基于Python的豆瓣电影Top250的短评分析
Scrapy 爬虫 + 数据清理 + 数据分析 + 构建情感分析模型
- 项目要求:
- 爬取 豆瓣Top250 or 最新电影(例如战狼2、敦刻尔克、蜘蛛侠、银魂)的短评数据,保证抓取尽量完整;
- 分析 大家的 短评用词 ,分析 总体/分词性 的核心词,通过 可视化 方式展示;
- 统计分析 电影的打分分布状况、右侧有用的分布、点评量随时间的变化、点评人常居地的分布等,并用可视化的方式展示;
- 通过评分与短评数据,构建 情感褒贬分析分类器 ,通过短评数据预测用户“喜欢”or“不喜欢”电影。
注: 其他 的有意义的分析和建模,有 加分 !
- 提交要求:
- 根据project步骤,有任务子文件夹
- 根据project要求,建立相关文件夹与readme文档
- 学员应在readme文档中对自己的思路与各文件进行注释
- 项目总目标:
-
尽可能完备的爬取与短评相关的信息,足够完备的给出所有分析。
-
项目分步目标:
- 爬取豆瓣Top250电影站点中三类数据:每个电影详情信息、每个电影的短评内容和每个短评背后点评人的个人信息。
-
给每个数据集,分别完成统计分析、构建中文文本情感分析模型。
-
三个数据集交叉的统计分析,并构建中文文本深度学习模型。
-
Idea:
-
对每个数据集单独做一个统计分析:
- 250电影的纵向对比:最受欢迎(前10)的电影(根据豆瓣?总评分?)/电影类别(按出现频次)/导演(按出现频次)/演员(按出现频次)/语言(按出现频次,可以对其根据**分类?)/出品国家(按出现频次,可以对其根据大洲分类)/电影时长(按出现频次,可以对其分段,看不同段的直方图);所有电影的发布时间分布,以观察什么年代的电影最受欢迎(可以对其分段);在发布时间基础上,对比总评分/评价数/提问数的分布;以及,上述三者之间的分布依赖关系。从电影简介中分析情感关键词,看其与电影类别的关联、与导演的性格关联、与演员的关联。
- 所有短评的统计分析:对每个电影爬取的短评量大致分布均匀;取前10电影,分别观察,短评喜欢和不喜欢为label构建模型。
- 对点评人的常居地可视化;查看活跃的点评人(高关注数和好友数)的地理分布;点评人的个人简介中蕴含的特征词信息与地域的分布。
-
多个数据集综合分析:
- 各个电影的信息与其所有短评之间的关联,如根据短评判断电影的是喜剧片还是犯罪片。
- 各个点评人的信息与其所发出的所有短评之间的关联,如通过短评判断点评人的常居地。
- 构造模型,给定某电影信息和点评人信息,推断其会如何短评。
一、爬取豆瓣Top250的短评数据
首先,建立Scrapy爬虫project,名为“douban_movie”。
在完成整个的结业项目过程中,绝大部分时间都花在了豆瓣电影的爬虫上,其中大部分时间都花在防止403被ban或者爬取足够数目的items上。
关于Scrapy代码的细节和考虑可见douban_movie文件夹中的 README 文件,其中会详述如何运行scrapy爬虫以及其中考虑到过的细节。
概要地说,所有的spider文件都设置独立的pipeline输出文件到
./douban_movie/data
中,并且除了
movie_item
,都各自自定义了downloadpipeline参数
'DOWNLOAD_DELAY': 1.8,
,以确保不会立马被ban。每个spider的爬取都是先login,然后跳转到目标解析URL来进行的;另为了提高爬取速度,对spiders做了DNS缓存,详情可见文件
./douban_movie/dns_cache.py
和spider文件中调用的
_setDNSCache()
函数;虽然书写了多个spiders并行爬取的代码,但是在实际的爬取过程中是采用部分spiders并行工作的,一般是2-3个spiders并行工作,以免被ban,详情查看文件
./douban_movie/setup.py
和文件夹
./douban_movie/commands/
。
在settings中,使用了faker代理:
python
from faker import Factory
f = Factory.create()
USER_AGENT = f.user_agent()
还设置了尽量使用宽度优先的策略
SCHEDULER_ORDER = 'BFO'
;最大requests数一口气设置到了1000:
CONCURRENT_REQUESTS = 1000
;为了保证爬取状态下的页面整洁:
LOG_LEVEL = 'INFO'
;
对于爬取douban_people的时候,设置了无头浏览器缓冲加载,因为豆瓣短评人的网页上,目标要爬取信息是动态JS的。其设置的详情可见
./douban_movie/middlewares.py
,在这个文件中,指定了phantomjs的执行目录。
总体上,我的目标是爬取三大类信息:
-
Top250电影的信息(文件位于:
./douban_movie/data/movie_item.json) -
Top250电影中短评的信息(文件位于:
./douban_movie/data/movie_comment*.json) -
每个短评所对应的用户信息(文件位于:
./douban_movie/data/movie_people*.json)
在实际的爬取过程中,先爬取Top250电影信息,输出数据文件
movie_item.json
,从中再切出每个电影的
movie_id
存到
./bin/movie_id.out
中。再爬取每个电影的前50页短评信息,根据
movie_id.out
文件,直接构造出每个电影的短评URL地址来爬取短评信息,输出数据文件
movie_comment*.json
,再从中切出每个不重复的点评人的URL地址,存到
./bin/people_url.out
中。最后根据
people_url.out
文件,再爬取其中每个URL中的目标信息。
上述关于写入文件的关键代码,如下所示:
python
people_url = data.people_url.values.tolist()
np.savetxt('people_url.out', people_url, fmt='%s')
movie_item
movie_item.json
中是爬取Top250每个电影的信息,其中包括的item有19个,其中
movie_id
是每个电影的唯一ID编码。下面是一个实例,红色线中即是爬取的目标信息:



详情可见
./douban_movie/douban_movie/items.py
,也可预览下图:

值得说明的是,实际爬取下来的信息中,仅246个电影的信息是全面,另4个电影是木有网页信息的。
另外,没有爬取“编剧”和“上映日期”,前者是因为自己觉得此特征可能用处不大,应该没有多少人看电影会关注编剧是谁吧,后者是遗憾的没有爬取到,只爬取了上映的年份日期。
movie_comment
movie_comment*.json
中是爬取了246个电影中,每个电影短评的前50页,约有2000条短评。这样的考虑的原因有如下几点:
- 绝大部分电影的短评数量非常庞大,基本都在2w以上,完全爬取并不现实;
- 豆瓣电影短评的排名是基于豆瓣官方的某种算法排序的——“ 短评的排序是将豆瓣成员的投票加权平均计算后的结果,通过算法的调校,更好地反映短评内容的价值。”;
- 查看短评的排序,可以发现短评有用数基本是指数递减的;
除了爬取了 短评文本信息 外,还收集了其他含有价值的items信息,包括 短评评分 、 短评有用数 和 短评时间 ,其中前两者分别是分类有序和数值有序信息。下图是一个实例:
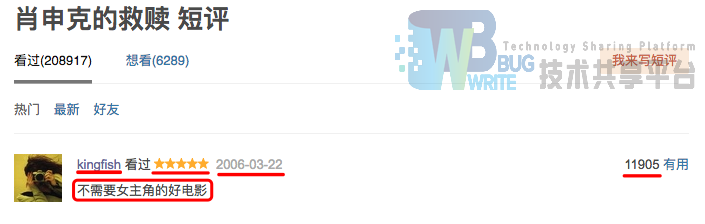
详情可见
./douban_movie/douban_movie/items.py
,也可预览下图:
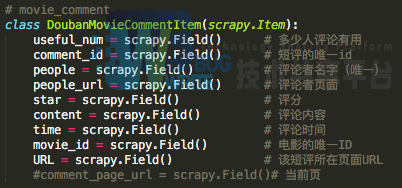
值得说明的是,items中
comment_id
是每条短评的唯一ID编码,
people
是每个短评人的用户名,可作为点评人的唯一ID编码。
实际爬取的过程中,由于代码要求先存下来每个电影的短评URL,然后同时批量每页爬取,很可能是截止到短评第50页的代码存在bug,而导致246个电影的短评数量并不是完全一样的,每个电影的短评数从1060到819不等分布:
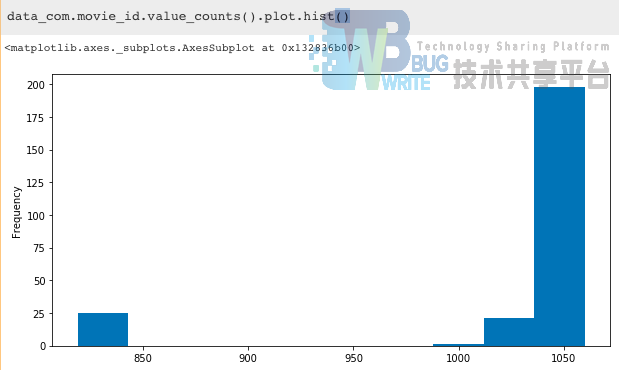
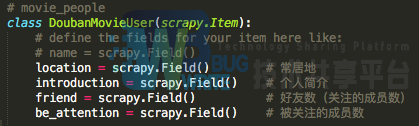
movie_people
movie_people*.json
爬取每个短评的点评人的特征信息。由于点评人的豆瓣页面上的用户信息并不充分,所以仅爬取了每个短评人的常居地、用户的个人简介、好友数和被关注的成员数。下面是一个实例,红色框中即是爬取的目标信息:


这里留下了一些遗憾,未能完整爬取每个点评人与电影短评相关的特征信息,如用户的豆瓣注册时间未能成功爬取下来。另外,每个豆瓣用户的电影短评(不仅仅是Top250电影)也应该是非常有用的特征信息,但是因时间精力有限为能爬取。
Scrapy中items详情可见
./douban_movie/douban_movie/items.py
,也可预览下图:
二、数据清理与特征工程+统计分析
收集到的json数据非常的raw,所以首先进行数据清理。若查看以下内容所对应的可执行文件,请移步 ./data_cleaning&feature_engineering/Filting.ipynb 文件。
movie_item
```python import pandas as pd import numpy as np import json
载入电影数据
data_item = pd.read_json('../douban_movie/data/movie_item.json', lines=True) print('电影数目:' ,data_item.shape[0])
data_item['movie_id'] = data_item['movie_id'].apply(lambda x: int(x[0][3:]))
[电影-1300267] -> int(1300267)
data_item['comment_num'] = data_item['comment_num'].apply(lambda x: int(x[2:-1]))
全部 62309 条 -> int(62309)
data_item['question_num'] = data_item['question_num'].apply(lambda x: int(x[2:-1]))
全部23个 -> int(23)
data_item['rating_num'] = data_item['rating_num'].apply(lambda x: float(x[0]))
[9.2] -> float(9.2)
data_item['rating_per_stars1'] = data_item['rating_per_stars1'].apply(lambda x: float(x[:-1]))
0.1% -> float(0.1)
data_item['rating_per_stars2'] = data_item['rating_per_stars2'].apply(lambda x: float(x[:-1]))
data_item['rating_per_stars3'] = data_item['rating_per_stars3'].apply(lambda x: float(x[:-1]))
data_item['rating_per_stars4'] = data_item['rating_per_stars4'].apply(lambda x: float(x[:-1]))
data_item['rating_per_stars5'] = data_item['rating_per_stars5'].apply(lambda x: float(x[:-1]))
data_item['release_date'] = data_item['release_date'].apply(lambda x: int(x[0][1:-1]))
[(1939)] -> int(1939)
data_item['vote_num'] = data_item['vote_num'].apply(lambda x: int(x[0]))
[272357] -> int(272357)
data_item['movie_title'] = data_item['movie_title'].apply(lambda x: (x[0]))
[238分钟] -> 238
data_item.loc[15,'runtime'] = ['80分钟']
处理电影时长
pattern = '\d+' import re data_item['runtime'] = data_item['runtime'].apply(lambda x: (x[0])) data_item['runtime'] = data_item['runtime'].str.findall(pattern,flags=re.IGNORECASE).apply(lambda x: int(x[0]))
处理电影简介
def Intro(introduces): Intro_ = '' for intro in introduces: intro = intro.strip() Intro_ += intro return Intro_ data_item['intro'] = data_item.intro.apply(Intro) ```
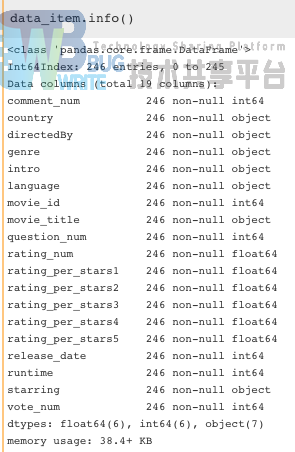
经过上述清理后,此时的DataFrame信息是:
1. 总评分最高的前10部电影
首先,我们就可以给出最高的前10部电影:
python
data_item.sort_values('rating_num', ascending=False)[['movie_title','rating_num']].head(10)
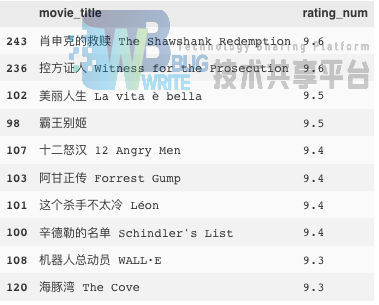
《肖申克的救赎》果然仍旧排在第一位,不过排在第二的《控方证人》确不在豆瓣Top250中排名靠前,看来豆瓣官方的排名是另有依据的。
接下来,将分别分析最受欢迎的电影类别
genre
、电影出品国家
country
、导演
directedBy
、演员
starring
、电影语言
language
、电影时长
runtime
和电影评价数
vote_num
。
首先,我们来定义三个函数以及电影类别和国别:
```python class_movie = ['剧情','爱情','喜剧','科幻','动作','悬疑','犯罪','恐怖','青春' ,'励志','战争','文艺','黑色幽默','传记','情色','暴力','音乐','家庭'] country_movie = ['大陆','美国','香港','台湾','日本','韩国','英国','法国','德国' ,'意大利','西班牙','印度','泰国','俄罗斯','伊朗','加拿大','澳大利亚' ,'爱尔兰','瑞典','巴西','丹麦']
def column_expand(data, column, list_values): for cl in list_values: tt = data_item[column].apply(lambda x: str(x)).str.contains('\W'+cl+'\W') uu = data_item[column].apply(lambda x: str(x)).str.contains('^'+cl+'$') ee = data_item[column].apply(lambda x: str(x)).str.contains(cl+'\s') ff = data_item[column].apply(lambda x: str(x)).str.contains('\s'+cl) cl_ = tt | uu| ee | ff cl_ *= 1 data['%s_%s' %(column ,cl)] = cl_
def get_values_list(data, column, sep=None): Language_values=[] def countLANG(Languages): for language in Languages: language = language.strip() if language in Language_values: continue else: Language_values.append(language) if sep: pd.DataFrame(data[column].str.split(sep))[column].apply(countLANG); else: data[column].apply(countLANG); return Language_values
def Paiming(data, column, list_values): column_expand(data, column, list_values) df = pd.DataFrame( {'数目':[data['%s_%s' %(column, p)].sum() for p in list_values]} , index=list_values).sort_values('数目', ascending=False) return df
列表匹配
column_expand(data_item, 'genre', class_movie)
column_expand(data_item, 'country', country_movie)
column_expand(data_item, 'language', get_values_list(data_item, 'language', sep='/'))
column_expand(data_item, 'starring', get_values_list(data_item, 'starring'))
```
上述代码中定义的
class_movie
和
country_movie
是搬运自豆瓣电影官方的电影分类,详情可点击这里:
XX
2. 最受欢迎的电影类别排名
python
Paiming(data_item, 'genre', class_movie)

看一眼遥遥领先的第一名,原来大家都爱看剧情片啊!再瞅一眼最后一名,居然没有人爱看励志片?在我心目中,《肖申克的救赎》就是因励志才排名首位的哦~不禁感觉豆瓣电影有点不靠谱。。。。话说,还有一部情色电影上榜,它的名字是。。。。
3. 最受欢迎的电影出品国家排名
python
temp = Paiming(data_item, 'country', country_movie)

美国好莱坞大片果然高居榜首,遥遥领先,紧随其后的是英国、日本、法国。香港和大陆的片总共有42部上榜。放在世界地图上看看:
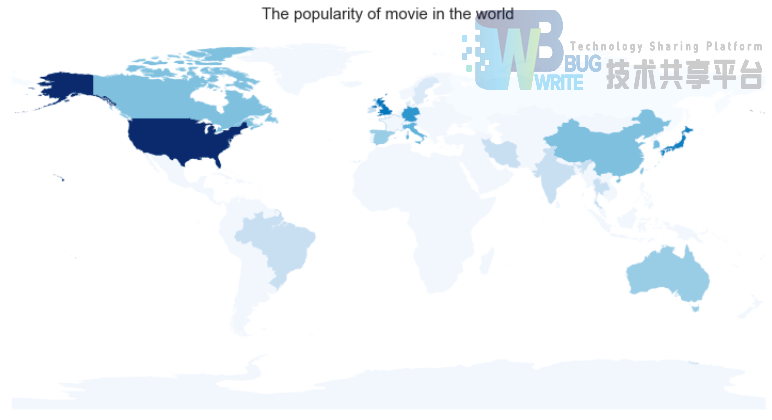
上图的代码:
```python def geod_world(df, title, legend = False): """ temp0 = temp.reset_index() df = pd.DataFrame({'NAME': temp0['index'].map(country_dict).tolist() ,'NUM': (np.log1p(temp0['数目'])*100).tolist()}) """ import geopandas as gp from matplotlib import pyplot as plt %matplotlib inline import matplotlib import seaborn as sns matplotlib.rc('figure', figsize = (14, 7)) matplotlib.rc('font', size = 14) matplotlib.rc('axes', grid = False) matplotlib.rc('axes', facecolor = 'white')
world_geod = gp.GeoDataFrame.from_file('./world_countries_shp/World_countries_shp.shp')
data_geod = gp.GeoDataFrame(df) # 转换格式
da_merge = world_geod.merge(data_geod, on = 'NAME', how = 'left') # 合并
sum(np.isnan(da_merge['NUM'])) #
da_merge['NUM'][np.isnan(da_merge['NUM'])] = 14.0#填充缺失数据
da_merge.plot('NUM', k = 20, cmap = plt.cm.Blues,alpha= 1,legend = legend)
plt.title(title, fontsize=15)#设置图形标题
plt.gca().xaxis.set_major_locator(plt.NullLocator())#去掉x轴刻度
plt.gca().yaxis.set_major_locator(plt.NullLocator())#去年y轴刻度
country_dict = {'大陆':'China','美国':'United States','香港':'Hong Kong' ,'台湾':'Taiwan, Province of China' ,'日本':'Japan','韩国':'Korea, Republic of','英国':'United Kingdom' ,'法国':'France','德国':'Germany' ,'意大利':'Italy','西班牙':'Spain','印度':'India','泰国':'Thailand' ,'俄罗斯':'Russian Federation' ,'伊朗':'Iran','加拿大':'Canada','澳大利亚':'Australia' ,'爱尔兰':'Ireland','瑞典':'Sweden' ,'巴西':'Brazil','丹麦':'Denmark'}
temp0 = temp.reset_index()
df = pd.DataFrame({'NAME': temp0['index'].map(country_dict).tolist()
,'NUM': (np.log1p(temp0['数目'])*100).tolist()})
geod_world(df, 'The popularity of movie in the world ')
```
4. 最受欢迎的电影导演排名
python
Paiming(data_item, 'directedBy', get_values_list(data_item, 'directedBy'))

排前几名的都是耳熟能详的大导演,其中还有自豪的中国人代表王家卫和李安。
5. 最受欢迎的电影演员排名
python
Paiming(data_item, 'starring', get_values_list(data_item, 'starring'))

上榜的名人几乎都是耳熟能详的,但在好莱坞大片席卷全球的今天,出乎意料的是“张国荣”演技出色,居然直接排名第一!共有八部参演电影入榜,影帝“汤姆·汉克斯”也只能屈居后位。
6. 最受欢迎的电影语言排名
python
Paiming(data_item, 'language', get_values_list(data_item, 'language', sep='/'))
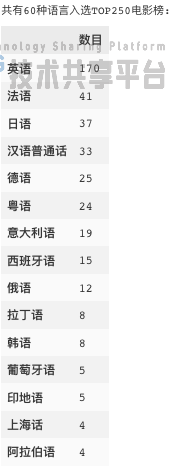
毫不意外地,英语是最受欢迎的电影语言。
7. 根据电影时长的电影排名
python
data_item.sort_values('runtime', ascending=False)[['movie_title','runtime']].head(10)

注:
runtime
为分钟数。
乱世佳人是超级经典片啊!排名第二的那个片是什么鬼。。。。
8. 根据电影投票数的电影排名
python
data_item.sort_values('vote_num', ascending=False)[['movie_title','vote_num']].head(10)

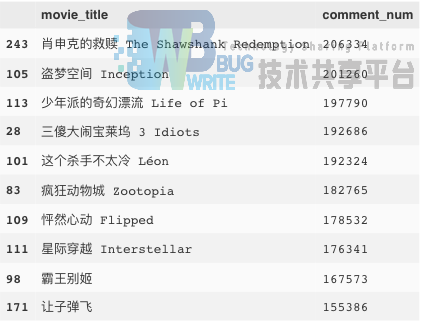
9. 根据电影评价数的电影排名
python
data_item.sort_values('comment_num', ascending=False)[['movie_title','comment_num']].head(10)
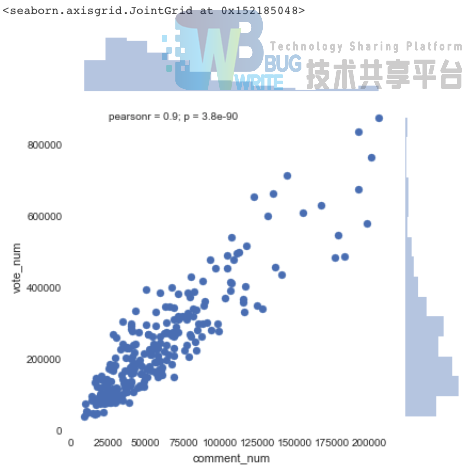
我们会发现电影评价数和电影的投票数是极强相关的,pearsonr系数达到了0.9:
python
sns.jointplot(x="comment_num", y="vote_num", data=data_item)
10. 根据电影提问数的电影排名
python
data_item.sort_values('question_num', ascending=False)[['movie_title','question_num']].head(10)
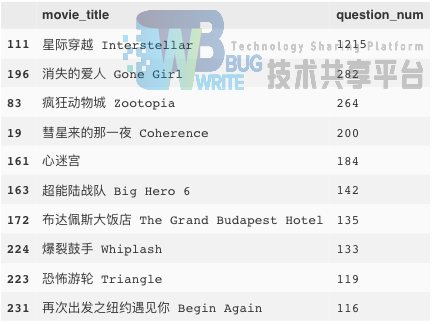
然而,电影提问数和上面的电影投票/评价数就没有多大的相关性了:
python
sns.jointplot(x="question_num", y="vote_num", data=data_item)
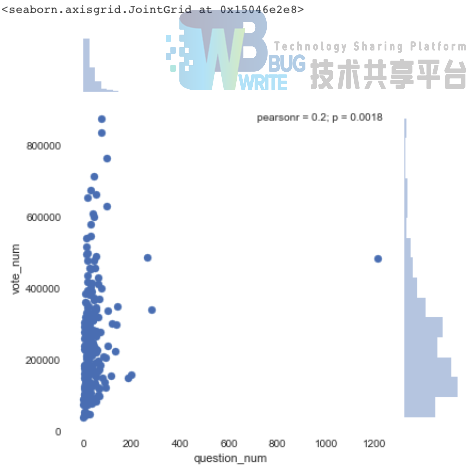
上述是分别针对data_item中的10个columns单独做统计排序分析。接下来对其他columns单独做相应的统计分析。
11. 根据电影发布时间的规律
将所有Top电影按照发布时间排序后,我们可以对比观察到Top好电影大多集中在90年代之后。每部电影的投票数也与之基本正相关,主要对90年代以来的电影尤为青睐和关注。
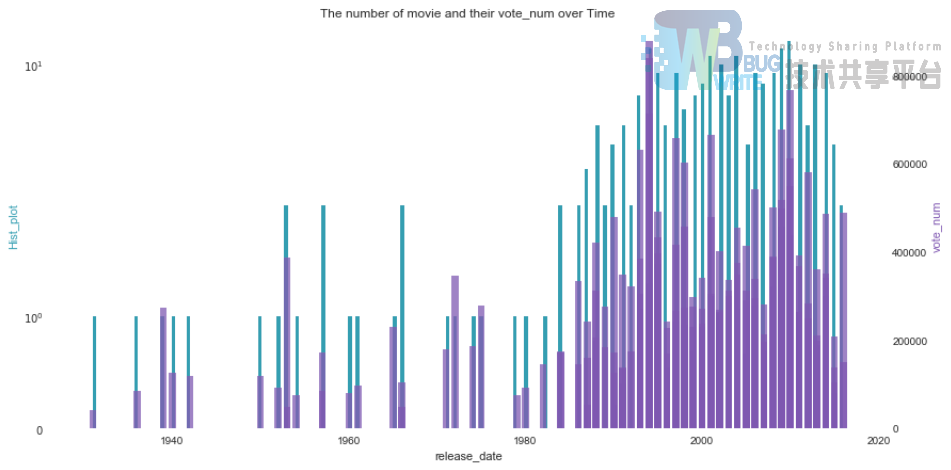
上图的代码:
```python def plot2y(x_data, x_label, type1, y1_data, y1_color, y1_label, type2, y2_data, y2_color, y2_label, title): _, ax1 = plt.subplots()
if type1 == 'hist':
ax1.hist(x_data, histtype='stepfilled', bins=200, color = y1_color)
ax1.set_ylabel(y1_label, color = y1_color)
ax1.set_xlabel(x_label)
ax1.set_yscale('symlog')
ax1.set_title(title)
elif type1 == 'plot':
ax1.plot(x_data, y1_data, color = y1_color)
ax1.set_ylabel(y1_label, color = y1_color)
ax1.set_xlabel(x_label)
ax1.set_yscale('linear')
ax1.set_title(title)
elif type1 == 'scatter':
ax1.scatter(x_data, y1_data, color = y1_color, s = 10, alpha = 0.75)
ax1.set_ylabel(y1_label, color = y1_color)
ax1.set_xlabel(x_label)
ax1.set_yscale('symlog')
ax1.set_title(title)
if type2 == 'bar':
ax2 = ax1.twinx()
ax2.bar(x_data, y2_data, color = y2_color, alpha = 0.75)
ax2.set_ylabel(y2_label, color = y2_color)
ax2.set_yscale('linear')
ax2.spines['right'].set_visible(True)
elif type2 == 'scatter':
ax2 = ax1.twinx()
ax2.scatter(x_data, y2_data, color = y2_color, s = 10, alpha = 0.75)
ax2.set_ylabel(y2_label, color = y2_color)
ax2.set_yscale('linear')
ax2.spines['right'].set_visible(True)
绘制双图函数plot2y:
plot2y(x_data = data_item.release_date , x_label = 'release_date' , type1 = 'hist' , y1_data = data_item.vote_num #(无效果) , y1_color = '#539caf' , y1_label = 'Hist_plot' , type2 = 'bar' , y2_data = data_item.vote_num , y2_color = '#7663b0' , y2_label = 'vote_num' , title = 'The number of movie and their vote_num over Time') ```
回想之前给出的电影时长排名,不禁疑惑,究竟是过去爱拍超长电影,还是现代更爱拍超长电影呢?上图来看看:
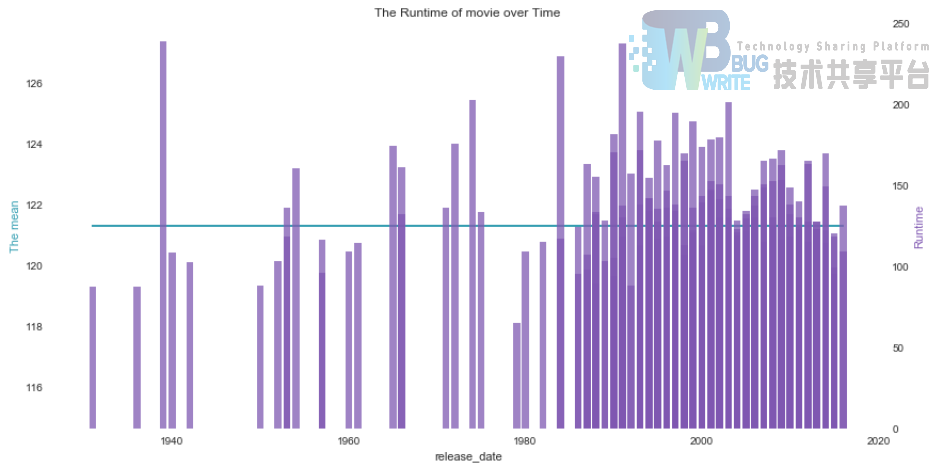
上图中的横线是Top电影时长的平均值,是2小时(121.3分钟)。可以看到,虽然历史上最长电影时长“乱世佳人”拍摄于40年代,但是现代电影从80年代开始就普遍开始更多的拍摄较长时长的电影了。
上图代码:
python
plot2y(x_data = data_item.release_date
, x_label = 'release_date'
, type1 = 'plot'
, y1_data = data_item.runtime.apply(lambda x : data_item.runtime.mean())
, y1_color = '#539caf'
, y1_label = 'The mean'
, type2 = 'bar'
, y2_data = data_item.runtime
, y2_color = '#7663b0'
, y2_label = 'Runtime'
, title = 'The Runtime of movie over Time')
12. 1~5星级投票的百分比
最后就只剩下给分星级所占比例的分析了,我们根据核密度估计绘制1-5星所占百分比的分布曲线。
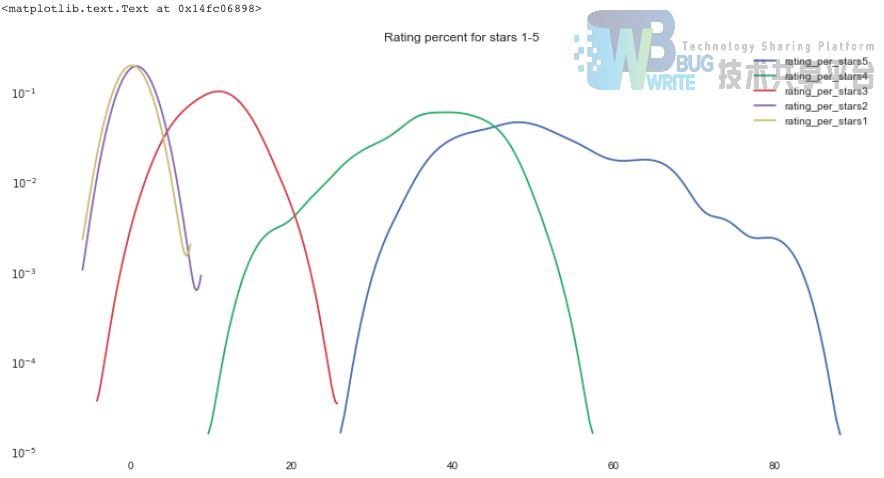
毕竟是Top250的电影,很自然地5星比例是最高的,超过了50%,1星和2星的比例非常少,基本接近0%。
上图的代码:
python
sns.kdeplot(data_item.rating_per_stars5, bw=2)
sns.kdeplot(data_item.rating_per_stars4, bw=2)
sns.kdeplot(data_item.rating_per_stars3, bw=2)
sns.kdeplot(data_item.rating_per_stars2, bw=2)
sns.kdeplot(data_item.rating_per_stars1, bw=2)
plt.yscale('log')
plt.title('Rating percent for stars 1-5')
13. 电影简介的情感分析
对每个电影的电影简介,分词-去停用词-关键词抽取,可如下图预览:

上图代码如下:
```python import warnings warnings.filterwarnings("ignore") import jieba # 分词包 import numpy as np import codecs import pandas as pd
def lcut(Intro_movie):
# 导入、分词、去停用词
segment=[]
segs = jieba.lcut(Intro_movie) # jiaba.lcut()
for seg in segs:
if len(seg)>1 and seg!='\r\n':
segment.append(seg)
return segment
def dropstopword(segment):
# 去停用词
words_df = pd.DataFrame({'segment':segment})
stopwords = pd.read_csv("../stopwords.txt"
,index_col=False
,quoting=3
,sep="\t"
,names=['stopword']
,encoding='utf-8') # quoting=3 全不引用
#stopwords.head()
return words_df[~words_df.segment.isin(stopwords.stopword)].segment.values.tolist()
基于TextRank算法的关键词抽取(仅动词和动名词)
import jieba.analyse as analyse
data_item['keywords'] = data_item.intro.apply(lcut)\ .apply(dropstopword)\ .apply(lambda x : " ".join(x))\ .apply(lambda x:" ".join(analyse.textrank(x, topK=8 , withWeight=False , allowPOS=('n','ns' ,'vn', 'v')))) data_item.sort_values('rating_num', ascending=False)[['movie_title','keywords']].head(10) ```
暂告一段落吧,其实还有很多可以分析的,比如导演最喜好拍的电影类型、导演最爱合作的电影演员,演员最喜好演的电影类型等等。。。时间有限~下回分解~
movie_comment
还是老套路,我们需要读取短评数据,并且清理一下:
```python import pandas as pd import numpy as np import json
短评数据
movie_comment_file = ['../douban_movie/data/movie_comment%s.json' %j for j in [ i for i in range(20,220,20)] +[225,250]] com = [] for f in movie_comment_file: lines = open(f, 'rb').readlines() com.extend([json.loads(elem.decode("utf-8")) for elem in lines]) data_com = pd.DataFrame(com) data_com['movie_id'] = data_com['movie_id'].apply(lambda x: int(x[0][5:])) data_com['content'] = data_com.content.apply(lambda x: x[0].strip()) data_com['people'] = data_com.people.apply(lambda x: x.strip()) data_com['people'] = data_com.people_url.apply(lambda x: x[30:-1]) data_com['useful_num'] = data_com.useful_num.apply(lambda x: int(x)) def regular_nonstar(x): if x == 'comment-time': return 'allstar00 rating' else: return x data_com['star'] = data_com.star.apply(regular_nonstar).apply(lambda x: int(x[7])) data_com['time'] = pd.to_datetime(data_com.time.apply(lambda x: x[0])) print('获取的总短评数:' ,data_com.shape[0]) ```
上述简单的清理过后,还需要对短评做取重处理,因为爬虫下来的短评存在了重复现象:
```python data_com = data_com[~data_com.comment_id.duplicated()] print('去重后的总短评数:' ,data_com.shape[0])
去重后的总短评数: 249512
以下代码是将去重后的短评人URL保存给Scrapy进一步爬虫:
people_url = data_com.people_url.unique().tolist()
np.savetxt('../douban_movie/bin/people_url.out', people_url, fmt='%s')
urllist = np.loadtxt('../douban_movie/bin/people_url.out', dtype='|S').tolist()
len(urllist) # 共38599个people
```
清理过后,我们获得了TOP250电影的总短评数249512个。瞅一眼每一列的数据类型之前,我们先drop掉用于爬虫时候检查爬取质量的URL信息,并且添加了
label
信息,标示出给出3星及其以上的为“喜欢”,其他为"不喜欢":
python
data_com = data_com.drop(['URL','people_url'], axis=1)
data_com['label'] = (data_com.star >=3) *1
data_com.info()
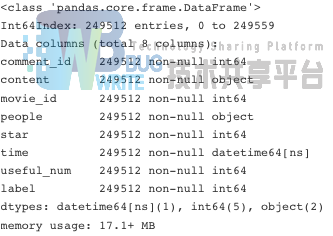

每个电影爬取的短评数量不太相同,最少有819个短评,如电影“贫民窟的百万富翁 Slumdog Millionaire”,最多有1060个短评,如电影“幸福终点站 The Terminal”。总体分布可见下图,横轴是每个电影的短评量,纵轴是相应的电影个数:
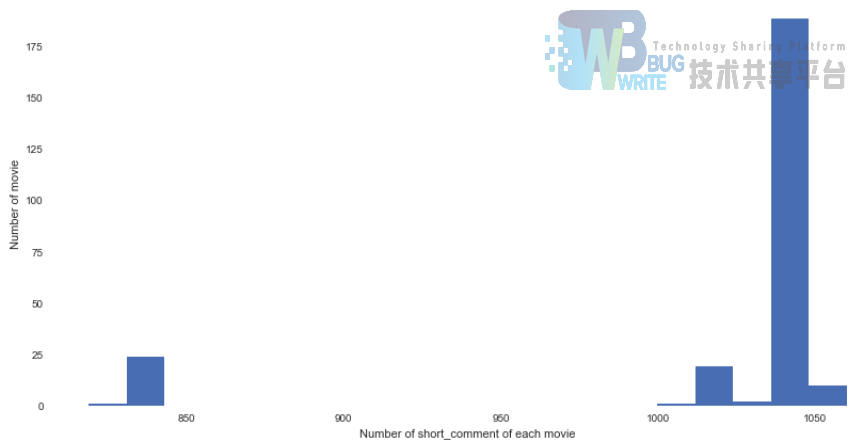
上图的代码:
python
data_com.movie_id.value_counts().hist(bins=20)
plt.ylabel('Number of movie')
plt.xlabel('Number of short_comment of each movie')
接下来的分析,我们分成两大角度:某个电影下的短评和所有电影的短评。
1. 就《肖申克的救赎》这个电影而言
首先,我们根据
movie_id
取出“肖申克的救赎”的所有电影短评:
```python data_com_X = data_com[data_com.movie_id == 1292052] print('爬取《肖申克的救赎》的短评数:', data_com_X.shape[0])
爬取《肖申克的救赎》的短评数: 1040
```
导入包文件:
python
from __future__ import division, print_function
from matplotlib import pyplot as plt
%matplotlib inline
import matplotlib
import seaborn as sns
matplotlib.rc('figure', figsize = (14, 7))
matplotlib.rc('font', size = 14)
matplotlib.rc('axes', grid = False)
matplotlib.rc('axes', facecolor = 'white')
首先,在短评数据中,真正吃信息的只有短评时间、短评星级、短评的有用数和短评文本。
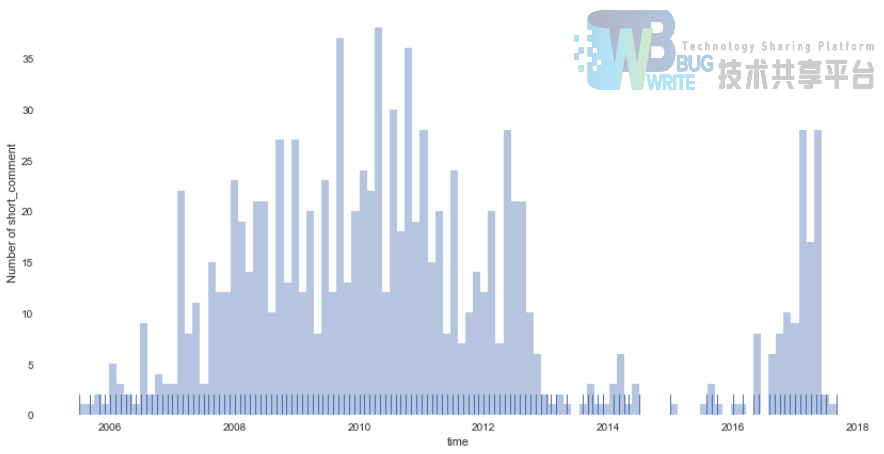
上图是所有的短评在时间尺度上的分布,可以看到2007-2013年的短评数量以及2017年最近的短评数尤为丰富,不得不怀疑,豆瓣电影在短评数据的筛选是别有用心的啊~~~上图代码:
python
sns.distplot(data_com_X.time.apply(lambda x: int(x.year)+float(x.month/12.0))
, bins=100, kde=False, rug=True)
plt.xlabel('time')
plt.ylabel('Number of short_comment')
接下来,我们查看下短评星级和短评的有用数,在时间尺度下如何分布的:
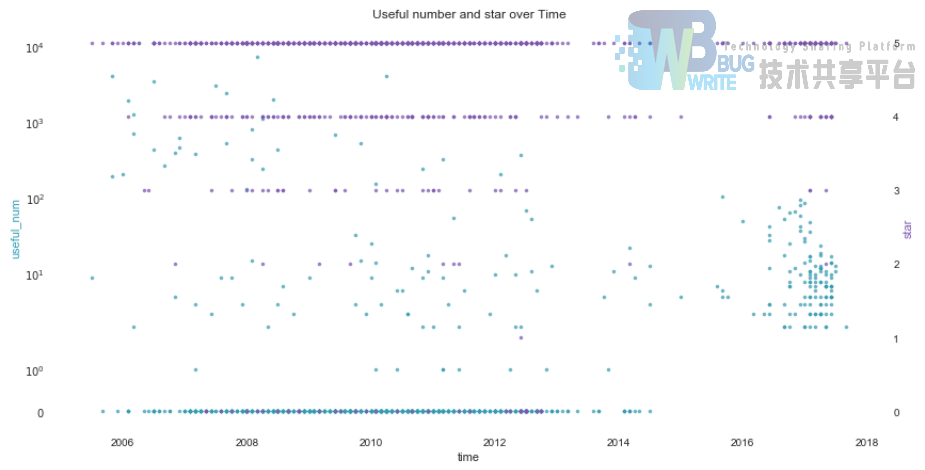
可以看到,绝大部分给的星级得分是5星,这很自然;其对应的分布在2006-2014年间,最高和最低有用数差距最大,而2017年最近的评价中,有用的短评数量比较聚集集中。上图的代码如下:
python
plot2y(x_data = data_com_X.time.apply(lambda x: int(x.year)+float(x.month/12.0))
, x_label = 'time'
, type1 = 'scatter'
, y1_data = data_com_X['useful_num']
, y1_color = '#539caf'
, y1_label = 'useful_num'
, type2 = 'scatter'
, y2_data = data_com_X['star']
, y2_color = '#7663b0'
, y2_label = 'star'
, title = 'Useful number and star over Time')
综合这些信息看来,豆瓣电影在考虑选取短评的时候,首先对评论时间做了筛选,选取了10年以内的短评,尤其针对最近1年左右的短评,还要求其中有用数相当,不允许其中存在“无用”的短评,由此提升电影短评对观众选择电影的影响力。
短评词云
接下来,我们根据短评文本生成该电影短评的词云:
```python import warnings warnings.filterwarnings("ignore") import jieba # 分词包 import numpy import codecs import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import matplotlib matplotlib.rcParams['figure.figsize']=(10.0,5.0) from wordcloud import WordCloud # 词云包
content_X = data_com_X.content.dropna().values.tolist()
导入、分词
segment=[]
for line in content_X:
try:
segs = jieba.lcut(line) # jiaba.lcut()
for seg in segs:
if len(seg)>1 and seg!='\r\n':
segment.append(seg)
except:
print(line)
continue
去停用词
words_df = pd.DataFrame({'segment':segment}) stopwords = pd.read_csv("../stopwords.txt" ,index_col=False ,quoting=3 ,sep="\t" ,names=['stopword'] ,encoding='utf-8') # quoting=3 全不引用
stopwords.head()
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
统计词频
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数":np.size}) words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
words_stat.head()
词云
wordcloud = WordCloud(font_path="../simhei.ttf" ,background_color="white" ,max_font_size=80) word_frequence={x[0]:x[1] for x in words_stat.head(1000).values} wordcloud=wordcloud.fit_words(word_frequence) plt.imshow(wordcloud) ```

自定义背景图看下哈!

图片是我从电影海报抠下来的哈。上图代码如下:
```python
加入自定义图
from scipy.misc import imread matplotlib.rcParams['figure.figsize']=(10.0,10.0) from wordcloud import WordCloud,ImageColorGenerator bimg=imread('cover.jpg') wordcloud=WordCloud(background_color="white" ,mask=bimg,font_path='../simhei.ttf' ,max_font_size=200) word_frequence={x[0]:x[1] for x in words_stat.head(1000).values} wordcloud=wordcloud.fit_words(word_frequence) bimgColors=ImageColorGenerator(bimg) plt.axis("off") plt.imshow(wordcloud.recolor(color_func=bimgColors)) ```
接下来,我们根据短评文本和点评人是否喜欢作为训练数据,构建情感褒贬分析分类器:
用朴素贝叶斯完成中文文本分类器
首先准备数据,我们会发现,训练数据样本的label非常的不平衡,正样本是负样本的20倍:
```python data_com_X.label.value_counts()
1 993
0 47
Name: label, dtype: int64
```
于是,我先采用下采样,复制负样本20遍使得正负样本平衡,并且drop停用词,最后生成训练集:
```python import warnings warnings.filterwarnings("ignore") import jieba # 分词包 import numpy import codecs import pandas as pd
def preprocess_text(content_lines,sentences,category): for line in content_lines: try: segs=jieba.lcut(line) segs = filter(lambda x:len(x)>1, segs) segs = filter(lambda x:x not in stopwords, segs) sentences.append((" ".join(segs), category)) except: print(line) continue
data_com_X_1 = data_com_X[data_com_X.label == 1] data_com_X_0 = data_com_X[data_com_X.label == 0]
下采样
sentences=[] preprocess_text(data_com_X_1.content.dropna().values.tolist() ,sentences ,'like') n=0 while n <20: preprocess_text(data_com_X_0.content.dropna().values.tolist() ,sentences ,'nlike') n +=1
生成训练集(乱序)
import random random.shuffle(sentences) """ for sentence in sentences[:10]: print(sentence[0], sentence[1]) """
明明 勇敢 心式 狗血 nlike
震撼 like
```
接下来就是通过交叉验证,在朴素贝叶斯分类器下构建模型,给出准确率:
```python from sklearn.cross_validation import StratifiedKFold from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import accuracy_score,precision_score
from sklearn.model_selection import train_test_split
x,y=zip(*sentences)
def stratifiedkfold_cv(x,y,clf_class,shuffle=True,n_folds=5, kwargs): stratifiedk_fold = StratifiedKFold(y, n_folds=n_folds, shuffle=shuffle) y_pred = y[:] for train_index, test_index in stratifiedk_fold: X_train, X_test = x[train_index], x[test_index] y_train = y[train_index] clf = clf_class( kwargs) clf.fit(X_train,y_train) y_pred[test_index] = clf.predict(X_test) return y_pred
NB = MultinomialNB print(precision_score(y ,stratifiedkfold_cv(vec.transform(x) ,np.array(y),NB) , average='macro'))
0.910392190906
```
虽然看似准确率还不错,但其实由于负样本太不丰富,且数据总量也小,所以测试短评时并不一定能给出理想的结果,如下面自定义的中文文本分类器例子:
```python import re from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split from sklearn.naive_bayes import MultinomialNB
class TextClassifier(): def init (self, classifier=MultinomialNB()): self.classifier = classifier self.vectorizer = CountVectorizer(analyzer='word' ,ngram_range=(1,4) ,max_features=20000) def features(self, X): return self.vectorizer.transform(X)
def fit(self, X, y):
self.vectorizer.fit(X)
self.classifier.fit(self.features(X), y)
def predict(self, x):
return self.classifier.predict(self.features([x]))
def score(self, X, y):
return self.classifier.score(self.features(X), y)
```
```python text_classifier=TextClassifier() text_classifier.fit(x_train,y_train) print(text_classifier.predict('一点 不觉得震撼')) print(text_classifier.predict('好看')) print(text_classifier.score(x_test,y_test))
['nlike']
['nlike']
0.913223140496
```
用SVC完成中文文本分类器
与上面类似的,我们用SVC构建模型,看下效果会如何:
```python import re from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.svm import SVC
class TextClassifier(): def init (self, classifier=SVC(kernel='linear')): self.classifier = classifier self.vectorizer = TfidfVectorizer(analyzer='word' ,ngram_range=(1,4) ,max_features=20000)
def features(self, X):
return self.vectorizer.transform(X)
def fit(self, X, y):
self.vectorizer.fit(X)
self.classifier.fit(self.features(X), y)
def predict(self, x):
return self.classifier.predict(self.features([x]))
def score(self, X, y):
return self.classifier.score(self.features(X), y)
```
```python text_classifier=TextClassifier() text_classifier.fit(x_train,y_train) print(text_classifier.predict('一点 不觉得震撼')) print(text_classifier.predict('好看')) print(text_classifier.score(x_test,y_test))
['like']
['like']
0.971074380165
```
看来SVC也就是类似的效果。
用Facebook FastText有监督完成中文文本分类
首先,我们需要生成FastText的文本格式:
```python import jieba import pandas as pd import random
停用词
stopwords=pd.read_csv("../stopwords.txt",index_col=False,quoting=3 ,sep="\t",names=['stopword'], encoding='utf-8') stopwords=stopwords['stopword'].values
def preprocess_text(content_lines,sentences,category): for line in content_lines: try: segs=jieba.lcut(line) segs = filter(lambda x:len(x)>1, segs) segs = filter(lambda x:x not in stopwords, segs) sentences.append(" label "+str(category)+" , "+" ".join(segs)) except: print(line) continue
生成训练数据
sentences=[] preprocess_text(data_com_X_1.content.dropna().values.tolist() ,sentences ,'like') n=0 while n <20: preprocess_text(data_com_X_0.content.dropna().values.tolist() ,sentences ,'nlike') n +=1 random.shuffle(sentences)
写入文件
print("writing data to fasttext supervised learning format...") out = open('train_data_unsupervised_fasttext.txt','w' )#,encoding='utf-8') for sentence in sentences: out.write(sentence+"\n") print("done!") ```
启用fastTest模型:
```python
调用fastTest模型
import fasttext
参考文献
- 基于移动用户观影记录的推荐系统研究(浙江大学·詹珂)
- 基于影评文本分析的电影推荐研究(燕山大学·赵阳)
- 基于NTM神经网络的电影推荐系统的设计与实现(宁夏大学·朱楠)
- 基于内容与协同过滤算法的电影推荐系统研究(黑龙江大学·潘悦)
- 具有反爬虫机制的影评系统的设计与实现(北京交通大学·高萍)
- 基于连续情绪序列与电影语义特征融合的推荐研究(汕头大学·陈伟灏)
- 具有反爬虫机制的影评系统的设计与实现(北京交通大学·高萍)
- 基于自编码器混合推荐算法的研究(中北大学·于悦)
- 基于对话的电影推荐系统设计与实现(北京邮电大学·李新胜)
- 基于连续情绪序列与电影语义特征融合的推荐研究(汕头大学·陈伟灏)
- 基于粒计算的电影推荐系统设计(上海师范大学·刘琼文)
- 基于SparkALS的电影推荐系统设计与实现(重庆大学·王旭东)
- 基于知识图谱的电影知识问答系统研究与实现(重庆师范大学·申豪杰)
- 基于用户行为的电影推荐系统的设计与实现(安徽理工大学·冯康)
- 基于连续情绪序列与电影语义特征融合的推荐研究(汕头大学·陈伟灏)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕业设计客栈 ,原文地址:https://m.bishedaima.com/yuanma/35394.html