基于Python的数据库实现
1.需求分析
1.1 概述
从底层做起,实现数据库的组织、存储、检索、更新和索引等功能。
1.2 基本功能
-
设计特定的数据结构,用于存储数据表、视图、索引三种数据库对象的元数据信息,建立数据库系统的数据字典
-
设计特定的数据结构,用于存储数据表中的数据
-
设计特定的数据结构,用于存储索引数据
-
设计特定的数据结构,分别用于存储用户和访问权限的信息
-
输入“help database”命令,输出所有数据表、视图和索引的信息,同时显示其对象类型;输入“help table 表名”命令,输出数据表中所有属性的详细信息;输入“help view 视图名”命令,输出视图的定义语句;输入“help index 索引名”命令,输出索引的详细信息
-
解析CREATE、SELECT、INSERT、DELETE、UPDATE等SQL语句的内容;检查SQL语句中的语法错误和语义错误
-
执行CREATE语句,创建数据表、视图、索引三种数据库对象;创建数据表时需要包含主码外码、唯一性约束、非空约束等完整性约束的定义
-
执行SELECT语句,从自主设计的数据表中查询数据,并输出结果;在SELECT语句中需要支持GROUP BY、HAVING和ORDER BY子句,需要支持5种聚集函数
-
执行INSERT、DELETE和UPDATE语句,更新数据表的内容;更新过程中需要检查更新后的数据表是否会违反参照完整性约束。如果是,则提示违反哪一条完整性约束,并拒绝执行更新操作;如果否,提示数据表更新成功,并说明插入、删除或修改了几个元组
-
当数据表的内容更新后,根据索引的定义,自动更新索引表的内容
-
在有索引的数据表上执行查询语句时,首先利用索引找到满足条件的元组指针,然后通过指针到数据表中取出相应的元组
-
执行GRANT语句,为用户授予对某数据库对象的SELECT、INSERT、DELETE、UPDATE等权限;执行REVOKE语句,收回上述权限
-
用户登录时,需要输入用户名;如果用户没有被授权,则拒绝执行用户查询或更新等操作,并给出提示信息
-
将SELECT语句转化为关系代数表达式,再利用查询优化算法对关系代数表达式进行优化,输出优化后的关系代数表达式或SELECT语句
1.3 系统需求
-
开发语言:Python
-
开发工具:Pycharm
2.概要设计说明
2.1 数据文件存储
设置system库,table_information库,view库为系统初始化后建立的初始数据库。文件使用excel存储。
2.2 模块功能及描述
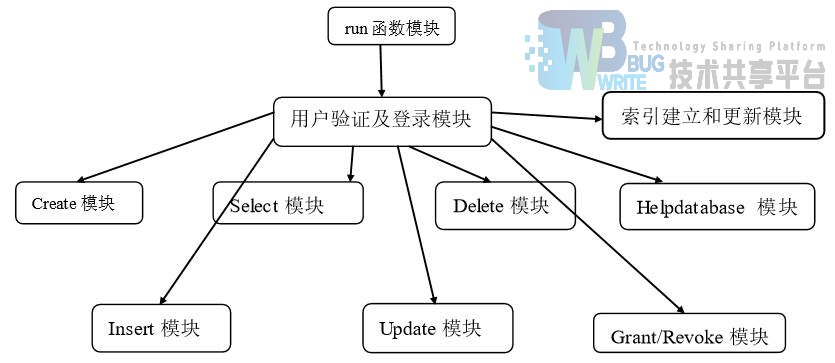
2.1.1 run函数模块
run函数模块是整个系统的入口,本模块的主要功能是初始化用户,调用各模块,处理用户输入,实现数据库管理功能。
2.1.2 用户验证及登录模块
本模块功能是进行用户的登录认证。
2.1.3 创建表模块
根据标准 SQL 语言将输入语句进行分割,获得表名,各个属性名,属性类型,约束条件等内容,再进行表的创建。
2.1.4 创建视图模块
本模块通过 CREATE VIEW VIEW_NAME AS SELECT …语句来创建视图,将存储视图和对应的语句。
2.1.5 插入数据模块
将用户输入的数据存入相应的表中并进行约束检查。
2.1.6 更新数据模块
根据用户的 WHERE 条件更新符合条件的元组并进行约束检查。
2.1.7 查询数据模块
根据用户的查询条件进行查询。
2.1.8 删除数据模块
根据用户的 WHERE 条件删除符合条件的元组。
2.1.9 帮助模块
-
HELP DATABASE 可查看当前数据库下的所有的表,视图信息
-
help table 表名可输出数据表中所有属性的详细信息
-
输入“help view 视图名”命令,输出视图的定义语句
-
输入“help index 索引名”命令,输出索引的详细信息
2.1.10 授权与权限收回模块
通过grant和revork实现用户对表和视图的 CREATE、DELETE、UPDATE、INSERT 四种操作的权限授予与收回。
2.1.11 索引建立和更新模块
使用create语句建立索引,在内容更新后更新索引。
2.3 模块调用图
3.详细设计说明
3.1 环境依赖
本程序用到的库:
``python from openpyxl import * import os import re from index import * from prettytable import PrettyTable import hashlib import bisect import Queue ```
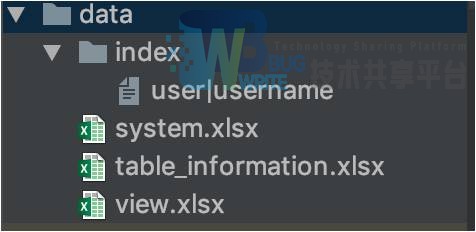
3.2 数据存储
数据库的数据使用xlsx格式存储,每一个文件对应一个数据库,工作簿对应库中的表,表结构和文件结构对应。
索引使用文本存储dict。
使用openpyxl库进行文件内容的操作。
数据库示例:

3.3 run函数的功能
```python * 程序初始化 * 打印欢迎语句 * 处理用户登录与认证 * 处理帮助命令和退出命令
def run(): Initialization() welcome() login() while True: command = get_command() #print command if command == 'quit' or command == 'exit': print("[🍻] Thanks for using L-DBMS. Bye~~") exit(0) elif command == 'help': help() else: query(command) ```
3.3 初始化函数的功能
```python * 创建数据存储目录 * 创建系统数据库文件 * 创建系统用户 * 赋予系统用户权限
def Initialization(): if not os.path.exists(db_path): os.mkdir(db_path) if not os.path.exists("data/table_information.xlsx"): Workbook().save("data/table_information.xlsx") if os.path.exists("data/system.xlsx"): print "Initializating......" else: creat_db('system') db = load_workbook("data/system.xlsx") permission_tb_col = ['database char[50] pk unique','select char','insert char','delete char','update char'] creat_table('permission', db, 'system',permission_tb_col) ```
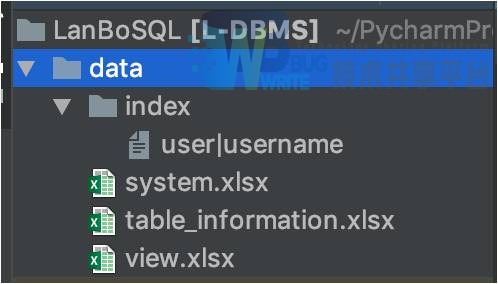
目录结构
3.4 用户验证及登录模块
登陆处理
通过raw_input()函数获取用户输入的用户名和密码,交给check_login()函数来验证是否正确。如果check通过,输出欢迎界面并将全局变量user赋值。
python
def login():
global user
print "Please Login:"
username = raw_input("username: ")
password = raw_input("password: ")
if check_login(username,password):
print "Login Success!Welcome {}! 😊".format(username)
user = username
else:
print "user not exist or password is wrong!😣 Try again."
login()
check_login函数通过输入的username查询数据库中对应的密码,将查询结果和用户输入的值的md5加密值进行比较,如果一致,认为成功登陆。 如果密码不正确或无此用户,都输出error并要求用户再一次输入
python
def check_login(username,password):
db = load_workbook("data/system.xlsx")
#right_pswd = select(password,user,{'username':username})
table = db['user']
col_list = list(iter_cols(table))
try:
pos = col_list[0].index(username)
except:
return False
right_pswd = col_list[1][pos]
if hashlib.md5(password).hexdigest() == right_pswd:
return True
else:
return False
登陆效果
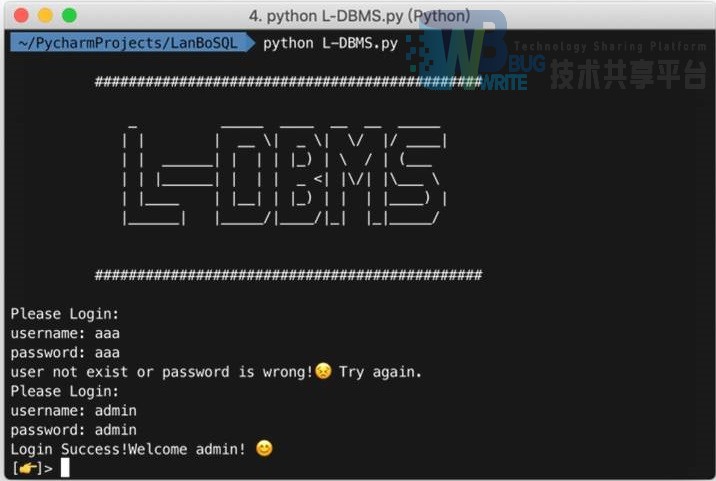
3.5 创建表模块
语句
sql
create table tbname (id int PK null,user char[10] )
在创建时将约束写入table_information表中。
python
def creat_table(table_name,current_database,current_dbname,columns_list):
# create table
if table_name not in current_database.sheetnames:
table = current_database.create_sheet(table_name)
else:
print (u"数据表已存在,请重新输入.")
return
if current_database.worksheets[0].title == 'Sheet':
del current_database['Sheet']
#表创建完成,开始创建列
length = len(columns_list)
#print length
tbinfo = load_workbook("data/table_information.xlsx")
tbinfo_tb = tbinfo[current_dbname]
tbinfo_rows = tbinfo_tb.max_row
column_names = []
for i in range(length): #将字段的属性写到table_information库中
column = columns_list[i].split(' ')
tbinfo_tb.cell(row=tbinfo_rows+1+i,column=1).value = table_name
tbinfo_tb.cell(row=tbinfo_rows+1+i, column=2).value = column[0]
tbinfo_tb.cell(row=tbinfo_rows+1+i, column=3).value = column[1]
for key in column[2:]:
if key == 'null':
tbinfo_tb.cell(row=tbinfo_rows + 1 + i, column=4).value = '1'
elif key == 'not_null':
tbinfo_tb.cell(row=tbinfo_rows + 1 + i, column=4).value = '0'
elif key == 'unique':
tbinfo_tb.cell(row=tbinfo_rows + 1 + i, column=5).value = '1'
elif key == 'pk':
tbinfo_tb.cell(row=tbinfo_rows + 1 + i, column=6).value = '1'
elif key == 'fk':
tbinfo_tb.cell(row=tbinfo_rows + 1 + i, column=7).value = '1'
column_names.append(column[0])
for j in range(1, 8):
if tbinfo_tb.cell(row=tbinfo_rows + 1 + i, column=j).value is None:
tbinfo_tb.cell(row=tbinfo_rows + 1 + i, column=j).value = 'NULL'
tbinfo.save("data/table_information.xlsx")
for i in range(length):
table.cell(row=1,column=i+1).value = column_names[i] #表第一行是列名
current_dbname = db_path + current_dbname + '.xlsx'
current_database.save(current_dbname)
print (u"数据表创建完成。")
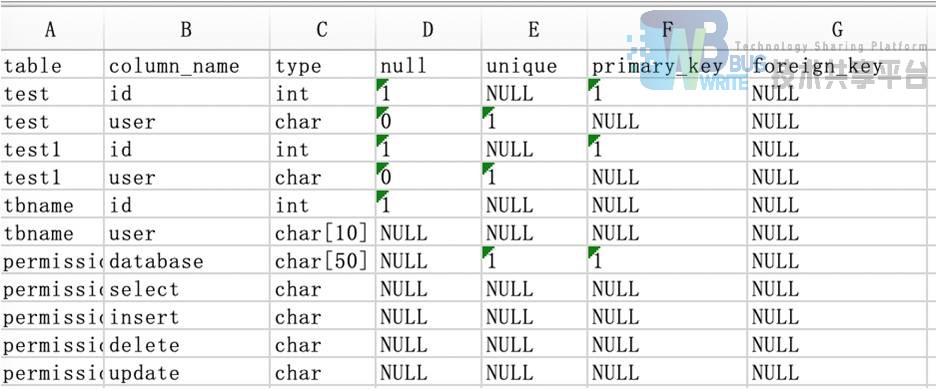
table_information表(测试数据)
3.6 创建视图模块
语句
sql
creat view view_name as select xx from xx
解析查询语句,将结果存在view库中,每一个视图已视图名作为表名写入view库中,在view库中设置一个sql表原来存储视图和对应的sql语句。
python
def view(viewname,sql):
"""
file = view_path + viewname
view = query(sql,'view')
f = open(file, "w")
f.write(str(view))
f.close()
print "Success"
"""
db = load_workbook("data/view.xlsx")
if viewname not in db.sheetnames:
table = db.create_sheet(viewname)
else:
print ("view is exist.")
return
if db.worksheets[0].title == 'Sheet':
del db['Sheet']
sql_table = db['sql']
maxrow = sql_table.max_row #在sql表中存view名和对应的sql语句
sql_table.cell(row=maxrow + 1, column = 1).value = viewname
sql_table.cell(row=maxrow + 1, column = 2).value = sql
table = db[viewname]
views = query(sql, 'view')
for i in range(len(views)):
for j in range(len(views[i])):
table.cell(row=i+1, column=j+1).value = views[i][j]
db.save("data/view.xlsx")
3.7 插入模块
支持单组和多组的插入,单组的插入处理就是将sql语句中的要插入的数据处理成字典,再交给insert函数处理。
多组的话将每组字典加入数组再进行处理。在插入数据前通过check_Constraint函数进行约束检查,注释部分是用来处理嵌套语句的,逻辑是通过正则取出其中的子查询语句,带上tag参数交给query函数处理,将结果以数组形式返回。因为对表的操作也是先转化成数组,这样直接处理数组就ok。
```python def insert(table_name, current_database, current_dbname, columns_list): if not check_Constraint(columns_list,table_name): #columns应为[dict] print "Constraint Error" return False table = current_database[table_name] for columns in columns_list: table_rows = table.max_row table_columns = table.max_column length = len(columns) # print length for i in range(length): column = re.search('((.*?))', columns[i], re.S).group(1) column_list = column.split(',') chk_len = len(column_list) if chk_len != table_columns: print ('插入失败,请检查输入的数据数量是否与列数量对应。') return
else:
for j in range(chk_len):
table.cell(row=table_rows + i + 1, column=j + 1).value = column_list[j]
current_dbname = db_path + current_dbname + '.xlsx'
current_database.save(current_dbname)
print ("数据插入完成。")
def check_Constraint(columns,tablename): #columns={'a':'xx'} db = load_workbook("system/table_information.xlsx") table = db[using_dbname] rows = [] rows_list = list(iter_rows(table)) #所有行 cols_list = list(iter_cols(table)) for col in columns: value = columns[col] for i in range(len(cols_list[0])): #table对应的行 if cols_list[0][i] == tablename: rows.append(i) for line in rows: if rows_list[line][1] == col: typee, is_null, unique, pk, fk = rows_list[line][2:] if is_null == '0': if value == '': return False if unique == '1': if not check_unique(tablename,col,value): return False if pk == '1': if not check_unique(tablename,col,value) or value == '': return False if '[' in typee: typee, maxlen = re.findall('(\w )[(\d )]',type) #int[10] => int,10 else: maxlen = 1000 if len(value) > maxlen: return False if typee == 'int': if type(value) != type(1): return False if typee == 'char': if type(value) != type('c'): return False ```
3.8 更新数据
支持单组和多组的更新,单组的更新处理就是将sql语句中的要插入的数据处理成字典,再交给insert函数处理。
多组的话将每组字典加入数组再进行处理。在更新数据前通过check_Constraint函数进行约束检查,其他功能和insert的逻辑一样。
语句
sql
UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value;
python
def update(table_name,current_database,current_dbname,columns_list,update_columns_list):
if not check_Constraint(update_columns_list,table_name): #columns应为dict
print "Constraint Error"
return False
table = current_database[table_name]
table_rows = table.max_row # 行
table_columns = table.max_column # 列
length = len(columns_list)
update_row_num = [x for x in range(2,table_rows+1)]
columns_name = []
for cell in list(table.rows)[0]:
columns_name.append(cell.value)
for key in columns_list:
flag = 0
for i in range(len(columns_name)): # 判断colmuns_list 是否有 not in colmus中的
if columns_name[i] == key:
flag = 1
if flag == 0: # 输入的列名不存在
print("Unknown column '{}' in 'where clause'".format(key))
return
for key in columns_list:
column_num = columns_name.index(key)
for i in update_row_num[::-1]: #倒着来
if table.cell(row=i, column=column_num+1).value != columns_list[key]:
update_row_num.remove(i)
if len(update_row_num) > 0:
for i in update_row_num[::-1]:
for j in range(1,table_columns+1):
clu_name = table.cell(row=1, column=j).value
table.cell(row=i, column=j).value = update_columns_list[clu_name]
else:
print("find 0 to update.")
current_database.save(db_path + current_dbname + '.xlsx')
print("更新完成,影响{}行".format(len(update_row_num)))
3.9 语句处理函数
```python * ql语句的处理与解析。 * 通过切词和正则来转化数据和调用各函数。 * 通过split将语句按照空格切成数组,先根据首词判断操作再细分。 * tag参数是为insert,view等函数需要用到查询结果但不输出是的标识,如果带着该参数调用select函数,不会打印结果而是将结果以数组返回。 * select操作的谓词通过predicate和symbol参数来标识,带着这两个参数调用select函数,具体参见select模块 * 如果都没匹配最后会输出错误
def query(sql,tag=''): sql_word = sql.split(" ") if len(sql_word) < 2: print "[!] Wrong query!" return operate = sql_word[0].lower() if operate == 'use': if sql_word[1] == 'database': try: use_db(sql_word[2]) except: print "[!]Error" else: print "[!]Syntax Error.\neg:>use database dbname" elif operate == 'create': if sql_word[1] == 'database': try: creat_db(sql_word[2]) except: print "[!]Create Error" elif sql_word[1] == 'table': columns_list = re.findall('((.*))', sql)[0].split(',') print columns_list, using_dbname try: creat_table(sql_word[2], using_db, using_dbname, columns_list) except: print "[!]Error" elif sql_word[1] == 'view': #creat view test1 as select * from user viewname = sql_word[2] sql = ' '.join(sql_word[4:]) view(viewname,sql)
elif sql_word[1] == 'index':
return
else:
print "[!]Syntax Error."
elif operate == 'select':
pos = 0
for i in range(len(sql_word)):
if '(' in sql_word[i] and 'select' in sql_word[i]:
pos = i
if pos == 3:
sql2 = sql_word[3][1:-1]
query(sql2,tag='nesting')
sql_word[3] = 'tmp'
sql = ' '.join(sql_word)
columns = sql_word[1]
table_name = sql_word[3]
if len(sql_word) > 4:
#try:
limit = sql_word[5].split()
predicate = 'and'
symbol = '='
if ',' in sql_word[5]:
limit = sql_word[5].split(',')
predicate = 'and'
elif '|' in sql_word[5]:
limit = sql_word[5].split('|')
predicate = 'or'
elif '>' in sql_word[5]:
#limit = sql_word[5].split()
symbol = '>'
elif '<' in sql_word[5]:
#limit = sql_word[5].split()
symbol = '<'
elif len(sql_word) > 6:
if sql_word[6] == 'in':
limit = [sql_word[5] + '=' + sql_word[7]]
predicate = 'in'
if sql_word[6] == 'like':
limit = [sql_word[5] + '=' + sql_word[7]]
predicate = 'like'
#except:
#limit = [].append(sql_word[5])
#print limit
for i in range(len(limit)):
limit[i] = limit[i].split(symbol)
limit = dict(limit)
return select(columns, table_name, limit, predicate=predicate, symbol=symbol, tag=tag)
else: #没where的情况
return select(columns, table_name, tag=tag)
elif operate == 'grant':
set_permission(sql_word[5], sql_word[3], sql_word[1])
elif operate == 'revoke':
del_permission(sql_word[5], sql_word[3], sql_word[1])
elif operate == 'insert': #INSERT INTO table_name col1=val1,col2=val2&col3=val3,col4=val4
table_name = sql_word[2]
columns_list = []
if '&' in sql:
cols = sql_word[3].split('&') #[{xx},{xx}] 多组
for p in range(len(cols)):
col = cols[p]
c = col.split(',')
for i in range(len(c)):
c[i] = c[i].split('=')
cols[p] = dict(c)
columns_list = cols
else:
cols = sql_word[3].split(',')
for i in range(len(cols)):
cols[i] = cols[i].split('=')
columns_list.append(dict(cols))
insert(table_name,using_db,using_dbname,columns_list)
elif operate == 'update':
return
elif operate == 'help':
if sql_word[1] == 'database':
show_db()
if sql_word[1] == 'table':
usdbnm = using_dbname
use_db('table_information')
tbname = sql_word[2]
select('*',usdbnm,{'table':tbname})
if sql_word[1] == 'view':
view_name = sql_word[2]
use_db('view')
select('sql','sql',{'viewnamw':view_name})
if sql_word[1] == 'index':
print "All Index:"
indexs = os.listdir('data/index/') # 第二种方法,从保存数据库信息的库中查询
for index in indexs:
if '.DS' not in index:
print "[*] " + index[:-5]
else:
print "[!]Syntax Error."
```
3.10 删除模块
会先check用户权限再进行操作。其他逻辑类似insert函数。
```python def delect(table_name,current_database,current_dbname,columns_list): #columns_list={'name1':'value1','name2':'value2'}
table = current_database[table_name]
table_rows = table.max_row #行
table_columns = table.max_column #列
length = len(columns_list)
delect_row_num = [x for x in range(2,table_rows+1)]
columns_name=[]
for cell in list(table.rows)[0]:
columns_name.append(cell.value)
for key in columns_list:
flag = 0
for i in range(len(columns_name)): #判断colmuns_list 是否有 not in colmus中的
if columns_name[i] == key:
flag = 1
if flag == 0: #输入的列名不存在
print("Unknown column '{}' in 'where clause'".format(key))
return
for key in columns_list:
column_num = columns_name.index(key)
for i in delect_row_num[::-1]: #倒着来
if table.cell(row=i, column=column_num+1).value != columns_list[key]:
delect_row_num.remove(i)
if len(delect_row_num) > 0:
for i in delect_row_num[::-1]:
#print i,table_rows
table.delete_rows(int(i))
else:
print("find 0 to delect.")
current_database.save(db_path + current_dbname + '.xlsx')
print("删除完成,影响{}行".format(len(delect_row_num))) ```
3.11 权限检查模块
在用户对某对象进行操作之前确定该用户有没有操作权限。用户对对象的操作权限存储在system库中的permission表,在用户进行相关操作时先去查询该用户有没有该操作的权限。
python
def check_permission(user,database,action):
table = load_workbook("data/system.xlsx")['permission']
db_list = list(iter_cols(table))[0][1:]
row = db_list.index(database)+2
action_list = list(iter_rows(table))[0]
col = action_list.index(action)+1
allow_user = table.cell(row=row, column=col).value.split(',')
if user in allow_user:
return True
else:
print "Permission not allowed"
return False
3.12 权限的赋予和回收模块
使用grant和revoke关键字赋予权限和回收权限,实质是对permision表中数据进行更新。
grant语句
sql
grant select on test_tb for testuser

这里第一列是具有权限的对象,不只是数据库,可以是table,view,index,在函数对应函数处理时将数据库名变量换成其他对象就OK。
python
def set_permission(user,database,action):
db = load_workbook("data/system.xlsx")
table = db['permission']
db_list = list(iter_cols(table))[0][1:]
row = db_list.index(database) + 2
action_list = list(iter_rows(table))[0]
col = action_list.index(action) + 1
allow_user = table.cell(row=row, column=col).value.split(',')
if user in allow_user:
print "user have this permission"
else:
table.cell(row=row, column=col).value = table.cell(row=row, column=col).value + ',' + user
db.save("data/system.xlsx")
revoke语句
sql
revoke select on test_tb for testuser
python
def del_permission(user,database,action):
db = load_workbook("data/system.xlsx")
table = db['permission']
db_list = list(iter_cols(table))[0][1:]
row = db_list.index(database) + 2
action_list = list(iter_rows(table))[0]
col = action_list.index(action) + 1
allow_user = table.cell(row=row, column=col).value.split(',')
if user in allow_user:
if allow_user.index(user) == 0:
table.cell(row=row, column=col).value = table.cell(row=row, column=col).value.replace(user, '')
else:
table.cell(row=row, column=col).value = table.cell(row=row, column=col).value.replace(',' + user, '')
db.save("data/system.xlsx")
else:
print "user didn't have this permission"
3.13 约束检查模块
检查主码、外码、唯一性约束、非空约束等完整性约束。
单独的约束检查函数,在进行insert,update等操作时直接调用就OK。
```python def check_Constraint(columns,tablename): #columns={'a':'xx'} db = load_workbook("system/table_information.xlsx") table = db[using_dbname] rows = [] rows_list = list(iter_rows(table)) #所有行 cols_list = list(iter_cols(table)) for col in columns: value = columns[col] for i in range(len(cols_list[0])): #table对应的行 if cols_list[0][i] == tablename: rows.append(i) for line in rows: if rows_list[line][1] == col: typee, is_null, unique, pk, fk = rows_list[line][2:] if is_null == '0': if value == '': return False if unique == '1': if not check_unique(tablename,col,value): return False if pk == '1': if not check_unique(tablename,col,value) or value == '': return False if '[' in typee: typee, maxlen = re.findall('(\w )[(\d )]',type) #int[10] => int,10 else: maxlen = 1000 if len(value) > maxlen: return False if typee == 'int': if type(value) != type(1): return False if typee == 'char': if type(value) != type('c'): return False
def check_unique(tablename,column,value): table = using_db[tablename] col_pos = list(iter_rows(table))[0].index(column) #第几列 cols_list = list(iter_cols(table))[col_pos][1:] if cols_list.count(value) > 1: #该列中该值数量 return False else: return True ```
3.14 查询模块
```python * 支持嵌套查询,and,or,in,like谓词。 * 通过eval函数处理比较运算和数学运算 * 通过select等关键字个数判断子查询,子查询通过tag参数调用query函数获得查询结果数组 * query函数中语句的处理很关键,通过一些参数告诉select函数要返回什么样的值。提前讲语句处理成dict或list讲谓词等转换成符号方便select函数的处理。 * 查询时转换成数组方便操作
elif operate == 'select':
pos = 0
for i in range(len(sql_word)):
if '(' in sql_word[i] and 'select' in sql_word[i]:
pos = i
if pos == 3:
sql2 = sql_word[3][1:-1]
query(sql2,tag='nesting')
sql_word[3] = 'tmp'
sql = ' '.join(sql_word)
columns = sql_word[1]
table_name = sql_word[3]
if len(sql_word) > 4:
#try:
limit = sql_word[5].split()
predicate = 'and'
symbol = '='
if ',' in sql_word[5]:
limit = sql_word[5].split(',')
predicate = 'and'
elif '|' in sql_word[5]:
limit = sql_word[5].split('|')
predicate = 'or'
elif '>' in sql_word[5]:
#limit = sql_word[5].split()
symbol = '>'
elif '<' in sql_word[5]:
#limit = sql_word[5].split()
symbol = '<'
elif len(sql_word) > 6:
if sql_word[6] == 'in':
limit = [sql_word[5] + '=' + sql_word[7]]
predicate = 'in'
if sql_word[6] == 'like':
limit = [sql_word[5] + '=' + sql_word[7]]
predicate = 'like'
#except:
#limit = [].append(sql_word[5])
#print limit
for i in range(len(limit)):
limit[i] = limit[i].split(symbol)
limit = dict(limit)
return select(columns, table_name, limit, predicate=predicate, symbol=symbol, tag=tag)
else: #没where的情况
return select(columns, table_name, tag=tag)
```
select函数,不仅仅提供查询的功能,还用来处理view的一部分数据,通过tag参数来标识数据如何处理。
查询函数
```python def select(columns,table_name,limit={},predicate='and', symbol='=', tag=''): #{'c':'x','d':'x'} if using_dbname == '': print "please choose databse!" return table = using_db[table_name] #print columns if columns == '*' and len(limit) == 0: columns_name = list(iter_rows(table))[0] table_print = PrettyTable(columns_name) for i in range(1,len(list(iter_rows(table)))): table_print.add_row(list(iter_rows(table))[i]) table_print.reversesort = True if tag == 'view': print table_print return list(iter_rows(table)) #view
else:
print(table_print)
else:
sel_cols = columns.split(',') #*的情况
rows_list = list(iter_rows(table)) #所有的行
cols = rows_list[0]
col_pos = []
limit_pos = []
print_row = []
limit_cols = list(limit)
symbol = '==' if symbol == '=' else symbol
if columns[0] != '*':
for i in range(len(sel_cols)):
col_pos.append(cols.index(sel_cols[i])) #要查的列的列号
else:
sel_cols = list(iter_rows(table))[0]
col_pos = range(len(cols))
for i in range(len(limit)):
limit_pos.append(cols.index(limit_cols[i])) #where的列
for i in range(1, len(rows_list)):
match = 0
if predicate == 'in':
match_list = limit[limit_cols[0]]
for j in len(match_list):
if rows_list[i][limit_pos[0]] == match_list[j]:
print_row.append(i)
if predicate == 'like':
like_word = re.findall('(.*)\%',limit[limit_cols[0]])
if like_word in rows_list[i][limit_pos[0]]:
print_row.append(i)
else:
for j in range(len(limit_pos)): #通过eval实现比较运算
if eval("'" + rows_list[i][limit_pos[j]] + "'" + symbol + "'" + limit[limit_cols[j]] + "'"):
match += 1
if predicate == None:
print_row.append(i)
if predicate == 'and' and match == len(limit_pos): #and时要全部匹配
print_row.append(i) #符合条件的行号
if predicate == 'or' and match > 0: #or时至少一个匹配
print_row.append(i)
table_print = PrettyTable(sel_cols)
for i in range(len(print_row)):
add_rows = []
for x in col_pos:
add_rows.append(rows_list[print_row[i]][x])
table_print.add_row(add_rows)
table_print.reversesort = True
if tag == 'view':
return table_print
elif tag == 'nesting':
tmpdb = using_db
table = tmpdb['tmp']
for i in range(len(sel_cols)):
table.cell(row=0,column=i+1).value = sel_cols[i]
for i in range(len(print_row)):
add_rows = []
for x in col_pos:
add_rows.append(rows_list[print_row[i]][x])
for j in range(len(add_rows)):
table.cell(row=i+2,column=j+1).value = add_rows[j]
tmpdb.save("data/" + using_dbname + ".xlsx")
else:
#table_print.reversesort = True
print(table_print)
```
3.15 索引模块
B+树的索引,将数据先处理成数组,每一组数据包含数据值和数据在表中的位置(起到指针的作用)。B+树的处理单独写了一个类,方便调用处理。
```python def index(current_database,table_name,column_name): table = current_database[table_name] table_columns = table.max_column table_rows = table.max_row column_num = 0 column_value = [] column_position = [] for i in range(1,table_columns+1): if table.cell(row=1,column=i).value == column_name: column_num = i if column_num == 0: print "no this column" return else: for i in range(2,table_rows+1): column_value.append(str(table.cell(row=i,column=column_num).value)) column_position.append('<{},{}>'.format(i,column_num)) column_value.sort() for i in range(len(column_value)): tmp = [column_value[i],column_position[i]] #like [1,aaa|<2,1>] column_value[i] = tuple(tmp) #like [(1,aaa|<2,1>)] #print column_value[0] bt = test_BPTree(column_value) indexname = table_name + '|' +column_name save_index(str(bt), indexname)
def save_index(bt,indexname): line = re.findall(r'[.*?]', bt) for i in range(len(line)): line[i] = line[i][2:-2].replace('|', '') file = open('data/index/' + indexname,'w') for i in range(len(line)): file.writelines(line[i] + '\n') file.close() ```
索引的存储,存储生成的b+树,每一行是B+树的一层。存储数据类型是字典。
```python def select_index(a) Pos = BPTree_search(a)
def update_index(table_name, column_name) index(using_db, table_name, column_name) ```
B+树的部分代码
```python class BPTree(object): … def search(self, node, key): i = bisect.bisect_left(node.keys, key) if i < len(node.keys) and key == node.keys[i]: if node.is_leaf(): return (node, i) else: return self.search(node.children[i + 1], key) if node.is_leaf(): return (None, None) else: # self.disk_read(node.children[i]) return self.search(node.children[i], key)
… def insert(self, key, value): if len(self.root.keys) == self._maxkeys: oldroot = self.root self.root = BPNode() self.root.children.append(oldroot) self.split_child(self.root, 0, oldroot) self.insert_nonfull(self.root, key, value) else: self.insert_nonfull(self.root, key, value) … def levels(self): leveldict = {}
for level, node in self.bft(self.root):
leveldict.setdefault(level, []).append(node)
return leveldict
def pprint(self, width=80):
leveldict = self.levels()
keys = leveldict.keys()
for k in keys:
print ' '.join(str(e) for e in leveldict[k]).center(width)
return leveldict
def min(self):
node = self.root
while node.children:
node = node.children[0]
return node.keys[0]
def max(self):
node = self.root
while node.children:
node = node.children[-1]
return node.keys[-1]
def bft(self, node, level=1):
"""Breadth first traversal."""
q = Queue.Queue()
level = level
q.put((level, node))
while not q.empty():
level, node = q.get()
yield (level, node)
for e in node.children:
q.put((level + 1, e))
… def ceiling(self, node, key): i = bisect.bisect(node.keys, key) if i < len(node.keys) and key == node.keys[i]: if node.is_leaf(): return key else: return self.ceiling(node.children[i + 1], key) if node.is_leaf(): if i == len(node.keys): kp = node.keys[-1] if node.keys[-1] < key: if len(node.next.keys) > 0: return node.next.keys[0
参考文献
- 中小型企业仓库管理系统的设计与实现(吉林大学·郭楠)
- 基于Web的卫星信息数据库系统的研究与实现(北京邮电大学·郑俐)
- 基于.NET框架的Web数据库访问技术的研究与实现(武汉理工大学·希凡)
- 基于网络爬虫的基金信息抽取与分析平台(华南理工大学·陈亮华)
- 中小型企业仓库管理系统的设计与实现(吉林大学·郭楠)
- 基于行列转换的统计功能研究与应用(中国海洋大学·张娜)
- 库存管理系统的设计与实现(厦门大学·铁鑫磊)
- 基于计算与存储分离的Key-Value数据库的研究与实现(电子科技大学·何毅帆)
- 分布式统计信息基础数据库统计报表查询子系统的设计与实现(福州大学·曾瑾)
- 基于触发器的数据库监控系统的设计与实现(南京大学·邓明)
- 动态WEB数据库应用研究(昆明理工大学·李玉梅)
- 基于行列转换的统计功能研究与应用(中国海洋大学·张娜)
- 数据库虚拟实验室的研究与实现(中南大学·杨瑛瑛)
- Web数据库系统的研究和实践(广东工业大学·何晓桃)
- 基于J2EE和多维数据模型的金融数据分析系统(西安电子科技大学·王凯)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码工坊 ,原文地址:https://m.bishedaima.com/yuanma/35442.html