
python数据分析(6)——挖掘建模(1)分类与预测
经过数据探索与数据预处理,得到了可以直接建模的数据.根据挖掘目标与数据形式可以建立分类与预测、聚类分析、关联规则、时序模式和偏差检测等模型。
分类与预测问题是预测问题的两种主要的类型,分类主要是预测分类标号(基于离散属性的),而预测是建立连续值函数模型,预测给定自变量对应的因变量的值。
一、实现过程
1.1 分类
分类属于有监督学习的范畴,大致上的意思就是我们可以将样本数据分成几个类别,将我们的数据与我们的类别相互对应。
1.2 预测
预测是指建立两种或者两种以上变量之间相互依赖的函数模型,然后进行预测或者控制。
1.3 实现过程

二、常用的预测和分类方法

三、回归分析

主要回归模型分类


3.1 Logistic回归分析介绍
3.1.1 Logistic函数


3.1.2 Logistic回归模型

3.1.3 Logistic回归模型解释

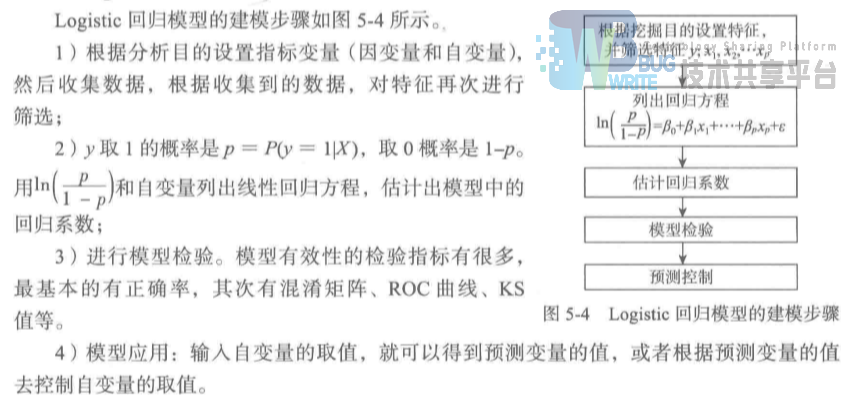
3.2 Logistic回归建模步骤
```python
- - coding: utf-8 - -
逻辑回归 自动建模
import pandas as pd
参数初始化
filename = 'bankloan.xls' data = pd.read_excel(filename) x = data.iloc[:,:8].as_matrix() y = data.iloc[:,8].as_matrix()
from sklearn.linear_model import LogisticRegression as LR from sklearn.linear_model import RandomizedLogisticRegression as RLR rlr = RLR() #建立随机逻辑回归模型,筛选变量 rlr.fit(x, y) #训练模型 rlr.get_support() #获取特征筛选结果,也可以通过.scores_方法获取各个特征的分数 print(u'通过随机逻辑回归模型筛选特征结束。') print(u'有效特征为:%s' % ','.join(data.columns[rlr.get_support(indices=True)])) x = data[data.columns[rlr.get_support(indices=True)]].as_matrix() #筛选好特征
lr = LR() #建立逻辑货柜模型 lr.fit(x, y) #用筛选后的特征数据来训练模型 print(u'逻辑回归模型训练结束。') print(u'模型的平均正确率为:%s' % lr.score(x, y)) #给出模型的平均正确率,本例为81.4% ```
四、 决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。

4.1 ID3算法简介及基本原理

显然E(A)越小,Gain(A)的值越大,说明选择测试属性A对于分类提供的信息越大,选择A之后对分类的不确定程度越小。
4.2 ID3算法具体流程
- 对当前样本集合,计算所有属性的信息增益
- 选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集
- 若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本递归调用本算法。
```python
- - coding: utf-8 - -
使用ID3决策树算法预测销量高低
import pandas as pd
参数初始化
inputfile = 'sales_data.xls' data = pd.read_excel(inputfile, index_col = u'序号') #导入数据
数据是类别标签,要将它转换为数据
用1来表示“好”、“是”、“高”这三个属性,用-1来表示“坏”、“否”、“低”
data[data == u'好'] = 1 data[data == u'是'] = 1 data[data == u'高'] = 1 data[data != 1] = -1 x = data.iloc[:,:3].as_matrix().astype(int) y = data.iloc[:,3].as_matrix().astype(int)
from sklearn.tree import DecisionTreeClassifier as DTC dtc = DTC(criterion='entropy') #建立决策树模型,基于信息熵 dtc.fit(x, y) #训练模型
导入相关函数,可视化决策树。
导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。
from sklearn.tree import export_graphviz
x = pd.DataFrame(x)
from sklearn.externals.six import StringIO
x = pd.DataFrame(x)
with open("tree.dot", 'w') as f:
f = export_graphviz(dtc, feature_names = x.columns, out_file = f)
```

五、人工神经网络
人工神经模型

激活函数

人工神经算法


BP算法学习流程

例子如下:(用神经网络算法预测销量高低)
```python
- - coding: utf-8 - -
使用神经网络算法预测销量高低
import pandas as pd
参数初始化
inputfile = 'sales_data.xls' data = pd.read_excel(inputfile, index_col = u'序号') #导入数据
数据是类别标签,要将它转换为数据
用1来表示“好”、“是”、“高”这三个属性,用0来表示“坏”、“否”、“低”
data[data == u'好'] = 1 data[data == u'是'] = 1 data[data == u'高'] = 1 data[data != 1] = 0 x = data.iloc[:,:3].as_matrix().astype(int) y = data.iloc[:,3].as_matrix().astype(int)
from keras.models import Sequential from keras.layers.core import Dense, Activation
model = Sequential() #建立模型 model.add(Dense(input_dim = 3, output_dim = 10)) model.add(Activation('relu')) #用relu函数作为激活函数,能够大幅提供准确度 model.add(Dense(input_dim = 10, output_dim = 1)) model.add(Activation('sigmoid')) #由于是0-1输出,用sigmoid函数作为激活函数
model.compile(loss = 'binary_crossentropy', optimizer = 'adam')
编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy
另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。
求解方法我们指定用adam,还有sgd、rmsprop等可选
model.fit(x, y, nb_epoch = 1000, batch_size = 10) #训练模型,学习一千次 yp = model.predict_classes(x).reshape(len(y)) #分类预测
from cm_plot import * #导入自行编写的混淆矩阵可视化函数 cm_plot(y,yp).show() #显示混淆矩阵可视化结果 ```
BP神经网络预测销售高低混淆矩阵图:

参考文献
- 基于业务插件化的电商大数据采集系统(浙江工业大学·李天琦)
- 标准化报表的数据分析在电信财务收入系统中的应用(电子科技大学·金鑫)
- 基于Hadoop的电商数据分析系统的设计与实现(广西师范大学·孙明铎)
- 基于Spark的社交网络数据分析平台(山东大学·王海林)
- 基于Hadoop的电商数据分析系统的设计与实现(广西师范大学·孙明铎)
- 零售业大数据下载与分析系统的设计与实现(西安电子科技大学·吴霜)
- 音视频数据获取与同源性分析关键技术研究(电子科技大学·范清宇)
- 文本综合处理平台的研究与实现(济南大学·王孟孟)
- 基于Python的非结构化数据检索系统的设计与实现(南京邮电大学·董海兰)
- 基于数据挖掘的用户上网行为分析(中央民族大学·丰玄霜)
- 网站运营分析系统设计与实现(电子科技大学·蒋黎)
- 基于数据挖掘的用户上网行为分析(中央民族大学·丰玄霜)
- 基于Hadoop的电商数据分析系统的设计与实现(广西师范大学·孙明铎)
- 音视频数据获取与同源性分析关键技术研究(电子科技大学·范清宇)
- 基于Django的模型参数分析系统的设计与实现(南京大学·府洁)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设助手 ,原文地址:https://m.bishedaima.com/yuanma/35393.html









