python数据分析(7)——挖掘建模(2)聚类分析
1. 常用聚类分析算法
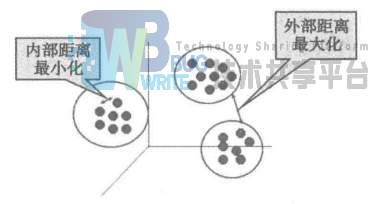
聚类分析建模原理
常用聚类方法
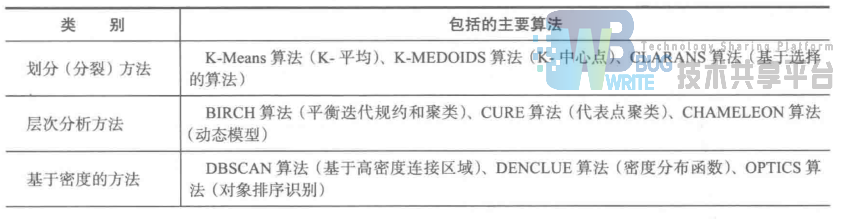

常用聚类分析算法

2. K-Means聚类算法
2.1 算法过程
K-Means算法的计算步骤 取得k个初始质心:
- 从数据中随机抽取k个点作为初始聚类的中心,来代表各个类把每个点划分进相应的类;
- 根据欧式距离最小原则,把每个点划分进距离最近的类中重新计算质心;
- 根据均值等方法,重新计算每个类的质心迭代计算质心;
- 重复第二步和第三步,迭代计算聚类完成;
- 聚类中心不再发生移动
2.2 代码
```python
- - coding: utf-8 - -
使用K-Means算法聚类消费行为特征数据
import pandas as pd
参数初始化
inputfile = 'consumption_data.xls' #销量及其他属性数据 outputfile = 'data_type.xls' #保存结果的文件名 k = 3 #聚类的类别 iteration = 500 #聚类最大循环次数 data = pd.read_excel(inputfile, index_col = 'Id') #读取数据 data_zs = 1.0*(data - data.mean())/data.std() #数据标准化
from sklearn.cluster import KMeans model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration) #分为k类,并发数4 model.fit(data_zs) #开始聚类
简单打印结果
r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目 r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心 r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目 r.columns = list(data.columns) + [u'类别数目'] #重命名表头 print(r)
详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别 r.columns = list(data.columns) + [u'聚类类别'] #重命名表头 r.to_excel(outputfile) #保存结果
def density_plot(data): #自定义作图函数 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False) [p[i].set_ylabel(u'密度') for i in range(k)] plt.legend() return plt
pic_output = 'pd_' #概率密度图文件名前缀 for i in range(k): density_plot(data[r[u'聚类类别']==i]).savefig(u'%s%s.png' %(pic_output, i)) ```
分群1的概率密度函数图
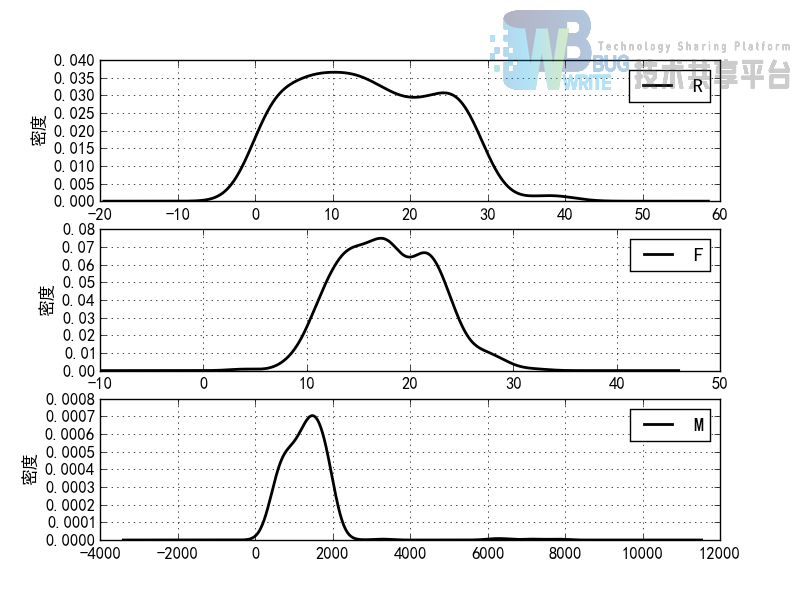
分群2的概率密度函数图
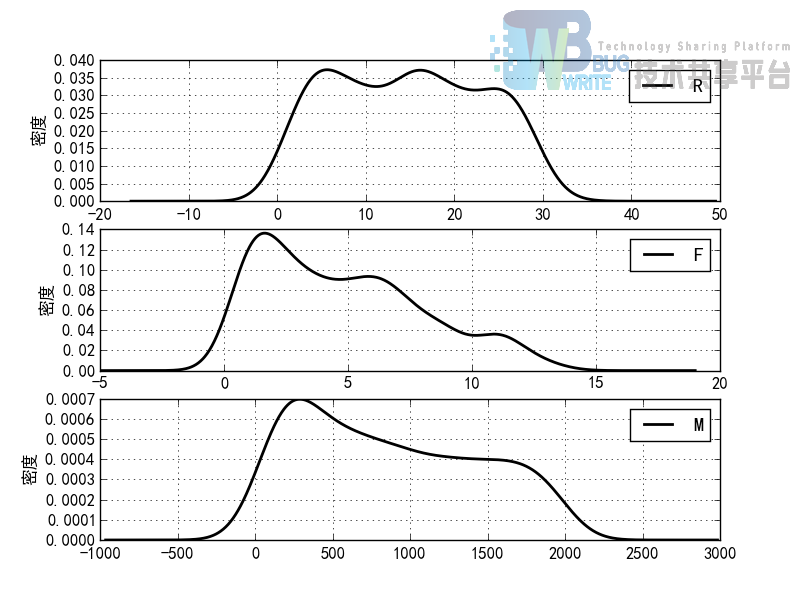
分群3的概率密度函数图
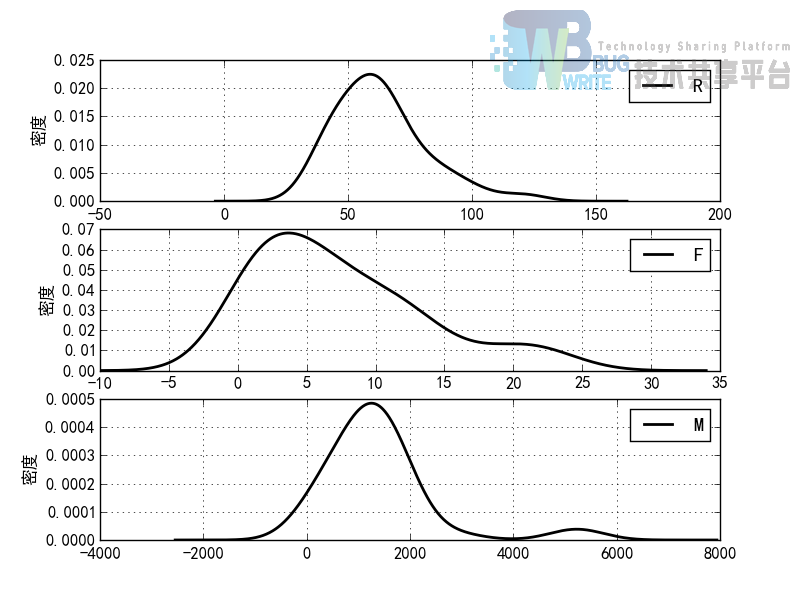
2.3 用TSNE进行数据降维并展示聚类结果
```python
- - coding: utf-8 - -
接k_means.py
from sklearn.manifold import TSNE
tsne = TSNE() tsne.fit_transform(data_zs) #进行数据降维 tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) #转换数据格式
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
不同类别用不同颜色和样式绘图
d = tsne[r[u'聚类类别'] == 0] plt.plot(d[0], d[1], 'r.') d = tsne[r[u'聚类类别'] == 1] plt.plot(d[0], d[1], 'go') d = tsne[r[u'聚类类别'] == 2] plt.plot(d[0], d[1], 'b*') plt.show() ```
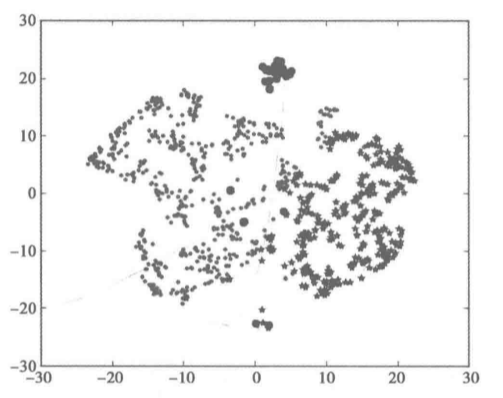
参考文献
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
- 基于redis的分布式自动化爬虫的设计与实现(华中科技大学·曾胜)
- 制造业数据交互式分析平台的设计与实现(西安电子科技大学·杨妍)
- 基于股票数据流和投资者情绪的股价预测系统的设计与实现(华南理工大学·陈泽铭)
- 一个数据需求管理系统的设计与实现(华中科技大学·陈志)
- 基于Web数据挖掘商务网站推荐系统的研究(西南师范大学·谢中)
- 数据分析流程编排系统设计与实现(大连理工大学·闫欣)
- 基于J2EE的数据挖掘系统的设计与实现(暨南大学·叶松云)
- 基于J2EE的数据挖掘系统的设计与实现(暨南大学·叶松云)
- 基于移动平台股票资讯搜索与预测系统研究(哈尔滨理工大学·滕文达)
- 基于J2EE和多维数据模型的金融数据分析系统(西安电子科技大学·王凯)
- 基于数据挖掘的用户上网行为分析(中央民族大学·丰玄霜)
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
- 基于Django的模型参数分析系统的设计与实现(南京大学·府洁)
- 基于数据挖掘的用户上网行为分析(中央民族大学·丰玄霜)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码客栈 ,原文地址:https://m.bishedaima.com/yuanma/35398.html