
Python网络爬虫
一、设计目的
-
巩固和加深我们对python知识,以及对爬虫技术进一步加深认识。
-
提高我们编程的能力以及思考能力
二、设计任务完成
-
网络爬虫是从web中发现,下载以及存储其中的内容。并且从首页URL爬取,然后不断从当前网页获取URL加入,来不断深入获取各个URL的内容。
-
抓取小说网站,抓取一系列小说的篇名、作者、出版单位(或首发网站)、出版时间(或网上发布时间)、内容简介、小说封面图画、价格、读者评论或评分等多项信息,并将上述信息组织成表格形式(可以是csv、json、excel等)加以保存。另外,还可以深度抓取某部小说的多个章节或全部章节进行分词和词频统计。
-
抓取的是网站不是网站的首页。抓取的内容一定要分布在整个网站的多个页面和多个链接中。
- 程序中加入了反爬技术(包含模拟人加入了时间间隔访问,以及隐藏爬虫身份)
- 程序使用了正则表达式(通过正则来匹配标签)
三、网络爬虫程序步骤
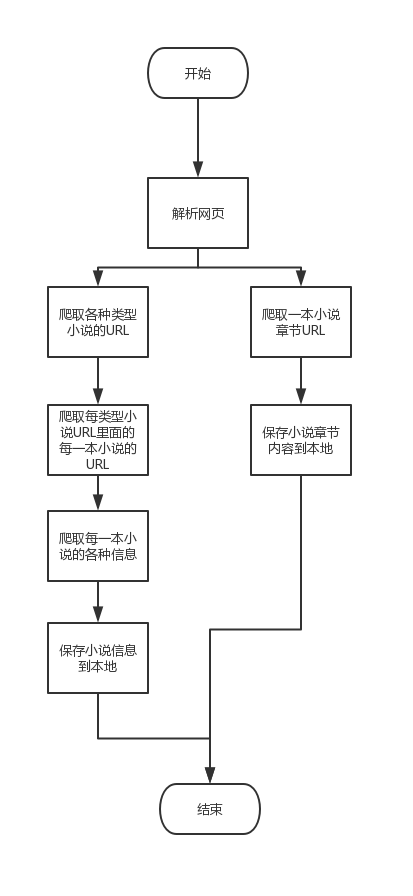
四、爬虫详细设计
4.1 设计环境和目标分析
4.1.1 设计环境
①本地环境
IDE:pycharm
Python版本:python3.7.1
②首先需要安装bs4的库:pip3 install beautifulsoup4
③使用到的库如下:
python
from bs4 import BeautifulSoup
import requests
import random
import re
import time
import csv
import os
4.1.2 目标分析
目标 :爬取新笔趣阁小说网开始,爬取各分类小说的网址以及各分类小说里的部分小说,以及小说的各种信息,同时爬取一本小说下来进行词频统计。
简介 :
-
初始URL:http://www.xbiquge.la/
-
页面编码:UTF-8
通过F12在控制台输入document.charset来查看页面编码
- 小说URL:http://www.xbiquge.la/62/62203/
小说章节URL和小说URL的关系:通过小说URL和获取的章节URL拼接才是正确的可访问的章节URL
- 分析网页HTML代码
①首页
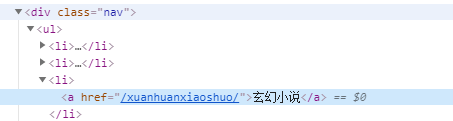
②类型小说

③小说章节
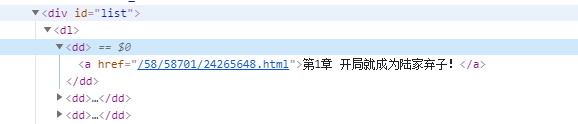
4.2 代码流程详细分析
爬取URL内容

获取首页各类小说URL
说明:即首页中的玄幻小说分类,网游小说分类等一些链接的URL(获取该URL再逐个进去获取各个分类小说)

获取分布在各类小说URL内的每一本小说的网址

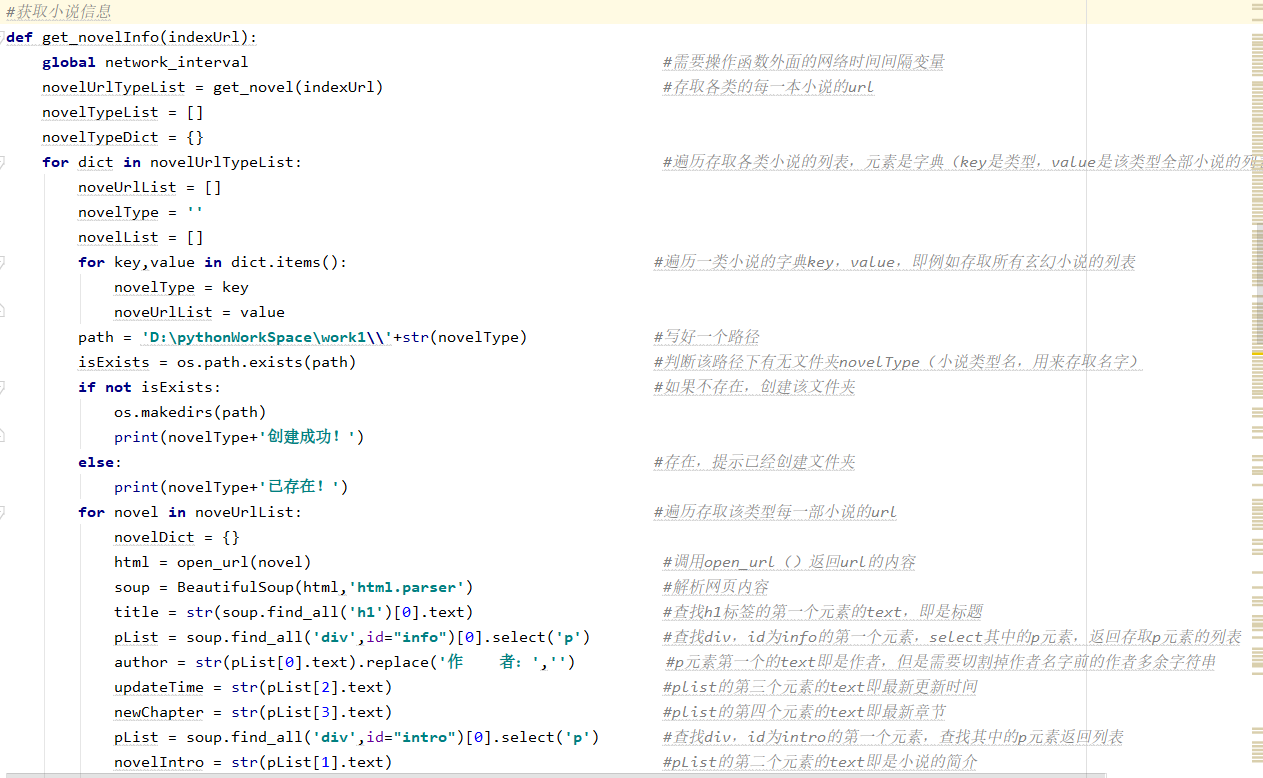
获取每一部小说的信息

保存小说图片

保存小说简介到csv文件

爬取小说的每一章节的URL

爬取章节内容

下载小说

获取小说内容

统计文本

主程序

4.3 完整代码
```c++ from bs4 import BeautifulSoup import requests import random import re import time import csv import os
network_interval = 0.1 # 联网间隔,自动调整避免503
爬取url的内容
def open_url(url): global network_interval header = [ 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)', 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)' ] header = {'User-Agent': str(header[random.randint(0, 3)])} request = requests.get(url=url, headers=header) if request.status_code != 200: network_interval += 0.1 print('(503 正在重试...)', round(network_interval, 2)) return open_url(url) if network_interval > 0.1: network_interval *= 0.995 response = request.content response_decode = response.decode("UTF-8","ignore") return response_decode
获取首页各类小说URL
def get_novelTypelUrl(indexUrl): html = open_url(indexUrl) soup = BeautifulSoup(html,"html.parser") urlList = [] textList = [] aList = [] for novels in soup.select('.nav'): aList += novels.find_all(re.compile('a')) for novels in aList: text = novels.text textList.append(text) novels = novels['href'] url = indexUrl + novels urlList.append(url) textList = textList[2:8] urlList = urlList[2:8] dict = {} for i in range(len(urlList)): dict[textList[i]] = urlList[i] return dict
获取各类小说里的每一本小说url
def get_novel(indexUrl): dict = get_novelTypelUrl(indexUrl) novelTypeList = [] for key,value in dict.items(): html = open_url(value) soup = BeautifulSoup(html,"html.parser") novelList = [] typeDict={} urlList = [] for s2 in soup.find_all('div',attrs={'class':"l"})[0].select('.s2'): novelList += s2.find_all('a') for url in novelList: url = url['href'] urlList.append(url) typeDict[key] = urlList novelTypeList.append(typeDict) return novelTypeList
获取小说信息
def get_novelInfo(indexUrl): global network_interval novelUrlTypeList = get_novel(indexUrl) novelTypeList = [] novelTypeDict = {} for dict in novelUrlTypeList: noveUrlList = [] novelType = '' novelList = [] for key,value in dict.items(): novelType = key noveUrlList = value path = 'D:\pythonWorkSpace\work1\'+str(novelType) isExists = os.path.exists(path) if not isExists: os.makedirs(path) print(novelType+'创建成功!') else: print(novelType+'已存在!') for novel in noveUrlList: novelDict = {} html = open_url(novel) soup = BeautifulSoup(html,'html.parser') title = str(soup.find_all('h1')[0].text) pList = soup.find_all('div',id="info")[0].select('p') author = str(pList[0].text).replace('作者:','') updateTime = str(pList[2].text) newChapter = str(pList[3].text) pList = soup.find_all('div',id="intro")[0].select('p') novelIntro = str(pList[1].text) imgList = soup.find_all('div',id='fmimg')[0].select('img') imgUrl = str(imgList[0]['src']) imgContent = requests.get(imgUrl).content writeImg(key,title,imgContent) novelDict['标题'] = title novelDict['作者'] = author novelDict['更新时间'] = updateTime novelDict['最新章节'] = newChapter novelDict['小说介绍'] = novelIntro novelDict['链接'] = novel print('链接:',novel) novelList.append(novelDict) time.sleep(network_interval) novelTypeDict[novelType] = novelList novelTypeList.append(novelTypeDict) writeNovelData(novelType,novelList)
保存小说图片
def writeImg(key,title,imgContent): with open('D:\pythonWorkSpace\work1\'+key+'\'+title+'.jpg','wb') as f: f.write(imgContent)
保存小说简介到csv
def writeNovelData(key,novelList): with open(key+'.csv', 'w', encoding='UTF-8', newline='') as f: writer = csv.DictWriter(f,fieldnames=['标题','作者','更新时间','最新章节','小说介绍','链接']) writer.writeheader() for each in novelList: writer.writerow(each)
爬取小说每一章节的URL
def chapter_url(url): html = open_url(url) soup = BeautifulSoup(html,'html.parser') charpterUrlList = [] charpterurl = soup.find('div',id="list").select('a') for i in charpterurl: i = i['href'] trueUrl = 'http://www.xbiquge.la'+i charpterUrlList.append(trueUrl) return charpterUrlList
获取章节内容
def get_content(url): pageHtml = open_url(url) soup = BeautifulSoup(pageHtml,'html.parser') chapterTitle = soup.h1.string chapterContent = soup.find_all('div',id='content')[0].text chapterContent = ' '.join(chapterContent.split()) content = chapterContent.replace(' ','\r\n\n') finallContent = chapterTitle+'\r\n\n\n'+content return finallContent
下载小说
def downloadNovel(url): print("线程1") pageHtml = open_url(url) soup = BeautifulSoup(pageHtml,'html.parser') title = soup.h1.string print("开始下载小说:") chapterlist = chapter_url(url) lenchapter = len(chapterlist) print("这部小说一共有%d章"%lenchapter) count = 1 for url in chapterlist: text = get_content(url) with open('D:\pythonWorkSpace\work1\'+title+'小说.txt','a',encoding='UTF-8') as f: f.write(text+'\r\n\n\n\n') a = (count/lenchapter)*100 print('正在下载%d章,进度%.2f%%'%(count,a)) count+=1 time.sleep(network_interval) print("下载完成")
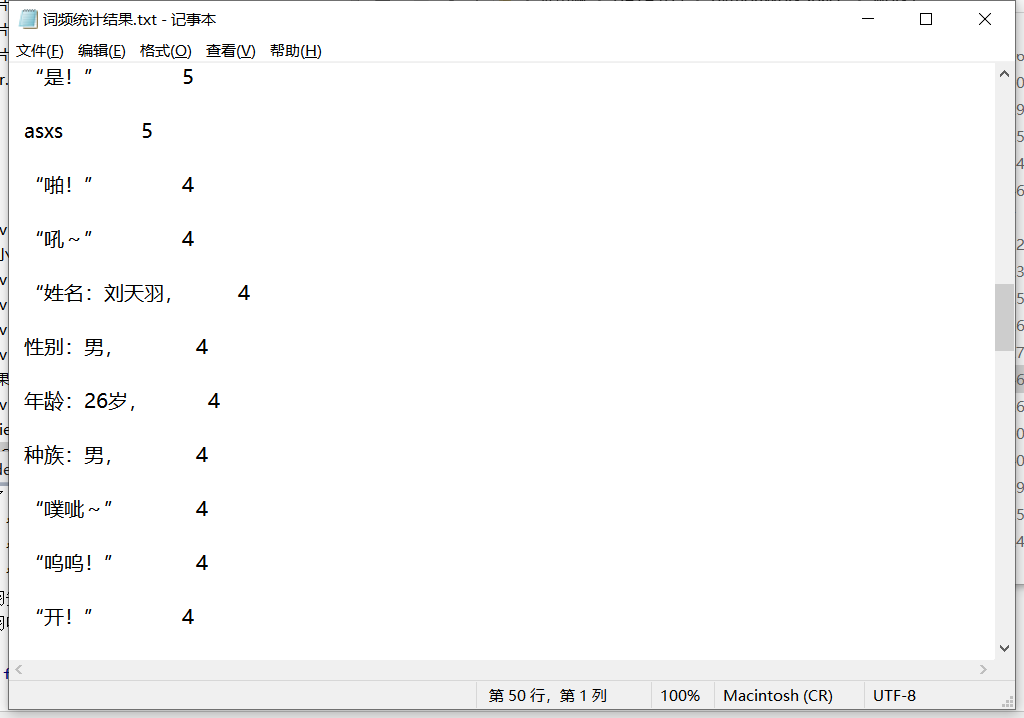
词频统计
def getFileText(): with open("D:\pythonWorkSpace\work1\末日大世界小说.txt","r",encoding="UTF-8") as papFile: filTxt=papFile.read() filTxt=filTxt.lower() for ch in '!"#$%&() +- /,.:;<=>?@[]\^_{}|~': filTxt=filTxt.replace(ch,' ') return filTxt
def staticsText(): papTxt = getFileText() papTxt = papTxt.replace('点击进去','').replace('给个好评呗','').replace('分数越高更新越快','')\ .replace('据说给新笔趣阁打满分的最后都找到了漂亮的老婆哦','')\ .replace('手机站全新改版升级地址:http','').replace('xbiquge','')\ .replace('la,数据和书签与电脑站同步,无广告清新阅读!','') words = papTxt.split() wdCountDict = {} excludes = {"的", "你", "我", "他", "这", "和"} for word in words: wdCountDict[word] = wdCountDict.get(word, 0) + 1 for word in excludes: if word in wdCountDict: del wdCountDict[word] items = list(wdCountDict.items()) items.sort(key=lambda x: x[1], reverse=True) staticsStr = "" staticsStr += "{0:<17}{1:>4}".format(" word", "count") print("{0:<17}{1:>4}".format(" word", "count")) print("*" * 24) for key, val in items: if len(key) > 3 and val > 2: print("{0:<17}{1:>3}".format(" " + key, val)) staticsStr += "{0:<17}{1:>3}".format(" " + key, val) return staticsStr
def writeStatics(staticsStr): with open("D:\pythonWorkSpace\work1\词频统计结果.txt","w",encoding="UTF-8") as f: f.write(staticsStr)
if name ==' main ': indexUrl="http://www.xbiquge.la/" novelUrl = "http://www.xbiquge.la/62/62203/" open_url(indexUrl) get_novelInfo(indexUrl) downloadNovel(novelUrl) writeStatics(staticsText()) ```
五、效果截图
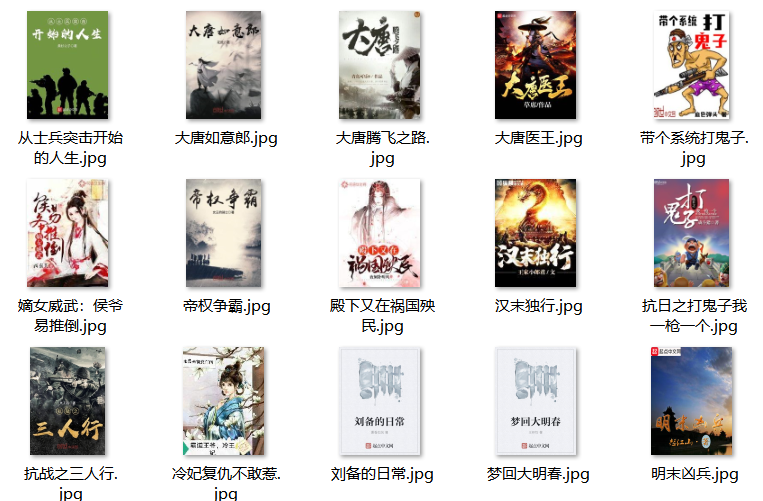
①小说图片
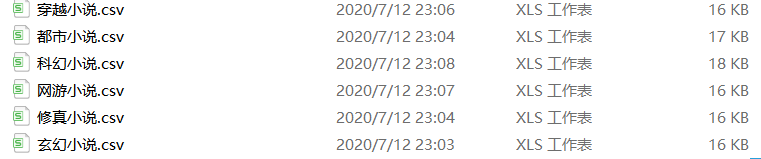
②小说简介信息

③小说内容


六、总结
经过这一次爬虫的学习,可以说是对老师之前所讲的知识的一个巩固,无论是列表,字典,又或者是字符串的操作,又或者是文件操作,以及爬虫相关的知识全都用上了。同时,这一次也让自己学会了很多东西,比如是自己在做的时候有遇到许多问题,比如是自己因为没有加入时间间隔去访问,会经常503访问异常,同时加入了时间间隔,有时也会出现,就需要我们递归重新调用该函数重新爬取数据。又或者是对文本的处理,对他们保存的格式,让他们看起来更加的方便,以及CSV格式的保存。这一次的爬虫课程设计,不仅仅是一次作业,更是对自己这一个学期以来学习的回顾,也是提高自己python编程能力,以及自己思考问题的方式。
参考文献
- 过滤型网络爬虫的研究与设计(厦门大学·陈奋)
- 面向垂直搜索的聚焦爬虫研究及应用(浙江大学·吕昊)
- 网络文学平台的设计与实现(华中科技大学·王俊)
- 垂直搜索引擎爬虫系统的研究与实现(贵州大学·吴建强)
- 基于网络爬虫的搜索引擎的设计与实现(湖北工业大学·冯丹)
- 基于Bloom Filter算法的URL去重算法研究及其应用(河南大学·孟慧君)
- 分布式智能网络爬虫的设计与实现(中国科学院大学(工程管理与信息技术学院)·何国正)
- 网络爬虫技术在云平台上的研究与实现(电子科技大学·刘小云)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 基于网络爬虫的搜索引擎的设计与实现(湖北工业大学·冯丹)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 基于WEB的爬虫系统的设计与实现(西安电子科技大学·卢哲辉)
- 主题爬虫关键技术研究(哈尔滨工程大学·黄正德)
- 面向垂直搜索的聚焦爬虫研究及应用(浙江大学·吕昊)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码港湾 ,原文地址:https://m.bishedaima.com/yuanma/35954.html









