
一、前言
1.1 实践目的和要求
1.1.1 实习目的:
以程序设计语言系列课程所涉及的编程技能为基础,融合软件工程系列课程中的软件工程理论和软件工程方法,结合专业系列课程所涉及的专业领域知识,使学生进行系统化、综合性的软件开发实践。
目的在于强化学生对实践涉及的专业技术知识的理解,掌握专业领域中软件知识的应用方法,了解其发展趋势,培养学生对软件工程方法在具体行业领域的实际应用能力。
主要任务是培养学生利用软件工程方法分析、设计并完成具体行业软件开发的能力,同时也培养学生的自我学习能力、调查研究能力、团队协作能力以及独立解决复杂工程问题的能力和创新意识,最终使学生具备终身学并适应软件产业持续发展的能力。
1.2 实践项目背景及意义(介绍项目背景和意义)
随着计算机技术的发展,“中国正迎来从 IT 时代到 DT 时代的变革”。在蓬勃发展的大数据时代,越来越多的企事业单位认识到数据的重要性,并通过各种手段进行数据的搜集。其中的“网络爬虫”技术是当下比较流行的获取万维网公开数据的一种手段。
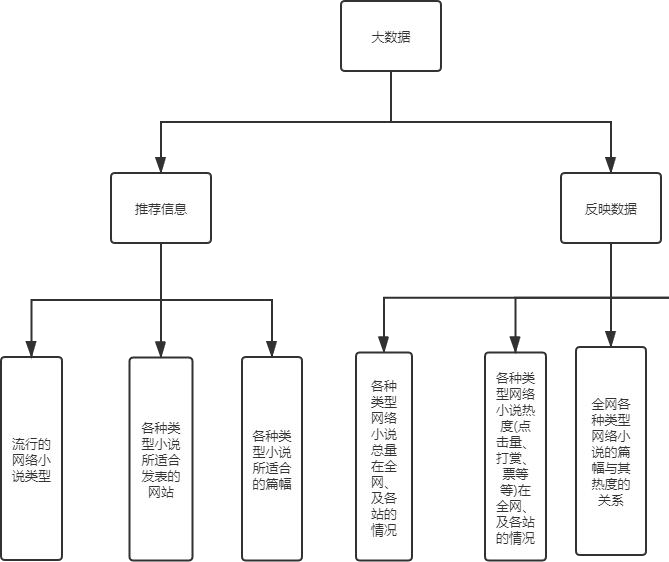
本项目旨在构建一个系统。系统的用户主要是新入行的网络小说作者。系统通过爬取小说网站的小说信息,并进行数据处理和分析,可以给用户推荐当前比较流行的网络小说类型、各种类型小说所适合发表的网站、及各种类型小说所适合的篇幅。系统主要反映的数据有“各种类型网络小说总量在全网、及各站的情况”、“各种类型网络小说热度(点击量、打赏、票等)在全网、及各站的情况”和“全网各种类型网络小说的篇幅与其热度的关系”。用户可根据从系统获取的结果来计划更加适合自己未来的写作方案。
二、实践内容
2.1实践过程(概述实践各阶段所从事的主要工作等)
-
第一周:根据指导教师介绍的项目背景及应用需求,学生查阅课题相关资料,撰写需求分析报告(系统需求说明书)。同时复习项目相关专业知识。
-
第二周:根据需求分析报告,对系统进行总体设计;划分系统功能模块,选择系统的实现技术方案,同时撰写系统设计报告(系统概要说明书)。
-
第三周:根据系统概要说明书进行系统详细设计和实现。运用选定的软件平台和开发工具对各功能模块进行设计和实现。(要求撰写详细设计说明书)。
-
第四周:整合各功能模块,对系统进行联调,并根据系统设计指标进行系统测试,最终完成整个软件系统程序的开发;提交设计报告文档,并进行成果展示和答辩。
2.2实践内容(包括项目介绍、本人从事的工作、软硬件平台和技术等) 项目:基于大数据的数据分析与处理系统
2.2.1 系统需求
①系统主要目的:
-
系统的用户主要是新入行的网络小说作者。
-
系统可以给用户推荐:
-
当前比较流行的网络小说类型;
-
各种类型小说所适合发表的网站;
-
及各种类型小说所适合的篇幅。
系统主要反映的数据:
-
各种类型网络小说总量在全网、及各站的情况
-
各种类型网络小说热度(点击量、打赏、票等等)在全网、及各站的情况
-
全网各种类型网络小说的篇幅与其热度的关系。
特别说明:系统只爬取“起点”、“晋江”、“飞卢”三个网站作为示例。
②系统应该完成的具体内容:
数据的获取:
用爬虫获取三个网站的数据(详细数据格式参见数据库格式)
数据的清洗:
-
处理重复的、不完整的、异常的数据
-
将三个网站的数据的格式统一
-
数据持久化存储
数据分析:
“各种类型网络小说总量在全网、及各站的情况”
获取各类总量并用饼状图显示。
变量一:小说类型
变量二:对应总量
“各种类型网络小说热度(点击量、打赏、票等等)在全网、及各站的情况”
获取各类对应的热度(点击量、打赏、票等等)并用直方图显示
横坐标:小说类型纵坐标:对应热度
“全网各种类型网络小说的篇幅与其热度的关系。”
数据挖掘:
推荐全网热度最高的小说类型;
推荐各站热度最高的小说类型;
推荐各类小说适合发表的网站;
推荐各类小说适合的篇幅;
数据的显示:
*显示平台:Java Web
*结果列表:
-
全网及各站的分类热度排名
-
各种类型小说所适合发表的网站各种类型小说所适合的篇幅
其它注意事项:
- 散点图
先选择网站,再选择分类,将此网站该分类下的所有小说显示,每个小说相当于一个点,从 而拟合出曲线或聚点。在后端处理时,要将只有几千字就弃坑了的那种小说筛掉。
纵坐标要能够选择显示内容,如起点只能选择推荐票,飞卢可以选择鲜花、点击数、打赏、 月票,晋江为积分、礼物、收藏数、书评数
- 直方图
选择网站,动态生成该网站每个分类的热度,分类的热度由特定算法实现,热度应当与字数 成反比,而与成绩性质数据成正比。
返回数据如:
[
{‘科幻’:2000},
{‘玄幻’:3000},
{‘轻小说’:4000},
{‘仙侠’:5000}
]
- 饼状图
选择小说类型,生成各个网站在此分类小说的市场占有量,不只是数量,与字数、人气等也 要相关。
- 输入作者名,获得此作者所有小说加起来的各种数据。

2.2.2系统框图
2.3项目相关技术
-
Java 面向对象编程
-
Springboot 项目的编写C、Python 编程基础
-
mysql 数据库管理系统的使用
-
Python 中 requests、beautifulsoup、pymysql、pandas 等模块的使用
2.4主要成果
(具体列出自己所完成的主要成果。包括界面、计算结果、图表、结果分析、关键程序代码等)
程序的结果和分析详情参考 2.2,此处不再赘述,如下是主要代码:
PYTHON 脚本:
```c++ return cursor.fetchall() except Exception: print(Exception) def fun(a,url,yuanBookId):#a:数据库连接对象 url:小说地址html=requests.get(url)#获取网页内容#fo=open('1.html','w')
fo.write(r.text)
soup=BeautifulSoup(html.text,'html.parser')#解析网页脚本 def get_t(string):#根据选择器标示获取对应文本s=soup.select(string) if len(s)>0: return s[0].get_text() return '' ''' ```
爬取小说名
c++
'''
novelName=get_t('#novelName') print(novelName)
'''
爬取小说分类
c++
'''
Type=get_t('.C-One > span:nth-of-type(1) > span:nth-of-type(1) > a:nth-of-type(3)') print(Type)
'''
爬取小说标签
c++
'''
tags=soup.select('body > div.center > div.C-Two.bodyBorderShadow > div.Two-Right > div.T-R-Top > div.T-RT-Box2 > div:nth-of-type(6)')
_tags=''
if len(tags)>0: array=tags[0].get_text().split('\n')[1:-1]
_tags='|'.join(array) print(_tags)
'''
爬取小说开更时间
c++
'''
start_time=get_t('body > div.center > div.C-Two.bodyBorderShadow > div.Two-Right > div.T-R-Top > div.T-RT-Box2 > div:nth-of-type(5) > span > span')
print(start_time)
'''
爬取小说最近更新时间
c++
'''
end_time=get_t('body > div.center > div.C-Two.bodyBorderShadow > div.Two-Left > div.T-L-One > div.T-L-O-Z uo > div.T-L-O-Z-Box1 > span > span')
print(end_time)
'''
爬取小说月票
c++
'''
yuepiao=get_t('body > div.center > div.C-Three.mgTop20.bodyBorderShadow > div:nth-of-type(7) > div.C-ThrB1-Box3.colorQianlan')
print(yuepiao)
'''
爬取小说点击量
```c++ ''' dianji=get_t('body > div.center > div.C-Two.bodyBorderShadow > div.Two-Left > div.T-L-One > div.T-L-O-Zuo
div.T-L-O-Z-Box2.fs14 > span:nth-of-type(3) > span') print(dianji) ----------------------------------------data_wash.py--------------------------------------------------- ```
```c++ feilu.n_type[(feilu['n_type']=='女频言情')&(feilu['tag'].str.contains('明星'))]='女频同人'
In[17]:
print(jinjiang.n_type.value_counts())
In[18]:
qidian.n_type[qidian['type']=='短篇']='短篇'
In[19]:
In[8]:
In[9]:
```
参考文献
- 面向金融信息的主题爬虫研究与应用(哈尔滨工业大学·卜永忠)
- 主题网络爬虫的研究和实现(武汉理工大学·林捷)
- 基于页面分析的网络爬虫系统的设计与实现(华中科技大学·郝以珍)
- 基于标记模板的分布式网络爬虫系统的设计与实现(华中科技大学·杨林)
- 分布式书籍网络爬虫系统的设计与实现(西南交通大学·赵鹏程)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 支持AJAX的网络爬虫系统设计与实现(中国科学技术大学·曾伟辉)
- 分布式书籍网络爬虫系统的设计与实现(西南交通大学·赵鹏程)
- 基于页面分析的网络爬虫系统的设计与实现(华中科技大学·郝以珍)
- 复合规则驱动聚焦爬虫系统的设计与实现(哈尔滨工业大学·刘强)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 主题搜索引擎搜索策略的研究及算法设计(兰州大学·高庆芳)
- 轻量级分布式虚假信息爬虫的设计与实现(辽宁大学·韩昱)
- 基于网络爬虫的电影集成搜索系统设计与实现(江西农业大学·江沛)
- 复合规则驱动聚焦爬虫系统的设计与实现(哈尔滨工业大学·刘强)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设小屋 ,原文地址:https://m.bishedaima.com/yuanma/35684.html









