
大数据中的文本挖掘
Introduction
本次作业的任务是故事生成,即给定一个故事标题,要求输出 5 个句子的短故事。我们力图复现一下论文(Seq2Seq,静态两步式生成),并尝试加了一些模块(Self-Attention),以期在本任务上达到较好效果。
Related Work
本次作业本质上是文本生成的任务,序列到序列[1]模型是文本生成领域比较常用的一个算法,也是课程提供的参考文献[2]中使用的方法,采取了编码器-解码器的架构,用编码器编码输入,解码器则用来产生输出,两个模块之间采用注意力模块相连。
参考文献[2]中提出了两步式的故事生成方法,即先对给定的标题生成一个简短的 storyline,再通过 storyline 生成具体的故事。文中提出了两种故事生成的模型,即静态生成模型和动态生成模型。前者先使用序列到序列模型根据标题生成完整的 storyline,再用 storyline 生成故事;后者则是交替式地动态生成 storyline 和故事。在此基础上我们做了一些调研。
Ammanabrolu 等人采用了一个级联的模型来完成给定故事开头续写故事的任务[3]。他们使用了 Martin 等人提出的 event 抽象结构[4]来表示句子,并将其进一步扩展。他们将故事生成的任务分成了生成 event 和生成故事两个步骤,与文献[2]采用中间结构 storyline 的思路相似。Yang 等人提出了根据若干个主题生成文章的方法[5]。他们在 decode 生成文本的时候引入了外部知识,并且借用了 seqGAN 的训练方法增强模型表现。这些工作和本次作业一样,需要根据比较短的输入生成较长的文本。
本次作业采用的评测指标 bleu 值,全称 bilingual evaluation understudy,由 Papineni 等人于 2002 年提出[6],是一种常用于机器翻译等领域的自动评价指标,现也多用于各种文本生成任务的评价。
对于测试集中的每组数据,模型对于输入序列产生一个输出序列,这个输入序列对应一个或多个标准输出(因为机器翻译的任务并不是一对一的,一个句子可以有多种翻译方式,所以可以有多个标准输出)。其基本原则是希望机器翻译得到的译文与人工译文重合度尽可能高。具体评测时,会比较机器译文和参考译文之间的 n-gram 的重合度,即机器翻译中的 n-gram 在参考译文中的最大命中次数。n 一般取 1、2、3、4。但是这样会倾向于给较短的序列更高的分数,因此引入了长度惩罚因数 BP。若机器译文长度小于参考译文,则令 BP<1,会导致最终 bleu 评分降低。其余情况 BP=1。最终计算公式可以表示为:
$$ bleu = BP\dot{}exp(\sum_{n=1}^N{w_nlog(p_n)}) $$
其中 w 表示各个 n-gram 的权重,一般都取为 1/N,p 表示各 n-gram 的命中率。N 一般取为 4,即 bleu 值最多只看机器译文和参考译文 4-gram 的重合程度。BP 可以用以下公式表示:
$$ BP = \begin{cases} 1& {c > r}\ e^{1-r/c}& {c \leq r} \end{cases} $$
其中,c 表示机器译文的长度,r 表示匹配程度最高的参考译文的长度。
因为 n-gram 的命中率 p 可能为 0,导致对 0 取对数,因此在实际中会使用光滑函数[^7]进行特殊处理,保证对数中的自变量大于 0。
bleu 评分综合权衡了序列间的 n-gram 重合度和长度等因素,是一个被广泛使用的指标。但是它的一个比较明显的缺点是只会机械地比较模型输出和标准输出之间的 n-gram 重合度,无法正确比较两者在语义、情感等方面的相似性。不过这也是几乎所有自动评测指标共有的缺点。
Data Analysis
本次作业采用 ROCstories 数据,共有 98161 组数据,其中前 90000 组用于训练,后 8161 组数据用于测试。我们对训练集中数据进行了分析。
2.1. Title Analysis
训练集中,标题组成的词表共有 19349 个不同的词,总共由 196614 个词语组成,标题的平均长度为 2.18。其中出现频率前 5 的单词如下表所示:
| 单词 | the | a | new | to | day |
|---|---|---|---|---|---|
| 出现次数 | 16638 | 4214 | 2884 | 1711 | 1261 |
| 出现频率 | 8.46% | 2.14% | 1.47% | 0.87% | 0.64% |
可见,出现次数前 5 的单词的总出现频率超过了 10%。另一方面,有 9087 个单词在训练集的标题中只出现了一次,有 13397 个单词在训练集的标题中出现次数不超过三次,占了词表的 69.24%。
统计了训练集中标题长度的分布,最短的标题长度为 1,最长的标题长度为 25。具体分布如下图所示:
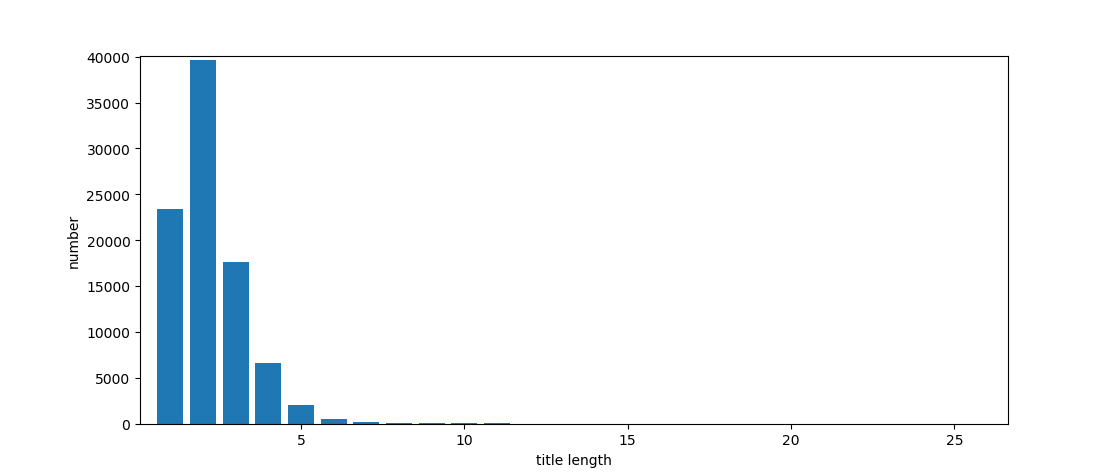
可以看到,长度为 2 的标题数量最多,其次是长度为 1,3,4,5 的。长度小于等于 5 的标题占了所有标题的 99.23%。
2.2. Story Analysis
故事组成的词表共有 65336 个不同的单词。总共由 3936562 个词语组成。在长度上,不同位置的句子的长度分布有比较明显的差别,各个位置句子的平均长度如下表所示:
| 句子位置 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 平均长度 | 7.90 | 8.82 | 8.89 | 8.80 | 9.33 |
所有句子的平均长度是 8.75。可以看到,第一个句子的平均长度明显小于其他位置的。另一方面,各个位置句子组成的词典出现频率前 10 的词中有 6 个共有的,前 20 的词中有 13 个共有的,前 100 的词中有 51 个共有的。说明各个位置的句子在词表的分布上也有一定区别。
所有句子组成的词表中出现次数前 5 的单词如下表所示:
| 单词 | the | to | a | was | he |
|---|---|---|---|---|---|
| 出现次数 | 196912 | 155817 | 127907 | 107254 | 103488 |
| 出现频率 | 5.00% | 3.96% | 3.25% | 2.72% | 2.63% |
与标题的词表中一样,出现频率前 5 的单词占了总的词数中的相当一部分,超过了 15%。另一方面,故事的词表中有 24688 个词只出现了一次,出现次数不超过三次的词有 39042 个,占了词表的 59.76%。
训练集中句子的长度最短为 1,最长为 19,具体分布如下图所示:

句子长度的分布大致上比较接近正态分布,越靠近平均长度的数量越多。
Work of This Repo
本来是想在作者的源码上改一下,加点其他模块。但是看了一下作者的源码,发现作者的源码里有相当多的操作非常迷幻,比如加了很多论文中没有提到的 trick(如 Weight Drop),似乎没有在 model 中用 Attention(但论文中明确提到有)等等。另一方面,从代码风格上来讲,作者的源码对我们而言确实不够平易近人,难以下手修改。总之,咱也看不懂,咱也不敢问,TAT
于是我们只能把 baseline 重写一遍。。。
Description
按照论文中的描述,所谓 Static 式生成其实就是两步走,先 Seq2Seq 生成 StoryLine,再 Seq2Seq 生成 Story。本 repo 也只实现了基本的 Seq2Seq(带 Attention 的)。
在实现过程中,参考了一些网上的风格较好的 tutorial,基于 pytorch 和 torchtext 等封装较好的库。
Usage
-
准备数据(
data目录下) -
利用 RAKE 算法抽取关键词不在本 repo 范围内
- 原始数据文件名为 /train/valid/test_title_line_story.txt
-
可运行 data_split.py 把数据集按照不同的域切分, 保存格式为 tsv
如在 title to story-line 过程中,只需使用
title与story_line两个域,生成的样例可参见train_title_line.tsv- 在 config.py 里设置参数,如数据集目录,模型超参数, 训练好的模型保存路径,生成的结果路径等 - 传入上一步 config 的名字,运行 main.py, 可参考scripts_example中的/title2line.sh和line2story.sh -
可通过
mode参数选择是否要进行训练或生成
Some Tricks
- Vocabulary 截断。本 Repo 并没有使用预训练好的词向量,而本任务又难以从头开始学到足够好的词向量,尤其是某些低频词。所以我们在构建词典的时候把很多低频词都扔掉了。(如果不扔的话,训练结果会非常差)
- 抑制重复。在生成故事线的过程中,生成的 5 个词往往会重复,论文中在 decode 的时候暴力去重,我们也沿用了这样的方法。
Advanced Attmpt
考虑到只重写了一个 baseline,没有一点儿花里胡哨的东西,面子上总是挂不住滴。由于时间有限,我们也没有尝试加其他更复杂的东西,考虑到 model architecture 最容易解耦,所以尝试了一个较为花哨的 model。
一言以蔽之,我们想把 self-attention 加到 RNN 里。self-attention 最早被大家熟悉应该是在 transformer 系列工作中。transformer 系列工作完全抛弃了 RNN 的循环思路,而是采用 MutiHeadAttention 模块作为基石。我们使用 多层 RNN 作为 Encoder,并在 RNN 层与 RNN 层之间插入了 MutiHeadAttention 模块。

Experiment
- 复现 Baseline
泛化性能差。具体表现在模型稍微一训练就会过拟合。trainset 上的 loss 可以一直下降,但 validset 上的 loss 不到 5 个 epoch 就到达了最低点并开始上升。这意味着模型的容量很大,足以拟合训练集,但这种拟合是大大牺牲了泛化性能的。
两步的 loss 如下图所示
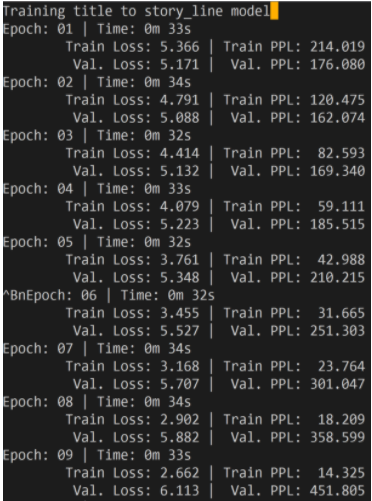
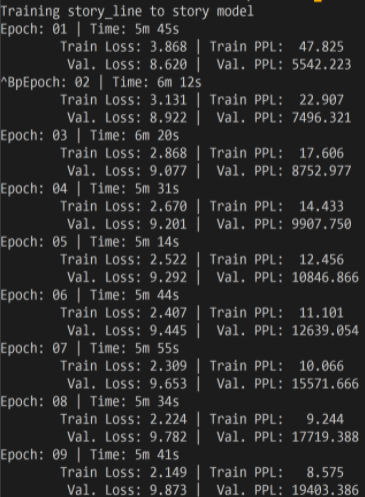
可能是由于我们并没有像论文中一样添加了很多 trick,所以我们复现的模型的 bleu score 的结果要比源码差一些 - 加入 Self-Attention 模块
我们惊奇地发现加入此模块后,训练过程中 valid loss 不再飘
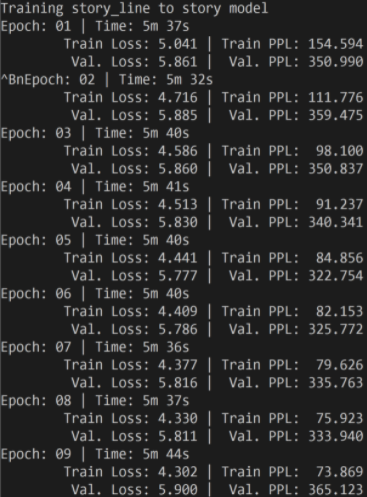
但很遗憾,我们发现 decode 的结果其实很差,每个 story-line 几乎都 decode 出了同样的结果。所以也解释了 valid loss 不飘吧。
究其原因,应该是这个 task 本身的 src 很短,在 encoder 模块加很复杂的可学习模块其实更容易导致整个框架过拟合
参考文献
- 基于Web数据挖掘的电子商务推荐系统研究(同济大学·裴蕾)
- 基于Spring Cloud的分布式语义分析挖掘平台中管理子系统的设计与实现(北京邮电大学·任聚才)
- 基于Mongodb推荐系统的研究与应用(华中科技大学·和慧)
- 数据挖掘算法的改进及应用研究(广西民族大学·路闯)
- 基于大数据的区域医疗系统数据采集与挖掘(湖北工业大学·刘波)
- 数据资产管理系统的设计与实现(南京大学·朱元甫)
- 基于Mongodb推荐系统的研究与应用(华中科技大学·和慧)
- 基于移动平台股票资讯搜索与预测系统研究(哈尔滨理工大学·滕文达)
- 基于大数据的区域医疗系统数据采集与挖掘(湖北工业大学·刘波)
- 基于元搜索的Web信息搜索技术研究(吉林大学·张春磊)
- 基于通用中间表示的脚本语言漏洞静态挖掘技术(哈尔滨工业大学·王一航)
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- 基于医疗数据的文本挖掘研究与实现(上海工程技术大学·沈宙锋)
- 数据挖掘算法的改进及应用研究(广西民族大学·路闯)
- 数据资产管理系统的设计与实现(南京大学·朱元甫)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码客栈 ,原文地址:https://m.bishedaima.com/yuanma/35884.html









