爬取饿了么某地区的外卖信息
闲来无事,爬取大学城周边的饿了么夜晚外卖信息打发时间。
数据生成josn格式的csv文件,生成词云以及食物信息统计图
数据来源平台 :饿了么
地点选择 :新乡大学城(夜晚)
抓取地址 :https://www.ele.me/place/wtw0tgvd7yr
抓取数据 :店名(name)和店的口味(flavors)。
1.首先观察网页结构,需要登录饿了么官网,F12查看
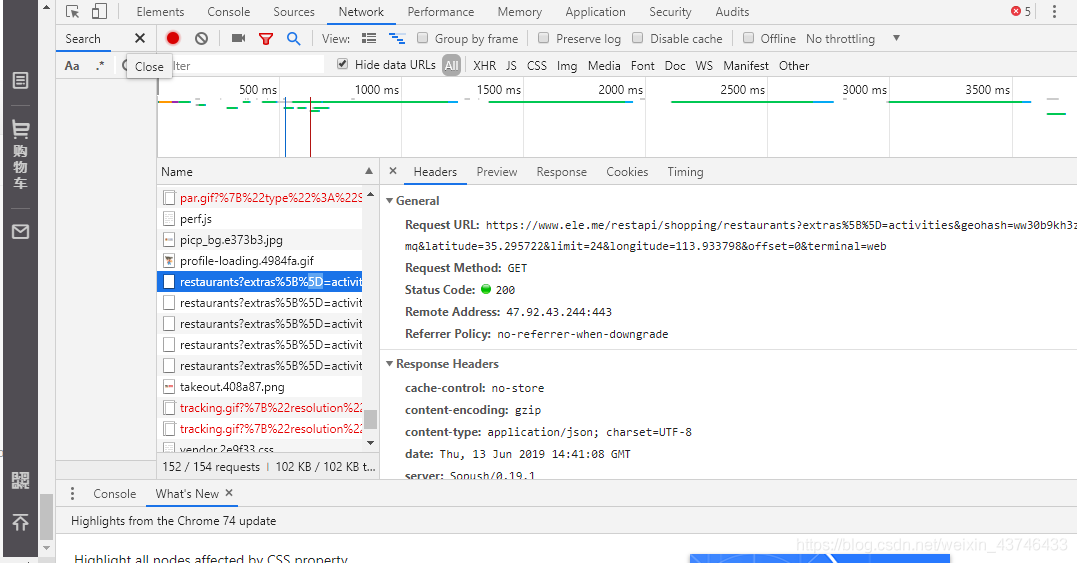
找到以restaurants开头的信息,并双击打开
 2.这时,可以观察到网页的结构信息,这时就比较简单了,
观察网页URL,发现‘offset=’在控制网页页数,limit为24。
2.这时,可以观察到网页的结构信息,这时就比较简单了,
观察网页URL,发现‘offset=’在控制网页页数,limit为24。
```python def Getdata(page): # 爬虫 print('正在爬取第{}页'.format(page/24)) url = 'https://www.ele.me/restapi/shopping/restaurants?extras%5B%5D=activities&geohash=ww30b9kh3zmq&latitude=35.295722&limit=24&longitude=113.933798&offset='+str(page)+'&terminal=web' print(url) headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36", "cookie": "你的cookie信息"} html = requests.get(url, headers=headers) content = re.findall(r'"flavors":.*?,"next_business_time"', html.text) # 用正则获取包含数据的那部分 print(content)
for con in content:
#print(con)
jsonstring = "{" + con.replace(',"next_business_time"', "}") # 完善格式,使其成为准确的json格式
#print(jsonstring)
jsonobj = json.loads(jsonstring)
restaurant_id = jsonobj["id"]
restaurant_name = jsonobj["name"].encode("gbk", "ignore").decode("gbk")
print(restaurant_name)
flavors = jsonobj["flavors"]
restaurant_type = []
for f in flavors: # 有些flavors中只有一个值,有些有2个,所以要for循环
restaurant_type.append(f["name"])
restaurants.append(restaurant_name) # 用于后面词云图
foodtype.append(restaurant_type) # 用于后面条形图
data.append([restaurant_id, restaurant_name, restaurant_type])
with open("elemedata.csv", "w", newline="") as f: # 保存数据到本地
writer = csv.writer(f)
writer.writerow(["restaurant_id", "restaurant_name", "restaurant_type"])
for d in data:
writer.writerow(d)
return restaurants, foodtype # 返回值应用到下面2个函数
```
爬取结果如下

csv文件:
 外卖种类信息直方图
外卖种类信息直方图
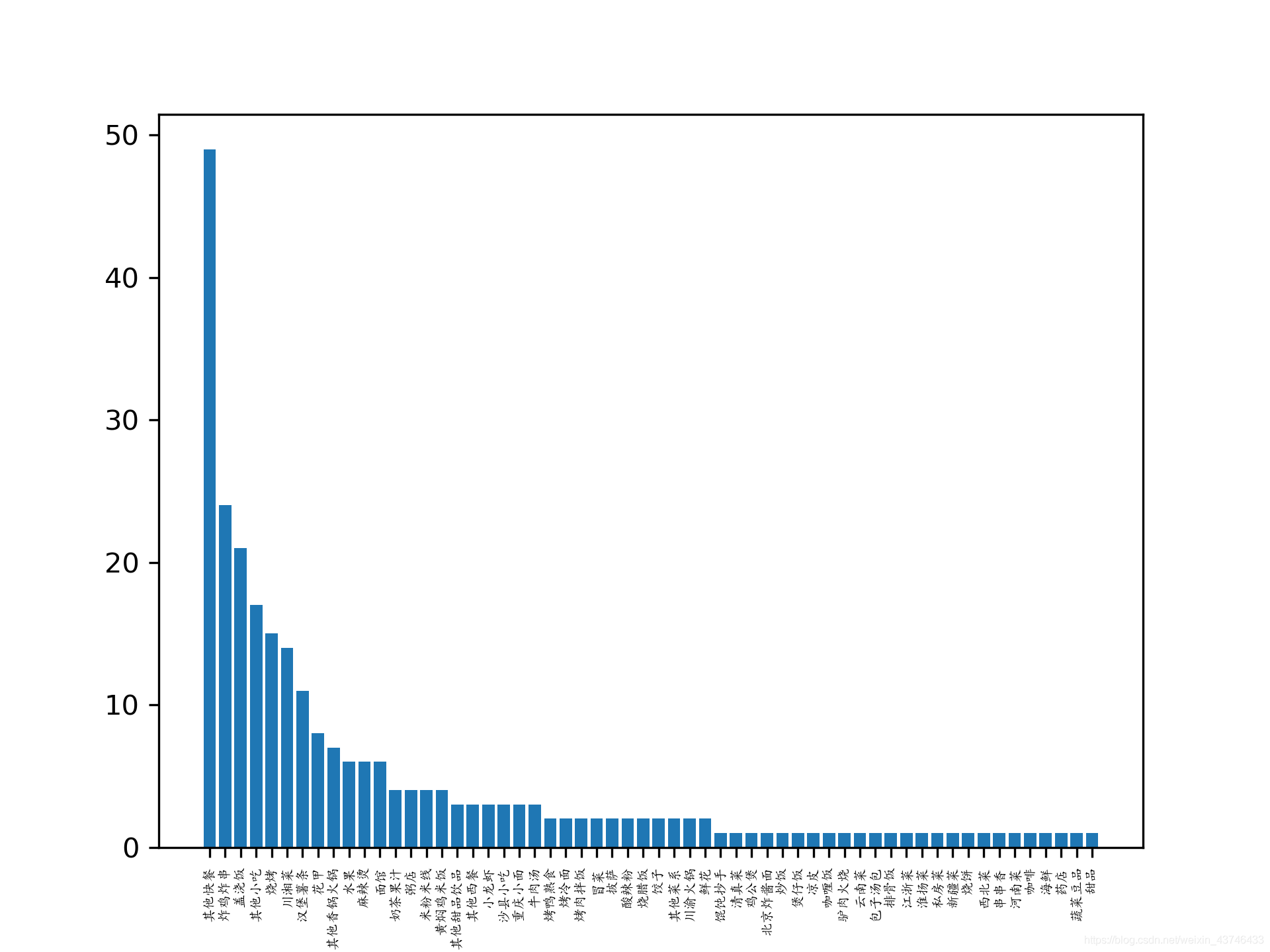
除简餐外,炸鸡炸串,盖浇饭、烧烤是夜间外卖三巨头,果汁奶茶和川湘菜,面食也是大家的心头好。
词云图

观察在夜晚大学城炸鸡,汉堡类要比面食类更受欢迎,粥、香锅、麻辣烫也十分受欢迎。
参考文献
- 基于redis的分布式自动化爬虫的设计与实现(华中科技大学·曾胜)
- 基于爬虫的网络新闻订阅和跟踪系统的设计与实现(华中科技大学·严园)
- 面向多爬虫的监控系统的设计与实现(北京邮电大学·张军强)
- 基于网络爬虫的基金信息抽取与分析平台(华南理工大学·陈亮华)
- 基于增量反馈和自适应机制的主题爬虫系统的设计与实现(南京理工大学·王斐)
- 面向中小学教育资源的网络爬虫的研究与设计(中央民族大学·郑名达)
- 基于网络爬虫的水利信息聚合系统的设计与实现(华中科技大学·闫宁)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 面向人物简介的主题爬虫设计与实现(吉林大学·蒋超)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 复合规则驱动聚焦爬虫系统的设计与实现(哈尔滨工业大学·刘强)
- 基于网络爬虫的数据采集系统设计与实现(东北大学·赵彦松)
- 基于页面分析的网络爬虫系统的设计与实现(华中科技大学·郝以珍)
- 主题微博爬虫的设计与实现(中原工学院·王艳阁)
- 基于网络爬虫的基金信息抽取与分析平台(华南理工大学·陈亮华)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码导航 ,原文地址:https://m.bishedaima.com/yuanma/35956.html