
对 EEG 数据进行聚类分析
实验内容:
采用任意 2 个聚类算法对 EEG 数据进行聚类分析,并分析聚类结果: –算法参数与聚类结果的关系 –聚类结果与其它标签之间的关系等
实验数据:
EEG 数据库,共 533 个脑电信号,每个脑电信号由 160 维特征组成,这些信号是收集 27 名测试者观察 20 个视频所产生的脑电信号所得,每个信号对应的标记为观看视频的人 subjectID,视频 videoID,情感类别 emotion category, valence, arousal,共五种标记。其中 subjectID 有 27 个状态,videoID 有 20 种状态,emotion category 有 9 中状态,valence 有 2 中状态,arousal 有两种状态。
实验过程:
首先对 533*160 的特征数据进行归一化。然后分别使用 KMeans 和 GaussianMixture 对其进行聚类,设置超参数聚类个数分别为 9,27,20,2,2,对应已知的五种标记对应的状态数目。
由于两种聚类方法初始均需随机初始化参数或者聚核,所以我们分别进行了十次实验然后根据内部指标选择最佳的实验结果。
测试聚类效果的时候我们分别采用内部指标与外部指标。外部指标为 adjusted random index(ARI)。内部指标有所不同,对于 KMeans 我们采用 DBI 指数和类内误差的平均值,对于 GaussianMixture 我们采用 DBI 指数。其中 ARI 指数越大越好,DBI 指数越小越好,类内误差的平均值越小越好。同时为了比较聚为不同类别时的聚类效果,我们利用 MDS 降维方法来进行可视化处理。
实验结果:
----------------KMeans---------------
================1、Emotion Category==================
外部指标 ARI:0.0020467375297614806
内部指标 avg center distance:34.660456271469684
内部指标 DBI:1.5041799557881894
stress(n_components = 2):1079890.2144941238 数据降维时造成的距离的误差总和

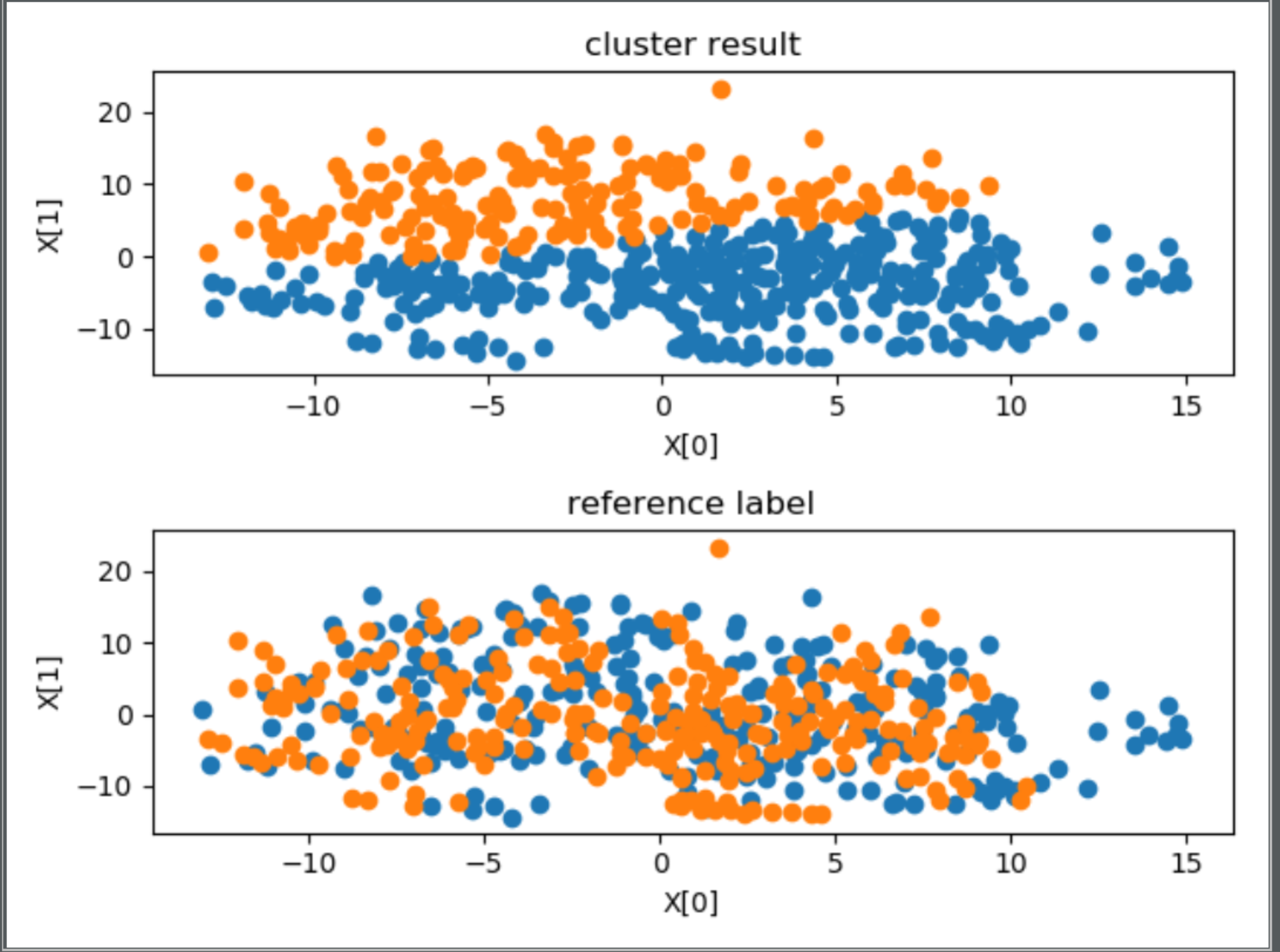
================2、Subject ID==================
外部指标 ARI:0.7924484950900978
内部指标 avg center distance:16.418370754616443
内部指标 DBI:1.1394404321099192
stress(n_components = 2):1007730.9877045417
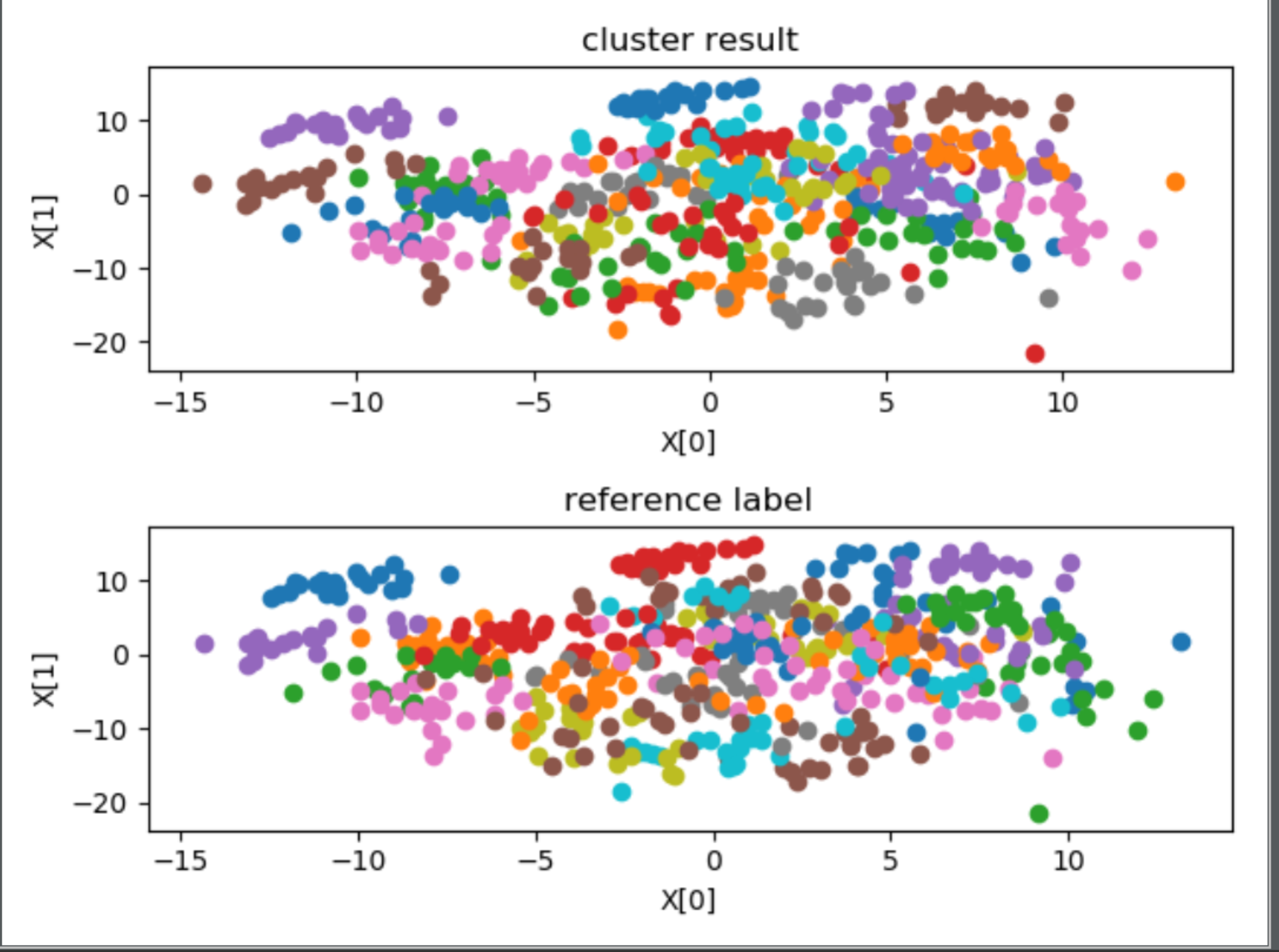
================3、VideoID==================
外部指标 ARI:-0.02616458010765954
内部指标 avg center distance:21.365765457716037
内部指标 DBI:1.2578781806024335
stress(n_components = 2):1134649.2184728314
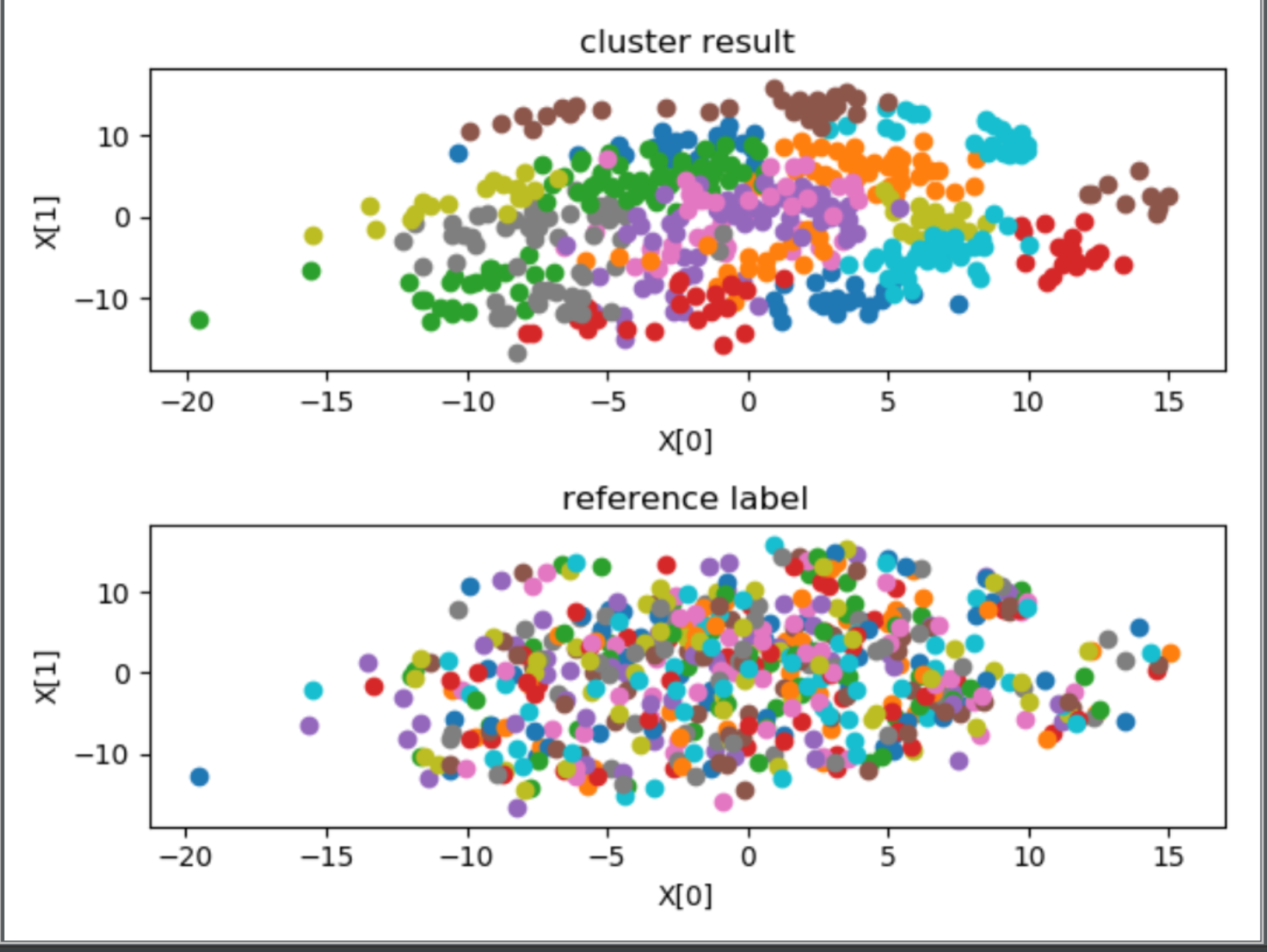
================4、valence==================
外部指标 ARI:-0.002312831819365238
内部指标 avg center distance:69.4935622847214
内部指标 DBI:1.4951516844883002
stress(n_components = 2):1060398.7266490702
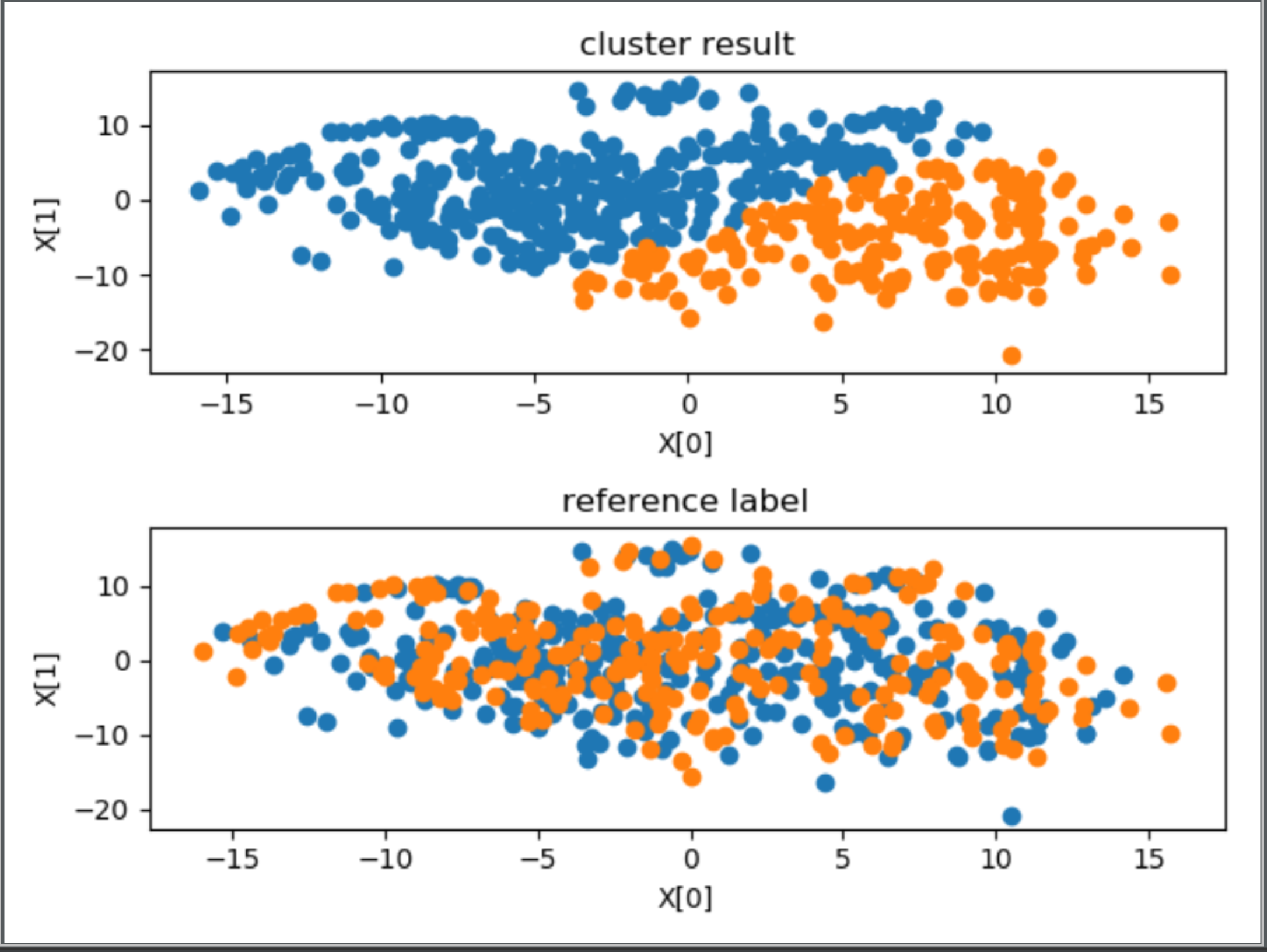
================5、arousal==================
外部指标 ARI:0.003130360396821968
内部指标 avg center distance:69.4935622847214
内部指标 DBI:1.4951516844883002
stress(n_components = 2):1157448.5527312672
----------------GaussianMixture-----------------
================1、Emotion Category==================
外部指标 ARI:-0.0005029018983204495
内部指标 DBI:1.5451636606300023
stress(n_components = 2):1141952.4220823725
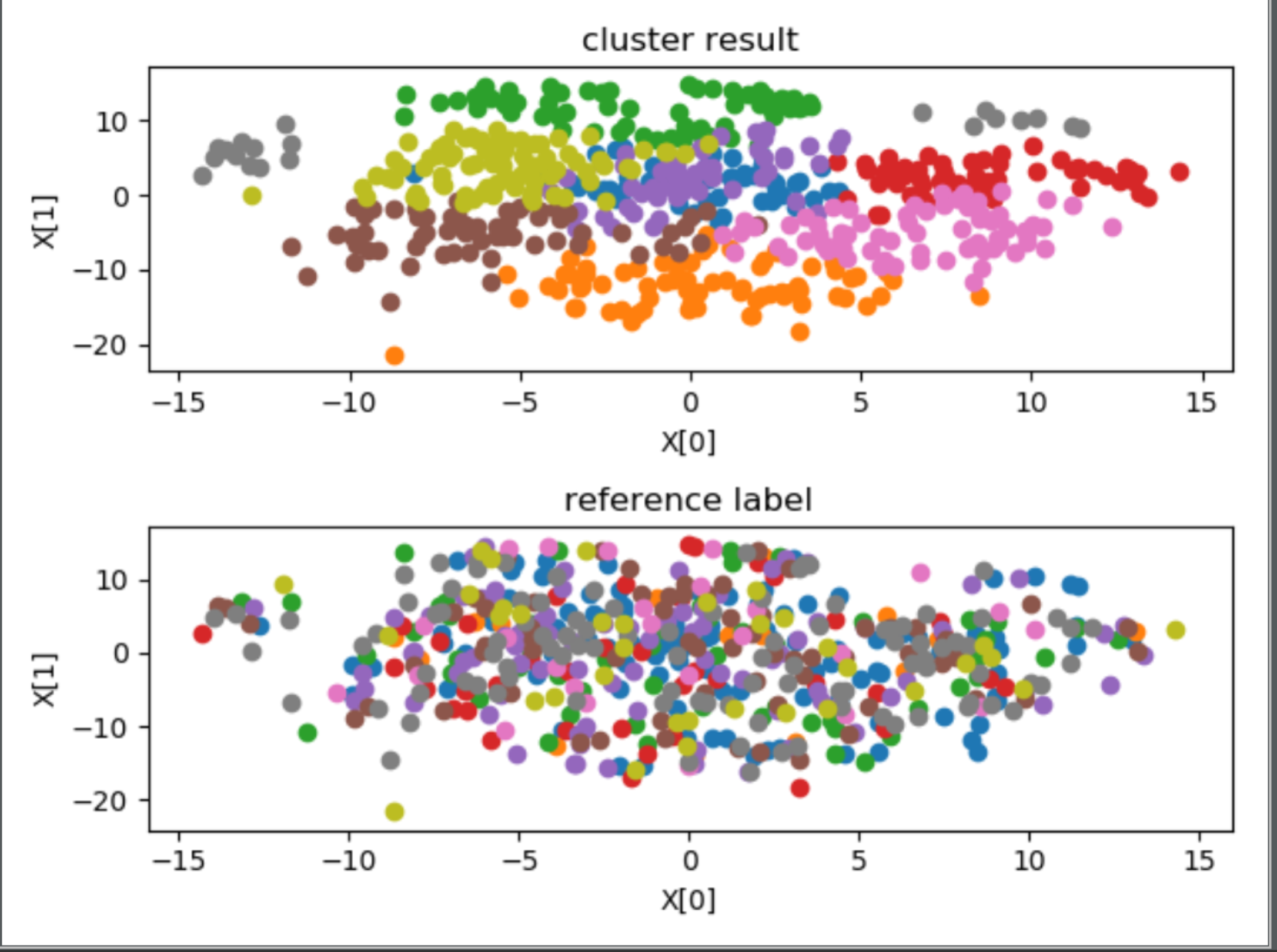
================2、Subject ID==================
外部指标 ARI:0.8369225786270984
内部指标 DBI:1.1364962346551442
stress(n_components = 2):1007713.8592547531
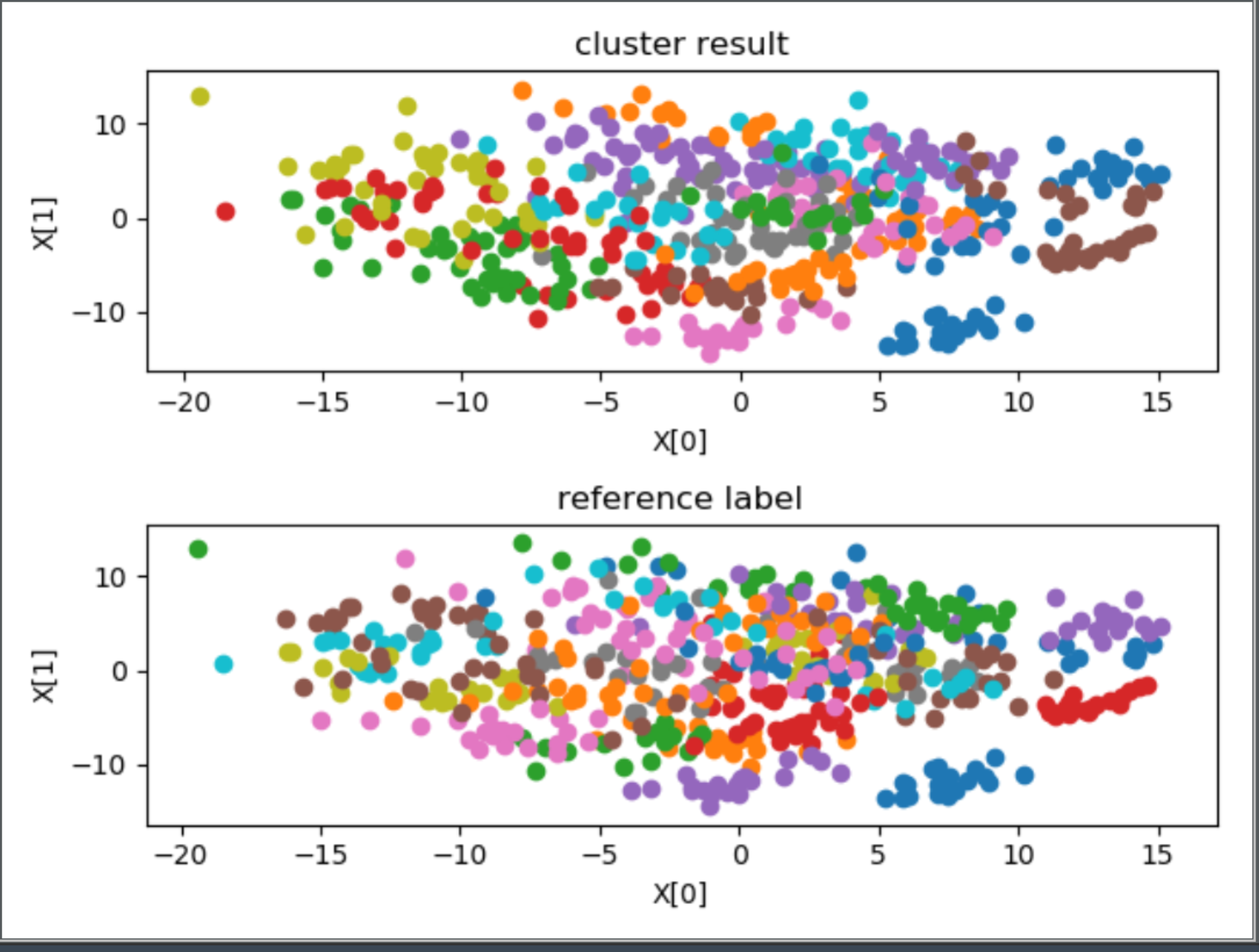
================3、VideoID==================
外部指标 ARI:-0.02650091723277949
内部指标 DBI:1.2352222772700536
stress(n_components = 2):1105012.0670813427
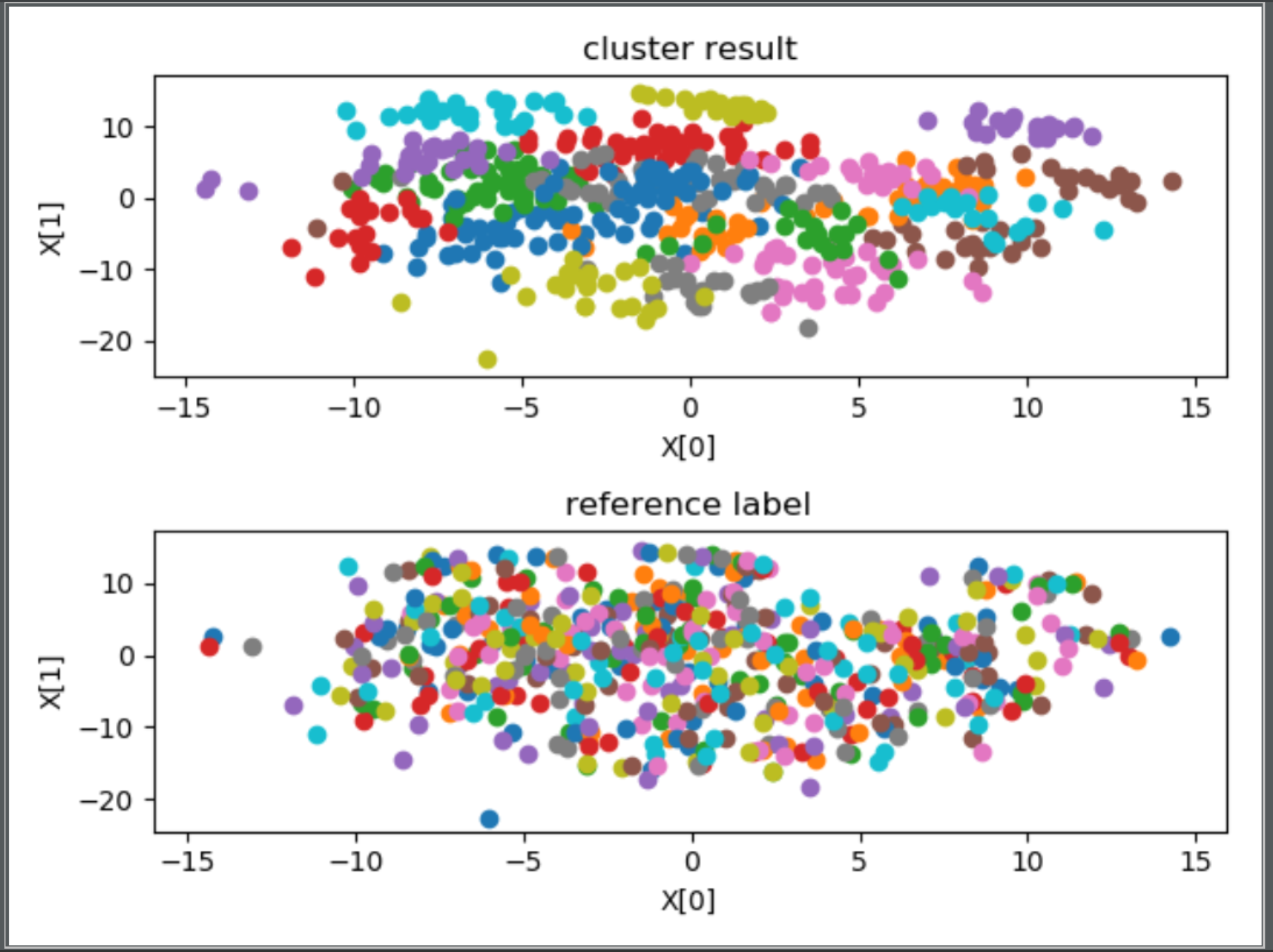
================4、valence==================
外部指标 ARI:-0.002239927863109331
内部指标 DBI:1.5193465665610577
stress(n_components = 2):1024772.0071349532

================5、arousal==================
外部指标 ARI:0.0025774351776258015
内部指标 DBI:1.5193465665610577
stress(n_components = 2):1038575.8012245239
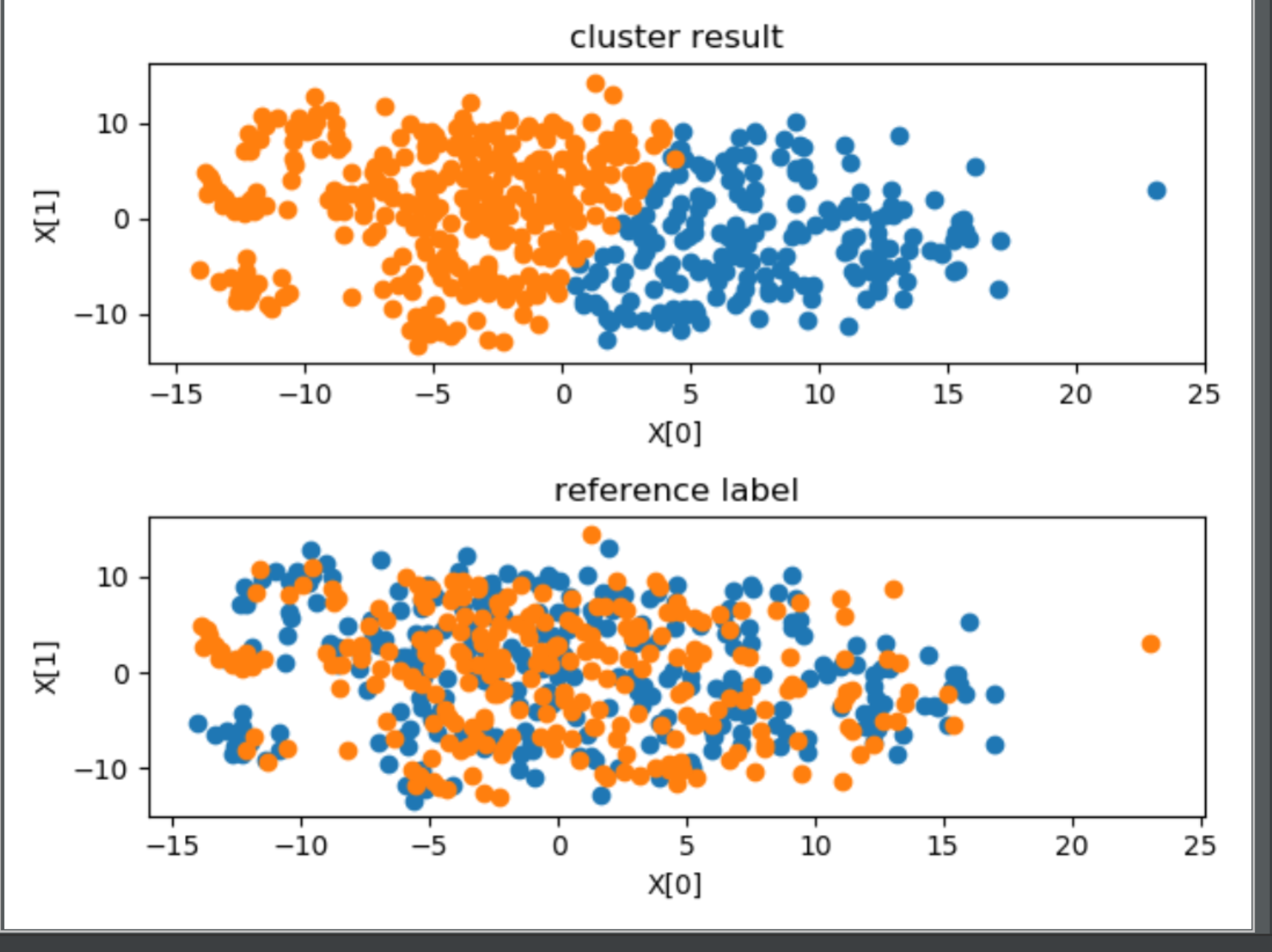
结果分析:
首先观察内部指标,如果内部指标效果很差,这说明聚类结果没有实际意义,如果内部指标效果很好,这说明聚类结果反映了某种指标下的分类情况,有实用意义,此时如果给定某种参考指标,然后得到的 ARI 指数也比较好的话,说明聚类情况近似反映了这种指标,否则只能说明聚类反映的情况与参考指标不符。
在本问题中,从可视化图中的第一幅子图,除了聚为 27 类时,其余的聚类效果均不错,空间上距离比较近的聚为了一类。对比每幅图中的两幅子图可以发现,聚为 27 类时,聚类结果与 subjectID 标记相近,尤其是两种聚类方法的外部指标 ARI 均在 0.80 附近,可以认为此时聚类结果近似反映了 subjectID,或者说 subjectID 关于这些特征在特种空间中的分布具有集群性。所以得出结论,将特征按照 subjectID 聚为 27 类比较合适,即测试者对于该问题的直接聚类具有非常大的影响,不同人的 EEG 脑电波有着显著的差别。
参考文献
- 股票系统之热门话题发现子系统的设计与实现(哈尔滨工业大学·周思华)
- 基于K-Means的分布式文本聚类系统的设计与实现(西安电子科技大学·马婵媛)
- 面向检验检疫领域主题爬虫的研究及系统实现(浙江大学·周桓)
- 大数据平台聚类分析系统的设计与实现(南京邮电大学·王壮)
- 信用卡信息记录平台构建及聚类方法研究与应用(吉林大学·朱张平)
- 深度学习在社交网络文本分类中的应用研究(大连交通大学·方金朋)
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
- 面向垂直搜索的聚焦爬虫研究及应用(浙江大学·吕昊)
- 深度学习在社交网络文本分类中的应用研究(大连交通大学·方金朋)
- 销量数据挖掘技术及电子商务应用研究(广东工业大学·周昊明)
- 基于Hadoop的电商数据分析系统的设计与实现(广西师范大学·孙明铎)
- 海量网络数据环境下的元数据管理及应用(北京邮电大学·常思源)
- 面向检验检疫领域主题爬虫的研究及系统实现(浙江大学·周桓)
- 图结构数据聚类分析平台的研究及原型实现(东华大学·陈文俊)
- 基于K-Means的分布式文本聚类系统的设计与实现(西安电子科技大学·马婵媛)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设向导 ,原文地址:https://m.bishedaima.com/yuanma/35887.html









