基于Python实现的孤立词语音识别系统
1 任务介绍
语音识别是通往真正的人工智能的不可缺少的技术。尽管能真正听懂人类说话的智能机器任然在未来不可捉摸的迷雾之中,但我们必须先解决如何识别出人类语音中包含的自然语言信息的问题。而数字信号处理技术将为这一任务赋能。在本课程项目的任务之中,我们面对的是一个简化的语音识别场景——即孤立词识别。
我们针对 20 个关键词,采集了所有参与课程的同学朗读每个词 20 遍的语音。我将以此为数据集来构建一个能正确识别这 20 个关键词的孤立词识别系统。
2 项目实现
基于一学期跟随老师学习到的关于信号处理与语音识别技术的知识,我额外查阅多方资料,最终呈现出了我的语音识别系统与报告。
我实现的语音识别系统的亮点有以下几个方面:
-
说话人无关的孤立词识别是语音识别技术发展中一个里程碑。从现代的观点来看,如果将语言信号视作时间序列,那么孤立词识别就是一个模式识别中的分类问题。模式识别问题的解决一般分为特征提取与模型构建两个部分。我们将这两个部分分开处理,使得代码的实现更加具有结构性和层次性。报告也将这两部分的处理分开叙述
-
我在整个系统的实现中,除了利用了数值处理函数包 numpy 和自动求导工具包 pytorch之外的所有核心代码都是单纯使用 python 实现。即真正锻炼了代码实现能力,也加深了对语音识别技术的理解。在报告中我也强调了各个方法和过程的代码实现,并将关键代码添加到附录之中以方便检阅
-
特别地,我基于课堂上所学的蝶形变换方法,实现了以 2 为基的快速傅里叶变换,并运用到了频域特征的分析之中。这让我更加领略到该算法的优美
-
根据我自行实现的快速傅里叶变换,实现了梅尔频率域的倒谱系数的计算,并根据通过梅尔滤波器之后得到梅尔频谱特征设计了基于卷积神经网络的识别算法
-
我将计算出的频谱特征视为图片,因而可以使用近年来在大规模图片分类任务上大放异彩的卷积神经网络来进行分类识别。我采用了 2014 年在 ImageNet 的比赛上获胜的VGG Net 作为我们的识别模型,并使用了批归一化和 Dropout 手段来避免过拟合,提高模型的泛化能力
2.1 预处理
首先我对数据进行了清洗。
各个同学上交的文件结构并不一致,有的是一个压缩包下包含所有文件,有的是一个压缩包中还有以自己的学号命名的文件夹,此外还有一些同学提交的压缩包是在 MacOS 上进行打包的,因此还有一个额外的缓存文件夹。这样的结构不利于我们对数据进行批量的读入。
因此我编写了程序先解压所有压缩包,然后进行深度优先搜索来遍历所有文件夹,根据文件的命名规则把所有文件提取出来,按照 data/学号/文件名.wav 的格式统一存储。同时因为需要大规模地进行复制提取,为了效率的考量,我使用多线程的方式完成了这一任务。
此外有几个文件显示已损坏而无法读取,以及一个文件录音长度大于两秒。为了数据的一致性,必须去除掉异常数据,但仅仅删除数据将导致样本不均衡的问题。为此我采用随机替换的方式,用同一个同学在同一个词下的另一个语音文件进行替换。这样就可以缓解数据缺失带来的样本不均衡的问题。
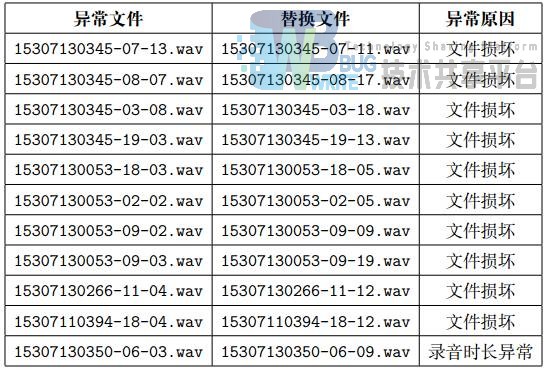
同时,考虑到最终测试时是采用集外测试的方法,理论上讲应剔除女生的数据。
在接下来的报告中,如无特殊声明,用 y0, y1 · · · , yt, · · · 来表示离散的信号构成的序列,用 sr 来表示采样率。
2.2 特征提取
2.2.1 归一化
因为数据在采集的时候声音强度并不一致,为了消除影响,我对每一段音频数据进行归一化。这里只需要对 y 使用 numpy.normailize 方法即可。
2.2.2 预加重
对读入的数据,我首先通过预加重的方法来补偿由于唇和空气导致的声音在产生和传播中高频部分的损失。预加重通常采用一个一阶的线性高通滤波器
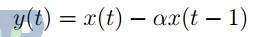
来实现,其中 α = 0.97。在代码实现上,只需要对数组进行加权差分即可。
2.2.3 分帧
一般情况下,语音信号是一种典型的非平稳信号,但是可以认为人说话的语调变换并不是是突然的,因此可假定语音信号在短时间 (10-30ms) 内是平稳的;故而在对语音信号进行分析时,我们可以将语音信号以 10-30ms 的间隔将连续的音频信号截取成一段一段来进行分析。
用 y[i : j] 来表示 yi, yi+1, · · · , yj−1,为一帧包含为 j − i 个采样点的语音信号,其时长为( j−i)/sr。
因此,当音频信号采样率为 48kHz 的时候,想要得到时长为 10-30ms 的信号帧,其应该包含480-1500 个采样点。
另外,从分帧后信号的连续性考量,一般在分帧的时候会让相邻的两帧有 30%-50% 的重叠。分帧的实现是简单的,只需要使用 python 支持的数组切片 (slice) 方法即可方便地取出一帧对应的采样点。
2.3 加窗
对于每一帧数据,我们应当强调该帧数据内中间部分的数据,并将边缘的数据进行弱化。我将使用汉明窗

作为窗函数。
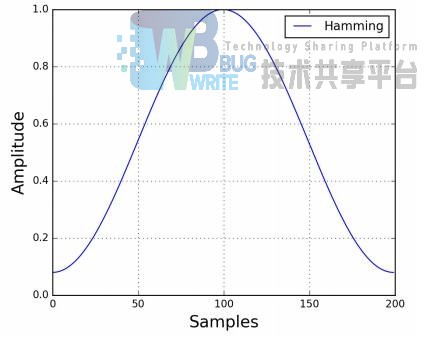
而所谓的加窗操作也就是用窗函数与一帧内的采样数据相乘
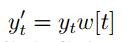

考虑之后要进行短时傅里叶变换,对每一帧数据进行加窗的理由将更加充分。观察图 2中的一帧余弦信号,可以看到其开始和结束的位置是断开的。而我们在做离散时间傅里叶变换的时候是将该帧数据在时域上无限延拓成周期信号,这将导致延拓之后的信号在帧的开始与结束会发生跳变。直接进行离散傅里叶变换将导致信号泄露的现象。如图 3所示,左边是取出开始和结束连续的一帧信号的离散傅里叶变换的结果,而中间则没有加窗直接进行变换,右边是加了汉明窗再进行变换的结果。可以观察到中间的结果在信号的主要频率周围有明显的泄露现象,导致在原始数据中不存在的频率成分出现在频率域。而增加了汉明窗后,频率泄露的现象有了明显的改善。
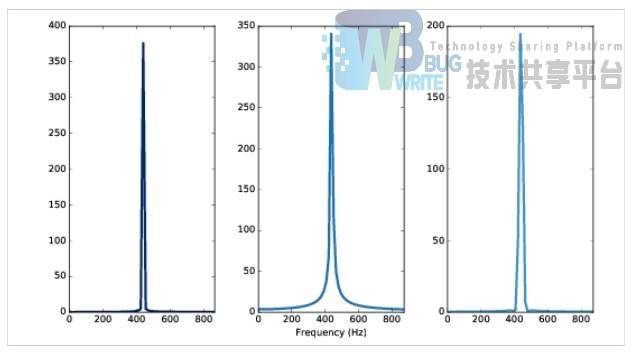
2.3.1 端点检测
为了减少非语音的信号对识别的影响,我首先通过信号的时域特征来检测出语音的端点。可以使用短时平均过零率和短时能量来进行端点的检测。
想要检测出语音信号的端点,最简单的想法就是通过信号的强度来判断,因为包含语音的信号强度会明显高于背景噪声。而短时能量就是刻画信号强度的一个有效的指标。对信号进行分帧之后,y[i : j] 的短时能量定义为
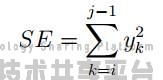
即帧内信号的平方和。但如果仅仅采用短时能量作为端点检测的指标,我们将很难检测出清音信号,从而导致语音不完全,譬如说单词”Speech” 中开始的清音就无法检测出来。因此我们引入短时平均过零率这个指标
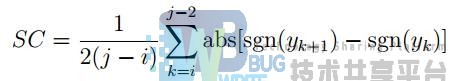
即该帧内信号通过 0 的平均次数。
因为无法检测出来的清音一般出现在单词的开始或者结束,所以我们采用以 SE 指标为主、SC 指标为辅的检测策略。首先观察到不少数据在一开始会有类似敲击键盘的的清脆噪声,导致 SE 指标较大,因此我去掉了前五帧信号;然后我设定一个阈值 E0,对于 SE > E0 的帧,可以断定其包含语音信号;取最开始判定为有语音的帧的开始和最末尾有语音的帧的结束作为粗糙的端点检测结果,再根据 SC 指标,设定一个平均过零率阈值 C0,根据粗糙的结果向前、向后扩展 SC > C0 的帧作为包含清音信号的判定条件。
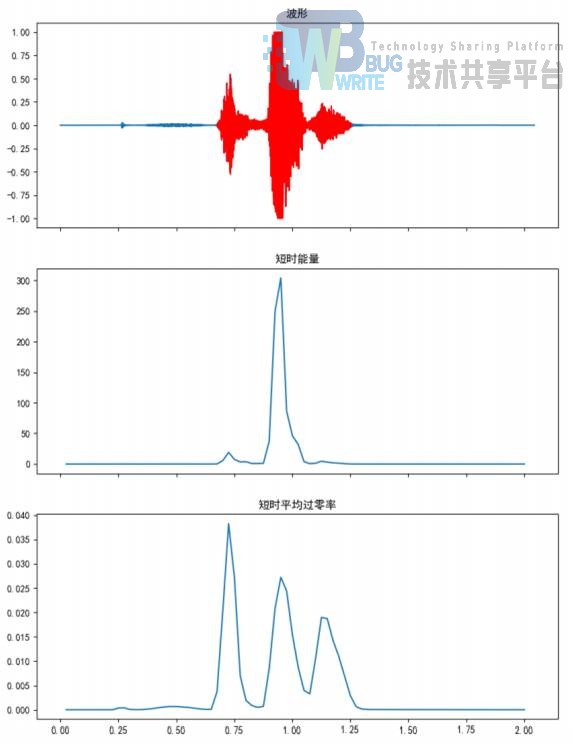
问题的难点在于阈值的设定,在多次试验后,我选择了 E0 = 0.98, C0 = 0.002 的参数,可以对大多数数据做到较好的端点检测效果。如图 4所示,上方为用红色标出检测结果的波形,中间为短时能量,下方为短时平均过零率。可以看到,如果仅仅使用短时能量进行检测,将无法测出开始的清音,而短时平均过零率的指标则将清音也一并检测出来了。
2.3.2 快速傅里叶变换
为了得到信号的频域特征,需要对每一帧信号进行离散傅里叶变换,即计算
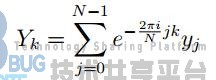
假设一帧数据的采样点数 N 是 2 的整次幂,那么
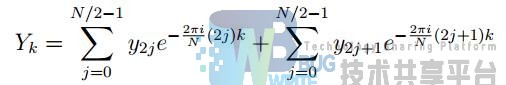
从而
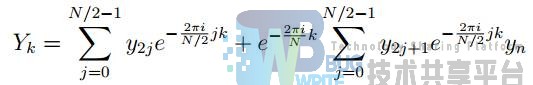
用 Ek 表示偶数下标子序列的 DFT,Ok 表示奇数下标子序列的 DFT,则 k < N/2 时

而 k > N/2 时

这样就可以按照下标的奇偶性将待变换的信号序列拆成两半,递归地进行计算,然后在从递归计算的两个子序列的结果中计算出整个序列的离散傅里叶变换。该算法被称为基 2 的 CooleyTukey快速傅里叶变换。显然该算法计算量为 T(n) = 2T(n/2) + Θ(n)。根据主定理,该算法的时间复杂度为 Θ(n log(n))。
在递归的过程中,数据的组合与流向的图样像蝴蝶一般对称而美妙,因此被称作蝶形变换。
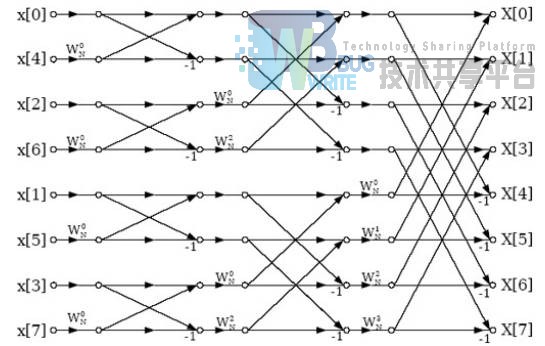
我用 python 实现了该算法,并将其利用到后续的梅尔频率域的频谱特征的计算之中。优美的算法通常在实现上也十分简洁。
2.3.3 梅尔频率域特征
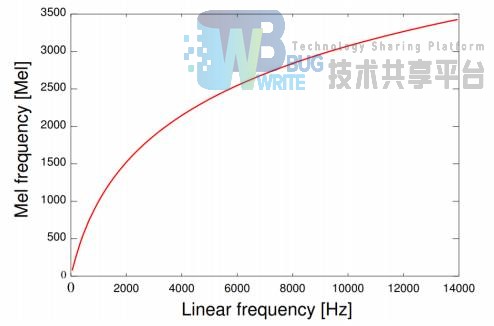
梅尔频率域的理论依据来自于人耳听觉对频率的感受。耳蜗相当于一个滤波器组,在 1000hz以下为线性尺度滤波,在 1000hz 以上为对数尺度滤波。通过 fMel = 2595 + log(1 + f/700) 可以将普通频率变换到梅尔频率尺度,观察这个变换的图形会发现在 1000hz 以下会有更高的分辨率,这和人耳对低频信号更加敏感是相符的。在变换之后的梅尔频率尺度取等间隔的带通滤波器组求倒谱即可得到梅尔倒谱。
对前述通过预加重、分帧、加汉明窗,离散时间傅里叶变换后得到的频谱变换到梅尔频率域,然后施加等间距的三角形滤波器,对滤波后的结果进行求和和取对数操作,即可得到梅尔频率尺度下的功率谱。
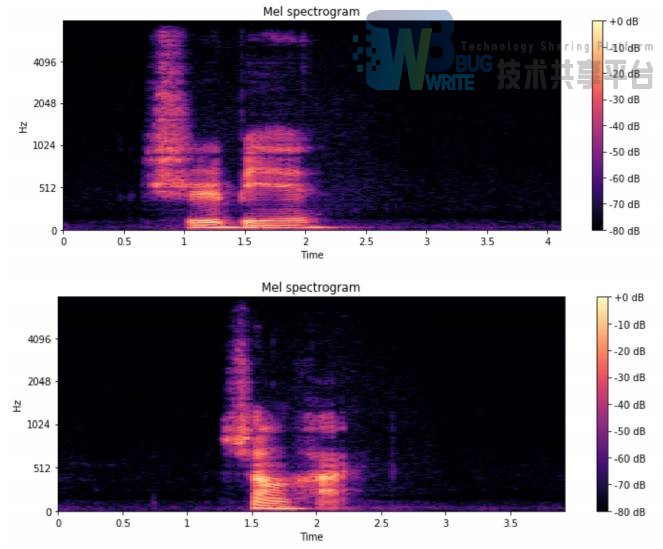
仔细观察该功率谱的结果,对于同一个词来说,在谱上的图样具有明显的图形特征。我们想到可以将其视为图片,然后利用图片的分类技术对语音进行识别。
传统上的语音识别特征会继续用离散余弦变换求出倒谱系数。余弦变换是傅里叶变换的一个变种,其结果是实数,没有虚部。离散余弦变换还有一个特点是,对于一般的语音信号,这一步的结果的前几个系数特别大,而后面的系数比较小,就可以忽略。这样就可以对特征进行降维,只需要十几个系数即可作为特征。这对于使用传统的模式识别的方法来说特别重要。
因为无论是支持向量机、高斯混合模型都需要数据的特征在各个维度上是无关的。而不必要的高维度必然导致特征的相关性,从而使得决策面变得扭曲。但使用深度神经网络的方法则不用担心这一点,因为它可以拟合出任意决策面。
至此完成了对特征的提取,接下来只需要根据特征图样对进行分类即可。
2.4 识别模型
2.4.1 模型构建
我使用了 128 个梅尔滤波器,并使用 30ms 作为分帧长度,以及 10ms 的重叠,因此最终得到的图样大小为 128 × 98。
我仿照 VGGNet 的设置,使用大小为 3 × 3 的卷积核,并构建了 8 层深度的卷积神经网络。因为经过每一层卷积之前都会对图片进行 1 × 1 的补 0 操作,所以对任意大小的图片都可以进行卷积。在经过卷积网络后,我使用一个多层感知器来作为最后的分类器。
其具体结构如下:

为了避免过拟合,我对多层感知机的神经元进行概率为 0.5 的 Dropout,并在每一层的卷积操作和非线性函数之间对进行批归一化。
2.4.2 数据加载
考虑到对模型进行训练和测试的复杂性,需要多种数据的加载方式。首先是对数据集进行划分,我需要将一部分同学的所有语音单独拿出来作为测试集,因为最终测试的时候的说话人并不在我们的训练数据中。其次是因为数据量有限,每个词只有不到 600 个的训练数据,为此我对数据进行了交叉验证的划分,采用 10 折交叉的数据划分方式。我利用 pytorch 提供的 Dataset 和 Dataloader 模块,编写了自己的数据加载器。
2.4.3 模型训练
利用 pytorch 提供的自动反向传播,利用交叉熵损失函数作为优化目标,对模型进行了训练。在一台配置为只需要迭代 5 遍测试数据集即可将模型训练至收敛。
绘制出训练的损失曲线如下图:
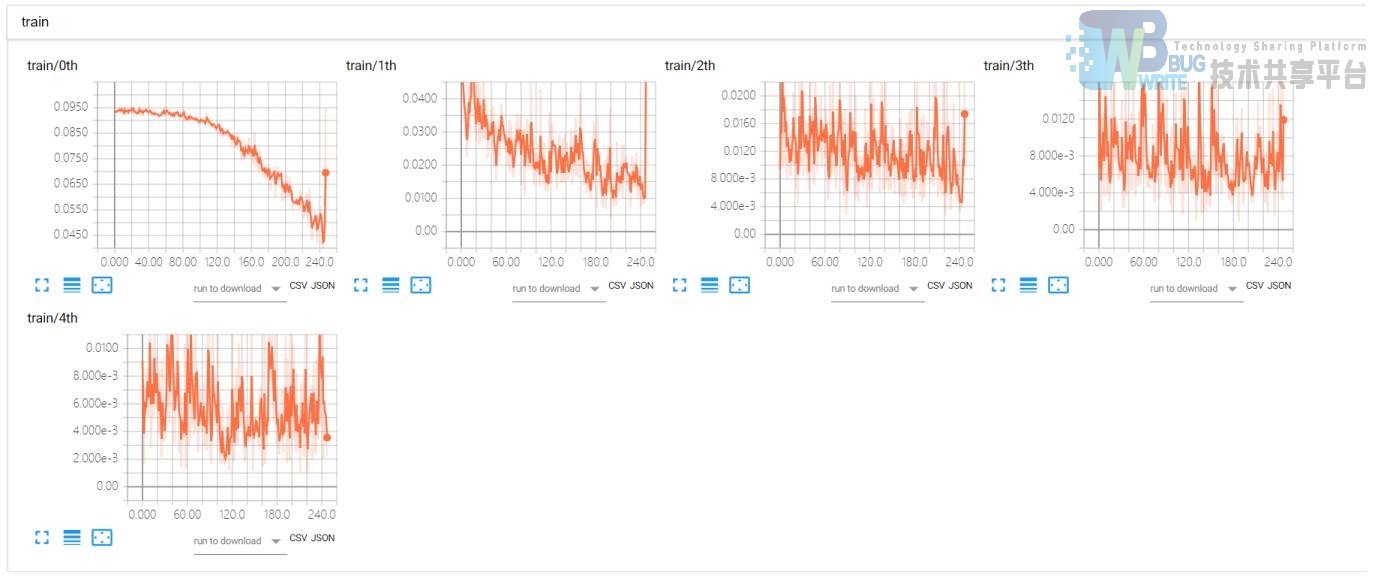
训练结束后,在训练集上能取得 99.5% 的正确率,而对于不在训练集中的说话人,也能取得98.0% 的正确率。说明该模型的确具有非常好的泛化能力。接下来我编写了交互界面,用于进行直接录音测试。
2.5 识别交互
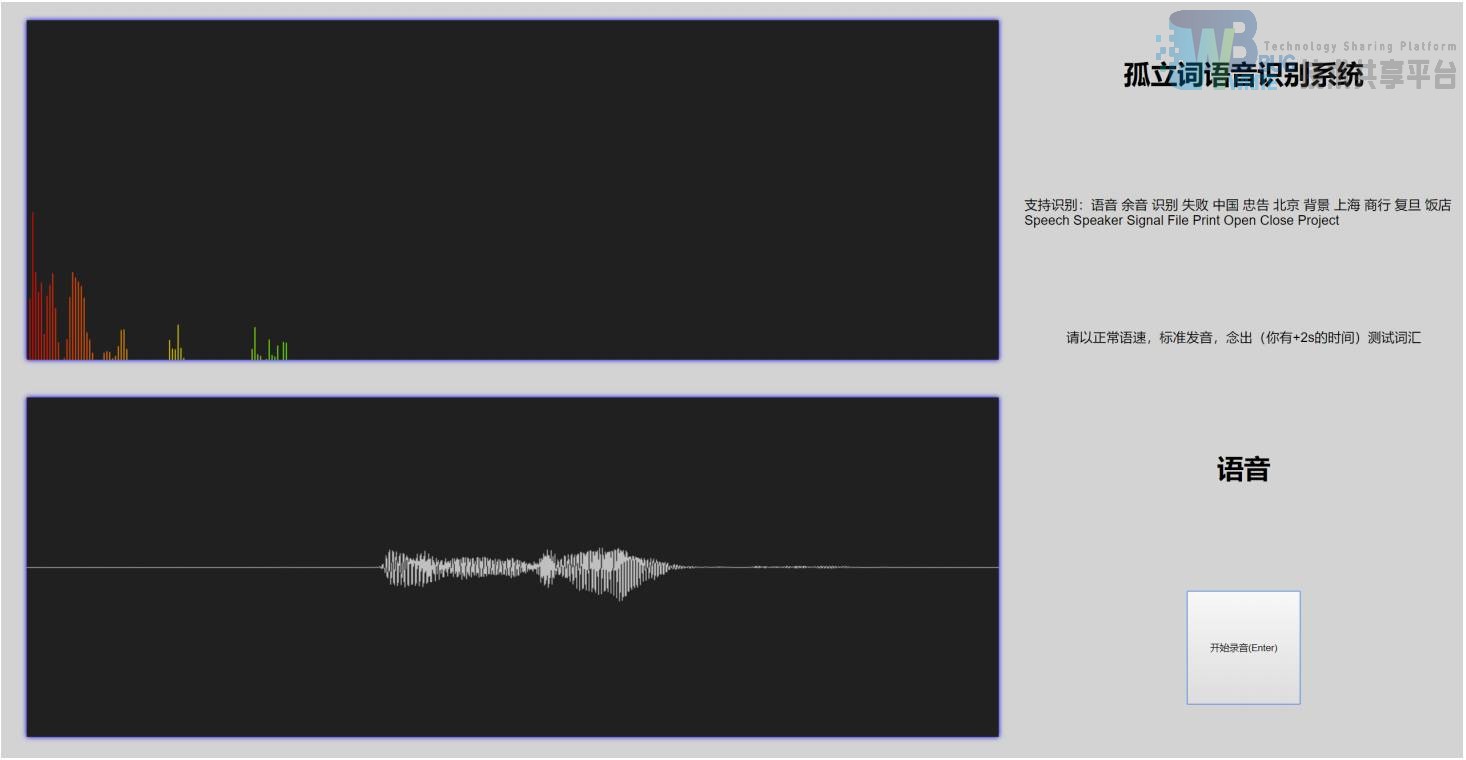
为了方便测试系统的语音识别效果,我基于我之前设计的录音采集系统进行了修改,使得我的系统可以在任何兼容的浏览器上进行测试,避免了为了测试而配置一系列复杂的环境。
2.5.1 前端界面
基于 Web APIs 技术,通过浏览器获取用户的麦克风进行音频录制。完成录制之后通过 JQuery框架使用 ajax 技术进行语音的上传和获取识别结果,再通过 Vue 框架实现的自动绑定,进行结果展示。这样可以实现不用刷新页面即可进行测试的效果,使得使用体验与桌面应用无异。
2.5.2 服务器端
为了能使用训练好的模型进行测试,我利用 flask 编写了服务端。当其接受到前端传回的语音信号后,就会构建模型,并载入训练好的模型参数,然后进行识别。完成识别后,再将结果传回到前端进行显示。
3 总结
在本项目中,我实现了一个识别效果较好的孤立词识别系统。在这一系列过程中,我编写了大量代码,即锻炼了自己的能力,又讲一学期学到的知识真正运用到了实践之中,加深了对知识的印象和理解。
参考文献
- 深度神经网络的语音识别技术研究与应用(中国地质大学(北京)·孙皓)
- 基于云边协同计算的语音识别系统的设计与实现(电子科技大学·王宇鑫)
- 基于SSM框架的语音管理平台的设计与开发(浙江工业大学·赵雨滴)
- 基于SSM框架的语音管理平台的设计与开发(浙江工业大学·赵雨滴)
- 面向领域的问答系统关键技术的研究与应用(中国科学院大学(中国科学院沈阳计算技术研究所)·王加存)
- 说话人识别系统的硬件设计及相关软件实现(吉林大学·张坤)
- 深度神经网络的语音识别技术研究与应用(中国地质大学(北京)·孙皓)
- 基于Internet的网站语音自动导航系统设计(西安电子科技大学·赵铭)
- 轻量级分布式虚假信息爬虫的设计与实现(辽宁大学·韩昱)
- 轻量级分布式虚假信息爬虫的设计与实现(辽宁大学·韩昱)
- 古代汉语虚词识别系统的设计与实现(华中科技大学·舒洁)
- 面向领域的问答系统关键技术的研究与应用(中国科学院大学(中国科学院沈阳计算技术研究所)·王加存)
- 基于语音的位置服务系统的设计与实现(东北大学·李想)
- 基于卷积神经网络的智能语音问答算法及应用(南昌大学·刘荫隆)
- 基于国产处理器平台的语音识别系统设计与实现(华中科技大学·朱帅)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码工厂 ,原文地址:https://m.bishedaima.com/yuanma/35520.html