基于 Python 的云笔记平台分析与设计
1 前 言
1.1 背景
苏联著名教育学家苏霍姆林斯基说得好:“如果学生的智力生活仅局限于教科书,如果他做完了功课就觉得任务已经完成,那么他是不可能有自己特别爱好的。”每一个学生要在书籍的世界里,有自己的生活。把读书,应视为自己的乐趣。当每读完一本有意思的书时,很多时候都想把书中感触深刻亦或是有趣的地方记录下来,以便日后查阅。
但是学生读书做笔记的习惯并没有被养成,很多人读完就搁置了,时间一长就会忘记书中当时令自己感慨万分的内容,传统的手写读书笔记效率低,而且有一定的成本,这些因素会导致很多人读书不记笔记,书中优美的语句以及作者表达的情感只会令读者一时的感慨,而不会走到读者心中;有相当一部分学生有想看的书,但是不知道值不值得花时间去看,很多时候在这种犹豫中,他们就会放弃于读这本书。目前的解决方案就是利用电子设备的便捷性,通过程序实现用户使用电子设备随时随地的记录想记录的内容,提高写笔记的效率。
1.2 现状分析
随着互联网技术的不断发展,网上出现大量学习资料与视频,学习过程中云笔记作为一种网上笔记,可以让人们随时学,随时用[1]。
一般的云笔记系统只提供笔记的增删改查等基本功能,只能满足用户的基本需求,不能提供额外的价值,本系统除这些基础功能以外还提供了图书搜索、用户行为分析、后台管理等功能,拥有更好的用户体验。未来的云笔记支持移动客户端和桌面 Web 端访问,具有多种方式记录、多途径社交化分享、多用户协同工作、智能日程提醒等差异化功能 [2]。相信云笔记系统必将在人们的生活中起到很大的作用,为人们的生活增添一丝的色彩。
1.3 系统目标
通过云笔记平台系统,代替手工的方式,减轻由于手写笔记效率低、易出错,导致读者不能将想法及内容及时记录的问题,提高了用户阅读时记笔记的效率。同时系统还提供了图书搜索功能,用户可以搜索自己想看的图书的信息,本系统还提供了用户行为分析功能,方便用户对自己的搜索记录进行查看,以及系统给用户的一些推荐建议。
同时云笔记系统还将实现管理员有效管理用户信息,给用户配置权限等后台管理功能,方便管理人员高效的对用户进行管理,减轻管理人员的工作负担,从而使系统更加趋于完整性。
2 系统分析
2.1 功能需求分析
2.1.1 功能结构
本系统前台由标题模块、笔记模块、图书搜索模块、用户行为分析模块组成,同时具有后台管理模块。系统结构如图 2.1 所示。

图 2.1 系统结构
2.1.2 前台功能分析
前台功能包括标题模块、笔记模块、图书搜索模块、行为分析模块。
(1) 标题模块
标题模块包括标题的增加、修改、删除,用户可以增删改自己的标题,同时可以查看标题列表。
(2) 笔记模块
笔记模块包括笔记的增加、删除、修改、查询,用户可以增删改自己的笔记,同时还可以模糊搜索,使用关键字进行笔记的搜索。
(3) 图书搜索模块
图书搜索模块包括图书的简介、作者的简介、20 条有代表性的书评,以及书评点赞数的可视化图形,用户可以使用搜索栏搜索自己想看的书籍,获取图书的信息,有利于对图书的了解。
(4) 行为分析模块
用户行为分析模块包括用户搜索历史的可视化,反馈用户搜索的图书数量,以及对用户搜索最多的书籍进行分析,提供书籍的购买途径,以及根据用户的这些行为给予一些建议,推荐一些图书。
2.1.3 后台功能分析
后台管理模块是给管理员使用的,包括对图书搜索记录的管理、标题的管理、笔记的管理、用户信息的管理、用户权限的管理。管理员可以对用户的搜索记录、标题、笔记、进行修改和删除,同时可以操作用户信息,管理员可以将各种权限添加到不同分组中,再将分组设置给不同的用户,实现给用户授权。
2.2 性能、安全性和可行性
本系统使用 MTV 模式,即 M(Model)模型、T(Template)模板和 V(View)视图,各组件之间保持松耦合关系。
使用 Django 作为本系统的安全框架,它是一个专注于为 Python 应用程序提供认证和授权的框架[3]。为本系统提供用户的权限管理,可以确保用户在自己的权限范围内操作,防止用户越权操作。数据库密码采用 MD5 加密,它的作用是让大容量信息在用 数字签名 软件签署私人 密钥 前被" 压缩 "成一种保密的格式,可以有效的防止了用户密码的泄漏问题[4]。
在性能方面,打开页面的响应速度 <5ms,大量使用 AJAX 异步请求的方式获取数据,提升用户的使用体验[5]。
(1) 技术可行性
系统的开发采用的是当下非常流行的 Python 语言,它是当前世界上使用最多的一种语言之一。具有一次编译,各处运行的特点,初步估计项目运行不受服务器操作环境的制约,有良好的可扩展性。在前台页面使用当下比较流行的 HTML5+CSS+jQuary,同时使用了 BootStrap 框架进行美化,数据库使用 MySQL 数据库,它是当下最流行的关系型数据库管理系统,在 Web 方面 MySQL 是最好的 RDBMS 之一[6]。项目后台使用 Django 框架,同时加入了爬虫技术、数据可视化、selenium 自动化技术。
(2) 经济可行性
系统开发所使用的 Django、BootStrap 等都是开源的框架,系统所使用的 MySQL 数据库,也是免费的,所以在系统中使用这些框架不需要支付额外的费用。预计系统在后期维护方面只需要投入很小的成本,就可以保证系统良好的运行。
3 开发技术概述
3.1 开发语言介绍
3.1.1 Python 简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构[7]。
3.1.2 Python 的特点
易于学习:Python 有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
易于维护:Python 的成功在于它的源代码是相当容易维护的。一个广泛标准的库:Python 的最大的优势之一是丰富的库,跨平台的,在 UNIX,Windows 和 Macintosh 兼容很好。
可扩展:当需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,可以使用 C 或 C++ 完成那部分程序,然后从 Python 程序中调用。
数据库:Python 提供所有主要的商业数据库的接口[8]。
3.2 开发工具介绍
3.2.1 集成开发环境
PyCharm 和 WebStorm 是捷克著名的软件公司 JetBrains 打造的两款优秀的集成开发环境,前者用来 Python 开发,后者用来前端开发。
PyCharm 是当前非常流行的 Python 集成开发工具,有强大的代码提示和自动完成功能,能使开发速度得到显著的提升。PyCharm 不仅支持 Python 的开发也支持其它语言的开发,如 HTML、JavaScript 等等。与 SublimeText 相比,PyCharm 可以配置项目中所使用的框架,对当前比较流行的版本控制工具 Git 有良好的支持。
WebStrom 是目前很流行的 JavaScript 开发工具,被广大的 JS 开发者称为“Web 前端开发神奇”、“最强大的 HTML5 编辑器”、“最智能的 JavaScript IDE”等,具有智能的代码补全、代码格式化、HTML 提示、联想查询、代码重构、代码检查和快速修复、代码调试等很受开发者欢迎的功能。
3.2.2 Selenium 自动测试工具
Selenium 是一个用于 Web 应用程序测试的工具。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样[9]。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl 等不同语言的测试脚本。
Selenium 测试可以在 Windows、Linux 和 Macintosh 上的 Internet Explorer、Chrome 和 Firefox 中运行。其他测试工具都不能覆盖如此多的平台。使用 Selenium 和在浏览器中运行测试还有很多其他好处。通过编写模仿用户操作的 Selenium 测试脚本,可以从终端用户的角度来测试应用程序。通过在不同浏览器中运行测试,更容易发现浏览器的不兼容性。Selenium 的核心,也称 browser bot,是用 JavaScript 编写的。这使得测试脚本可以在受支持的浏览器中运行。browser bot 负责执行从测试脚本接收到的命令,测试脚本要么是用 HTML 的表布局编写的,要么是使用一种受支持的编程语言编写的[10]。
Selenium 是一个成功的开源软件,其发展获得很多公司和独立开发者的支持。
3.3 相关技术简介
3.3.1 前端框架 BootStrap
BootStrap 是 Twitter 开发的一款优秀的前端框架,它集成了很多实用的功能。BootStrap 是基于 HTML、CSS、JavaScript 的,它简单灵活,使得 Web 开发更加快捷[11]。BootStrap 对开发中一些常用的组件进行了良好的封装,如表单验证,数据表格,弹出窗口,标签页,树等,对 AJAX 也实现了良好的封装。开发人员可以在不精通 JS 的情况下,开发出页面美观,用户体验好的应用程序。可以节省开发人员大量的时间,它的特点就是简单强大,能够节省网页开发的时间和规模。
3.3.2 后端框架 Django
Django 是一个开源的应用程序框架,由 Python 写成,采用了 MTV 的框架模式[12]。Django 的主要目的是简便、快速的开发数据库驱动的网站,他强调代码复用,多个组件可以很方便的以“插件”形式服务于整个框架,Django 有许多功能强大的第三方插件,也可以很方便的开发出自己的工具包,这使得 Django 有很强的可扩展性[13]。
它有很多显著的特性:
(1) 整体设计方面
Django 提供一站式的解决方案,从模板、ORM、Session、Authentication 都会给分配好,而且还有一个很棒的 admin 特性,配合 django-suit,后台即可搭建。
(2) 路由设计
Django 的路由设计是采用集中处理的方法,使用正则表达式匹配。
(3) 应用模块化设计
Django 的模块化是集成在命令中的,Django 一开始的目标就是做的非常强大,每一个应用都是一个独立的模块,为以后的复用提供了便利。
(4) 完美的文档
Django 有近乎完美的官方文档,包括 Djangobook[14]。
(5) Django 源码是经典的学习范例
Django 源码处处体现着大师对 Python 设计模式灵活的运用以及对 Python 技术高深的造诣。Django 源码是 Python 最佳的实践范例。
3.3.3 数据库 MySQL
MySQL 是一款当前最流行的关系型数据库管理系统之一,体积小,响应速度快,虽然于其它大型数据库如 Oracle 相比有很多的不足之外,但是这也丝毫没有减少它受欢迎的程度。MySQL 是能够支持企业级关系型数据库的管理系统[15],它有很多显著的特点:
(1) 可以处理成千上万条的数据;
(2) 支持常见的 SQL 规范;
(3) 良好的运行效率;
(4) 相对于其它大型数据库而言,调试和优化比较简单;
(5) 免费开源。
3.3.4 网络爬虫技术
网络爬虫,又被称为网页蜘蛛、网页机器人,在 FOAF 社区中间,更经常地称为网页追随者[16]。网络爬虫是一种按照一定的规则,自动的抓取万维网信息的程序或脚本。简单说就是事先写好的程序去抓取网络上所需要的数据,这样的程序就叫网络爬虫。
网络爬虫可以分为通用网络爬虫(如搜索引擎的爬虫,根据几个 URL 的种子不断的去抓取数据)和聚焦网络爬虫(有选择性的抓取预先定义好的主题和相关页面的网络爬虫)。
(1) 通用网络爬虫
搜索引擎中第一步就是爬虫。但是搜索引擎中的爬虫是一种广泛获取各种网页的信息的程序;除了 HTML 文件外,搜索引擎通常还会抓取和索引文字为基础的多种文件类型,如 TXT,WORD,PDF 等;但是对于图片,视频等非文字的内容则一般不会处理;但是对于脚本和一些网页中的程序是不会处理的。
(2) 聚焦网络爬虫
针对某一特定领域的数据进行抓取的程序,比如旅游网站,金融网站,招聘网站等等。特定领域的聚集爬虫会使用各种技术去处理我们需要的信息,所以对于网站中动态的一些程序,脚本仍会执行,以保证确定能抓取到网站中的数据。
4 系统设计
4.1 系统工程结构
4.1.1 系统应用目录
系统应用目录如图 4.1。

图 4.1 系统应用目录
4.1.2 MTV 目录
Models 模型层、Templates 模板层、Views 视图层目录如图 4.2。
图 4.2 Models 模型层、Templates 模板层、Views 视图层目录
4.1.3 系统配置文件目录
系统配置文件目录如图 4.3。

图 4.3 系统配置文件目录
4.2 系统详细设计
系统采用 MTV 的设计模式,以下是模型、模板、视图各部分的详细设计说明。
Models 模型类用来实现与数据连接进行数据交互,Django 中使用 ORM 映射关系,将模型类中的变量对象映射成数据库中表中的字段,提高了开发效率,省略了程序中庞大的数据访问层,不使用 SQL 编码就可实现对数据的 CRUD 操作。模型类中同时可以自定义数据库表名,还可配合 admin.py 配置后台管理页面的显示信息。
Topic 类对应数据库中 topic 表,代码如下所示:
class Topic(models.Model):
text = models.CharField(max_length=200, verbose_name='标题')
date_added = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
owner = models.ForeignKey(User, null=True, on_delete=models.CASCADE)
class Meta:
db_table = 'topic'
verbose_name_plural = '标题'
def __str__(self):
return self.text
Templates 模板的目的是为了解决复杂的显示问题,使用 loader 获取模板,通过 HttpResponse 进行响应,所有的 HTML 页面都放在每个应用下的 templates 目录中,在 settings.py 中设置静态文件访问路径,系统会自动搜索模板进行显示。
Base.html 基础页面代码如下所示:
``` {%load bootstrap3%}
```
View 视图组成了 Django 应用程序里几乎所有的逻辑。它们的定义实际上很简单:它们是链接到一个或多个定义 url 上的 python 函数,这些函数都返回一个 http 响应对象。在 Django 的 http 机制两端之间要执行什么操作完全都在你的控制之下。Django 为这类任务提供了很多方便快捷的帮助函数,但是我们可以自己编写一切来完全控制整个过程。灵活和强大两者具备就是视图的特点。
标题模块、笔记模块的业务逻辑基本是一致的,以笔记模块为例,添加新的笔记需要获取对应标题的 id、用户的 id,连同笔记内容一起保存到数据库。修改笔记时需要获取到笔记的 id,从数据库中把原笔记内容提取出来,填充在文本框中,等用户修改完后,再将其保存到数据库。搜索笔记是根据用户输入的关键词进行匹配,同时需要传递用户 id,保证用户只能搜索数据库中自己的笔记内容。删除笔记只需要知道笔记 id 即可,因为笔记的 id 都是唯一的,不会出现误删的情况。
笔记模块的视图代码如下所示:
@login_required
def new_entry_views(request, topic_id):
topic = Topic.objects.get(id=topic_id)
if request.method == 'GET':
form = EntryForm()
else:
form = EntryForm(request.POST)
if form.is_valid():
new_entry = form.cleaned_data
new_entry['topic'] = topic
new_entry['owner'] = request.user
Entry(**new_entry).save()
return HttpResponseRedirect(reverse('learning_logs:topic', args=[topic_id]))
return render(request, 'learning_logs/new_entry.html', locals())
@login_required
def edit_entry_views(request, entry_id):
entry = Entry.objects.get(id=entry_id)
topic = entry.topic
if topic.owner != request.user:
raise Http404
if request.method == 'GET':
form = EntryForm(instance=entry)
else:
form = EntryForm(instance=entry, data=request.POST)
if form.is_valid():
form.save()
return HttpResponseRedirect(reverse('learning_logs:topic', args=[topic.id]))
return render(request, 'learning_logs/edit_entry.html', locals())
图书搜索模块在前端为用户提供了一个搜索入口,利用爬虫技术将用户输入的图书名作为关键字,利用正则表达式进行匹配,使用 selenium 工具自动去豆瓣网上抓取相应的图书信息、作者信息,以及豆瓣用户对图书的评论信息,并将评论的点赞数与豆瓣用户 id 使用高阶函数处理成一定的数据类型,利用 pygal 画图库将数据传入生成图形,保存成 svg 格式的文件,在前端调用展示,将图书信息全面的呈现给用户,同时将用户的搜索记录保存到数据库中,为后面用户行为分析提供数据支持。代码如下所示:
行为分析模块实现将用户搜索行为可视化展示,从数据库中获取用户搜索次数最多的一本书,提供图书的购买链接,同时根据用户搜索次数最多的图书进行一些相关图书的推荐。代码如下所示:
```
@login_required
def behavior_analysis_views(request):
analysis = History.objects.filter(owner=request.user).order_by('-num')
text = []
num = []
for i in analysis:
text.append(i.text)
num.append(i.num)
my_style = LS('#333366', base_style=LCS)
my_config = pygal.Config()
my_config.x_label_rotation = 45
my_config.show_legend = False
my_config.title_font_size = 24
my_config.label_font_size = 14
my_config.major_label_font_size = 18
my_config.truncate_label = 15
# my_config.show_y_guides = False
my_config.width = 1000
chart = pygal.Bar(my_config, style=my_style)
chart.title = '您的历史搜索'
chart.x_labels = text
chart.add('', num)
chart.render_to_file(
'/Users/mingnaichao/Desktop/小项目/读书笔记/learning_log/learning_logs/templates/learning_logs/analysis.svg')
s_book = text[0]
book = parse.quote(s_book)
dict = {
'book_num': len(text),
'hot_book': text[0],
'search_num': num[0],
'jd_buy': 'https://search.jd.com/Search?keyword=' + book + '&enc=utf-8&wq=' + book
}
url = 'https://book.douban.com/subject_search?search_text=' + book + '&cat=1001'
driver = webdriver.Chrome()
driver.get(url)
elements = driver.find_elements_by_class_name('title-text')
elements[1].click()
pattern = re.compile(
'
([\s\S]*?)
')
data = re.findall(pattern, driver.page_source)
driver.close()
books = []
for book in data:
books.append(book.strip())
books_dict = {
'book1': books[0],
'book2': books[1],
'book3': books[2],
'book4': books[3],
'book5': books[4],
'book6': books[5],
'book7': books[6],
'book8': books[7],
'book9': books[8],
'book10': books[9],
}
return render(request, 'learning_logs/behavior_analysis.html', locals())
```
5 数据库设计
5.1 数据库模型图
模型图如图 5.1 所示。
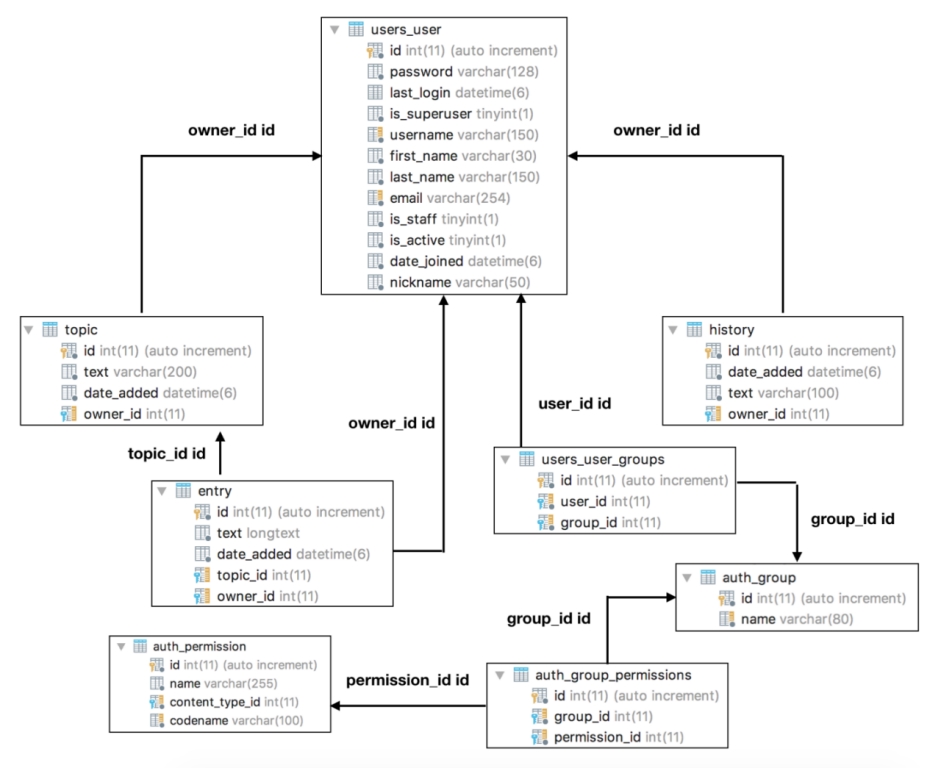
图 5.1 模型图
5.2 数据库表设计
(1) 用户表如表 5.1 所示。
表 5.1 用户表
| 字段名 | 描述 | 字段类型 | 长度 | 主/外键 |
|---|---|---|---|---|
| id | 标识符 | int | 11 | PK |
| password | 密码 | varchar | 128 | |
| last_login | 最后登陆时间 | datetime | 6 | |
| is_superuser | 超级用户 | tinyint | 1 |
续表5.1
| username | 用户名 | varchar | 150 | |
|---|---|---|---|---|
| first_name | 名 | varchar | 30 | |
| last_name | 姓 | varchar | 150 | |
| 邮箱 | varchar | 254 | ||
| is_staff | 工作人员 | tinyint | 1 | |
| is_active | 账户激活状态 | tinyint | 1 | |
| date_joined | 注册时间 | datetime | 6 | |
| nickname | 昵称 | varchar | 50 |
(2) 标题表如表 5.2 所示。
表 5.2 标题表
| 字段名 | 描述 | 字段类型 | 长度 | 主/外键 |
|---|---|---|---|---|
| id | 标识符 | int | 11 | PK |
| text | 标题名称 | varchar | 200 | |
| date_added | 创建时间 | datetime | 6 | |
| owner_id | 用户 ID | int | 11 | FK |
(3) 笔记表如表 5.3 所示。
表 5.3 笔记表
| 字段名 | 描述 | 字段类型 | 长度 | 主/外键 |
|---|---|---|---|---|
| id | 标识符 | int | 11 | PK |
| text | 笔记内容 | longtext | ||
| date_added | 创建时间 | datetime | 6 | |
| topic_id | 标题 ID | int | 11 | FK |
| owner_id | 用户 ID | int | 11 | FK |
(4) 历史记录表如表 5.4 所示。
表 5.4 历史记录表
| 字段名 | 描述 | 字段类型 | 长度 | 主/外键 |
|---|---|---|---|---|
| id | 标识符 | int | 11 | PK |
| date_added | 搜索时间 | datetime | 6 |
续表 5.4
| text | 搜索文本 | varchar | 100 | |
|---|---|---|---|---|
| owner_id | 用户 ID | int | 11 | FK |
| num | 文本搜索次数 | int | 11 |
(5) 历史记录表如表 5.5 所示。
表 5.5 分组表
| 字段名 | 描述 | 字段类型 | 长度 | 主/外键 |
|---|---|---|---|---|
| id | 标识符 | int | 11 | PK |
| name | 名称 | varchar | 80 |
(6) 历史记录表如表 5.6 所示。
表 5.6 权限表
| 字段名 | 描述 | 字段类型 | 长度 | 主/外键 |
|---|---|---|---|---|
| id | 标识符 | int | 11 | PK |
| name | 显示名称 | varchar | 255 | |
| content_type_id | 内容类型 | int | 11 | |
| code_name | 代号 | varchar | 100 |
6 系统实现
6.1 进入界面
(1) 进入界面
界面如图 6.1 所示。
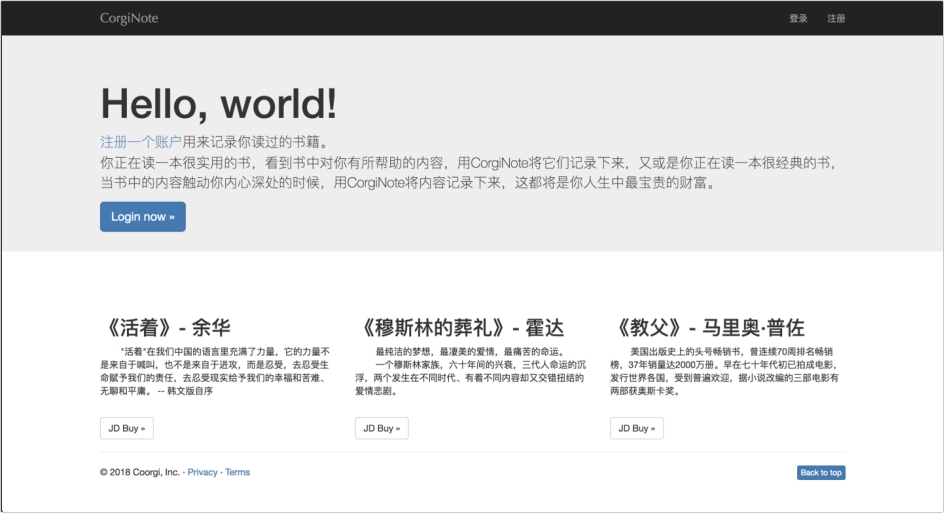
图 6.1 进入界面
(2) 操作说明
① 用户点击“注册一个帐户”或右上角“注册”,进行用户注册;
② 用户点击“Login now”或右上角“登录”,进行登录。
6.2 注册登录
(1) 注册界面
注册界面如图 6.2 所示,登录界面如图 6.3 所示。
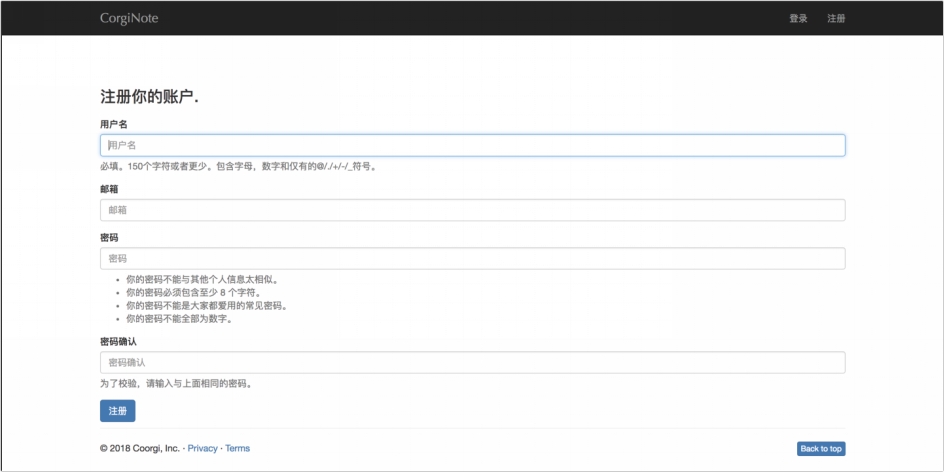
图 6.2 注册页面
图 6.3 登录页面
(2) 操作说明
① 用户点击“用户名”输入框,输入自己的用户名;
② 用户点击“邮箱”输入框,输入自己的邮件;
③ 用户点击“密码”输入框,输入自己的密码。
6.3 标题和笔记操作
6.3.1 HOME 页面
(1) HOME 界面
界面如图 6.4 所示。
图 6.4 HOME 页面
(2) 操作说明
用户点击“<”和“>”,进行图片的查看;
6.3.2 添加标题
(1) 添加标题界面
界面如图 6.5 所示。

图 6.5 添加标题
(2) 操作说明
① 用户可以通过点击标题栏“添加标题”进入添加标题界面;
② 用户通过输入框,输入想添加的标题;
③ 用户点击“添加标题”按钮,实现添加标题。
6.3.3 显示标题列表
(1) 标题列表界面
界面如图 6.6 所示。
图 6.6 显示标题列表
(2) 操作说明
① 用户可以通过点击标题栏“标题列表”,进入到标题列表界面;
② 用户点击自己创建的标题名,进入标题下笔记列表页面;
③ 用户点击“修改标题”按钮,可以修改标题;
④ 用户点击“删除标题”按钮,可以删除标题;
⑤ 用户点击“添加标题”按钮,可以添加标题。
6.3.4 添加笔记
(1) 添加笔记界面
界面如图 6.7 所示。
图 6.7 添加笔记
(2) 操作说明
① 用户点击“添加笔记”按钮,进行笔记添加;
② 用户点击“编辑笔记”按钮,可以对原有笔记进行编辑;
③ 用户点击“删除笔记”按钮,可以删除笔记。
6.3.5 搜索笔记
(1) 搜索笔记界面
搜索界面如图 6.8 所示,搜索结果如图 6.9 所示。
图 6.8 搜索笔记
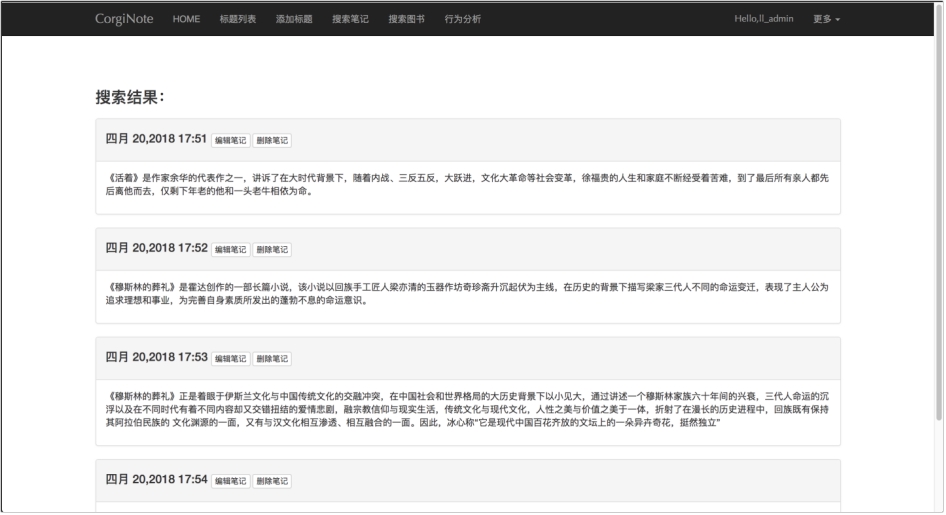
图 6.9 搜索结果
(2) 操作说明
① 用户点击标题栏“搜索笔记”,进入笔记搜索界面;
② 用户点击“搜索笔记”按钮,进行关键字搜索;
③ 用户点击“编辑笔记”按钮,可以编辑笔记;
④ 用户点击“删除笔记”按钮,可以删除笔记。
6.4 搜索图书
(1) 搜索图书界面
搜索如图 6.10 所示,搜索结果如图 6.11,6.12,6.13 所示。
图 6.10 图书搜索
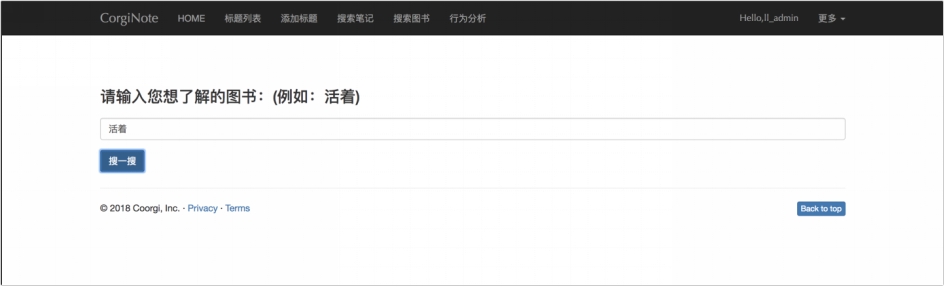
图 6.11 搜索结果-简介
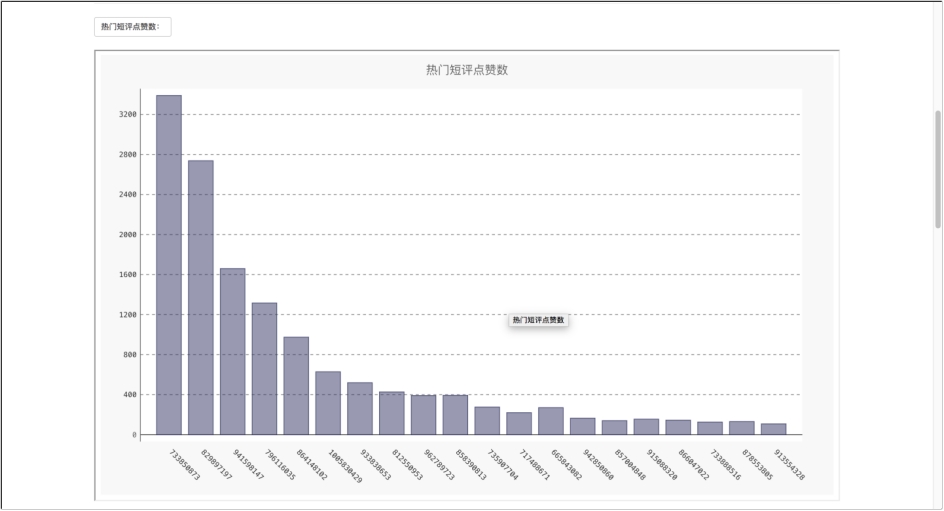
图 6.12 搜索结果-点赞评论数统计

图 6.13 搜索结果-评论内容
(2) 操作说明
① 用户可通过点击标题栏“搜索图书”,进入图书搜索界面;
② 用户点击输入框,可以输入想查看的书籍信息;
③ 用户点击“搜一搜”按钮,进行图书搜索;
6.5 用户行为分析
(1) 用户行为分析界面
界面如图 6.14 所示。

图 6.14 用户行为分析
(2) 操作说明
① 用户可通过点击标题栏“行为分析”进入分析页面;
② 用户点击超链接,可到京东购买搜索次数最多的书籍;
③ 用户可查看根据用户搜索行为系统推荐的书籍。
6.6 后台管理
6.6.1 后台管理登录
(1) 界面
界面如图 6.15 所示。
图 6.15 后台管理登录
(2) 操作说明
① 管理员点击用户名输入框,输入账户;
② 管理员点击密码输入框,输入密码;
③ 管理员点击“登录”按钮,进行后台登录。
6.6.2 控制后台
(1) 后台界面
界面如图 6.16 所示。
图 6.16 后台界面
(2) 操作说明
① 管理员点击右上角“查看站点”,回到前台页面;
② 管理员点击 LEARNING_LOGS 中的“添加”或“修改”,可以对图书搜索历史、标题、笔记进行相应的添加和修改;
③ 管理员点击 USERS 中的“添加”或“修改”,可以对用户信息进行添加和修改;
④ 管理员点击认证和授权中的“添加”或“修改”,可以添加和修改分组,对用户权限进行管理;
⑤ 管理员点击右上角“注销”,可以退出后台管理。
6.7 详细后台管理
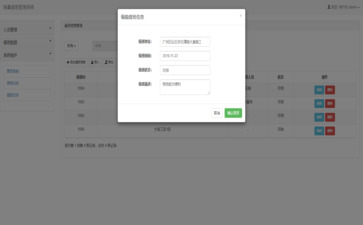
6.7.1 图书搜索记录管理
(1) 图书搜索记录界面
界面如图 6.17、6.18 所示。
图 6.17 图书搜索历史
图 6.18 搜索图书详细界面
(2) 操作说明
① 管理员可通过点击图书名字进入搜索历史图书的详细页面;
② 管理员通过修改“搜索内容”文本框中的内容,修改历史搜索信息;
③ 管理员通过修改“搜索次数”文本框中的内容,修改搜索次数;
④ 管理员点击“删除”按钮,删除搜索记录;
⑤ 管理员点击“保存并添加”或“保存并继续编辑”按钮,进行页面保存添加新记录或继续编辑;
⑥ 管理员点击“保存”按钮,保存页面信息。
6.7.2 标题管理
(1) 标题管理界面
界面如图 6.19、6.20 所示。
图 6.19 标题列表

图 6.20 标题信息
(2) 操作说明
① 管理员可通过点击标题名进入标题的详细页面;
② 管理员通过修改“标题”文本框中的内容,修改标题内容。
③ 管理员点击“删除”按钮,删除标题;
④ 管理员点击“保存并添加”或“保存并继续编辑”按钮,进行页面保存添加新标题或继续编辑;
⑤ 管理员点击“保存”按钮,保存标题信息。
6.7.3 笔记管理
(1) 笔记管理界面
界面如图 6.21、6.22 所示。
图 6.21 笔记列表
图 6.22 笔记详细信息
(2) 操作说明
① 管理员可通过点击笔记名字进入笔记的详细页面;
② 管理员通过选择“标题”选择框,为笔记更换标题;
③ 管理员通过修改“内容”文本框中的内容,修改笔记内容;
④ 管理员点击“删除”按钮,删除笔记;
⑤ 管理员点击“保存并添加”或“保存并继续编辑”按钮,进行页面保存添加新笔记或继续编辑;
⑥ 管理员点击“保存”按钮,保存笔记信息。
6.7.4 用户信息管理
(1) 用户信息管理界面
界面如图 6.23、6.24 所示。

图 6.23 用户信息管理
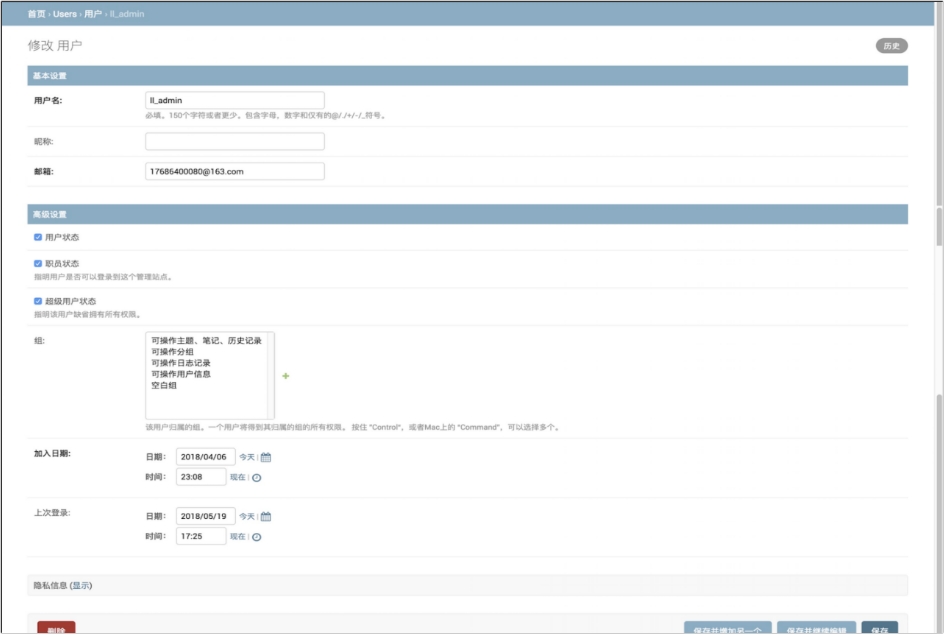
图 6.24 用户详细信息
(2) 操作说明
① 管理员可通过点击用户 ID 进入用户的详细信息页面;
② 管理员可通过“用户名”、“昵称”、“邮箱”输入框修改用户名、昵称、邮箱;
③ 管理员可通过点击“用户状态”、“职员状态”、“超级用户状态”单选按钮修改用户权限;
④ 管理员通过“组”中的“+”,给用户或其他管理员分组;
⑤ 管理员通过“加入日期”和“上次登录时间”修改用户创建时间和最后登录时间;
⑥ 管理员点击“删除”按钮,可以删除用户,击“保存并添加”或“保存并继续编辑”按钮,进行页面保存添加新用户或继续编辑,点击“保存”按钮,保存用户信息。
6.7.5 认证和授权
(1) 认证和授权界面
界面如图 6.25、6.26 所示。
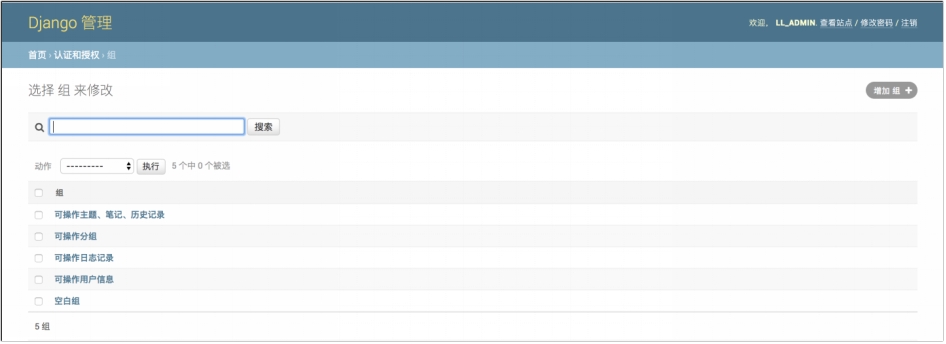
图 6.25 分组列表
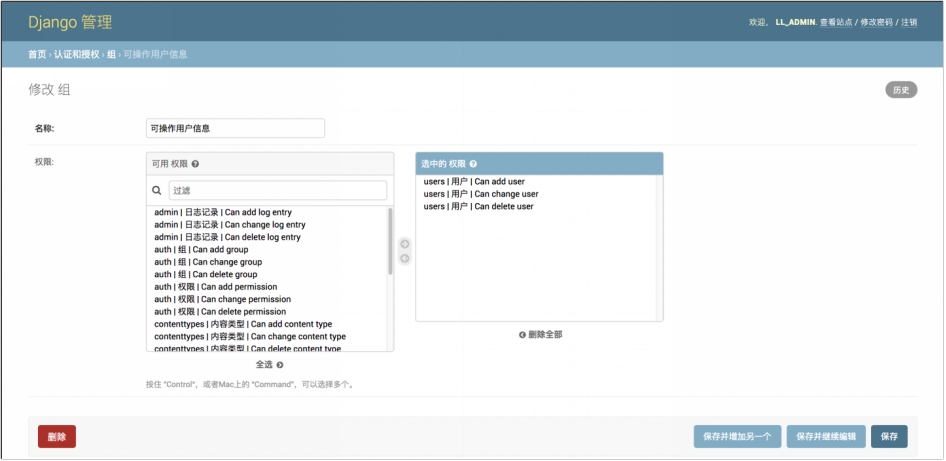
图 6.26 分组信息
(2) 操作说明
① 管理员可通过点击页面右上角“添加组”按钮添加新组;
② 管理员可通过点击“名称”输入框修设置修改分组名;
③ 管理员可通过点击“用户状态”、“职员状态”、“超级用户状态”单选按钮修改用户权限;
④ “权限”左边选择框内是一系列权限,管理员通过“->” ,将单个权限一一添加到创建的分组中;
⑤ 管理员通过“全选->”和“<-删除全部”按钮添加全部权限和删除全部权限;
⑥ 管理员点击“删除”按钮,可以删除分组,点击“保存并添加”或“保存并继续编辑”按钮,进行页面保存添加新分组或继续编辑,点击“保存”按钮,保存分组信息。
7 系统测试
7.1 系统测试的方法和步骤
系统测试从不同的角度出发会派生出两种不同的测试原则,从用户的角度出发,就是希望通过系统测试能充分暴露软件中存在的问题和缺陷,从而考虑是否可以接受该产品,从开发者的角度出发,就是希望测试能表明系统产品不存在错误,已经正确的实现了用户的需求,确立人们对系统质量的信心。软件测试使用人工或者自动手段来运行或测试某个系统的过程,其目的在于检验它是否满足规定的需求或弄清预期结果与实际结果之间的差别[17]。为了对本系统进行测试,制定的测试方法如下:先对每个小功能进行测试,最后对整个系统进行测试。测试的规模是由小到大,尽可能的使测试的代码覆盖率最大。
7.2 功能测试
主要功能的详细测试情况如下:
(1) 如图 7.1 所示,用户注册时,当出现没有填写的内容时,点击注册按钮会出现提示。
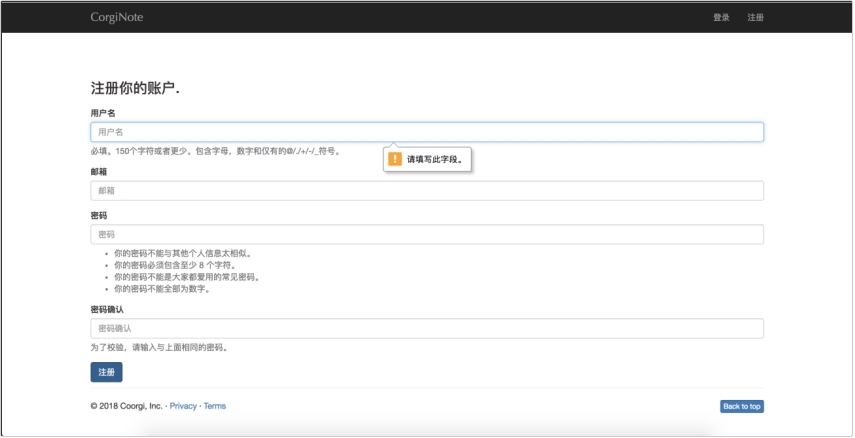
图 7.1 注册错误提示
(2) 如图 7.2 所示,用户填写的邮箱不符合格式时,会出现错误提示。
图 7.2 邮箱错误提示
(3) 如图 7.3 所示,用户两次填写的密码不一致,点击注册按钮时,会出现错误提示,引导用户重新填写。
图 7.3 密码错误提示
(4) 如图 7.4 所示,添加标题时,如果用户输入空白字符,当点击添加标题按钮时,提示用户标题字段是必填项。
图 7.4 标题填写错误提示
(5) 如图 7.5 所示,用户使用搜索笔记功能时,当输入要搜索的内容为空白字符时,提示用户该字段是必填项。
图 7.5 搜索笔记错误提示页面
(6) 如图 7.6 所示,当没有权限的用户尝试登录后台管理界面时,系统会拦截用户,出现错误提示。
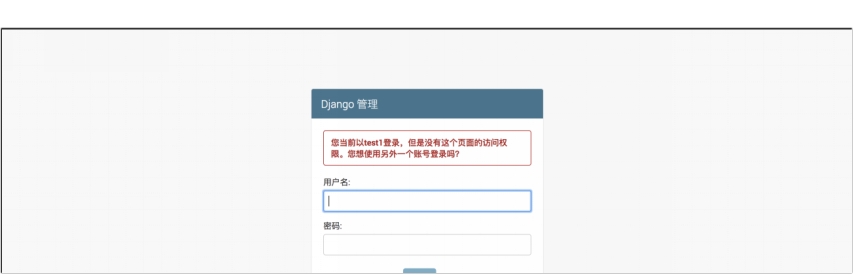
图 7.6 登录后台管理错误提示
(7) 如图 7.7 所示,管理员在后台添加新用户时,如果有必填信息没有填写时,会出现错误提示信息。
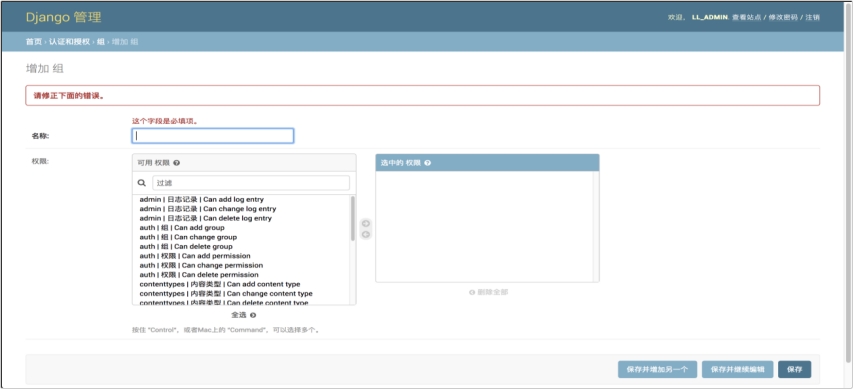
图 7.7 后台添加用户错误提示
(8) 如图 7.8 所示,管理员添加分组时,出现没有填写的字段时,会出现错误提示。
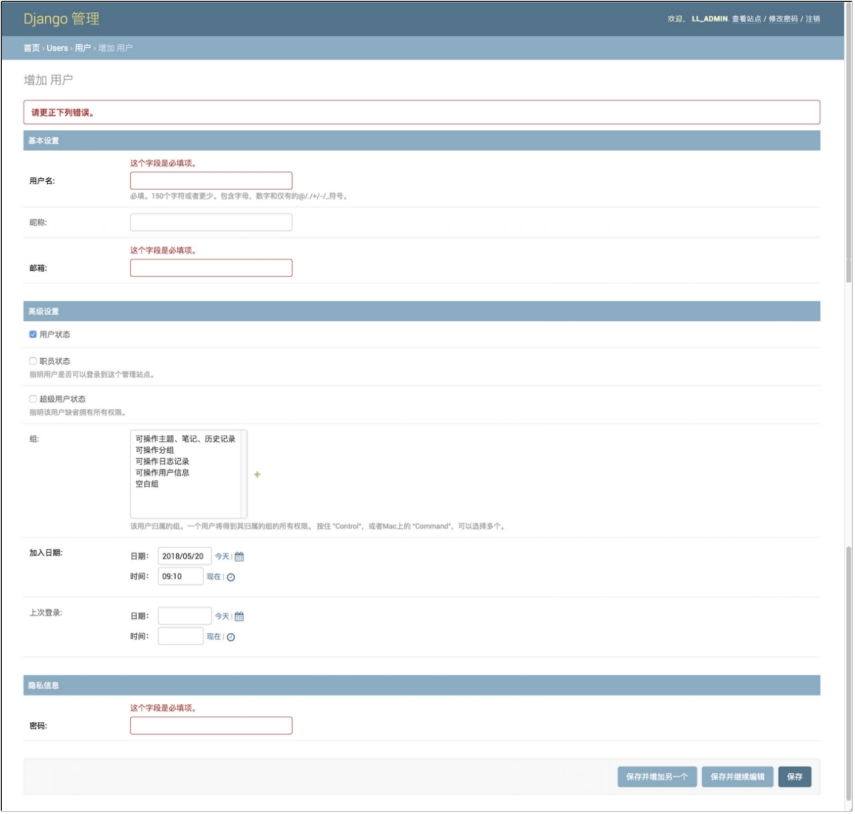
图 7.8 添加分组错误提示
8 结 论
云笔记平台系统通过对标题、笔记、图书信息、用户信息提供统一的管理平台,进行实时的记录和分析来提高的用户的阅读效率。
系统采用 MySQL 作为的数据库,使用 Django+BootStrap 开发,完成云笔记平台系统中标题模块、笔记模块、图书搜索模块、用户分析模块,以及后台管理模块。界面友好,有很好的可维护性和可重用性。在系统开发过程中,使用 Django 的分层模型,将模型层、模板层和视图层代码分开,使代码更易于管理和维护,适合大型项目的开发。
目前,经过测试可以正常使用各个模块。由于时间较短,在一些细节问题的处理上做的还不够好,还需要进一步的改进和完善。在后续使用的过程中,对发现问题及时改正,不断的完善程序,提高用户的满意度。
谢 辞
随着时间的流逝,毕业季也已经到来,而我们的大学生活也将在这 6 月的夏天画上一个完美的句号。心中有很多感慨,舍不得我们的大学生活、大学的同学们、老师们。此时此刻的心情五味陈杂、百感交集,但是更多的还是感激之情。
经过几个月的努力,云笔记平台的开发工作终于完成了。在系统开发过程,首先要感谢徐秀杰老师,徐老师凭着她丰富的知识和多年的经验及时帮我解答开发过程中遇到的问题,无论我犯了多么低级的错误,徐老师都会耐心的帮我指导。徐老师态度严谨,对我们要求很严格,对代码的质量要求也很高。而且她定期检查我的开发进度并提出一些有益的建议。还要感谢我的同学,在我需要他们的时候能够抽出时间来帮我。感谢帮助过我的每一个人!
参考文献
[1] 苏文芝.云笔记的设计与实现[J].电脑迷, 2016,55(12):20-25.
[2] 魏青,杨杰,陈典铖.基于云存储技术的云笔记产品研发[J].广东通信技术, 2013,34(9):43-47.
[3] 齐伟. Django 实战[M].北京:电子工业出版社,2017:150-180.
[4] 林蔚. MD5 安全性分析[D].北京:北京邮电大学, 2014.
[5] 李刚.疯狂 AJAX 讲义[M].北京:电子工业出版社, 2014:30-50.
[6] 孟小峰,周龙骧,王珊.数据库技术发展趋势[J].软件学报, 2004,69(12):1822-1836.
[7] Mark Lutz. Python 学习手册[M].北京:机械工业出版社, 2011:36-45.
[8] 张恒喜,史争军.基于 MySQL 的 Python 数据库编程[J].电脑编程技巧与维护, 2011,55(21):30-31.
[9] Kresse G,Kirchhoff F,Gillan M J.Defects in liquid selenium[J].Physical Review B, 1999, 59(5):3501-3513.
[10] Rayman M P. The importance of selenium to human health.[J]. Lancet, 2000, 356(9225):233-241.
[11] 未来科技. Bootstrap 实战从入门到精通[M].北京:中国水利水电出版社, 2017:25-50.
[12] 曹骏.基于 Django 的数据收集系统的设计与实现[D].南京:南京大学, 2013.
[13] Julia Elman.轻量级 Django[M].北京:中国电力出版社,2016:150-180.
[14] Forcier J, Bissex P, Chun W. Python Web Development with Django[J]. Prentice Hall Computer, 2009,2(2):44-53.
[15] Baron Schwartz,Peter Zaitsev.高性能 MySQL[M].北京:第案子工业出版社,2013:75-90.
[16] 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 2010,36(15):4112-4115.孙品.软件测试[J],计算机与数字工程, 2015,41(11):2713-2715
参考文献
- 基于Django框架的浮云笔记系统的设计与实现(华中科技大学·罗丹)
- 基于微服务架构的大数据分析平台设计与实现(山东大学·徐奎)
- 基于Hadoop的分布式数据存储设计与实现(吉林大学·毛剑)
- 基于微服务的大数据分析平台设计与开发(西安电子科技大学·赵鲁生)
- 基于Spring Cloud的云平台管理系统的研究及实现(华北电力大学(北京)·魏博)
- 区域教育云平台的设计与实现(电子科技大学·代凌薇)
- 基于云计算的桌面办公系统的设计与实现(电子科技大学·徐涛)
- 基于知识图谱的个人知识管理平台的设计与实现(北京邮电大学·罗玄)
- 基于微服务架构的大数据分析平台设计与实现(山东大学·徐奎)
- 基于Spark的社交网络数据分析平台(山东大学·王海林)
- 基于Kettle和Weka的数据转存与挖掘平台(西南科技大学·何宇恒)
- 区域教育云平台的设计与实现(电子科技大学·代凌薇)
- 基于Kettle和Weka的数据转存与挖掘平台(西南科技大学·何宇恒)
- 智能云服务平台系统的设计与实现(北京交通大学·蔡求童)
- 基于微服务的大数据分析平台设计与开发(西安电子科技大学·赵鲁生)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设导航 ,原文地址:https://m.bishedaima.com/yuanma/35872.html