
基于python实现的CS通信和P2P通信
一、实验要求
- C/S通信实现要求
- 两台计算机分别模拟服务器、客户端
- 通过编程实现服务器端、客户端程序Socket,Client。
- 服务器端程序监听客户端向服务器端发出的请求, 并返回数据给客户端。
-
不采用方式,自定义通信协议,传输文件要足够大(例如:一个视频文件)
-
P2P通信实验要求
- 为每个peer开发服务器程序、客户端程序
- 每个peer上线后,向服务器注册自己的通信信息
- 假设peer3要下载文件 (视频),A与peer1,peer2都拥有A,请设计方案使peer3能够同时从peer1、peer2同时下载该文件,例如:从peer1下载A的前50%、同时从peer2下载后50%
- 比较与C/S通信方式的性能指标
二、简介
-
本次实验使用Python3语言,在Linux操作系统上完成
-
C/S通信部分 :使用TCP作为传输层协议,使用固定头部 + 可变数据长度的应用层通信协议,能够解决TCP的分包、黏包问题
-
P2P部分 :研究并实现了简化版的有tracker服务器的Bittorrent协议。采用消息循环的设计方式,两台对等主机之间建立连接后各自开启一个线程,交换bitfield并初始化自身状态,进入消息循环,根据自身状态和收到的消息决定状态的转换和执行的操作。各台对等主机,以及对等主机和服务器之间的通信基于了C/S通信部分实现的可靠二进制文件传输模块
下面,将详细描述C/S通信、P2P通信的协议和实现,并给出运行结果。
三、C/S通信
3.1 应用层协议
C/S通信中采用TCP作为传输层协议,可以保证传输的文件流是有序且无误的。然而TCP作为一种流传输协议,应用层是无法获知接收缓冲区中一个文件起始和结束的位置。因此我们采用了固定头部+可变数据长度的应用层通信协议,我们将之命名为rdt_socket。

3.2 服务端
服务端在使用该协议时,首先建立普通的socket连接:
```python import socket import utilities #实用工具库,提供get_host_ip函数 SERVER_IP = utilities.get_host_ip() #获取本机ip SERVER_PORT = 6666 #服务器端口固定为6666
获取socket文件,采用tcp连接
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
设置允许重用地址,防止程序退出后提示端口仍被占用
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
开始监听端口
server_socket.bind((SERVER_IP, SERVER_PORT))
设置最大连接数为MAX_TCP_LINK
server_socket.listen(MAX_TCP_LINK)
阻塞等待客户端接入
(client_socket, address) = server_socket.accept() ```
然后将该server_socket传入rdt_socket类,获得rdt_socket对象,然后将要发送的二进制文件传入sendBytes方法,该方法将在在其头部加上8字节的文件长度信息。
python
def sendBytes(self, f : bytearray):
try:
#获取文件长度
l = len(f)
#设置header
header = struct.pack('!1Q', l)
send_data = header + f
#记录日志
logger.debug('Sending raw tcp data len {}'.format(len(send_data)))
#使用socket发送该message
self.s.sendall(send_data)
#异常处理
except socket.error as e:
print(e)
print(e.filename)
3.3 客户端
客户端在使用该协议时,同样首先建立普通的TCP连接连接到服务器,然后将socket传入rdt_socket类,使用rdt_socket的recvBytes方法获取文件。
python
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((SERVER_IP, SERVER_PORT))
rdt_s = rdt_socket.rdt_socket(sock)
data = rdt_s.recvBytes()
recvBytes的实现如下,其基本思路是:
首先检查缓冲区是否有8个字节的header,若有则检查缓冲区的长度是否有header中指出的文件长,若有则说明有一个文件可以取出了。该函数会首先检查当前TCP缓冲区中是否已经有有一个文件,如果没有,才会阻塞读取缓冲区,之后再检查是否有一个文件。
python
def recvBytes(self):
if len(self.databuf) >= FILE_HEADER_SIZE:
header = struct.unpack("!1Q", self.databuf[:FILE_HEADER_SIZE])
body_size = header[0]
if len(self.databuf) >= FILE_HEADER_SIZE + body_size:
body = self.databuf[FILE_HEADER_SIZE:FILE_HEADER_SIZE + body_size]
self.databuf = self.databuf[FILE_HEADER_SIZE+body_size:]
return body
while True:
data = self.s.recv(1024)
logger.debug('Received raw tcp data len {}'.format(len(data)))
if data:
self.databuf += data
while True:
if len(self.databuf) < FILE_HEADER_SIZE:
break
header = struct.unpack("!1Q", self.databuf[:FILE_HEADER_SIZE])
body_size = header[0]
if len(self.databuf) < FILE_HEADER_SIZE + body_size:
break
body = self.databuf[FILE_HEADER_SIZE:FILE_HEADER_SIZE + body_size]
self.databuf = self.databuf[FILE_HEADER_SIZE+body_size:]
return body
四、P2P通信
4.1 协议
下面我们将从三个方面分别介绍设计的P2P通信协议:
-
Torrent文件格式
-
Tracker — Peer协议
-
Peer — Peer 协议
4.1.1 Torrent文件格式
Torrent文件的作用是:
-
声明了一个P2P网络的tracker服务器地址和端口
-
声明了在该P2P网路上共享的一个文件的文件名、长度、区块数、各区块哈希值,唯一确定了一个文件
一个Peer在获取一个Torrent文件后,便可加入该P2P网络并获取该文件。
使用(类)Json的语法描述Torrent文件如下:
json
{
announce: <str>, #domain name
port: <int>
comment: <str>
info: <dict> {
piece_length: <int>
piece_hash: <list<str>>
file_name: <str>
file_length: <int>
}
}
4.1.2 Tracker — Peer协议
这部分协议提供了加入和退出P2P的机制。特别是使得加入P2P的Peer能够获取目前的Peer列表。
Peer发送的Request格式
包含:
-
Peer的IP
-
port,Peer的本地监听端口
-
peer_id,由peer的ip和port组成
-
event,可能值包括started(用于请求加入网络),stoped(未使用),completed(用于请求退出网络)
json
{
port: <int> (validator: 1~65536)
ip (opt): <str>, (validator: 点分十进制表示法)
peer_id: <str>, (peer ip + ':' + peer port)
event: <str>, [(started) | (stopped) | (completed)]
}
Traker发送的Response格式
包含:
-
error_code,收到的请求有效时为0,非法请求则为1
-
message,包括started ACK和disconnect ACK两种
-
num-of-peer,请求前的peer数
-
请求前P2P网络中的peer的id、端口、地址
python
{
error_code: <int>
message: <str>
num-of-peer: <int>
peers: <list> [
{
peer-id: <str> (peer ip + ':' + peer port)
peer-port: <int> <validator: 1 - 65536>
peer-ip: <str> <validator: 点分十进制表示法>
}
]
}
该Response仅会向刚刚发送请求的peer发送。这样已经加入的peer不会收到新peer加入的消息,然而由于我们的设计是peer1向peer2主动建立一个peer connection连接时,peer2会同样会(被动地)和peer1建立一个peer connection,因此之前已经加入网络的Peer依旧能够与新Peer建立连接。
4.1.3 Peer — Peer 协议
Peer—Peer之间的协议在PeerConnection类中实现,如上文所述,一个P2P连接的两台主机会对等地,分别建立一个PeerConnection。
每个PeerConnection维护两组状态,这两组状态分别用两个二进制位表示:
- send_file_state
- 高位:my_choke,表示我是否停止向他人发送文件
-
低位:peer_interested,表示他人是否需要从我获取文件
-
recv_file_state
- 高位:peer_choke,表示对方是否停止向我发送文件
- 低位:my_interested,表示我是否需要从对方获取文件
每个PeerConnection在建立之时首先进行交换bitfield的操作。
每个PeerConnection以消息循环地方式工作,收到消息时,依据消息类型,可能导致SendFile状态机或RecvFileMachine发生状态转移并执行相应动作,我们使用下图的状态机转移图进行描述。类似课本rdt协议状态机的格式,图中每条线状态转移线上有两行注释,上面一行表示收到的导致转移发生的消息,下面一行表示执行的动作和发出的消息。
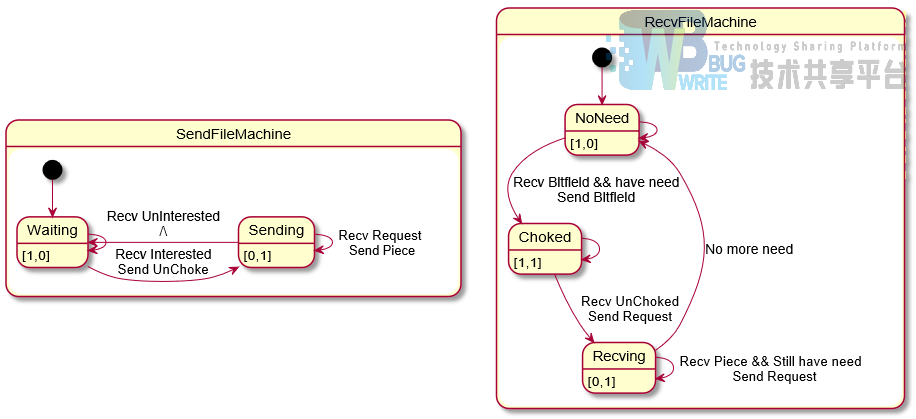
Peer — Peer间的消息有以下几种
-
Choke,发送该消息者拒绝向对方发送文件
-
UnChoke,发送该消息者可以向对方发送文件
-
Interested,发送该消息者需要从对方获取文件
-
UnInterested,发送该消息者无需从对方获取文件
-
Have,一方收到一个piece后,发送该消息通知对方已经完成接收该piece
-
Bitfield,一方拥有的文件区块信息
-
Request,一方向另一方请求piece,消息中包含piece编号
-
Piece,一方收到request后回复的文件piece,包含文件内容
-
KeepAlive,保持连接,接收者收到后忽略该消息
-
ServerClose,一方通知另一方自己要关闭了,另一方收到该消息后也会关闭该peer Connection
大多数消息均有以下三个字段:
json
{
type: <str>
length: <int>
message_id: <int>
}
特别地:
-
KeepAlive消息没有message_id字段,可以根据它的length为0的特点判断其类型
-
Bitfield消息有一个Bitfield字段,包含了自己的bitfield
-
Request消息有一个piece_index字段,表示请求的piece的序号
-
Piece消息有一个piece_index字段,表示自身序号;有一个raw_data字段,用以传送文件数据
4.2 实现
4.2.1 协议的消息传输
协议中消息的传递是基于C/S通信中的二进制传输代码。
Tracker — Peer协议的消息格式为Json,我们使用Json以下两端代码将Json转换和转换为二进制。
```python def objEncode(obj): """ obj,返回binary对象 """ return json.dumps(obj,indent=4, sort_keys=True,separators=(',',':')).encode('utf-8')
def objDecode(binary): """ binary 返回dict对象 """ return json.loads(binary.decode('utf-8')) ```
Peer — Peer 协议中协议的原始格式也为Json,但Piece中的原始文件数据在使用objEncode编码时会出错,因此使用Python的Struct类进行转换。
4.2.2 Tracker的实现
Tracker端的实现在src/backend/server.py中,与之相关的有两个类,ServerMonitor和Server,均继承于threading类,通过实现threading类的Run函数,将主逻辑运行在线程中。
ServerMonitor类的run函数处理用户输入,在输入q时终止Tracker。
Server类的run函数监听并Peer呼入的连接,根据消息做出回复。
available_peers_list函数返回当前Peer列表。START_ACK/COMPLETE_ACK两个函数方便地返回了两种Response消息。

4.2.3 Peer的实现
这部分是整个实现中的重点。
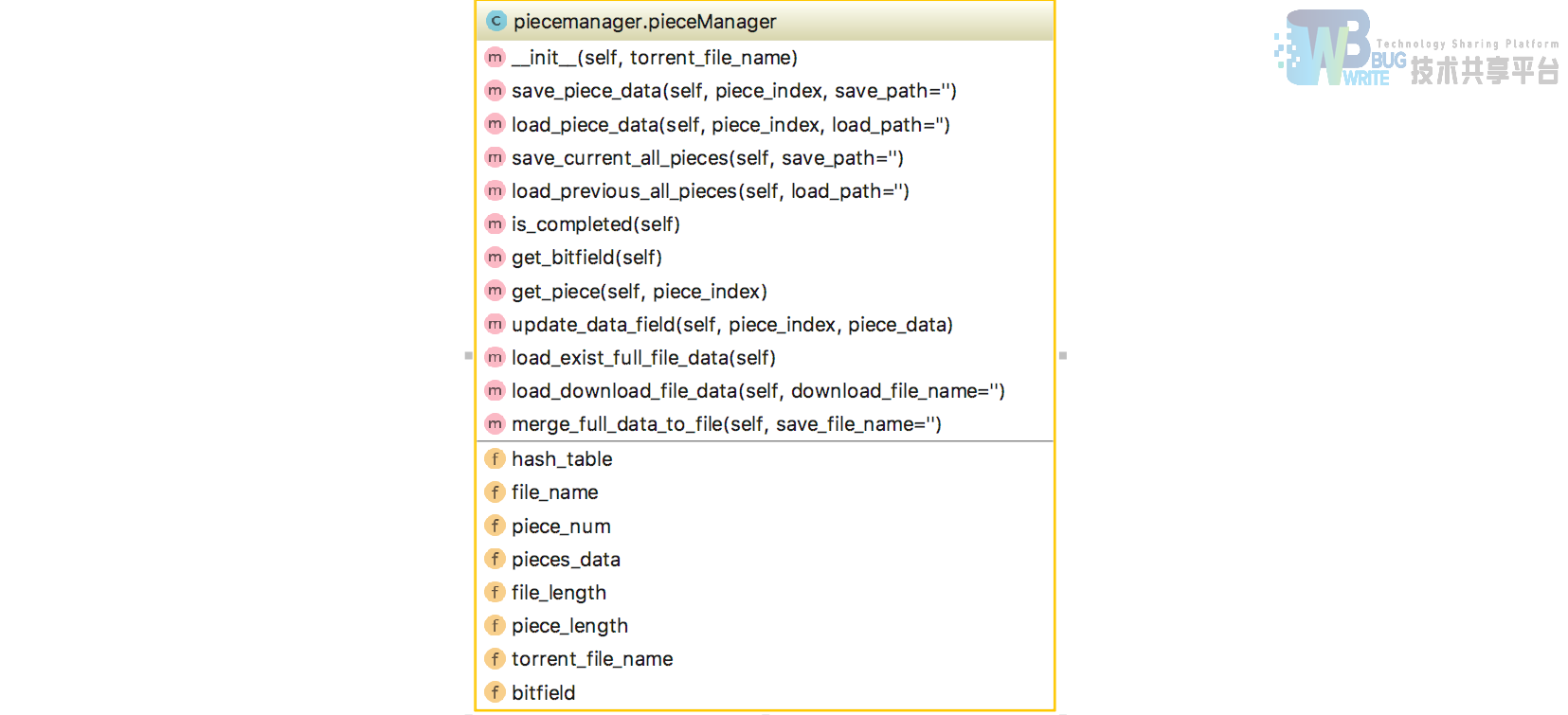
实现在src/backend/client.py、src/backend/piecemanager.py、src/backend/state.py、src/backend/message.py几个文件中。
由Client、PeerConnection、ClientMonitor、pieceManager这几个类实现,其中Client、PeerConnection、ClientMonitor三个类同样是继承与threading类,在run函数中,以多线程方式实现主逻辑。
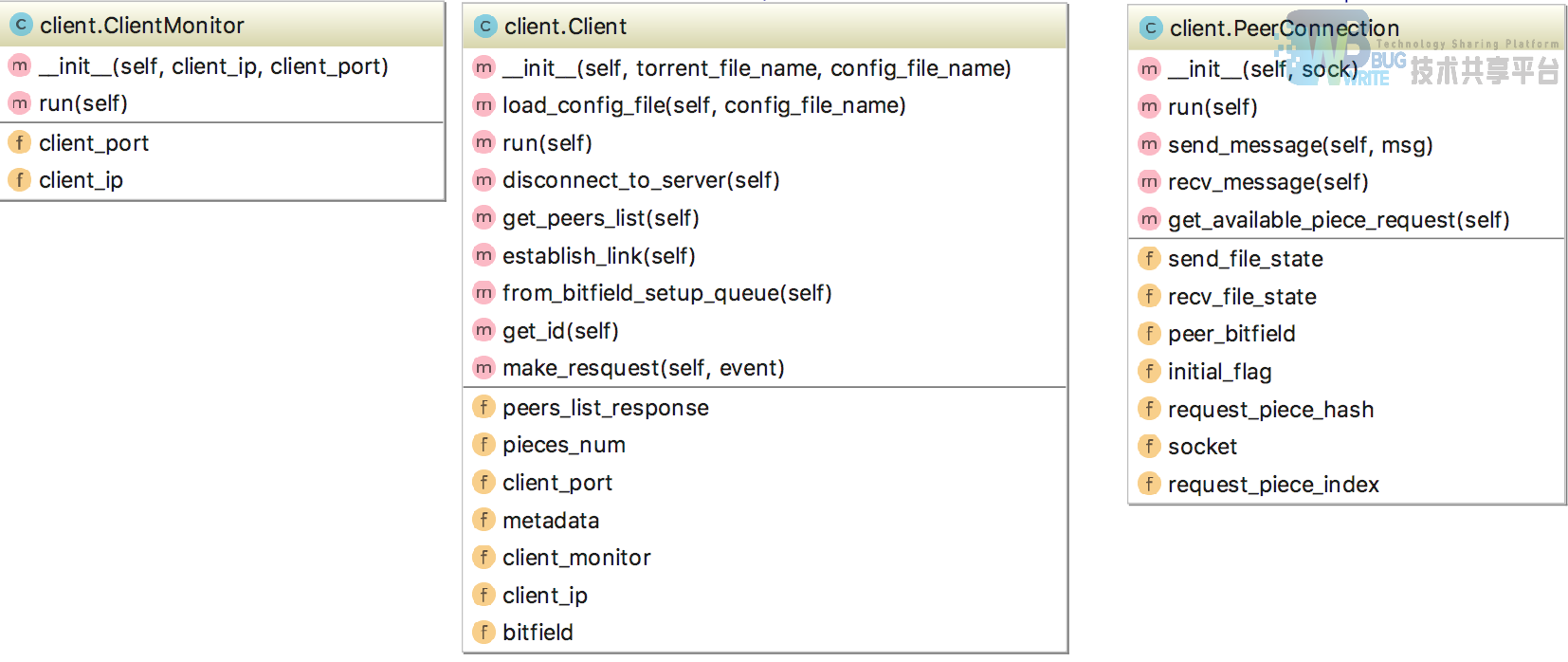
整个工作原理和流程如下:
-
Client类主要完成整个初始化流程,它接收一个torrent文件和配置文件,在构造函数中读取这些文件进行初始化,并启动一个pieceManager
-
pieceManager类管理本地文件分块,根据本机拥有的piece设置初始bitfield。并在拥有完整的bitfield时进行文件合并
-
Client使用一个全局的线程安全队列left_pieces保存缺失的piece的编号。run函数运行时,根据pieceManager设置的初始bitfield初始化left_pieces。然后执行get_peers_list向tracker请求peer列表。收到后向这些peer中的指定个(目前为4个)peer主动发起连接
-
之后,Client启动ClientMonitor,该类实现的是被动接收连接功能:它监听本地端口,阻塞循环接受来自其他线程的新连接。得到新的连接new_socket后,将new_socket传入并启动一个新的PeerConnection
-
Client类的工作基本结束,开始循环询问pieces_manager是否已经获取全部piece。在后台线程中运行的PeerConnections首先发送Bitfield,然后进行着协议中描述的消息循环:在一个While循环中,阻塞接收消息。然后简单地if语句进行判断
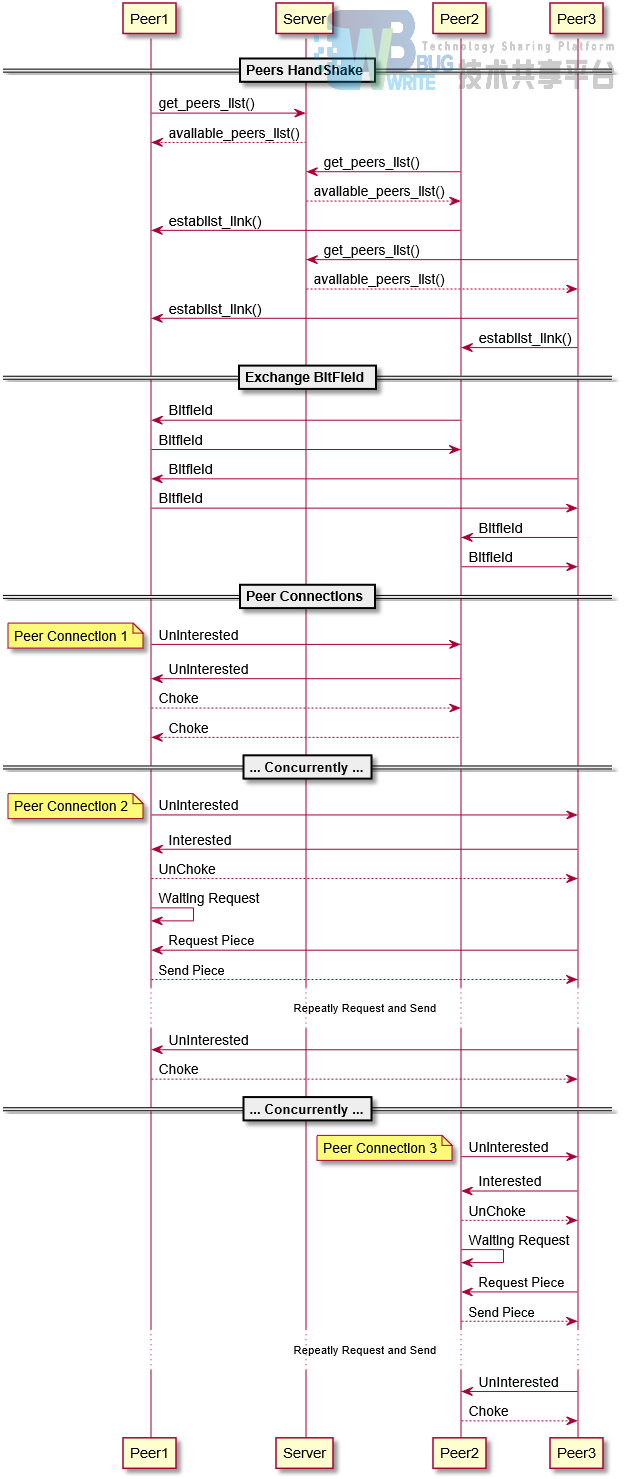
4.3 时序图
我们以实验要求中的使用场景为例,绘制了整个下载过程的时序图,让整个过程更加清晰易懂。
假设peer3要下载文件 (视频),A与peer1,peer2都拥有A,请设计方案使peer3能够同时从peer1、peer2同时下载该文件,例如:从peer1下载A的前50%、同时从peer2下载后50%。
注:图中 三个Peer Connection是并行执行的 。
4.4 安装部署及实验结果
4.4.1 运行环境
-
本项目在python3.5环境下开发并测试
-
服务器与客户端均运行在同一个内网中
4.4.2 TRACKER 服务器的部署
需要做两件事情。
-
制作 Torrent 文件
-
导入Server类,运行 Tracker 服务器
源代码可见:
```python import os import sys
这里是源代码的路径,可自行修改为对应的相对路径或绝对路径。
SRC_PATH = '../src/backend/' sys.path.insert(0, SRC_PATH) from torrent import *# 导入 种子文件 模块 full_file = './seed/test.txt'
制作种子文件,默认存到当前目录下
make_torrent_file(full_file)
运行server端
os.system("python3 "+SRC_PATH+"server.py") ```
4.4.3 BITTORRENT 客户端的部署
-
从源代码中代入Client类
-
使用种子文件,客户端配置文件,初始化客户端,并运行之
```python import sys sys.path.insert(0, '../../src/backend/') from client import * from torrent import *
file_name = '../test.txt' test_torrent_file = file_name+'.torrent' # 种子文件相对路径 test_config_file = './client_config.json' # 客户端配置文件 client = Client(test_torrent_file,test_config_file) client.start() ```
4.4.4 启动TRACKER服务器
在命令行下执行以下指令:
```
在demo文件夹下
python3 make_torrent_and_start_tracker.py ```
-
使用本机IP地址更新种子文件
-
启动tracker服务器
-
默认监听6666端口(可在server.py中修改端口号)
启动后的界面:
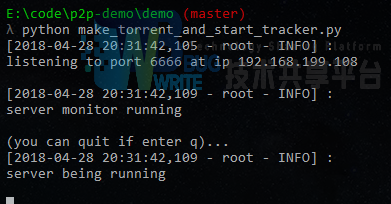
4.4.5 启动客户端
在启动客户端前,确保种子文件已经更新。
启动客户端的时候,客户端会做两件事情:
-
读取Torrent文件,并将数据初始化到客户端内部数据中
-
获知文件名后,检查"文件名_data/"文件夹下是否有历史数据块,有则加载,无则不管
由此,区分出做种的Peer与请求文件下载的Peer
同时,下载到一半的数据也可以被Peer加载做种
在命令行执行以下命令:(均在demo文件夹下)
cd seed
python3 seed_client.py
cd c2
python3 test2_client.py
可启动多个客户端,启动截图:
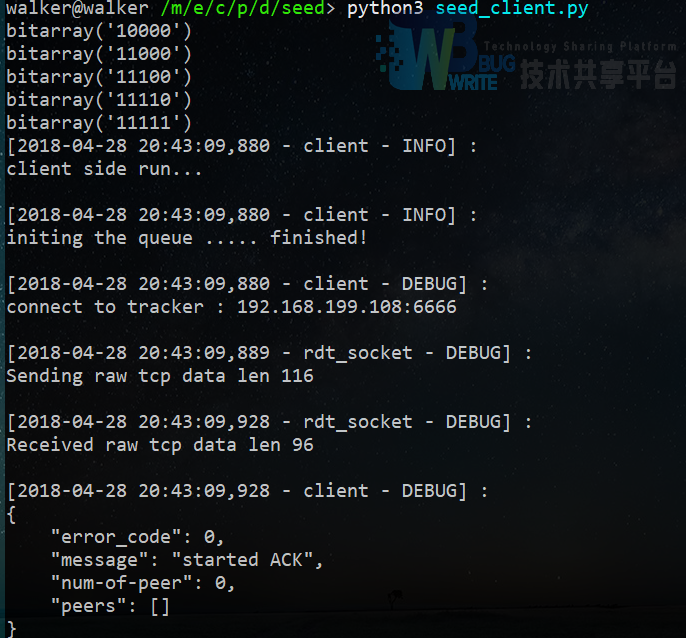
4.5 实验结果说明
使用该Bittorrent客户端,完成了以下测试。
-
一个有完整数据的 Peer 给 多个 Peer 发送文件
-
一个没有数据的 Peer 向 多个 有完整数据的 Peer 请求文件
-
多个 Peer 相互请求文件
- 每一个 Peer 都有部分数据,保证全部 Peer 拥有的数据块完整
- 通过多线程技术,每一个 Peer 在请求数据块的时候发送已有数据块
- 每一个 Peer 都能够获得完整文件
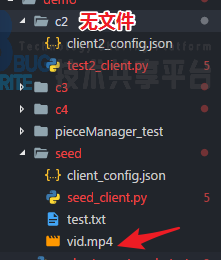
4.5.1 测试一:发文件
客户端已有文件
vid.mp4
.
启动做种Peer:
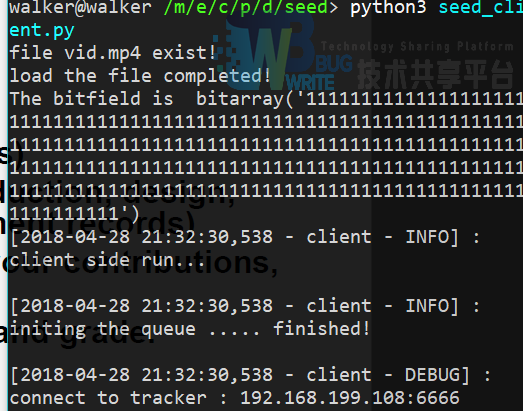


约花费了245.59s。
4.5.2 测试二:Peer3 同时向Peer1、Peer2请求文件
在上次测试中我们发现使用约7MB的文件测试时间过长,这次我们使用大小为109kb的文件进行测试。
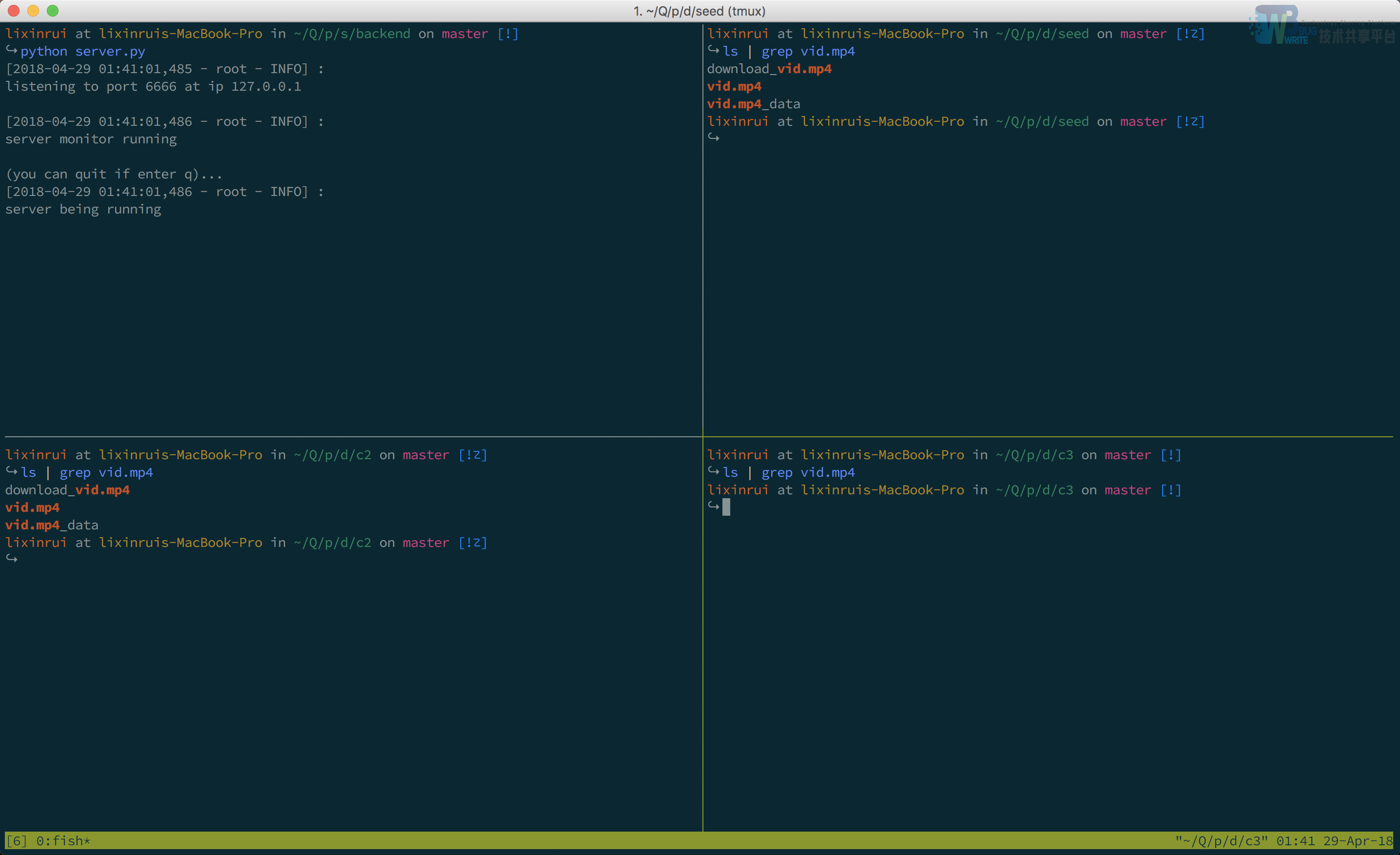
如下图所示,我将终端分为4个窗口,左上角是Tracker服务器,正在运行中。右上,左下分别是Peer1、Peer2。我在这三个窗口分别执行了ls | grep vid.mp4指令,确认了这两个Peer均有完整的该文件。右下是Peer3,它没有该文件。
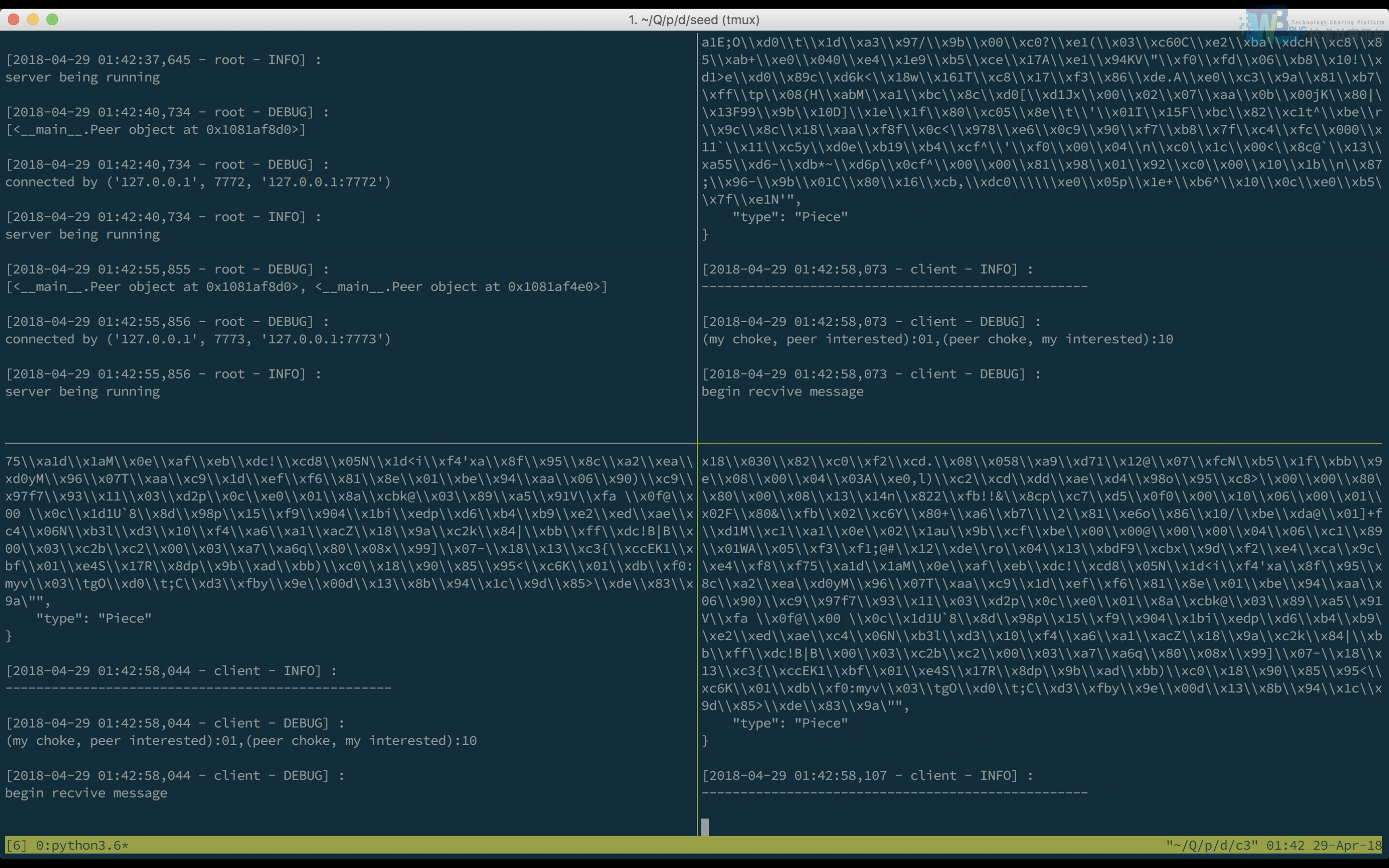
接下来执行Peer3,发现Peer1和Peer2的窗口中均有响应,正在向Peer3发送文件。
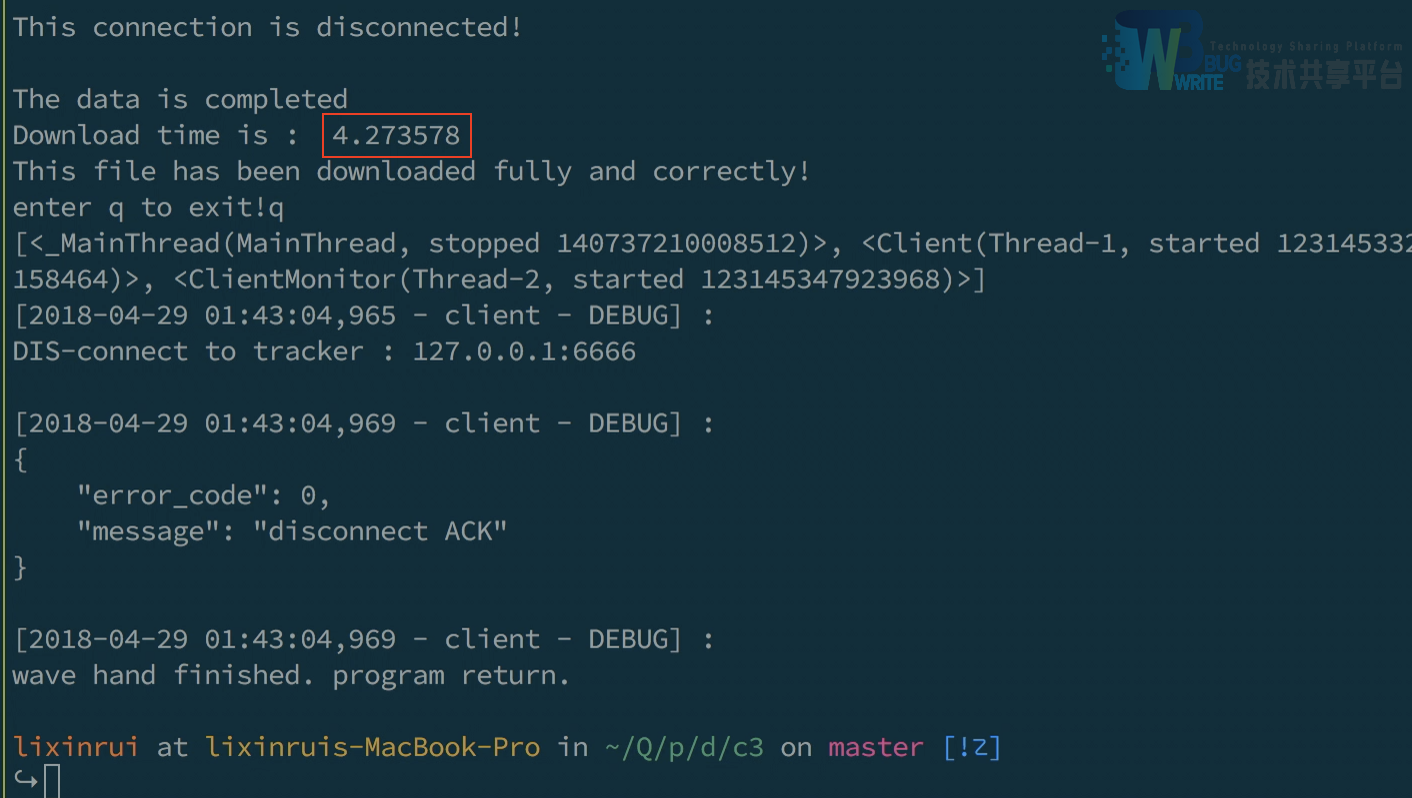
最终Peer3获得完整的文件,共耗时4.27秒。
五、性能比较
C/S模式中,我们使用7191359bytes(7.1Mb)的文件进行测试,三次测试结果分别是12.900446s、13.298574s、13.488140s。平均时间为13.2291s,平均信道容量为4.1474 mbps。
另外由上面的P2P测试可知,对应一个做种一个接受的速度为25kbs。可见速度还慢了许多,我们初步分析,这是由于P2P由于使用了大量多线程机制,然而在Python的全局线程锁的限制下,它是交替地(并发)而非同时(并行)地向多个Peer请求数据。为了验证这一结果,我测试了6个Peer向一个Peer同时发送文件,速度没有加快。我们看到右下角窗口中,获取文件的时间仍然是4秒多,而且还有7%的增长。

参考文献
- 基于区块链的安全通信平台(福州大学·刘炜烽)
- P2P视频点播系统优化研究与实现(华南理工大学·陈新新)
- 基于J2EE的远程网络教育系统研究与实现(电子科技大学·陈南荪)
- 基于MPLS/VPN及PKI体系的统一数据交换平台设计与实现(电子科技大学·陈跃斌)
- 汽车P2P借贷系统设计与实现(苏州大学·周桐)
- 基于PHP+MySQL的交互学习系统的设计与实现(吉林大学·刘博)
- 金融信贷背景下分布式信息采集策略研究(南京大学·王涛)
- 基于区块链的安全通信平台(福州大学·刘炜烽)
- P2P借贷平台的研究与设计(吉林大学·关海啸)
- 基于J2EE的协作式学习系统的研究与开发(曲阜师范大学·高玮)
- 基于CSCW的油田开发方案设计平台的研究与实现(大庆石油学院·刘亚姝)
- 基于J2EE的协作式学习系统的研究与开发(曲阜师范大学·高玮)
- P2P借贷系统的交易模块的设计与实现(南京大学·林智灵)
- 基于PHP+MySQL的交互学习系统的设计与实现(吉林大学·刘博)
- 基于.NET框架的Web数据库访问技术的研究与实现(武汉理工大学·希凡)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码客栈网 ,原文地址:https://m.bishedaima.com/yuanma/35472.html









