
电子商务网站用户行为分析及服务推荐
| 申请学位: | 工学学士 |
|---|---|
| 院 系: | 计算机与控制工程学院 |
| 专 业: | 软件工程 |
| 姓 名: | 景怡乐 |
| 学 号: | 201658503102 |
| 指导老师: | 谭征(副教授) |
[摘要] 互联网时代的到来和不断发展,逐步改变了人们传统的生活方式,社会也正朝着信息化、现代化的方向大步迈进。如今当人们遇到不懂的问题,首选已经不再是向老师或者身边的朋友咨询,而是向无所不知的百度询问。当人们需要购买东西时,也不用像之前一样只能去商场,在家里就可以利用电商平台轻松完成购买。人们的日常消费行为因为电商平台变得更为方便和快捷,但是大量信息的涌入也给用户带来一定的烦恼。用户如何快速在众多相似信息和商品中找到自己真正想要得到的内容,已经变得尤为重要。本文选取北京某家真实存在的法律网站为研究对象,进行用户行为分析,通过数据分析发掘出用户的浏览倾向,并对其进行个性化的网页推荐。本系统的核心算法为协同过滤推荐,并针对其冷启动问题,通过分析网站的实际情况和常见非个性化推荐算法的性能,最终确定了合适的非个性化推荐与协同过滤推荐相结合的推荐模型,极大地提高了推荐的准确率和推荐成功率。
[关键词] 电子商务网站;用户行为分析;个性化推荐;协同过滤算法
一、绪论
1.1 课题研究的背景与意义
与传统的单一广告推荐不同,个性化推荐可以基于用户的历史浏览或购买行为向用户做出推荐,推荐算法是推荐系统的核心,直接决定了推荐系统的性能,如何根据目标网站的不同特性选取合适的推荐算法,并加以结合使得推荐结果更为精确,是研究推荐系统的首要任务。
1.1.1 课题来源于背景
随着互联网时代的到来,网络业务也随之产生,并逐渐地取代了传统业务模式。如今人们的很多行为都可以借助网络足不出户的实现,例如交话费、交水电费、购买各种商品。各大购物网站的应运而生,更是颠覆性的改变了人们的日常消费模式,而随着大量店铺和商品的涌入,在给用户带来便利的同时也带来了一些负担,最为典型的就是信息过载。大量的、各式各样的商品和服务不断出现,使用户想要找到自己真正需要和满意的商品变得越来越困难,本来是为了帮助用户节省时间的消费方式却往往使用户花费了更多的时间和精力还是没能找到自己满意的商品。如何更有效的对用户进行个性化推荐成了当前电子商务领域的热点话题。基于购物网站的研究和设计已经有很多,本文选取了相对冷门的一种电商平台——法律服务网站,对其进行用户行为分析和个性化服务推荐的设计。
总的来说,互联网中的电子商务为推荐系统的应用提供了平台,而推荐系统推荐效果的不断提高也促进了电子商务的快速发展[1]。
1.1.2 研究的目的和意义
本文选取的研究对象是某家法律电商平台,由于网站访问量的不断上升和网站内容的不断增多,用户很难从网站中及时找到自己想了解和感兴趣的相关信息,这极大地影响了用户的使用体验,导致很多用户的流失。本文决定对网站进行用户行为的探索和分析,并利用个性化推荐算法和网站的实际情况尝试对不同的用户做出个性化推荐。若能将合适的内容推荐给需要的用户,便能使用户对网站的好感度不断上升,逐步对网站产生依赖,从而形成稳定的客户源,促进企业长期的发展。
1.2 国内外研究现状
随着网络技术的不断发展,电子商务这一概念逐渐进入了很多人的生活中,无论是国外的亚马逊网站,还是国内的淘宝、天猫等购物网站都取得了很不错的效果,电商平台具有方便、快捷、高效的特点,其优越性是传统门店所无法比拟的。加上现在电商平台的安全保障和物流服务可在全国范围内配送,很多用户更乐于网上购物。而这一趋势也逐渐扩大到了各行各业,很多的企业开始将自身产品通过网络平台进行销售,电子商务化已经成为当今社会的主流趋势。
1.2.1 国外研究现状
世纪九十年代,电子商务在国外发展开来,很多人们开始进行网上购物。随着电子商务网站中商品信息数量的剧增,可供人们选择的商品越来越多,这些大量的信息进入用户的视野,对用户造成了一定的困扰。用户如何快速地找到自己感兴趣的商品已经变得尤为重要。在这种时代潮流下,便出现了搜索引擎和推荐系统。
随着 Web2.0 时代的到来,互联网技术得到了进一步的发展,特别是电商网站大量普及和应用。为了效仿传统购物超市中营销员这一角色,解决如何用机器更精准的向用户推荐商品这一难题,出现了许多著名的推荐算法。协同过滤则属于其中最为成功的算法之一,协同过滤受到了许多学者的关注并不断加以优化,如今已经在很多领域都取得了不错的成果。亚马逊是最早使用推荐系统的电子商务平台,基于物品的 ItemCF 算法(协同过滤算法)于 1998 年正式上线,这一算法将用户推向了一个电子商务领域发展的新高度[2]。个性化推荐算法陆续在各大电子商务网站中得到了应用,展现出了其显著功效。传统的、单一的推荐算法往往存在着冷启动、数据稀疏性、拓展性等问题[3]。随后,一大批优秀的学者开始对其性能进行优化并且开始研究各类推荐算法的结合使用。使用推荐系统已经成为了信息技术企业之间互相竞争的必备工具[4]。
1.2.2 国内研究现状
我国电子商务技术相比国外起步较晚,而对推荐系统的研究更是晚于国外。在国内,豆瓣网是最早开始使用个性化推荐的网站之一,它通过记录客户对于电影、音乐、书籍等的浏览历史和评价,然后分析用户的浏览喜好,从而为用户提供相应的资讯和相似作品的推荐。而提到国内的推荐系统,今日头条无非是其中的佼佼者,其独特的推荐算法能够精准预测用户喜好,极大地提高了用户的使用体验,在短短几年内就吸引了数亿的用户。除此之外,腾讯的 QQ 看点、淘宝的猜你喜欢、抖音的短视频推荐等都很好的发挥了个性化推荐的作用,且取得了很不错的效果。
目前推荐系统已成为国内学者研究的热点之一,国内研究者在资源数据处理的准确度、智能数据挖掘等涉及到推荐系统的各个方面都取得了丰硕的成果[1]。西安电子科技大学的孔德卫为了解决了协同过滤算法存在的矩阵稀疏性和可拓展性的问题提出了一种新的混合协同过滤推荐算法[5]。南京邮电大学的沈鹏和李涛中将协同过滤算法与内容属性过滤的优点结合,提出了一种改进的混合推荐算法[6]。张玉叶教授用 Python 的序列字典代替了二维数组存放稀疏矩阵,有效提高了算法的效率[7]。广州大学王敏针对个性化精度的问题,采用 K-means 算法对协同过滤进行了优化,有效提高了精度[8]。天津理工大学的石京京等人重新对物品相似度的计算做了定义,加入了物品间联系的计算,进一步提高了推荐的准确率[9]。在推荐系统中,协同过滤因其推荐范围广、算法较为简单、易于实现等优点,受到越来越多学者的关注[10]。 虽然目前和国外相比,我国的研究水平还有很大不足,但是毫无疑问,未来国内推荐系统必将在各个领域大量应用和快速发展。
二、相关理论与关键技术
2.1 个性化推荐系统概述
个性化推荐系统尚没有得到明确定义,但其实质都是由机器模拟销售人员向用户进行商品推荐的过程。个性化推荐在我们目前的生活中无处不在,我们所有的上网行为都会伴随着一系列的推荐。例如,当看完某部电影时系统会向用户推荐类似电影、当进入淘宝时系统会主动根据用户的历史行为和购买喜好推荐用户可能喜欢商品、当在知乎浏览和点赞过某篇创作,系统会主动推荐许多类似话题等。个性化推荐在提升用户浏览体验的同时也为企业带来了一定的收益。
目前,个性化推荐算法主要分为以下几类:基于内容过滤的推荐(CBF)、基于网络结构的推荐、协同过滤推荐(CF)、基于关联规则的推荐(ARB)、基于矩阵分解的推荐(MFB)等[5]。
2.2 协同过滤算法
协同过滤算法是众多推荐系统中应用最早、最为流行、最为成功的推荐算法之一。Tapestry 是最早被提出的个性化推荐系统[11],GroupLens[12, 13]则是最早被提出的个性化协同过滤系统[14]。协同过滤推荐算法的核心思想较为简单,例如,某个用户的好朋友对于某部观看过的电影评价很高并推荐观看时,该用户很有可能也会喜欢这部电影。即在具有相似兴趣偏好的用户之间进行交叉推荐[15]。
协同过滤算法可分为两类:基于用户的协同过滤(UserCF)和基于的项目协同过滤(ItemCF)[16],下面分别进行介绍。
2.2.1 基于用户的协同过滤
UserCF 算法的基本思想,当需要对用户 3 做出推荐时,先找到与用户 3 兴趣爱好相似的用户 1,然后从用户 1 感兴趣但是用户 3 没有接触过的物品中为用户 3 做出推荐,算法的示意图如图 2.1 所示。其核心计算包括两部分:
-
确定与当前用户兴趣相似的用户。
-
根据相似用户的喜好生成推荐列表。
2.2.2 基于项目的协同过滤
ItemCF 算法的基本思想:当需要对用户 1 做出推荐时,若已知用户 1 对物品 A 感兴趣,只需找到与物品 A 相似度较高的物品集合 B,然后找出物品集合 B 中用户 1 尚未接触过的产品,并对其生成推荐列表。即若是 A 与 B 两种物品的相似度较高,则对物品 A 感兴趣的用户也很大可能对物品 B 感兴趣。算法示意图如图 2.2 所示。其核心计算包括两部分:
-
物品间相似度的计算。
-
根据物品之间的相似度为用户生成推荐列表。
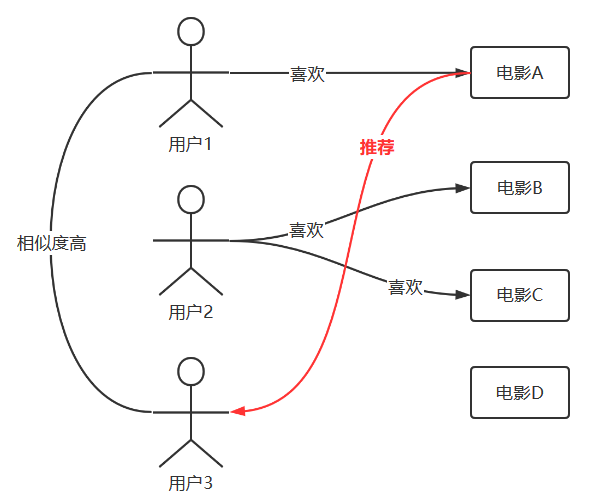
图 2.1 UserCF 算法示意图

图 2.2 ItemCF 算法示意图
2.2.3 异同点分析
从问题的角度分析,UserCF 算法解决“将当前物品推荐给哪个用户?”的问题,ItemCF 算法解决“将哪个物品推荐给当前用户?”的问题。两者的目标对象是恰好相反的,但是从推荐结果来说却是一致的。
从数据的角度分析,UserCF 算法需要维护一个庞大的兴趣相似度矩阵,当网站的用户不断增加时,计算其相似度所需的时间和空间成本都会成倍的增长。而 ItemCF 算法维护的是物品相似度矩阵,在物品数量小于用户的情况下,系统会稳定很多,相比前者更加适合电商网站。
总的来说,ItemCF 算法适合物品数远小于用户数的情景,UserCF 则相反。
2.3 物品相似度
在很多情况下,用户对物品的偏好程度并不会明确地表现出来,此时就需要根据用户的浏览记录或购买历史记录进行分析,得出用户的购物喜好,才能将相似商品推荐给用户。物品相似度则很好的解决了这一重要问题。常见的物品相似度有余弦相似度、Person 系数和 Jaccard 相似系数。
下面对其计算公式分别进行介绍。
2.3.1 余弦相似度
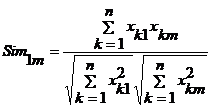
说明:结果绝对值越接近 1,相似度越高。
2.3.2 Person 相关系数
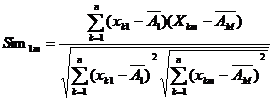
说明:结果绝对值越接近 1,相似度越高。
2.3.3 Jaccard 相似系数

说明:结果取值越接近 1,相似度越高。
三、实验准备阶段
3.1 系统需求分析
本系统旨在分析探索目标网站的用户访问习惯和找出网站的各个话题下的热点问题,并通过分析网站实际情况建立合适的以协同过滤推荐为主的混合推荐模型对不同的用户进行个性化服务推荐,提升网站的访问量和用户体验。
3.2 可行性分析
3.2.1 技术可行性
拟采用的协同过滤算法作为常见推荐算法之一,目前已经在很多领域都取得了不错的成果,而其实现方法网上也能找到很多参考。Jaccard 相似系数最适合该系统,其计算是基于已实现的用户物品矩阵的,常规方法是按照公式(3)进行计算,或者可调用库函数,但是效率都不高。这里引进一种向量化的计算方式,更高效、符合系统要求的完成相似度的计算和物品相似度矩阵的构造。
3.2.2 经济可行性
若能将合适的内容推荐给需要的用户,便能使用户对网站的好感度不断上升,逐步对网站产生依赖,从而形成稳定的客户源,促进企业长期的发展。
3.2.3 操作可行性
Python 提供了很多的插件可用于进行数据处理,PyCharm 更是很好的提高了开发效率。Pandas 库的使用极大方便了对于数据的处理,可利用其内部函数直接读取数据库,在针对大量数据的问题上,Pandas 也提供了分块读取的功能。
3.3 数据集简介
本文采用的数据集来自北京某家法律网站一段时期内的用户访问数据,该数据集包含有 837450 条用户访问记录,包含了用户 ID、用户所访问网址、网址关键字、访问时间、访问来源等多个属性。
3.4 实验环境说明
- 操作系统:Ubuntu 18.04.2 LTS
- 编程环境:Python3.6.9
- 开发工具:PyCharm 2019.3.3 (Community Edition)
- 数据库服务器:MySql5.7.29
3.5 模型评价标准
本文将数据划分为训练集和测试集时采用随机划分的方法,保证测评结果的可靠性。
但是随机性实验的不确定性因素较多,特别是在数据集不足够大的情况下,对于结果的影响会比较大,为了避免过拟合现象,应该进行多次相同重复试验并对某些明显偏离预期的实验结果进行人为的剔除,而最终的评测指标应为多次实验结果的平均值。
本系统采用多种不同的方式来对推荐模型的性能进行评估。下面分别进行介绍。
- 准确率(Precision):用户喜欢当前推荐网址的概率。
若向用户推荐了 5 个网址,其中只有 2 个是用户感兴趣的,那么其 Precision 值就是 40%。
其计算公式为:
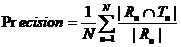
- 召回率(Recall):用户喜欢的网址被推荐的概率。
若向用户推荐了 5 个网址,其中有 2 个是用户感兴趣的,但是用户感兴趣的共有个网址,那么其 Recall 值就是 20%。其计算公式为:
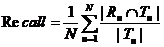
说明:在上述公式(1)(2)中,Rμ表示用户 u 的推荐网址集合,Tμ表示用户 u 真正感兴趣的网址集合。
- F1指标(F1-score):综合的评价指标,计算公式为:
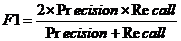
推荐成功率:若生成的推荐列表中有一个成功被用户点击,则视为推荐成功。比如给用户推荐了三个网址,只要其中有一个是用户真正喜欢的,那么这次推荐就可视为是有效推荐,该指标针对推荐总体效果而言。
个人认为推荐准确率这一指标对目标网站的推荐具有重要的意义,只要推荐的 K 个页中,能有一个被用户成功点击,就达到了推荐的效果。而当用户跳转到新的页面后,接下来的推荐就会由下一次的算法进行生成,也很好的利用了 ItemCF 算法的本身特点。推荐网页的个数 K 不应该太多,太大量的推荐是没有意义的,也容易让用户产生反感,适得其反。
四、系统具体实现
该系统可分为四个模块,如图 4.1 所示。具体实现过程如下。
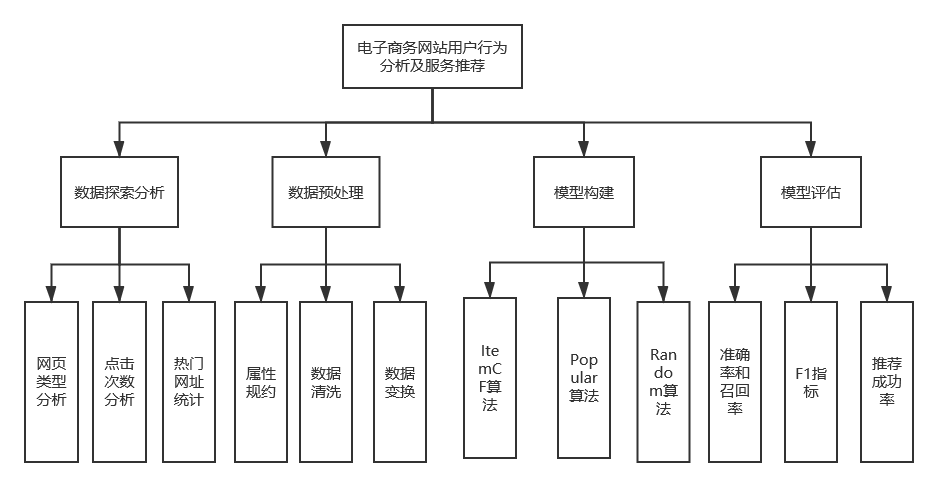
图 4.1 功能模块图
4.1 数据探索分析
对初始的用户访问数据集进行探索分析,确定用户访问行为的特点和用户感兴趣的热点话题。下面分别对网页类型、网页点击次数和网页排名进行探索分析,探索用户访问行为的总体特点和规律。并通过进一步的数据分析,解释其可能出现的原因和拟定解决方案。
4.1.1 网页类型分析
根据数据集中网页类型(fullURLld)这一属性的前 3 位数字(该属性本身有 6 或 7 位数字),可得出每个类型网页的浏览数和其占比,其结果如图 4.2 所示。
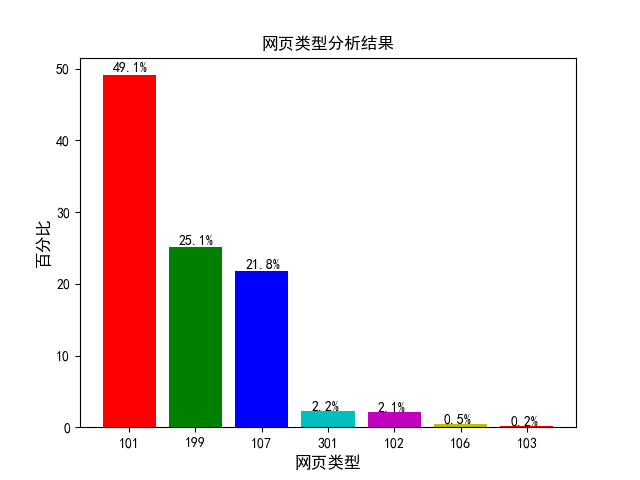
图 4.2 网页类型分析结果
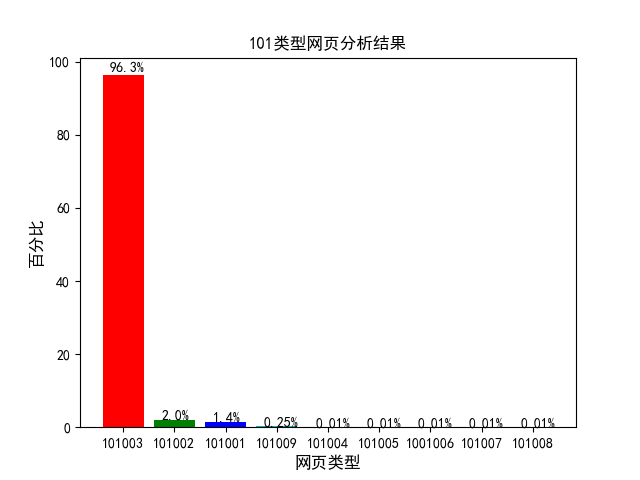
图 4.3 101 类型网页分析结果
通过图 4.2 可看出,浏览量比较多的三中网页类型分别为 101、199、107。分别对应咨询相关、其他类型和知识相关网页。根据网页类型(fullURLld)对其分别进行更详细的分析,其结果如图 4.3 所示。通过图 4.3 可看出,在网页类型 101 中,占比最多的为 101003,其对应的网页类型为咨询内容页。接着是 101002 和 101001,分别对应咨询列表页和咨询首页。
而 107 和 199 类型的网页都是只有一个内部类型,那么就要通过其他办法进行内部划分。例如按照网址的详情进行正则匹配进行划分,结果如图 4.4 所示。或依据网页关键词进行划分,结果如图 4.5 所示。
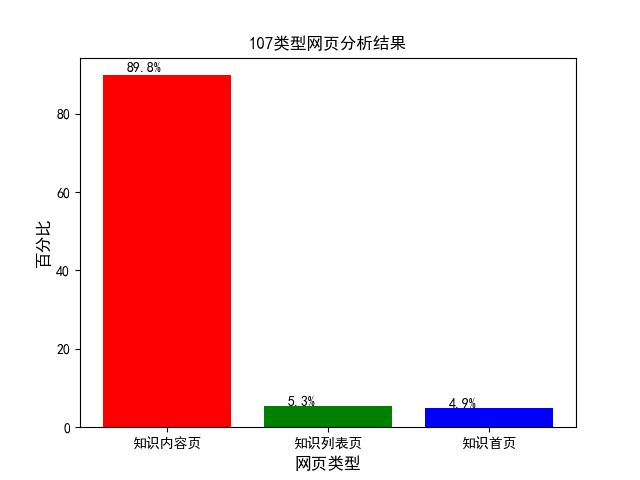
图 4.4 107 类型网页分析结果

图 4.5 199 类型网页分析结果
通过图 4.5 可轻易发现在 199 类型中有点大量带有‘?’的网址,利用其网页关键字信息对其进行进一步分析,结果如图 4.6 所示。
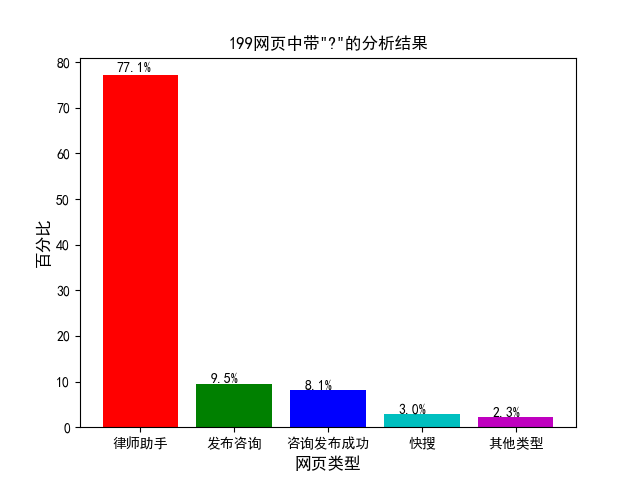
图 4.6 199 网页中带“?”的分析结果
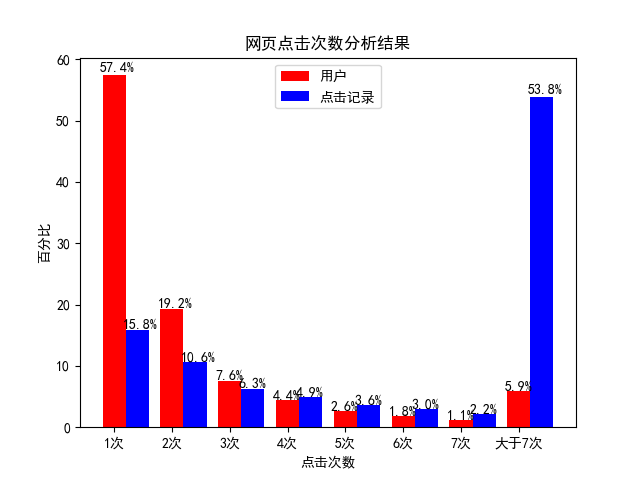
图 4.7 网页点击次数分析结果
结论:在众多类型的网页中,用户对咨询和知识相关的内容最感兴趣,应该着重将该类网页推荐给用户。在后续系统中,将着重对这些内容进行模型的构建和分析。
4.1.2 点击次数分析
统计用户浏览网页次数的情况,结果如图 4.7 所示,可得出两个结论。
-
结论一:大约 20% 的用户,为网站提供了 70% 的浏览量。(大体上满足二八原则)。
-
结论二:有 76.6% 的用户点击不超过两个网页。经验证发现,这些用户都是通过百度等搜索引擎进去的某个问题详情页,在找到或者未找到想要的答案后便离开了。如何通过向新用户推荐其感兴趣的网页,让这些用户多在网站内停留一会,已经成为当前急需解决的问题。
4.1.3 热门网址统计
根据不同类别对网页的流行度进行分析,得出用户比较感兴趣的话题。
例如,婚姻类型的热点话题分别为离婚协议书的写法、最新产假规定和中国婚姻法规定。咨询类型的热点话题分别为火车和高铁上是否可以带酒,收入证明的写法和最低工资标准。热点话题往往会得到大多数人的青睐,可能会在后面的推荐中取得很不错的效果。
4.2 数据预处理
4.2.1 属性规约
由于初始数据集中数据量特别的庞大,属性也很多,但是真正对研究有用的属性并不是很多,所以在预处理开始前,便只将对研究有用的属性保留并导出生成新的数据集,舍弃其余没用的属性。经分析,模型需要的属性有用户的真实 IP(realIP)、网址(fullURL)、网址类型(fullURLID)和网页标题(pageTitle)。
4.2.2 数据清洗
在探索分析的过程中发现了许多不适合参与推荐的网址,需要将这些网址提前删去。数据清洗的规则和结果如表 4.1 所示。
表 4.1 数据清洗规则表
| 删除数据规则 | 删除数据记录 | 百分比 |
|---|---|---|
| 律师助手数据 | 54927 | 0.07 |
| 咨询发布成功数据 | 5220 | 0.01 |
| 中间类型网页数据 | 22 | 0.00 |
| 不包含 lawtime 关键字 | 81 | 0.00 |
| 非 HTML 类型数据 | 106258 | 0.13 |
| 非婚姻类型数据 | 639645 | 0.78 |
| 重复浏览记录数据 | 14646 | 0.02 |
由于数据量太大,使得后面的工作很难进行,决定选取婚姻类型的话题进行接下来的工作,也就是说在预处理阶段筛选婚姻类型数据,可以在模型构建阶段极大的减少算法的时间复杂度和减轻计算机的硬件负担。
4.2.3 数据变换
经过探索分析发现,存在许多带“?”的网址和存在翻页功能的网址,即不同的网址对应相同的内容。若是直接将这类网址在清洗阶段删除掉,会导致损失大量的有效数据,对后面的研究产生一定的影响,所以这类网址应该对其进行还原并进行去重操作。也就是说,直接把存在翻页的网页第二页内容推荐给用户显然是不合适的,因此需要从目标网页的第二页还原到第一页(首页)。
4.3 模型构建
本系统采用的核心算法为 CF 算法,并基于目标网站的特性(用户多、物品少),选择使用 ItemCF 算法。而且由于目标网站的用户行为只有浏览与否,而没有像其他电商网站的购买、评分和评论行为,也就是说不存在显式的兴趣偏好,所以在相似度的计算方面采用最合适的 Jaccard 相似系数。其工作流程图如图 4.8 所示。

图 4.8 ItemCF 算法工作流程图
4.3.1 数据集的划分
经过数据预处理的婚姻类型数据,共包含 16651 条访问记录。根据选取的 N 值(N 为提前设置好的用户最少访问网页个数,当用户访问网页数大于 N 时才可入选模型数据集,例如若是某个用户只访问了一个网页,那么便无法进行后续的模型学习和测评,这类数据属于无效数据)对数据进行筛选,然后将其按照一定的比例随机地划分为训练集数据和测试集数据,分别用于模型的学习和性能评测。
4.3.2 测试集用户字典的构造
为了方便对模型推荐结果的评测,构建测试集用户网址浏览字典。其 Key 值对应用户的 IP,Values 值对应此用户访问过的所有网址。例如表 4.2 所示。
表 4.2 用户网址浏览字典
| Key | Values |
|---|---|
| 用户 8 | 网址 A、网址 B、网址 C |
| 用户 9 | 网址 C、网址 A |
| 用户 10 | 网址 E、网址 B、网址 A、网址 D |
4.3.3 用户物品矩阵的构建
对训练集的用户数据构造用户物品矩阵,例如表 4.3 所示。
表 4.3 用户物品矩阵
| 网址 A | 网址 B | 网址 C | 网址 D | 网址 E | |
|---|---|---|---|---|---|
| 用户 1 | 1 | 1 | 0 | 0 | 1 |
| 用户 2 | 0 | 1 | 0 | 1 | 0 |
| 用户 3 | 1 | 1 | 1 | 1 | 1 |
| 用户 4 | 1 | 1 | 0 | 1 | 0 |
| 用户 5 | 1 | 1 | 0 | 0 | 1 |
| 用户 6 | 0 | 0 | 0 | 1 | 0 |
| 用户 7 | 1 | 0 | 0 | 0 | 0 |
4.3.4 物品相似度矩阵的构建
依据上一阶段的用户物品矩阵和公式(3),很容易可以计算出物品相似度矩阵,结果例如表 4.4 所示。
表 4.4 物品相似度矩阵
| 网址 A | 网址 B | 网址 C | 网址 D | 网址 E | |
|---|---|---|---|---|---|
| 网址 A | 0.00 | 0.67 | 0.20 | 0.29 | 0.60 |
| 网址 B | 0.67 | 0.00 | 0.20 | 0.50 | 0.60 |
| 网址 C | 0.20 | 0.20 | 0.00 | 0.25 | 0.33 |
| 网址 D | 0.29 | 0.50 | 0.25 | 0.00 | 0.17 |
| 网址 E | 0.60 | 0.60 | 0.33 | 0.17 | 0.00 |
4.3.5 推荐列表的生成
有了上述的物品相似度矩阵,便可轻易的找出与当前访问网址相似度较高的前 K 个网址,对用户生成推荐列表,例如表 4.5 所示。
表 4.5 推荐列表
| 访问网址 | 推荐网址 1 | 推荐网址 2 | |
|---|---|---|---|
| 用户 8 | 网址 A | 网址 B | 网址 E |
| 用于 9 | 网址 C | 网址 E | 网址 D |
| 用户 10 | 网址 E | 网址 A | 网址 B |
4.4 模型测评
借助之前构建好的测试集用户浏览字典,分别从 Precision、Recall、F1-score 和推荐成功率对当前模型进行评估。上述测评结果如表 4.6 所示。
表 4.6 测评结果
| 用户 8 | 用户 9 | 用户 10 | 平均值 | |
|---|---|---|---|---|
| Precision | 0.50 | 0.00 | 1.00 | 0.50 |
| Recall | 0.50 | 0.00 | 0.67 | 0.39 |
| F1-score | 0.50 | 0.00 | 0.80 | 0.43 |
| 推荐成功率 | 1 | 0 | 1 | 0.67 |
五、模型测试与总结
很明显,上述 ItemCF 算法有个致命的缺陷:若是当前用户浏览的网址在已知的物品相似度矩阵中找不到,那么便不存在与其相似的物品(网址),推荐也便无从谈起。那么便需要与非个性化推荐进行结合使用,这里使用了两种比较常见的非个性化推荐算法:Popular 算法与 Random 算法。
-
Popular 算法:按照当前话题下网址的流行度,找到用户没有浏览过的前 K 个热门网址,为用户生成推荐列表。
-
Random 算法:随机的挑选当前话题中用户没有浏览过的 K 个网址,为用户生成推荐列表。
通过大量、随机的实验发现,Random 算法的各项评测指标都要远远低于 ItemCF 算法和 Popular 算法,这也是意料之中的。在物品很多的情况下很难通过随机化推荐的方式为用户推荐到满意的内容,但是该推荐算法可以提高冷门物品(网址)的曝光率,在某种特定条件下可以适当采用。而 Popular 算法的表现则超出预期的好,在各项指标上甚至超越了 ItemCF 算法。究其原因,很可能是因为当前的物品相似度矩阵的规模还不够大,数据集不够全面,还没有发挥协同过滤算法最大的性能。加上由于目标网站的性质和人们的行为特点,比较热门的内容往往会得到更多人的关注,所以可利用 Popular 算法解决 ItemCF 算法的冷启动问题。
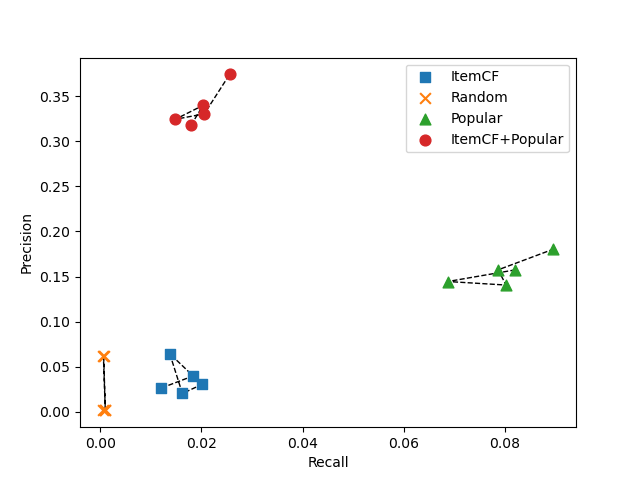
图 5.1 准确率-召回率图
图 5.1 和图 5.2 是多次随机性实验中较为典型的结果,由图 5.1 可看出,Popular 算法在 Recall 和 Precision 指标上甚至都要优于 ItemCF 算法,这是超出预期的。而将 ItemCF 算法与 Popular 算法结合后可以极大的提高推荐的 Precision,而其 Recall 相比较 ItemCF 算法也有一定的提升。由图 5.2 可以看出,随着推荐个数 K 的提升,各个算法的推荐成功率都大体呈上升趋势,而 ItemCF 算法与 Popular 算法的结合推荐,可以使当前的推荐成功率进一步提升,对于网站的实际应用来说,该提升是极为重要和有意义的。

图 5.2 推荐成功率图
由于给新用户一开始推荐的是热门网址,加上新用户也倾向于热点话题的浏览,而老用户才会浏览一些比较非热门的网址。在 ItemCF 算法中,两个网址同时被浏览的次数越多,则其相似度就越高,这就可能导致由于某几个热门网址同时被一些新用户浏览,其相似度就会很高,那么系统会总是将这些网址推荐给用户,对于老用户的使用体验便很不好,因此需要对相似度的计算公式(3)进行进一步的改进,改进后相似度的计算公式为:
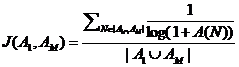
最终确立的推荐模型工作流程图如图 5.3 所示。(物品相似度矩阵已提前构造完毕)
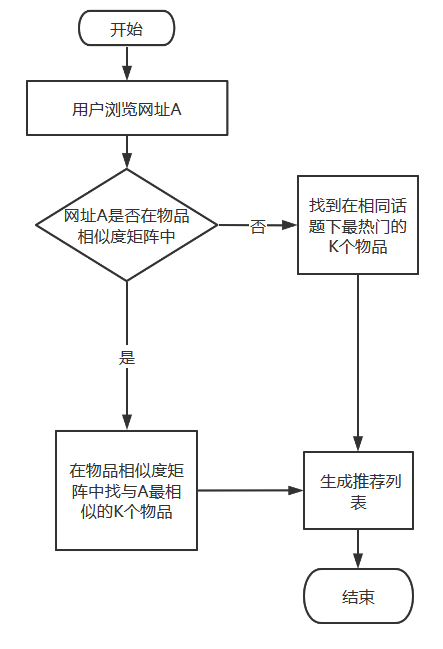
图 5.3 最终推荐流程图
经过上述的分析,已经确立了合适的推荐模型。当用户浏览网址时,首先在物品相似度矩阵中查找此网址,若存在,则直接根据相似度进行推荐。若是不存在,那么就找到在相同话题下最热门的 K 个物品,为用户生成推荐列表即可。该模型不仅可以解决 ItemCF 算法的冷启动问题,而且在各项性能指标上都取得了可观的提升。
六、结束语
从收集相关资料确定毕设题目,到开始学习相关算法理论知识,再到逐步动手编程实现系统,直到后面系统的不断测试与完善。这段时间是漫长且枯燥的,有时连续好几天都在研究同一个问题却一无所获,有时因为某个小小的 Bug 没有找到整天心情低落。系统的开发过程中难免会遇到一些问题,有本身对理论知识的理解障碍,也有具体实现上的技术难题,而有时候甚至遇到奇奇怪怪的电脑环境问题。好在经过自己的不懈探索和老师同学的悉心帮助,这些问题都一一得到了解决,在困扰了自己好几天的问题突然得到解决时,这种欣喜和放松的心情是无法言表的。在本次系统的开发过程中,逐渐的体会到了 Python 之所以会在大数据时代如此热门的原因,也了解了日常随处可见的一些推荐的工作机制。
这次的毕设,我最大的收获有两点,一是学到了许多热门推荐算法相关的知识和初步掌握了 Python 这一编程语言。二是自己的心态得到了进一步的锻炼,在面对问题时能够不气馁,及时的调整心态和思路。这也是我觉得对于编程人员最为重要的一点,在开发过程中出现一些 Bug 是很正常的事情,要勇于面对 Bug,善于找出 Bug,乐于解决 Bug。
由于自身能力的欠缺和数据集的限制,系统至今仍有许多不足之处,比如推荐模型的具体性能还需要在实际的用户使用中得到进一步的在线测试,目前只进行了离线测试。又比如基于流行度的推荐可能对于新用户效果较好,对于老用户来说应该再尝试其他推荐算法与协同过滤推荐的结合,来达到更好的用户满意度。这都是系统在未来应该完善解决的问题。
七、致谢
今年无疑是学习生涯中经历过最漫长的一个假期,由于肺炎疫情的影响,到现在也没能开学。庆幸各项工作都在正常进行,因为本次毕设的工作全程在家进行,在相关资料的搜集方面有挺大的困难,好在学校及时的推出了网页版 VPN,让我们在家里就能轻松的访问校园网里提供的各类学习资料,这对本次研究的意义是巨大的。
本次毕设最应该感谢的是我的导师谭征老师,从系统的开题阶段到最后的评测阶段,谭老师都给了我极大的帮助,并定期督促我的研究进程,毕竟我在家的时候总会更容易变得懒惰。有时候某个概念难以理解,谭老师会耐心全面的进行讲解,特别是关于评测指标的计算,由于我一开始总是着眼于现成的公式,好几天想不明白具体如何套用到自己的系统中进行计算,谭老师通过概念解释和实际举例让我明白了其实质的含义,并教导我不必拘泥于公式本身,这句话对我的影响是巨大的。其次应该感谢的我的父母,在家的这段时间对于我需要安静学习环境的理解和支持。最后还应该感谢同组的各位同学,大家在毕设过程中不断地交流和互相学习,才使这段枯燥的代码生活变得有丰富多彩,特别是郭聪同学、姜淇瀚同学和闫春相同学在此过程中对我的知识分享和互相鼓励。
八、参考文献
- 张恒玮. 基于协同过滤技术的电子商务推荐系统的研究与实现[D]. 华北电力大学, 2012.
- 颜颖. 个性化推荐系统在电子商务中的应用研究[J]. 太原城市职业技术学院学报, 2019(11):35-37.
- 吴汉. 基于混合过滤的推荐算法研究及其应用[D]. 南京邮电大学, 2018.
- 董文远. 基于混合过滤的推荐系统开发研究[D]. 吉林大学, 2011.
- 孔德卫. 基于协同过滤混合推荐系统的研究与实现[D]. 西安电子科技大学, 2015.
- 沈鹏, 李涛. 混合协同过滤算法在推荐系统中的应用[J]. 计算机技术与发展, 2019,29(03):69-71.
- 张玉叶, 宿超. 基于 Python 的协同过滤算法的设计与实现[J]. 山东广播电视大学学报, 2019(02):82-85.
- 王敏. 基于协同过滤的电子商务个性化推荐系统设计和实现[D]. 广州大学, 2019.
- 石京京, 肖迎元, 郑文广. 改进的基于物品的协同过滤推荐算法[J]. 天津理工大学学报, 2019,35(01):32-36.
-
项阳,徐浩楠,赵显基.近十年协同过滤研究热点和前沿分析[J].产业创新研究,2020(06):86-87.
-
Goldberg D, Nichols D A, Oki B M, et al. Using collaborative filtering to Weave an information TAPESTRY[J]. Communications of the Acm, 1992,35(12):61-70.
- RESNICK P. GroupLens : An open architecture for collaborative filtering of netnews[J]. Proc Cscw, 1994.
-
Resnick P, Iacovou N, Suchak M, et al. GroupLens: An Open Architecture for Collaborative Filtering of Netnews[J]. 1994.
-
吴步祺. 电子商务推荐系统中协同过滤技术的研究[D]. 南昌大学, 2010.
-
张琳. 电子商务网站个性化推荐的多样性对推荐效果的影响研究[D]. 北京邮电大学, 2017.
-
布海乔, 高媛.基于协同过滤技术的电子商务推荐系统[J]. 电子制作, 2013(17):91.
参考文献
- 基于中小型电商平台的个性化推荐系统建模(华北电力大学(北京)·梁德祥)
- 基于Spark电商用户行为数据的分析与研究(沈阳师范大学·叶力铭)
- 基于个性化推荐的在线购物系统的设计与实现(华中科技大学·张云霄)
- 基于用户行为数据的网络商城监控预警系统的分析与实现(首都经济贸易大学·温程伟)
- 基于Hadoop与Mahout的商品推荐系统的设计与实现(南京大学·徐思)
- Web数据挖掘在电子商务推荐系统中的应用研究(山东师范大学·房晓南)
- 基于Spark电商用户行为数据的分析与研究(沈阳师范大学·叶力铭)
- 基于HADOOP的电商实时用户行为分析系统(上海交通大学·赵东昕)
- 基于个性化推荐的在线购物系统的设计与实现(华中科技大学·张云霄)
- 基于个性化推荐的在线购物系统的设计与实现(华中科技大学·张云霄)
- 基于HADOOP的电商实时用户行为分析系统(上海交通大学·赵东昕)
- 基于数据挖掘的个性化推荐系统的研究与设计(南昌大学·汪毅峰)
- 基于用户行为的日志分析系统的研究(吉林大学·范俊广)
- 基于大数据技术的用户网购行为精准分析方法研究(北京理工大学·姜玉婷)
- 基于Spark电商用户行为数据的分析与研究(沈阳师范大学·叶力铭)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设驿站 ,原文地址:https://m.bishedaima.com/yuanma/35729.html









