
基于python实现的某东手机评论数据采集与分析爬虫
一、系统概述
对评论所含内容进行简单的分析,初步确定所需要抓取的内容。首先,在京东商城手机信息界面的用户评价中含有昵称、会员等级、评价星级,评价内容、手机型号、购买时间等等。
其中通过分析会员等级与购买的关系,可以给为不同会员提供不同的产品做参考。分析评价内容可以大概可以推断出消费者对该产品的态度、以及哪些回复关注度比较高等等。分析购买时间可以了解到消费者集中的购买时间段。这些分析对商品广告的精准投放以及为消费者提供更个性化的服务提供了重要参考。
二、所用工具
2.1 运行环境
-
Chrome 版本 72.0.3626.109(正式版本) (64 位)
-
Python 3.5.2 :: Anaconda 4.2.0 (64-bit)
2.2 前置库
-
json
-
time
-
numpy
-
requests
-
BeautifulSoup
-
fake_useragent
三、数据采集
3.1 确定待采集数据
用户ID、评论内容、会员级别、点赞数、回复数、评价星级、购买时间、手机型号
3.2 确定采集对象及采集思路
选择按评论数降序排列的手机型号,选择Apple iPhone 8 Plus(A1864) 64GB的评论数据进行采集。采集思路如图3-1所示。

3.3 采集准备
(robots协议说明:robots是网站对爬虫的限定规则,它规定了那些爬虫可以爬,那些数据可以爬)
因此在采集之前,查看京东商城的robots协议,如图3-1所示。

参考robots协议规则:
-
User-agent :指定对哪些爬虫生效
-
Disallow :指定不允许访问的网址
-
Allow :指定允许访问的网址
通过分析robots协议的内容,而下面即将采集的目录在根目录的comment的子目录下,不涉及到用户的个人隐私,因此可以继续进行采集。但是在采集过程中,添加sleep函数,既为了防止频繁访问ip被封,也防止高频度访问对网站带来的负荷。
3.4 开始采集数据
3.4.1 分析网页
首先选择一款评论数目多的手机,按照评论数降序排列,如图3-3京东手机评论降序所示。

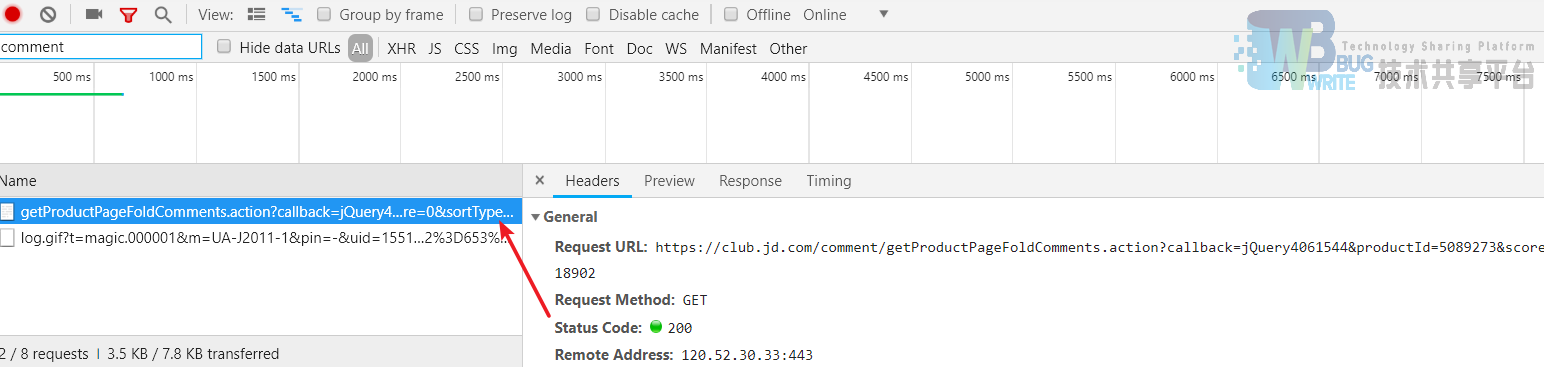
点击进入手机信息页面,在默认手机参数选择下,按F12打开调试界面,打开network面板并在过滤器中填入“comment”,如图3-4 Chrome开发人员工具所示。

此时,点击商品评价,筛选到如图3-5评论数据捕获所示。
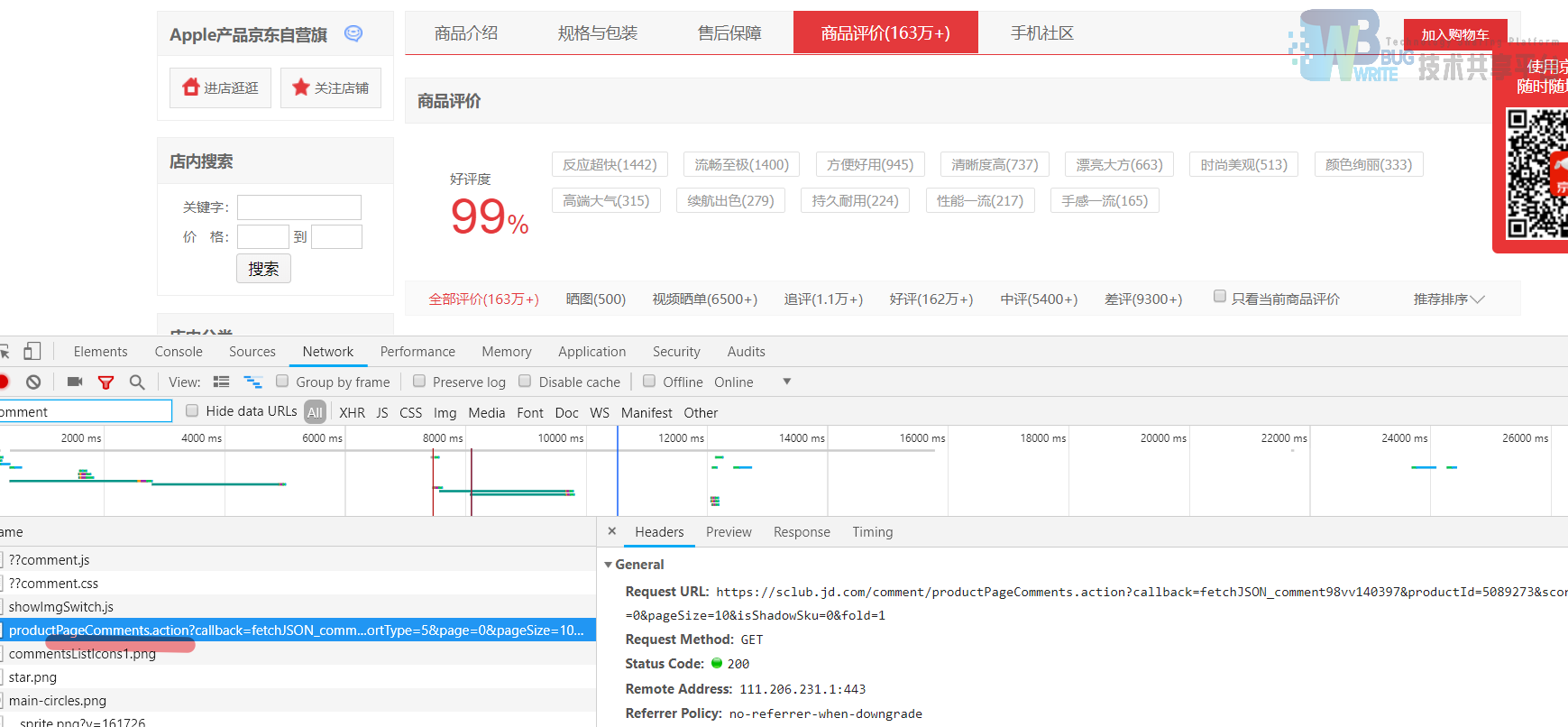
含有pageComment字段的即为服务器返回的页面评论数据,右键该文件->copy->Copy link address复制url并在url地址栏进行访问。访问结果如图3-6所示。
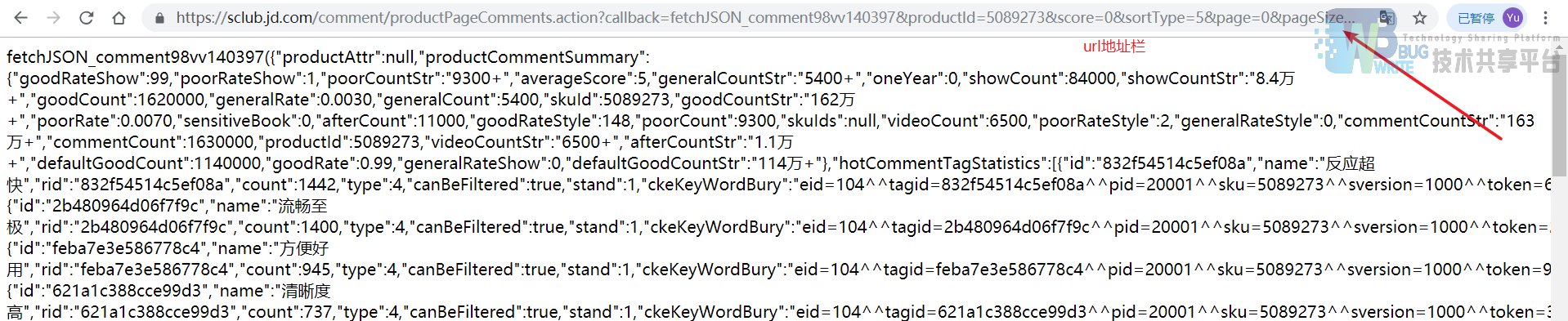
可以很容易的看到,服务器返回给页面的数据是JSON格式的数据。
可以先使用JSON在线编辑器进行json解析来验证这部分数据,在解析时发生错误,这是由于页面的数据的头部和尾部有一些其他的字符使得页面内容不完全是json数据,去掉第一个’(‘以及其之前的字符,同时去掉最后一个’)’以及其之后的字符即可。整理之后的结果如图3-7所示。
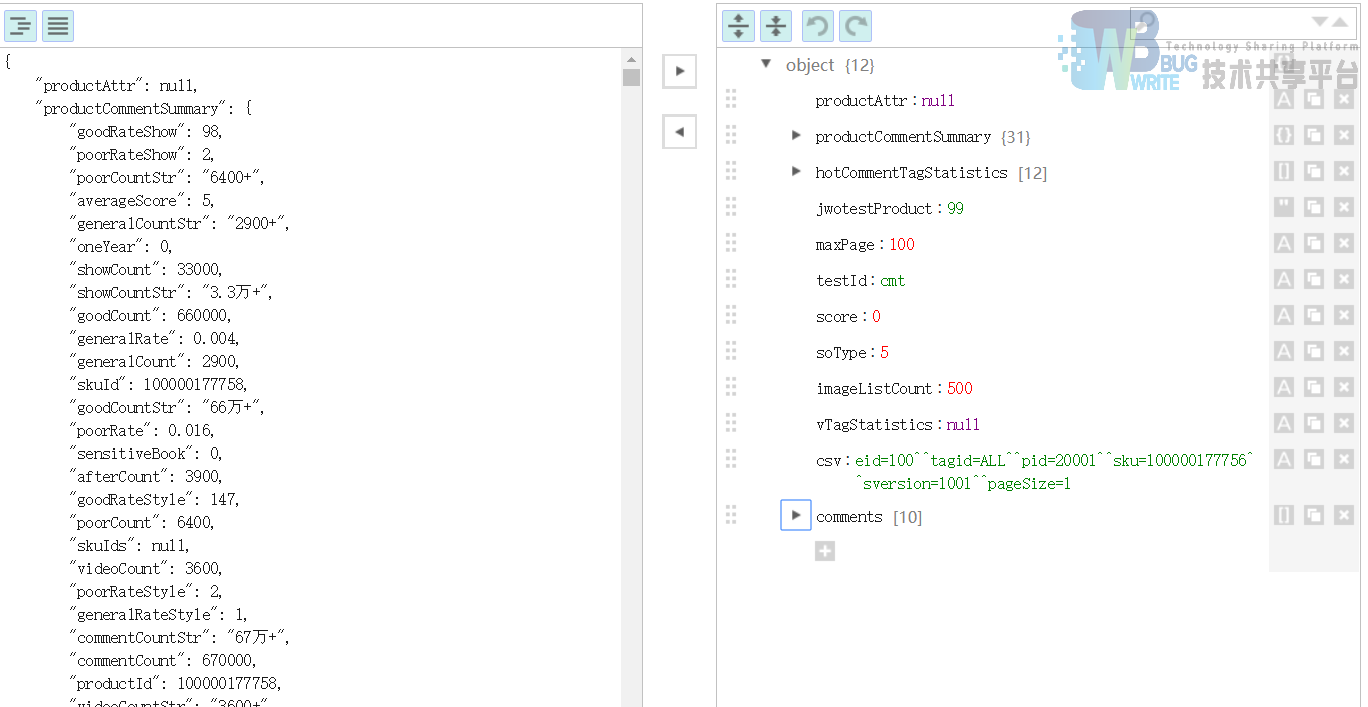
从图中可以清楚的看到,评论共有100页,每页的comment有10条。单独点开其中一条评论数据如下图。
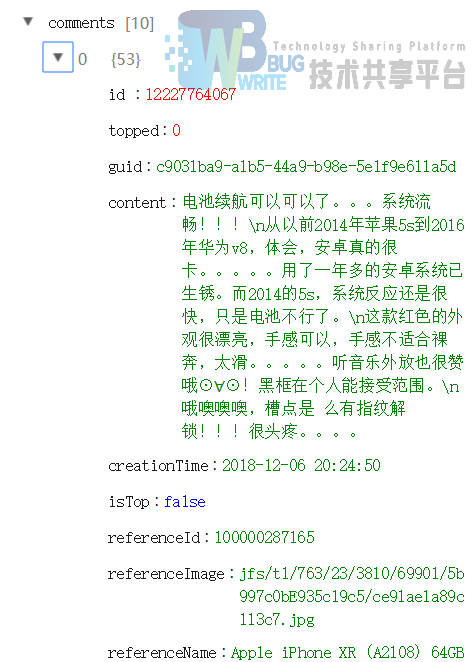
可以清楚的看到我们所需要的数据。
那么新的问题来了,京东界面所写评论有163万+条,那其他的数据都去哪了?查看一下第100页后面,看有没有发现。
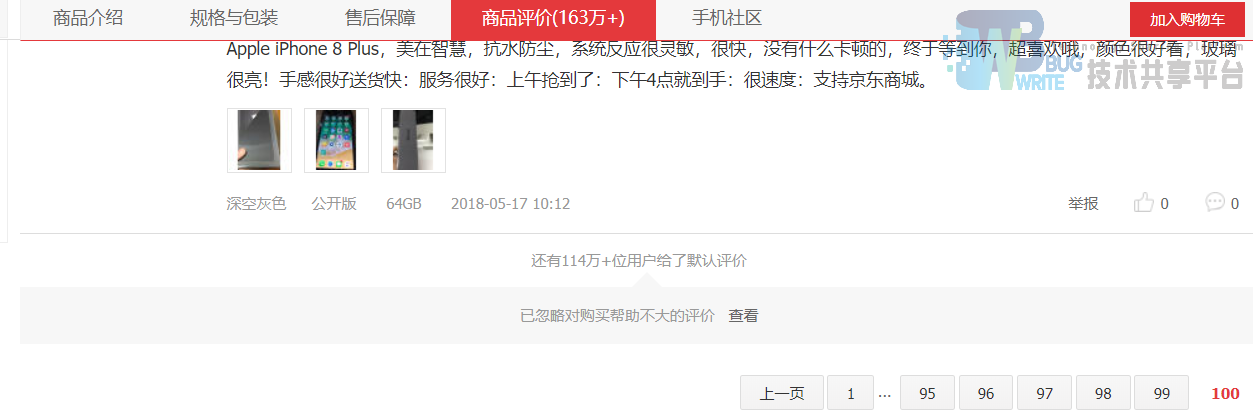
从图3-9中可以看出,还有114万+用户给了默认评价,为了分析更准确,加上这部分数据(其实点开也就100页,其他的可能服务器就没留着)。按照同样的方式,获取这部分评论的通用url。
尽管如此,也才仅有1500条左右的数据,不过在评论的菜单中还有追评、好评、中评、差评等,把这些也算进来,对比比较差异,见图3-11url参数分析。

发现不同评价的score不同,综合大约有4000~5000条数据。
继续统计手机不同参数所含的评论。在这里我将手机颜色从“金色”改为了“深空灰色”,按照同样的方式查看url。并与之前获取的进行对比。如图3-12。

对比之后发现,不同颜色的产品ID(productid)发生了变化。但其实评论区域还是各种颜色都有,所以这也是手机评论数据,只不过为了美观,在每次更改手机参数选择时进行了刷新(动态生成)。
根据这些url参数,就可以尽可能多的爬取该款手机的评论数据,代码里面的SpiderScript是一个完整的京东评论爬虫脚本,并且采用了随机浏览器和延时访问来防止爬虫被封,为了获取完整的数据,加入了try…except防止程序中断崩溃。
3.4.2 思考
经过上面的分析,可以看到数据量非常有限,远远没有达到163万条。经分析,有以下两种可能:
-
出现了数据造假,这个数字可能是刷出来的(机器或者水军)
-
真的有这么多的评论,但这时候系统可能只显示其中比较新的评论,而对比较旧的评论进行了存档
四、数据清洗与分析
4.1 清洗过程简述
在进行数据清洗之前要做的一项工作是先观察数据,看看数据中的哪些部分是合理的,哪些是不合理的,来确定待清洗的部分。使用python语句读取的数据如图4-1。

从图中可以清晰的看出,有大量的用户并未填写评价,这部分数据没有任何用处,并且会影响到我们最后统计的,结果,因此这部分数据需要清空。其次每一列中还存在一些空值,这些空值会严重影响我们的分析判断,并且很容易出现语法错误,因此这部分空值还要进行列格式的统一。
4.2 可视化与分析
这部分主要使用python结合pyecharts库来实现整体的功能,将上面清洗过的数据接着进行分析。
4.2.1 消费时段分析
按照最初的想法进一步分析下我们现有的数据,首先是购买一天中对不同时间段购买情况的分析,如图4-2所示。
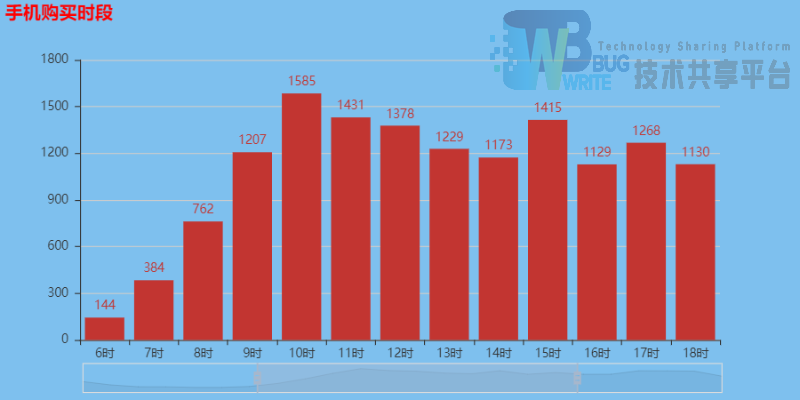
分析一天中不同时段消费者的手机购买情况,可以分析得出,大部分消费者在午时(10-12时)和晚上(20-22时)出现了消费高峰期,在此时段顾客购买商品的概率更大,他们浏览商品的机会更多。
4.2.2 月消费与会员等级分析
从规格化的数据中看出,会员等级是有限个,但都是字符串形式,只有对它们进行统一编码,才能统计类别个数。猜测会员等级和销售额存在一定的关系,并且通过分析月份和小时能更精确的为消费者提供服务,因此用折线图来表示销量与月份、会员级别的关系是非常有必要的。
绘制出折线图如图4-3所示。
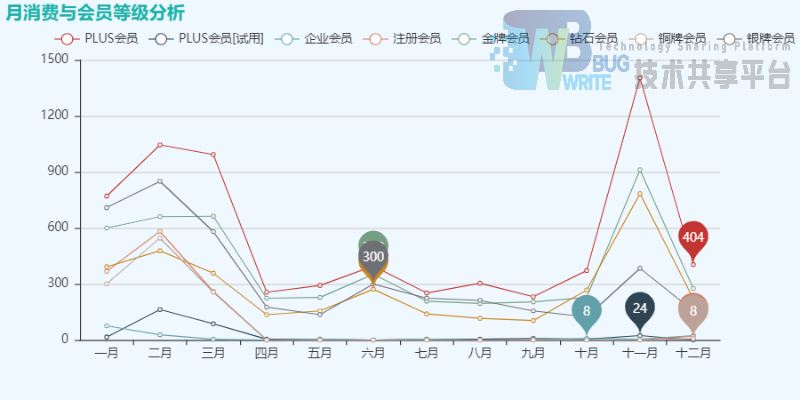
通过分析上图可知,不论是哪种会员,他们在三月份前后以及十一月份前后购买该款手机的数量最多,三月份换手机的原因推测是新年到来,更新换面的想法。十一月份换手机的原因推测与双十一有关,这时有很大的优惠,也是人们多样化选择手机的时段。
分析不同会员的购买情况可知,他们购买的频次降序排列为PLUS会员>金牌会员>银牌会员=钻石会员>PLUS会员(试用)>企业会员。 分析原因,大致是因为PLUS会员大部分都属于高消费群体,他们购买这些价值昂贵的手机概率更大。因此,大致可以推断,这款手机的主要消费对象是京东商城的PLUS会员(31.00%)、金牌会员(21.87%)、银牌会员(18.52%)。
4.2.3 评论内容分析
将评论内容的数据整合到一起,采用jieba库分词,并使用wordcloud生成词云,结果如图4-4所示。

通过上面此图基本可以看出消费者对该款手机的整体评价,但其中可能还有一些刷单的情况,这些量无法控制,没法排除,因此还是要理性的看待一款手机综合性能。
五、设计过程中存在的问题和解决过程
5.1 问题1
评论数据量超出jupyter可处理的范围。

解决办法:
重新生成jupyter配置文件,将里面的iopub_data_rate_limit限制值改一下就能处理,不过处理过程会比较慢。
5.2 问题2
通过采集之后发现京东的评论数据没有达到要求,于是到淘宝上看同款产品的评价进行搜集。如图5-2所示。
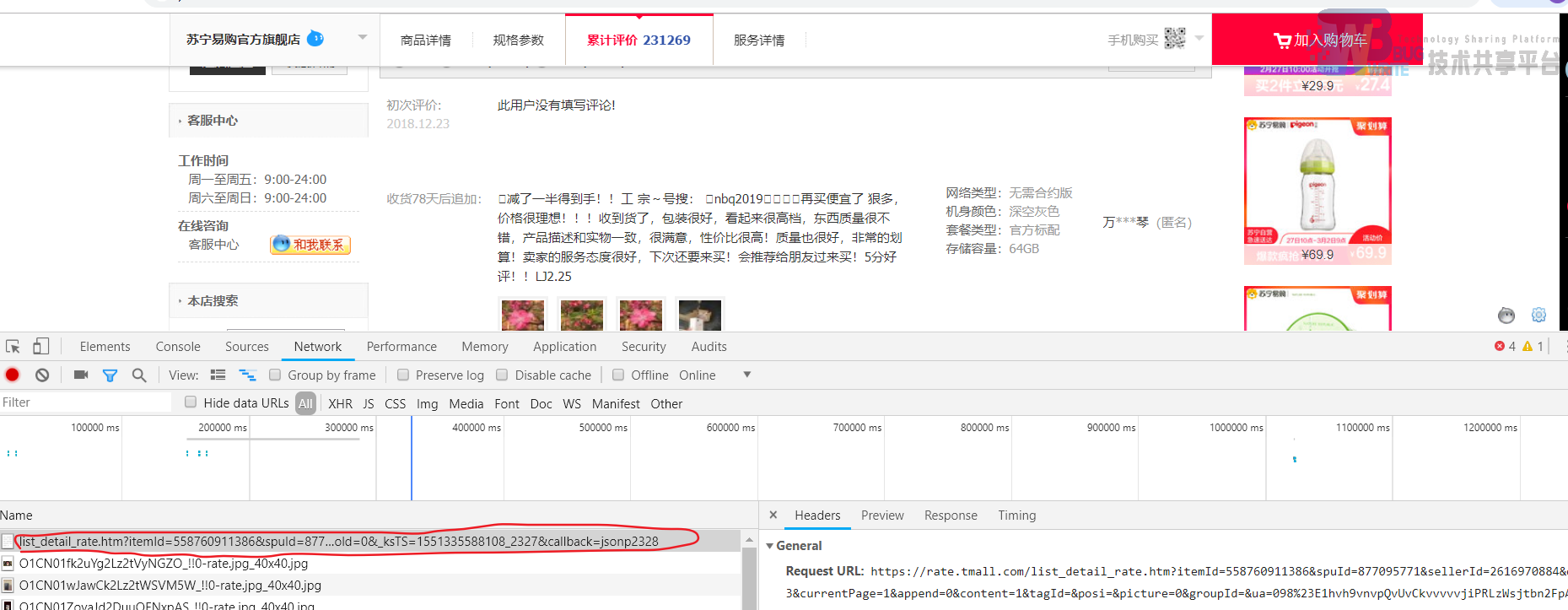
能找到包含json格式的评论数据,但是使用python进行访问时,却没有跳转到应该有的数据界面,而且跳到了其他界面,如下图:
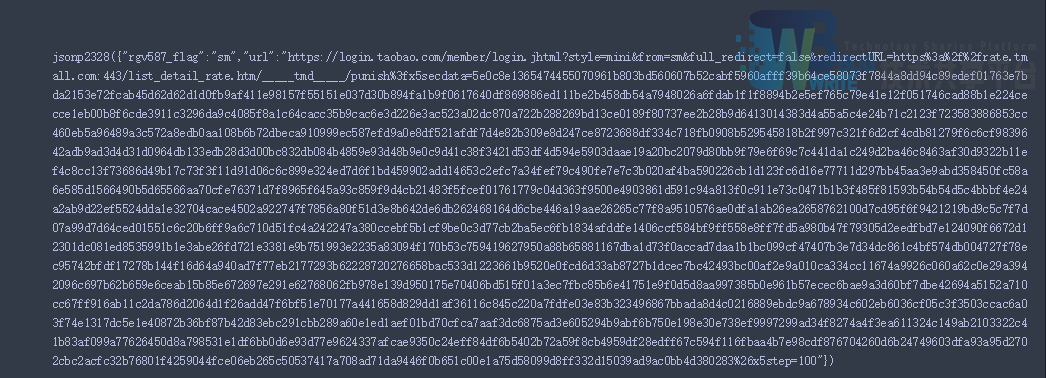
这意味着,没有登陆授权,无法查看评论信息(上面能看到评论信息,也是因为事先登陆过了),无法获取评论数据。
解决办法:
-
方法1 :python+selenium+webdriver的探索及问题:通过一系列的碰壁探索,发现selenium无法绕过淘宝登陆界面的验证,淘宝网应该是有识别自动化脚本登陆的反爬机制,根本无法获取登陆状态,无法登陆
-
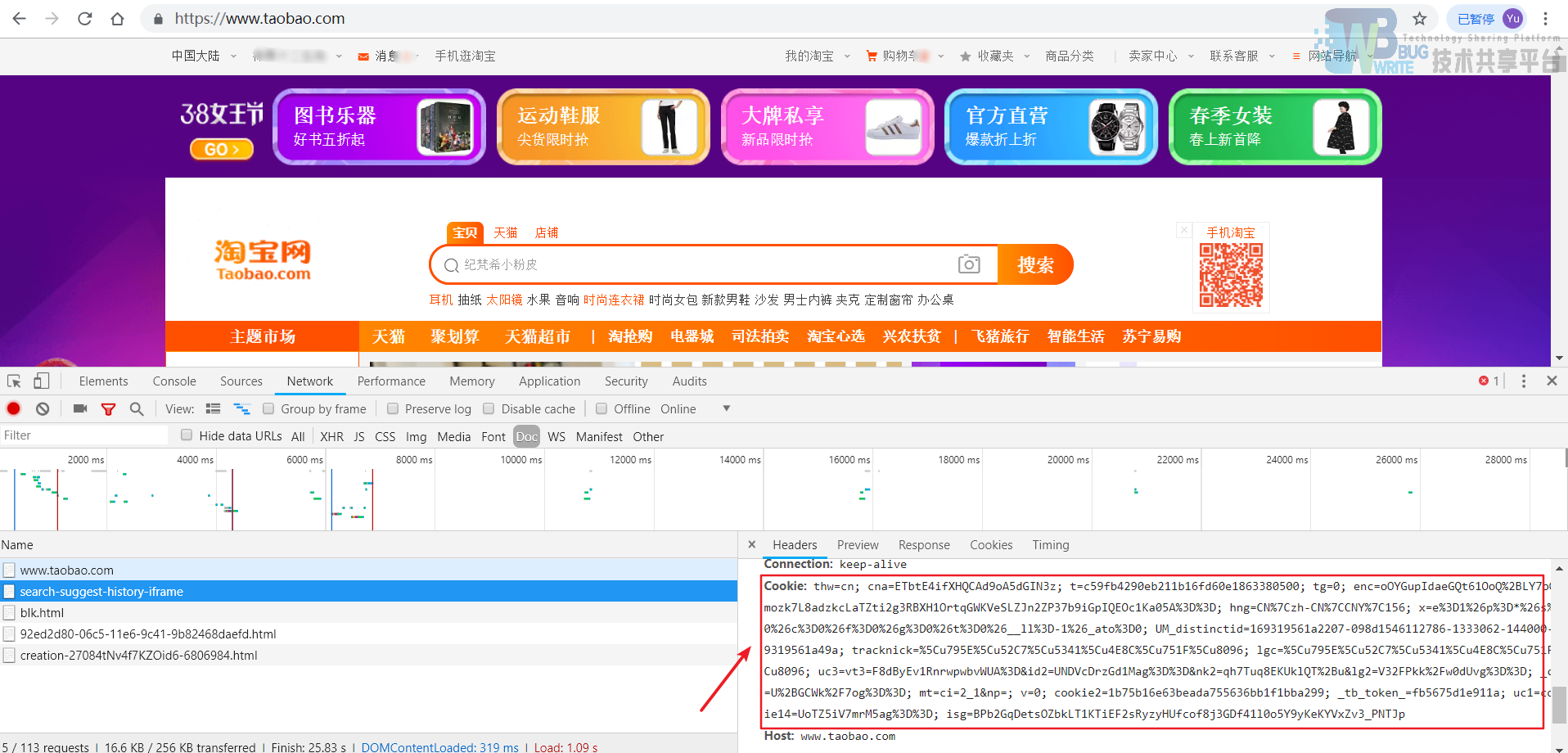
方法2 :通过伪造请求头来获取淘宝数据:登陆淘宝后,在淘宝主界面刷新,来获取登陆的cookies信息,如图3-14所示
随后用这部分cookies来构造请求头,如图3-15所示。
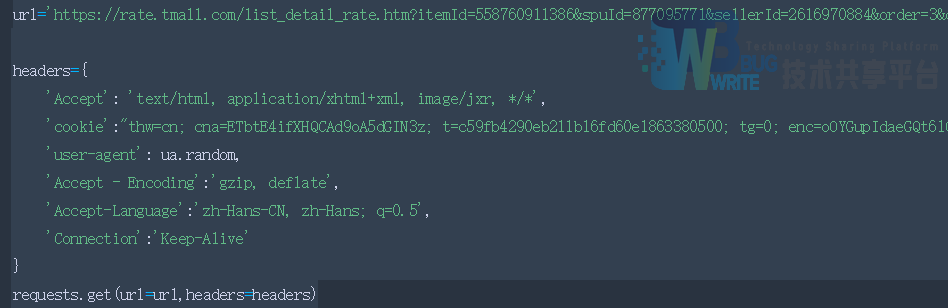
这样,就能访问淘宝上需要登陆才能获取的页面信息,不过当你尝试就会发现,即使这样,在短时间连续访问多次,也很容易被检测到,从而限制页面的获取数量。我使用该爬虫在不同的时间段爬了六七次,每次requests到第17次就会出错了,有待完善。
六、心得体会
在这次数据库课程设计中,我又重新熟悉了一下python来做数据爬取、分析挖掘及可视化的过程,对requests、pyecharts等库也有了更多的熟悉,中间还遇到了一些从没见到过的问题,通过一次次的修改,最终呈现出了一个较为完整的版本,当然这次爬取的数据还有一部分没有用上,其实再深层剖析的话,还是有很多可分析空间。不过,自己对数据的理解还很浅,还需要多看看别人的文章进行学习。坦白说,这次课程设计对自己的提高不大,有些新技术还没来的及尝试,课设就结束了,在以后的时间里,我还会多去了解一些新的技术和方法来更有效率的完成学习和工作!
这次课设让我们对数据库编程理解有了更深的了解,我们的课程设计要求是通过网络爬虫,采集京东某一型号手机的评论,根据评论的各类信息,来分析出购买手机顾客的类型和手机的方方面面的使用体验,这次我们使用的爬虫代码和主程序全部采用python编写,让我们对新的汇报语言有了更深的了解,懂得了如何使用这种语言去分析数据。
七、参考文章
-
搞定python多线程和多进程(https://www.cnblogs.com/whatisfantasy/p/6440585.html)
-
JSON在线编辑器(http://www.bejson.com/oldbejson/jsoneditoronline/)
-
Python爬虫,抓取淘宝商品评论内容(https://www.cnblogs.com/qun542110741/p/9221040.html)
-
Python入门网络爬虫之精华版(https://github.com/lining0806/PythonSpiderNotes)
-
Selenium Python文档:四、元素定位(https://www.cnblogs.com/taceywong/p/6602736.html)
-
为何大量网站不能抓取?爬虫突破封禁的6种常见方法(https://www.cnblogs.com/junrong624/p/5533655.html)
-
处理Jupyter Notebook报错:IOPub data rate exceeded(https://blog.csdn.net/LaoChengZier/article/details/80705298)
参考文献
- 基于海量评论导购系统的设计与实现(河北科技大学·底慧萍)
- 电子商务环境下用户观点的情感挖掘研究(四川师范大学·陈苹)
- 基于业务插件化的电商大数据采集系统(浙江工业大学·李天琦)
- 基于蚁群算法的分布式爬虫技术研究及应用(江苏科技大学·张冬冬)
- 初次评论及追加评论信息对生鲜水果销量影响研究(黑龙江八一农垦大学·李春月)
- 电商空调产品的评论数据情感分析(山西大学·杨瑞欣)
- 基于语义分析的电商用户评论多维度文本挖掘研究(长江大学·王宁)
- 基于深度学习混合模型的商品垃圾评论识别研究(江苏科技大学·张鹏)
- 基于时域信息异常检测的炒信刷单研究与实现(北京工业大学·刘文倩)
- 基于电商平台的产品评论大数据获取及应用(贵州师范大学·谭文斌)
- 线上用户评价信息的文本挖掘分析——以京东小米8手机自营为例(天津财经大学·吴瑞媛)
- 初次评论及追加评论信息对生鲜水果销量影响研究(黑龙江八一农垦大学·李春月)
- 基于情感分析的商品评价系统设计与实现(河北工程大学·崔新宇)
- 基于电商产品评论的图形化数据分析系统设计(长江大学·高聪)
- 基于Scrapy技术的数据采集系统的设计与实现(南京邮电大学·杨君)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码项目助手 ,原文地址:https://m.bishedaima.com/yuanma/35349.html









