基于python构建搜索引擎系列——(一)简介
我们上网用得最多的一项服务应该是搜索,不管大事小情,都喜欢百度一下或谷歌一下,那么百度和谷歌是怎样从浩瀚的网络世界中快速找到你想要的信息呢,这就是搜索引擎的艺术,属于信息检索的范畴。
这学期学习了《现代信息检索》课程,使用的是Stanford的教材Introduction to Information Retrieval,网上有电子版,大家可以参考。
本课程的大作业是完成一个新闻搜索引擎,要求是这样的:定向采集3-4个新闻网站,实现这些网站信息的抽取、索引和检索。网页数目不少于10万条。能按相关度、时间和热度(需要自己定义)进行排序,能实现相似新闻的自动聚类。
截止日期12月31日,我们已经在规定时间完成了该系统,自认为检索效果不错,所以在此把过程记录如下,欢迎讨论。
网上有很多开源的全文搜索引擎,比如Lucene、Sphinx、Whoosh等,都提供了很好的API,开发者只需要调用相关接口就可以实现一个全功能的搜索引擎。不过既然学习了IR这门课,自然要把相关技术实践一下,所以我们打算自己实现一个搜索引擎。
这是简介部分,主要介绍整个搜索引擎的思路和框架。
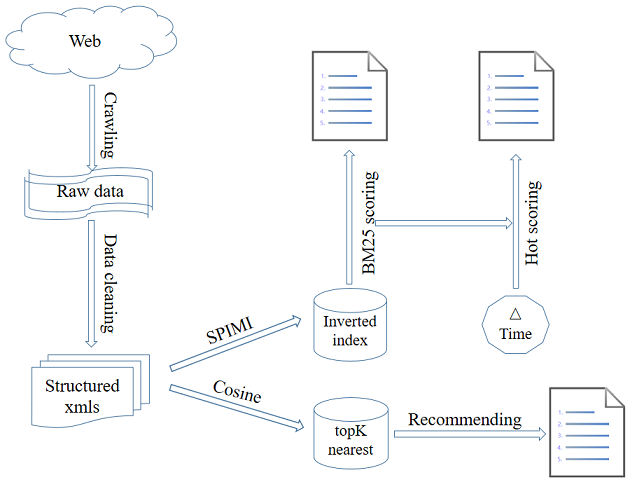
上图为本搜索引擎的框架图。首先爬虫程序从特定的几个新闻网站抓取新闻数据,然后过滤网页中的图片、视频、广告等无关元素,抽取新闻的主体内容,得到结构化的xml数据。然后一方面使用内存式单遍扫描索引构建方法(SPIMI)构建倒排索引,供检索模型使用;另一方面根据向量空间模型计算两两新闻之间的余弦相似度,供推荐模块使用。最后利用概率检索模型中的BM25公式计算给定关键词下的文档相关性评分,BM25打分结合时间因素得到热度评分,根据评分给出排序结果。
在后续博文中,我会详细介绍每个部分的实现。
使用方法
-
安装python 3.4+环境
-
安装lxml html解析器,命令为
pip install lxml -
安装jieba分词组件,命令为
pip install jieba -
安装Flask Web框架,命令为
pip install Flask -
进入web文件夹,运行main.py文件
-
打开浏览器,访问 http://127.0.0.1:5000 输入关键词开始测试
如果想抓取最新新闻数据并构建索引,一键运行
./code/setup.py
,再按上面的方法测试。
本文转载自:http://bitjoy.net/2016/01/04/introduction-to-building-a-search-engine-1
参考文献
- 分布式Web Crawler系统研究与实现(江西理工大学·胡炜)
- 基于Lucene的中英文文档全文搜索引擎(电子科技大学·张瑞)
- 分布式Web Crawler系统研究与实现(江西理工大学·胡炜)
- 基于领域的网络爬虫技术的研究与实现(武汉理工大学·谭龙远)
- 基于网络爬虫的搜索引擎的设计与实现(湖北工业大学·冯丹)
- 基于Lucene的商品垂直搜索引擎研究与实现(东华大学·潘磊宁)
- 校园网有害信息监测系统设计与实现(西南交通大学·杨亚群)
- 个性化资讯推荐系统的设计与实现(山东大学·仵贇)
- 垂直搜索引擎爬虫系统的研究与实现(贵州大学·吴建强)
- 垂直搜索引擎爬虫系统的研究与实现(贵州大学·吴建强)
- 面向商品的垂直搜索系统的设计与实现(北京交通大学·王海涛)
- 基于Lucene的中英文文档全文搜索引擎(电子科技大学·张瑞)
- 基于Lucene技术搜索引擎设计与实现(吉林大学·张阳)
- 基于元搜索的Web信息搜索技术研究(吉林大学·张春磊)
- 基于Web Service的企业搜索引擎的架构及优化(吉林大学·吴学义)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕业设计货栈 ,原文地址:https://m.bishedaima.com/yuanma/35582.html