
客服脚本解释器实现
一、脚本设计说明
1. 编码
默认情况下,以UTF-8编码进行解析脚本 也可以为源码文件指定不同的编码解析方式(类似于Python) 在脚本开头注明以下语句代表文件以GBK编码解析
! using coding GBK
2. 关键字
$\color{red}{Entry}$ : 入口过程的过程名,缺失则无法执行脚本 $\color{red}{Proc}$ : 定义过程的定义符号 $\color{red}{begin}$ : 过程结构和分支结构的开始符 $\color{red}{end}$ : 过程结构和分支结构的结束符 $\color{red}{OUT}$ : 控制台输出指令 $\color{red}{IN}$ : 控制台输入指令 $\color{red}{Switch}$ : 分支选择结构定义符 $\color{red}{Branch}$ : 分支结构内用于选择分支的关键字 $\color{red}{Default}$: 分支结构内用于默认分支的关键字 $\color{red}{Run}$ : 运行指定过程指令 $\color{red}{Loop}$ : 循环运行指定过程指令 $\color{red}{EXIT}$ : 退出程序指令
关键字不允许被标识符定义或使用
(1) 入口过程Entry
入口过程必须在脚本中给出具体的声明与定义 程序寻找Entry作为入口解释执行 若未定义改Proc过程将会抛出错误
定义方法
python=
Proc Entry
begin
# 此处需要给出过程执行语句
OUT $name + ",请问有什么可以帮您?"
end
若未声明定义抛出错误
Can't find Entry Proc in script
The program must start at Entry Proc
(2) 过程定义Proc
过程定义方式为:
python=
Proc 过程名称(需要遵守标识符规定)
begin
# begin 和 end是必须的,指明过程块的开始与结束
# 此处填写过程语句
end
example:
python=
Proc Complain
begin
OUT "您的意见是我们改进工作的动力,请问您还有什么补充"
IN $complain_content
OUT "您的建议我们已经收到,感谢您对我们工作的支持"
end
(3) 输出指令OUT
输出方式为
python=
OUT "内容"
输出指令仅允许在过程中给出
这里的内容指的是一个字符串,这里可以是单独的字符串,也可以是多字符串的拼接,也可以对字符串变量进行引用
python=
OUT "您好" + $name + ",感谢你的来电"
(4) 输入指令IN
输入指令IN后必须跟已经提取声明的变量以将内容存储于该变量
输入方式为
python=
IN $name
(5) 分支结构定义Switch
选择分支Switch的定义方式为
python=
Switch $需要选择模糊匹配的变量名称
begin
Branch "内容1" Run 过程名
Branch "内容2" Loop 过程名 次数
Default Run 过程名
end
上述说明中,Branch后面仅允许跟字符串内容,进行模糊匹配:若内容出现在输入中则走向该分支,分支仅允许单次运行某个过程或者循环运行某个过程(见 6 分支结构跳转Branch)
匹配可进行多次匹配,即可以按顺序进入多个分支进行执行
在Switch结构中必须给出Default分支,代表无匹配内容则走向默认分支(见 7 分支结构默认跳转Default)
python=
Switch $input
begin
Branch "查询" Loop QueryInfo 3
Branch "投诉" Run Complain
Branch "退出" Run Exit
Default Run Unknow
end
(6) 分支结构跳转Branch
Branch仅能出现在Switch结构中
Branch代表匹配分支,只能使用Run和Loop执行过程
python=
Branch "内容1" Run 过程名
Branch "内容2" Loop 过程名 次数
(7) 分支结构默认跳转Default
Default必须存在于每个Switch结构中,否则抛出错误
python=
Default Run Unknow
(8) 单次运行过程语句Run
Run 后跟随过程名代表执行单次该过程
可以在过程中出现,可以进行嵌套调用或递归调用
python=
Run 过程名称
example
python=
Run QueryInfo
(9) 循环运行过程语句Loop
Loop后跟随过程名和循环次数可以执行指定循环次数的该过程
python=
Loop 过程名称 次数
example
python=
Loop QueryInfo 3
(10) 退出脚本指令EXIT
使用EXIT指令代表程序的退出 PS:EXIT代表程序的强制结束,而程序实际结束点在Entry过程的end
样例脚本
```python=
using coding utf-8
样例脚本
@ 多行注释测试 author:Test date: 2021/12/29 联通客服机器人 @
$name = "Jo hn" $input = "" $month = 1 $used = 20.20 $left = 40.80 $complain_content = ""
Proc Entry begin OUT $name + ",请问有什么可以帮您?" IN $input # 根据输入内容进行模糊匹配 单行注释测试 Switch $input begin Branch "查询" Loop QueryInfo 3 Branch "投诉" Run Complain Branch "退出" Run Exit Default Run Unknow end Run Entry end
Proc QueryInfo begin OUT "尊敬的" + $name + ",您" + $month + "月份账单如下" OUT "话费已用" + $used + ",剩余" + $left $month = $month + 1 $used = 1 + $used $left = $left + 1 end
Proc Complain begin OUT "您的意见是我们改进工作的动力,请问您还有什么补充" IN $complain_content OUT "您的建议我们已经收到,感谢您对我们工作的支持" end
Proc Unknow begin OUT "您好,没有听清,请您再说一遍" OUT "您可以选择查询,投诉或者退出" end
Proc Exit begin OUT "退出成功" EXIT end ```
3. 标识符
标识符第一个字符必须为字母表中字母或下划线 _
标识符的其他的部分由字母、数字和下划线组成
标识符对大小写敏感
4. 变量
变量声明
变量名仅允许使用所规定的标识符,禁止使用关键字作为标识符
声明方法:
php=
$varname = value
变量类型
仅允许出现三种变量类型:整数int 浮点数float 和字符串str 声明时无需指定变量类型,解释器将自动识别类型 同一变量的类型可以在脚本中因为赋值而改变其类型(继承python)
如示例:之前为字符串类型,进行赋值后可转变为int类型
$var = "test"
$var = 123
变量声明位置
变量不允许在过程结构或者Switch中定义 推荐在脚本开始时声明变量
使用范围
所有变量均为全局变量而可以被整个脚本识别(前提是在使用前必须声明)
5. 注释
单行注释以 # 开头,多行注释以 @ 开头 @ 结束
规定仅允许注释在一行的开头指明,不允许在语句中间或结尾出现注释符(错误注释1 2) 不允许将注释标注到过程Proc和Switch结构的begin和定义之间(错误注释3) 由于引入编码规范# using coding 编码,不允许在第一行进行注释
正确示范: ``` Proc Entry begin
单行注释
@
多行
注释
@
OUT "内容"
end
错误示范:
Proc Entry #注释1:入口
注释2:这里进入
begin OUT "错误示范"@ 注释3:多行注释 @ end
```
6. 行与缩进
不采用缩进,start标记Proc结构和Switch结构的开始,end标记结构的结束。
不使用封号作为语句的结束符,使用换行符用于标记语句的结束
缩进可用于使代码结构更清晰,但若不使用缩进对解释并无影响
二、程序设计说明
1. 参数设计
使用argparse进行参数解析
shell=
python main.py -h
```shell= usage: main.py [-h] [-f SCRIPTFILE] [-d [DEBUG_FLAG]] [-s speak_filedir] [-v var_filedir] [-p parser_filedir] [-o outprint_filedir] [-r [RECORD_FLAG]] [-nc [NO_COLOR_FLAG]] [-nt [NO_TIME_FLAG]]
optional arguments:
-h, --help show this help message and exit
-f SCRIPTFILE, --scriptfile SCRIPTFILE
script file to execute
-d [DEBUG_FLAG], --debug [DEBUG_FLAG]
DEBUG controller [DEBUG_FLAG] = TRUE/FLASE or default
-s speak_filedir, --speakfile speak_filedir
if use speak , need a file(example: test.speak) as speak content to test
-v var_filedir, --varfile var_filedir
init var from a file (example: var.json),the file has json only
-p parser_filedir, --parserfile parser_filedir
load parser object from pickle file(example: test.parser)
-o outprint_filedir, --outfile outprint_filedir
out print content to outfile
-r [RECORD_FLAG], --record [RECORD_FLAG]
IF use this arg , send var infomation to http server
-nc [NO_COLOR_FLAG], --no_color [NO_COLOR_FLAG]
IF use Auto test and don't want to print color just add this args.[NO_COLOR_FLAG] = TRUE/FLASE or
default
-nt [NO_TIME_FLAG], --no_time [NO_TIME_FLAG]
IF use Auto test and don't want to print time just add this args.[NO_TIME_FLAG] = TRUE/FLASE or
default
```
2. 交互设计
命令行交互输入输出
若不加任何输出限制(-nt 禁止输出时间 -nc 禁止输出颜色)
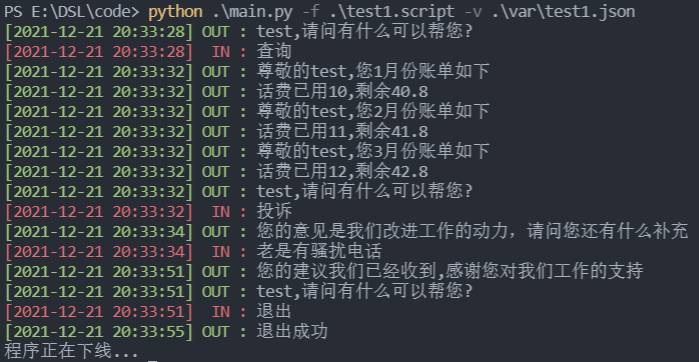
即存在颜色区分输入与输出
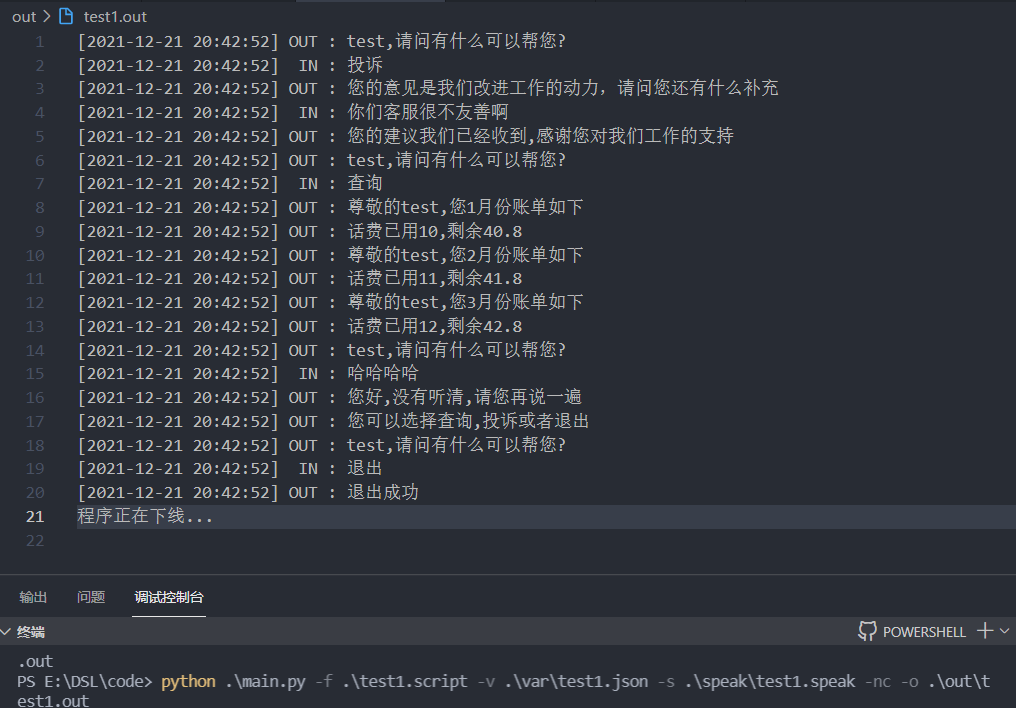
文件输入 文件输出
由于存在测试桩 模拟语音输入后保存到文件,脚本解释器输入的来源为文件。则可以使用 -s参数指定输入文件位置进行模拟输入

输出可以使用-o 指定输出文件以提供测试和调试,这里由于不需要颜色,所以指定参数-nc
远程服务器交互
为提供测试桩,发送信息等用途,定义函数send_var()和send_msg()函数,用于向远程服务器发送消息 使用recv_msg()函数接受来自远程服务器的信息等
```python= def send_var(self): """[测试桩: 向远程服务器发送GET请求 请求内容为变量值] """
# 测试桩: 向远程服务器发送GET请求请求内容为变量值
url = 'http://xxx.xxx.xxx.xxx/test.php?var=' + json.dumps(self.var)
respose = requests.get(url=url)
# 响应输出
print(respose.text)
def send_msg(self, msg):
"""[向远程服务器发送信息]
:param msg: [要发送的信息]
:type msg: [str]
"""
# 测试桩: 向远程服务器发送信息
url = 'http://xxx.xxx.xxx.xxx/test.php?msg=' + msg
respose = requests.get(url=url)
def recv_msg(self,request):
"""[从远程服务器获取信息]
:return: [返回相应]
:rtype: [Respose]
"""
# 测试桩: 从远程服务器接收信息
url = 'http://xxx.xxx.xxx.xxx/' + request
respose = requests.get(url=url)
return respose
```
3. DSL解析器整体设计
程序整体流程图:
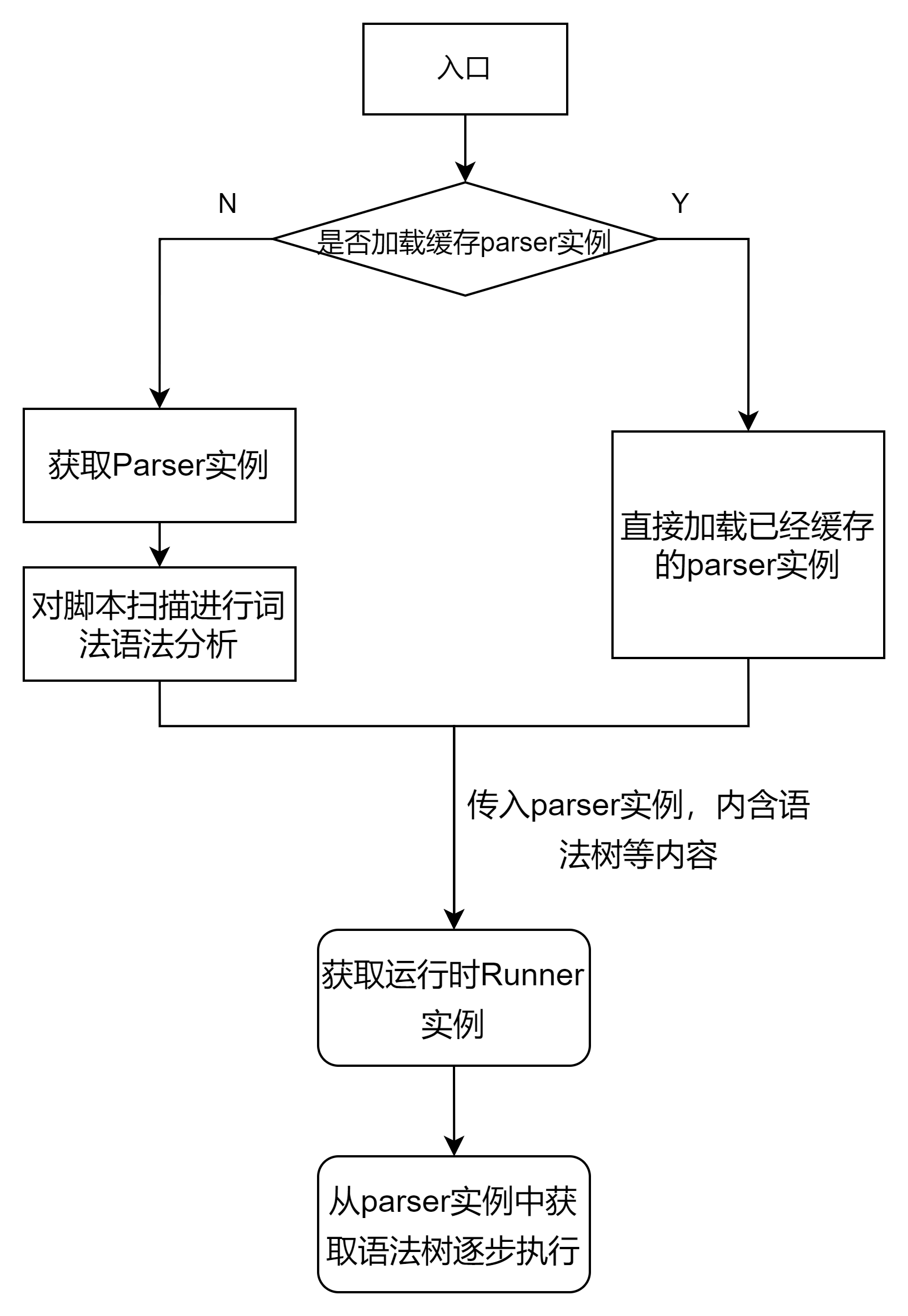
在main函数(入口)中读取传入的参数决定是否读入包含语法树parser实例的缓存
若选择读入且路径正确则直接加载缓存并且将该实例传入运行时类Runner中 否则对该脚本进行parse并且在此过程中建立语法树和变量表,同时对该脚本进行检错 ```python= # 测试桩: 读取程序语法树,提供多用户方案 if config.parserfile != '': with open(config.parserfile,'rb') as fp: parser = pickle.load(fp) else: if config.scriptfile != '' and config.scriptfile[-7:] == '.script': # 解析脚本 file, parser = get_parser(config.scriptfile) parser.parse_file(file)
# 测试桩: 保存程序语法树,提供多用户方案
with open('.\\parser\\' + config.scriptfile[:-7] + '.parser', 'wb') as fp:
pickle.dump(parser,fp)
fp.close()
else:
print("There is no script for parse and run")
runner = get_runner(parser)
runner.start()
```
若获得parser类并且将其传入Runner运行时类中后 Runner类对语法树自顶向下从左向右按序解析执行 执行过程中不同指令调用不同的函数进行执行,在此过程中处理脚本的部分语法错误和运行错误 等待脚本执行完成
4. 词法语法分析器设计
词法语法分析器流程图如下:
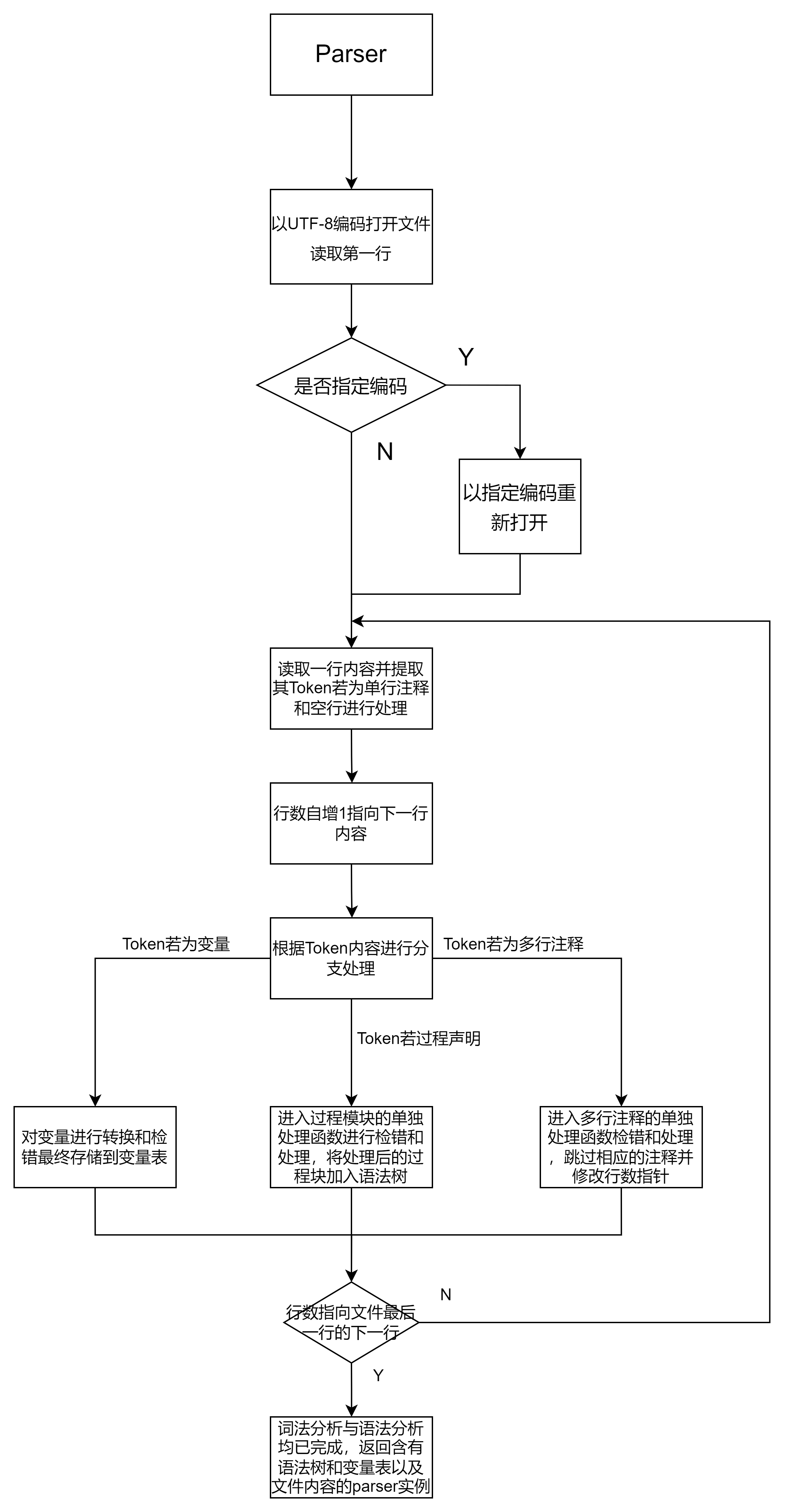
由于脚本解释器支持多编码方式,若脚本中指定该脚本编码方式 第一遍打开文件仅读取编码方式,若无指定编码则按UTF-8编码打开脚本进行解释 ```python= if encoding[0] == "#": if encoding[1] == "using" and encoding[2] == "coding": try: # 根据编码方式重打开 file.close() file = open(self.file_name, 'r', encoding=encoding[3]) except: print("Some wrong happend at line 1") else: print("error grammer at line 1") exit(0) else: file.close() file = open(self.file_name, 'r', encoding='utf-8') # 返回文件io流 return file
打开文件后读取文件的全部内容存入类成员变量lines中
声明文件行数指针指向当前分析的语句的下一行
python=
# 过程块类实例字典
self.proc_block = {}
# 存储变量的dict
self.var = {}
# 脚本文件名
self.file_name = file_name
# 待parse的下一行的行数
self.line_num = 0
# 存储文件内容
self.lines = []
```
从第一行开始读取脚本文件,若遇到空行和单行注释则跳过 由于解释器是过程Proc驱动的(指令只能出现在Proc中),在解析过程中若遇到Proc声明即进入parse_proc进行单独处理,遇到变量则处理加入变量表,以及遇到多行注释进行单独的函数handle_note进行处理 在parse_proc中对指令进行词法分析和语法分析(内含Switch结构的词法语法分析),模块化过程Proc,使得分析结束后的proc单独成块作为proc实例保存到proc_block字典中以便后续执行 函数具体说明见API文档 http://xxx.xxx.xxx.xxx/index.html
```python=
parse_file 函数(部分)
while True: i = self.line_num self.line_num += 1
if i >= len(self.lines):
file.close()
return
line = self.lines[i].lstrip().rstrip()
if line != '' and self.is_linefeed(line) == False:
if self.is_note(line) == False:
token = line.split()
# 处理变量定义并插入到符号表
if token[0][0] == '$':
self.parse_var(line)
# 处理过程定义
elif token[0] == 'Proc':
self.parse_proc(line)
if line.strip()[0] == "@":
# 处理多行注释
self.handle_note()
```
```python=
parse_proc 函数(部分)
while True: line = self.lines[self.line_num] line = line.lstrip().rstrip() self.line_num += 1
if self.is_linefeed(line):
continue
if self.is_note(line):
if line[0] == '#':
continue
if line[0] == '@':
self.handle_note()
token = shlex.split(line)
tmp_token = token[0]
# 如果Token为OUT代表输出
if tmp_token == 'OUT':
plus_num = token.count('+')
if plus_num != len(token) - plus_num - 2:
self.exception(line)
i = 0
while plus_num != 0:
if token[i + 2] != '+':
self.exception(line)
plus_num -= 1
i += 2
# 如果Token为IN代表输入
elif tmp_token == 'IN':
if len(token) == 2:
if token[1][0] != '$' or token[1][1:] not in self.var.keys():
self.exception(line)
else:
self.exception(line)
```
5. 运行时Runner设计
运行时Runner流程图如图所示:
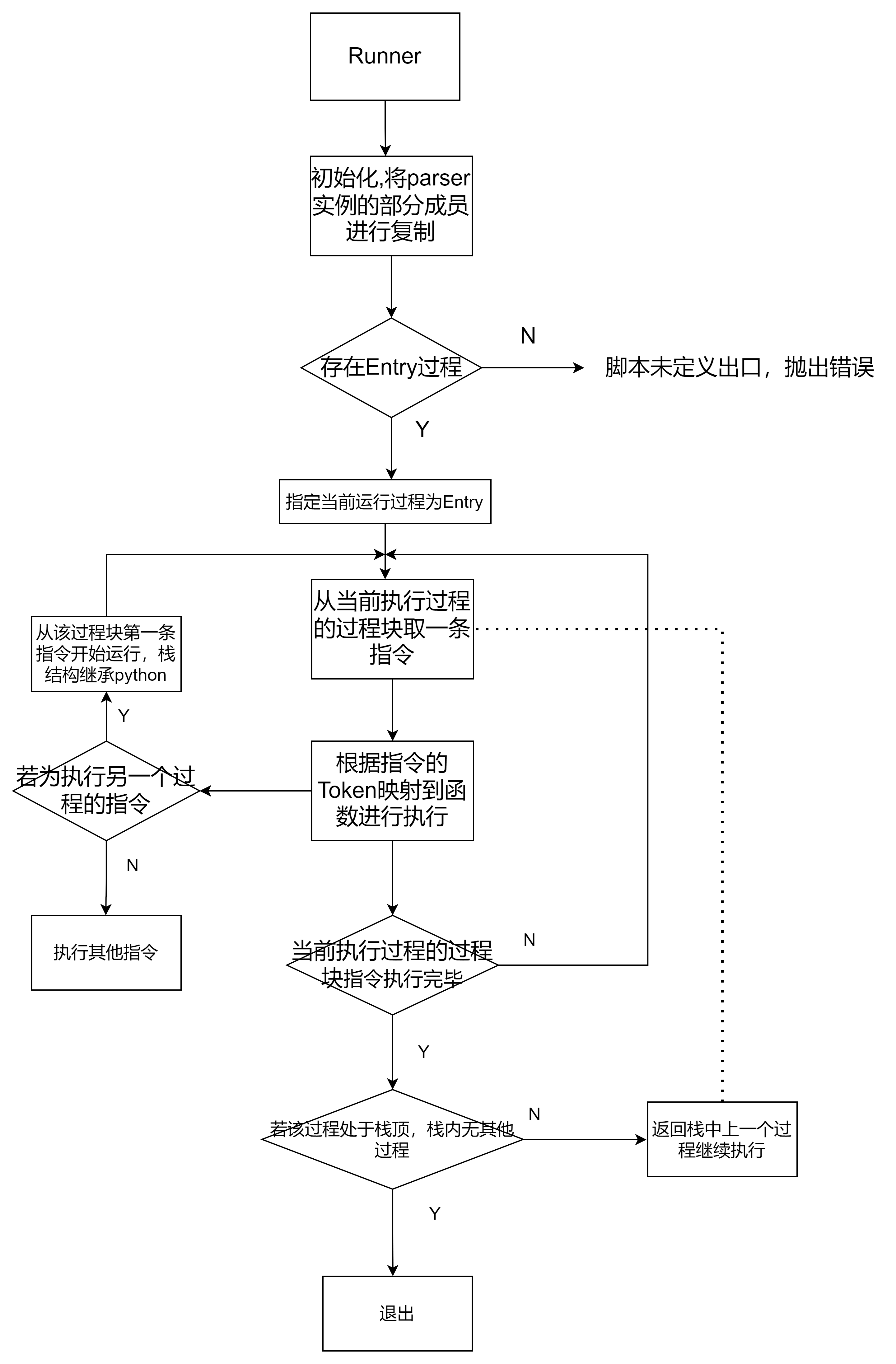
在初始化运行时Runner时,包含语法树的parser实例被传入当作类成员,该实例还包含每个过程块的执行语句。解释器从Entry开始运行,从过程块中按序取指令进行执行,执行时调用对应指令的操作函数(如OUT指令调用run_out函数)。若遇到过程调用语句则直接跳转到对应过程块,开始按序执行,执行结束后即可返回。这里的栈结构和指令执行继承了python的栈结构和指令执行方式,无需另外开辟空间。 ```python=
Srunner.py run_proc函数
def run_proc(self, proc): """[运行脚本过程]
:param proc: [传入过程的具体内容,包括指令行数和解析后的具体指令]
:type proc: [list]
"""
for inst in proc.inst:
if 'Switch' not in inst[1][0]:
# 如果是Switch结构单独映射
if '$' not in inst[1][0]:
func = self.function[inst[1][0]]
func(inst)
else:
if len(inst[1]) == 5 or len(inst[1]) == 3:
self.handle_expression(inst)
else:
self.exception(inst)
else:
# 直接根据映射内容调用函数
func = self.function[inst[1][0][0]]
func(inst)
```
6. 词法语法分析器优化设计
考虑到同一脚本若运行于多个用户,而仅存在变量上的不同,于是进行优化,同一脚本只进行一次词法分析,之后只传入语法树和运行所需要的信息。即可以通过pickle序列化parser实例并且保存起来,之后即可直接加-p 参数指定路径 进行读取并且传入Runner运行时类。 ```python= # 测试桩: 读取程序语法树,提供多用户方案 if config.parserfile != '': with open(config.parserfile,'rb') as fp: parser = pickle.load(fp) else: if config.scriptfile != '' and config.scriptfile[-7:] == '.script': # 解析脚本 file, parser = get_parser(config.scriptfile) parser.parse_file(file)
# 测试桩: 保存程序语法树,提供多用户方案
with open('.\\parser\\' + config.scriptfile[:-7] + '.parser', 'wb') as fp:
pickle.dump(parser,fp)
fp.close()
else:
print("There is no script for parse and run")
runner = get_runner(parser)
```
7. 测试桩设计
(1) 输出重定向
通过参数指定输出文件路径,将标准输出重定向
-o 路径
python=
# 测试桩: 输出重定向到文件,可用于
if config.outfile != '':
out = open(config.outfile, 'w',encoding='utf-8')
sys.stdout = out
(2) 保存读取parser类实例(含语法树)
解析脚本后默认将parser实例保存于当前路径下的parser文件夹中 ```python=
测试桩: 读取程序语法树,提供多用户方案
if config.scriptfile != '' and config.scriptfile[-7:] == '.script':
# 解析脚本
file, parser = get_parser(config.scriptfile)
parser.parse_file(file)
# 测试桩: 保存程序语法树,提供多用户方案
with open('.\\parser\\' + config.scriptfile[:-7] + '.parser', 'wb') as fp:
pickle.dump(parser,fp)
fp.close()
else:
print("There is no script for parse and run")
``` 可以使用 下面参数读取parser实例
-p 路径
```python=
测试桩: 读取程序语法树,提供多用户方案
if config.parserfile != '':
with open(config.parserfile,'rb') as fp:
parser = pickle.load(fp)
### 省略
runner = get_runner(parser)
runner.start()
```
(3) 语音模拟文件读入
通过-s参数可以指定一个文件,该文件内容为输入内容,意在模拟语音输入驱动
-s 路径
python=
if self.config.speakfile != '':
line = self.speak_file.readline().strip('\n').strip('\r\n')
# 测试桩 语音输入接口
if self.config.no_color == False:
print("\033[31m" + " IN : " + "\033[0m", end='')
print(line)
else:
print(" IN : ", end='')
print(line)
return line
(4) 调试模式输出变量信息
可以通过-d参数输出调试信息(程序运行前初始化的变量信息和结束后的变量信息)
-d
```python= # 测试桩: 若开启调试模式则输出初始化后的变量键值对 if config.debug == True: runner.print_var()
### 省略
# 测试桩: 若开启调试模式则输出结束时的变量键值对
if self.config.debug == True:
self.print_var()
```
(5) 从json文件初始化变量
通过以下参数可以指定初始化变量内容,以满足部分变量没有在脚本中写明,需要在解释运行前查询初始化变量
-v 变量json文件路径
python=
# 测试桩: 用于接收从其他端口获得变量数据后给与脚本变量初始化
if config.varfile != '':
runner.init_var(config.varfile)
(6) 结束时以json格式发送变量到远程
若使用
-r
参数可在程序结束前将变量以json格式发送到远程服务器
```python= # 测试桩,记录客服服务内容并上传到服务器 if self.config.record == True: self.send_var()
def send_var(self): """[测试桩: 向远程服务器发送GET请求请求内容为变量值] """
# 测试桩: 向远程服务器发送GET请求 请求内容为变量值
url = 'http://xxx.xxx.xxx.xxx/test.php?var=' + json.dumps(self.var)
respose = requests.get(url=url)
# 响应输出
print(respose.text)
```
(7) 向远程服务器发送数据
提供函数接口供开发人员使用 ```python= def send_msg(self, msg): """[向远程服务器发送信息]
:param msg: [要发送的信息]
:type msg: [str]
"""
# 测试桩: 向远程服务器发送信息
url = 'http://xxx.xxx.xxx.xxx/test.php?msg=' + msg
respose = requests.get(url=url)
```
(8) 从远程服务器接收数据
提供函数接口供开发人员使用 ```python= def recv_msg(self,request): """[从远程服务器获取信息]
:return: [返回响应]
:rtype: [Respose]
"""
# 测试桩: 从远程服务器接收信息
url = 'http://xxx.xxx.xxx.xxx/' + request
respose = requests.get(url=url)
return respose
```
8. 自动化测试设计
自动化测试脚本可以自动寻找路径下的脚本自动寻找是否存在speak文件和变量json文件进行运行,还可以根据测试人员需求调整参数,最终将测试结果按文件输出到指定目录并且生成日志文件 ```python= import shutil import os import glob import time
额外参数
arg = ''
输出时间标志,若为0则不保留输出时间,若为1则保留输出时间
time_flag = 1 time_arg = ''
存放各种文件的路径
script_dir = '.\' varjson_dir = '.\var\' parser_dir = '.\parser\' speak_dir = '.\speak\' output_dir = '.\out'
count = 0
刷新输出目录
shutil.rmtree(output_dir) os.mkdir(output_dir)
遍历脚本所在目录
script = glob.glob(os.path.join(script_dir, "*.script"))
log_file = open(output_dir + '\log.log','w',encoding='utf-8')
for file in script: count += 1 # 自动寻找文件 if os.path.exists(speak_dir + file[:-7] + ".speak"): speak = ' -s ' + speak_dir + file[:-7] + ".speak" else: speak = ''
if os.path.exists(".\\" + file[:-7] + ".json"):
var_json = '-v ' + varjson_dir + file[:-7] + '.json'
else:
var_json = ''
if time_flag == 0:
time_arg = '-nt'
else:
time_arg = ''
cmd = 'python .\main.py -f ' + file + speak + var_json + ' -nc ' + arg + time_arg + ' -o ' + output_dir + '.\\' + file[:-7] + '.out'
os.system(cmd)
print_time = time.strftime("[%Y-%m-%d %H:%M:%S]", time.localtime())
log_file.write(print_time + ' ' + file + ' 执行命令行: ' + cmd + '\n')
print(file + "测试结束")
print("\n脚本遍历结束,已自动化测试" + str(count) + "个脚本") print("输出到文件目录" + output_dir)
```
三. 程序设计API说明
1. Sparser 模块



2. Sproc 模块

3. Srunner 模块




4. config 模块

5. main 模块

参考文献
- 制造业数据交互式分析平台的设计与实现(西安电子科技大学·杨妍)
- 在线客服聊天后台系统的设计与实现(电子科技大学·倪万迁)
- 基于B/S架构的客户服务系统的设计与实现(东北大学·刘锐)
- 面向企业员工的智能客服系统的设计与实现(北京交通大学·徐平)
- 面向企业员工的智能客服系统的设计与实现(北京交通大学·徐平)
- 基于IP语音的地铁客服热线系统的设计和实现(南昌大学·王康正)
- 基于SSH的客户关系管理系统的研究与实现(西安电子科技大学·张荣召)
- 客服工单管理系统的设计与实现(华中科技大学·张觉文)
- 基于WebSocket的在线客服系统的设计与实现(华中科技大学·杨佳)
- 企业客服系统的设计与实现(北京交通大学·赵宇)
- 基于WebSocket的在线客服系统的设计与实现(华中科技大学·杨佳)
- 基于IP语音的地铁客服热线系统的设计和实现(南昌大学·王康正)
- 面向企业员工的智能客服系统的设计与实现(北京交通大学·徐平)
- 基于SSH框架的Web网站设计与实现(长春理工大学·冯学军)
- 综合客户服务系统的设计与实现(东北大学·梁阳)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设导航 ,原文地址:https://m.bishedaima.com/yuanma/36195.html









