
基于Python Web框架和MySQL的图书借阅系统
1.需求分析
1.1 系统目标
利用Python web框架和MySQL开发一个仿真模拟的图书借阅系统。分为管理员和读者两个方面的功能实现。
1.1.1 管理员方面
-
增、删、改、挂失图书信息和读者信息
-
查看用户信息和图书信息
-
登录管理员界面
-
为读者办理借书还书
1.1.2 读者方面
-
登录读者界面
-
查询借书记录和个人信息
1.2 数据流图
1.2.1 读者注册

1.2.2 图书上架
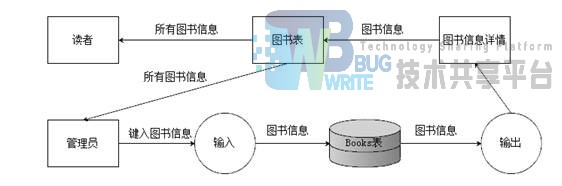
1.2.3 图书搜索
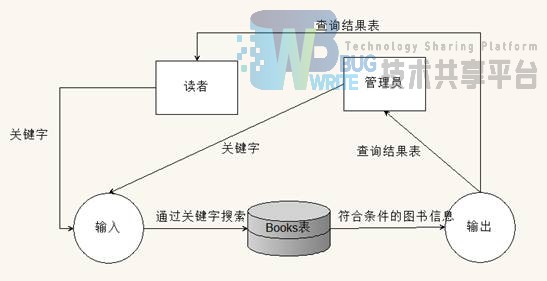
1.2.4 图书借阅

1.2.5 借书记录搜索

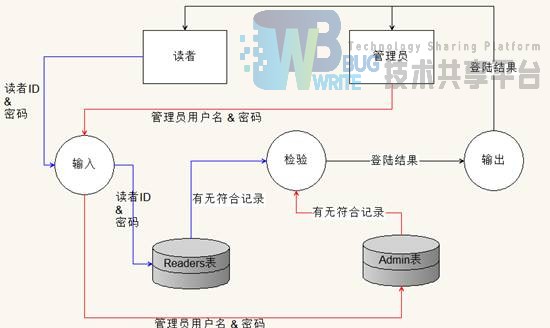
1.2.6 登陆
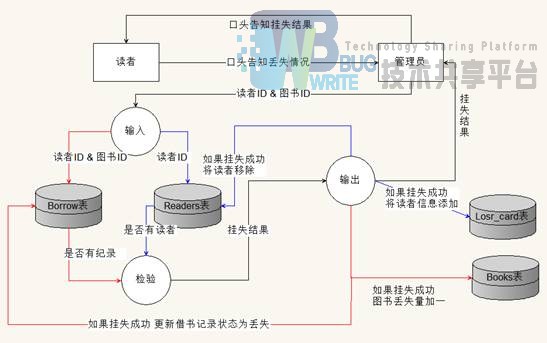
1.2.7 图书、读者证挂失
1.2.8 图书、读者删除

1.3 数据字典
1.3.1 数据项
| 数据项名 | 别名 | 数据类型 | 说明 |
|---|---|---|---|
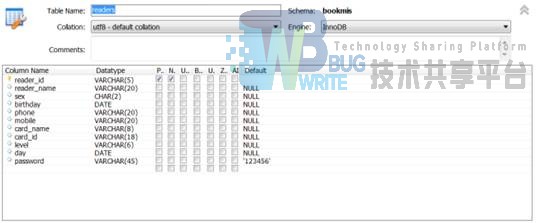
| 读者编号 | reader_id | varchar(5) PK | 读者证的编号按顺序系统分配 |
| 姓名 | reader_name | varchar(20) | 读者姓名 |
| 性别 | sex | char(2) | 读者性别 |
| 出生日期 | birthday | date | 读者出生日期 |
| 电话 | phone | varchar(20) | 读者电话 |
| 手机 | mobile | varchar(20) | 读者手机 |
| 证件名称 | card_name | varchar(8) | 读者的证件可以是身份证学生证等 |
| 证件编号 | card_id | varchar(18) | 读者的证件号 |
| 会员级别 | level | varchar(6) | 有三个级别,普通银卡金卡 |
| 办证日期 | day | date | 即注册日期 |
| 读者登录密码 | Password(Readers表) | varchar(45) | 读者登录系统中时使用的密码 |
| 图书编号 | book_id | varchar(5) | 图书的编号系统分配 |
| 书名 | book_name | varchar(50) | 书的名字 |
| 作者 | author | varchar(20) | 书的作者 |
| 出版社 | publishing | varchar(20) | 书的出版社 |
| 类别编号 | category_id | varchar(5) | 书的类别编号 |
| 单价 | price | double | 书的价格 |
| 入库日期 | date_in | datetime | 入库的时间即图书上架时间 |
| 库存数量 | quantity_in | int | 上架的书的数量 |
| 借出数量 | quantity_out | int | 书借出去的数量 |
| 遗失数量 | quantity_loss | int | 书的丢失的数量 |
| 出借日期 | date_borrow | date | 书借出去的日期在借阅中生成 |
| 应还日期 | date_return | date | 根据会员的级别确定的日期 |
| 遗失 | loss | char(2) | 有“否”“是”区分书是否丢失了 |
| 类别名称 | category | varchar(20) | 类别的名字如“计算机” |
| 最长出借天数 | days | smallint | 根据会员级别相应天数 |
| 最多借书册书 | numbers | smallint | 根据会员级别能借最多的书 |
| 会费 | fee | smallint | 会员级别所要的费用(单位:元) |
| 管理员ID | User_ID | Varchar(20) | 管理员登录用ID |
| 管理员密码 | Password(admin表) | Varchar(20) | 管理员登录用密码 |
1.3.2 数据结构
-
数据结构名:读者证
-
说明:定义了读者的信息
-
组成
- reader_id,
- reader_name,
- sex,
- birthday,
- phone,
- mobile,
- card_name,
- card_id,
- level,
-
day
-
数据结构名:图书信息
-
说明:定义了一本书的信息
-
组成:
- book_id,
- book_name,
- author,
- publishing,
- category_id,
- price,
- date_in,
- quantity_in,
-
quantity_out
-
数据结构名:借阅信息
-
说明:用户借阅书的信息
-
组成:
- reader_id,
- book_id,
- date_borrow,
- date_return,
-
loss
-
数据结构名:会员等级
-
说明:定义了会员的等级
-
组成:
- level,
- days,
- numbers,
- fee
2.概念设计
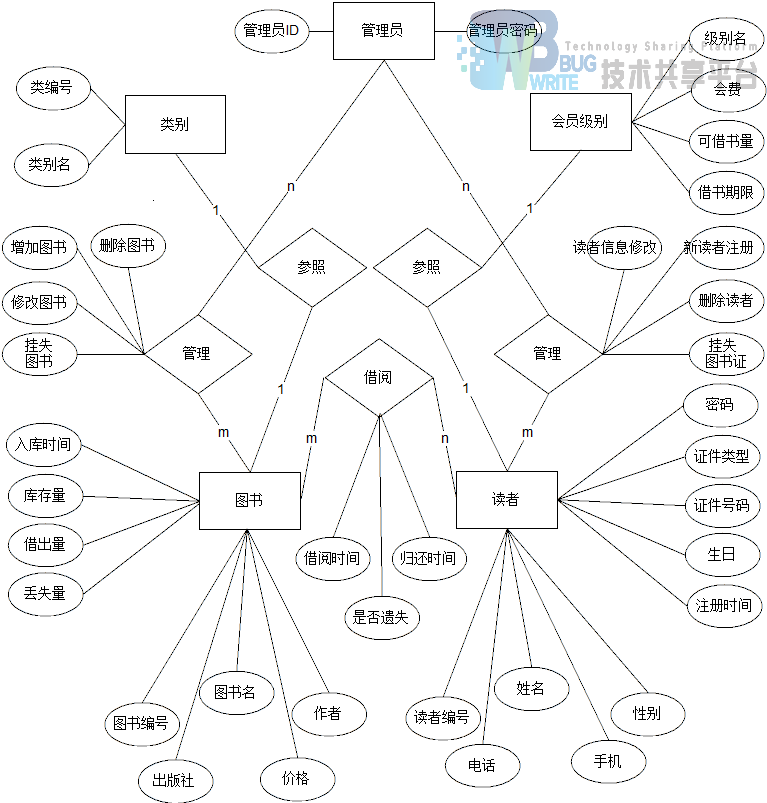
2.1 系统ER图
3.详细设计
3.1关系模型
-
会员级别:{ 会员级别 ,最长出借天数,最多借书书册,会费}
-
读者:{ 读者编号 ,姓名,电话,手机,性别,办证日期,出生日期,证件名称,证件编号, 会员级别 ,密码}
-
借阅:{ 图书编号 , 读者编号 ,借阅日期,归还日期}
-
图书:{ 图书编号 ,书名,作者,出版社, 类别编号 ,单价,入库日期,库存数量,出借数量,遗失数量}
-
读者管理:{ 管理员编号 , 读者编号 ,遗失日期}
-
类别:{ 类别编号 ,类别名称}
-
管理员:{ 管理员编号 ,密码}
3.2 物理结构设计
3.2.1 Readers表
3.2.2 Books表

3.2.3 Borrow表

3.2.4 Member_level表

3.2.5 Lost_card表

3.2.6 Admin表

4.系统实现
4.1 程序框图
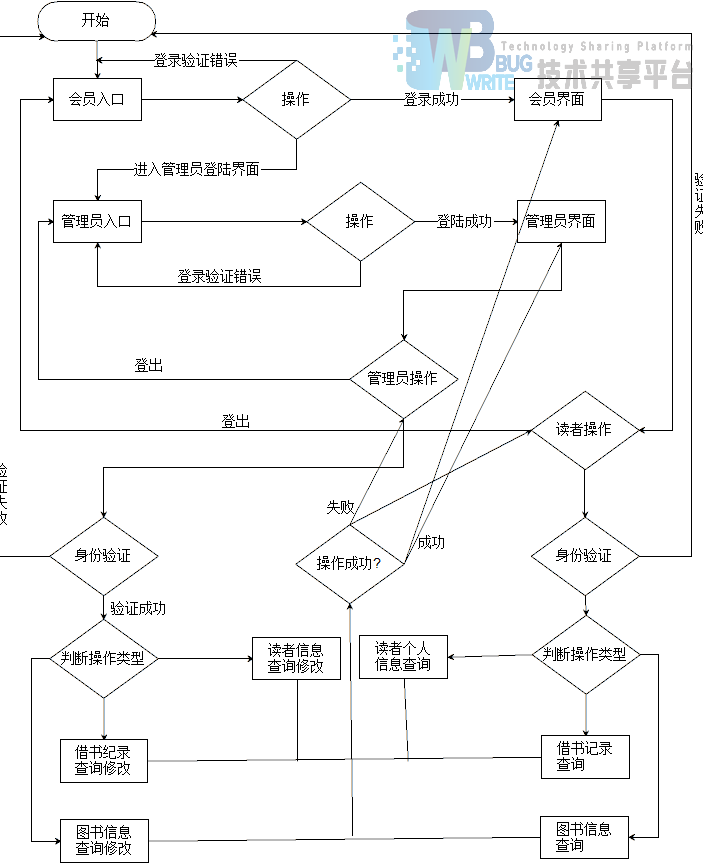
4.1.1 总框图
4.1.2 登录操作框图

4.1.3 管理员操作框图
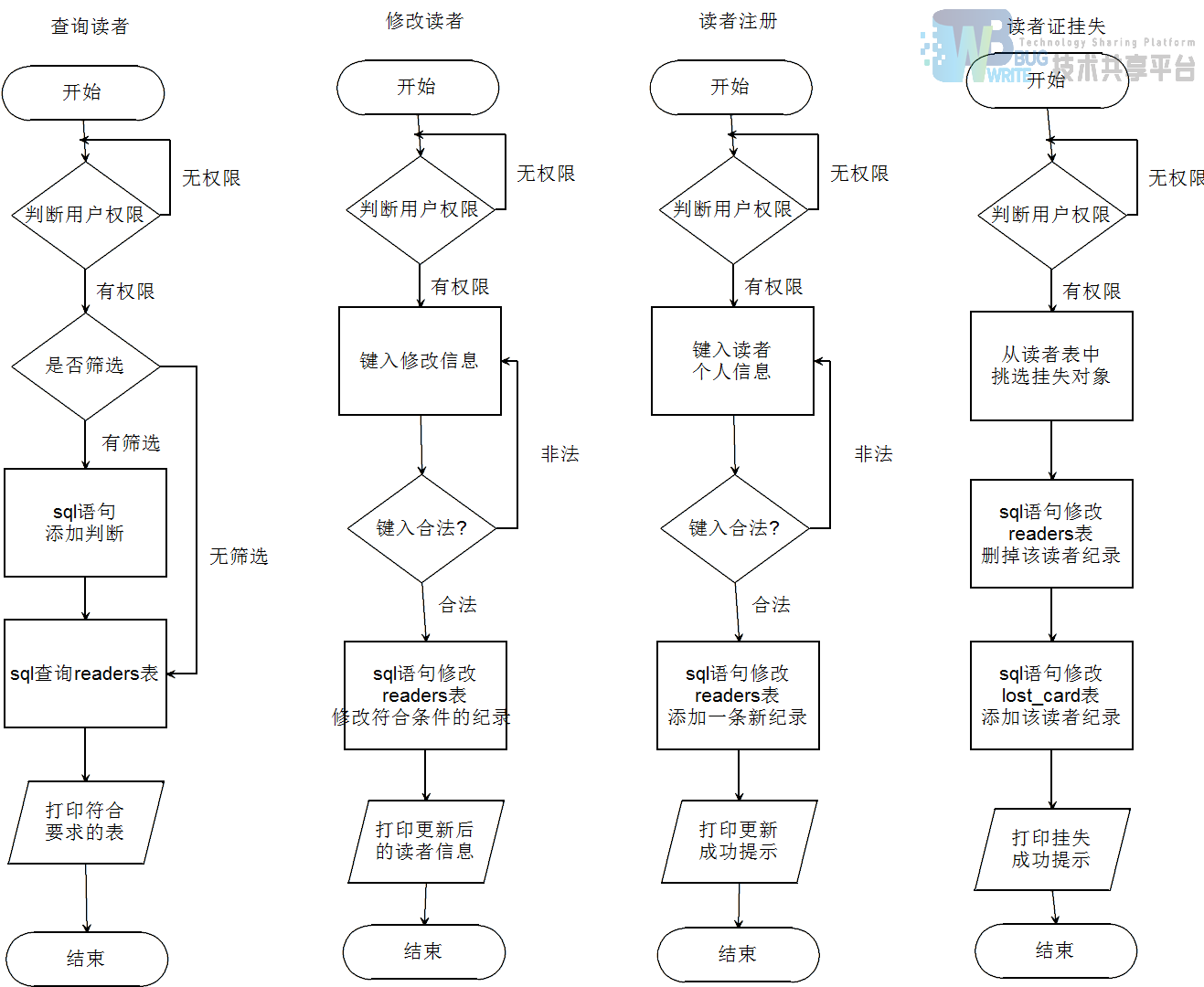
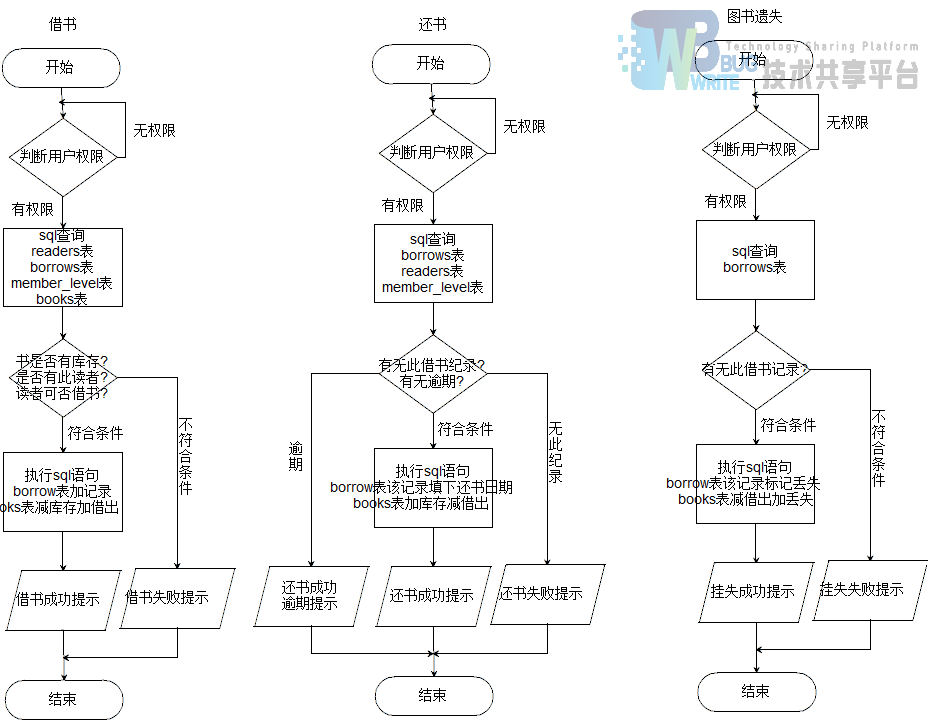

4.1.4 读者操作框图
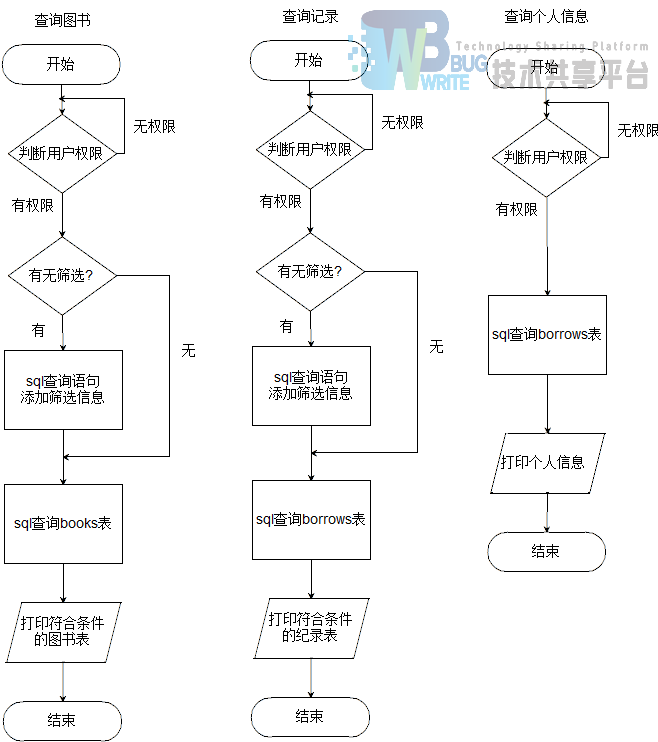
4.2 运行界面
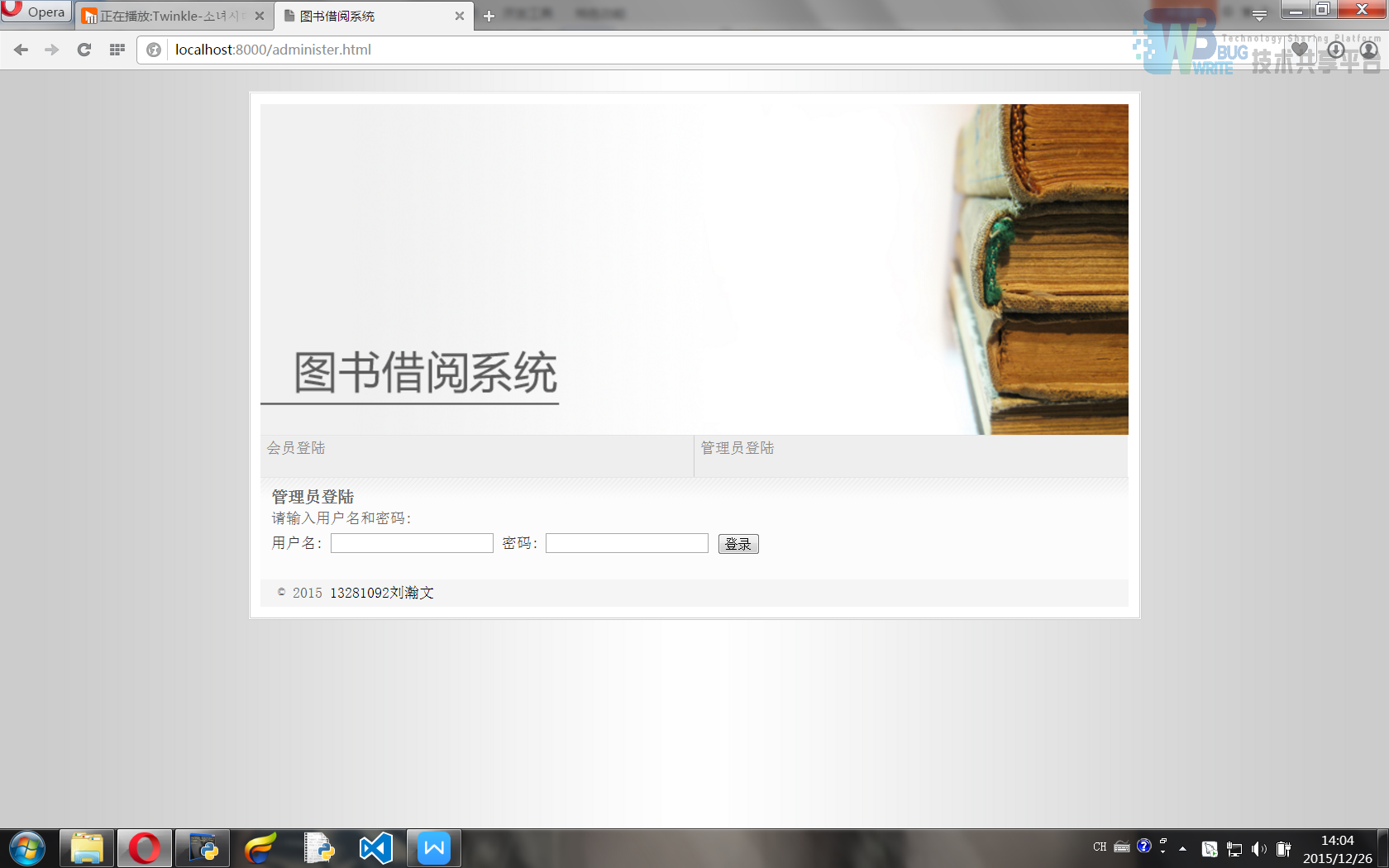
4.2.1 登陆界面
登录界面可以输入用户名和密码登录,两种不同用户组的登陆界面可以通过menu上的标签切换,在程序里是直接读取两个html文件(根目录下的member.html 和 administer.html)然后通过浏览器提出get请求完成操作。登录是提交get请求,登录信息在超链接里,后端分析登录信息做出判断。登录成功后会跳转相关界面,然后在根目录下产生一个user.txt,里面记录了登录用户的用户组和用户名,如a:root就代表管理员“root”、m:r001就代表读者“r001”。
会员登录界面

管理员登陆界面
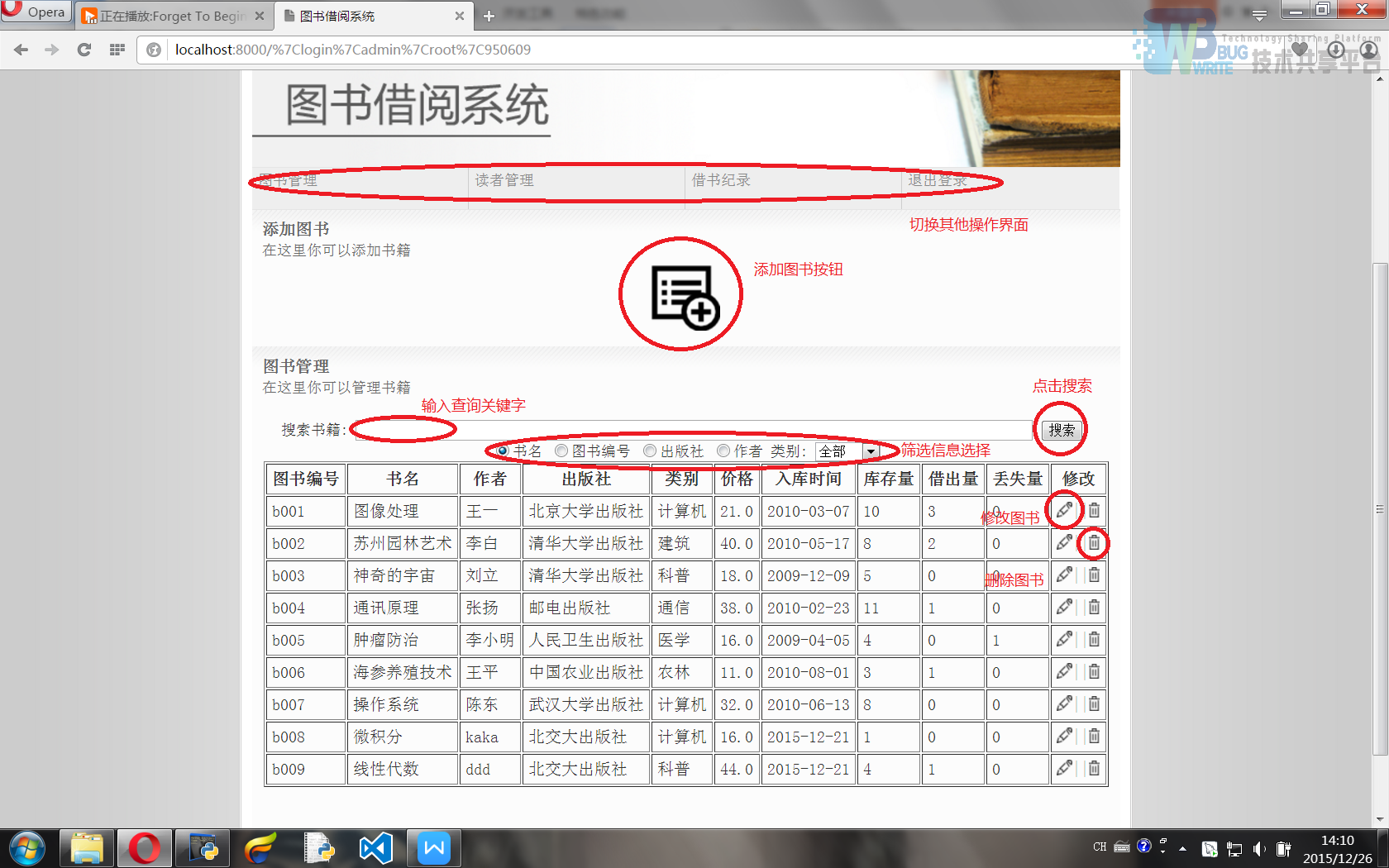
4.2.2 管理员
所有操作都是通过get请求将信息返回给后端程序的。所有管理员的操作都要通过判断根目录下的登录信息文件user.txt里面的首字母来判断当前操作的用户是否拥有权限。
图书信息表展示界面(外观模版为admin/adminBook.html)
添加书籍界面(外观模版为admin/adminBookNew.html)
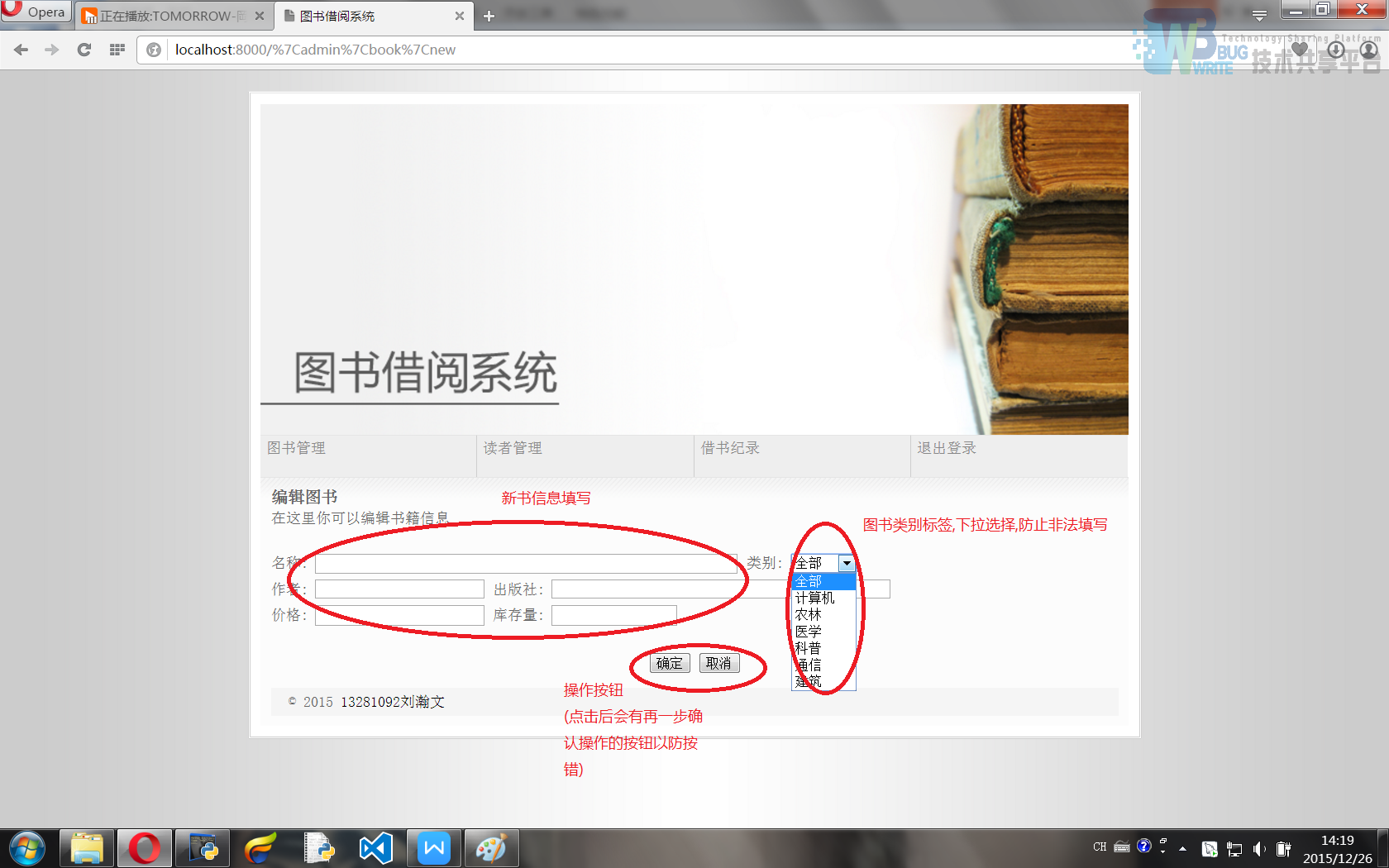
修改书籍界面(外观模版为admin/adminBookEdit.html)

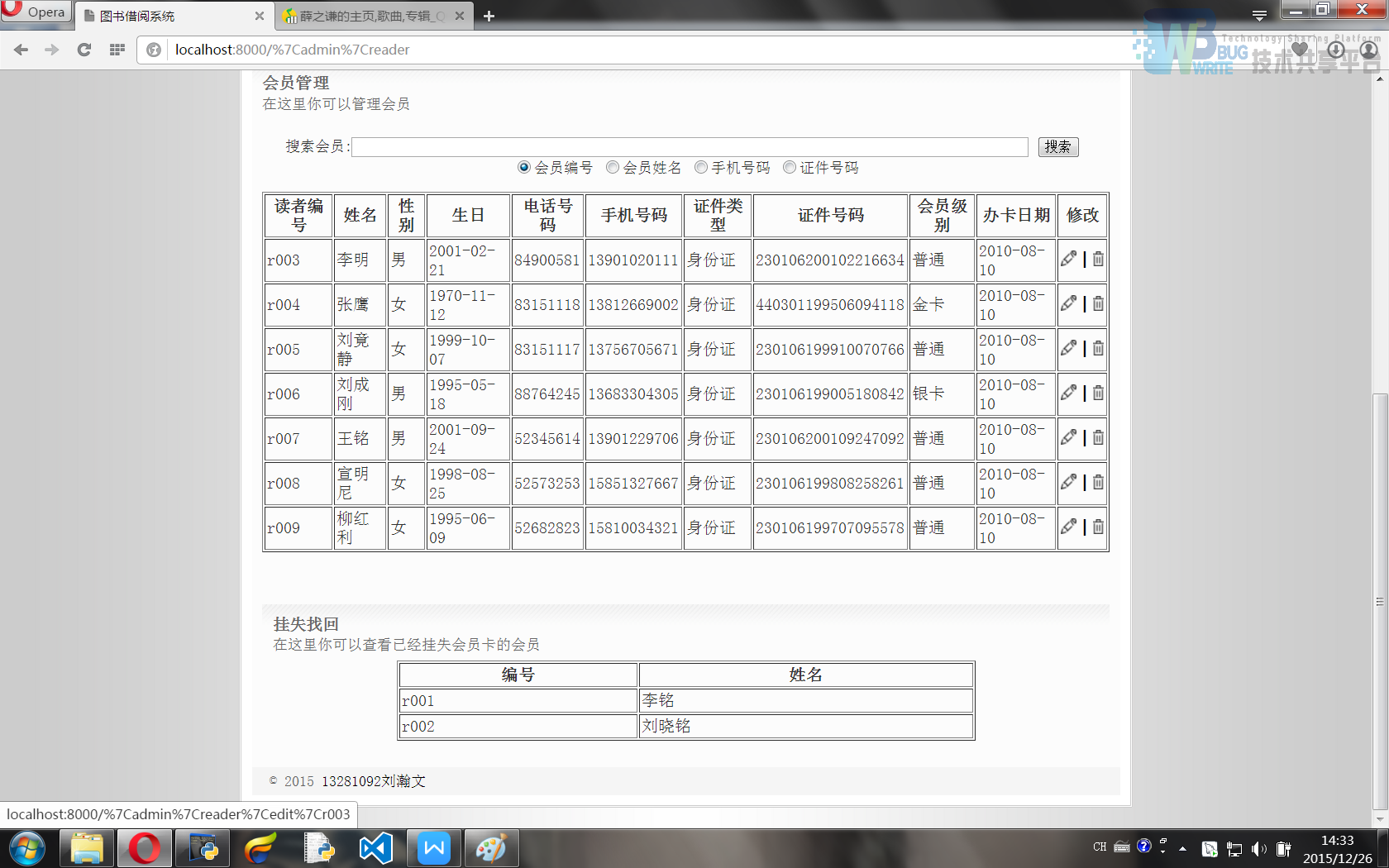
读者信息表显示界面(外观模版为admin/adminReader.html)

注册新读者界面(外观模版为admin/adminReaderNew.html)

修改读者信息界面(外观模版为admin/adminReaderEdit.html)

借书记录管理界面(外观模版为admin/adminRecord.html)

4.2.3读者
个人资料界面(外观模版为member/memberInfo.html)

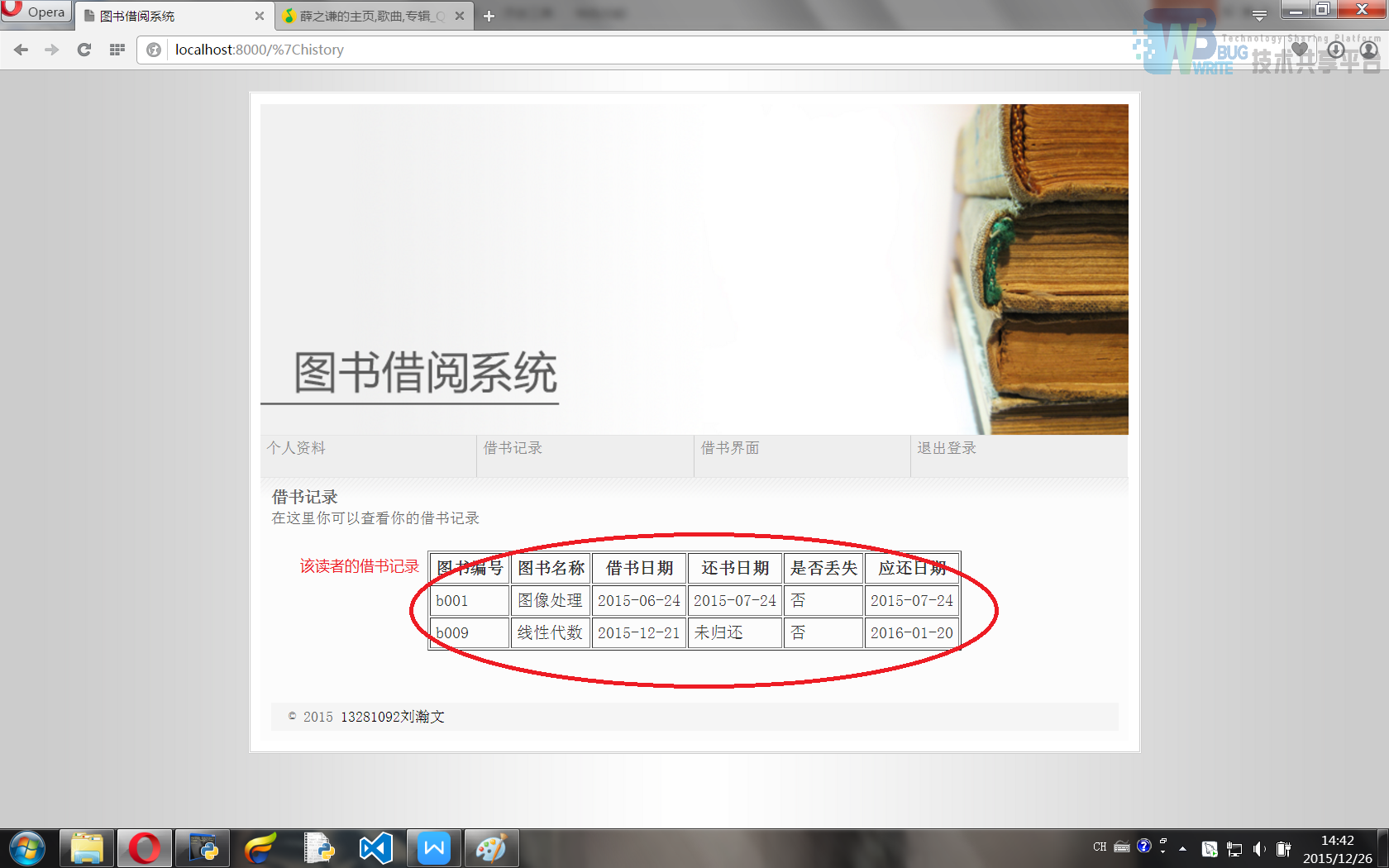
借书纪录界面(外观模版为member/memberHistory.html)
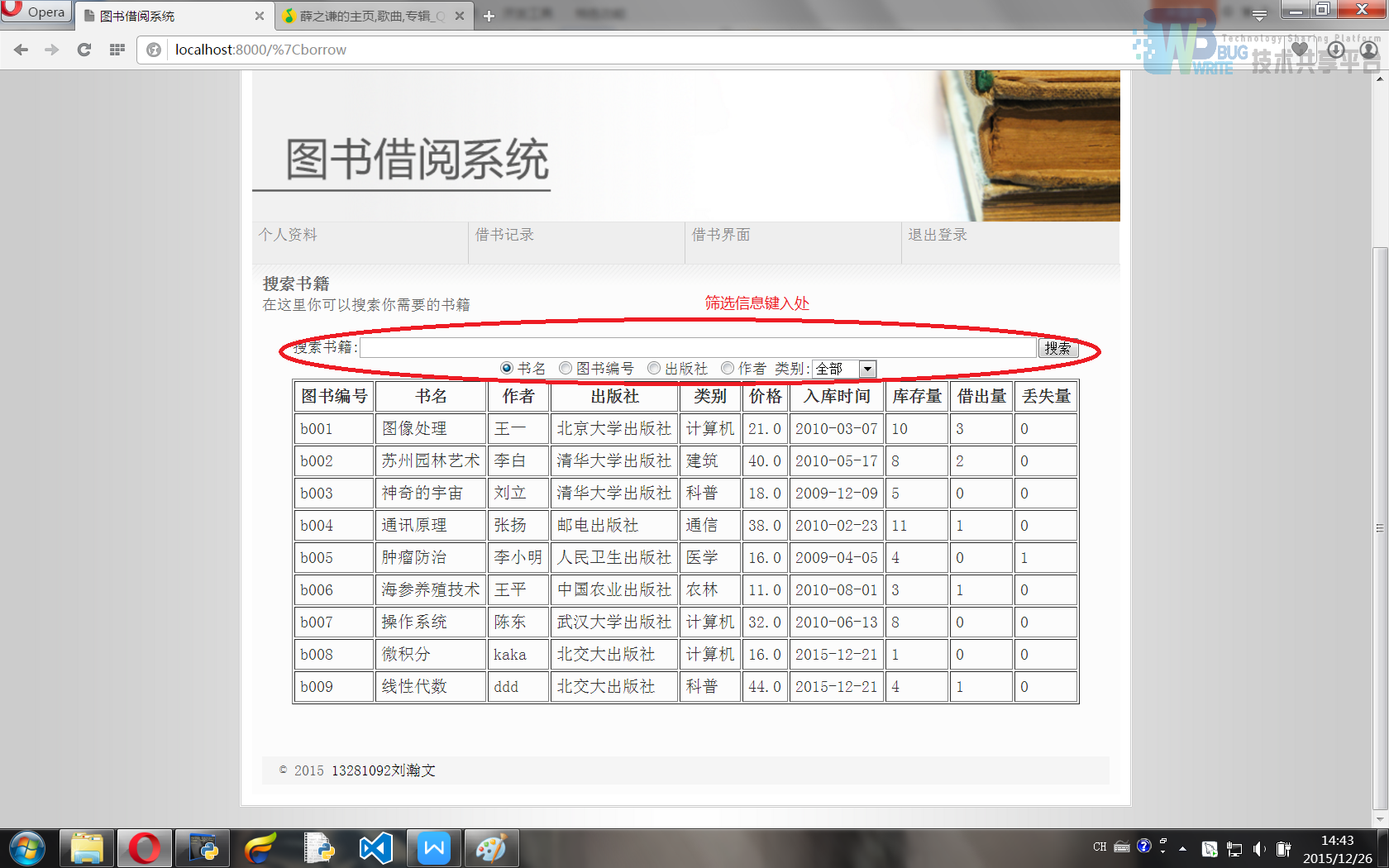
搜索图书界面(外观模版为member/memberBorrow.html)
4.2.4控制台
开始界面

Get请求path详情
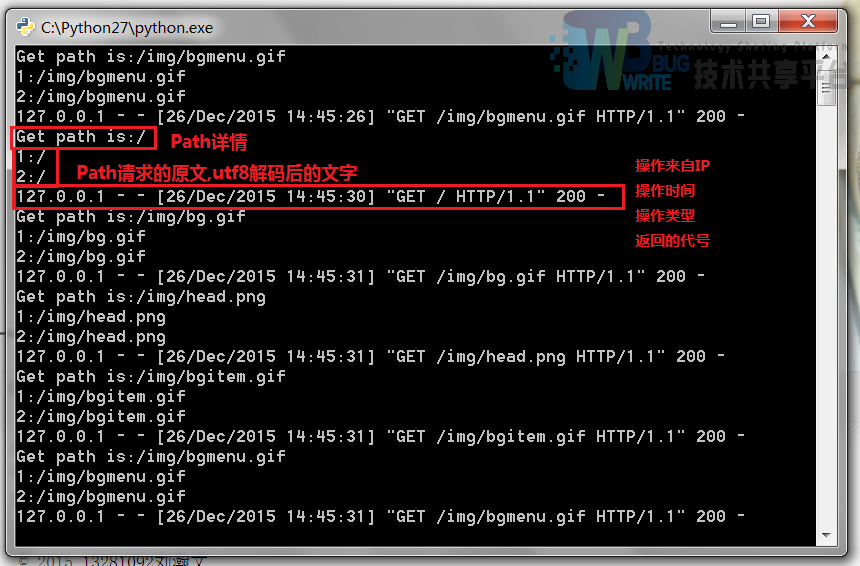
出错信息
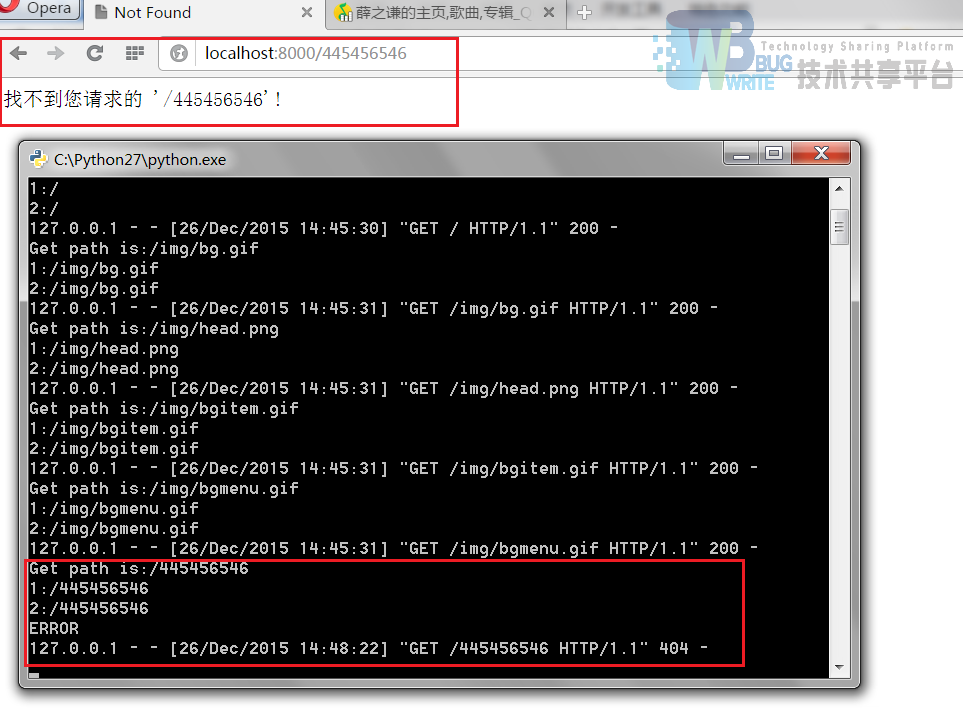
操作
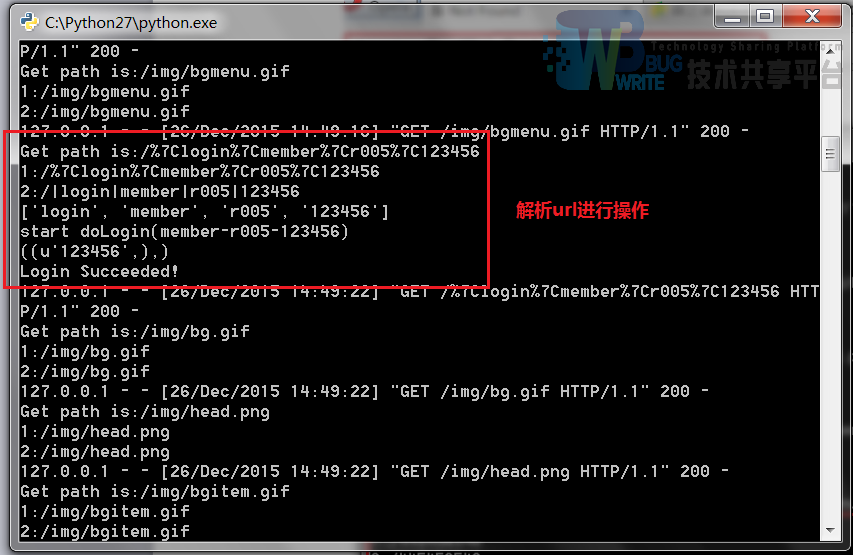
输出信息打印
5.用户使用说明
5.1 编程语言
-
服务器: Python 2.7
-
前端: HTML + JavaScript + CSS
5.2 依赖库
-
服务器库:BaseHTTPServer
-
连接MySQL库:MySQLdb
-
控制台设置库:Sys
-
URL解析库:Urllib
-
时间库:Time
-
时间库:Datetime
-
操作系统库:os
5.3 编码方式
-
前端网页:GBK
-
服务器端:GBK
-
数据库:UTF-8
5.4 运行环境
-
服务器:Windows7 SP1旗舰版 + Python2.7
-
前端:Opera浏览器 34.0(Chrome内核)
-
数据库:MySQL Server 5.5(默认端口3306)
6.实验总结问题与解决
6.1 实验总结
在这个大作业实验中,我学会了很多东西,不仅更了解了数据库连接的方式和数据库的操作,还学会了使用Python搭建一个服务器和javascript语言。我也通过这次实验,深刻的考虑到了用户体验的需求,我们开发软件不仅要注重程序的完整性,更要关注界面以及操作对于用户的体验。一个好的程序必须是良好的用户体验加上完整的系统,缺一不可。我也通过这次实验了解到了web开发中前端和后端是如何交互的,比如说get请求的处理、post请求的处理,还有表单的递交、url的解析、编码的统一等等。我还学会了使用触发器来控制数据库的操作,以防非法操作,这比在程序中来判断更具有完整性,因为在程序中很有可能没有想到,而建立了触发器就可以在数据库端就把非法信息隔绝。
6.2 遇到的问题与解决
6.2.1 服务器、前端、url、数据库的编码不统一怎么办?
服务器使用的是Python 2.7,这个版本的Python使用的是全局Unicode编码,前端网页使用的是GB2312的中文编码,url使用的是UTF-8编码,数据库使用的是UTF-8编码。
解决方法
服务器在通过转换设置为全局GBK编码,因为GBK编码包括了GB2312编码的部分,然后对于所有接收到的信息都解码然后转换为GBK编码,在服务器端统一编码。
6.2.2 自动分配ID的机制如何实现?
我们在读者和图书的添加操作的时候,如果需要用户输入编号就不太人性化,但是自动生成有可能会在删除书籍的时候重复。
解决方法
计算最大的编号,在最大的编号加一即可。
6.2.3 读者证挂失怎么实现?
图书证挂失的过程中,因为设计的时候没有在readers表添加挂失标记,所以挂失操作的时候不能标记为挂失,也不能直接删除这条纪录。
解决方法
新建一张挂失表lost_card表,凡是挂失图书证的读者就将信息复制到这个表,然后删除readers表中的相关记录,在解除挂失的时候只要反过程操作即可实现。
参考文献
- 一种模块化校内阅读平台的设计与研究(云南大学·刘戈阳)
- 基于B/S模式的社区图书馆管理系统的设计与实现(大连理工大学·丁娟娟)
- 基于JSP的高校图书管理系统开发和实现(电子科技大学·朱丽萍)
- 基于SSH框架的图书馆管理系统分析与设计(云南大学·郑晨)
- 高校图书管理系统的设计与实现(东北大学·黄鑫)
- 基于WEB的图书管理系统的设计与开发(大连理工大学·邬金池)
- 图书管理系统的设计与实现(山东大学·宫昌利)
- 基于JSP的高校图书管理系统开发和实现(电子科技大学·朱丽萍)
- 基于SSH框架的图书馆管理系统的设计与实现(山东大学·檀雪姣)
- 高校图书管理系统的设计与实现(东北大学·黄鑫)
- 高校图书管理系统的设计与实现(东北大学·黄鑫)
- 基于J2EE架构的图书馆网站设计与实现(山东大学·王磊)
- 基于B/S架构的图书管理系统(山东大学·彭鹏)
- 基于JSP的图书馆管理系统的设计与实现(吉林大学·葛再立)
- 一种模块化校内阅读平台的设计与研究(云南大学·刘戈阳)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕业设计货栈 ,原文地址:https://m.bishedaima.com/yuanma/35166.html









