在推荐系统中引入 Serendipity 的算法研究
摘要 :
现今广泛使用的推荐算法所推荐的项目,往往出自于一个相对固定和狭窄的特征集合,因此忽略了用户兴趣的改变和对新鲜感的诉求。为了让用户有更好的用户体验,推荐系统应该考虑在准确率之外更加重要的衡量尺度,比如说新颖度、惊喜度、覆盖率、有效性等。这篇论文的核心是如何将推荐系统结合 serendipity 这个尺度。Serendipity 的定义是在一种轻松愉快的氛围中偶然发现让自己意想不到的物品,因此算法中融合了商品的属性特征 genre,评分越高的 genre 往往有着越低的 serendipity。算法代码是用带有科学计算包 numpy 的 pyhon 语言写成,并且在 100K MovieLens 数据集上进行测试,可以鉴别出在利用协同过滤算法推荐给用户的项目中,serendipity 较低的项目,进而提升推荐系统的用户体验。
关键词 :推荐系统;协同过滤;Serendipity
一、引言
传统的推荐系统的目的在于准确预测在用户还没有看过的物品中可能评分较高的物品,可是预测的准确性并不能完全反映推荐系统的好坏。随着经济发展,各种各样种类的商品出现在公众眼前,然而用户频繁接触的可能只是其中的一小部分,很多用户不常接触到但是有用的商品可能会给用户带来更多的惊喜感。因此近年来,推荐系统的研究核心已经转变为如何为用户推荐新颖度高而且有用的物品,在这篇论文中,我们会介绍在传统推荐算法中如何提升 serendipity,从而让用户更加满意。
1.1 研究背景
随着互联网的普及和信息技术的发展,我们已经到了一个信息膨胀的时代。在网络上呈现给我们的信息越来越多,找到有价值的信息反而变得越来越困难。在这样的现实背景下,推荐系统的出现给社会带来了积极正面的影响。一个好的推荐让用户在不刻意寻找的情况下发现有价值的信息,从而节省了用户大量的时间。因此推荐系统在各行各业都得到了广泛应用,如何提升推荐系统的性能是专家学者亟待研究的问题。
1.2 现有成果
信息过滤是一种移除用户不想要的信息进而为用户呈现有用且相关的内容的技术,推荐系统采用这种技术来为目标用户提供个性化的信息。随着互联网的普及,在各行各业里推荐系统都获得了广泛应用。推荐系统的目标是自动为用户找到最符合心意的项目,例如书籍、音乐、电影等等,而推荐算法可能是依据用户画像或者用户对项目的评分。一些受欢迎的推荐系统有的是利用基于历史内容的推荐,有的是利用协同过滤算法,有的是利用用户行为数据,还有的是利用社交网络数据,当然方法不限于此。
基于内容的推荐算法是利用信息过滤与信息检索技术发现用户的历史喜好进而把物品推荐给用户,而协同过滤算法是利用用户之间或者项目之间的相似度得到喜好相似的用户和评价相似的项目进而进行推荐。这两种类型的推荐算法都要求收集用户喜好,而用户的喜好可以根据显示方法和隐式方法进行收集。显示方法是在用户主动参与的情况下进行的,例如用户的评分、收藏夹、购物车等,隐式信息是在用户不知觉情况下收集的,例如用户的浏览历史、页面停留时间等。然而这两种推荐算法也会有局限性,比如“冷启动”问题,对于一个没有历史数据的新加入的商品和用户,总是难以进行推荐。虽然冷启动问题是大多数推荐系统都会遇到的,但是有些技术可以有效缓解其带来的影响,例如基于知识发现的推荐和多种算法相融合的技术,根据物品的属性和用户的关系或者其他网站上的现有数据进行推荐,因此无需用到商品的评分。
用以上几种推荐算法都可以得到比较高的准确率,因为主要依靠物品或用户的相似度作为依据,但是推荐的物品种类和范围却很局限,不利于用户数的增长。因此,推荐系统还应该考虑到商品覆盖率、用户惊喜度、商品新颖度这些因素。Serendipity 被定义为在不刻意找寻的时候偶然发现令自己满意的而且有用的东西,可以作为用户惊喜度的衡量标准。近年来,怎样提升推荐系统的 serendipity 的问题得到很多学者的关注。
在信息检索领域,Campos 和 Figueiredo 最先设计了一个软件代理,通过网络爬行来支持意外信息的发现[1]。Iaquinta 及其团队首先将 serendipity 的概念引入推荐系统并使推荐性能得到最优化[2],他们认为与用户资料相似度较低的项目可能是更 serendipitous 的项目,并修改了基于内容的系统,以便将这些项目也包含在内。Onuma 及团队提出了一种基于图的算法来支持 serendipity[3],并介绍了在用户项目二分图中计算项目节点的“桥接分数”的想法。最近,Oku 和 Hattori 提出了一个系统,可以通过融合用户资料中的两个内容特征来引发可能的 serendipitous 的建议。
二、相关技术简介
2.1 协同过滤算法
协同过滤、基于内容过滤是大部分推荐系统都采用的两种基本方法。协同过滤算法是一种用于推荐系统的比较成功的算法。一般来说,它主要由两种技术组成:基于相似度的算法和基于模型的算法。
2.1.1 基于相似度的算法
协同过滤基本组成成分:
- 评分矩阵 R。其行标签为用户 id,列标签为物品 id,矩阵内容为用户对物品的评分 rating。
- 用户之间的相似度 sim(u,v)。通常使用的向量相似度测量标准有向量余弦夹角和皮尔逊相关系数,其他的测量标准有斯皮尔曼等级相关系数,平方差,熵等。
- 利用相似度和评分来产生预测的方法。
评分矩阵表示如下:

表 评分矩阵
针对某个用户 u 而言,要用 user-user CF 预测 u 对物品 i 的评分,要先在其他已经为物品 i 做出评价的用户中根据 sim(u,v)计算得出一个相似度高的邻域 N,
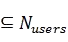 。根据相似度的大小进行排序,N 可以选自 top-N users,也可以选自某一个范围以内。例如,我们可以划定一个阈值为 0.8,N 为由 sim(u,v) >= 0.8 的用户组成。一旦有了可以用来参考的邻域 N,可以根据公式(2-1)来计算:
。根据相似度的大小进行排序,N 可以选自 top-N users,也可以选自某一个范围以内。例如,我们可以划定一个阈值为 0.8,N 为由 sim(u,v) >= 0.8 的用户组成。一旦有了可以用来参考的邻域 N,可以根据公式(2-1)来计算:
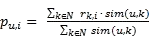
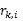 表示用户 k 对物品 i 的评分,sim(u,k)表示用户 u 和 k 的相似度。
表示用户 k 对物品 i 的评分,sim(u,k)表示用户 u 和 k 的相似度。
虽然 user-user CF 算法被广泛使用,但是这种算法只适用于用户较少的情况下。因为当用户的评价改变时,与其他人的相似度就会改变,然而这种情况每时每刻都在发生着,为了减少计算,item-item CF 算法被 Linden et al 提出[5]。这个算法是依据项目的相似度进行计算而非用户相似度。在用户远多于物品的推荐系统中,即使用户对物品的评分频繁发生改变,对于物品的相似度来说只会产生微小的改变,因此用户仍旧可以得到较好的推荐。皮尔逊相关系数和余弦夹角依旧可以用于 item-item CF 中来测量物品的相似度。
2.1.2 基于模型的算法
基于模型的推荐算法有用关联算法做协同过滤、用聚类算法做协同过滤、用分类算法做协同过滤、用回归算法做协同过滤、用矩阵分解做协同过滤、用神经网络做协同过滤、用图模型做协同过滤、用隐语义模型做协同过滤等算法。
三、需求分析
在推荐系统领域,很多研究学者都开始研究 serendipity。为了发现这个概念的特征,Iaquinta 团队分析了这个词语的语源。他们发现在推荐系统相关领域,serendipity 与推荐系统的质量息息相关。它是一个相对主观的概念,因此是一个难以研究的课题。
3.1 SERENDIPITY 的定义
在推荐系统领域,对于 serendipity 有多种定义。例如,在文献[8]中,serendipity 被定义为衡量推荐项目对用户有吸引力和令人惊讶的程度。这意味着一个非常偶然的建议将有助于用户找到一个令人惊讶和有趣的项目。根据这个定义,我们可以看到与 serendipity 有关的两个重要方面。 首先,这个项目应该是用户未曾发现的并且意想不到的;其次,这个项目应该是和用户的兴趣相关并且有用的。 在其他的研究中 serendipity 也有类似的定义。
3.2 SERENDIPITY 能解决的问题
理想情况下,当我们在推荐系统中成功融入 serendipity 时,我们能够避免协同过滤系统中的过于“明显”的建议,解决基于内容的系统中的过度规范问题,在用户非主动参与的情况下帮助用户发现意外的兴趣。 然而,由于从主观意义上判断 serendipity,可能推荐物品会被用户认为是不满意的或者是无用的,因此带来难以预料的风险。
3.3 SERENDIPITY 的衡量标准
怎样衡量一个推荐系统的 serendipity 是一个开放的问题。但是从我们判断一个系统 serendipity 的高低时可以推荐出衡量 serendipity 至少有以下三个方面:是否意想不到、有效性和新颖性。
3.3.1 意向不到的度量
意向不到的度量标准可以用 UNEXPECT 来表示。为了衡量 UNEXPET,我们需要一个用户意料之中的推荐项目的集合。因此我们用传统方法找到参与人数最多的项目集合和评分最高的项目集合,并合并成同一个集合,我们称其为 PM 模型。则 PM 是由原始预测模型生成的一组建议,RS 表示由推荐系统生成的建议。当 RS 的元素不属于 PM 时,我们认为元素是一个意想不到的建议因此,我们计算出意想不到的建议如下: UNEXPECT= RS \ PM
3.3.2 有效性
有效性可以用 USEFUL 来表示。为了保证推荐项目的质量,可以设定一个阈值 k,假设评分在 k 以上的项目被认为是有效的,评分低于 k 的项目被认为是无效的。
3.3.3 新颖性
项目的新颖性可以用 NOVELTY 来表示。增加推荐项目的新颖性可以用 genre-based 算法来实现。根据 genre-based 算法得到的评分较低的项目是用户兴趣较低的项目,从而增加推荐的新颖性。例如,用 User-user 协同过滤算法推荐电影,如果我们发现用户喜欢动作电影也可能喜欢喜剧电影,我们可以通过添加喜剧电影来多样化推荐列表。但是这不是偶然的推荐,因为他可能会自己发现这部电影,所以对这个推荐不会感到惊喜。因此需要 genre-based 算法对用户可能感兴趣的电影类型进行排除,进而增加推荐内容的新颖性,提升用户体验。
四、详细设计和实现
这一章节的内容介绍如何在推荐系统中引进 serendipity 的算法的详细设计和实现,以及算法实现所依托的语言和环境。Serendipity 的定义是在不刻意寻找的时候发现令自己满意并且有用的物品。在推荐系统中,它被定义为一种能够为用户找到意想不到的并且有用的物品的方法。因此在本章中介绍了一种利用协同过滤技术并结合物品内容产生 serendipity items 的方法,基本假设是当基于物品内容的算法 genre-based algorithm 计算得分越高,则该物品对于用户的 serendipity 越小[11]。
4.1 算法流程
产生 serendipity items 算法流程,见图 4-1:
-
第一步:利用协同过滤技术得出要推荐的物品单 RS,以及对物品预测的评分

-
第二步:利用物品的评分分数排序评分数量排序和得出用户意想之中的物品单 PM。
- 第三步:在 RS 中排除 PM 中的物品,可以得到用户意料之外的物品单 UEXPECT。
- 第四步:在 UEXPECT 中排除评分低于某个阈值的物品,可以得到更有用的物品单 SERENDIP。
- 第五步:结合物品的内容提升 SERENDIP 的新颖度进而得到最能体现 serendipity 的物品单。

算法流程图
4.1.1 利用协同过滤算法得出 RS
首先我们用 user-user 协同过滤算法初步得出要推荐的项目集合,用 RS 表示,具体算法如下:
User-based recommendation method
c++
function User-basedRecommender(User u)
for each 没有被用户评分的物品 i do
for each 对物品i有评分的用户 v do
compute u 和 v 的相似度 sim(u,v)
compute v 的加权移动平均值
end for
compute u 对物品的评分 p(u,i)
end for
return 推荐单 RS 和预测评分
4.1.2 原始推荐算法模型 PM
原始推荐方法所推荐的是综合用户评分最高的物品以及物品评分数量最多的物品集。因此 PM 中包含两种物品:一种是平均分高的,另一种是人气最旺的,这两种无疑都是用户意料之中的物品,因此没有推荐价值。
关键代码:
PM=np.unique.vstack((topN_users_for_items[‘itemid’],topN_ratings_for_items[‘itemid’])).ravel()
4.1.3 得出用户意想不到的物品集 UNEXPECT
Serendipity items 的关键组成之一就是高度的 unexpected,PM 模型中的内容无疑是高度 expected,在确保准确的情况下给用户更多的惊喜,可以在 RS 中排除 PM。得出的集合 list3 可以用 UNEXPET 表示。
UNEXPECT = {
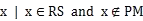 }
}
4.1.4 利用有效性得出 USEFUL
Serendipity items 的另一个关键组成就是提供有用的物品,我们可以确立衡量物品有效性的阈值,在实验中我们可以把这个阈值确立为 3,评分大于 3 的物品我们可以认定为 useful,进而保留在推荐集中,以这种方法得出的物品集 list4 我们用 SERENDIP 来表示。
USEFUL=
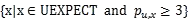
4.2 PYTHON 和 NUMPY
这个算法使用 Annaconda(python2.7 的发行版)和 numpy 写的,以下介绍选用这种方法进行科学计算的原因。
4.2.1 工具的选择
Python 是一种在科学领域被广泛使用的通用编程语言[13],在 python 中可以调用以前的 C、 Fortran 或者 R 代码。同时 Python 是比 C 和 Fortran 更加高级的面向对象语言,可以写出易读、整洁并且缺陷最少的代码。Numpy 系统是 Python 的一种开源的数值计算扩展,它提供了许多高级的数值编程工具如矩阵数据类型、矢量处理,以及精密的运算库,使用 numpy 就可以很自然地使用数组和矩阵。同时 Numpy 中包含很多实用的数学函数,涵盖了线性代数运算、傅里叶变换和随机生成等功能,可以方便地进行数据科学计算。
复杂代码的实现例一:向量余弦法计算相似度
c++
def cosine_similarity(ratings_matrix,avg_ratings_of_users,i,j):
mask = np.logical_and((ratings_matrix[i,:] > 0),(ratings_matrix[j,:] >0)) if np.sum(mask) == 0:
return 0
r_i = ratings_matrix[i] r_j=ratings_matrix[j] numerator = np.dot(r_i[mask],r_j[mask]) denom = np.linalg.norm(r_i[mask])*np.linalg.norm(r_j[mask]) if denom < 1e-6:
return 0
return numerator/denom
例二:在 RS 中排除 PM 中出现的项目
c++
mask = np.in1d(RS['itemid'][:],PPM,invert=True)
UNEXPEC = RS[mask]
五、测试与结果
在这篇论文中介绍的算法采用来自 GroupLens 研究中心在 movielens.org 网站上发布的 100K MovieLens 数据集进行检测。检测结果结果将在这一章中进行展示。
5.1 输入文件
在该 100K Movielens 中记录了 943 个用户,1682 部电影和 100000 个评分,其中每个用户至少对 20 部电影进行了评分。
- 文件 u.info 保存了该数据集的概要:
c++
users
items
ratings
- 文件 u.item 保存了 1682 部电影信息,电影 id 依次是 1、2、3、……、1682。每一行中的电影信息用如下格式来表示。
格式:Item id | 电影名称 | 上映日期 | URL | gnr1 | gnr2 | …… | gnr19
举例:
c++
| Toy Story (1995) | 01-Jan-1995 | http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)
|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0
说明:最后 19 个字段保存的是电影的类型,一个字段对应一种类型 genre(值 0 代表不属于该类型,值 1 代表属于该类型),类型信息保存在文件 u.genre 中。为了方便计算,在 u.item 文件中我们只取 id 和 gnr 这两种信息。
- 文件 u.user 保存了 943 个用户信息,用户 id 依次是 1、2、……、943。每一行中的用户信息用如下格式来表示。
格式:User id | 年龄 | 性别 | 年龄 | 邮编
举例:1 | 24 | M | technician | 85711
- 文件 u.data 保存了 100000 个评分记录,评分的分值为 1、2、3、4、5。每一行中记录的信息用如下格式来表示。
格式:User id | item id | 评分 | 时间戳举例:196 242 3 881250949
经过处理后最终输入的文件及格式如下:

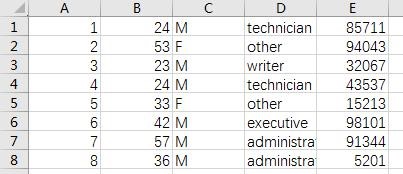
u.data 文件格式 u_.csv 格式
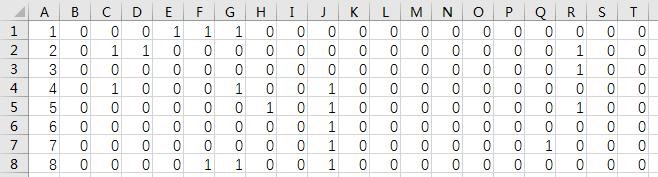
u_item.csv 格式
- 构造评分矩阵 R 用 u.data 中的数据构造一个矩阵,矩阵的横轴标签为用户 id,纵轴标签为电影 id,矩阵内容为用户对电影的评分。用来构造此矩阵的 python 代码如下:
```c++
导入 u.data,用户评分信息
data_ratings = np.genfromtxt('u.data',delimiter='\t', dtype=[('userID',int), ('itemID',int), ('rating',float), ('timestamp',int)])
导入 u.user,用户信息
data_user = np.genfromtxt('u_user.csv',delimiter=',',
dtype=[('userID',int),
('age',int),
('gender','S1'),
('occupation','S20'),
('zipcode',int)])
导入 u.item,电影信息
data_items_genre= = np.genfromtxt('u_item.csv',delimiter=',',
dtype=[('itemID',int),
('genre','19float')])
np.sort(data_items_genre,order='itemID') nitems = data_items_genre.shape[0] nusers = data_user.shape[0]
构造评分矩阵 Nusers x Nitems
ratings_matrix = np.zeros((nusers,nitems)) for i in xrange(data_ratings.shape[0]): userid = data_ratings[i]['userID'] itemid = data_ratings[i]['itemID'] rating = data_ratings[i]['rating']
ratings_matrix[userid-1,itemid-1] = rating
```
那么 ratings_matrix 即为评分矩阵。
5.2 结果测试
输出数据收录在 plot_new_serendipity.dat 文件中进行保存。为了证明结果的有效性,我们对比了 RS 和
 这两个集合的推荐效果。
这两个集合的推荐效果。
5.2.1 GENRE 比较
所选的数据为对用户 user=5 的推荐结果。对比 RS 中排名前 20 名的电影的种类分布和
 中排名前 20 的电影的种类分布和 genre 的数量分布,结果如下:
中排名前 20 的电影的种类分布和 genre 的数量分布,结果如下:
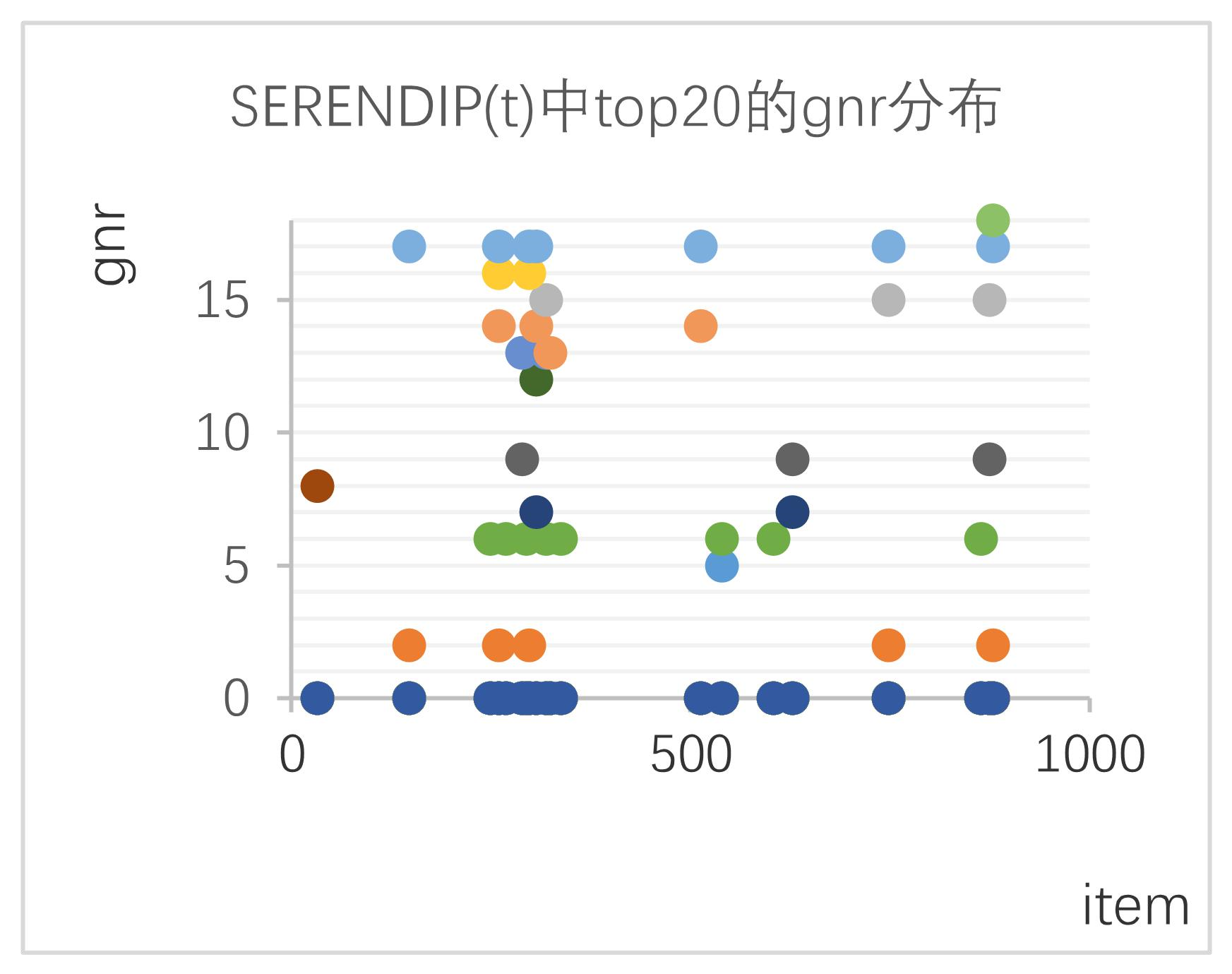
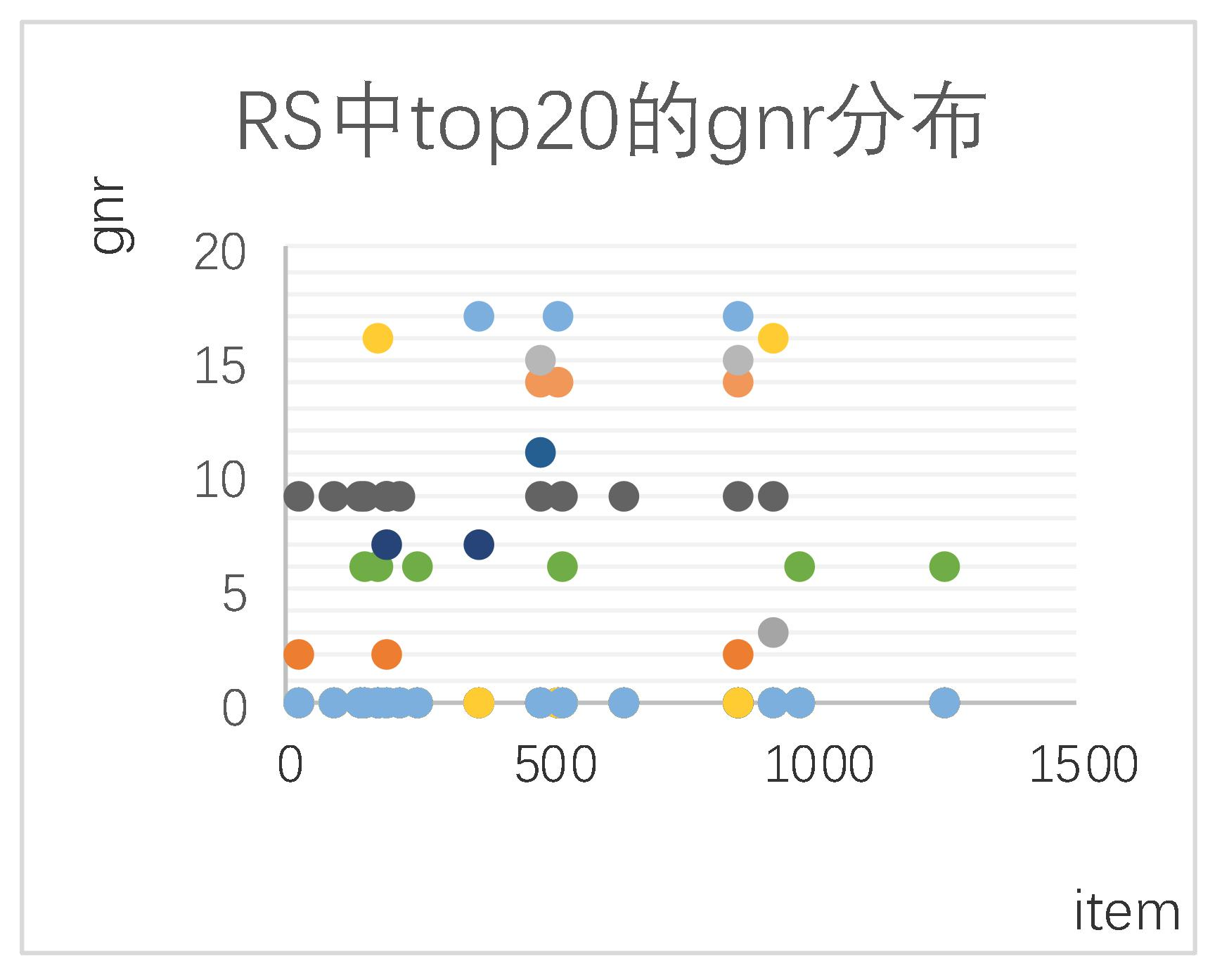
RS 中 top20 的 gnr 分布 图SERENDIP(t)top20 的 genre 分布

图RS 中 top20 的 gnr 数量分布
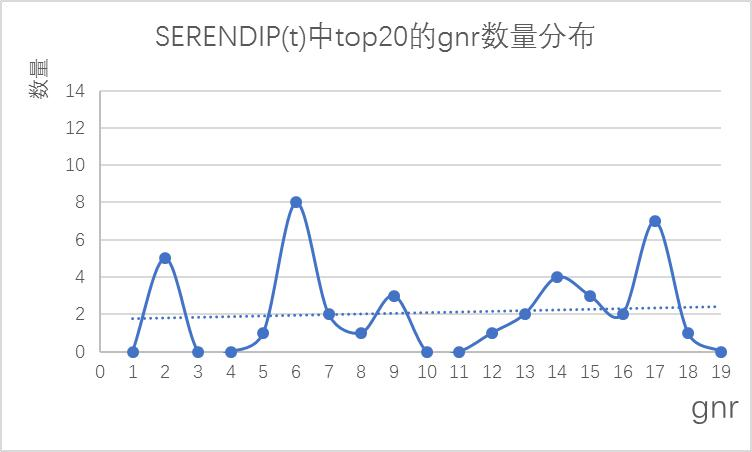
图SERENDIP(t)中 top20 的 gnr 数量分布
根据两种推荐方法的对比图,我们观察到:
-
根据图 a 和图 b 中 item 和对应的 gnr 分布图,可以看出这两种方法推荐的电影 RS 和
 分布是比较均匀的。
分布是比较均匀的。
-
根据图 c 和图 d,观测到在
 推荐的前 20 部电影中,gnr 的分布曲线与 RS 相比更加平缓,因此
推荐的前 20 部电影中,gnr 的分布曲线与 RS 相比更加平缓,因此
 中类型 gnr 的分布更加均匀。
中类型 gnr 的分布更加均匀。
-
在图 c 中 gnr=9 时出现峰值,由此推断出 user 偏向于观看 gnr 为 9 的影片,但是在图 d 中 gnr=9 时曲线较为平缓,可以推测出
 中减少了用户喜爱的电影类型的推荐。
中减少了用户喜爱的电影类型的推荐。
5.2.2 用户测试
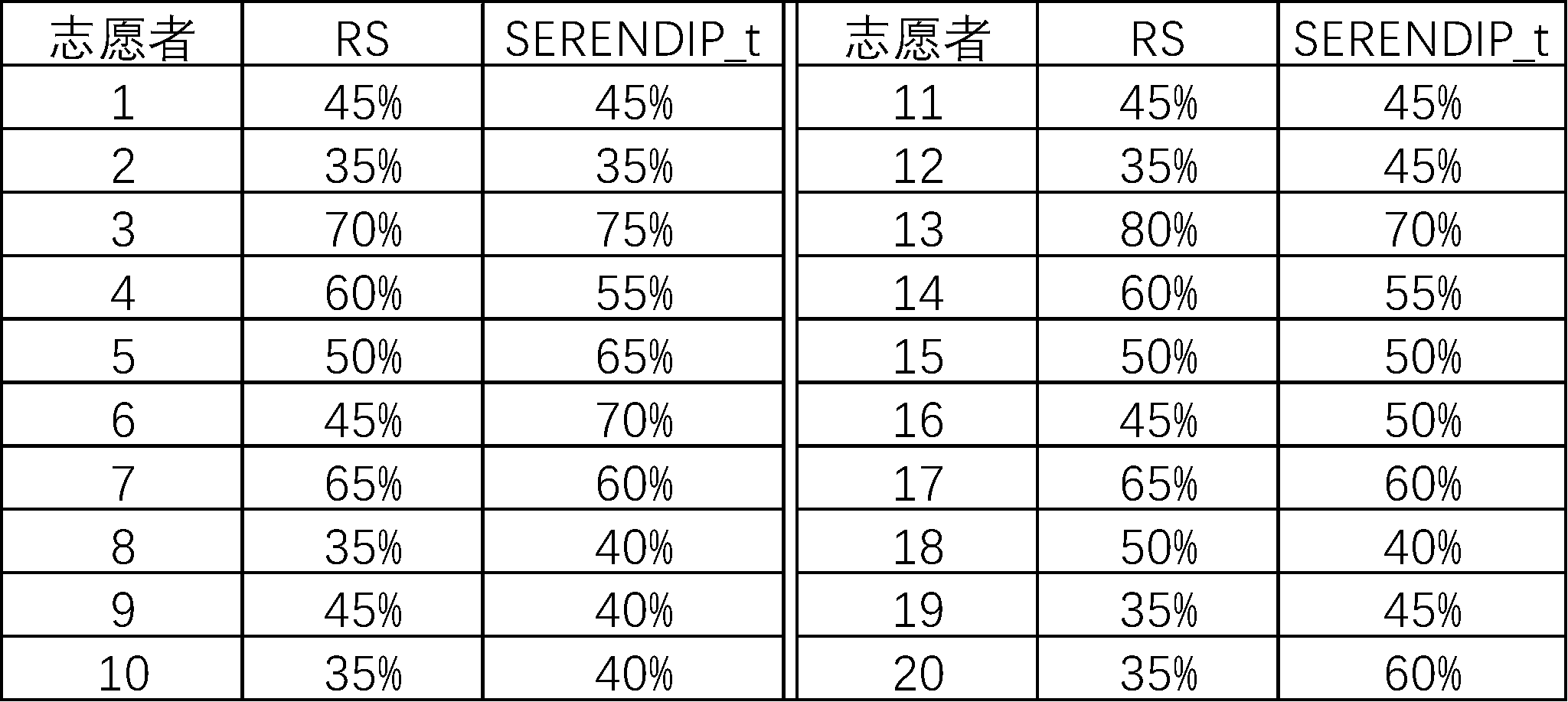
虽然用 genre-based 算法可以有效减少用户偏爱的类型的电影推荐,但是如果不询问用户的意见,这种惊喜度还是难以测量出来的[14],为此在本次论证中我们找到 20 个志愿者进行评测。
所得结果如表 5-1 所示。
具体步骤:
- 志愿者被要求为在 u.item 中的不少于 20 部电影进行评分。
- 把志愿者的评分结果加入评分矩阵 R。
-
根据评分矩阵 R 分别得出用 user-user CF 算法和在此基础上融入 genre-based 算法之后得出的 RS 中 top20 的电影(记作 RS20)和
 中 top20(记作
中 top20(记作
 的电影。
的电影。
-
让用户分别挑选出在 RS20 和
 中让自己满意的电影。
中让自己满意的电影。
-
计算用户满意的电影分别在 RS20 和
 中所占的比例。
中所占的比例。
结果:RS 中满意度的平均分为 50%,
 中满意度的平均分为 52%。
中满意度的平均分为 52%。
可见 user-user CF 和 genre-based 相结合的算法可以提升用户的满意度。
用户满意度调查表
六、总结
6.1 整体评估
在本次研究中,我们提出了一种把 genre-based 算法融入 user-user 协同过滤算法中的方法,从而提高算法的 serendipity。这个算法使用 Annaconda 和 numpy 写的,Annaconda 是 python 的一个发行版本,算法的每一步运行的结果都可以非常清楚地展示在页面中。为了评估这个算法的有效性,我们用取自于 GroupLens 的 100K MovieLens 数据集进行测试。测试结果表明这种算法可以有效地减少用户偏爱的类型的电影推荐,从而提升用户的惊喜度和满意度,使用户体验更加轻松愉快。
6.2 存在的限制
因为在推荐系统中用到协同过滤算法,那么势必会有协同过滤算法遇到的一些:
- 冷启动问题
第一类是新用户问题,当协同过滤算法有新的用户出现时,由于没有新用户的任何历史行为数据,导致算法无法确定用户自身的信息需求,因而就无法完成推荐[16]。解决新用户问题有多种方法,例如根据用户的注册信息对用户分类并给用户推荐他所属分类中用户喜欢的物品,选择合适的物品启动用户的兴趣等。
第二类是新项目问题,当协同过滤算法中有新的项目加入到系统中时,由于没有任何的评分信息,导致协同过滤算法在计算近邻集合的时候无法考虑到这些新项目,从而也导致了这些新的项目无法向用户进行推荐。但是新项目问题可以在基于内容的推荐算法得到很好的解决,因为基于内容推荐算法只需要考虑项目自身的内容信息即可完成推荐,因此我们可以将基于内容的推荐算法与协同过滤算法相结合[17],不仅可以解决新项目问题,而且可以发挥协同过滤算法的挖掘用户潜在信息需求的能力。
- 评分的稀疏性问题
评分的稀疏性问题是指评分数据在整个系统中占有量非常少,冷启动问题就是评分稀疏性问题的极端例子。在推荐系统中,如果用户评价的项目相比于整个系统中的项目数量而言是非常少的,将会导致用户项目评分矩阵的稀疏。在数据极端稀疏的情况下,无论是基于用户的协同过滤算法还是基于项目的协同过滤算法所计算出的相似度的准确度都不高,因此无法作出准确可靠的推荐。一些学者对此进行了研究,文献[18]将奇异值分解技术应用到协同过滤中来,通过降低输入矩阵的维度降低数据的稀疏性。文献[19]提出了一种通过计算项目相似度填充用户评分矩阵的方法,有效缓解了数据的稀疏性。
- 模糊用户问题模糊用户问题又叫做“灰羊问题” [20]。在基于用户的协同过滤算法中,相似度计算是整个算法中非常重要的环节,然而,在系统中可能存在一些兴趣需求非常特殊的用户,很少甚至没有与其兴趣相似的用户,这将导致推荐变得十分困难。模糊用户问题是用户信息需求不明确造成的,这些问题可以通过结合基于内容的推荐算法到协同过滤算法那中来,从而增强需求信息的表达能力。
参考文献
- 基于用户日志的新闻推荐系统研究(吉林大学·高冉冉)
- 基于知识图谱与注意力机制的序列推荐方法研究(辽宁师范大学·吕福泽)
- 基于用户上下文的推荐系统(吉林大学·田欧)
- 基于混合算法的个性化推荐系统(北京邮电大学·谢艺聪)
- 基于融合用户行为特征知识图谱的推荐算法研究(辽宁大学·王宏旭)
- 基于中小型电商平台的个性化推荐系统建模(华北电力大学(北京)·梁德祥)
- 基于Django的课程推荐系统的设计与实现(华中科技大学·羊雪玲)
- 面向信息过载的个性化推荐算法研究(东北大学·姚振宇)
- 基于Java的个性化推荐系统研究(西安电子科技大学·祁康峰)
- 在线推荐系统的算法研究及其应用(电子科技大学·黄海波)
- 基于特征的个性化电子商务网站推荐系统的研究与实现(华东师范大学·吴昕方)
- 基于用户自适应策略的深度推荐算法(中国科学院大学(中国科学院深圳先进技术研究院)·陈磊)
- 基于知识图谱与注意力机制的序列推荐方法研究(辽宁师范大学·吕福泽)
- 基于互联网用户特征的商品推荐系统研究——基于Hadoop和Mahout(东华大学·黄鹏)
- 基于协同过滤的推荐算法比较研究(重庆大学·高寒)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码助手 ,原文地址:https://m.bishedaima.com/yuanma/35809.html