
基于python实现的Bilibili弹幕检索系统
一、概述
首先是完成信息分析与设计的作业,该作业需要完成一个检索系统。
我完成的是一个弹幕检索系统,而对于一个检索系统而言,首先是对于数据的获取,这部分通常使用爬虫进行抓取,事实上,如果Bilibili能够提供更好的api,显然是更容易的,但是还是习惯于传统的爬取工作,因此本项目是B站的爬虫系统。
二、前言
由于B站视频数量比较多,涉及的范围也比较广,不同的视频类型之间有不同是弹幕风格。
为了进一步的细化题目,并且分析自己相对比较了解的部分。本文主要抓取了 snh48-黄婷婷 相关,可能会进一步的包括SNH48 TEAM NII的部分。

由于整个项目是大学四年的一次大作业,我相对比较重视,因此,整个系统的设计和系统的一些完成工作是十分重要的。
三、爬虫部分
3.1 检索字段
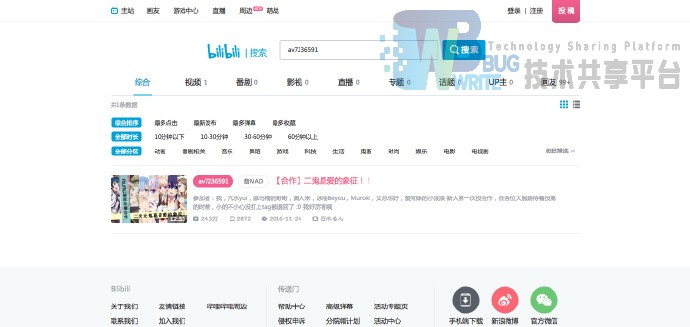
http://search.bilibili.com/
Bilibili的检索关键词字段包括
```html
```
由此可以看出,如果检索字段包括多个部分,如综合,视频等,可以检索不同的字段。因此除了综合检索外,为了检索的完全性,我还使用了专题和话题集合的方式进行抓取。
例如:
http://www.bilibili.com/sp/%E9%BB%84%E5%A9%B7%E5%A9%B7
其包含了视频中包含TAG的href,然后将这个href放到需要抓取的url表中:
SQL
INSERT IGNORE INTO need_crawl_url(aid,url,create_time) SELECT aid,video_url,crawler_time FROM query_table;
然后
python run_spider.py
便能够实现第一轮抓取,进一步的将人工筛选的query_tag进行query进一步得到query_table的数据,然后再将query_table放到need_crawl_url的表中,再启动爬虫,从need_crawl_url中抓取。可以循环进行,但是在本次项目中,最后的部分,应该包括如下:
-
sp :黄婷婷
-
query_word :黄婷婷
-
query_word :人工筛选其他的表达黄婷婷的单词
进一步的我为了补充一些多一点的数据,抓了一些"snh48"和"李艺彤"tags的数据和其检索结果的数据。
事实上,可以关于SP,在bilibili的sitemap里有大量的涉及。将其抽取出来可以发现。
http://www.bilibili.com/sitemap/sp.xml
其涉及了大概3072个sp,我大概看了一下,确实和SNH48相关的不多,也就包括SNH48-汤敏、SNH48、SNH48-赵嘉敏、SNHELLO、黄婷婷、李艺彤。(2016年11月24日数据)
3.2 视频数据
事实上,开始的抓取的部分是没有视频的元数据的,而只有UCG的数据。这对于项目而言有巨大的打击。
因此我需要包含我抓取的视频的元数据的信息,这个部分是需要进行解析地址的。
而我参看了 哔哩哔哩真实视频地址解析-初探 和 you-get 的bilibili部分,使用了其包含的APPKEY和编码方法。
大体上获取了元数据的信息(PS:由于视频太多太大,遂放弃了把视频保存下来的想法,内存还是要钱的=_=)。timelength是该元素最重要的信息,是以0.001s为单位的时间信息。
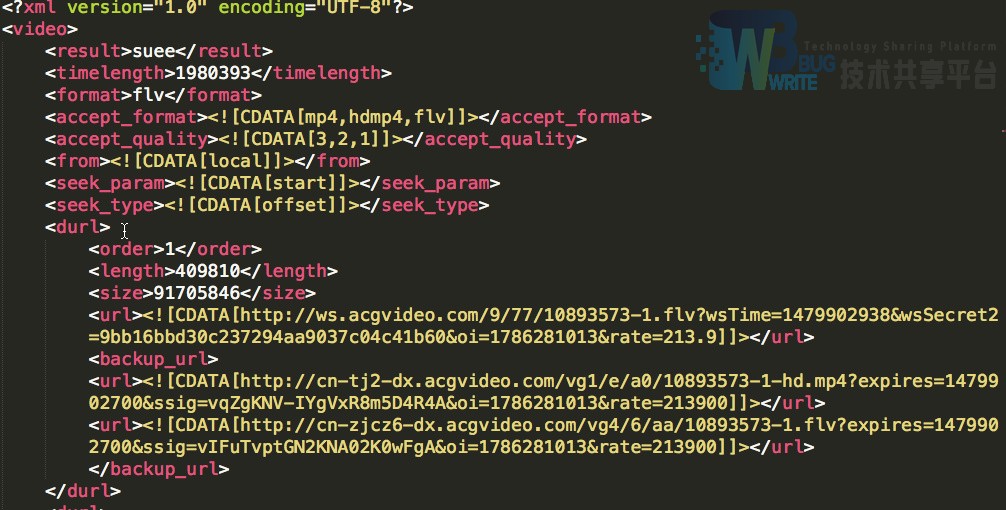
3.3 爬虫思路
写一个获取要抓取的url列表,放在数据库中。
scrapy爬虫从数据库中读取需要抓取的url,并且将这个url放到start_urls列表中,开始抓取。
定期轮训数据库,然后得到需要抓取的url,保持抓取。
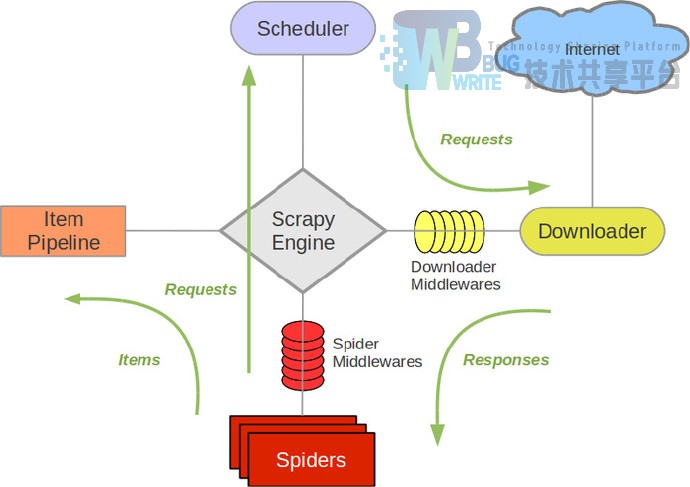
3.4 爬虫框架
本次爬虫的部分的框架Scrapy图为:
而在我的具体的实现的过程中。
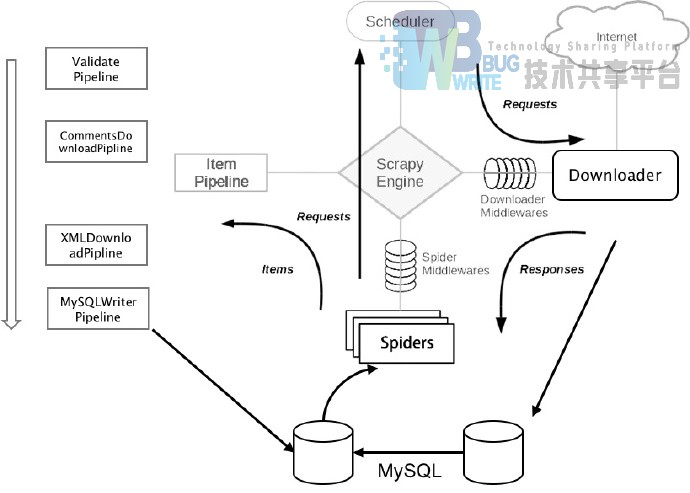
3.5 url列表的获取办法
-
query
-
基于up主
-
基于排行榜
-
其他
3.6 数据库结构
```SQL create database XFS_DB charset=utf8;
create table query_table( aid int primary key, query_word char(100) not null, page_num int, video_url varchar(1000), crawler_time int, video_matrix varchar(10000) ) charset=utf8;
create table need_crawl_url( aid int primary key, url varchar(1000), create_time int, finished_time int default 0 )charset=utf8; ```
四、数据分析
首先需要对于xml文件进行一定程度的解读:
```
在上述的例子中,根据相关网站 弹幕信息 。
-
第一项是弹幕所在时间,单位为秒
-
第二项是弹幕类型,其中:
- 1~3 为滚动弹幕
- 4 为底端弹幕
- 5 为顶端弹幕
- 6 为逆向弹幕
- 7 为精确弹幕
-
8 为高级弹幕。
-
第三项是弹幕字体大小,其中 25 为中,18 为小
-
第四项是弹幕颜色,格式是十进制的 RGB 颜色
-
第五项是弹幕的发送时间,使用的是 Unix 时间戳
-
第六项是弹幕池,其中 0 为普通弹幕,1 为字幕弹幕,2 为特殊弹幕
-
第七项是发送者的 ID 的 CRC32b 加密,可以用来屏蔽发送者
-
第八项是弹幕在数据库的 ID ,可能是用于历史弹幕
有上面的解析,可以看出,讨论分析的部分包括:弹幕随着视频出现的时间的分布情况,弹幕类型的占比情况,颜色,发送的时间相比视频的上传时间等分析。
4.1 统计信息
sql
select aid,count(*),startDate,author,view,danmaku,reply,favorite,coin,share from video_info group by aid into outfile "f:\\data.txt" FIELDS TERMINATED BY ',';
使用sql语句导出必要的数据统计文件,进行SPSS和python数据分析包pandas的分析。大体上回答了以下的问题:
-
有多少个视频,视频的时间的长度?
-
这些视频的子视频划分情况?
-
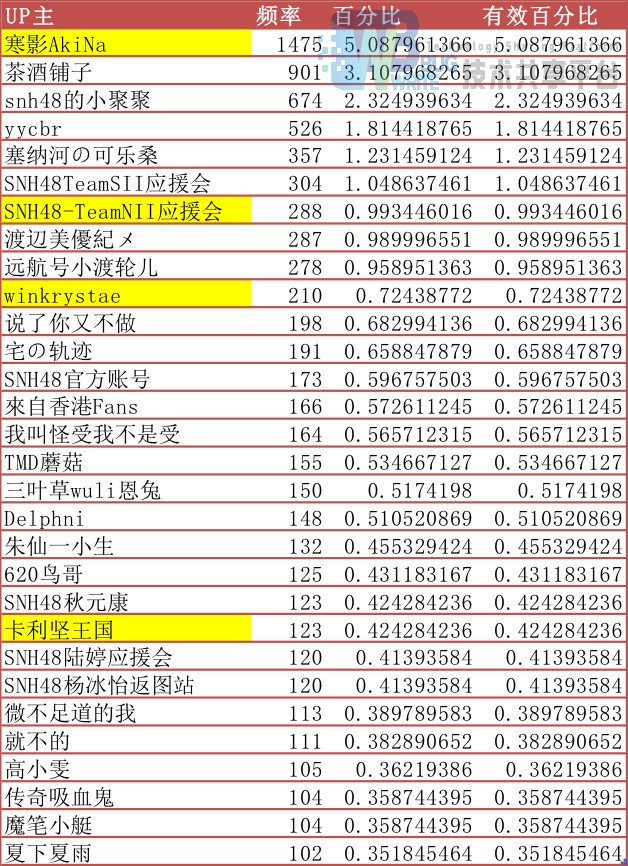
这些视频的UP主的信息是怎么样的?
- 大部分的UP主都是少量UP视频,明星up主列表如下(黄色是我关注的=_=):
- 这些视频的view、danmaku、reply、favorite、coin、share的情况是怎么样的分布?是否有相关性?
-
长尾分布,这个和互联网本身的特点非常相关
-
up时间?
弹幕的分布情况,类型,颜色。
其他的扩展:
-
弹幕的文本分析,朴素贝叶斯分类器
-
弹幕文本情感识别 (需要相关语料信息)
-
暂时未完成
4.2 可视化
可视化系统除了必要的数据的展示外,重要的是数据的过滤,这个过程是非常重要的。
The main goal of data visualization is its ability to visualize data, communicating information clearly and effectivelty. It doesn’t mean that data visualization needs to look boring to be functional or extremely sophisticated to look beautiful. To convey ideas effectively, both aesthetic form and functionality need to go hand in hand, providing insights into a rather sparse and complex data set by communicating its key-aspects in a more intuitive way. Yet designers often tend to discard the balance between design and function, creating gorgeous data visualizations which fail to serve its main purpose — communicate information.
确实,对于可视化系统而言,炫不是重要的,但是丑也不是必然的。是相对讨论问题的,事实上,应该知道的是,数据可视化需要一个好的问题的切入,而我对于弹幕的切入,显然是这个视频的弹幕分布是什么样子的,在哪里的弹幕是最多的?(也许是视频的高潮?也许是视频的重点?)这些弹幕有什么的特点?等等。
而在本项目中,设计的Column很多都可以作为可视化的项目,可以认为其是高维数据。因此本项目舍弃了D3作为可视化的工具,转而使用了 DC.js 作为可视化的框架。此外,前段的展示本项目使用了Bootstrap进行定制,事实上SASS对于前段我个人认为是革命性的,大量的重复劳动可以被组件化后减少,这也是当前前端发展的重要特点。为了保持项目主题的特点,本项目移植了许多的B站本身的元素。
4.3 机器学习
暂时没有,没有人标记数据校验。
想法包括弹幕分类(过滤无意义的弹幕),弹幕情感识别(爆炸黑子),弹幕自动生成(刷视频的人气 2333),有时间会尝试做一个。
五、检索系统
5.1 索引字段
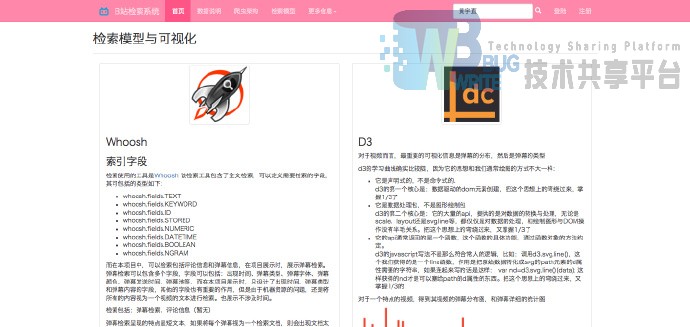
检索使用的工具是 Whoosh
该检索工具包含了全文检索,可以定义需要检索的字段,其可包括的类型如下:
-
whoosh.fields.TEXT
-
whoosh.fields.KEYWORD
-
whoosh.fields.ID
-
whoosh.fields.STORED
-
whoosh.fields.NUMERIC
-
whoosh.fields.DATETIME
-
whoosh.fields.BOOLEAN
-
whoosh.fields.NGRAM
而在本项目中,可以检索包括评论信息和弹幕信息,在项目展示时,展示弹幕检索。
弹幕检索可以包含多个字段,字段可以包括:出现时间、弹幕类型、弹幕字体、弹幕颜色、弹幕发送时间、弹幕池等,而在本项目展示时,只设计了出现时间、弹幕类型和弹幕内容的字段,其他的字段也有重要的作用,但是由于机器资源的问题,还是将所有的内容视为一个视频的文本进行检索。也展示不涉及时间。
检索包括:弹幕检索、评论信息(暂无)
弹幕检索呈现的特点是短文本,如果将每个弹幕视为一个检索文档,则会出现文档太多,词项分布将会异常稀疏,因此本项目在该弹幕检索系统的考虑上, 将一个视频的所有的弹幕视为该视频弹幕文档,对弹幕文档建立索引进行检索。字段还包括弹幕的数量,弹幕的最大数量等。
5.2 结果排序
whoosh的排序方法包括:
-
BM25F(B=0.75, K1=1.2)
-
TF_IDF
-
Frequency
默认使用BM25F方法,BM25算法,通常用来作搜索相关性评分。一句话概况其主要思想:对Query进行语素解析,生成语素q_i;然后,对于每个搜索结果D,计算每个语素q_i与D的相关性得分,最后,将q_i相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
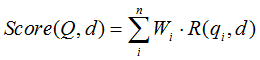
其中,Q表示Query,q_i表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素q_i。);d表示一个搜索结果文档;Wi表示语素q_i的权重;R(q_i,d)表示语素q_i与文档d的相关性得分。
BM25算法的相关性得分公式可总结为:
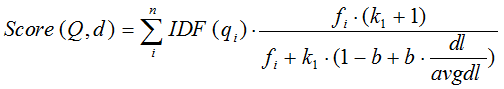
K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。现有的实验数据表明,k1的取值为1.2~2,B的取值为0.75有好的效果。
在本项目中,由于检索的结果可能出现在许多的文档中,并且人们应该期望那些弹幕相对比较多的视频,应该将弹幕数量多的放在文档中,因此,我认为应该将弹幕文档的长度纳入考虑中。因此,本文在使用BM25算法那时,将b设置在为0,并且进一步的将弹幕长度也作为排序的一个指标。权重是我自己的设定的。
六、网站建设
计划使用Flask进行网站建设。
6.1 可视化部分
由于DDL的问题,只能先出Version,事实上,我的可视化分为两个部分,一个是基于我的主题SNH48的特点,包括总选的数据、 官网的妹子的数据 、妹子的外部数据库(贴吧,微博等统计数据),想好的可视化包括总选票数,名次的变化等。
但是限于时间,不做这个部分。
第二个部分就是对于一个特点的视频,得到其视频的弹幕分布图,和弹幕详细的统计图。最开始的设计是:
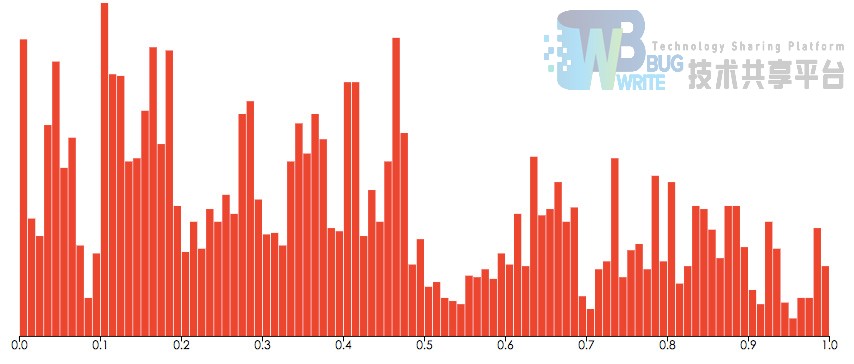
但是显然这样的结果不够令人满意,我需要实现一个交互的系统,更好的HCI,否则我觉得自己PKU白上那么多课程了。于是,希望借鉴dc.js在 examples 上的效果,实现一个动态的视频弹幕统计系统。
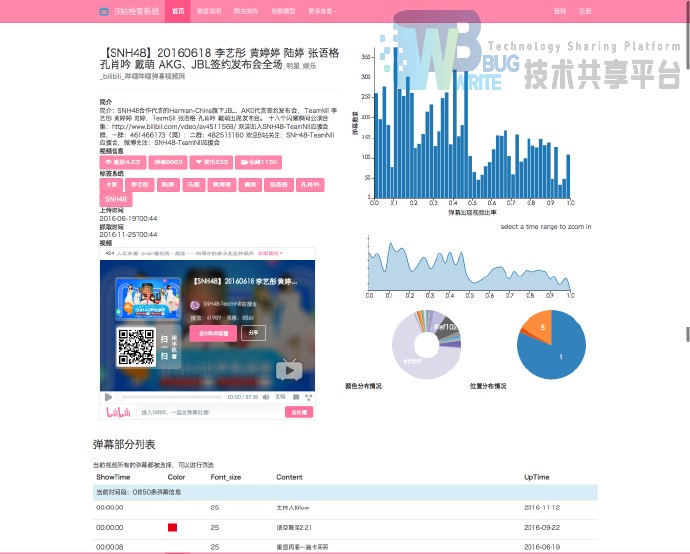
6.2 检索页面
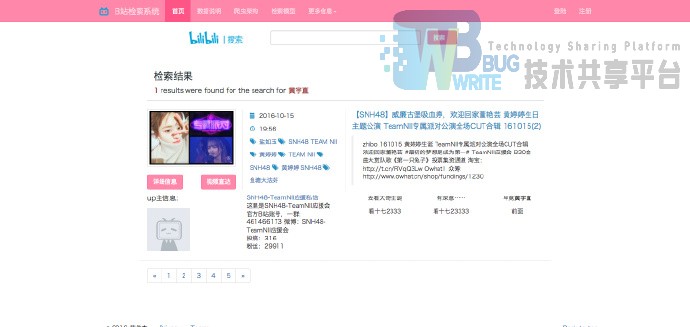
如果你喜欢的话,欢迎关注 黄婷婷应援会 。谢谢了
6.3 其他
之前一直遇到“OperationalError (2006, 'MySQL server has gone away')”的错误,改了很多方法,包括:
最后却是MYSQL的设置的问题导致的超时。
Error 2006: “MySQL server has gone away” using Python, Bottle Microframework and Apache
关于数据结构问题,确实存在冗余,但是为了更简单一些后面的处理,容纳这些数据的冗余的问题。
参考
-
[1] 弹幕信息:https://lintmx.com/bi-li-bi-li-dan-mu-fen-xi/
-
[2] 哔哩哔哩真实视频地址解析-初探:http://blog.csdn.net/qyvlik/article/details/49473489
-
[3] you-get:https://github.com/soimort/you-get
-
[4] whoosh:https://pypi.python.org/pypi/Whoosh/
参考文献
- 基于J2EE的分布式信息检索查询平台的研究(北京化工大学·高峰)
- 面向B站弹幕情感分析系统的设计和实现(山东大学·姚宗豪)
- 基于Web的信息发布与信息交流平台的设计与实现(吉林大学·许昭霞)
- 融合多特征的弹幕视频推荐算法的研究与实现(西北民族大学·黄昌昊)
- 个性化资讯推荐系统的设计与实现(山东大学·仵贇)
- 基于SSH框架的视频检索系统的设计与实现(内蒙古大学·孟宪)
- 基于元搜索的Web信息搜索技术研究(吉林大学·张春磊)
- 视频处理平台的设计与实现(北京交通大学·时月月)
- 基于J2EE的分布式信息检索查询平台的研究(北京化工大学·高峰)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 基于内容推荐的视频服务平台的设计与实现(北京交通大学·张雨萌)
- 基于JavaEE和XML的分布式信息检索系统设计与实现(山东大学·牛拥军)
- 基于J2EE的分布式信息检索查询平台的研究(北京化工大学·高峰)
- 基于Hadoop视频处理与检索系统(复旦大学·温建娇)
- 视频检索与推荐系统的设计与实现(华中科技大学·陈凡)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码码头网 ,原文地址:https://m.bishedaima.com/yuanma/35370.html









