TensorFlow 2 EMNIST 数据集上的 ResNet 字母数字识别模型
本项目在 window10 + tf2.1 + python3.7 环境下运行良好。可供 tf2 入门学习。
数据准备
数据全部来自于 TF 官网收录的 EMNIST 数据集:
- https://tensorflow.google.cn/datasets/catalog/emnist?hl=en
- emnist/byclass (default config):本项目使用默认的 62 分类数据集,分别为 10 个数字,26 个大小写字母(10+26+26),训练集 697932 个,测试集 116323 个
读取(路径没有数据则自动下载)数据集:
python
(ds_train, ds_test), ds_info = tfds.load(
'emnist',
split=['train', 'test'],
data_dir='./tensorflow_datasets',
shuffle_files=True,
as_supervised=True,
with_info=True,
)
这部分在 mytrain.py,参考自官方文档 https://tensorflow.google.cn/datasets/keras_example
模型构建
使用 keras 构建了 4 个 CNN 模型分别做测试,最后选用了效果最好的 ResNet,模型构建写在 model.py。
```python
--------------------------
RESNET
--------------------------
def res_net_block(input_data, filters, conv_size): # CNN层 x = layers.Conv2D(filters, conv_size, activation='relu', padding='same')(input_data) x = layers.BatchNormalization()(x) x = layers.Conv2D(filters, conv_size, activation=None, padding='same')(x) # 第二层没有激活函数 x = layers.BatchNormalization()(x) # 两个张量相加 x = layers.Add()([x, input_data]) # 对相加的结果使用ReLU激活 x = layers.Activation('relu')(x) # 返回结果 return x
def ResNet_inference(input_shape, n_classes, dropout): inputs = keras.Input(shape=input_shape) x = layers.Conv2D(32, 3, activation='relu')(inputs) x = layers.Conv2D(64, 3, activation='relu')(x) x = layers.MaxPooling2D(3)(x) num_res_net_blocks = 10 for i in range(num_res_net_blocks): x = res_net_block(x, 64, 3) # 添加一个CNN层 x = layers.Conv2D(64, 3, activation='relu')(x) # 全局平均池化GAP层 x = layers.GlobalAveragePooling2D()(x) # 几个密集分类层 x = layers.Dense(256, activation='relu')(x) # 退出层 x = layers.Dropout(dropout)(x) outputs = layers.Dense(n_classes, activation='softmax')(x) res_net_model = keras.Model(inputs, outputs) res_net_model.compile(optimizer=keras.optimizers.Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy']) res_net_model.summary() # 105s 53ms/step - loss: 0.2584 - accuracy: 0.8978 - val_loss: 0.3838 - val_accuracy: 0.8743 # 2000*20steps开始过拟合 return res_net_model ```
训练模型
- 使用 keras.models.fit 来训练模型
python
callbacks = [
tf.keras.callbacks.ModelCheckpoint(ckpt_path,
save_weights_only=True,
verbose=1,
period=SAVE_PERIOD),
tf.keras.callbacks.TensorBoard(log_dir, write_graph=True, write_images=True)
]
运行 mytrain.py 开始训练,会自动下载数据集(根目录生成 tensorflow_datasets 文件夹)
- 使用 tf.keras.callbacks.ModelCheckpoint 实现训练中自动保存。
- 支持断点续训,退出时直接保存模型,再次训练会读取最近保存的 weight。
- TensorBoard 用于实时监测训练情况,根目录下命令行输入 tensorboard --logdir=tblogs,按提示打开浏览器查看
数据集较大,建议使用 GPU 训练。
tensorboard 查看训练 20 轮后的情况:
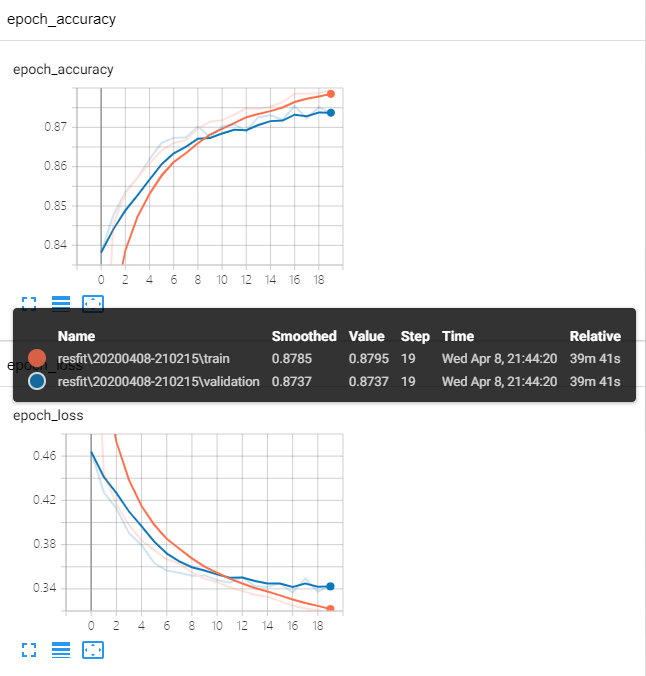
模型测试
将待识别图片放入 assets(支持白底彩字),运行 demo.py 即可,默认识别 PNG,想识别 jpg 修改一下 demo.py 就可以
python
if __name__ == '__main__':
img_files = glob.glob('assets/*.png')
model = get_model()
for img_f in img_files:
a = cv2.imread(img_f)
cv2.imshow('monitor', a)
cv2.moveWindow("monitor",960,540)
predict(model, img_f)
cv2.waitKey(0)
运行时会逐一弹窗,并打印识别的字,文件夹中会生成由字母本身命名的图片。

参考文献
- Construction of Knowledge Graph of Electromagnetic Compatibility Standards(华中师范大学·Huaxin Zheng)
- Python知识自动问答系统的研究与实现(河北工程大学·郝光兆)
- 基于深度学习的小学数学辅助学习系统设计与实现(北京交通大学·王磊)
- 基于网络百科的中文实体链接研究(西南交通大学·袁金伟)
- 深度学习在社交网络文本分类中的应用研究(大连交通大学·方金朋)
- 基于深度学习的验证码识别技术(大连交通大学·慕亚东)
- 面向对象软件代码结构解析及知识图谱构建(西南大学·关雪婷)
- 基于Python的非结构化数据检索系统的设计与实现(南京邮电大学·董海兰)
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
- 移动APP下母婴产品知识推广平台的设计与实现(中国地质大学(北京)·张春玲)
- “天眼查”分布式爬虫系统中验证码识别模块的设计与实现(北京交通大学·张泽阳)
- 基于结构数据的多模式智能问答消歧系统(山东大学·李华东)
- 基于深度学习的软件实体识别方法(云南师范大学·孙超)
- 实体解析技术研究与应用(上海交通大学·朱灿)
- Python知识自动问答系统的研究与实现(河北工程大学·郝光兆)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码向导 ,原文地址:https://m.bishedaima.com/yuanma/35871.html