringCloud是基于SpringBoot快速构建的一个工具集,并且它们俩都是Spring家族的子集,因此,它们也都是基于Java语言实现的,而Java是一种跨平台、适合于分布式计算机环境的面向对象编程语言。
如上所述Vue与SpringCloud都顺应了主流的趋势,所以这个组合在JavaWeb开发中变成了“香饽饽”,同样它们也推动了软件开发技术的进步。
2.2 研究的目的
在校大学生想要快速融入到企业当中都必须花一定的时间自学,或者不满足于个人所学,参加一些比赛或者自己动手写几个项目。大学生就业困难也是一个愈来愈显著的问题,在校学习的东西不够,不愿意花时间学习等。
因此设计本次博客的目的在于强化对Java和JavaScript的理解,增强个人的JavaWeb能力,提高对于系统架构的理解,写一个完整的Web对自己的提升是巨大的,除了提高个人技术外还会增强个人的毅力,对以后的工作都是有积极意义的。
三、博客的相关理论与技术
3.1 博客系统理论分析
本次设计使用的是JavaWeb开发中主流的微服务架构方式,微服务一定会涉及分布式,一般提到微服务大多在系统逻辑与物理结构设计上,而分布式则涉及到的都是一些机器或者实现技术,阅读本章可以理解整个博客用到的理论及其技术。
3.1.1 博客的微服务分析
目前来说,微服务(SpringCloud)是软件开发中的一个主流的热门技术,而SpringCloud只是微服务的一个重要子集。微服务的概念可以这样被定义:微服务之间通过HTTP等一些轻量通信进行交互数据,而每一个微服务都存在自己的进程中,独立承担着某些业务功能,最终所有微服务聚合共同架起整个系统。
设计一个微服务系统需要遵守以下原则:
微服务的单一原则:一般指的是一个类中只负责一个完整的功能,与其相关性不大的功能最好不要放进去,对以后的功能扩展不太友好。
微服务的隔离原则:指每一个微服务中心的功能代码块独立地运行在一个模块包中,多个微服务则有多个模块包,它们一起独立运行,并且不会发生互相干扰,从微服务的逻辑设计到开发设计都是独立在一个包中。
微服务的通信原则:当多个微服务发生数据交互时,它们之间应该使用轻量的通信服务来进行交互,轻量通信需要具备跨语言,跨平台的特点。
微服务的控制原则:每一个微服务都需要把控服务的代码量,在设计逻辑结构时要考虑周当,并不是一味地把代码量减少,使微服务变小容易控制。因为每个微服务的功能特性不同,所要要编写的代码量也不同。因此在逻辑结构设计时,就需要应该确定业务的边界,保持相对独立且松耦的关系。
微服务修复原则:微服务最好编写完整且稳定的高可用组件,除了微服务组件的高可用,还需要考虑“熔断”微服务的业务来保护系统。
3.1.2 博客的分布式分析
博客系统除了会涉及到微服务,还会涉及到分布式,分布式系统的定义大多从程序来看的,可以是相同的程序,例如“集群”方式。也可以不是相同的程序,通过远程调用来完成交互,分布式可以认为是一种对机器的有效管理方式。
关于分布式需要了解五个重要的特性:
-
内聚和透明性:分布式系统是利用计算机网络构建的协作系统,所以分布式系统通常都具备内聚性与透明性的特性。
-
独立扩展性:其一是垂直扩展即优化服务器的性能或者升级服务器硬件;其二,增加服务器水平扩展,即增加服务器的数量。
-
可靠性与可用性:可靠性是在指定的时间内,系统无错误和障碍的平均运行时间,可用性则是某个时间段内无错误和障碍的总运行时间。
-
高性能:对于高并发的平均处理时间越少越好,单位时间内处理的人物越多越好,利用更多的机器来实现更高的计算与存储能力。
-
致性:多节点部署下,保证计算与存储的数据只有一份。
由于分布式与微服务涉及到的面会有一些相似,但是两者的核心本质是不一样的,在此需要详细说明一下微服务与分布式两者的具体区别:
微服务是架构设计方式,例如:博客的逻辑设计需要涉及到某些功能,功能要怎么划分,需要考虑到“高并发”的问题,最终系统该如何拆分,功能如何划分比较合理,再为以后的系统扩展打下基础,而分布式是系统部署方式,系统拆分后,把功能放到某个机器上,若是采用了微服务的架构方式,利用的是分布式部署。若不是微服务架构方式则可以采用“集群部署”或者分布式部署,“集群部署”相当于同一个业务,部署在多个服务器上。
不管微服务还是分布式都有两个共同的缺点,第一个就是网络的的问题,例如:网路延迟,丢包和信息丢失,所以需要编写补偿机制来保护用户的体验。第二个就是节点故障,微服务节点故障或者分布式系统的某个节点故障,节点故障不一定可以完全避免,但是可以人为的操作干预,相比第一个缺点产生的网络通信还是有可操作性,但是动手起来有不小的挑战难度,需要仔细打磨每一个细节。
3.1.3 关于分布式锁分析
关于分布式锁的详解可以自行查找了解,在此只介绍分布式锁的概念和博客采用的分布式锁。简而言之,对Java分布式锁来说,对于不同的机器产生的不同JVM虚拟机之间需要资源共享,这个时候就需要用到分布式锁来进行控制。
如果程序中使用了Synchronized关键字,Lock并发接口,并发工具类或并发集合,这些操作也可以完成多线程的“共享资源”,但这只是单体应用的服务实例,对于分布式系统来说,独立的JDK和主机Host,两者区别就是在于单体并发控制到分布式跨JVM之间的差别,分布式锁也是基于跨JVM来进行“共享资源”的控制。
对于分布式锁有五点要求:
-
排他性:一个资源只允许在一个时间段被一个JVM上的一个线程执行。
-
避免死锁:需要人为释放锁,可以设置锁的失效时间。
-
公平锁:不同机器争夺资源时的几率是一样的,但不是必要的。
-
高可用锁:获取与释放锁的机制需要保证性能符合设计。
-
可重入锁:设置锁的可重入次数或者时间,若是发生获取失败,则可以等待一个时间段或者设置一个时间段获取锁的次数。
博客使用了基于Redis实现的分布式锁(关于Redis的分析可看标题2-7,在此只提一下Redis的分布式锁的要点),Redis提供了原子操作SETNX与EXPIRE,SETNX表示当key在Redis中不存在时才能设置成功,key间接当作“锁”,并用EXPIRE来释放获取的锁,Redisson可以看作内置了这些特性,封装好给我们使用。
由上可知,重要的操作就是SETNX,关于SETNX的操作有三个要点:
- 使用SETNX操作获取锁,如果返回0则说明已经存在且被其它线程获取,出现了1则说明获取成功。
- 需要为锁设置合理的失效时间,若是发生了程序异常,锁不释放就会导致死锁,时间需要合理且符合程序的流程。
- 与多线程操作的理念相似,执行完锁后需要释放获取到的锁。
3.1.4 博客的高可用分析
高可用是微服务架构中一个重要的设计元素,一般指的是系统减少微服务不能提供的时间。博客的高可用的需要做到服务自治,当一个微服务出现无法响应,而另一个微服务就可以替代它,所以在设计博客高可用系统时,需要从许多方面去考虑,远不止一个高可用,最重要的就是自我修复避免系统的无法响应。
博客中一共涉及到Eureka,Zuul的高可用,后续标题中会提到,在此不做介绍,高可用的分布式系统需要遵守微服务的开发准则,也需要遵守以下微服务运行机制(括号中是博客使用到的技术,会在后续的标题中一一详细介绍,在此作为理解):
-
扩展机制:水平与垂直扩展,与分布式的扩展相似
-
隔离机制:避免博客的一个业务占用太多资源导致服务的无法响应,会对其他博客业务造成影响,添加容错机制即可。
-
解耦原则:尽可能地使用合成复用原则来代替继承关系。
-
限流机制(Zuul):限流可以在路由网关上面体现出来,根据不同的算法可以实现不同的负载均衡。
-
降级机制:在核心业务运行时,牺牲一部分非核心的业务保证核心业务功能
-
稳定运行,当系统不可用时,需要给予用户一些提示。
-
熔断机制(Hystrix):在调用微服务请求时,添加回退保护即可。
-
跟踪机制(Zipkin):博客API会产生数据指标,产生的数据需要用来观测,然后再做数据分析,对系统做个深度分析以便以后的功能扩充。
-
维护机制:博客的系统维护比较需要方便,压力与微服务的数量成正比。
-
补偿机制:如果发生网络问题导致博客业务数据不一致性的问题,需要补偿机制弥补用户。例如:RabbitMQ异步消息,补偿表和定时任务检测。
-
监控机制(Hystrix+Turbine):更多的是通过Hystrix监控各个微服务的运行指标,通过HTTP转递给开发者观看。
演练机制:算是一种未雨绸缪,在测试博客功能时,适当关闭个微服务中心,把博客的异常或者补偿都要测试一下,防止在真实情况下出现业务炸裂情况,尽可能的在某个机器或某个微服务挂掉时,尽量不影响博客系统整体的高可用性。
3.2 前端的搭建
3.2.1 Node-Npm简介
Node.js是服务端的Javascript解释器,是一种服务端语言,可以被看作是一个基于JavaScript运行环境的平台。
Npm则是属于node.js里面的一个网络下载包的管理工具,博客前端需要用到的一些UI组件均存在npm中。前端Npm与后端“maven”相似,都可以下载需要用到的组件包。
对于Vue的安装可以采用原始的Npm安装也可以采用IDE直接创建Vue的脚手架,因为时间飞速的发展,前端也发展迅速,当项目过大时前端也必须分工协作所以模块化与组件化也是非常重要的部分,因此前端的自动化部署也应运而生。
前端的工程化与webpack离不开,在npm中即可下载webpack,webpack的模块化的运行原理如图2-1所示:
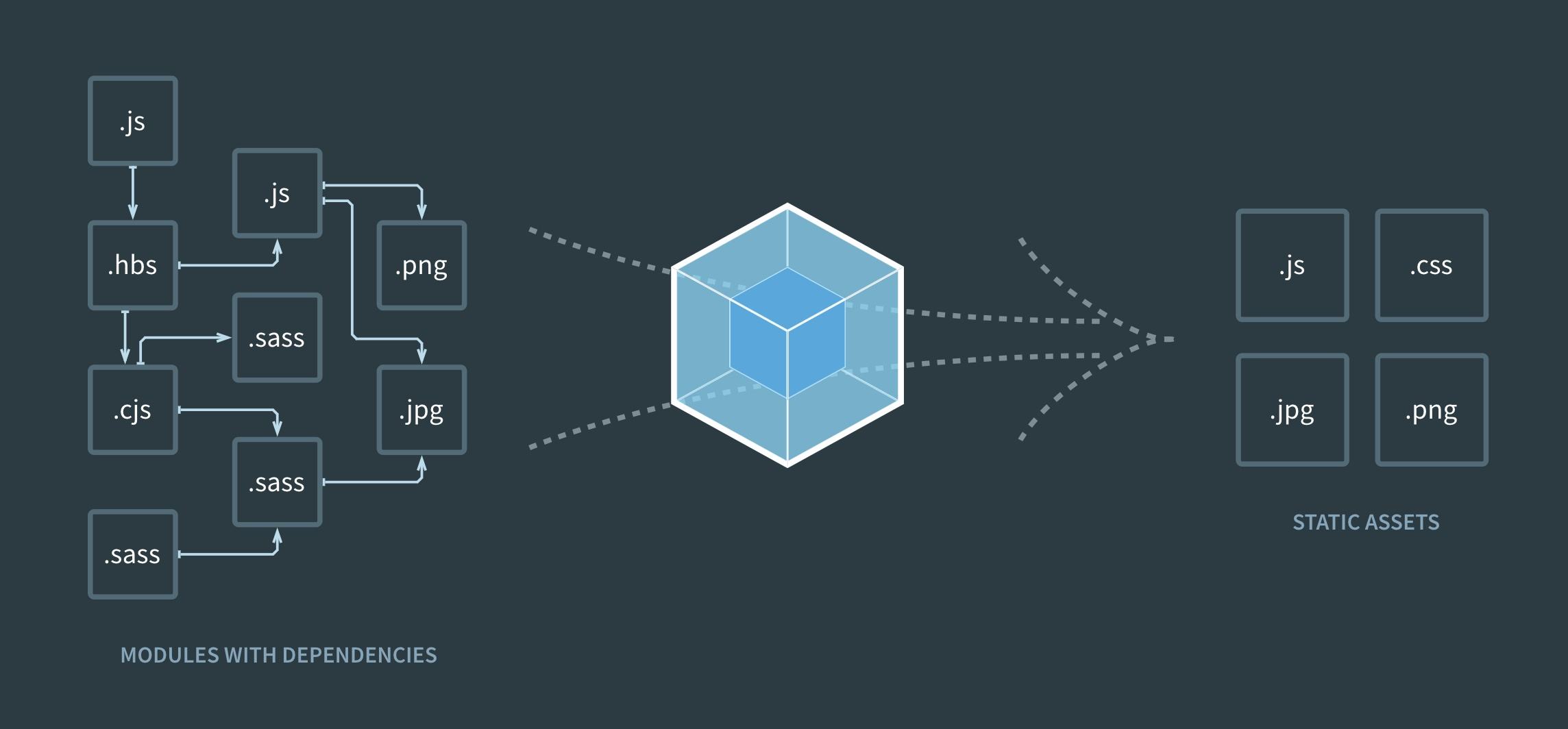
图2-1 webpack模块化示意图
Webpack是将所有的文件都最后统一生成静态资源文件,每一相同类地资源文件相当于都是一个moudle。Webpack模块化了前端,增强了前端的协作性。
3.2.2 采用的UI框架
UI(界面设计)框架是博客的美观的体现,可以由开发者自行根据HTML,CSS,JavaScript开发美观组件,也可以节省时间使用他人封装好的UI框架,UI框架需要做到拿来即用,使用者可以做一些代码实际性的修改来结合业务的实现。
关于本次博客的开发一共采用了三种UI库:
Bootstrap:Bootstarp是过去几年中web开发中受欢迎的前端组件库,不过现在的Bootstarp组件库却不是很常用, 由于Bootstarp在布局上面占据显著的优势,所以Bootstarp非常适合博客的开发,
Element-UI: Element-UI是一个利用原生JavaScript编写的UI组件库,当前是与vue配合开发的一个比较好的UI框架。
View-UI:View- UI是一套基于 Vue 的 UI 组件库,博客的开发采用了Vue框架,所以使用这个UI框架上手十分简单,对每一个开发者学习时会非常的友好,除此之外View-UI的组件漂亮又整洁,非常适合博客的开发。
这三个UI库在设计中都有体现,Bootstarp的组件趋于整洁,View-UI与element-UI的常用组件趋于漂亮实用化,并且View-UI本次博客采用的组件与Element-UI相差不大,但是npm上View-UI的下载量趋于快速上升的趋势,并且view-UI 的api 更加简洁,View-UI现在保持一种热门的趋势。
View UI具备以下友好的特性:
Ⅰ. 丰富的组件和功能,满足绝大部分网站场景,也可以自己自定义组件开发
Ⅱ. 提供开箱即用的 Admin 系统 和 高阶组件库,需要付费才可以使用
Ⅲ. Vue.js生态环境友好,有问题可以解答,对于学习者方便快捷。
Ⅳ. 友好的 API ,自由灵活地使用空间。
Ⅴ. 细致、漂亮的 UI可节省开发者的时间,也可以重构组件。
Ⅵ. 事无巨细的文档,官网的文档非常适合初学者学习。
Ⅶ. 可自定义主题,直接导入使用。
3.2.3 -charts图表
博客的开发少不了图表,图表可以增强用户的体验,例如开发中的常用功能会有消费记录,访问记录等。每一个网页界面中可以创建多个echarts图表实例,但是每一个 echarts 实例都会独立占有一个对象节点,除此之外还需要做一些繁琐的数据的类型转换,修改图表的基础配置,这对于开发者比较棘手,所以v-charts 的出现正是为了解决这个痛点。v-charts是居于 vue 与 echarts 封装好的图表组件,只需要更改图表的参数就可以完成图表的显示与遍历,非常适合vue的整合开发。
可以自行配置局部的图表组件,也可以按照以下全局导入的方式:
python
//npm下载v-charts图表组件
npm i v-charts echarts -S
// main.js的全局导入
import Vue from 'vue'
import VCharts from 'v-charts'
import App from './App.vue'
//全局使用图表组件
Vue.use(VCharts)
new Vue({
el: '#app',
render: h => h(App)
})
3.3 Vue架构
3.3.1 关于MVVM模式
MVVM(Model-View-ViewModel)模式是基于原来 Model–View–Controller(MVC)模式改进而来的,MVVM 的核心是 ViewModel (V)层,这个V作用就是替代了controller层。原先的MVC模式是View与Controller直接交互,而这个V直接负责与 Model 层交互,这就完全分离了 View 层和 Model 层,可以把V是看作是一个数据中转站,它是实现前后端分离的最重要一环,同样MVVM模式也是Vue的数据绑定系统的设计核心,MVVM模式的用例图如图2-2所示:
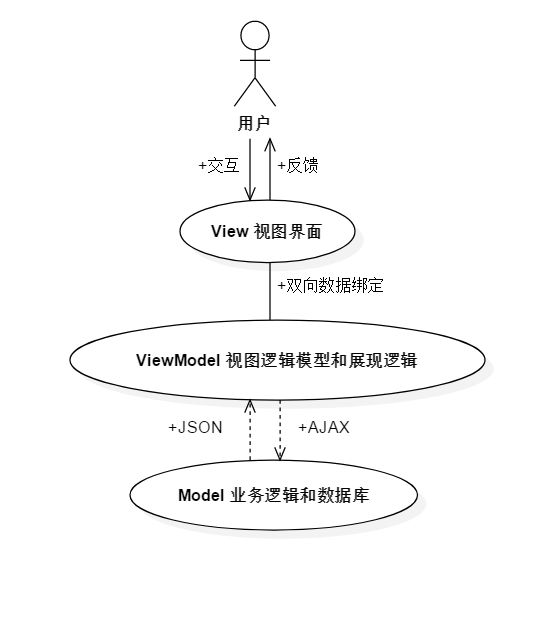
图2-2 MVVM模式
3.3.2 关于Vue的生命周期
每一个运行框架都会有比较完整的生命周期,设计出一个稳定的生命周期可以保障框架有序地运行。Vue的生命周期含有运行生命周期函数,数据data,模板template,挂载el、方法函数methods,。Vue的生命周期也可以认为是Vue的运行的流程图,这个说法虽然不够严谨,但是可以加强对Vue框架的理解与控制。
图2-3是Vue 2.0的生命周期的活动图:
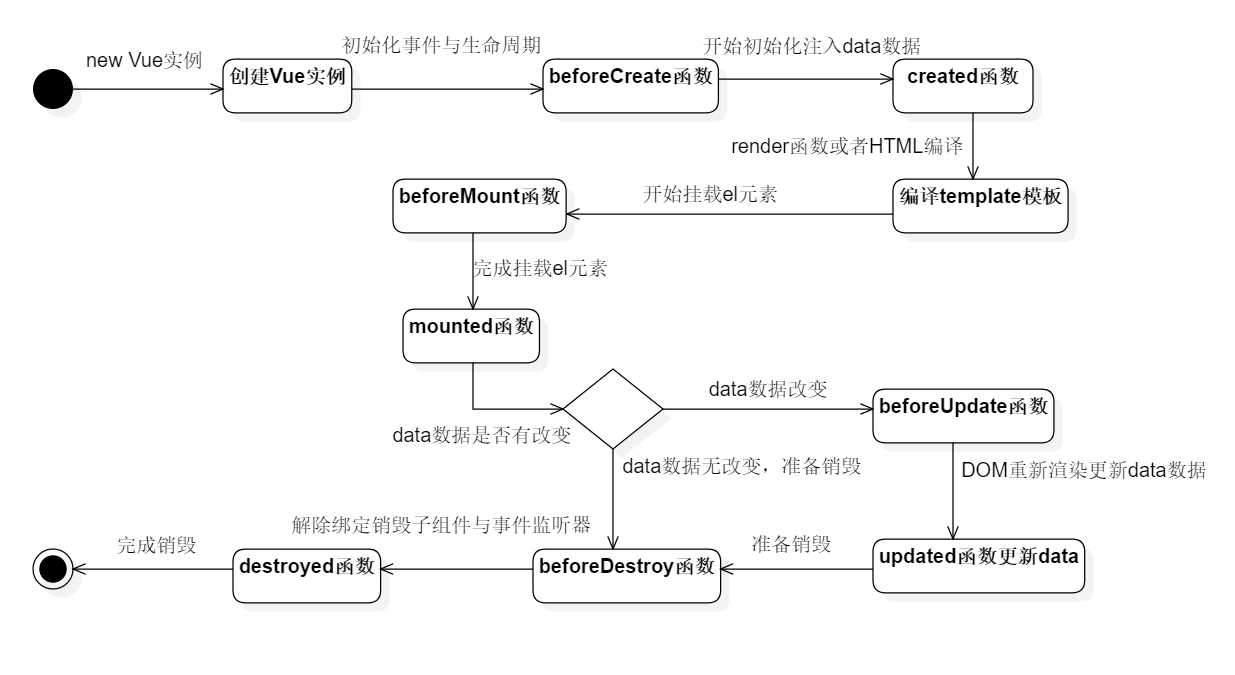
图2-3 Vue的生命周期
对于上图需要解释一下常用的三个函数:
-
created函数:完成创建vue实例后调用created函数来完成data数据的初始化任务,不过$el不可用,因为el尚未挂载。create函数适合初始化数据。
-
mouthed函数:el挂载到实例上,还可以完成data数据的更新。mounted函数如果完成业务逻辑改变,可以改变data再挂载el。
-
beforeDestroy函数:解除事件的监听,例如addEventListener监听。
3.3.3 Ajax运行原理分析
异步的JavaScript和Xml(Ajax)是一种利用异步方式来快速创建动态的网页技术,它不是一种常见的编程或者脚本语言。使用Ajax的好处就在于可以不用重新刷新整个网页,就可以对网页进行异步更新,而一般的传统网页(不采用 Ajax)若是要更新网页中的内容,需要重新刷新整个页面,可以认为是同步刷新。Ajax 的核心对象就是XMLHttpRequest(XHR),属于原生JavaScript的范畴。
关于Ajax的运行原理可以分为以下几个部分,图解如图2-4所示:
-
首先创建一个异步XHR调用对象来进行交互。
-
其次XHR定义HTTP请求与配置信息,使用XHR.open()函数。
-
然后发送HTTP请求,使用XHR.send()函数。
-
之后通过XHR的onreadystatechange事件获取异步调用返回的数据。
-
最后利用JavaScript和DOM实现网页的局部刷新。
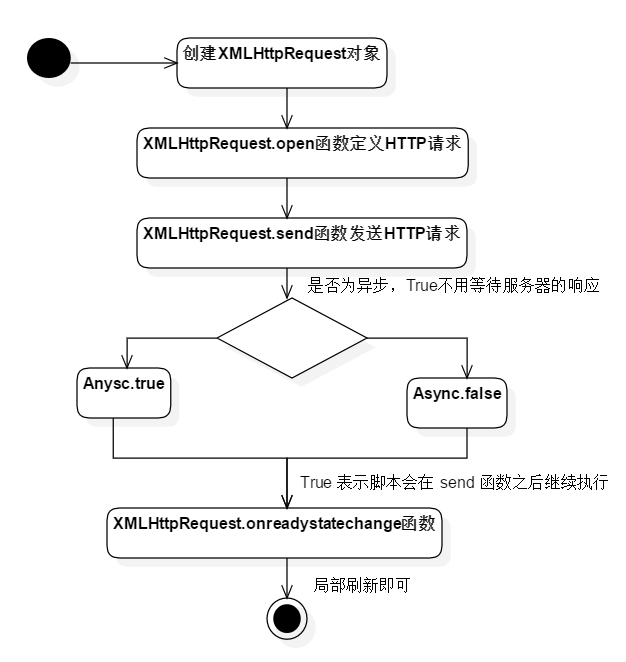
图2-4 Ajax运行原理
3.3.4 使用Axios的原因
前些年比较火的是JQuery,JQuery包中 ajax 也是对原生XHR对象封装,在前端慢速的时代有着卓越的影响,但现在却有几个明显的缺点:
-
JQuery是基于MVC规范,不符合现在前端的MVVM规范。
-
JQuery是基于最初的XHR进行整合,不符合前端的ES语法规范。
-
JQuery完整包过于庞大,要用一个组件却要导入整个包,不合理。
-
不符合关注分离的原则,封装过于密封,维护压力比较大。
-
JQuery的配置与其调用时的方式非常混乱,基于事件的异步不友好。
Axios其实也是对最初XHR的封装,因为它是基于Promise API实现,比较符合现在前端的ES规范,例如常用的POST,GET请求,Axios也可以自定义配置这些请求函数,自定义的方便在于可以请求体Headers附带Token或者指定的数据,也可以定制数据的转换方式,比较合理化,符合编程的艺术思维。
前端自定义Axios的POST函数的详解如以下所示:
c++
post(url, data) {
return axios({
method: 'post', //请求的方式
url: url, //请求的地址
baseURL: host, //host
data: Qs.stringify(data), //字符串转换data
timeout: 30000, //请求响应时间
headers: {
'X-Requested-With': 'XMLHttpRequest', //请求的对象与类型
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'TOKEN': window.localStorage.getItem('token'), //携带元数据Token
}
})
}
3.4 SpringCloud架构
3.4.1 SpringCloud框架
SpringCloud 是基于SpringBoot基础上构建的,用于快速构建系统的工具框架集合,SpringBoot有自动装配Spring MVC和内置Tomcat的优势。SpringBoot有四个特性。例如:编码相对简单,简化了配置,部署更加便捷,监控更加方便。总的来说,就是“习惯大于配置”。目前应用项目的搭建规范是基于Maven构建多模块的方式,这种方式搭建的各个模块各司其职,负责不同的功能,同时每个模块采用层级依赖的方式最终构成一个聚合型的Maven项目。
把SpringCloud比喻成一栋楼的话,SpringBoot就相当于地基,随着版本的发展,两者的版本会发生兼容冲突,消除兼容不一致需要按照图2-5所示来适配:
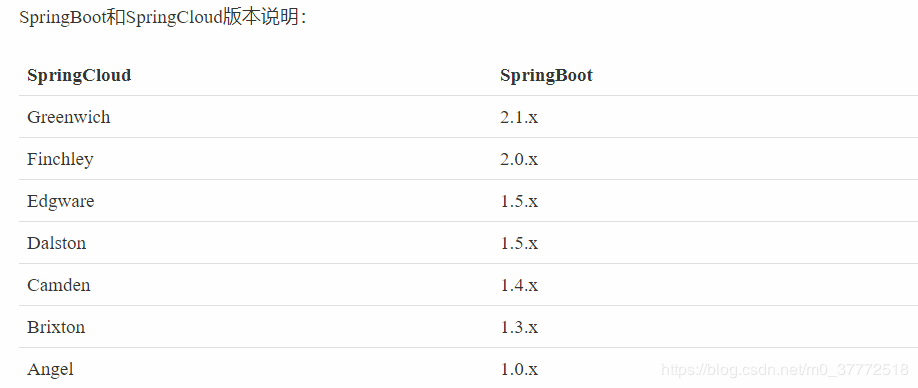
图2-5 兼容图
SpringCloud的版本名只是官方定义的地铁站名字,从首字母A开始更新利用人们方便记忆,版本在一般情况下是向下兼容,向上不兼容,所以版本需要装配一致,否则项目无法运行。由于微服务的体系并不完全成熟,所以向下兼容也会出问题,包会有BUG和缺少部分类,新学者都直接使用最新的稳定包即可。
3.4.2 Zuul路由网关
微服务的网关Zuul是客户端与服务端的通信中转站,用户的API请求会经网关到指定的微服务,Zuul同样也是一种“过滤器”。用户的流量成千上万的点击,所以需要高可用的Zuul来保证不会发生单点故障。博客采用的是Zuul注册到服务中心上的一种方式,未采用外部Nginx负载均衡,所以Zuul的高可用如图2-6所示:
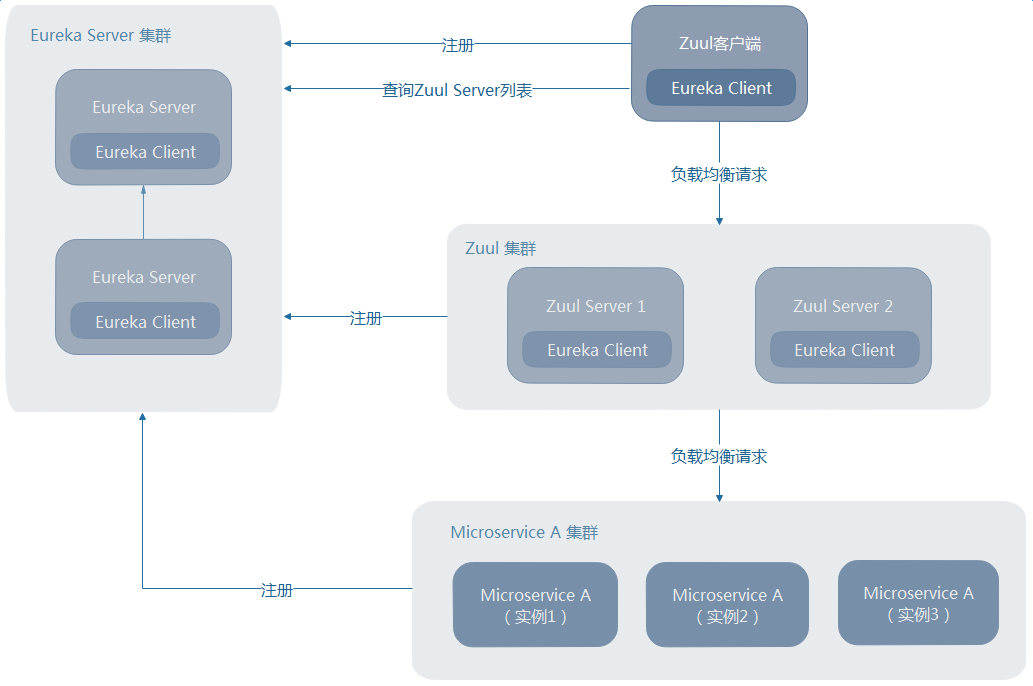
图2-6 Zuul高可用架构图
Zuul路由网关的核心配置是过滤器,它起到的作用是“拦截”信息,关于Zuul路由网关官方一共定义了四种不同过滤器类型,允许自定义过滤器:
-
pre类型:before拦截,请求前被调用,可以用来做Token的验证。
-
routing类型:拦截过后会把API请求转发分配到指定的微服务中心。
-
post类型:响应API请求,收集API指标,把响应结果发送给用户。
-
error类型:任执行发生错误时,会使用该过滤器执行报错。
3.4.3 Eureka服务发现组件
一般在微服务系统中,服务发现组件是微服务系统的核心组件,就拿服务发现组件的运行机制来说,它运行时需要包含了三个对象,提供者,消费者,微服务注册中心。消费者来消费时,会从微服务注册中心查询提供者的“密码”,“密码”正确时,提供者就可以根据实际情况来返还给消费者的响应结果。以上三个对象都是微服务,而微服务注册中心就相当于提供者与消费者的中转“报名”站。
Euraka是Netflix的微服务发现组件,是一个基于REST的服务的轻量级组件,Eureka组件通过Server和Client完成服务的注册与发现。因为Eureka官方2018年7月宣布不再维护Eureka 2.X版本,所以可以考虑Consul,Zookeeper等开源的服务发现组件替代Eureka。
Eureka的架构图如图2-7所示:
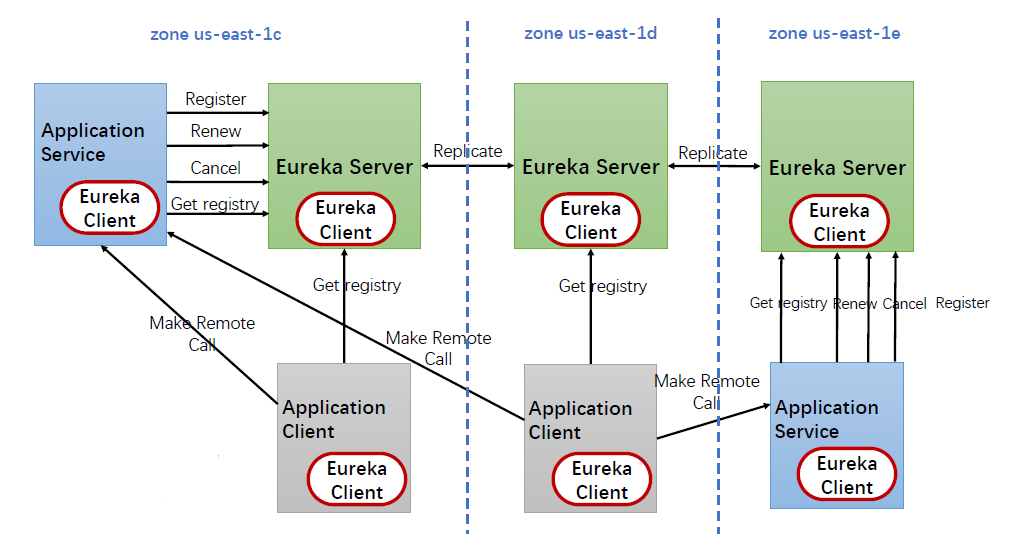
图2-7 Eureka架构图
EurekaServer:Eureka Server会注册微服务的机器信息。
EurekaClient:使用@EnableDiscoveryClient注解完成注册。
server之间会用按照默认的30s保持通信,维持之间的联系。
3.4.4 Feign负载均衡
负载均衡是保证流量请求分发到各个微服务的实例上面,在SpringCloud的Hystirx(Hystrix在标题2-4-5中会提到)组件中,Hystrix一共整合了Ribbon和Feign两种负载均衡器。Ribbon是基于url直接实现客户端的负载均衡,而Feign是基于接口形式来实现服务端的负载均衡。
Feign的实现过程就是两个微服务之间进行接口实现的传导,可以携带一些请求数据等,可以通过Feign的源码来理解Feign的实现。
Feign的源码实现的过程如下:
-
首先Spring通过@EnableFeignCleint(“包”)注解扫描feign包的位置
-
微服务添加@FeignCleint注解,设置微服务的虚拟主机名。
-
Spring扫描@ FeignCleint的类,并将Feign对象注入到SpringIoc中。
-
通过JDK的动态代理,来生成具体的RequesTemplate,再生成Resquest。
-
最后交给Client去处理,Client可以是HttpUrlConnection等。
-
最后把Client封装到LoadBalanceClient类中,这个类封装了Ribbon的负载均衡,虽然图2-8中并未提到,但是这个类是Ribbon的一个重要实现类。
Feign的反射运行原理序列图如图2-8所示:

图2-8 Feign的运行原理
图2-8描述了Feign的源码流程,因为Java是一个以反射为核心的语言,所以需要学习Java的反射机制才能理解图2-8与源码流程,在此不再累述。
3.4.5 Hystrix容错机制
Hystrix是整个系统的核心,每个微服务都很有可能发生网络延迟或者响应失败等意外情况。如果不增加回退机制,请求API就会长时间占用微服务,导致微服务系统资源被一直占用导致无法响应。因为微服务之间通过网络通信,若是微服务之间关联性较强并且不添加容错机制就会导致级联效应,个个微服务都可能产生不可用的状态,从而使整个系统资源全被占用,最终系统会发生“雪崩效应”。
“雪崩效应”是一种微服务的业务故障导致的系统的“级联故障”,可以使用Hystrix来解决这个问题。Hystrix是一个实现了超时机制和断路器模式的工具类库,Hystrix给负载均衡都提供了容错机制,由于Feign是以接口的形式实现则只要实现Feign接口的回退就可以保证容错机制。
Hystrix具备以下6个重要的特性:
-
包裹请求:可以使用HystrixCommand在每个线程中执行命令。
-
阀门机制:若是出现微服务错误的情况,到达一定的范围,会自动“跳闸”。
-
隔离机制:每个API请求后都会进入一个默认的线程池,也可以使用信号量,好处在于不会发生大量的排队等候,加速业务回退的判定。
-
监控指标:Hystrix具备的监控微服务的指标与API的请求指标的功能。
-
容错机制:若是发生成功、失败、执行回退或者断路器打开时,有返回值,再由开发者自行判断错误类型。
自我治理:Hystrix中的“断路器”打开后的某个一段时间内,它会自动进入“半开”状态保护微服务,当放行一个微服务的请求API时,若是成功调用则关闭断路器,否则继续保持打开状态。若是发生了回退,并不能说明断路器已经打开,只有失败的比率达到上限才能触发断路器的开启。
对于断路器可以理解成电路上的电闸,当发生电流短路,防止火宅需要安装电路上的保护器,失败率则可以认为是当电流超过某一个阈值后会自动打开阀门保护电路。对于“雪崩效应”,当一段时间内,若是发生依赖的服务不可用,并且失败率达到某个阈值后,断路器就会打开,也可以认为是打开断路器时快速失败,从而防止雪崩效应。只有依赖的微服务恢复正常时,会回到“半开”模式,从而恢复请求。
3.4.6 Turbine聚合微服务
由上个标题中Hystrix可以它有监控的作用,Hystrix具备监控单个微服务和API的响应情况,而Hystrix DashBoard则可以让数据可视图化。可以把每个组件都写成一个微服务中心,让它就做这一个功能,也可以写在符合需要的微服务中。
Hystrix Dashboard的初始页面如图2-9所示:
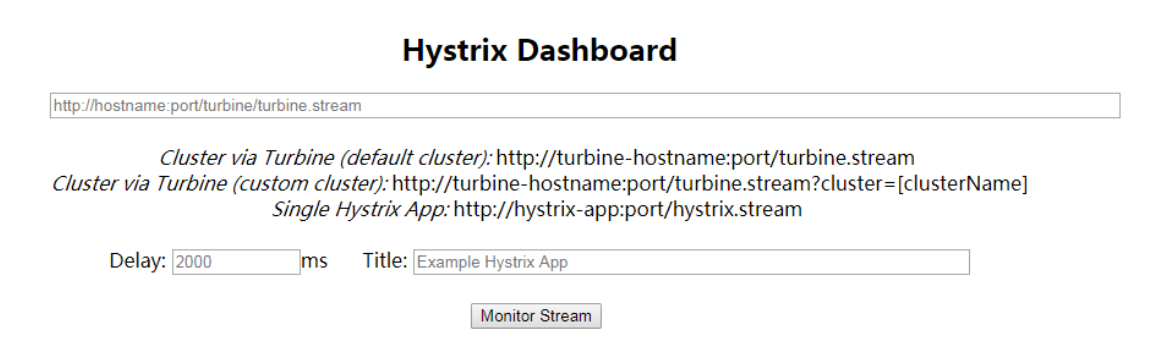
图2-9 Hystrix Dashboard
Http端口号为要想观察的微服务的虚拟主机名,Delay为延迟查看时间,以及标题名Title,每一个微服务产生的都是一个hystrix.stream数据文件。由于Hystrix只能监控一个微服务的实例,当微服务很多时可以使用Turbine来聚合多个微服务,最终Hystrix监控的所有微服务产生的数据文件会整合一起传到Turbine,然后再由Hysrix DashBoard图形化界面显示。
Turbine聚合监控数据的过程是把每个微服务所产生的数据聚合在一块传给Hystrix DashBoard图形界面显示。HTTP可以传递数据,但是微服务发生与Turbine网络不通时,则会无法接收到实时数据。由于HTTP传递不符合主流的流程聚合,所以在此不累述,下面只介绍主流的聚合方式。
当网络发生连接不畅的时,就需要借用一些消息中间件来保存产生的数据,关于中间件的详解会在标题2-8讲到,在这只需要了解消息中间件是用来辅助Turbine来聚合微服务即可,可以借助图2-10来加深对Hystrix+Turbine组合的理解:
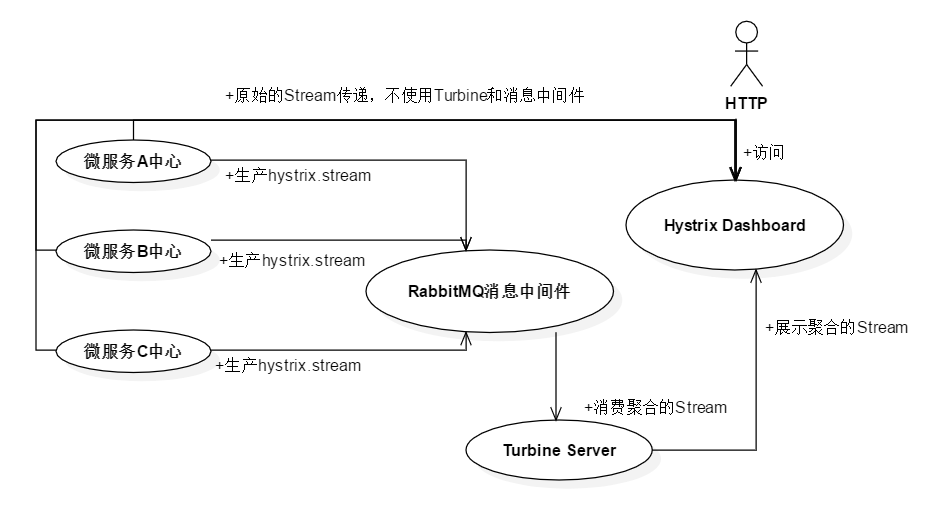
图2-10 Hystrix与Turbine的组合
3.4.7 Zipkin跟踪微服务
Zipkin是Twtter开源的分布式跟踪系统,基于Dapper的设计而来。主要的功能是收集博客系统微服务产生的时序数据,给开发人员观测问题所在的服务。例如:可以跟踪博客的请求API,可以看到用户的请求经过的微服务和运行的的时间,这样就能很好地分析出微服务的问题所在。
Zpkin的主页面如图2-11所示:
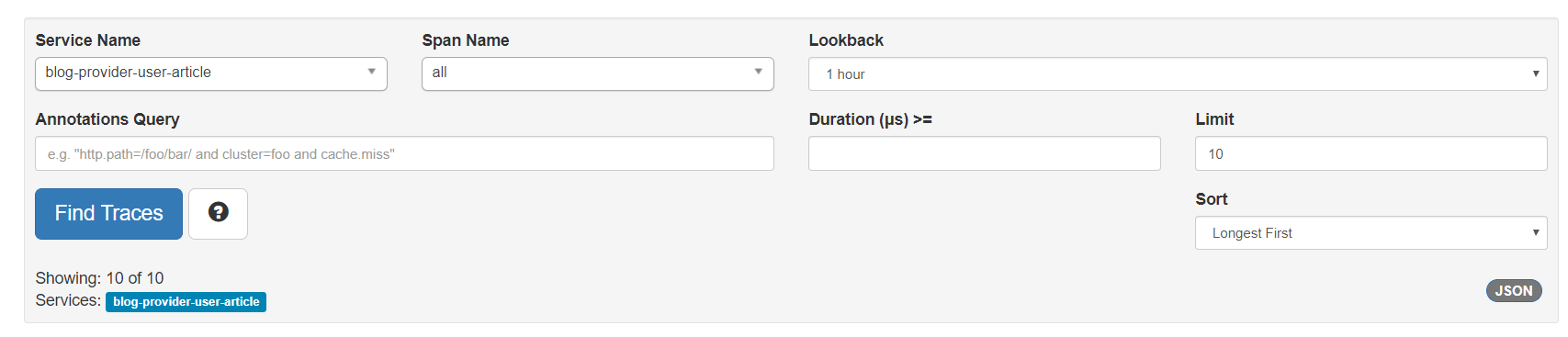
图2-11 Zipkin主页面
Service Name就是微服务的虚拟主机名,Span Name选择多少个API,Lockback可以选择时间段,Limit也可以自行定义时间段,最终数据都会打印在下面。
例如:跟踪微服务的一个API指标如图2-12所示:
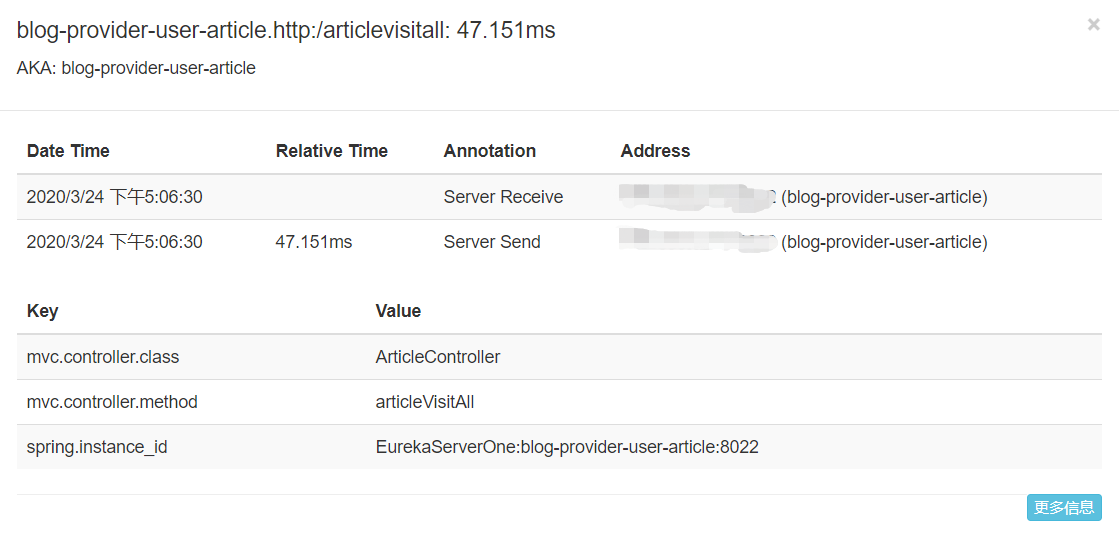
图2-12 Zipkin跟踪微服务
有开始的时间,也有运行的时间可供观看,Address包含IP端口和虚拟主机名,马赛克的位置就是机器的IP地址。Key-Value对应Java的文件位置和名称,可以快速定位到错误的地方以便开发者调试,Zipkin的跟踪会从开始到结束经过的所有API都会有各个指标可以观看。
3.5 Mysql数据库
数据库是根据数据的存储结构来存储、管理和操纵数据的存储库,每种数据库都有多个封装好的不同调用方式,可以直接用于增删改查存储库中的数据。
Mysql是一种关系型SQL数据库,Mysql数据库开源,使范围,跨平台持性好,还提供了多种语的调API,所谓关系型数据库就是在存储库中建立了一个关系模型,然后再利用数学等集合关系来操纵存储库中的数据。
Mysql作为一种常规的后端存储库,其性能虽然比Oracle弱,也被Oracle收购,但是Mysql是免费的,所以用来学习非常适合。
3.6 Mybatis框架
Mybatis的前身是IBatis。Ibatis是一个基于Java的持久层框架,2010年改名Mybatis,现由GitHub提供维护。Mybatis的优势在于定制SQL,由于Mybatis底层采用大量的反射,所以Mybatis会提供自动映射,动态SQL等。因此Mybtais的DAO层是不需要实现类的,只需要一个接口和XML配置类就可以启动。如今主流Mybatis编程是Mapper接口编程,所以本次博客采用的是国人开发的MyBatisCodeHelperPro插件,插件可以直接生成简单的SQL增删改查,节省简单SQL代码的时间。
Mybatis的核心组件一共分为四个部分:
-
SqlSessionFactoryBuilder:生成SqlSessionFactory,相当于一种构造器。
-
SqlSessionFactory:采用的是工厂模式生成SqlSession。
-
SqlSession:执行Sql与返回Sql结果。
-
SQL Mapper:Sql的Mapper映射器,采用主流的Mapper编程。
可以用一张图来解释Mybatis的4个核心组件的联系,如图2-13所示:
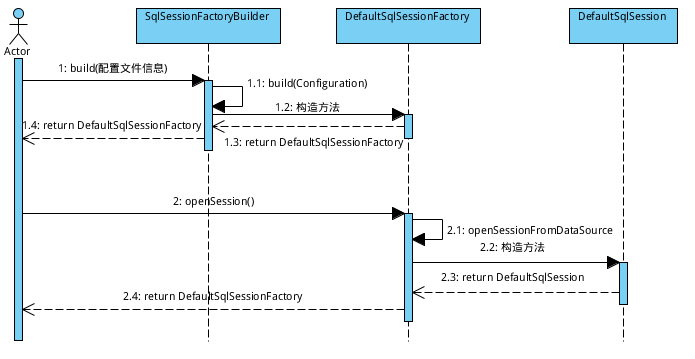
图2-13 Mybatis的核心组件
图2-13可以理解为传递“钥匙”,通过Java构造来实现SQL的执行流程。其底层是基于Java拦截器反射实现,若想学习可自行去了解。
3.6.1 Mybatis分页插件
在开发博客时,用到了许多分页操作,原生的分页类操作起来又比较麻烦,所以在使用MyBatis框架时,可以使用开源Mybatis的PageHelper分页插件。当然也可以采用原生的Mybatis分页插件,不过没有开源的Mybatis分页插件pageHelper好用。使用开源的插件比较危险,使用的时候需要仔细控制好每个环节。
SpringBoot整合pageHelper分页插件可以导入Maven以下配置:
c++
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.12</version>
</dependency>
pageHelper调用的方式有许多种,但是个人建议使用以下的代码方式调用:
c++
//Mapper接口方式的调用,推荐这种使用方式。
PageHelper.startPage(1, 10); //第几页多少数据
List<Country> list = countryMapper.selectIf(1); //数据库中的数据
PageInfo pageInfo=new PageInfo(list); //进行数据分页
关于pageHelper的yml配置信息如以下所示:
c++
//这只是pageHelper的配置,完整需要配置Mybatis,Mapper和Entity位置。
pagehelper:
helperDialect: mysql
reasonable: true
supportMethodsArguments: true
params: count=countSql
3.7 Redis缓存中间件
Redis是Nosql缓存数据库。Redis的优势有三点。第一,它是基于ANSI C语言编写的,接近机器语言,运行速度快。其次,Redis基于内存的读写,相比于数据库的磁盘读写要快的多。最后,相比SQL而言,本身的数据结构类型比较简单。但是Redis同样也有弊端,内存相比磁盘来说存储较小,所以需要考虑系统的数据所需的存储量和数据存在的时间。在早期互联网产品面对“高并发”响应时会发生“响应慢”等情况,原因是用户的读请求远大于写请求,造成数据库的整体压力上升,所以引入了Redis中间件来把用户的读请求放到缓存中。随着微服务、分布式架构时代的到来,Redis得到了一席施展之地。
Redis有5+1种基本数据结构:
-
字符串:key-value,类似Java中的Map结构,通过key取出值,常用的信息可以放在里面,可以降低数据库读写的压力。
-
链表:List实现的双链表,可以保存个人博客主键Id的List集合。
-
哈希:Map结构,对String的性能升级,可以大量存储有效信息。
-
无序集合:与Java中的Set接口相似,无序并且不能含有重复的数据。
-
有序集合:有序集合中的元素是可以排序的,它给每个元素设置一个分数,作为排序的依据。有序集合中的元素不可以重复,但是分数可以相同。
-
基数:基数并不是存储元素,而是用来判断一个含有重复元素的集合(一般是很大的集合评估需要的空间单元数。
Redis的存在就是降低数据库的读写压力,Redis缓存的使用在给应用带来整体性能和效率提升的同时,也带来一定的问题。Redis的key超时回收并不是自动的,只是被标识超时了。因为超时的数据可能会很大,需要收回需要占用较长的时间,所以Redis提供两种收回超时命令,第一种人为可以定制在某个时间段触发代码回收超时key,第二种是某个key在被get时,若是key超时则将会从内存中清空。
Redis发展愈来愈成熟,不过缓存使用不当也是产生一定的问题,Redis的key键的时间设置不当也会导致缓存的雪崩。对于key的时间设置不能太过随意,因为缓存是数据库的一道重要防线,当缓存奔溃,用户请求压力都会转到数据库上,大量的请求不一定会使数据库崩溃,但是会导致系统的性能出现下降,不符合分布式系统的设计。
3.7.1 Redisson综合中间件
Redisson是一款免费,开源的高性能分布式中间件,是给予Redis基础上实现Java对于内存数据管理的综合中间件。俗话说,青出于蓝而胜于蓝,Redisson充分利用了Redis的Key-Value的数据结构与内存数据库的一系列优势,并自己增强了多线程的并发能力,一定程度上降低了分布式系统架构的难度。除了之外Redisson还提供了分布式服务,分布式对象,分布式集合和一些分布式锁组件,相当于减少开发者的一部分代码量,优化了程序之间的协作能力。
Redis具备的特性Redisson几乎都具备了,关于Redisson的特性如以下所示:
-
多种连接方式:支持同步,异步,异步流,管道流的方式连接服务。
-
数据序列化:对象的序列化和反序列化。
-
集合数据分片:通过自身的分片算法,把切割的数据均匀地分配到集群的每个节点中,保证每个节点分配到的片段数量大体相同。
-
分布式对象:布隆过滤器,基于订阅发布式的话题功能等。
-
分布式集合:与原Redis所提供的数据结构类似,但是Redisson与Java中的集合比较相似,例如List,Set,Map等。
-
分布式锁: Redsson提供了可重入锁,一次性锁,读写锁等组件。
-
分布式服务:可以实现在不同一个机器节点Host的远程服务的调度。
Redisson需自行配置RedissonClient,其简单的Redisson的配置如以下所示:
c++
//这种方式配置只适合学习,Redisson也可以配置集群等方式。
Config config=new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
从配置Redisson中可以得到Redisson是以Redis搭建的服务为基础,相当于又一次封装的RedisClient实例来实现各种Redisson功能特性。Redisson的节点部署模式与Reids大致相同,可以自行按照需要配置节点模式。
3.8 RabbitMQ消息中间件
Java Message Service(JMS)是Java消息服务,相当于JDBC和JDBC驱动的关系,是一套标准。AMQP(Advanced Message Queuing Protocol)是一个线路层的协议规范,所以AMQP是跨平台的,只要按照AMQP规范发送数据,任何平台都可以进行接收交互。
RabbitMQ是一个基于AMQP协议的消息中间件,RabbitMQ是ErLang语言编写的,所以本次博客采用的是19.3Ealang+3.7.7RabbitMQ搭配方式,两个版本的搭配必须要符合版本的依赖性,不然会无法使用。
RabbitMQ遵守生产者-消费者的规范,其运行的的架构图如图2-14所示:

图2-14 RabbitMQ用例图
RabbitMQ的结构远不止如以上图所示,交换器包含路由键和绑定。每种交换器都有四种类型,4中不同的交换器可以放到不同的队列中,队列是RabbitMQ的存储对象,是用来存储用户的消息。RabbitMQ的用户消息都需要存在队列中,每一个生产者与消费者都会与RabbitMQ发生连接,一个连接产生一个信道,信道用于生产和消费用户的信息。
3.9 Elasticsearch搜索引擎
Elasticsearch(ES)是实时的分布式搜索分析引擎,内部使用Lucene做索引与搜索,Lucene是Java语言编写的全文搜索框架,并且也在与时俱进地更新自己的包。总结来说,ES是面向文档的,存储内容可以是一段话,一个网址,一个日志等。
ES的问世比较晚,属于后浪推前浪的一种产品,不过ES已经算是一种主流的存储库,虽然它封装了Lucence,但是它自己的分布式水平扩展的模型非常强大,这是它的一个非常重要的优势,通过JSON的HTTP方式可以直接管理ES的集群。
当然搜索远不止这些,ES可以像数据库一样运行,只是侧重点不同,ES也可以像数据库存储一些数据,但是并不能取代数据库,因为Elasticsearch不支持事务。ES可以存储一些安全性无关但是重要的数据,分担一些系统的压力,但是额外引进一个数据源会增加系统的复杂度,所以在系统设计阶段需要权衡数据的主要存储方式。
3.10 阿里云的增值服务
3.10.1 阿里云智能验证
登录的验证是分析出当前的有效请求,无效请求和恶意请求,一般登录可以使用常规的验证码或者其它免费的开源拼图,也可以使用阿里云付费的人机验证。
关于一般的验证是不可以用纯前端的方法实现,因为需要借助后端对恶意的请求直接拦截,纯前端验证会导致被他人篡改验证码或者恶意刷新网页给系统带来压力,不能做到验证完美但是尽可能地消除已经存在的风险。
后续的博客登录功能使用了阿里云人机验证中的智能验证,而人机验证是阿里云的新一代人机识别产品,使用智能验证可以分析出是否存在恶意的请求,维护系统的稳定,在第一道关卡为系统树立一个坚实的屏障。
智能验证可以具体到某一个业务上,并不单是用到登录上,若是需要对于系统频繁地大量读写的API上智能验证就可以保证数据库的稳定。
关于阿里云人机验证中的智能验证原理的序列图如图2-15所示:
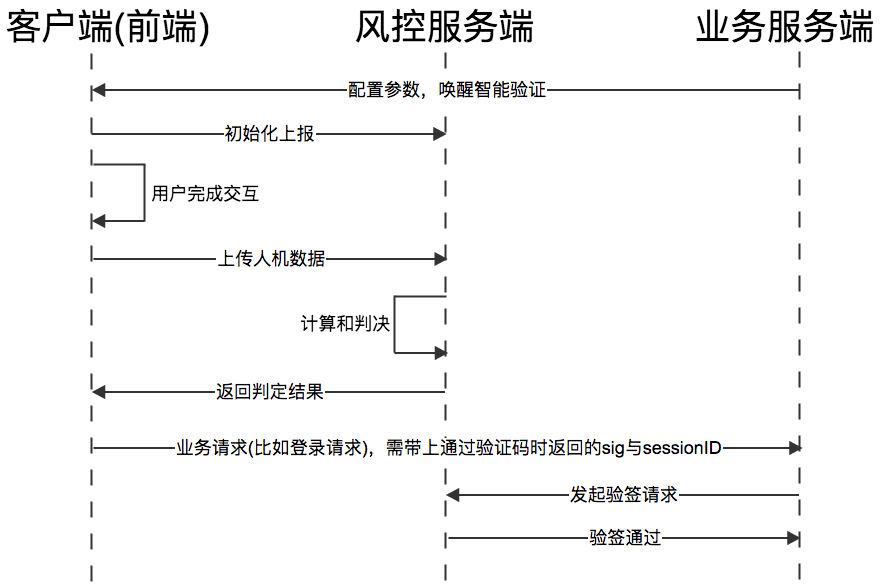
图2-15智能验证的序列图
阅读图2-16可以加深对登录智能验证的理解:
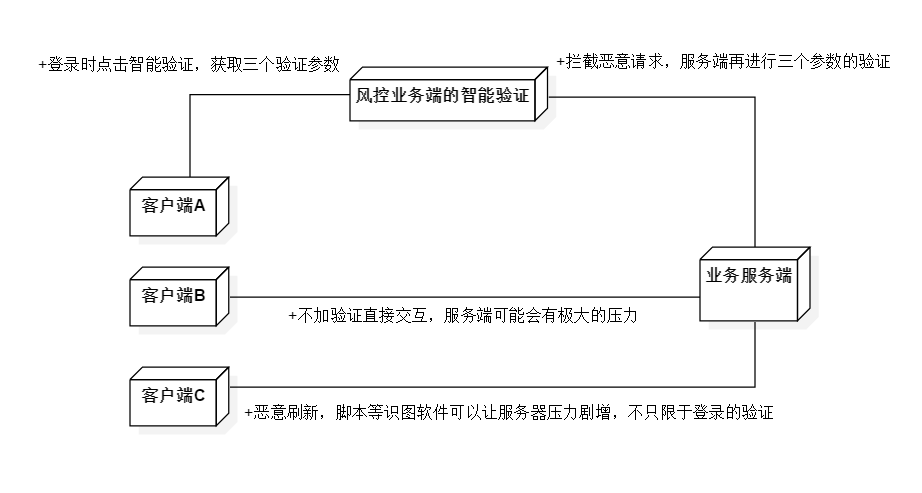
图2-16 登录与验证
风控业务端也可以认为是一种验证的“智能中间件”,中转客户端与服务端之间的验证,与传统的方式多出一个中转验证来维护系统的稳定。
3.10.2 阿里云短信服务
博客手机注册功能采用的是阿里云的短信服务,由于是个人用户,所以只能开通验证码发送的模板,不过够开发者学习使用。
因为博客未采用手机号的登录方式,所以需要用户注册手机号保证账号的安全。手机验证码的发送采用阿里云API的短信服务,本次博客所有关于手机的验证码均用一个模板验证码发送。
阿里云短信API流程图如图2-17所示:

图2-17 阿里云短信API服务流程图
开发者自行去官方建立一个阿里云账号,保持余额开通短信服务,申请一个发送短信的模板。当用户触发短信API时,就会调用个人账号信息去验证短信服务,验证码在本地的Redis中保存,等到用户输入成功就可以完成对应的业务逻辑。
3.10.3 阿里云OSS存储
博客只是用来分享个人的动态,文件可以存储自己的本地服务器,也可以存储在阿里云的OSS(付费),可由个人自行选择。
使用OSS的好处在于可以分担个人的系统压力,不过重要的文件需要存储在本地或者个人自行备份。可以把OSS当作一个中间件来替代原本服务器的存储位置,用户的大量图片与一些文件可以通过网络的方式传到指定的OSS位置,相当于付费缓解服务器的一些存储压力,同样也增强了用户的体验与系统的功能。
网页博客需要上传的大多是图片,可以借助图2-18来理解OSS上传:
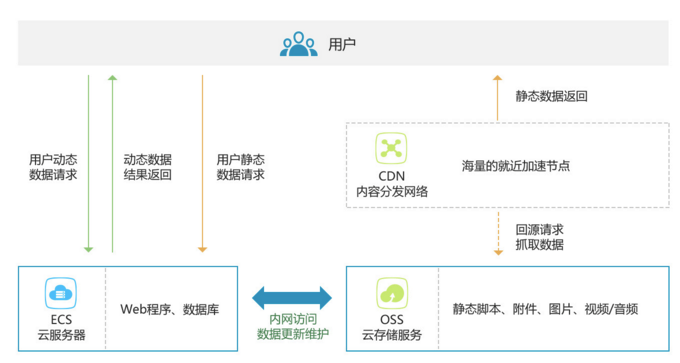
图2-18 OSS上传
开发者需要设置存储库,当用户点击传送图片后,根据开发者的安全信息传到指定的存储库位置,开发者再保存返还回来的外网url即可,传给登录的前端显示,利用LocalStorage把头像的外网url保存到本地。
3.11 关于支付宝支付
本次博客只采用支付宝支付的支付方式,由于需要虚拟测试,所以需要使用支付宝的沙箱App模拟真实的支付宝支付进行博客业务逻辑。
支付宝也是我们生活中常用的App之一,博客中的会员支付业务也涉及到了,支付宝的流程比较复杂,配置信息也比较繁琐,微服务支付中心也是博客的核心功能,支付宝的原始支付方式与二维码支付均有涉及。
阅读支付宝的支付序列图就可以理解支付宝的运行流程,如图2-19所示:
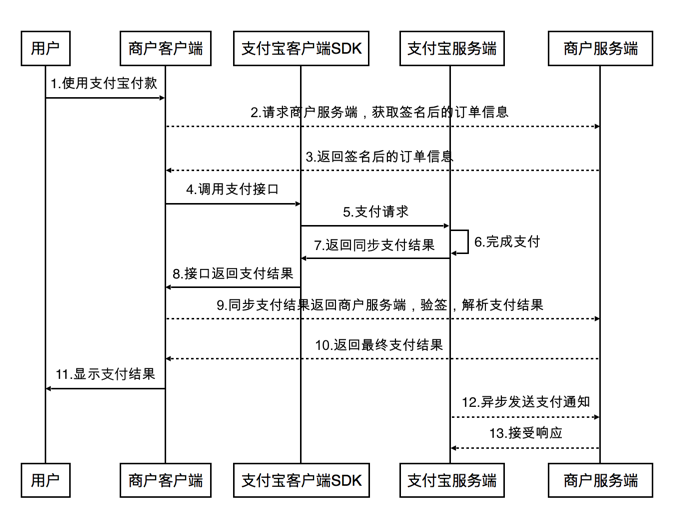
图2-19 支付宝序列图
从图2-19可以看得出,商户客户端代表系统的客户端,商户代表系统的服务端,而支付宝客户端提供传递的SDK来进行交互,在这几个“端”传递的消息是同步通知与异步通知,也就是支付结果,阅读下面的标题就会明白。
3.11.1 同步与异步通知
同步通知:用户的API请求被处理后,支付宝会将请求支付的结果直接同步响应给用户,但是同步通知不可以作为后端判定是否成功的凭证。
异步通知:支付宝会根据后端properties文件中的异步通知地址 notify_url,把用户产生交易的数据通过 POST 请求的方式将支付结果作为参数通知到系统中。
简而言之,同步通知是用来告诉用户的请求支付结果,而异步通知是用来处理业务上的信息,例如对于数据库的一些操作等。由于异步操作可能会耗费一些时间,对于用户来说只需要关心支付结果,所以这些操作用异步来做,并不影响主流程的业务。因此,同步是给用户看,异步是服务器处理请求。
可以借助通信图2-20来加深同步与异步通知的理解:
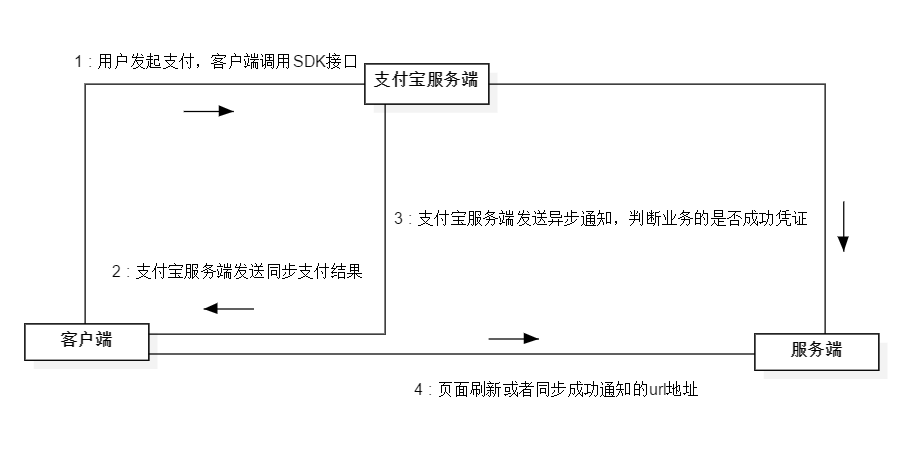
图2-20 同步与异步通知通信图
3.12 本章总结
本章涵盖了整个博客所需要用到的所有的技术,解释了微服务与分布式的概念与区别,为什么要用分布式锁,如何理解高可用,完美细化了Vue的生命周期。
下一个章就会开始定义博客的需求功能业务,本章到此结束。
四、博客的需求分析
4.1 博客的微服务功能分析
博客是互联网的一种分享类型的技术产物,但是如何留着用户才是重要的,并不都是所有的功能都会涉及到“高并发”,博客的功能多样性会增强用户的体验,让用户对博客的使用产生依赖性,利用从众心态合理地开发增值功能。
本次系统的开发采用了主流的微服务架构方式,所以把控每个微服务的功能相互独立和完整是“微服务”系统的关键。由于博客的实现比较简单,所以只有涉及到“高并发”的时候需要断点分析即可,下面将介绍博客系统的一些功能。
博客基本的功都具备,例如博客的核心功能:博客的发表,删除,浏览,评论,点赞等。除了这些,还可以每天定时签到提升博客的等级,充值会员提升使用体验。个人的安全信息也非常重要,所以我单独划分一个微服务中心来实现。同样我在每行重要的代码上都增加了明显的注释,这对于我以后的维护和扩充博客功能可以打下坚实的基础,尽可能地符合软件设计开发原则。
关于博客的功能一共涉及到8个微服务中心:
-
用户的个人中心:包含登录、注册、智能验证。
-
用户的安全中心:安全信息、手机与邮箱的基本功能和安全认证的接口。
-
用户的博客中心:发表和管理个人的博客,游客可以浏览公开的博客。
-
用户的文件中心:发表博客需要用到的图片和个人用户的头像。
-
用户的签到中心:博客的签到累计的经验值和签到奖励。
-
用户的会员中心:包含普通会员和超级会员。
-
用户的支付中心:VIP的充值功能,个人钱包功能,账单等。
-
用户的搜索中心:根据摘要或者文章标题的关键字搜索指定的博客。
4.2 本章总结
本章写的大多是要实现的博客需求,下一章会具体提到博客的架构设计。
五、博客的设计分析
5.1 博客的架构设计
划分完需求后,博客的微服务架构涉及如图4-1所示:
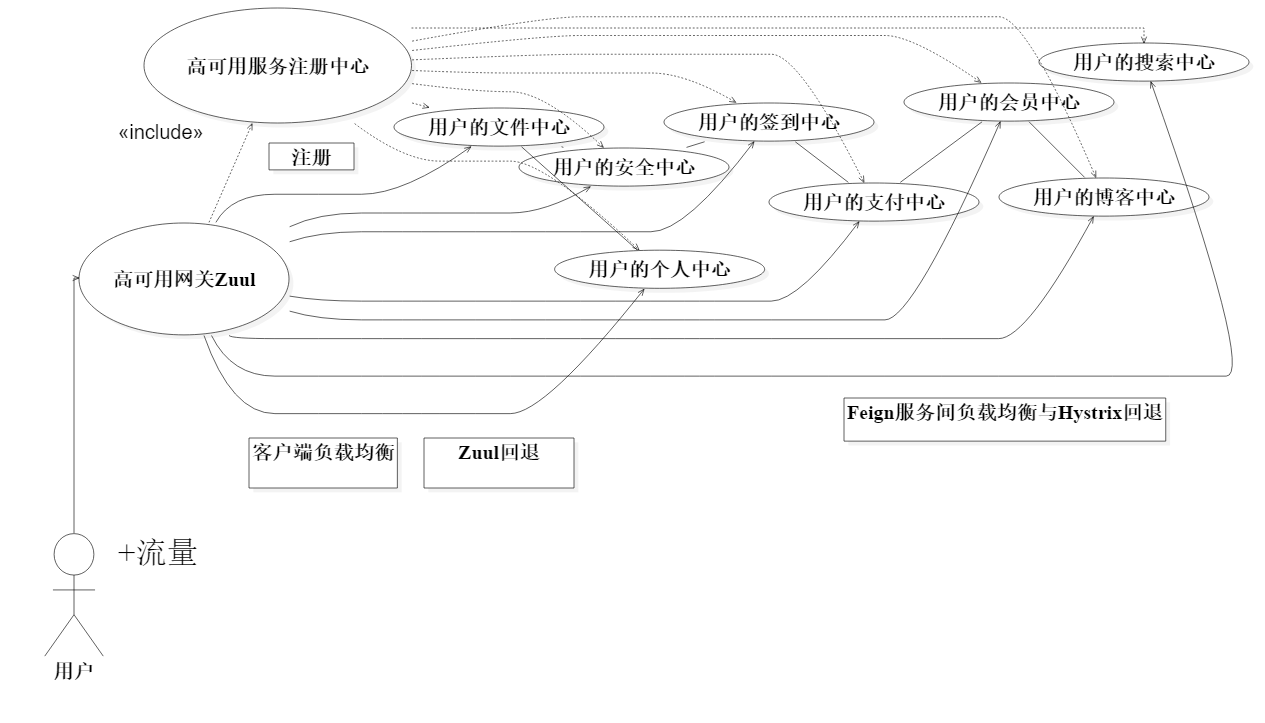
图4-1 博客的微服务架构图
从宏观设计来说,各个微服务中心都是一个moudle,需要注册到一个高可用的微服务注册中心上保证机器信息的正确性。
从微观运行来说,用户的请求API都经过Zuul,再由Zuul负载均衡分配给需要的微服务中心,所以Zuul也需要高可用保证用户流量可以得到回应。通过zuul网关后,请求通过Feign实现微服务之间数据的交互。
当发生错误运行时,利用Hystrix的回退机制保护系统的稳定运行,不会发生级联占用效应,保证每一个请求API都可以得到响应。当发生网络不可用的情况下,需要触发用户的补偿机制,当出现不可知的错误时,也可以直接管理机器的集群来维护系统的稳定运行。
5.2 博客的数据库设计
对于用户来说,需要输入账号和密码,若是不存在可以注册自己的账号和密码。注册的时候提供30分钟填写博客信息的有效时间,不填写则直接登录。需要设置个人的手机和邮箱来绑定安全认证,若想要开通我的钱包则需要实名注册,同样也包含校园认证。丢失了个人信息,则可以用身份证申诉。每天凌晨开始可以开始签到,根据会员的不同增益不同,签到的持续天数不同经验值累加也不同。会员的开通只包含支付宝,账单是每笔消费的记录。核心表是用户博客之类的表,文章均存在数据库,不过ElasticSearch也保存了文章的标题和摘要。每个用户可以评论他人的文章,私密的文章不会出现,会员的文章会出现在会员专区。
博客一共含有8个主功能,所以一共涉及用户表,用户信息表,安全表,头像表,签到表,签到奖励表(两种奖励),会员表,钱包表,订单表,博客表,博客分类表,博客标签表,博客图片表,博客的评论表,点赞表和收藏表17个表。
各个微服务所需要的表如图4-2所示:
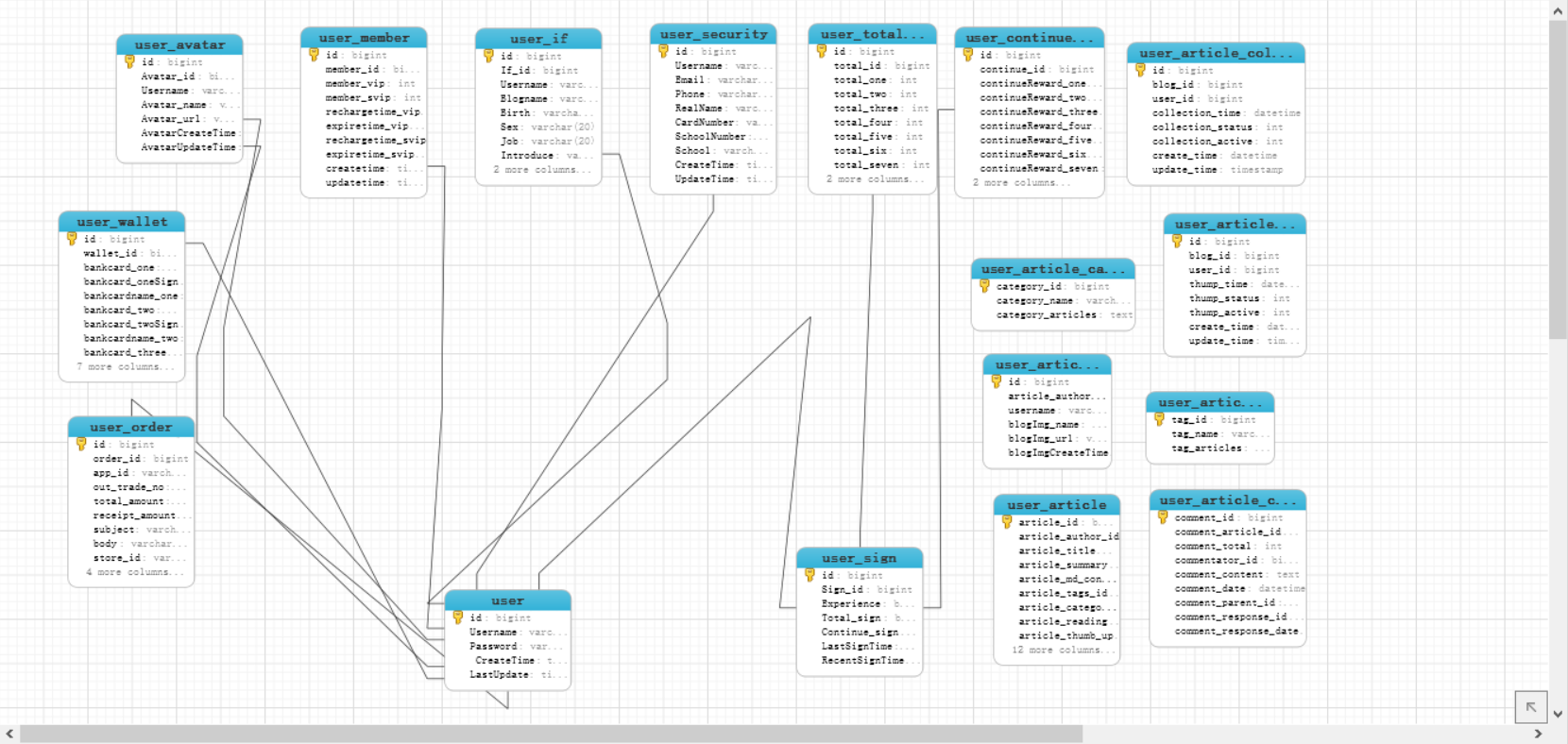
图4-2 博客的Mysql关系图
5.3 本章总结
本章涉及到只有架构设计,而博客总体的功能实现会在下一章中提及。
六、博客的设计实现
6.1 博客总体架构的实现
博客的各个功能均已实现,从前端到后端都会有详解的实现,本章是对前4章的一个实现总结,前文涉及到高可用与分布式时候都会有所提及但未有详解的解答,阅读本章就会明白微服务到底是怎么运行的。
6.1.1 Vue架构的实现
前端IDE采用的是WebStorm,博客的Vue主要分布如图5-1所示
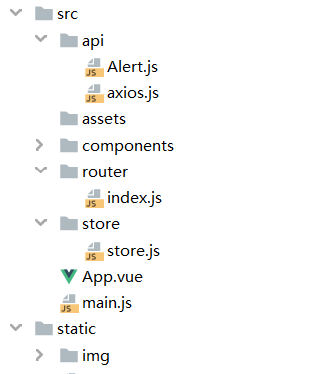
图5-1 Vue架构
Alert.js是自定义重构代码的漂亮提示框。axios.js是封装好的axios请求HTTP函数,components是Vue文件存储位置,也是Vue的组件,index.js是管理前端路由url的跳转,利用components组件与url的控制。store.js是组件状态管理的文件,由于采用的LocalStorage本地存储所以并不是主用。main.js是全局文件也是最重要的文件,管理Vue的全局配置。static/img中保存的是博客所用的图片。
6.1.1 package.json文件
不管是用IDE创建的项目还是采用常规脚手架创建的vue项目,其项目都会在根目录生成一个package.json文件,这个文件与后端的“pom”相似,这个文件包含所需要的各种包,还包含项目的配置的名称与版本对应。
博客项目中的package的完整dependencies代码如以下所示:
c++
"dependencies": {
"axios": "^0.19.0",
"bootstrap": "^3.3.7",
"echarts": "^4.6.0",
"element-ui": "^2.12.0",
"font-awesome": "^4.7.0",
"github-markdown-css": "^4.0.0",
"highlight.js": "^9.18.1",
"jquery": "^3.4.1",
"marked": "^0.8.0",
"mavon-editor": "^2.7.7",
"popper.js": "^1.12.5",
"showdown": "^1.9.1",
"v-charts": "^1.19.0",
"view-design": "^4.0.2",
"vue": "^2.5.2",
"vue-drag-verify": "^1.0.6",
"vue-nocaptcha": "^0.2.8",
"vue-puzzle-vcode": "^1.1.2",
"vue-qr": "^2.2.1",
"vue-router": "^3.0.1",
"vue-schart": "^2.0.0",
"vue-splitpane": "^1.0.6",
"vuex": "^3.1.2"
}
6.1.2 SpringCloud架构的实现
博客Maven的整体微服务中心实现的结构图如图5-2所示:
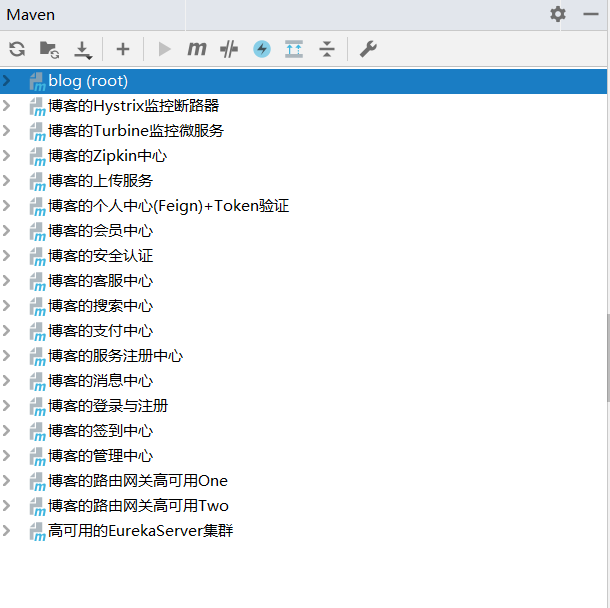
图5-2 SpringCloud后端图
SpringCloud是基于Java语言的工具集,SpringCloud具备拿来就用的特性,可以节省开发的配置时间,它可以在Docker等云环境中开发和部署。SpringCloud的组件比较丰富,博客使用了Eureka,Zuul,Feign,Htsrrix,trubine,Zipkin微服务组件。组件可以自由地选择,不过需要解决SpringBoot与SpringCloud之间的版本依赖才能使用。博客涉及到的Java的JDK版本是1.8,SpringBoot的版本是Spring Boot 1.5.9.RELEASE,SpringCloud的版本是Edgware SR4。后端的IDE采用的是IDEA,Maven的版本为3.6.1,任何一个版本的更改都可能会导致兼容不一致。
6.1.3 博客的高可用的实现
博客使用了两个Zuul并且注册到高可用的服务发现中心来构造Zuul高可用集群。Eureka是所有微服务的注册中心,并且自己本身也是微服务不过需要禁止自我注册。Eureka注册中心包含每个微服务的名称,IP,端口等,由于因为的单个节点的微服务可能会发生不可用的情况下导致系统发生停机,所以采用高可用的微服务注册中心。让两个(多个)服务发现组件相互注册以达到可以保持其它微服务的调用,维持整个系统的高可用性,整个博客的Eureka服务注册中心图如图5-3所示:
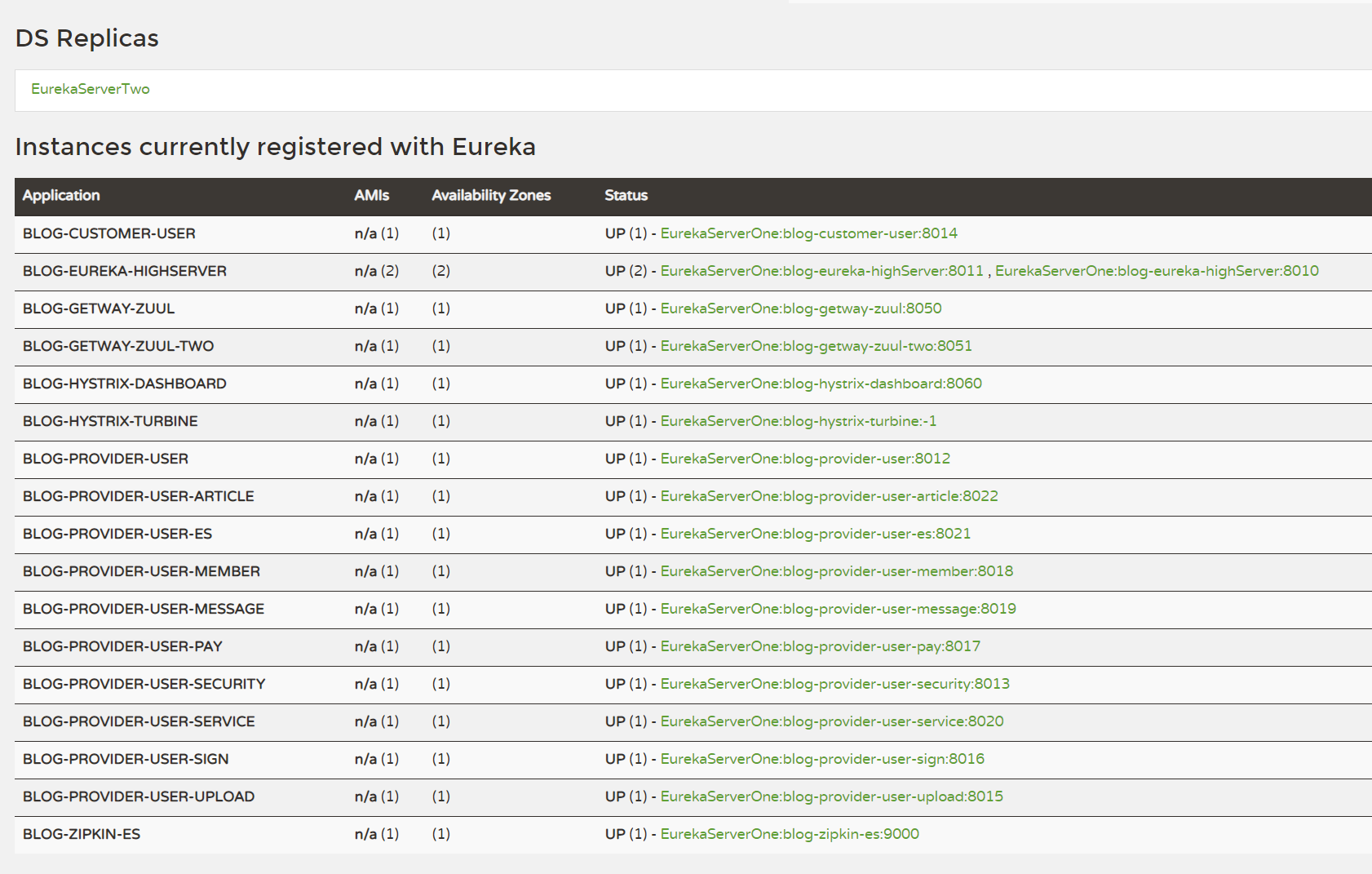
图5-3 Eureka高可用图
DS Replicas代表两个模块加载模拟单机代替高可用的实现,不过需要修改本地Host来模拟真实多机高可用的效果。每个微服务都具有自己的虚拟主机名以及状态来描绘微服务的显示情况。每个微服务之间通过与服务注册中心每30S心跳传递保证服务可用性。默认90S没有收到心跳则会注销该微服务。EurekaServerOne与EurekaServerTwo为两个微服务注册中心,两者相互注册到对方的服务中心上来保证Eureka的高可用稳定,从而使每一个博客的请求都可以得到响应。
6.2 用户的个人中心
用户的个人中心相当于博客的大门,用户的首次流量都经过此处,首次负载均衡调用也是基于这个中心开始,主要涉及到用户的登录与注册的基本功能,在登录上排除恶意的攻击与干扰,保证博客登录的稳定,从而保证系统的稳定。这个中心核心功能就是权限验证,保持登录的标志,它是保持业务稳定的重要因素,后续的实现会在以上所述的三个重要功能展开来讲。
6.2.1 登录的智能验证
Vue整合阿里云智能验证时,需要注册布局组件来动态加载JavaScript文件,不然无法使用阿里云的智能组件,前端登录智能验证的核心代码如以下所示:
c++
//动态加载阿里云的JavaScript文件
<remote-js
src="//g.alicdn.com/sd/nvc/1.1.112/guide.js" @loaded="initCaptcha">
</remote-js>
//注册局部组件来加载阿里云的JavaScript文件
components: {
"remote-js": {
render(createElement) {
const self = this;
return createElement("script", {
attrs: { type: "text/javascript", src: this.src },
on: {
load() {
self.$emit("loaded");
}
}
});
},
props: {
src: { type: String, required: true }
}
}
},
//点击智能验证的封装函数
initCaptcha() {
let _this=this;
let ic = new smartCaptcha({
renderTo: '#sc',
width: 350,
height: 42,
default_txt: "请点击验证按钮",
success_txt: "博客登录验证成功",
fail_txt: "点击按钮重新刷新登录验证",
scaning_txt: "智能检测中",
success: function (data) {
console.log(NVC_Opt.token);
console.log(data.sessionId);
console.log(data.sig);
_this.aliToken=NVC_Opt.token;
//动态加载阿里云的JavaScript文件
< remote - js
src = "//g.alicdn.com/sd/nvc/1.1.112/guide.js"@
loaded = "initCaptcha" > < /remote-js>
//注册局部组件来加载阿里云的JavaScript文件
components:
{
"remote-js":
{
render(createElement)
{
const self = this;
return createElement("script",
{
attrs:
{
type: "text/javascript",
src: this.src
},
on:
{
load()
{
self.$emit("loaded");
}
}
});
},
props:
{
src:
{
type: String,
required: true
}
}
}
},
//点击智能验证的封装函数
initCaptcha()
{
let _this = this;
let ic = new smartCaptcha(
{
renderTo: '#sc',
width: 350,
height: 42,
default_txt: "请点击验证按钮",
success_txt: "博客登录验证成功",
fail_txt: "点击按钮重新刷新登录验证",
scaning_txt: "智能检测中",
success: function(data)
{
console.log(NVC_Opt.token);
console.log(data.sessionId);
console.log(data.sig);
_this.aliToken = NVC_Opt.token;
_this.sessionId = data.sessionId;
_this.sig = data.sig;
},
});
ic.init();
},_this.sessionId=data.sessionId;
_this.sig=data.sig;
},
});
ic.init();
},
6.2.2 博客的登录注册
登录是一个系统的重要的功能,也是个人隐私的重要体现,拿常见的登录有邮箱,手机,账号或,语音或者二维码登录,不过不管通过哪种登录,个人信息的安全都应该得到保护,保护个人隐私重要的是从个人做起,拒绝非法点击与输入。
拿本次博客的登录来说只需要验证账号和密码就行,个人登录是不会进行权限验证。注册成功会保持30分钟的权限验证,关于权限验证会在标题5-2-3中提到,以便后面的博客信息的操作,超过则需要重新登录去博客的个人中心填写博客信息。
博客的登录与注册的页面如图5-4所示:
-
图5-4 登录与注册的页面
-
博客登录的用户名需要以英文子母开头,用户名和密码均不可以超过16位,
-
注册保证两次登录密码正确就可,在此不再贴出图片累述。
6.2.3 登录的权限验证
登陆权限控制是每个系统都应必备的功能,是保持登录状态的重要实现。微服务所有的权限验证均在一个module上,Token消时则直接回退给前端status 404失败码,成功则是执行对应的业务逻辑,注意登录的博客是不需要权限验证。
博客使用了前后端拦截器拦截Token(登录成功的认证码),所以后端需要定义一个token验证注解,用拦截器拦截系统的url请求,再进行拦截用户的API请求,最后再验证传过来的token与Redis中token值是否一致,效验通过才可以正常访问。当用户登录成功博客后,后端返回token数据。token具有存在时间,如果用户一段时间后不在线或者操作的话,则token会失效,用户保持登录时,则不会过期。
Redis中会以用户的登录账号作为与token关联的认证,有效的token码可以取出用户的账号,然后再进行业务逻辑。这些redis中的key都可以自行设置一些时间,不过前端只保存token值,二次登录会覆盖Redis中的token值。
权限验证保持登录状态如图5-5所示:

图5-5 权限验证
权限验证相当于系统的第一道大门,如今的安全框架越来越丰富,例如SpringSecurity,Shiro,OAuth等,shiro->security->oauth的上手难度逐渐提升。若是需要对密码加密的,可以需根据个人开发自行配置使用对应的安全框架。
登录验证的前端钩子与拦截器实现前端的Token的检测的代码如以下所示:
c++
//钩子方法验证Token是否存在
router.beforeEach((to, from, next) =>
{
//改变网页的标题
window.document.title = to.meta.title;
//强制登录并且检测token
let token = localStorage.getItem('token');
if(!token && to.path !== '/home/login')
{
return next('/home/login')
}
next()
});
// 添加响应拦截器
axios.interceptors.response.use(function(response)
{
// 对响应数据做点什么
return response;
}, function(error)
{
// 对响应错误做点什么
if(error.response.status === 401)
{
router.replace(
{
name: 'Login'
}).then(res =>
{
alert('身份验证失效,请重新登录!');
window.localStorage.clear();
})
}
else
{
alert('服务开了小差,请稍后再试!');
}
// if (error.response.status === 500)
return Promise.reject(error);
});
登录验证的后端拦截所有的URL请求实现Token检测的代码如以下所示:
c++
//拦截所有从前端传过来的请求,必须被@AuthToken注解修饰
//Springboot2.X之后是实现WebMvcConfigurer接口
//Springboot1.X-2.X之间是继承WebMvcConfigurer缺省适配器类
@
Configuration
public class WebAppConfiguration extends WebMvcConfigurerAdapter
{
//拦截所有的URL请求
@
Override
public void addInterceptors(InterceptorRegistry registry)
{
registry.addInterceptor(new AuthorizationInterceptor()).addPathPatterns("/**");
}
}
//自定义注解Token,凡是被@AuthToken注解修饰的要验证headers中的TOKEN
@
Target(
{
ElementType.METHOD, ElementType.TYPE
})@ Retention(RetentionPolicy.RUNTIME)
public@ interface AuthToken
{}
// 如果打上了AuthToken注解则需要验证token
if(method.getAnnotation(AuthToken.class) != null || handlerMethod.getBeanType().getAnnotation(AuthToken.class) != null)
{
String token = request.getHeader(httpHeaderName); //从headers中获得TOKEN码
//String token = request.getParameter(httpHeaderName);//从URL上面获得TOKEN
String username = "";
Jedis jedis = new Jedis("localhost", 6379);
if(token != null && token.length() != 0)
{
username = jedis.get(token);
}
}
6.3 用户的安全中心
6.3.1 用户的安全布局
安全中心包含邮箱,手机,身份证,校园认证和其它微服务中心需要用到的认证接口。邮箱采用QQ邮箱,开启SMTP 587端口发送邮箱验证码。手机采用阿里云短信API服务。两者的验证码存在的时间均为1次失效且存在10分钟。身份证需要手机号的验证。校园认证的名字需要和身份证的名字一致。除了绑定一些安全的服务,还包括三种修改密码的方式,原始密码修改新密码,邮箱重置密码,手机重置密码,身份证重置密码。个人申述包括手机号重置邮箱,旧手机更换新手机,身份证重置手机。安全中心前端图如图5-6所示:
图5-6 安全中心前端图
安全中心包括用户的规则规章,博客旨在分享自己的动态和经验给他人,不可以辱骂他人,以及不遵守国家的法律法规。本次博客的其它微服务中心所需要的手机认证接口均由这个微服务中心提供。
6.3.2 用户的邮箱注册
博客采用的是免费的QQ邮箱,邮箱的yml配置如下:
c++
mail:
host: smtp.qq.com
port: 465或587
c++
protocol: smtp
username: 个人的邮箱
password: 邮箱的SMTP的密码,可在邮箱的账户中开启SMTP服务
python
default-encoding: UTF-8
properties:
mail:
debug: true #控制台开启运行日志
QQ邮箱(邮箱与手机的六位验证码共用)发送验证码按钮的原代码如以下所示:
c++
//自动生成的验证码,验证码的位数可以自己设定
public static String generateVerifyCode(int verifySize, String sources)
{
if(sources == null || sources.length() == 0)
{
sources = EMAIL_CODES;
}
int codesLen = sources.length();
Random rand = new Random(System.currentTimeMillis());
StringBuilder verifyCode = new StringBuilder(verifySize);
for(int i = 0; i < verifySize; i++)
{
verifyCode.append(sources.charAt(rand.nextInt(codesLen - 1)));
}
return verifyCode.toString();
}
绑定QQ邮箱JavaScript的代码如以下所示:
c++
//绑定邮箱的发送
registerEmail()
{
let emailPatter = /[\w!#$%&'*+/=?^_`{|}~-]+(?:\.[\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?/;
if(this.email === '' || !emailPatter.test(this.email) || this.emailYzm === '')
{
this.$message.error('输入内容不能为空且邮箱要符合格式')
}
else
{
this.$http.post('/whc/blog-customer-user/emailButtonRegister',
{
email: this.email,
emailYzm: this.emailYzm,
}).then(res =>
{
console.log(res);
if(res.data.success === true)
{
this.$notify(
{
title: '成功',
message: '邮箱绑定成功',
type: 'success',
});
window.localStorage.setItem('myEmail', res.data.message);
this.reload();
//this.$router.go(0);
}
else
{
this.$message.error(res.data.message);
}
})
}
}
后端发送QQ邮箱注册的验证码如以下所示:
c++
//后端QQ邮箱发送验证码的按钮服务
@Override
@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED)
public void sendEmailCode(String email) {
//生成邮箱随机的6位验证码
String emailYzm= generateVerifyCode(6, EMAIL_CODES);
//From-to,主题和信息.
SimpleMailMessage simpleMailMessage = new SimpleMailMessage();
simpleMailMessage.setFrom(FORM);
simpleMailMessage.setTo(email);
simpleMailMessage.setSubject(SUBJECT);
simpleMailMessage.setText("你的邮箱验证码是: "+emailYzm+"本次验证码 会在10分钟后失效,请立马使用。");
//发送邮箱验证码
javaMailSender.send(simpleMailMessage);
//开启Redis存入email和yzm
Jedis jedisEmail = new Jedis("localhost", 6379);
//设置邮箱(key)-验证码(value)的绑定,秒为单位,存在时间为10分钟。
jedisEmail.set(email,emailYzm);
jedisEmail.expire(email,600);
//设置验证码(key)-邮箱(value)的绑定,秒为单位,存在时间为10分钟。(双向绑定可以判断失败存入的验证码,双向保险)
jedisEmail.set(emailYzm,email);
jedisEmail.expire(emailYzm,600);
}
6.3.3 用户的手机注册
发动短信的前端JavaScript的代码如以下所示:
c++
//前端绑定手机
phoneRegister(){
let phonePatterRegister=/^1([38][0-9]|4[579]|5[0-3,5-9]|6[6]|7[0135678]|9[89])\d{8}$/;
if (this.phone === '' || this.phoneYzm === '' || !phonePatterRegister.test(this.phone)){
this.$message.error('手机或者验证码不符合规则');
}else {
this.$http.post('/whc/blog-customer-user/phoneRegisterButton',{
phone: this.phone,
phoneYzm: this.phoneYzm,
}).then(res =>{
console.log(res);
if (res.data.success === true){
this.$notify({
title: '成功',
message: '手机绑定成功',
type: 'success',});
window.localStorage.setItem('myPhone',res.data.message);
this.reload();
//this.$router.go(0);
}else {
this.$message.error(res.data.message);}})}}
后端发送验证码的代码如以下所示:
c++
//前端绑定手机
phoneRegister()
{
let phonePatterRegister = /^1([38][0-9]|4[579]|5[0-3,5-9]|6[6]|7[0135678]|9[89])\d{8}$/;
if(this.phone === '' || this.phoneYzm === '' || !phonePatterRegister.test(this.phone))
{
this.$message.error('手机或者验证码不符合规则');
}
else
{
this.$http.post('/whc/blog-customer-user/phoneRegisterButton',
{
phone: this.phone,
phoneYzm: this.phoneYzm,
}).then(res =>
{
console.log(res);
if(res.data.success === true)
{
this.$notify(
{
title: '成功',
message: '手机绑定成功',
type: 'success',
});
window.localStorage.setItem('myPhone', res.data.message);
this.reload();
//this.$router.go(0);
}
else
{
this.$message.error(res.data.message);
}
})
}
}
6.3.4 用户的安全认证
提供安全的认证有身份认证与校园认证,当然只是表单的提交,真实的认证需要有关部门的配合,在此只是用来模拟,校园认证需要与身份证的名字保持一致,否则无法通过。实名认证与图5-7所示,校园认证由图5-8所示。
图5-7 实名认证

图5-8校园认证
6.3.5 用户的密码安全
当个人安全账号发生异常,可以提供修改密码,也可以重置密码。
如图5-9修改个人密码与图5-10重置个人密码所示:
图5-9 修改个人密码
图5-10 重置个人密码
6.3.6 用户的账号申诉
可以使用手机号重置邮箱,也可以使用旧手机号更换新手机号。如果个人博客的手机号安全信息被盗取,手机号也可以被重置,但是需要借助身份证申诉,不过一天只可以成功申诉一次。如图5-11所示:
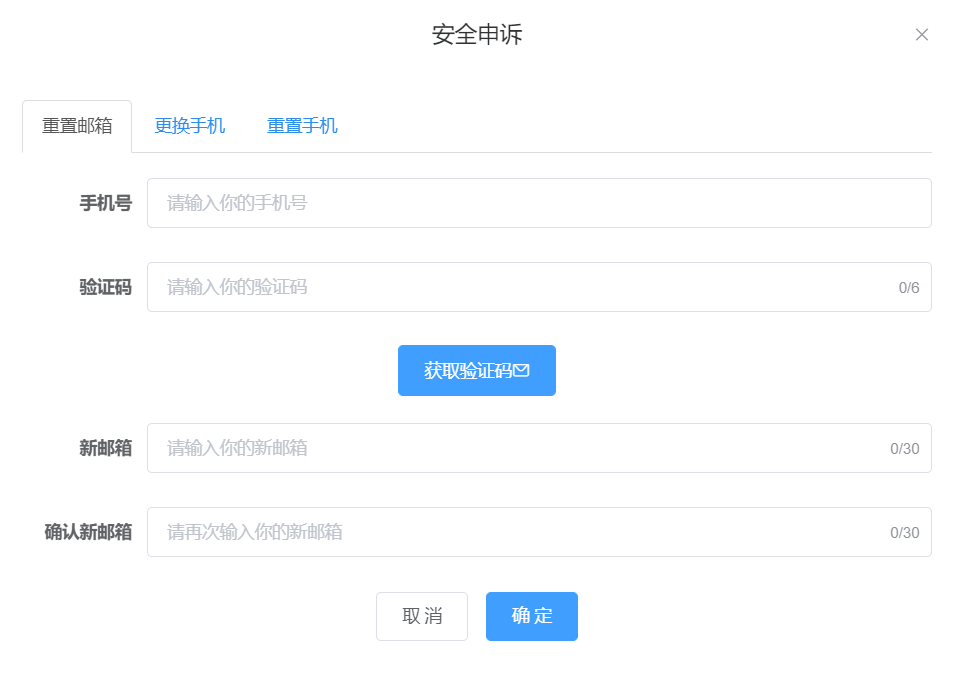
图5-11 安全申诉
对于安全申诉的一天时效使用Redis中间件:
c++
//设置一天的限时
jedis.set(resetName,username);
jedis.expire(resetName,86400);
6.4 用户的文件中心
6.4.1 用户的头像存储
当用户注册的时会需要选择个人的头像,上传的头像只能是JPG格式且大小不能超过2MB,且上传前会先查询数据库中的头像图片名是否已经存在,存在的话直接会先删除OSS中旧图片,再插入新图片,如果不存在的话,直接插入到OSS文件服务器中。头像的存储流程由前端发起file传给后端,后端接受file头像,利用二进制传给OSS文件服务器。服务器再传过来头像的外网URL地址,此时修改显示时间为10年再返还给用户,最后把头像外网URL地址保存到自己的LocalStorage本地。用户头像上传到OSS对象文件服务器如图5-12所示:

图5-12 OSS用户头像上传
6.4.2 博客的图片存储
发表博客时文章中会包含图片,前端获取后端的博客图片url绑定在前端文章中显示,同样url也在文章内容中一起保存到数据库中。上传图片和上传头像不同,文章需要用到的图片可以有多张,不存在覆盖问题。需要根据个人的文件服务器的存储量来权衡上传图片大小。上传博客图片的原代码如以下图5-13所示:
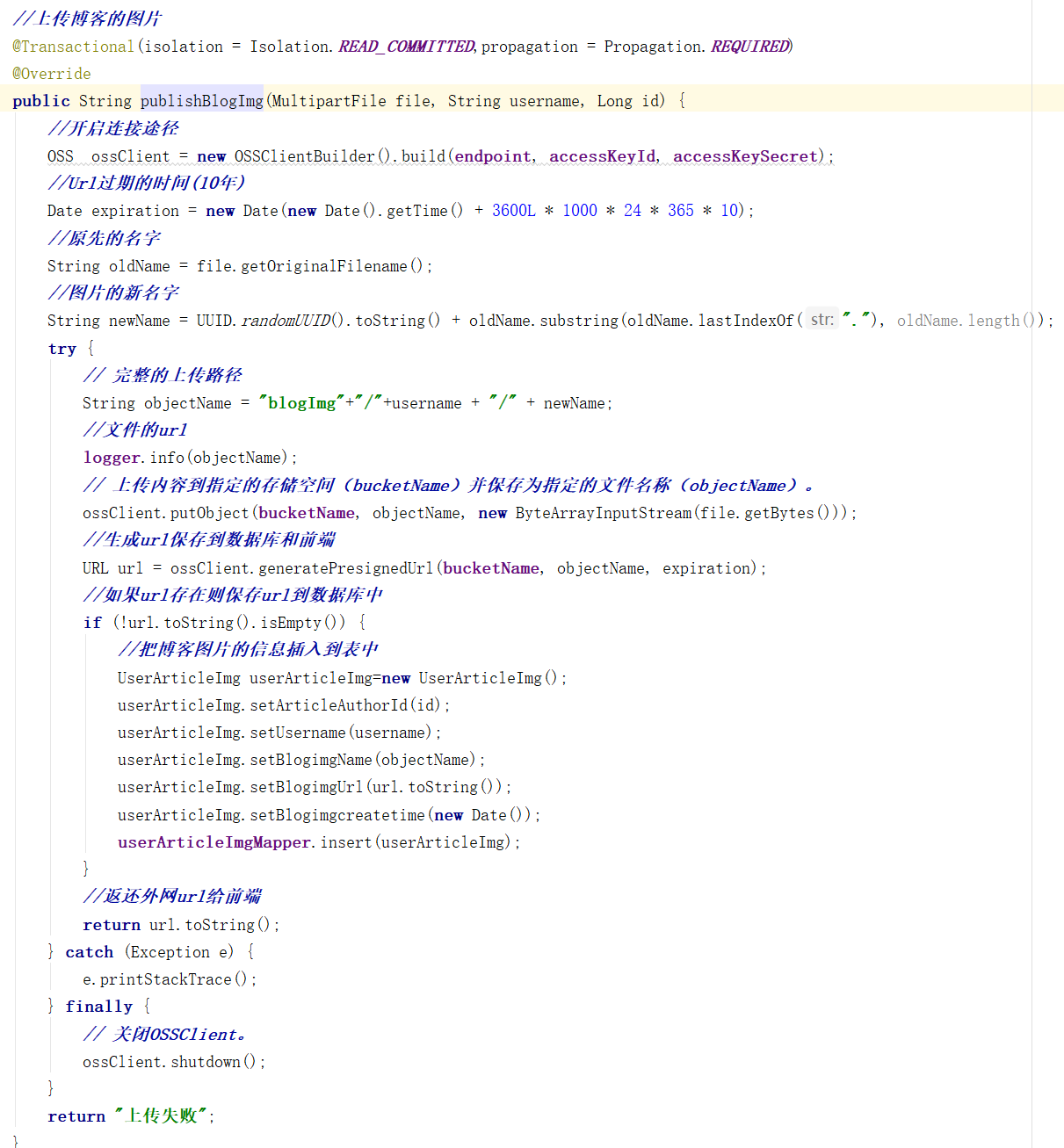
图5-13 上传博客的图片
6.5 用户的签到中心
用户的签到等级代表用的可以使用的权限,当签到累计天数和连续天数达到奖励阶段时触发一键领取奖励按钮,每次奖励每个账号只可以领取一次。整个签到的等级由经验值决定,但是每天获得经验值为1500。签到的经验值还会进行快速排序排名返还给前端,提升竞争效果,同时会员增益机制也会导致不同的叠加效果。
每天0点之前只能签到一次,过完0点后Redis中限时凭证失效既可以再次签到,签到的经验值采用二分查找和快速排序算法进行计算最后的排名返还给用户。
签到按钮的计算代码如以下所示:
c++
//先判定是否redis中是否存在限时凭证
Jedis jedis = new Jedis("localhost", 6379);
if (jedis.get(id.toString()) == null) {
//获取明天0点的时间并且设置限时凭证
try {
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//设置日期格式
Calendar cal = Calendar.getInstance();
cal.add(Calendar.DATE, 1);//这里改为1
Date time = cal.getTime();
String tomorrow = new SimpleDateFormat("yyyy-MM-dd 00:00:00").format(time);
String now = df.format(new Date());
Date d1 = df.parse(now);
Date d2 = df.parse(tomorrow);
//小时和分钟和秒相减
Long hour = ((d2.getTime() - d1.getTime()) / (60 * 60 * 1000));
Long minute = ((d2.getTime() - d1.getTime()) / (1000 * 60));
Long second = ((d2.getTime() - d1.getTime()) / 1000);
//最后存在的秒时间
int total = (hour.intValue()) * 3600 + (minute.intValue()) * 60 + second.intValue();
//控制台观看
logger.info(tomorrow + "/n" + now + "/n" + total);
//设置redis中的签到过期时间
jedis.set(id.toString(), "今天签到已经完成!");
jedis.expire(id.toString(), total);
return SUCCESS;
} catch (ParseException e) {
printStackTrace();}
}
return FAILED;
经验值的排名的代码如以下所示:
c++
//先查询所有的经验值
List<Long> exAll=userSignMapper.selectExperience();
//先将List<Long>集合转为Long[]数组
Long[] a=exAll.stream().toArray(Long[]::new);
//可以使用转换工具类,也可以自己动手写Long数组的转换
long[] quickSort = ArrayUtils.toPrimitive(a);
//快速排序排序成从小到大的顺序
sortService.quickSort(quickSort,0,quickSort.length-1);
//利用二分查找算法查找经验值所在的索引位置
int position=sortService.binarySearch(quickSort,myExperience);
//最终排名,倒序输出。
int lastPosition=quickSort.length-position;
//控制条输出你的排名
logger.info("你在经验值排行榜中的名次是:"+lastPosition);
//返回给前端的排名
return lastPosition;
6.6 用户的会员中心
6.6.1 会员的流程控制
由于会员中心与支付中心联系比较密切,所以两者的中心可以结合起来看作一个中心来观看。用户的会员中心包括普通会员和超级会员,每种方式存在三种收益方式,年费季费和月费,支付成功后均由负载均衡执行业务逻辑。由于支付不属于这个module中,所以这个module只是由其它微服务调用直接完成业务逻辑。
支付微服务Feign调用的年费会员的状态图如以图5-14所示:
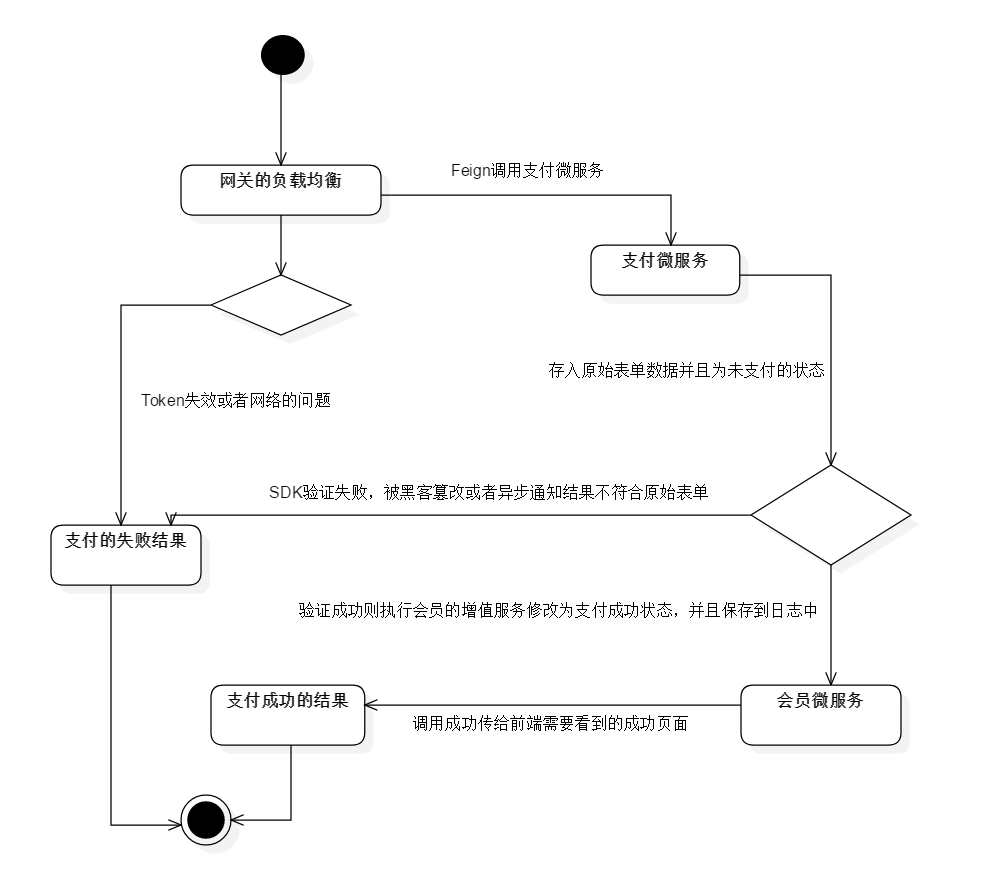
图5-14 用户会员的状态图
6.7 用户的支付中心
6.7.1 用户的支付中心
未完成实名认证时页面会转到实名认证中,当完成实名认证时,首次进入我的钱包中心会触发设置支付密码,当设置成功后,支付以及绑定个人银行卡均需要用到支付密码。可以用旧支付密码修改新密码,也可以手机重置手机密码。还可以绑定自己的银行卡,需要有关部门的配合。本次博客只允许建设银行,工商银行和中国银行,且每张银行卡只允许绑定一张。利用v-charts组件把个人的时间段的消费情况以条形图展现给用户观看。博客支付中心的前端图如图5-15所示:
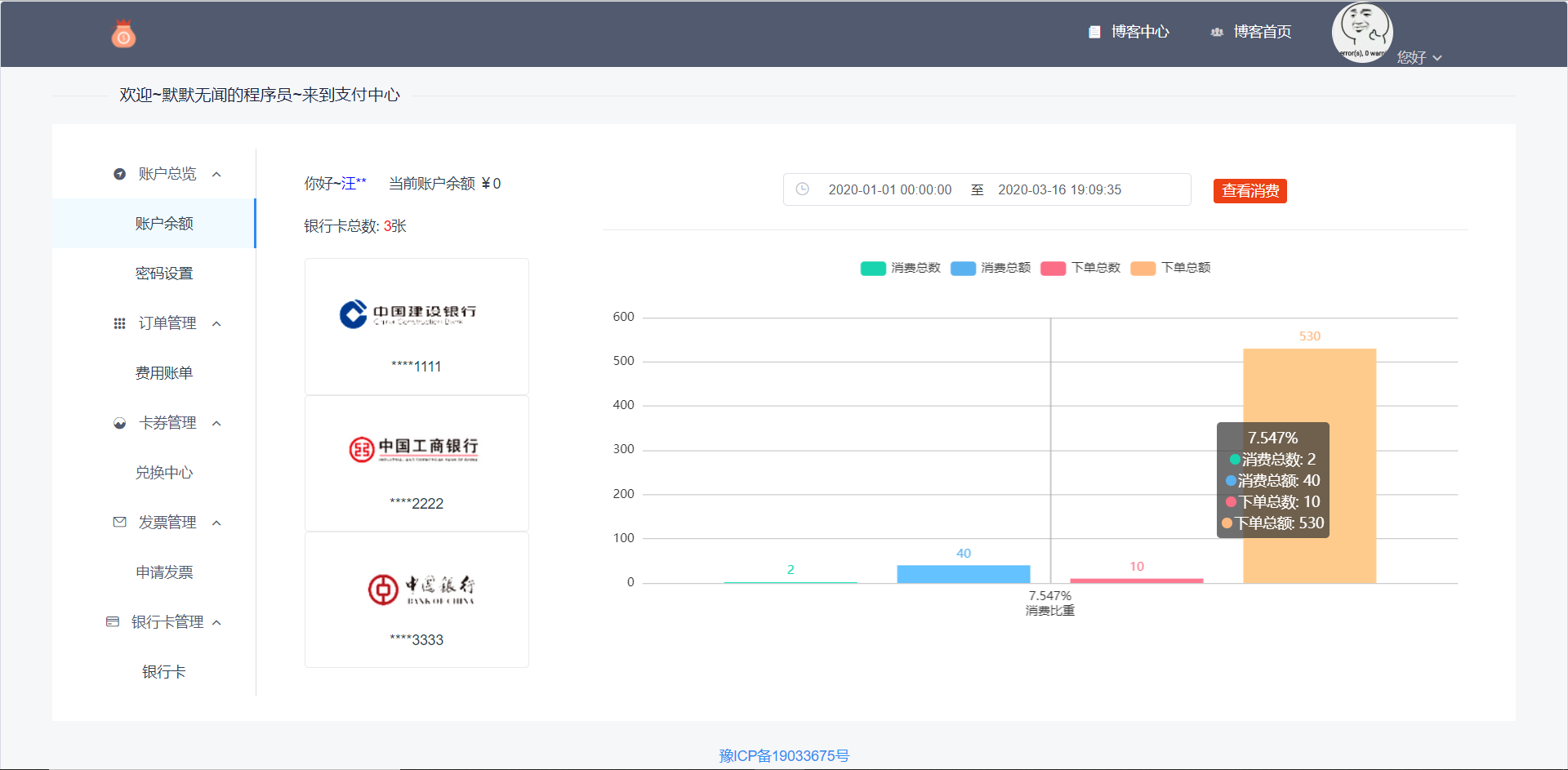
图5-15 前端支付中心
用户设置个人支付密码由5-16所示:

图5-16 设置支付密码
6.7.2 用户的账户钱包
6.7.2 我的账户余额
当用户开通了我的钱包后,可以选择是否进行余额充值,账户余额暂时只可以用支付宝充值。所有关于金额的操作均需要在后端安全操作,前端只用来显示数据,必须使用数据库中的金额。
我的钱包如图5-17所示:
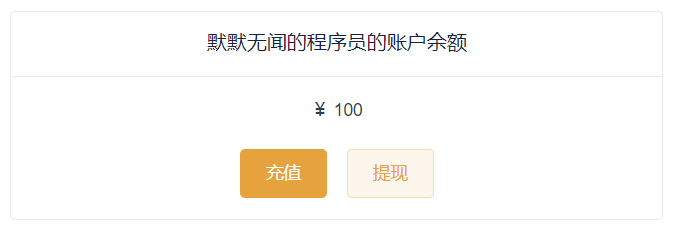
图5-17 我的钱包
充值账户余额如图5-18所示:
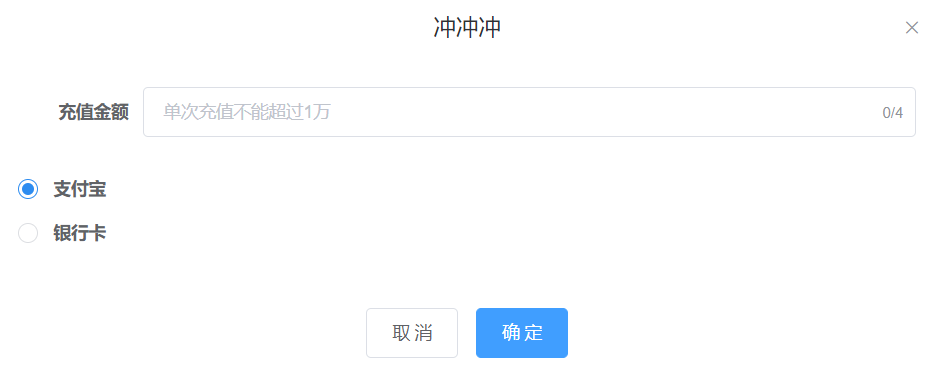
图5-18 充值
6.7.2 我的支付密码
密码为6位有效数字,可以使用原密码更换新支付密码,如图5-19所示:

图5-19 更换支付密码
丢失忘记,可以使用手机号重置支付密码,如图5-20所示:
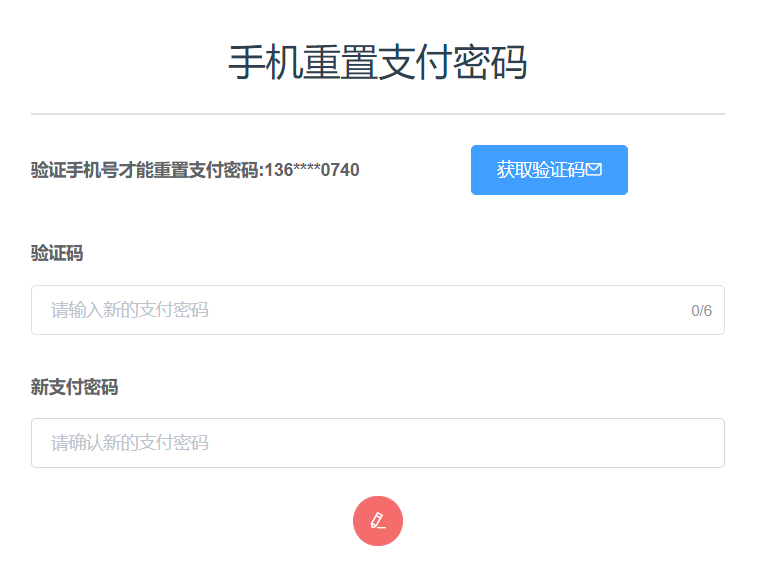
图5-20 重置支付密码
6.7.2 我的账户银行卡
银行卡姓名需要与实名认证的姓名一致。主页如图5-21所示,绑定银行卡如图5-22所示,解绑银行卡如图5-23所示:
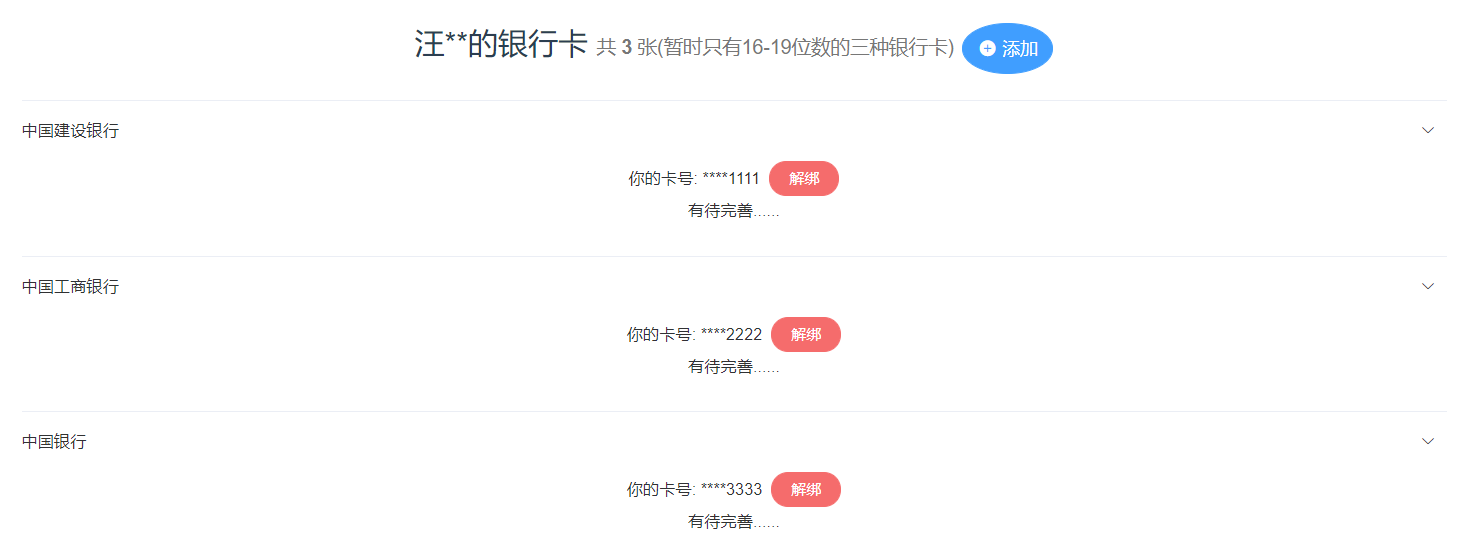
图5-21 银行卡主页
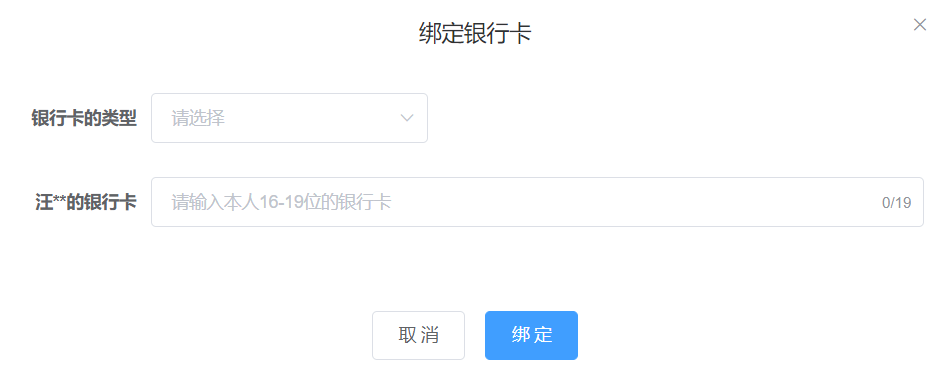
图5-22 绑定银行卡
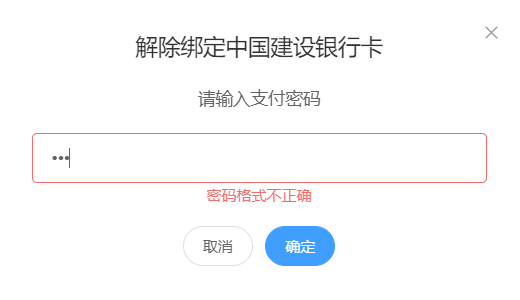
图5-23 解绑银行卡
6.7.3 用户的会员支付
支付中心包含普通会员和超级会员,由于普通会员采用支付宝原始的方式,而超级会员采用支付宝的二维码方式,所以两者会在调用的时候会有所不用。
超级会员的支付页面由图5-24所示:
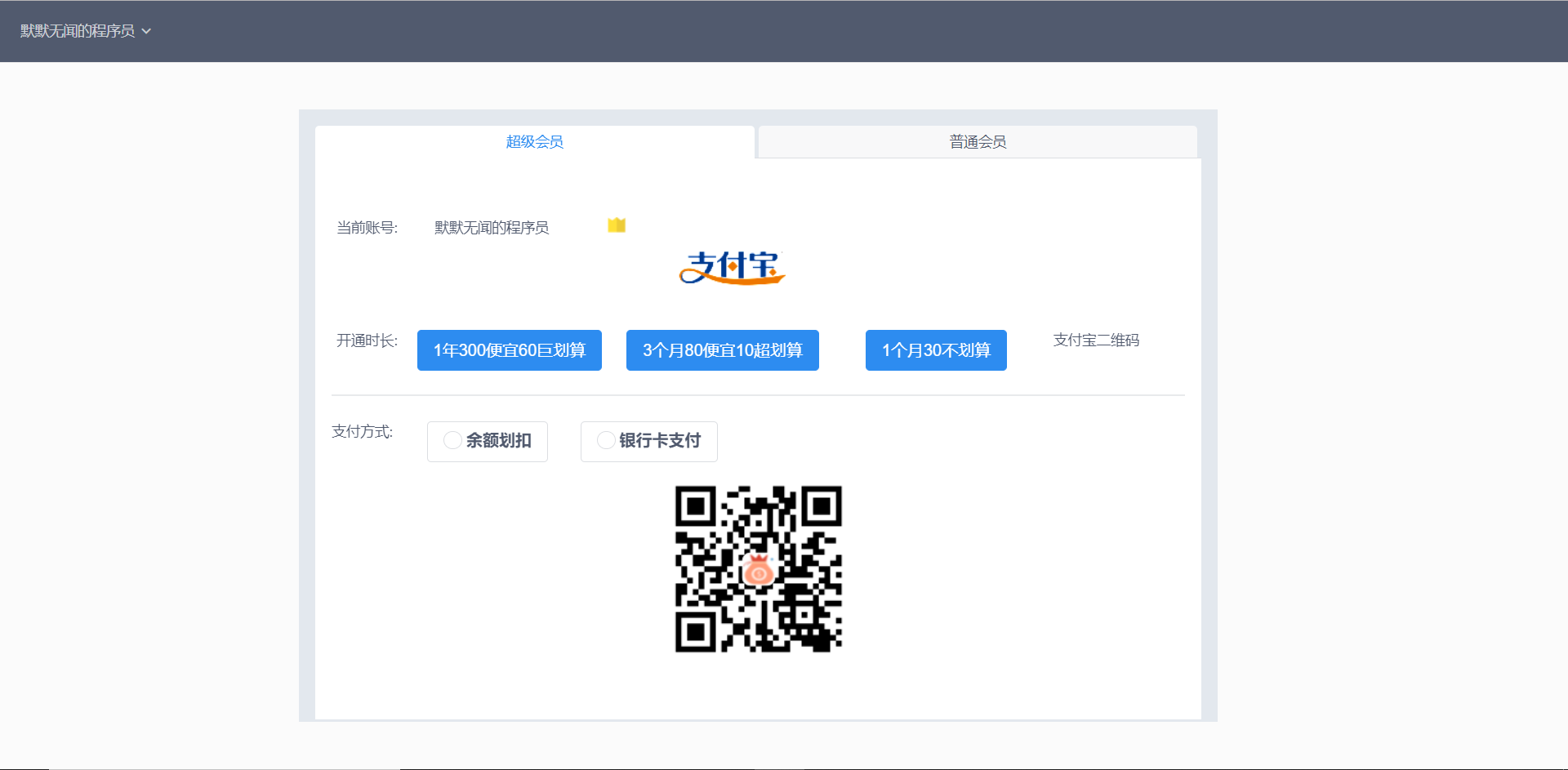
图5-24 超级会员
普通会员的支付页面由图5-25所示:

图5-25 普通会员
6.7.3 普通会员支付的发起
由开通普通会员为例,结果以图2-19中的异步发送支付通知为准,成功与失败均由这个通知为基准,判定进行什么样的业务逻辑。开通普通会员的同步支付的后端原代码如以下所示:
c++
//1、获得初始化的AlipayClient
AlipayClient alipayClient = new DefaultAlipayClient(
PropertiesConfig.getKey("gatewayUrl"),//支付宝网关
PropertiesConfig.getKey("app_id"),//appid
PropertiesConfig.getKey("merchant_private_key"),//商户私钥
"json",
PropertiesConfig.getKey("charset"),//字符编码格式
PropertiesConfig.getKey("alipay_public_key"),//支付宝公钥
PropertiesConfig.getKey("sign_type")//签名方式
);
//2、设置请求参数
AlipayTradePagePayRequest alipayRequest = new AlipayTradePagePayRequest();
//3、页面跳转同步通知页面路径
alipayRequest.setReturnUrl(PropertiesConfig.getKey("return_url"));
//4、服务器异步通知页面路径
alipayRequest.setNotifyUrl(PropertiesConfig.getKey("notify_url"));
//5、封装参数
alipayRequest.setBizContent(JSON.toJSONString(alipayBean));
//6、请求支付宝进行付款,并获取支付结果
String result = alipayClient.pageExecute(alipayRequest).getBody();
//7、返回付款信息
return result;
6.7.3 超级会员支付的发起
同样超级会员也是与普通会员的支付过程一致,但是与支付宝交互的方式为当面付的方式,所以返回的是一串字符串网址放到前端的二维码中,二维码可以是一段话,一张图片也可以是一个网址。超级会员的回调过程也必须按照图2-19中的异步发送支付通知为准。
二维码支付的后端的原代码如以下所示:
c++
//1、获得初始化的AlipayClient
AlipayClient alipayClient = new DefaultAlipayClient(
PropertiesConfig.getKey("gatewayUrl"),//支付宝网关
PropertiesConfig.getKey("app_id"),//appid
PropertiesConfig.getKey("merchant_private_key"),//商户私钥
"json",
PropertiesConfig.getKey("charset"),//字符编码格式
PropertiesConfig.getKey("alipay_public_key"),//支付宝公钥
PropertiesConfig.getKey("sign_type")//签名方式 );
//2、设置请求参数
AlipayTradePrecreateRequest alipayRequest = new AlipayTradePrecreateRequest();
//3、页面跳转同步通知页面路径
alipayRequest.setReturnUrl(PropertiesConfig.getKey("return_url"));
//4、服务器异步通知页面路径
alipayRequest.setNotifyUrl(PropertiesConfig.getKey("notify_url"));
//5、封装参数
alipayRequest.setBizContent(JSON.toJSONString(alipaySvipBean));
//6、返回JSON
AlipayTradePrecreateResponse response = alipayClient.execute(alipayRequest);
//7、返回二维码的网址,也可以自己在后端定义图片传给前端
return response.getQrCode();
6.7.3 关于博客支付的回调
支付宝回调的接口需要验证博客支付的结果,正确的话需要另起一个线程来执行业务逻辑,所以需要用到线程池框架中的Executors.newFixedThreadPool(20),表示20个定长并发线程池,超过必须等待。支付宝配置中的notify_url网址需要在外网可以被访问,如果需要测试则需要把项目放到外网。不过可以使用内网穿透测试,相当于把你本地的端口号模拟到外网的IP地址上。所以每次异步通知会访问到本地的异步通知的API,来达到真实支付宝的效果。
支付宝回调接口的具体步骤如以下所示:
-
检验支付宝签名回调,成功后进行后续操作。
-
需要检验该异步通知中数据的订单号是否为用户最开始请求的订单号
-
检验参数中的数据是否为开始支付的实际金额。
-
检验用户的seller_id,也可以省略。
-
检验收款Id是否为该收款人,上述任何一个操作失败,都表明本次的异步通知是异常通知。
在上五个步骤通过后,开发者需要根据不同的业务通知,正确的进行不同的业务逻辑。在博客的支付业务中,只有从支付宝传过来的支付结果状态为Success或者Finish时,系统才会认为是交易成功,成功后需要负载均衡调用会员中心执行对应的会员业务,并且完成订单的更新。
支付宝回调核心的原代码如图5-26以下所示:

图5-26 支付宝回调
支付宝验证回调签名是回调的核心,只要回调过来的异步信息是本人本次,并且实收金额与发起金额一致就就可以另起线程去执行完整的业务逻辑。
6.7.4 用户的支付账单
账单中心是分页展示给用户观看,提供当前页面,月份和全部的账单打印Csv。前端可以直接把后端的数据直接打包Csv,也可以自行后端打包Csv数据到本地。
支付中心的消费账单如图5-27所示:
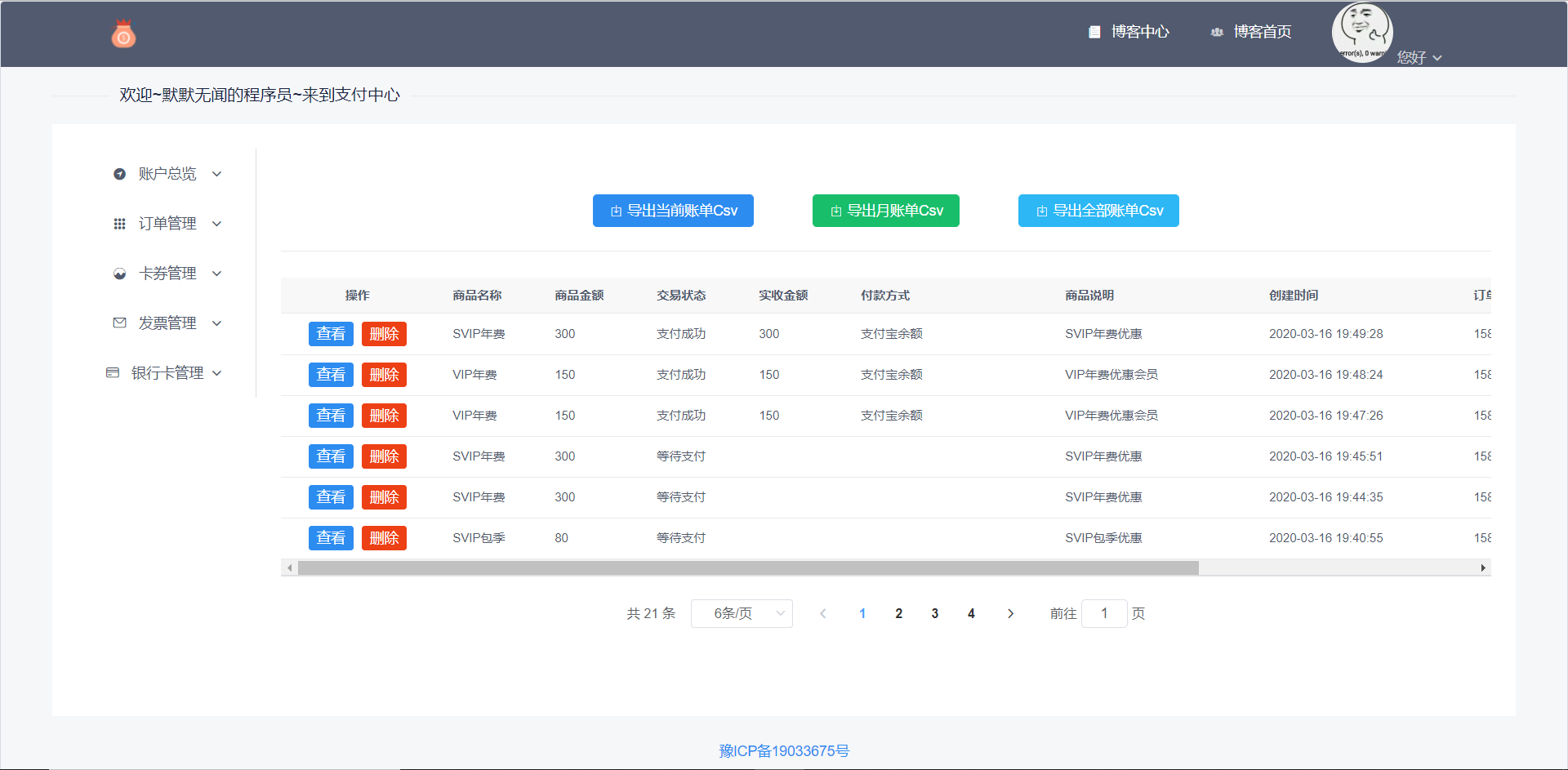
图5-27 消费的账单
查看按钮如图5-28所示:

图5-28查看按钮
删除指定的消费记录如图5-29所示:

图5-29 删除消费记录
打印不同的账单如图5-30所示,导出全部账单需要手机验证如图5-31:
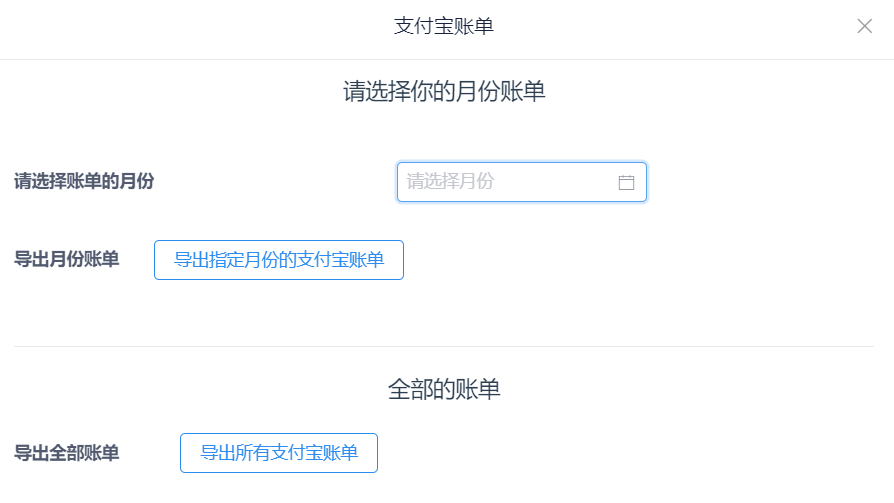
图5-30账单打印页面
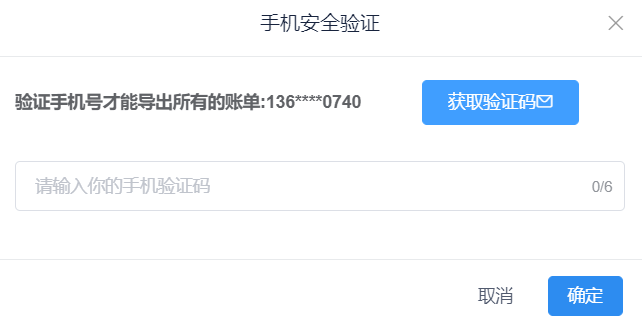
图5-31 用户手机验证
6.8 用户的博客中心
6.8.1 用户的访问主页
编写博客是一个展示自我的机会,通过这个机会,可以增强个人的表达能力,还会结识一些五湖四海的博友。通过他人文章的学习,我们还可以增强个人的知识度和眼界。综上所述,用户的博客中心是博客系统的最核心功能。
用户可以分享自己的博客动态,博客旨在分享自己所学所知给他人,或者解决他人的困难。博客中心包含发表博客,查看个人博客,删除博客,更新个人博客。非本人也可以观看他人的博客,也可以评论他人的博客,所以需要用到分页功能和轮滑加载功能配合前端展示不是私密的博客给他人观看。每个用户所看到的博客都是最新发的博客,可以与他人进行学习交流。每个发表者要尊重他人的知识劳动成果,切勿抄袭并且发表不适当的文章,做一名合格的博友。
当用户输入账号密码登录后,可以看到博客的主页如图5-32所示,主页面可以看到发表人和发表的文章,点击文章可以进入文章的主页面进行学习交流。
图5-32 博客主页
6.8.2 用户的文章中心
用户的文章微服务中心的功能包含发表,查看,修改,删除,用户可以控制自己发表过的每一篇文章。
个人的博客中心如图5-33所示:

图5-33 个人博客中心
关于文章的增删改会在后续标题中得到详解,在此只放出用户的个人文章中心由图可以看出是用户发表过的全部文章,后端利用的是先分页后List方式,最终传送前端进行ListItem遍历显示即可。
由于也使用了Elasticsearch把文章分类作为存储索引,但是重要的文章信息均放在数据库中,在此只提一下,到后续的分类搜索中会详细说明。
6.8.2 发表个人的博客
文章的的发布有许多选择,自己可以选择文章的分类和文章的标签,同样也可以设置文章的可见性。用户可以设置文章的标签,标签用来显示给游客看,用来文章的标识认证,还可以设置文章的分类,类型和保密性,每种文章的分类会发布到那个分类的专区。文章类型有三种,若是转载和翻译他人的文章需要著名地址,保护他人的知识劳动成果。只有具备会员资格才可以发送到会员专区,但是转载的文章不可以发送到会员专区,发表文章时可参考红字注意事项。
博客发表的页面如图5-34所示:
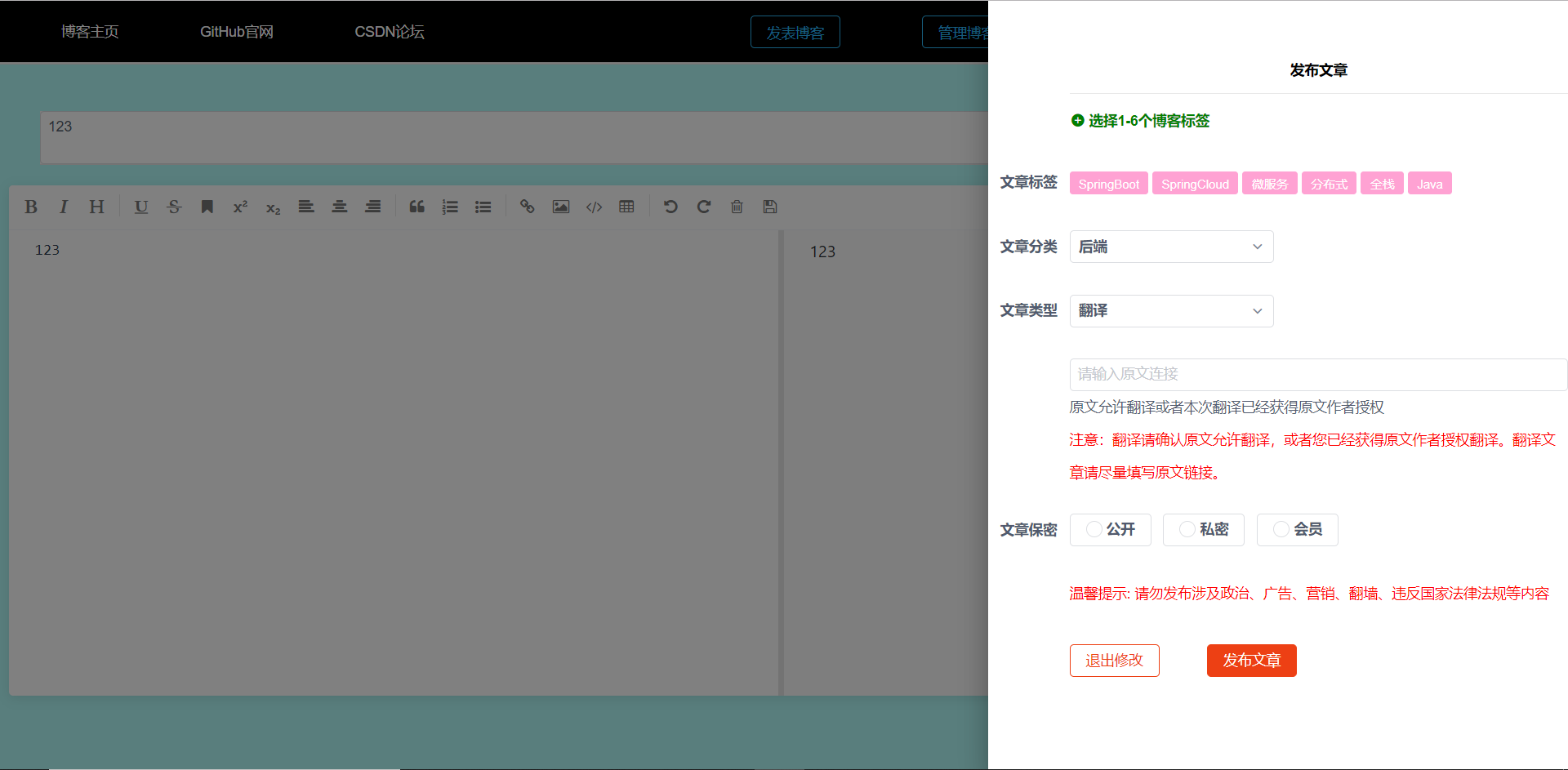
图5-34 确认发表文章
博客的发表的核心原代码如以下所示:
c++
//获取文章的摘要markdown格式-html-summary
String words = StringFromHtmlUtil.getString(MDTool.markdown2Html(blogFrontPublish.getArticleContent()));
//获取文章的摘要且摘要长度为255个字符
String summary = words.length() > 240 ? words.substring(0, 240) + "......" : words;
//去除转换后存在的空格
String tagTar = blogFrontPublish.getArticleTag().replaceAll(" ", "");
//将文章的分类写入分类表然后再插入整篇文章
UserArticleCategory userArticleCategory = userArticleCategoryMapper.findAllByCategoryName(blogFrontPublish.getArticleCategory());
if(userArticleCategory == null)
{
userArticleCategory = new UserArticleCategory();
userArticleCategory.setCategoryArticles("");
userArticleCategory.setCategoryName(blogFrontPublish.getArticleCategory()); //返回获取到的自增ID
userArticleCategoryMapper.insert(userArticleCategory);
}
//把标签写入数据库
for(String tag: tagTar.split(","))
{
if(tag.replaceAll(" ", "").length() == 0)
{
//单个标签只含空格
continue;
}
UserArticleTag userArticleTag = userArticleTagMapper.findAllByTagName(tag);
if(userArticleTag == null)
{
userArticleTag = new UserArticleTag();
userArticleTag.setTagName(tag);
userArticleTag.setTagArticles("");
userArticleTagMapper.insert(userArticleTag);
}
//转换后的值再更新得到文章表的主键 userArticleTag.setTagArticles(userArticleTag.getTagArticles()+userArticle.getId()+","); userArticle.setArticleTagsId(userArticle.getArticleTagsId()+userArticleTag.getId()+","); userArticleTagMapper.updateTagNameAndTagArticlesById(userArticleTag.getTagName(),userArticleTag.getTagArticles(),userArticleTag.getId());
}
6.8.2 修改个人的博客
若是需要修改个人的博客,需要进入图5-33的个人博客中心,查看发表的指定文章进入到指定文章的页面,点击编辑按钮,不是本人的文章不会出现编辑按钮,博客的编辑按钮效果图如图5-34所示:

图5-34 博客的编辑按钮
可以修改文章的所有的条件与内容,如图5-35所示:
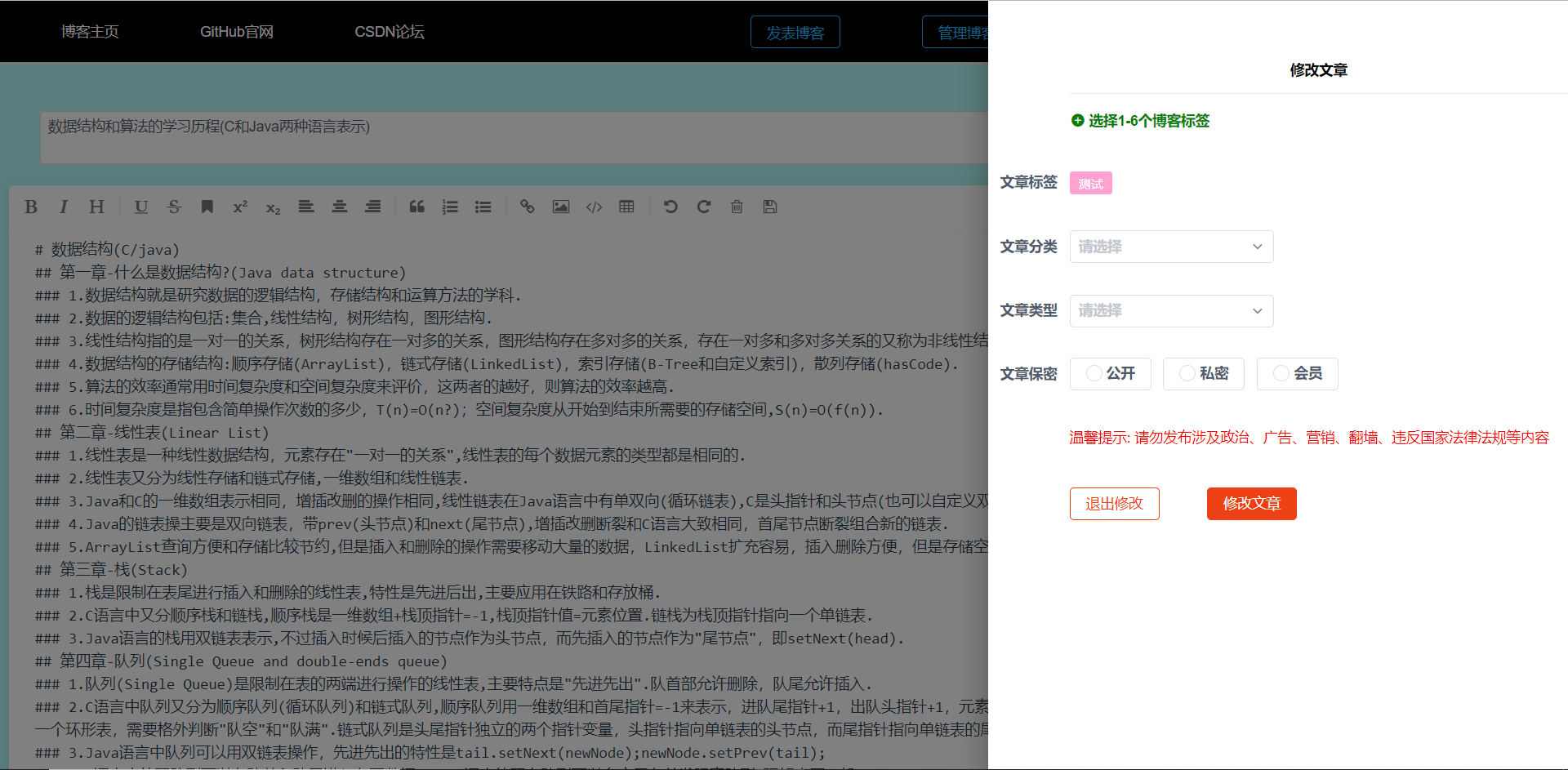
图5-35 修改个人博客
文章的发表与修改的源码不同在于要删除之前的原属文章的分类Id与标签Id的关联,再进入文章的插入,不过文章的修改也会触发在搜索引擎上的文章信息修改,搜索引擎上的文章信息也会跟着更新,保持搜索到最新的数据。
6.8.2 删除个人的博客
删除个人的博客需要删除数据库和搜索引擎上的文章,删除文章后不可恢复。
删除文章的原代码图5-36所示:

图5-36 删除个人的博客
6.8.3 用户的文章布局
完整博客的显示方式是采用GitHub的代码高亮布局,可以是用户看到自己的博客是嵌入式的面板,可以给予人一种清爽的感觉。由于采用Vue,可以不用动态渲染html,使用v-html命令就可以把后端传过来的数据利用showdown转换器转换给html直接显示给用户看。完整的用户观看的布局如图5-37所示:
图5-37 完整博客的显示
前端重要的核心代码如以下所示:
c++
import showdown from 'showdown'
import 'github-markdown-css/github-markdown.css'
let converter = new showdown.Converter();
//转换为HTML
let html = converter.makeHtml(res.data.articleAll[0].articleMdContent);
6.8.4 点赞用户的文章
互联网时代每个人都或许都点赞过他人分享的文章,本次设计是博客所以会涉及到点赞,当用户太多时需要考虑到高并发的情况。正常情况的点赞并不会给后端造成多大的负载压力,如果是热门的文章博客,用户点赞与取消点赞,评论,分享等,对于后端来说这些都会带来巨大的流量,如果后端接口支撑不住,前端得不到响应,前端无法响应就会返回404,会导致用户体验极差。可以利用2-7-1中的分布式中间件Reidsson来实现点赞的功能。
博客点赞的用例图如图5-38所示:
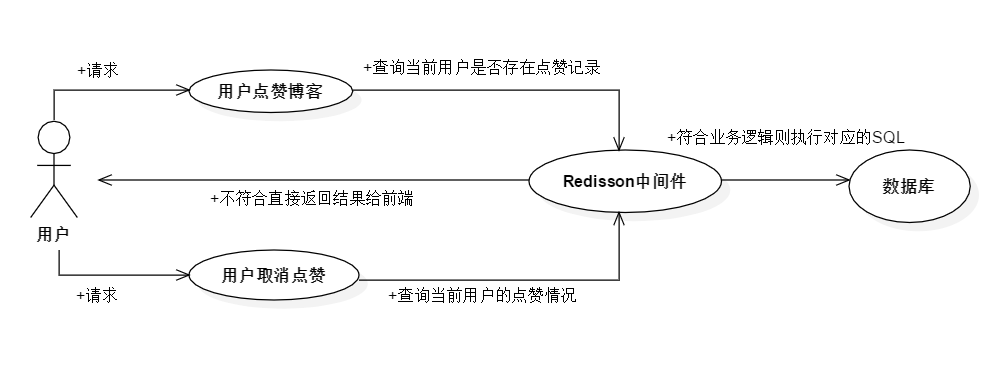
图5-38 点赞的用例图
由上图可知,核心的模块就是点赞与取消点赞,利用Redisson把多个用户的请求利用分布式锁分开请求,利用“缓存”保护数据库。若用户点赞微博,则后端会先查询是否存在点赞记录,当存在点赞记录时,分析是否是完成点赞还是已经取消了点赞。若没存在点赞记录,则完成数据库中的点赞记录更新,再把点赞结果“缓存”到Redis中,若是取消点赞,则直接会在“缓存”中删除,更新数据库中的结果。每一篇文章的点赞总数都是利用“缓存”计算得到一篇文章的结果发送给前端显示。前面的操作都是利用Redisson操作的,所以当高并发多线程请求时,分布式锁就会控制资源的并发访问,避免出现文章数据不一致的情况。
点赞与取消点赞的涉及分布式锁的重要源码如以下所示:
c++
//获取分布式锁实例(一次性锁对象)
RLock rLock=redissonClient.getLock(lockName);
//可重入锁的方式获取分布式锁(锁也可以设置消时时间)
Boolean suo=rLock.tryLock(100,10, TimeUnit.MINUTES);
Redisson分布式锁实现博客点赞与取消点赞的完整缓存图如图5-39所示:
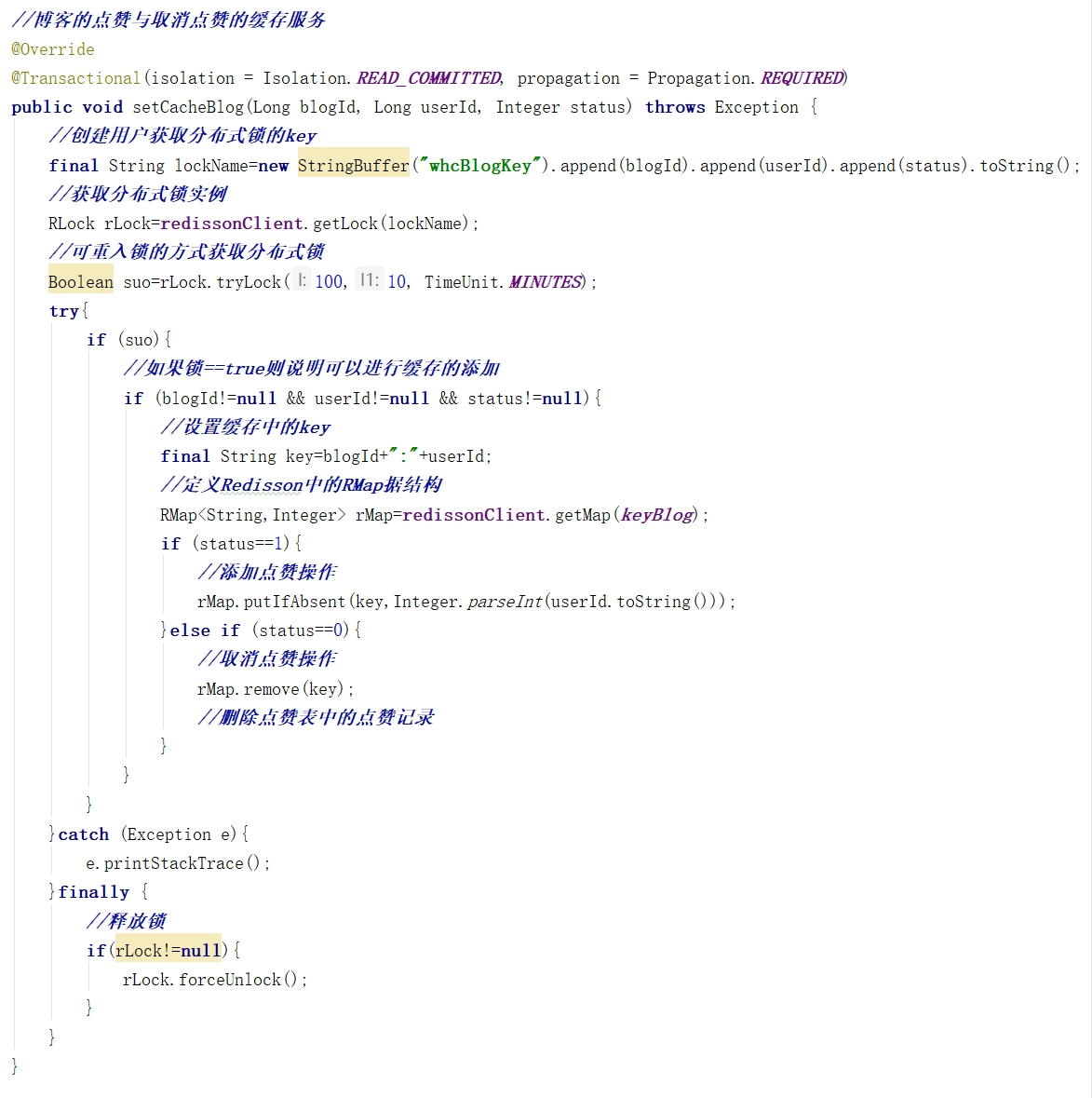
图5-39 Redisson点赞分布式锁
6.8.5 收藏用户的文章
用户允许收藏自己的文章,收藏的功能也借用了Redisson的分布锁来控制收藏的缓存,收藏与博客的点赞功能相似,可借助标题5-8-4中的点赞图5-38举一反三换成收藏即可。关于收藏功能合成的核心代码通信图如图5-40所示:
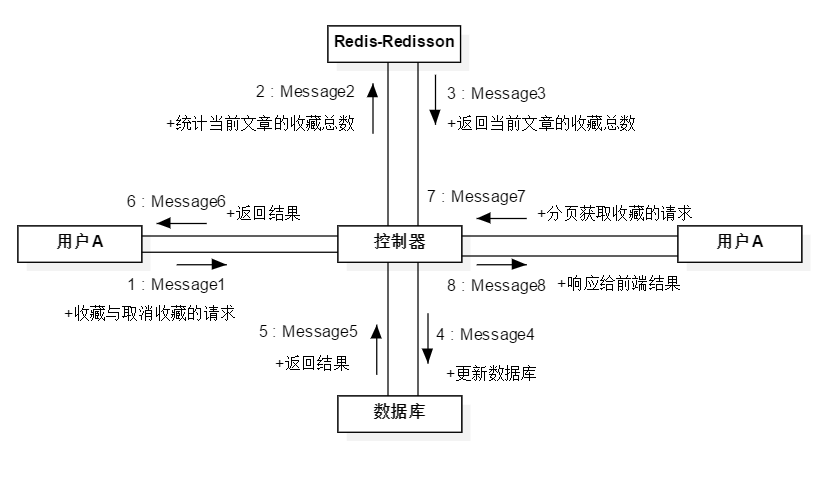
图5-40 收藏合成通信图
用户收藏中心的前端图如图5-41所示:
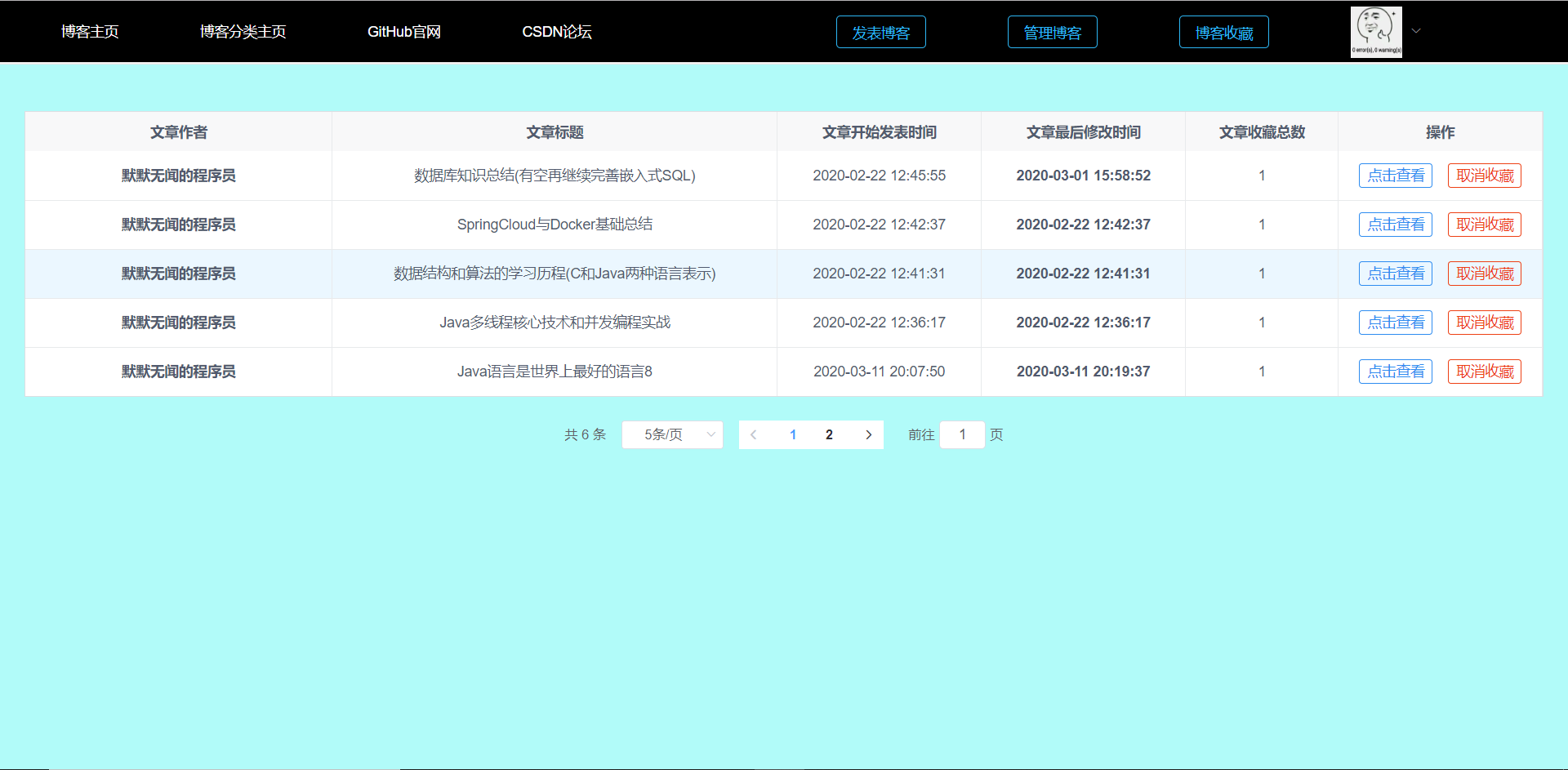
图5-41 用户的收藏中心
6.8.6 评论用户的文章
文章博客的评论区如图5-42所示:
图5-42评论区
评论的实现比较简单,一级评论的用户的Id为父Id,只含有一级评论与二级评论,分页直接查看文章的所有评论。Elment-ui组件分页的前端代码如以下所示:
```c++
```
6.8.7 博客的文章排行榜
文章排行榜采依旧是利用了Redisson,排行榜与标题3-7-4的点赞关联紧密,“点赞”会导致热流,形成短时间内的超高人气,把文章的排行榜放给用户看,可以增强用户的体验。不是所有的功能都要用分布式锁,排行榜不需要用到分布式锁,也不需要控制非常高的高并发流量,对于后端来说控制排行榜比较简单。
文章的排行榜运行原理如图5-43所示:
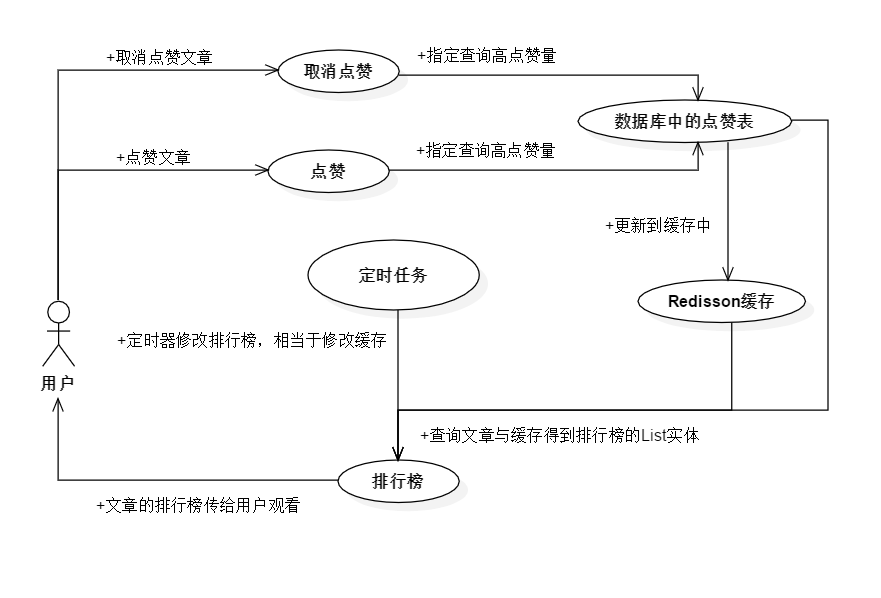
图5-43 文章排行榜运行原理
排行榜需要保证查询数据库的点赞表的SQL正确,SQL错误之后的所有操作都是白费力气,这个要设置一定的范围与时间差来确保文章的间断实时性,最后要把数据库中的数据放到缓存中。对于缓存的操作,用户的点赞与取消点赞都会触发缓存中的排行榜排序。用户请求后,会查到缓存中的排行榜点赞数最多的前10篇文章,利用List的文章Id找到文章的信息,最后打包传给前端显示。排行榜算是一种实时性要求不算很高的,可以使用定时的方式主动更新缓存中排行榜记录。
排行榜的Redisson的重要流程原代码如以下所示:
c++
//判断数据库中List的列表中是否有数据
if (list!=null && list.size()>0){
//获取Redisson的列表组件RList实例
RList<UserArticleRank> rList=redissonClient.getList(key);
//先清空缓存中的列表数据
rList.clear();
//将得到最新的排行榜更新至缓存中
rList.addAll(list);}
//获取Redisson的列表组件RList实例(从5开始不是一个代码块的)
RList<UserArticleRank> rList=redissonClient.getList(key);
//获取缓存中最新的排行榜
return rList.readAll();
博客排行榜的最终前端效果图如图5-44所示:
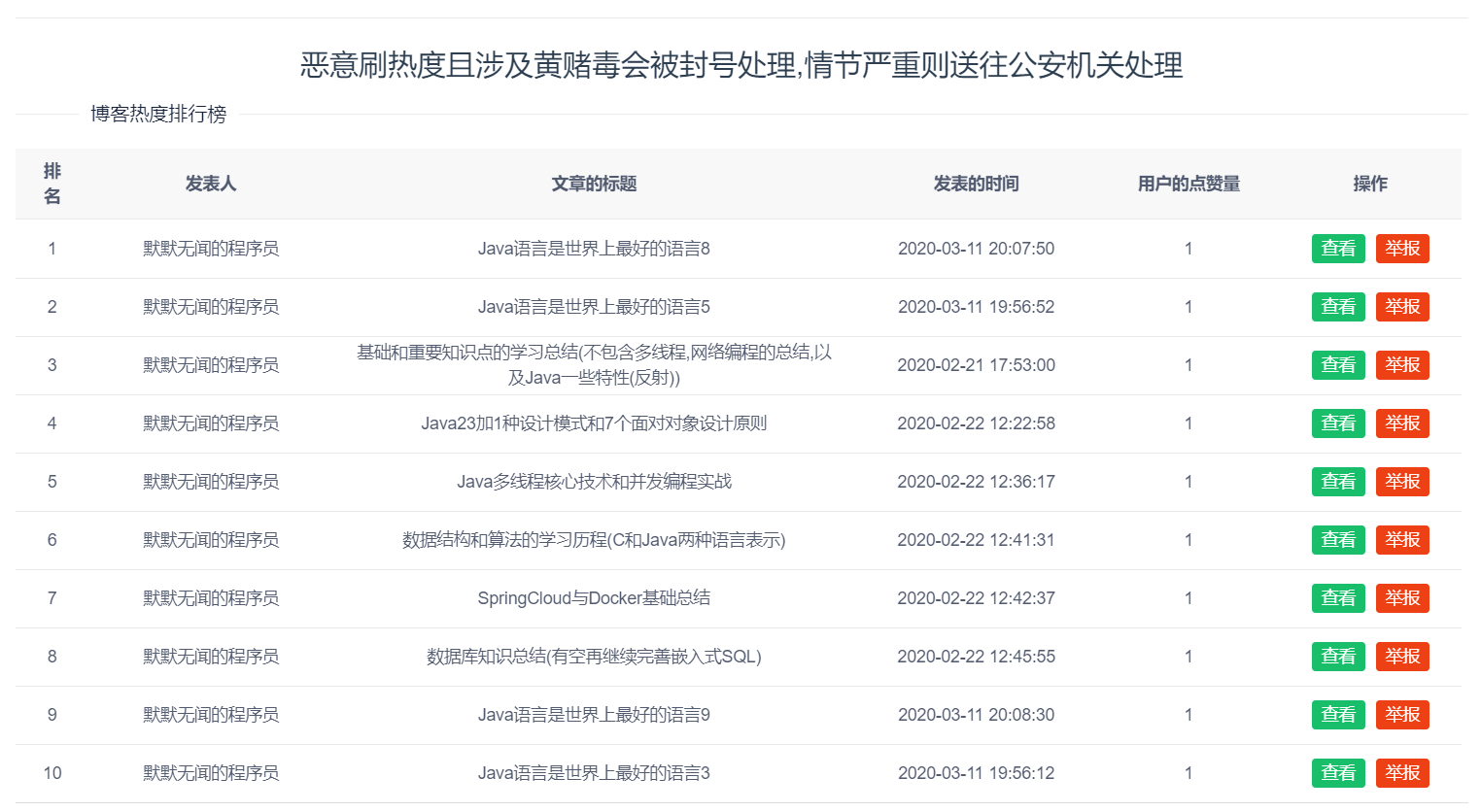
图5-44 博客的排行榜
6.9 博客的搜索中心
6.9.1 搜索引擎的应用
当微服务整合Zipkin时,运行系统会产生大量的API运行指标,而Elasticsearch(ES)作为一种存储方式,可以把那些运行API指标存储到ES中。
ES整合后一个微服务运行的API指标如图5-45所示:
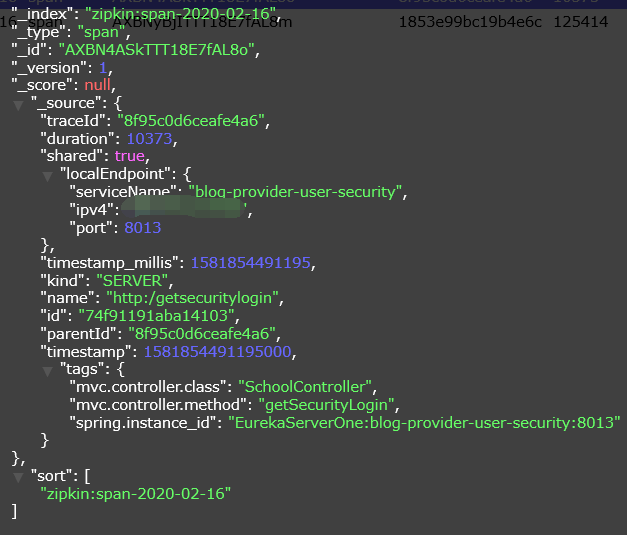
-
图5-45 ES整合Zpkin的API
-
图5-45中Elasticsearch的index是文档索引,与数据库的“库”相似,type是文档类型,与数据库中的“表”相似,id是一个字段作为主键。
-
图5-45可以与标题2-4-7中的图2-11结合观看,可以得出其实Zipkin就是从ES取出结果后可以做二次分析的跟踪组件。
Timestamp可使用@JsonFormat注解转换指定时间方式,当然也可以作为搜索时的排序,图中的sort就是排序的条件,使用ES远不止这些,博客使用的是Java客户端,操纵ES还有许多原始方式,在此不再累述,可自行查找。
6.9.2 博客的分类搜索
博客的搜索中心包含文章的显示的信息,例如标题和文章内容的摘要,由于把文章的整篇内容均放到数据库中,所以搜素引擎上的文章是负载均衡保存提示的信息,用户可以根据搜索界面的搜索框查询Elasticsearch上文章,根据的是文章的分类的区域和关键字,后端判关键字是否符合且存在,然后把结果传给前端显示。
博客首页的外搜索页面如图5-46所示:
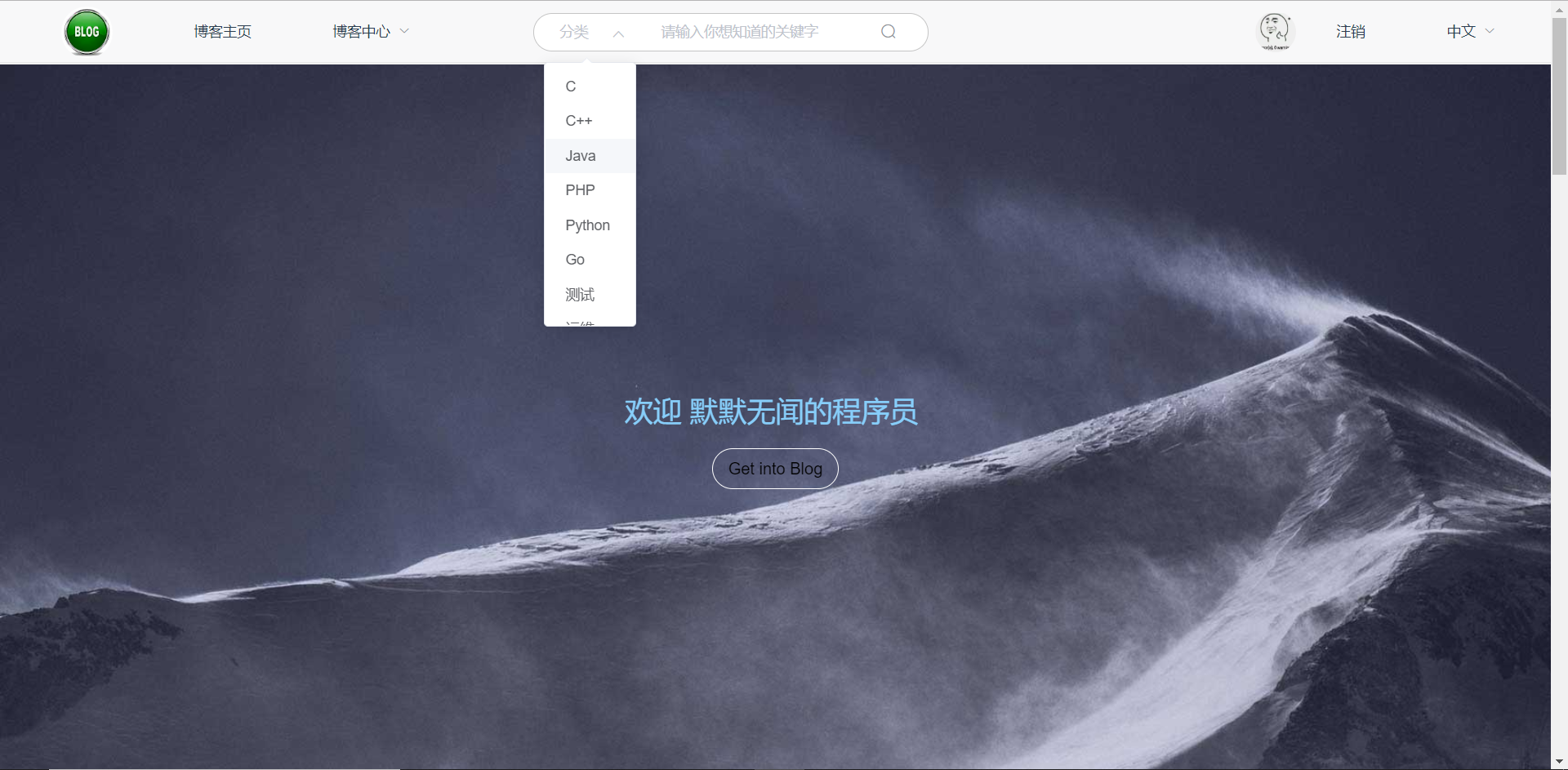
图5-46 博客首页搜素
Elasticsearch上的创建过的文章索引(index)图如图5-47所示:
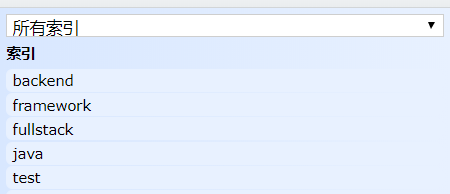
图5-47索引图
根据文章的关键字搜索结果图如以下图5-48所示:
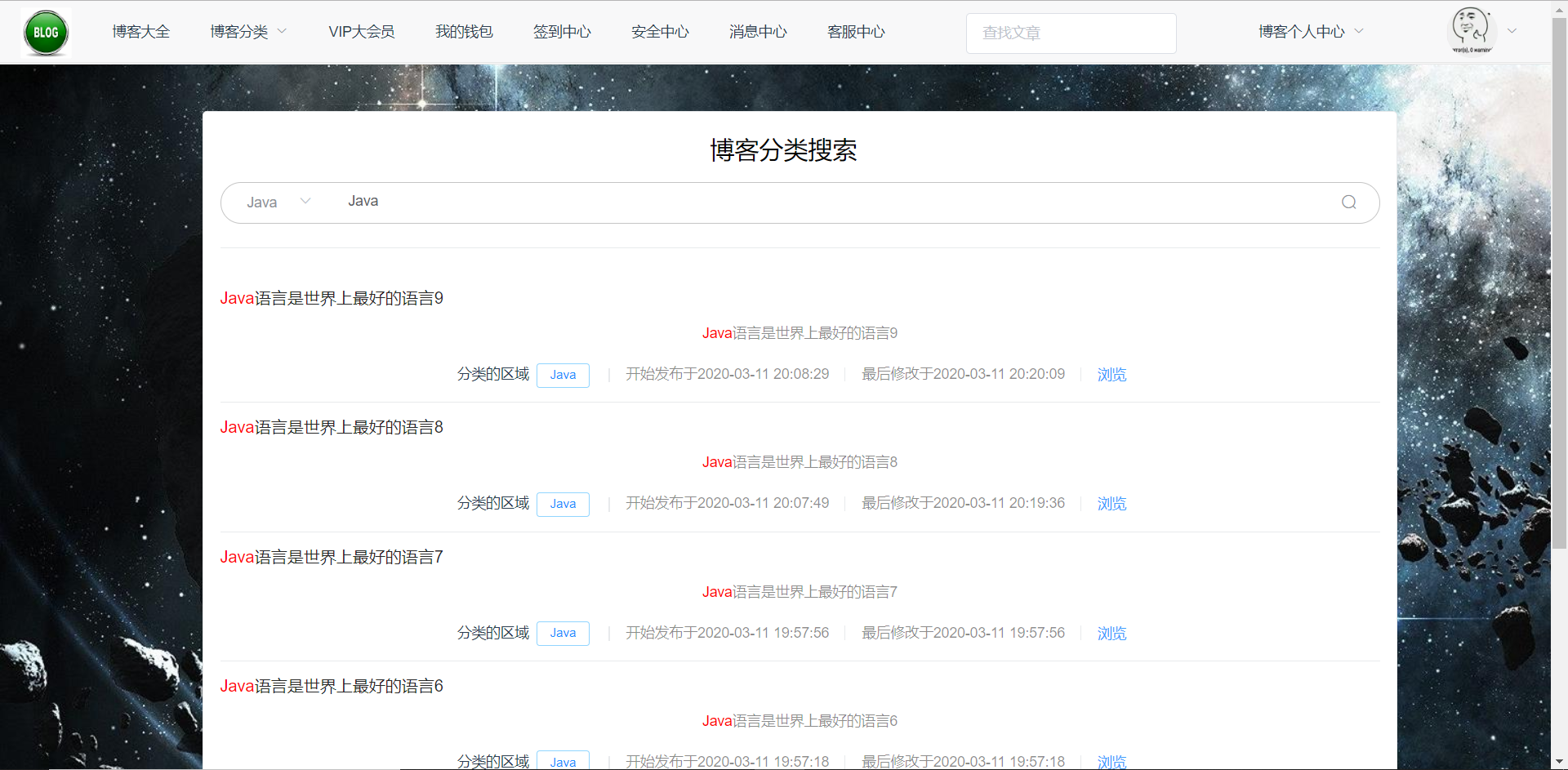
图5-48分类搜索的界面
主页搜索的前端resolve核心代码如以下所示:
c++
// 利用resolve函数实现新窗口打开的搜索页面
let routeUrl = this.$router.resolve({
//路由控制url和Query传关键字
name: "ArticleSearch",
query: {
categoryName: this.categoryName,
keyWord: this.esInput,
}
});
//打开新的搜索页面
window.open(routeUrl.href, '_blank');
博客分类搜索后端的关键字采用高亮且使用红色字体显示关键字,以博客发表的时间作为降序排序,分离ES中的结果集传给前端显示即可。由于后端的代码繁琐且麻烦,在此只说明后端具体流程。
6.9.3 博客的分类主页
博客的分类主页是利用Elasticsearch上的文章信息进行遍历,用户发表的博客时候选择的分类作为Elasticsearch索引的名负载均衡到Elasticsearch,分类中心的文章每次选择20篇最新的文章传给给用户观看,分类主页如图5-49所示:
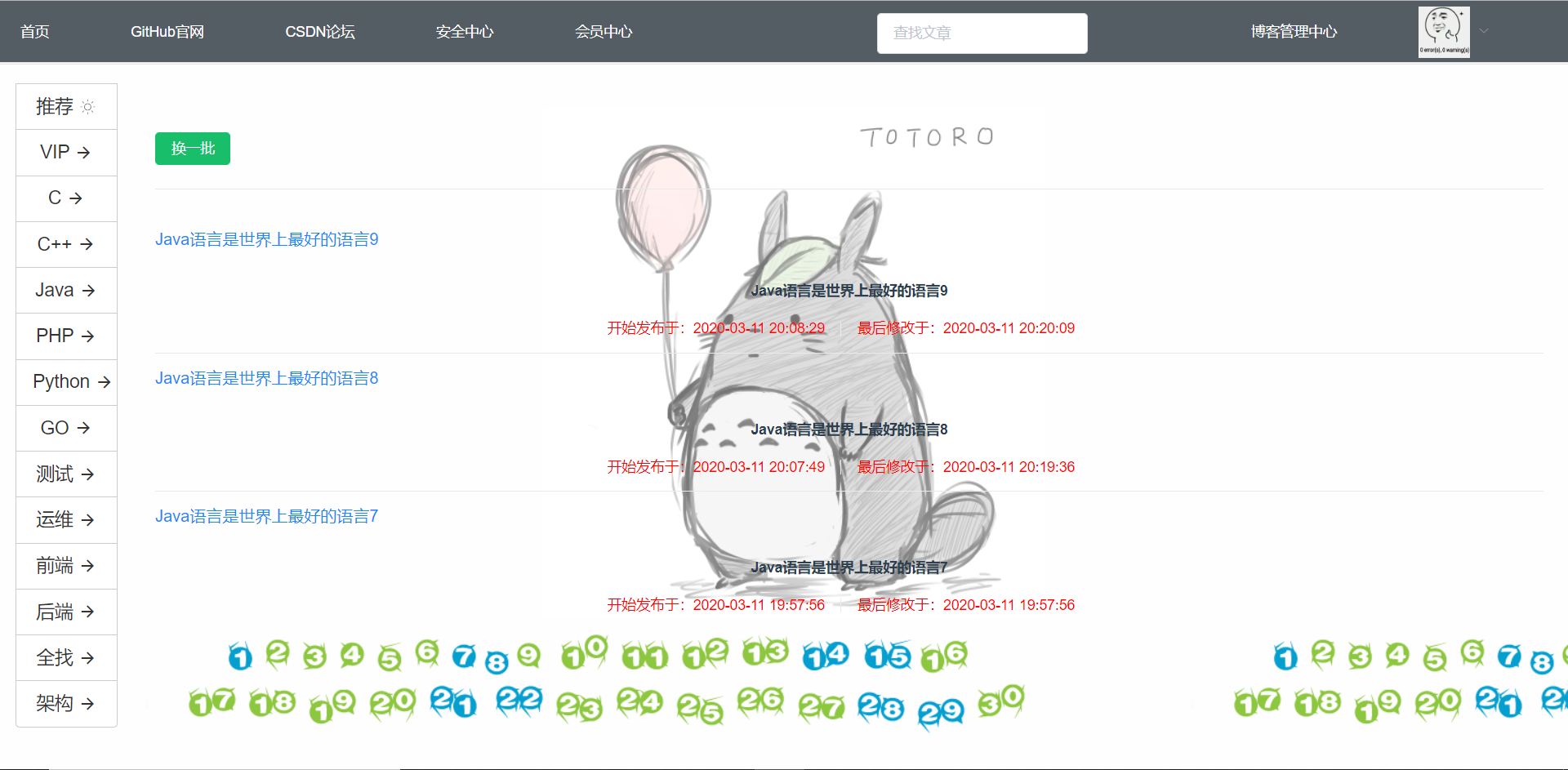
图5-49分类的主页
由于未使用Elasticsearch分页插件,使用原生的API查询,所以需要借助json包来转换List给前端遍历,博客后端分类搜索的结果转成List如图5-50所示:

图5-50处理结果集
6.10 本章总结
本章的8个微服务中心全已实现,后续标题会详解对博客的测试做出分析,还会对博客代码设计阶段时遇到的“BUG”和不可预防的错误给出解决方案。
七、博客的测试分析
7.1 博客的请求抗压性分析
博客采用的是前后端的分离模式,所以对于前端传过来的Token,后端只要鉴定Redis中存在Token即放行API的请求,同时前端可以防止表单的多次提交,前端可以增加JS监听Button的提交,也可以使用session鉴定请求的时间间隔。不过博客大多采用Axios的异步提交,http成功时可以把Button设置为true或者直接局部刷新网页重置数据。对于博客中的支付中心,另起线程中需要防止出现业务出现错误,或者网络错误导致负载均衡出现中断错误,所以需要catch防止程序出现错误,同样还必须保存支付宝异步通知的结果防止另起线程中出现异常。对于每个用户的请求,可以采用服务器的限制流量,限制的方向可由个人选择,需要在服务器的图形化界面中可以设置,服务器中的流量控制如6-1所示:
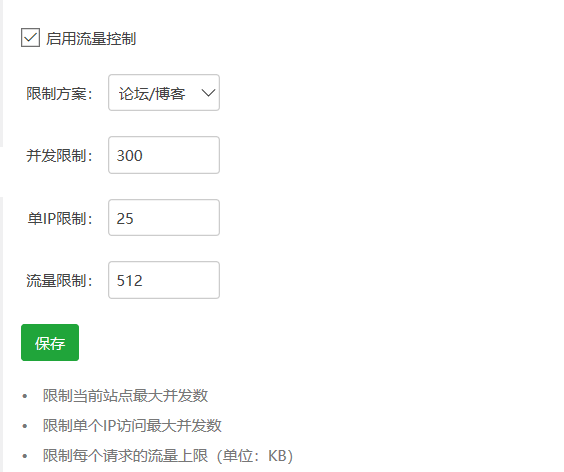
图6-1 博客的流量控制
7.2 博客的功能扩展性分析
博客的前端容易扩展,由于Vue本身具有的实用的数据绑定优势,所以前端只要时间充足就可以随意扩展,还有一个很重要的原因是安全是后端来控制的。博客后端的每一个微服务的中心承担着一个功能模块,若是发生不同功能的扩充则需要多添加一个微服务的中心。当功能相同只是扩展当前的功能,则可以直接在某个微服务中心增加代码即可。编写博客时遵守了Java代码的规范,为以后的扩充打下坚实的基础。本次博客各个中心均遵守了Java的代码规范,微服务中的module划分清晰,功能扩充方便。Pom文件中的module划分如图6-2所示:
图6-2 pom中的module
八、博客的注意事项
8.1 博客整合Hystrix后首次请求失败问题
博客中Feign、Zuul组件整合Hystrix后,会出现首次API传导失败。由于Hystrix的默认响应时间是1S,首次会导致用户的API请求得不到响应。最优的解决方案是为Ribbon客户端负载均衡开启饥饿加载,保证首次经过的微服务一定可以执行。
对于zuul开启Ribbon配置饥饿加载的原代码如以下所示:
c++
ribbon:
eager-load:
enabled: true
clients: 虚拟主机名(spring.application.name)多的话可以逗号分开。
8.2 SpringCloud中Turbine 1.X版本BUG
错误出现在spring-cloud-turbine-stream 包中,因为这个包会启动一个netty-port容器,并将它的server.port 设置为-1 ,从而关闭了Servlet容器,这是官方包的一个Bug,不过Spring Boot 2.0已修复,要么升级包要么按照以下配置:
```python //若不升级包则可以按照以下的方式解决无法注册Turbine的问题 server: port: 8070 instance: prefer-ip-address: true
务必跟server.port的配置保持一致
non-secure-port: 8070 ```
这样的话会使server.port=-1,但是可以是Turbine注册到微服务中心上。若要是想要修改显示,可以自定义微服务的hostname。
不建议升到最新版本的包,因为Springboot与SpringCloud有一定的关联,除了这些,还有用到其它的包,等微服务熟练了就可以尝试更换包的版本。
8.3 关于前后分离的CORS跨域问题
8.3.1 前后端分离的跨域
由于采用前后端分离的方式开发博客,则需要考虑前端跨域问题。对于跨域正确来说就是只要协议,端口,域名的任何一个出现不同,就存在跨域的问题。
拿本次博客来说,前端API路径重写,使用/API的方式把请求传递到Zuul网关接口上,同时后端再开启CrossOrigin注解,可以全局配置后端接受也可以单独配置某个类。此种方式适合学习,而实战可以采用nginx请求与分发,把请求分发到指定的server上。前端路径重写代码如以下所示:
c++
'/whc': {
//使用"/api"来代替原端口请求网关端口
//target: 'http://127.0.0.1:8088', //前端源地址
target: 'http://127.0.0.1:8050', //网关源地址
changeOrigin: true, //改变源
pathRewrite: {
'^/whc': '' //路径重写
}}
后端的CORS需要开启CrossOrigin注解,也可以自定义配置跨域参数或者全局配置,后端可以按照以下简单的注解来配置后端跨域:
c++
@CrossOrigin(origins = "http://localhost:8088")
8.3.2 Nginx反向代理
线上情况需要用到Nginx,Nginx反向代理就是把博客的前端端口和后端的端口请求转发到同一个地址下。需要打开Nginx文件下下面的nginx.conf进行修改,修改的原代码如以下所示:
```c++ listen 8088; server_name localhost;
= /表示精确匹配路径为/的url,真实访问为http://localhost:8050
可以指定导在后端的高可用Zuul路由上任何一个
location = / { proxy_pass http://localhost:8050; }
/one 表示以/one开头的url,非精确匹配
真实访问为http://localhost:8050/one开头的url
location /one { proxy_pass http://localhost:8051; }
/two/表示精确匹配以two开头的url
location /two/ { proxy_pass http://localhost:8052; } ```
上面代码是将localhost:8088转发为location:8050,相当于现在访问localhost:8088实际上是访问location:8050,而访问localhost:8051/one则是访问localhost:8088,并以one开头的url, 而访问localhost:8052/two则是访问localhost:8088,并以two开头的精确的url。这并不是博客的Nginx的完整配置,只是用来解释Nginx的使用方式,个人可以自行按照这种方式进行Nginx的配置。
九、结束语
这次的毕业设计,不仅让我在Java和JavaScript方面有了巨大的提升,而且让我养成了遇难而上的品质。在确定了毕业设计的导师和题目之后,通过不同的途径,阅读有关微服务的文献,了解分布式系统的设计,再结合自己之前学习Java开发的基础,对博客的开发有了想法,所以选择了这个题目。
通过半年时间的奋战,我终于完成了毕业设计的博客。博客的实现参杂着许多困难和挫折,但我都一一克服。从我开始着手毕业设计后,我遇到了不少代码的问题,每一次看到学习文档和别人的解决方案时我都想要放弃,可是由于毕业设计的重要性以及自己的开源目标,只能顶着压力学习和测试。每一次解决问题后的成就感都增加了我以后面对问题时不再逃避的勇气。在博客的代码阶段,我逐渐弥补了前端的薄弱能力,现在的我可以游刃有余的进行Web全栈开发。通过这次的毕业设计让我的学识和对自己的认知都有所提高,对我以后的工作会有许多积极的影响。但我依旧会保持谦虚的态度,对于每一个问题和困难都会虚心求教,对于每一个有需要帮助的人我都会乐于奉献帮助他人解决问题。
这次的毕业设计完成比较艰难,在过程中也解决了很多难题,还存在一些不是非常完美的代码。在这次设计之前我对中间件的使用并不是非常熟练,完成时每个中间件在微服务中心都有了它的存在,这对于我的个人信心有了非常大的提升。由于时间和自己能力的问题,功能也有很多不完善的地方,但是对于功能的扩充非常友好,随着时间的发展,我会从应届生进入社会,但是我会抽出一些空闲的时间用来一步步优化我写过的代码,并且扩充微服务中一些次要功能,完成从一名应届生到合格的程序员的蜕变,在社会中实现自己的人生价值。
十、致 谢
首先向我的毕业设计指导老师表示由衷地感谢,从毕业论文选题,毕业设计和毕业论文期间,指导老师在毕业设计的思路和毕业论文上的写作给了我耐心的指导。在指导老师的精心协助下,使得我的论文可以顺利的完成。
感谢我的辅导员老师,她在这四年中对我学习上和生活上的帮助,她对我的帮助无微不至,在此由衷地感谢高园园老师的付出。
在信息管理与信息系统专业的中,首先要非常感谢我们的班长同学,他是一名合格的班长,对我们有求必答,对于困难的同学会及时伸出援助之手。很高兴可以认识班里每一个同学,也非常感谢每一个同学在班里的付出才有了我们这个团结的大家庭,班散人不散,情谊永在。
在大学的四年中认识了不少朋友和室友,他们是我人生中的见证人,也是我学习的榜样,对他们表示由衷的感谢。
在毕业设计的完成过程中,查找和测试了许多别人的代码解决方案,这给我的毕业设计提供了巨大的帮助。除了之外网上还有许多热心的“老师”分享自己的经验和想法,对于我的想法提出了修正,我也非常感谢那些在我毕业设计的代码阶段给予了我的帮助,可能是一句话过来人的话,也可能是一段精炼的代码,但他们的帮助都让我豁然开朗。每一个程序员都是热心肠,每个人都不平凡。
大学四年的学习时光就要结束了,我收获了知识也收获了友情,人生的一个阶段的结束就会代表着另一个阶段的开始,从应届生走去社会,是人生的一种彻底蜕变,再无“学生”的昵称,再也不会有老师的叮嘱,各自为战,努力拼搏。我一定会成为一名合格的程序员,对于有学习困难的人伸出援助之手,乐于奉献自己的代码,最终成为一名无私的社会建造者。
十一、参考文献
陈国君.Java程序设计基础第五版,清华大学出版社出版,2015
杨开振.JavaEE互联网轻量级整合开发(SpringMVC+Spring+Mybatis+redis).
电子工业出版社,2017.7
王松.Spring Boot+ Vue全栈开发实战,清华大学出版社,2019.6
周立.Spring Cloud与Docker(第二版)微服务架构实战,电子工业出版社,2018.7
梁颍.Vue.js实战,清华大学出版社,2018.12
刘伟.Java设计模式,清华大学出版社,2019.5
美]Baron Scbwartz.高性能Mysql,[译]宁海元,电子工业出版社,2013.5
百度阅读.胡杨的在线著作,Vue+Bootstarp+View-UI+element-UI的学习文档
钟林森.分布式中间件技术实战(Java版),机械工业出版社,2020.1
美]Matthew Lee Hinman.Elasticsearch实战,[译]黄申,人民邮电出版社,2019.10
方志朋.深入理解Spring Cloud与微服务构建,人民邮电出版社,2018
杨冠宝.阿里巴巴Java开发手册,电子工业出版社,2018.1
胡荷芬.吴邵兴.UML系统建模基础教程,清华大学出版社,2016.7
美]Brian Goetz.Java并发编程实战.[译]童兰云,机械工业出版社,2012.2
美]Nicholas C.Zakas.JavaScript高级程序设计.[译]曹力,人民邮电出版社,2012.3
美]Mark Allen Weiss.数据结构与算法分析(Java).[译]陈越,机械工业出版社,2016.2
朱忠华.RabbitMq实战指南,电子工业出版社,2017.11
小马哥.Spring Boot 编程思想(核心篇),电子工业出版社,2019.3
高洪岩.Java多线程编程核心技术,机械工业出版社,2019.1
方鹏飞.魏鹏.程晓明.Java并发编程的艺术,机械工业出版社,2015.7
参考文献
- 基于EPP的域名管理系统(山东大学·孟庆领)
- 博客管理系统的设计与实现(吉林大学·赵岩)
- 基于Struts架构的校园微博系统的设计与实现(东北大学·刘鑫)
- 基于SSH2的轻博客系统的研究与实现(吉林大学·杨雪梅)
- 基于Web应用的Spring框架的分析与研究(西安建筑科技大学·吴桂兰)
- 基于SSH2的轻博客系统的研究与实现(吉林大学·杨雪梅)
- 基于用户评价的技术博客小程序设计与开发(华东理工大学·徐小武)
- 基于SSH2的轻博客系统的研究与实现(吉林大学·杨雪梅)
- 基于SSH框架的企业内博客系统的设计与实现(山东大学·柳青)
- 基于Spring Boot的校园轻博客系统的设计与实现(华中科技大学·邓笑)
- 基于Java EE的个人博客管理系统的设计和实现(内蒙古大学·闫伟光)
- 基于SSH架构的个人空间交友网站的设计与实现(北京邮电大学·隋昕航)
- 博客管理系统的设计与实现(吉林大学·赵岩)
- 基于SSH框架模式的博客系统的设计与实现(西北师范大学·王刚成)
- 基于SSH框架模式的博客系统的设计与实现(西北师范大学·王刚成)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码工厂 ,原文地址:https://m.bishedaima.com/yuanma/36189.html