基于多源数据融合的 POI 智能推荐
引言
针对交通事故频繁发送的今天需要分析下交通事故发送的原因和造成损失的因素等等。
关键技术方案
[介绍采用的关键技术方法、原理、机理、算法、模型等。]
随机森林
利用随机森林可以对数据处理有好的结果,因为是一个多分类器的模型,所以无论是拟合效果和最后的结果还是都不错的。
随机森林就和他的名字一样,是一个森林一样的,我了解到的一种是他会建立很多的决策树分类器来做分类。然后在最后汇总效果好的。他会分袋内数据和带外数据。它会随机提取一些属性和一些数据,进行决策树的建立,然后在对建立的结果。
在随机森林中某个特征 X 的重要性的计算方法如下:
对于随机森林中的每一颗决策树,使用相应的 OOB(袋外)数据计算它的袋外数据误差,记为 errOOB1。
随机地对袋外数据所有样本的特征 X 加入噪声干扰(就可以随机的改变样本在特征 X 处的值),再次计算它的袋外数据误差,记为 errOOB2。
假设随机森林中有 Ntree 颗树,那么对于特征 X 的重要性 = ∑(err00B2-errOOB1)/Ntree,之所以可以用这个表达式来作为相应特征的重要性的度量值是因为:若给某个特征随机加入噪声之后,袋外的准确率大幅度下降,则说明这个特征对于样本的分类结果影响很大,也就是说它的重要程度比较高。
选择决策树的最主要原因是,相对于单独的分类器,看上面的描述可以知道泛华拟合好的同时不用担心过拟合的情况。相对于神经网络这种黑盒式的感知机模型,有着良好的解释性,可以知道那些属性影响如何。
用处: 对一些交通损失程度做一个预测,通过车流量对交通事故次数程度做一个预测。
经纬度转化
经纬度,首先经度是南极到北极的地球外表连线,范围是-180~180.维度是平行于赤道的一个外围,和地心的连线。范围为-90~90。
经纬度计算公式:这个可以看成球面上的 2 点求距离。这个时候我们需要假想第三个点,那就是和他有一个维度相同的点。计算的时候,分别计算统一经度下维度的差别,就是(2 pi 6371*角度差)/360=distance
维度相同求经度的距离:首先求同求圆环半径 r1=r cosx,这个时候在套用上面的公式(2 pi r1 角度差)/360=distance。这样就有了经纬度计算距离的关系式了。
聚类
[简要介绍本项工作涉及的关键技术方案]
通过对是事故点计算,整出一个范围内事故点的数目。
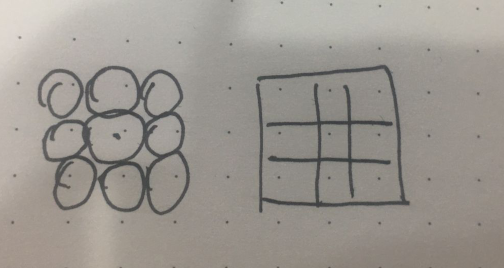
思路: 一开始我准备用一个一个的去填充他,后来觉得会有一部分的,空间没有背覆盖或者需要在添加一个再去覆盖,这样就有了多余的区域.如图上那个讲一个区域划分为等大的多个小圆,然后统计小圆内事故的数目。然后我在想通过正方形去覆盖。这样开始是不错的,因为全覆盖没有多余的空间覆盖,可以搜索区域。不过想了想还是转化了下思路,因为覆盖这个问题,如果我只做一次小范围圈存,那其实么那么多讲究,只需要全部覆盖就可以了。但是如果我需要将这些小的单元合并了。这个时候我就把这个问题划分成了一个每一个小的正方形都有一个中心点,他的中心点就是他的重要属性,这样我们视野就变化成了,我们没有范围的限制,只有这些点的限制。然后计算的方式就是先确定这些点在那 4 个中心点内,然后求最近的一个点。当然,之前也说了可以直接用正方形代替,所以我们可以将这个过程想成正方形区域内问题。可能感觉这 2 个是同一个东西。不过我是这么理解的。第一种正方形区域化,单纯的只是一个装载过程,第二个点的形式,我可以选择很多种计算事故点距离我这个中心点距离的方式,不过我选择的是正方形范围内取值。相当于把这个过程拆分成了 2 个步骤。
为啥需要这么做,其实也是个假想,因为我很多没有实现,哈哈哈。其实可能感觉起来很简单,但是我确实想了很多,比如很多实际问题。首先有一个假设,那就是我能划分的足够小,这个足够小是一个需要拿捏的过程,我没有计算出合适的范围。先假设这个存在,那么这一个点我们就把他叫做整个地图的基准点 base_point。然后我们没划分一个范围需要有一个中心点,center_point。细分的好处在哪里,那就是完全可以合并那些基准点。我可以把多个基准点合并在一起如果他们是类似的化,这个地方就是如果一个区域范围很大,没办法一个范围容纳。这个区域划分是一个什么思路了,我感觉可以通过 bfs 搜索其他的相邻的点,然后计算 2 者之间事故点的差别是否可以容许。这个计算就很需要讲究了如果他是一个低间隔下降的,那肯定会被划分在一起,所以这一块的设计就需要一个整体化去和的过程,怎么理解这个过程了,我想的是优先队列和 dfs 结合。然后求整体的方差去绝对是否需要下一个点。这样我觉得就算是一个环形范围的区域也可以找的出来,当然这个需要避免环的问题。然后这一部将合并的区域一起做一个标识,我们可以首先对基准点范围内所有的事故次数做一个统计,然后进行一个分类,比如 0~10 分为 1,10~20 分为 2。这样我们还可以对同一个 2 个不同的中心点区域进行一个分析。我们可以通过计算这些区域点的分布情况来计算相似度。这个用处就很大了,计算城市不同区域的结构相似度,当然这是假设,因为我也没做实验。
实验数据
有 2 张表
1 表记录事故(31 个属性)Accident_Index,Location_Easting_OSGR,Location_Northing_OSGR,Longitude,Latitude,Police_Force,Accident_Severity,Number_of_Vehicles,Number_of_Casualties,Date,Day_of_Week,Time,Local_Authority_(District),Local_Authority_(Highway),1st_Road_Class,1st_Road_Number,Road_Type,Speed_limit,Junction_Detail,Junction_Control,2nd_Road_Class,2nd_Road_Number,Pedestrian_Crossing-Human_Control,Pedestrian_Crossing-Physical_Facilities,Light_Conditions,Weather_Conditions,Road_Surface_Conditions,Special_Conditions_at_Site,Carriageway_Hazards,Urban_or_Rural_Area,Did_Police_Officer_Attend_Scene_of_Accident,LSOA_of_Accident_Location,Year(很多属性我都没看懂)
2 表记录所有公路的起点终点,车流量属性等。AADFYear,CP,Estimation_method,Estimation_method_detailed,Region,LocalAuthority,Road,RoadCategory,Easting,Northing,StartJunction,EndJunction,LinkLength_km,LinkLength_miles,PedalCycles,Motorcycles,CarsTaxis,BusesCoaches,LightGoodsVehicles,V2AxleRigidHGV,V3AxleRigidHGV,V4or5AxleRigidHGV,V3or4AxleArticHGV,V5AxleArticHGV,V6orMoreAxleArticHGV,AllHGVs,AllMotorVehicles,Lat,Lon
- 具体属性解释可以看连接
- 实验环境
- [包括使用的硬件、软件(服务器/客户端操作系统,服务器、数据库、虚拟机等支撑软件)
Windows 10,python,MySQL
Ubuntu16.04
实验步骤
事故严重程度
数据清理
将所有属性进行一个筛选,如果有一项的出现次数大于 70% 就去掉这个属性,如果缺失属性太多去掉,一些不好处理的数据也去掉。这样就筛选了 15 个左右属性,然后将这个属性转化成数字类型。
套用模型
利用随机森林的模型,将事故损伤程度作为标签,然后进行套用,参数是 200 棵决策树 cr4.5 类型。
分析结果
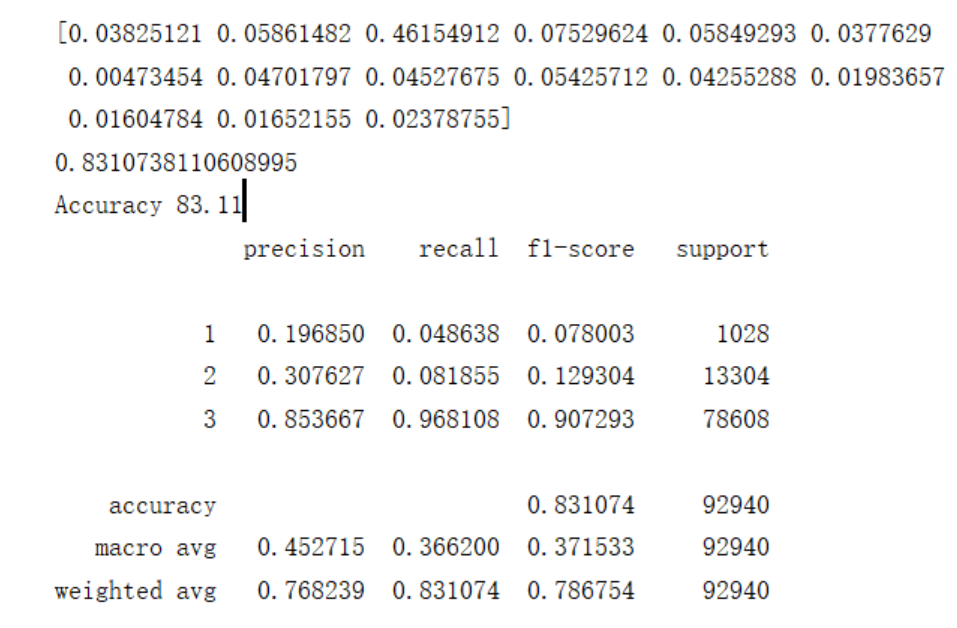
精度是 0.83,前面是属性所占的比率。如果是看这个比重的话,事故的严重程度和警察兼管力度是十分相关的,其次是受伤人数,车辆,速度,在后面和地面是否干燥,天气情况,和光线问题有关,在接着就是人行道和过路是否有天桥。像关系依次下降。所以单单根据这个分析结果,如果交警在附件的话出事的严重程度会大大下降。
道路事故率
数据预处理
这一块涉及到 2 张表,有 6 种道路类型,但是我有很多地方看不懂,所以我就只分析了我看得懂那种道路,类型 3 对应另外一张表是 A 开头。他同一条道路会有很多的关卡点,所以有个道路有多个坐标。然后我就计算最近的坐标。然后在事故表加一项该路的索引。
划分
得到的路事故数量是一个离散的值,我把它除以它的总车流量,然后离散的属性太多了,我需要将他划分成更小块的,以更好的分类。
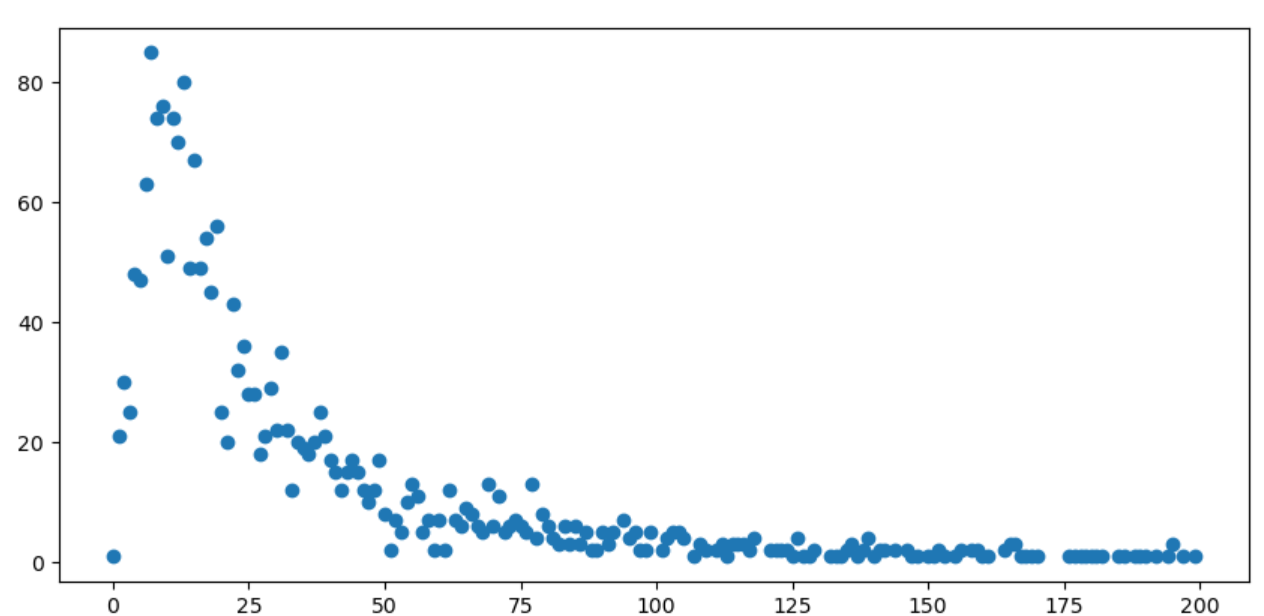
这个就是出现事故的数目和次数。例如出现事故 30 次道路为 20 个这样。我们怎么划分它了,我其实也不太清楚怎么处理,不过我想他这个已经给出了趋势,这个图强行像泊松分布,我就根据这个趋势划分即可。先划分次数高数目和低数目的点,0~5,5~45,45~+。分为 1,2,3 类。当然这只是划分标签,训练的输入就是车流量,每一种车的比例。模型方面还是随机森林,不过数据相对较少,计算能力不行,只得到了 3k 条数据进行分析。
结果分析
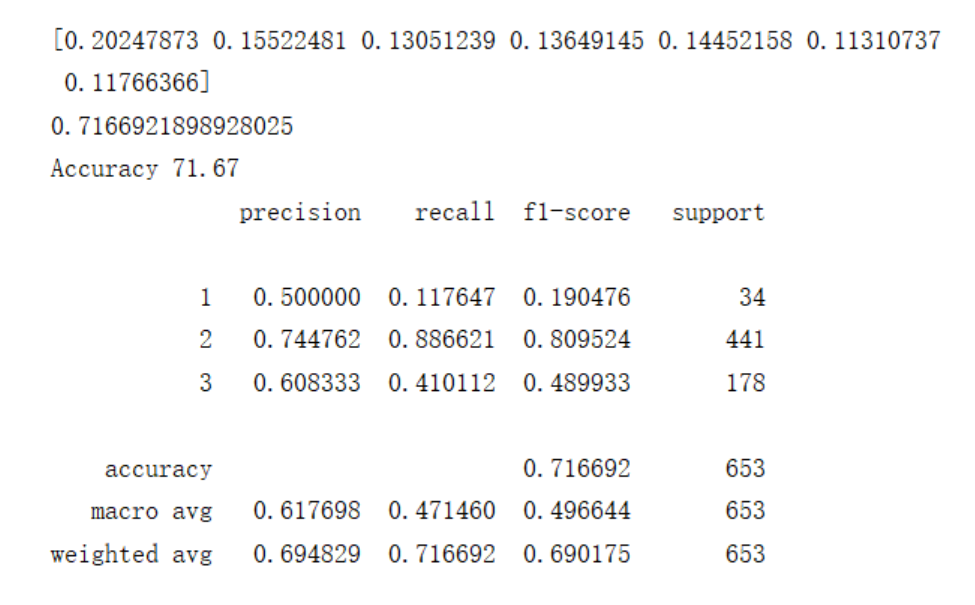
结果的进度是 0.716 可以看出比重反面都不算很大,可以看出最相关的几项分别是车流量,单车所占的比例,卡车所占的比例,公交车所站的比例。其实小汽车和的士影响不是特别大。所以事故高发的应该是车流大,自行车和公交车多的地方。
高发地点分析
圈区域
我挑了 4 块区域进行查看,然后进行一个区域分析。范围是 4km,每一个小的区域是 20m。这样在统计初始的数目。就知道哪里是高发地点了,然后在进行分析,当然这里分析做的少,因为不知道咋做。
取点
由于点很多,所以我们需要筛选出具有特征的点,例如事故高发点和事故低发点,这里我们选事故高发点进行分析,筛选出一个区域内 10 个事故高发点。
观察
查看这些出事故点的共同特征都有些啥,这里截一下图片。
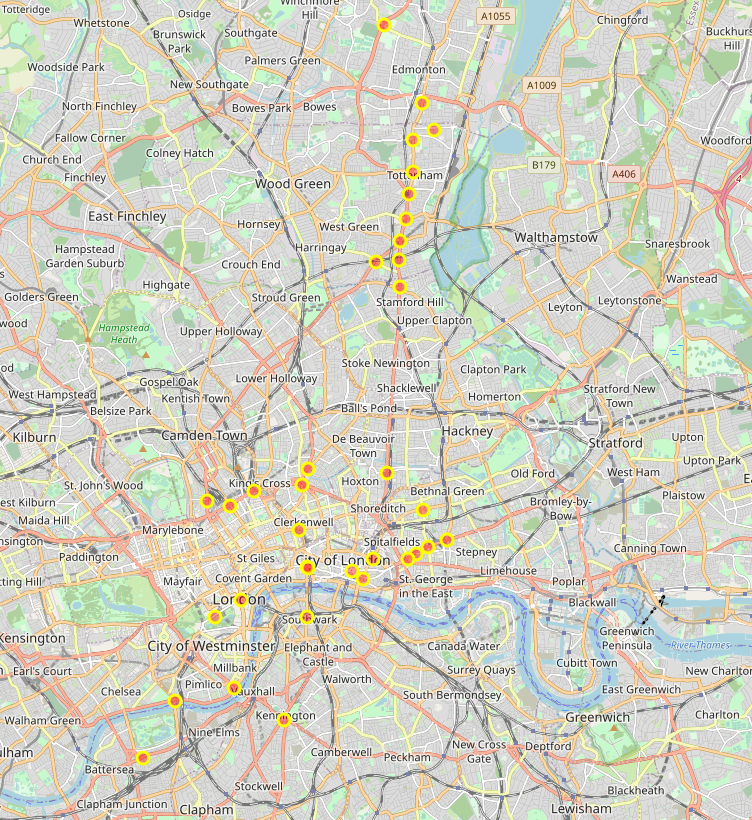
这个是我在伦敦挑选的几个点,他们分别是伦敦中心,一个博物馆一个大商场的出事点的分布情况。其实分析这些路段难度有点大,我直接看起来,我觉得快车道下来的地方容易出事情,红色的是快车道。不过这也不能说明啥,因为我没办法去证明它,也因为城市内也有大量的事故点。总的来说应该是岔路口,建筑出口(商场,体育馆等),多条路的汇合处容易出问题。
结果与讨论
结果
本次实验发现车祸的受损程度和交警分布,速度,路况天气有很大的关系,路口出事情况和车流量,自行车和公家车数目占比有很大的关系,容易出现车祸的地方是岔路口,建筑出口(商场,体育馆等),多条路的汇合处。
车祸的时间分布:
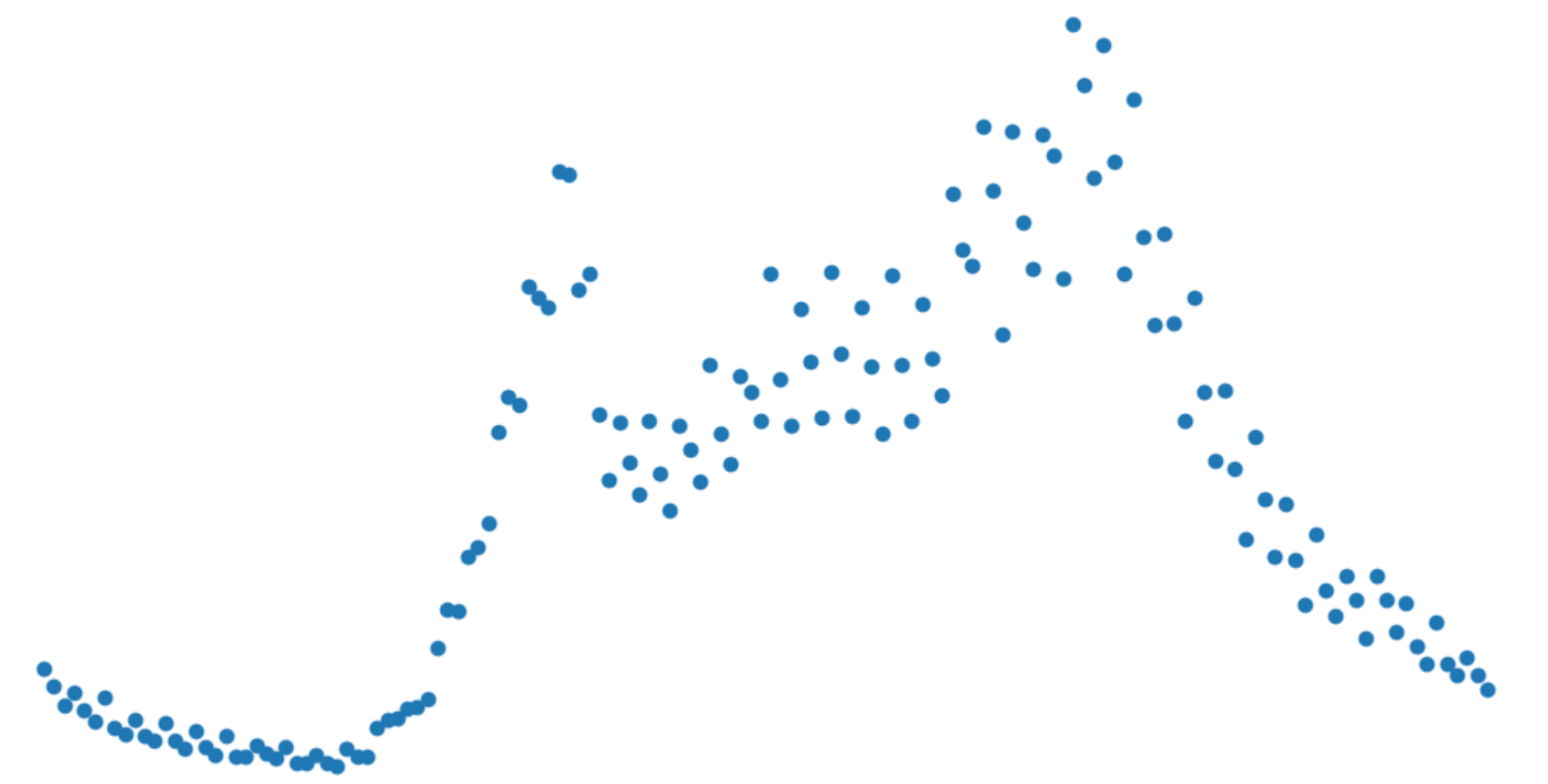
可以看出它 6 点多在急速上升到了 8 点到达第一个高峰,然后在 10 点到达谷底,然后继续上升,这里其实很让人意外的,因为我以为过了 12 点之后一段时间就会下降的,没想到会继续上升。一直上升到 6.30 左右才开始下降。为什么下午那段时间会整体趋势上升,我觉得可能是没睡午觉疲劳驾驶。因为一般高峰期在早晚,中午可能部分人会回家。
事故发送严重程度分布图:
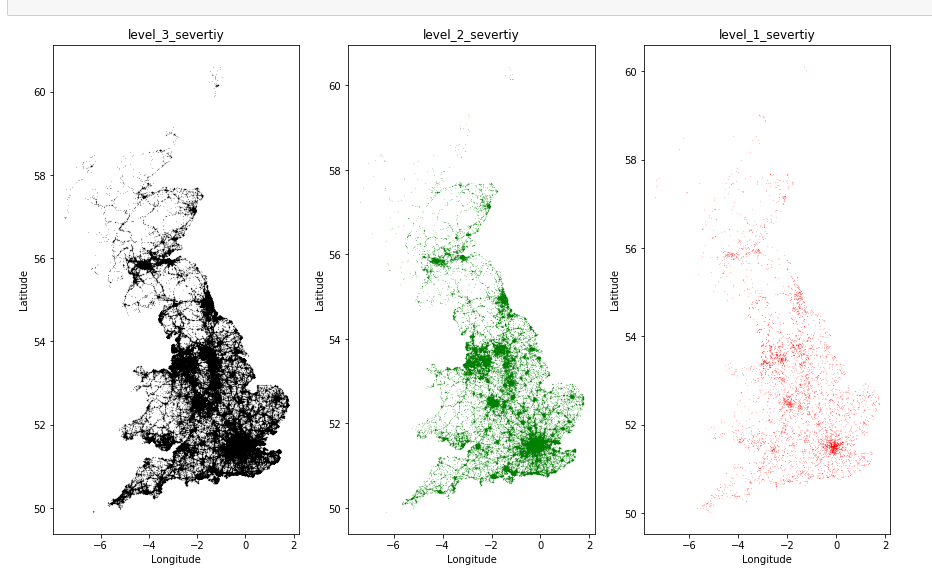
可以看出该严重的地方还是严重,事故严重程度为 3 的很多。右下角那个最灿烂的就是伦敦了,可以看出发生情况很严重。

这个是第二个的范围,伦敦下面的大部分道路。
讨论
本次工作中,有许多需要解决的问题,都没有去做。比如说一些后续工作,程序中的一些错误和 bug 我都懒得改了。目前完成的一个交通严重程度和什么情况下道路容易出问题进行了分析。之后完成了将区域划分,然后进行多个区域合并。然后后面一些操作都没写了。其实我觉得我划分出区域了,可以对一个一个小区域里面的数据进行分析,比如天气和地面情况,这个相当于控制到了同一个地方,但是我没有做,因为我整体的设计框架有问题,如果想加入事故索引,肯定要花一段时间改代码,后来想象还是算了。因为我看了下一个区域数据最多就 30 条,数据太少了,如果想要数据量大,还要计算区域相似度的扩展数据,太麻烦了,就没写了。
遇到的问题,数据字段太难理解了,很多字段不知道啥意思和怎么用。处理上的问题很多都是计算相对坐标的问题,因为开始写的太死了,后来改成多个参数控制,中心点,范围,划分大小等等参数。这个改的时候遇到 很多问题。
总结
[对本次课程报告工作的整体总结。包括:结果要点和结论,本次实习收获和不足。]
[总结性地阐述本研究结果可能的应用前景、研究的局限性及需要进一步深入的研究方向]
整体的工作还是很有意思的,但是由于工作时间不是太连续,所以思路断断续续的,也因为我老是写着写着有人找我打游戏,我就去打游戏了,所以很多东西想了,没有写进去。感觉这次工作收获还是很多的,熟悉了 pandas,matplotlib 等库的操作。还有就是我们的 SQL 语句学习的太浅了,感觉我学的 SQL 语句在这个工作里面根本不够看的,我查了很多 SQL 的写法,感觉很变态,我可能需要代码写半天的功能他只需要 2,3 行就可以解决了。所以感觉还是需要了解 SQL 更多,更高的用法,不能只局限于增删改查等基本操作。其实感觉现在还是太菜了,很多数据科学的方法,只能说看一点点,实现起来还是很难的,只能去调调库,代码的实现能力还是差了点,理解也不是很深,而且代码的风格也不太行,写代码是一回事,写出能广泛使用的代码是另外一回事。所以还是需要加强代码和理解能力,才能自己写出自己的库来。
参考文献
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- 基于混合推荐算法的演练平台的设计与实现(吉林大学·张椋)
- 融合卷积神经网络与协同过滤的个性化推荐系统(东北财经大学·王一镝)
- 基于遗忘理论和加权二部图的推荐系统研究(贵州大学·刘晓光)
- 推荐系统协同过滤算法的改进(云南大学·石婷)
- 基于混合模式的个性化推荐系统的研究与应用(武汉理工大学·梁洁)
- 数据挖掘技术在智能推荐系统中的研究与应用(北京工业大学·沙志强)
- 基于深度学习的Next POI推荐系统研究(烟台大学·祁明明)
- 中小学教育资源个性化推荐系统研究与实现(东北师范大学·刘荣橙)
- 隐私保护的推荐系统的设计与实现(苏州大学·刘肖)
- 隐私保护的推荐系统的设计与实现(苏州大学·刘肖)
- 基于混合推荐算法的演练平台的设计与实现(吉林大学·张椋)
- 基于时空因素的推荐算法研究与实现(扬州大学·田星晨)
- 基于混合推荐算法的演练平台的设计与实现(吉林大学·张椋)
- 基于深度学习的推荐算法研究(黑龙江大学·马胜超)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设导航 ,原文地址:https://m.bishedaima.com/yuanma/35769.html