基于python的B站弹幕数据分析(爬虫+可视化)
python--B站弹幕数据分析
1 背景
在视频网站上,一边看视频一边发弹幕已经是网友的习惯。B站就是其中一个比较出名的弹幕网站,许多年轻人都喜欢逛B站,看喜欢的动漫亦或某些UP主做的一些剪辑。本项目,就是对B站弹幕数据进行分析。选取分析的对象是B站上一部国漫《全职高手》。
2 环境的安装
本项目实在pycharm中实现,使用到的第三方库有requests,bs4,pandas,jieba.posseg,pyecharts。具体如何安装,百度都有详细的步骤,我在这里就不啰嗦了。
3 相关代码代码实现
3.1 爬虫部分
在《全职高手》动漫的播放页查看网页源码,找到cid

因为b站需要通过格式为:"https://api.bilibili.com/x/v2/dm/history?type=1&oid={}&date=2018-{}-{}" 的链接获取弹幕历史文件,所以我们到时候可以通过url拼接,来爬取我们想要的具体哪一天的弹幕。
存放B站弹幕的是网站是xml格式的,如下图所示

其中每个字段都有对应的含义:
-
第一个参数是弹幕出现的时间以秒数为单位
-
第二个参数是弹幕的模式1..3 滚动弹幕 4底端弹幕 5顶端弹幕 6.逆向弹幕 7精准定位 8高级弹幕
-
第三个参数是字号, 12非常小,16特小,18小,25中,36大,45很大,64特别大
-
第四个参数是字体的颜色以HTML颜色的十进制为准
-
第五个参数是Unix格式的时间戳。基准时间为 1970-1-1 08:00:00
-
第六个参数是弹幕池 0普通池 1字幕池 2特殊池【目前特殊池为高级弹幕专用】
-
第七个参数是发送者的ID,用于“屏蔽此弹幕的发送者”功能
-
第八个参数是弹幕在弹幕数据库中rowID 用于“历史弹幕”功能
遍历爬取弹幕历史文件,存入csv中,保存格式为:['弹幕出现时间', '弹幕格式', '弹幕字体', '弹幕颜色', '弹幕时间戳','弹幕池','用户ID','rowID','弹幕信息']

3.2 可视化部分
保存了所有数据之后,先对数据进行处理:先读取csv文件,再进行可视化分析
每一集弹幕总量变化--折线图:逐个读入弹幕历史文件:d1.csv,d2.csv,……经过去重后,统计出每集的弹幕总量:
python
data = pd.read_csv(path.strip(),encoding='gbk',engine='python')
统计每一集的弹幕总量,存放在字典中
python
episode_comment_dic[i] = every_episode_comment(data)
之后便进行可视化绘图了
python
def every_episode_comment_change(episode_comment_dic):line = pyecharts.Line("每一集弹幕变化总量",'2018-12-27',width=1200,height=600)
keys = []
values = []
for i in episode_comment_dic:
keys.append("第%d集" % i)
values.append(episode_comment_dic[i])
'''每一集弹幕总量的折线变化图'''
line.add("每一集弹幕总量的折线变化图",keys,values)
es = pyecharts.EffectScatter()
es.add("",keys,values)
overlap = pyecharts.Overlap()
overlap.add(line)
overlap.add(es)
return overlap
发送弹幕总量TOP5用户:1.统计每一集弹幕数量,把用户排序,每一集排序后的结果都是一个DataFrame, 结果的大致结构:user_sort_dic = {1: DataFrame1, 2:DataFrame2, ......,12: DataFrame12}。
python
'''每一集用户发送弹幕数量排序'''
def every_episode_usersort(data):
df = data.drop_duplicates()
dd = df.groupby("用户ID").count()
user_sort = dd.sort_values(by = '弹幕信息',ascending=False).loc[:,['弹幕信息']]
return user_sort
用户发弹幕长度分布,统计发送弹幕的字符串长度:

用户发弹幕数量分布,统计一集,用户发送弹幕数量的百分比分布图。
python
user_sort_dic[i] = every_episode_usersort(data)
'''统计用户发送弹幕数量的百分比分布图'''
for i in user_sort_dic:
d_tmp = user_sort_dic[i]
pie = every_episode_barrage_pie(d_tmp,i)
timeline1.add(pie,i)
del d_tmp
每集弹幕密度变化图:每个弹幕都有一个时间参数,代表了用户在视频的什么时间发了弹幕。所以我们可以统计出在相同时间参数发出的弹幕量,然后再画出“时间--弹幕数量”折线图,就可以看到弹幕量的变化了。
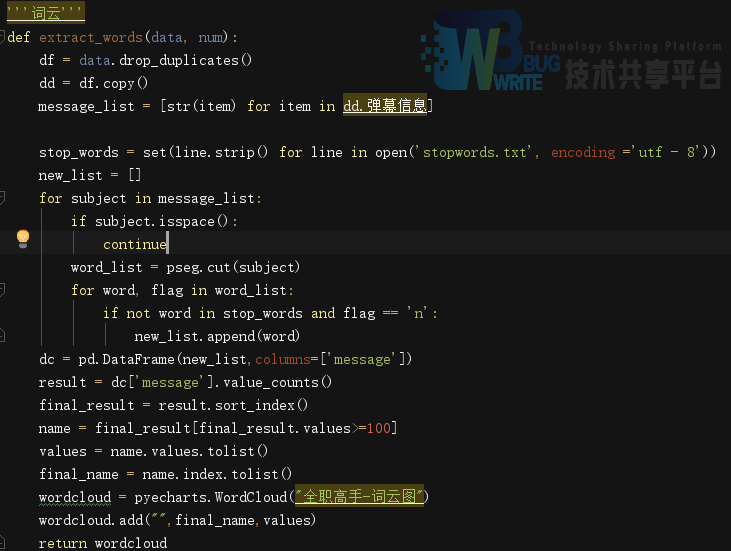
词云图:对所有的弹幕文本进行分析。先用jieba词库进行分词,然后逐行对弹幕进行词频统计,最后用pyecharts的WordCloud画出词云图,wordcloud = pyecharts.WordCloud("全职高手-词云图")
3.3 统计结果
全职高手动漫12集用户发送弹幕条数饼图--轮播:

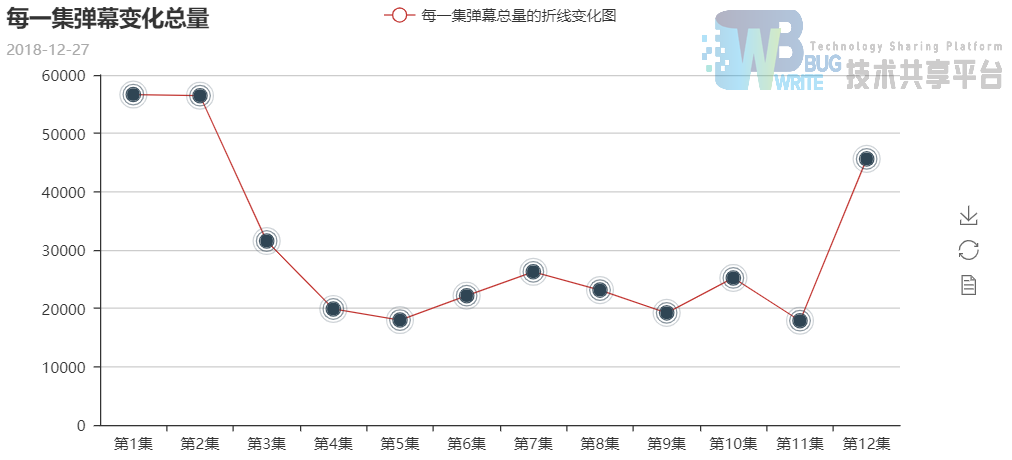
每一集弹幕总量的变化:
每一集用户发送弹幕的字数饼图--轮播:

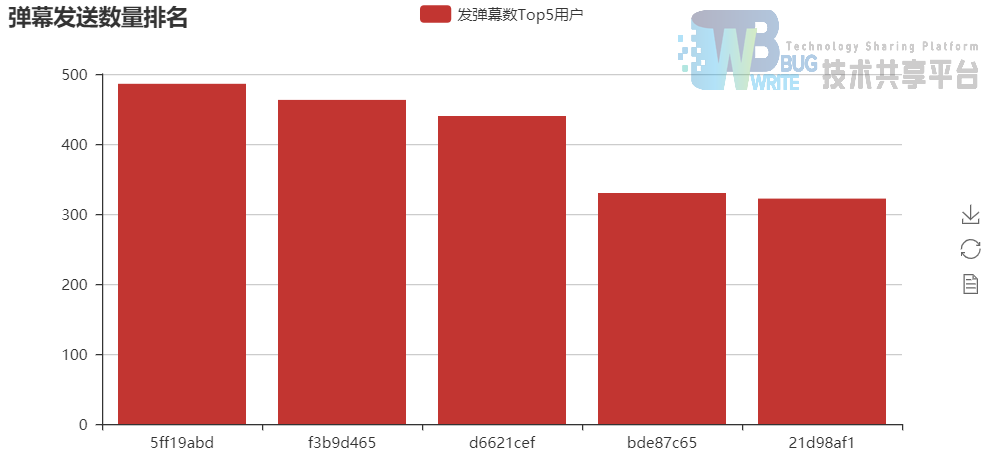
12集用户发送弹幕总量排名--直方图:
一集视频中用户发送的弹幕密度图:

12集动漫的词云图:

3.4 结果分析
通过以上的图表数据可以看出用户的弹幕的一些行为。
12集剧里,第一集,第二季和最后一集,弹幕数量是最多的,说明这部动漫刚上线的时候关注度还是很高的,之后的弹幕数量不高可能是因为剧情发展比较平稳,最后一集弹幕数量又多了起来,说明动漫结束,用户们都纷纷发表感慨,从词云中的‘散场’也可看出。
统计了12集的弹幕,用户ID为5ff19abd的用户共发送了480多条弹幕,算是超级粉丝了。
通过弹幕数量和长度的分布,可以看出:绝大部分用户只会发送2条以内的弹幕。参与弹幕讨论的用户以10个字符以内的短语为主。
统计每一集的弹幕密度,可以通过用户观看时的讨论,大致确定视频的精彩点。
通过词云图,可以大致看出用户的分布。例如‘散场’作为热词显示里。说明许多用户都为动漫的结束发表感慨。
4 总结
因为绘制热词云图的代码运行太久了,所以本实验的词云图只截取了某些天的弹幕,或许可以引入多线程使程序效率更高。因为B站的网页是动态的,当时做爬虫的时候准备用webdriver,无奈环境搞不会,放弃了。本项目还是有许多缺陷的,当时做的时候借鉴了一篇博客,又把它给改进了一下,然后才实现出了该项目。(大三上python数据分析大作业,本人很菜,不完全原创,内有许多不足。)
参考文献
- 基于协同过滤的视频推荐系统研究与实现(江苏科技大学·浦艺钟)
- 互联网招聘数据分析与可视化系统设计与实现(西南大学·田书丽)
- 视频检索与推荐系统的设计与实现(华中科技大学·陈凡)
- 基于Web的信息发布与信息交流平台的设计与实现(吉林大学·许昭霞)
- 视频处理平台的设计与实现(北京交通大学·时月月)
- 电影网站数据挖掘可视化系统设计与实现(华中科技大学·王志)
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- 基于视频分享社交系统后台的设计与研发(中国地质大学(北京)·刘昌瑞)
- 面向视频网站的自感知通用爬虫系统的设计与实现(北京邮电大学·黄国锴)
- 基于Spark的社交网络数据分析平台(山东大学·王海林)
- 逼真流数据测试集的弹性并行生成框架技术(华东师范大学·顾伶)
- 视频推荐系统数据分析决策平台(华南理工大学·贺栋博)
- 融合多特征的弹幕视频推荐算法的研究与实现(西北民族大学·黄昌昊)
- 电子商务网站的数据分析系统研究与开发(北方工业大学·韩杰)
- 互联网招聘数据分析与可视化系统设计与实现(西南大学·田书丽)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码项目助手 ,原文地址:https://m.bishedaima.com/yuanma/35396.html