
python实现的面向推荐系统的数据挖掘
摘 要
信息化世界存在着大量的数据,如何在大量的数据中为每一个用户找到其所需求的数据 成为了一个问题。本文尝试以包括基于用户的协同过滤算法、基于物品的协同过滤算法以及其混合算法在内的多种不同的推荐算法对于数据进行挖掘分析,并在此过程中尝试对于推荐系统的实现提出一个行之有效的解决方法。
1 综述
1.1 数据集
本实验采用的数据集使用了 Jester 数据集作为所有算法的训练和测试数据集。Jester是一个为研究而开发的笑话推荐系统,使用的数据集中的数据则是次系统获取的真实用户数据。
数据集包含 3 个文件,共包含 73421 个用户对于 100 个笑话的评分数据。数据为 xls 格式,每一行有 101 个数据,第一个为用户评价过的笑话个数,剩下的 100 个为用户对于 100 个笑话的评分,评分为 -10~10 之间的实数,99 表示 “null”,即未打分。数据集的 5, 7, 8, 13, 15, 16, 17, 18, 19, 20 是密集的,几乎所用的用户都给这些笑话打分过。
1.2 算法
本次实验采用多种不同的算法并将其结果进行对比。采用的算法包括基于用户的协同过滤算法、基于物品的协同过滤算法等方法。
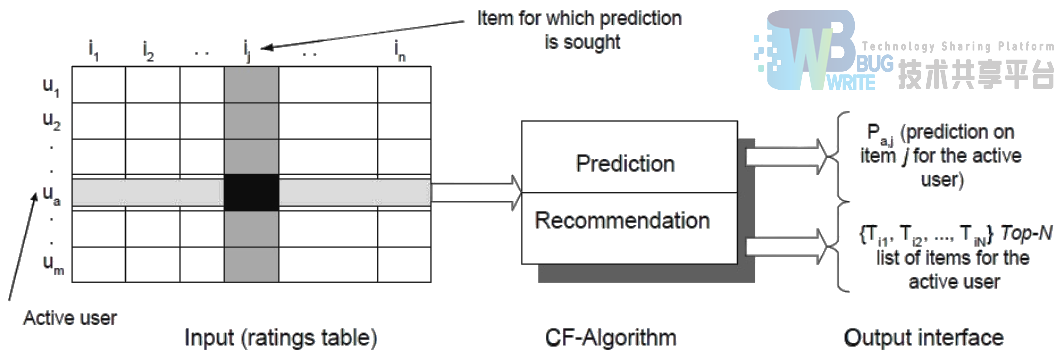
如图1所示,在协同过滤算法中,用 m×n 的矩阵表示用户对物品的喜好情况,一般用打分表示用户对物品的喜好程度,分数越高表示越喜欢这个物品。图中行表示用户,列表示物品,Uij 表示用户 i 对物品 j 的打分情况。协同过滤分为两个过程:预测过程和推荐过程。预测过程是预测用户对没有购买过的物品的可能打分值,推荐是根据预测阶段的结果推荐用户最可能喜欢的一个或多个物品。
1.2.1 基于用户的协同过滤算法
基于用户的协同过滤算法通过用户的历史行为数据发现用户对商品或内容的偏好,并对这些偏好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。如图2所示,如果用户 1、用户 3 两个用户都对于物品 2 和物品 3 显示出偏好,并且评价较高,那么用户 1 和用户 3 就属于同一类用户,可以将用户 1 偏好的物品 4 也推荐给用户 3。这里仅是一个简单的例子。在实际的应用过程中还要考虑偏好的程度,同一类用户的人数以及偏好物品的个数等多方面的因素。
简而言之,基于用户的协同过滤算法主要分为 2 个步骤:
-
寻找相似的用户集合
-
寻找集合中用户喜欢的且目标用户没有的进行推荐

然而,基于用户的协同过滤算法存在两大问题:
-
数据较为稀疏,往往在一个系统中有非常多的物品,而用户偏好的物品数量很少,购买相同物品的用户不够密集,导致无法找到一个用户的邻居进行推荐
-
算法的可扩展性较低,随着用户和物品数量的增加,为所有用户推荐所需时间呈几何模式增加,这往往是一个系统所不能接受的
1.2.2 基于物品的协同过滤算法
与基于用户的协同过滤不同,基于物品的协同过滤根据所有的用户偏好计算物品之间的相似度,并把相似的物品推荐给用户。仍以图2为例,推荐物品 2 和物品 3 的人群相似,因此这两个商品相似,在用户 2 选择物品 2 时就可以推荐较为相似的物品 3。
由于物品间的相似性比较固定,因此可以预先计算不同物品之间的相似度,在性能上较优于基于用户的协同过滤算法。简而言之,基于物品的协同过滤算法分为 2 步:
-
计算物品之间的相似度
-
根据物品之间的相似度以及用户历史行为给用户生成推荐列表
上述为不同算法的概述,具体的算法实现见第3节。
2 数据预处理
由于原数据使用 99 表示用户未平分,而这样的数据在计算时会带来较大的不便,因此在预处理时首先将这些数据置为 0,相当于用户在进行 -10~10 的连续打分中给这些数据打分为 0。可以证明,进行如此的预处理之后在进行各种距离计算时与忽略掉这些数据的结果是一致的,也就是说可以令其直接参与计算而不影响结果。
此外,在使用第三组数据作为训练数据集时,可以考虑预先剔除只给一个物品打分的用 户,因为在计算推荐物品时这些用户不可能作出贡献(不可能选择此用户偏好的其他物品进行推荐)。
3 推荐算法实现
3.1 基于用户的协同过滤
3.1.1 计算用户相似度
要实现基于用户的协同过滤算法,首先要进行计算的是用户间的相似度。计算用户的相似度主要有 4 种方法:Jaccard 距离、皮尔逊相关系数、闵可夫斯基距离以及余弦距离。其定义分别如下:
- Jaccard 系数主要用于计算布尔度量的个体间相似度,当个体的特征均使用布尔值进行度量时,无法衡量具体的差异大小,只能获得个体间的特征是否一致,其公式如下:
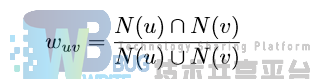
其中,wuv 为两个个体之间的相似度,N(u) 和 N(v) 分别为 u 和 v 所具有的属性。
- 皮尔逊相关系数是比欧几里德距离更加复杂的可以判断人们兴趣相似度的一种方法。它在数据不是很规范时,会倾向于给出更好的结果。其计算方法如下:
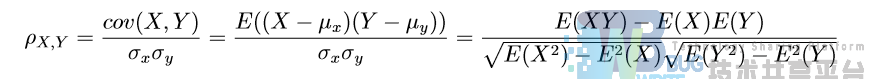
其中 E 为数学期望,cov 为协方差。
- 两个点 X 和 Y 之间的闵可夫斯基距离定义为:

p 取 1 或 2 时的闵氏距离是最为常用的,p = 2 即为欧氏距离,而 p = 1 时则为曼哈顿 距离。当 p →∞ 时的极限情况下,可以得到切比雪夫距离:
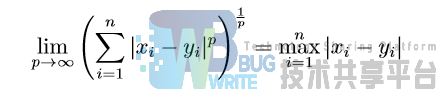
- 余弦距离,也称为余弦相似度,是用向量空间中两个向量余弦值作为衡量两个个体间差异大小的度量值。欧几里德距离相似,点 X、Y 的余弦距离表示为:

在本实验中,由于物品的打分为连续的,为了尽可能的将打分考虑进取以及便于计算,采用余弦距离作为衡量用户之间距离的标准。
3.1.2 推荐算法
这里选用了余弦距离作为距离计算方法后,对于任意一个用户 u,选取与之 k 个用户,用集合 S(u,k) 表示,并将 S 中所有用户喜欢的物品提取出来,去除目标用户 u 已经喜欢的物品。然后对余下的物品进行评分与相似度加权,得到的结果进行排序。最后由排序结果对目标用户 u 进行推荐。其中,对于每个可能推荐的物品 i,预测的用户 u 对其的感兴趣的程度可以用如下公式计算:

其中,N(i) 为对于物品 i 打分的用户集合,rvi 为用户 v 对于 i 的打分,而 wuv 为用户 u 和用户 v 之间的相似程度。
具体的推荐算法如下,传入的参数中,item 为被推荐用户已选物品, table 为训练数据, k 为最近邻居数。

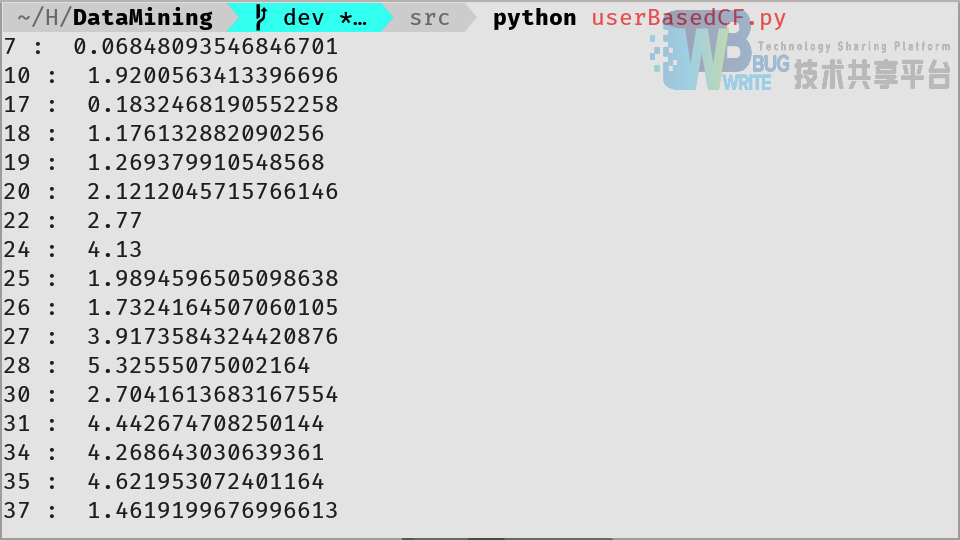
在这一算法下,基于训练数据集 1 的一个可能的推荐列表如图3所示,其中包含了这一用户所没有购买的商品推荐及其预测打分(在最终输出中这些分数不会显示,只显示正确率)。
3.2 基于物品的协同过滤
3.2.1 计算物品相似度
基于物品的协同过滤相似度计算方法与基于用户的类似,只不过其对象变为了物品,而评估相似度的指标变为了对两个物品进行打分的用户组的相似度。同样,在本实验的相似度计算中采用余弦相似度作为相似度的计算方法。
3.2.2 推荐算法
与基于用户的推荐算法不同,由于本数据集中的物品较少(100 个),因此可以先计算物品-物品相似度表,然后通过这一相似度表进行推荐。而对于物品的分数预测方法如下:
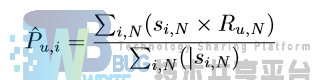
其中 si,N 为物品 i 与物品 N 的相似度,Ru,N 为用户 u 对于物品 N 的打分。此时,基于用户的推荐算法如下,输入参数中 items 为用户已经打分的物品,而 distance 为预先计算好的物品相似度表:

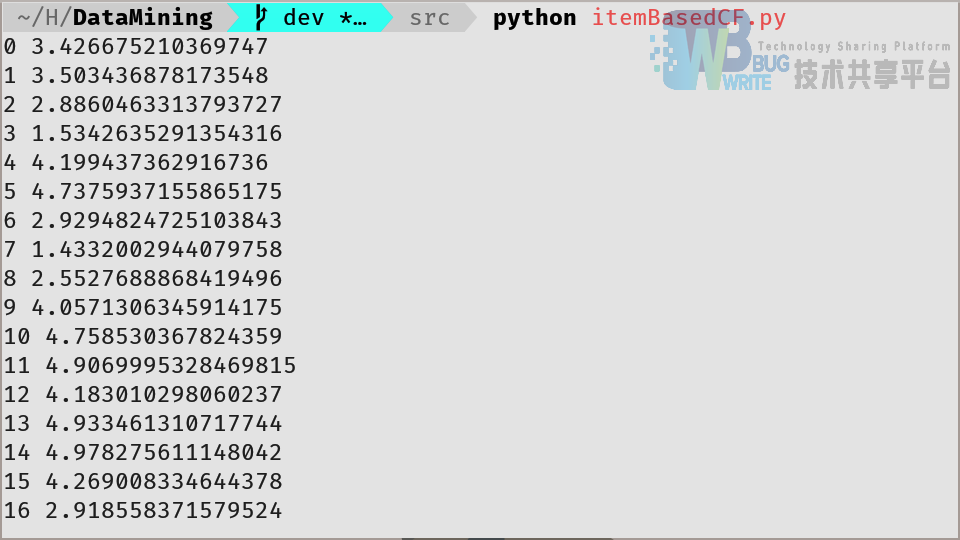
完成算法后,对于随机的一个用户运行程序,得到的输出如图4所示,由于基于物品的协同过滤是对于未选择的物品按序计算的,因此也是按序输出的。
4 算法测试与结果评估
4.1 评价指标
要进行完整的测试,需要知道用于评价算法的各个指标。通常而言,用于评价的指标包括:
-
准确率 :准确率就是最终的推荐列表中正确的推荐所占有的比例
-
召回率 :正确的推荐占全局的比例
-
覆盖率 :表示推荐的物品占了物品全集空间的比例
-
新颖度 :新颖度是为了推荐长尾区间的物品,用推荐列表中物品的平均流行度度量推荐结果的新颖度。如果推荐出的物品都很热门,说明推荐的新颖度较低,否则说明推荐结果比较新颖。
而对于本实验而言,由于打分是连续的,不能简单的判断推荐是否 “正确”,因此需要使 用其他的方法进行判断。为了能够尽可能准确地评价此推荐系统的准确程度,采用 NMAE (Normalized Mean Absolute Error)对于结果进行评价。从 Jester 数据网站可以得知随机推荐的 NMAE 约为 33%,而 Jester 所使用的 Egintaste 协同过滤算法的准确度为 20%(2000 年), 以此为基准可以度量本实验所实现的算法的准确性。
(原文:many papers, including ours, report Normalized Mean Absolute Error (NMAE) rates of approx 20%. How good is this compared with random guessing? In the Appendix to our paper, we show that if user ratings are uniformly distributed, random guessing yields NMAE = 33%.)
除了准确性指标,还需要考虑性能问题,由于基于用户的推荐算法所需要比较的用户数量较多,因此进行推荐的性能可能较差。在这个实验中,通过比较推荐所需的时间(不包含读取与预处理数据的时间)来对于性能进行评估。最终使用的评估算法如下:

其中,Recommend 过程分别选用随机推荐、基于用户的协同过滤以及基于物品的协同过滤以进行比较。
4.2 评估过程
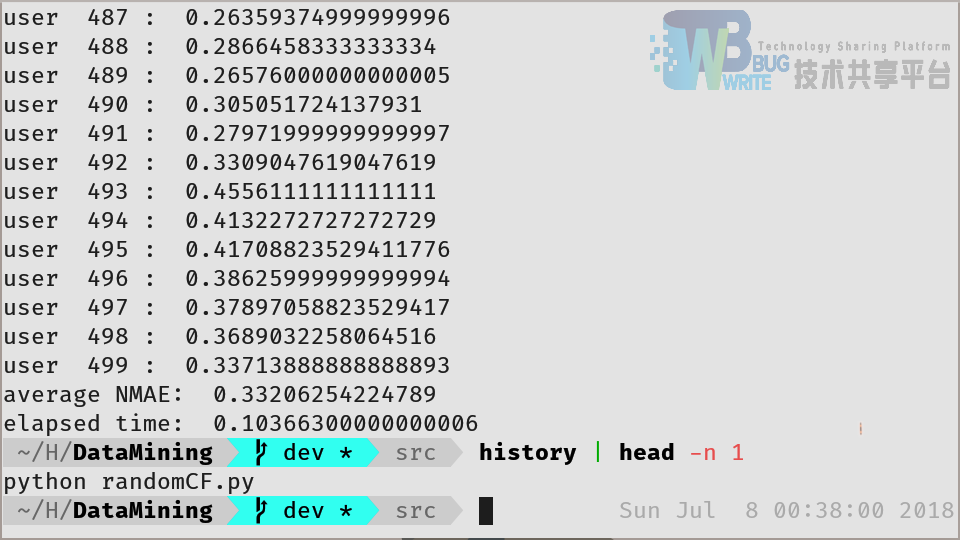
在 =500 的条件下进行测试首先进行随机推荐测试,运行 randomCF 进行推荐,其结果如图5所示,可以看出,NMAE 为 33.20%,多次统计结果均在 32%~34% 之间,由此可以验证上述的 “随机推荐 NMAE 为 33%” 这一基准。同时,可以得知使用随机推荐处理 1000 个用户所需要的时间为 0.1 秒。
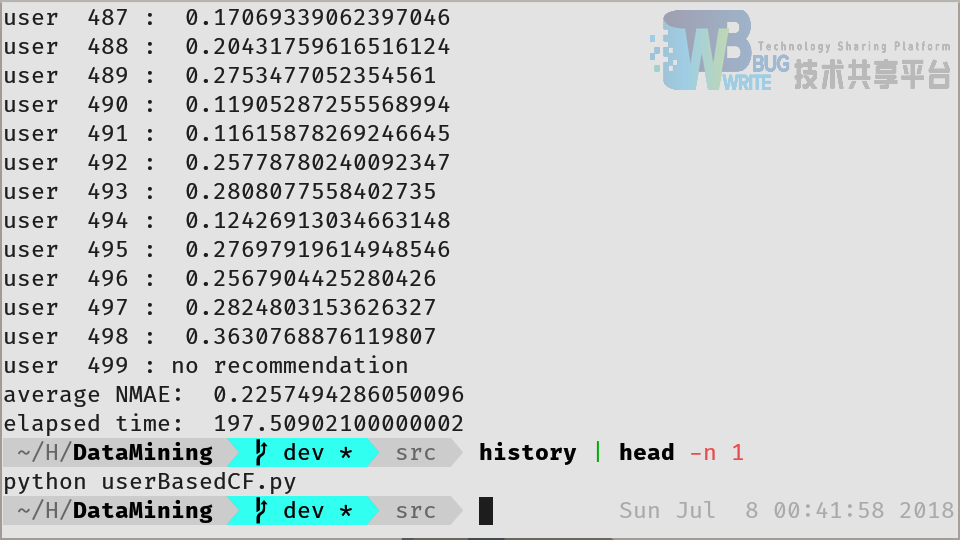
接下来,对于基于用户的协同过滤进行测试,测试在同样的条件下进行(输入数据与测试数据相同),在计算相邻用户时取 k = 10,结果如图6所示。从图中可以看出,推荐的 NMAE 为 22.57% 明显优于随机推荐的 33%,但相比于 Egintaste 算法的 20% 还有较大的改进空间。基于用户的协同过滤用时为 197.5 秒,约为随机推荐算法的 1975 倍,说明在用户基数较大时,此算法较为低效。同时,可以看出如对于第 499 个用户进行推荐时,不能找到有效的推荐,这说明此用户的偏好与其他用户重叠较低,这也是基于用户的协同过滤算法的弊端之一。
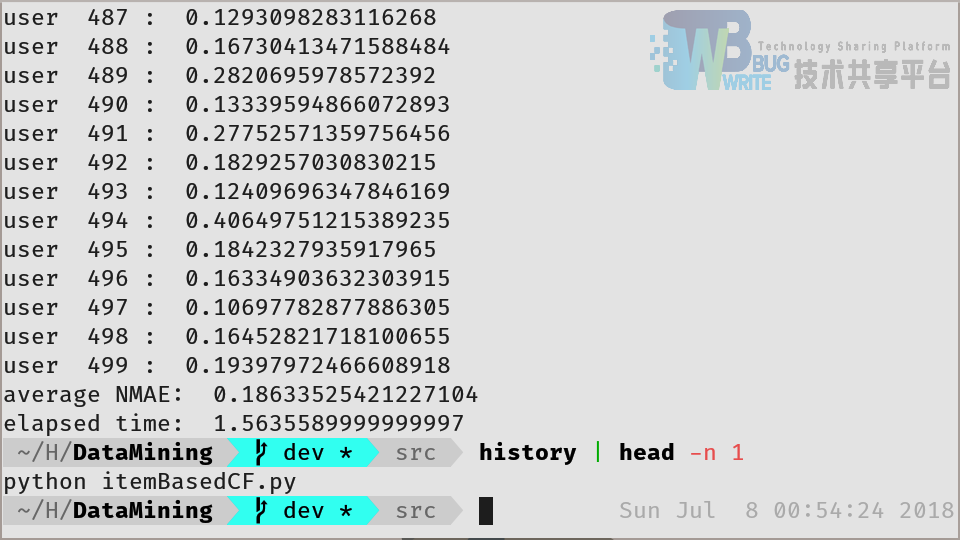
最后,对于基于物品的协同过滤进行测试,测试结果如图7所示,从图中可以看出,对于 500 个用户推荐仅用时 1.65 秒,这需要归功于预先建立的物品相似度表。由于此测试数据集的物品较少(只有 100 件),因而建立的物品相似度表的规模较小。在如电商网站等物品规模持续增大的数据集中,需要采取其他的方法以减少计算的时间。
从图中可以看出,平均 NAME 达到了 18.63,远优于基于用户的协同过滤。同时,由于是计算物品之间的相似度,因此不存在没有近邻而导致的不能推荐的情况,这也可以说明,在这一数据集下,基于物品的协同过滤的整体效果要好于基于用户的协同过滤。
4.3 评估结果
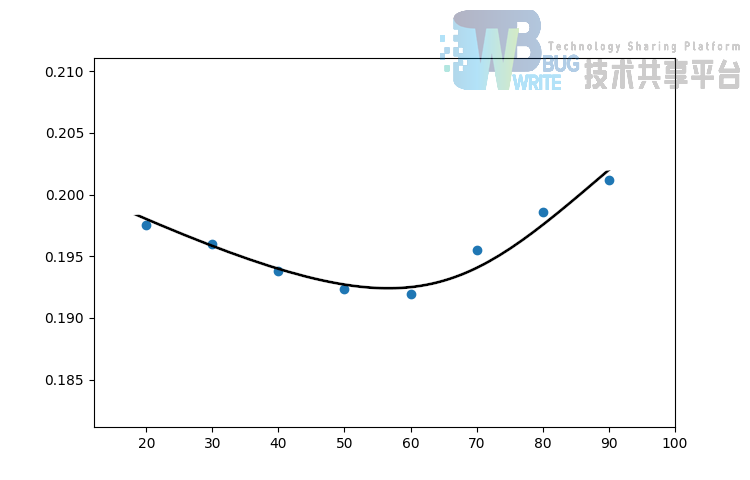
除了上述对于基于用户的协同过滤与基于物品的协同过滤的对比外,还需要对于不同的 初始值进行计算以评估准确性随着用户已经打过的打分个数的变化。如图8所示,此图使用 itemCF 中的 trend 函数生成。其中,横轴为测试样例中已知部分的比例。如 x = 10 表示已知用户为前 10 个物品的打分,预测后 90 个物品的打分,而纵轴为平均 NMAE。使用同样的 500 个样例进行测试。可以发现,在已知打分的占比为 50%~60% 时预测的准确度最高。
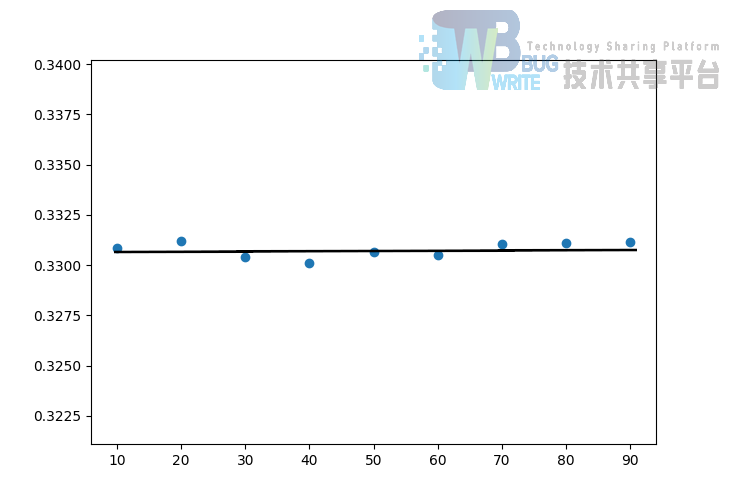
而对于随机推荐而言,其准确率并不随已知的打分占比明显变化,如图9所示,平均NMAE 一直稳定在约 33% 的位置。这也与预想的结果一致。将此结果与基于物品的协同过滤结果进行对比,说明已知用户偏好占全部物品的比例小于 50% 时预测的准确率呈增加趋势,而大于 50% 时呈减少趋势。在实际的应用中,用户观察并评价的物品数一般小于总物品数的 50%,那么在这个区间内,用户评价的越多,推荐就越准确,这也是符合直觉的。然而在物品数较少的情况下就需要考虑当用户评价的物品数占比过大时的 “过拟合” 状态。此外,从图中可以看到,即使用户的评价很少,NMAE 也可以维持在 20% 上下,这一结果依旧是十分不错的。
对于基于用户的随机推荐而言,由于计算所花费的时间过长,因此未能生成 NMAE 岁已知打分比例的变化图,不过根据推测,其趋势应与基于物品的推荐一致。
5 结语
本实验对于 Jester 数据集实现了基于用户的协同过滤算法以及基于物品的协同过滤算法, 并将其与随机推荐进行比较,同时在基于物品的协同过滤算法上达到了较好的准确性以及性能。
从实验中可以总结,基于用户的协同过滤算法的特点是:
-
用户较少的场合,否则用户相似度矩阵计算代价很大
-
适合时效性较强,用户个性化兴趣不太明显的领域
-
对新用户不友好,对新物品友好,因为用户相似度矩阵不能实时计算
-
很难提供令用户信服的推荐解释
对应地,基于物品的协同过滤算法的特点有:
-
适用于物品数明显小于用户数的场合,否则物品相似度矩阵计算代价很大
-
适合物品丰富,用户个性化需求强的领域
-
对新用户友好,对新物品不友好,因为物品相似度矩阵不需要很强的实时性
-
利用用户历史行为做推荐解释,比较令用户信服
与其他优秀的推荐算法相比(如 egintaste、混合算法、基于知识的推荐、基于模型的协同过滤等),本实验中实现的基于物品的协同过滤算法已经达到了较好的效果,但是仍然有较大的改进空间,这主要体现在计算所需要花费的时间上。由于计算各个用户以及各个物品之间的逻辑关联性很小,因此此算法有极大的可并行性,若充分利用多核服务器的并行性能,则能够很好的缩短计算所需要的时间。
参考文献
- 基于子兴趣分解的神经协同过滤方法(太原理工大学·付泽润)
- 网格数据挖掘平台服务推荐系统研究(天津大学·刘伟)
- 电子商务网站个性化推荐技术研究与实现(华侨大学·李影)
- 数据挖掘在电子商务推荐系统中的应用(哈尔滨工程大学·张秀娟)
- 基于Spark的混合推荐电影系统的设计与实现(广东工业大学·李强)
- 基于Web使用挖掘的在线报名推荐系统的研究与实现(电子科技大学·王玥)
- 推荐系统中多源信息融合和隐式反馈挖掘的研究(南京大学·胡光能)
- 基于Web使用挖掘的在线报名推荐系统的研究与实现(电子科技大学·王玥)
- 面向推荐系统的数据稀疏问题研究(吉林大学·潘强强)
- 基于社交网络图挖掘的深度推荐算法研究(吉林大学·王宁)
- 基于Spark的混合推荐电影系统的设计与实现(广东工业大学·李强)
- 基于中小型电商平台的个性化推荐系统建模(华北电力大学(北京)·梁德祥)
- 基于Web数据挖掘的电子商务推荐系统研究(同济大学·裴蕾)
- 基于在线评论的个性化推荐系统(电子科技大学·李君)
- 基于Web数据挖掘的电子商务推荐系统研究(电子科技大学·张高准)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设助手 ,原文地址:https://m.bishedaima.com/yuanma/35478.html









