
文本内容抓取
网络爬虫(Web Crawler)技术是从网页中抽取可用数据的方式,广泛运用于大规模从网络中提取信息。本文使用 Python,通过编写爬虫程序 ,以政府工作报告全文为检索目标,在中华人民共和国中央人民政府网站自动爬取了 1954-2016 年政府工作报告全文的文本数据,截止 2016 年 12 月 27 日,除掉缺失年份,其中剩余有效年份为 48 年。

爬虫代码如下:
```python
===================================================================
抓取报告正文部分、词频统计
===================================================================
建立一个空的字典用于存储网页数据,如标题、网页地址等;
从历年国务院政府工作报告(1954年至2013年)http://www.gov.cn/test/2006-02/16/content_200719.htm中过滤出历年报告的链接并返回到'ReportLinks'
url = 'http://www.gov.cn/guowuyuan/2006-02/16/content_2616810.htm' Report_Links = dict()
过滤出页面中的网页链接
def filterReportLinks(url): print '过滤1954-2016年政府工作报告网址······' html_doc = urllib2.urlopen(url).read() standard_html = BeautifulSoup(html_doc, "html.parser") for link in standard_html.find_all('a', href = re.compile(r'/content_')): url = link.get('href') year = link.get_text() Report_Links[year] = url return Report_Links
提取网页(URL)文本
def extract_text(url): """Extract html content.""" page_source = requests.get(url).content bs_source = BeautifulSoup(page_source) report_text = bs_source.find_all('p') text = '' for p in report_text: text += p.get_text() text += '\n' return text ```
报告文本预处理
采用结巴分词系统对 48 年的全文数据进行分词处理。结巴分词系统在 Python 中有现成的组件,对文本(Text)进行分词处理时,需要去除停用词和标点符号,停用词是指那些对文本的影响可以忽略不计的,不包含有任何实质性内容的词语,如“的”、“得”、“地”,在这里我们直接从分词完毕后的文本中筛选出长度大于 2 的字符串就达到期望的效果,得到名为
fil_seglist
的变量,然后用空格拼接过滤掉停用词和标点符号的
fil_seglist
变量。如“必须全面深化改革,坚持和完善基本经济制度,建立现代产权制度”一段文本,经过预处理之后,处理之后的文本为“必须 全面 深化改革 坚持 完善 基本 经济 制度 建立 现代 产权制度”。
构建词同现网络
词同现网络的构造思路比较简单,每一个词语对应网络中的一个节点(node),而同现词组之间的连接则成为连接节点的边(edge)。也就是说,如果在一个句子中,两个词在 n 阶 Markov 链的条件下存在同现关系,则可认为网络中的两个节点之间存在一个连接。实践表明,在自然语言处理中,n 阶 Markov 链的 n 取 2 比较合适,因为句子中两个词相邻是最常见的,如“发展农业”的“发展”和“农业”,“补贴农村”的“补贴”和“农村”,n 太大(两个词在一句话中距离太远)则会引入大量的无关词,导致同现网络准确性的降低,另一方面,又可以使模型的复杂度得到有效的控制。
构建词同现网络代码如下:
```python
===================================================================
同现词统计并封装在CSV文件中
===================================================================
针对每年报告文本结巴分词之后得到的seg_list进行“同现词”统计
def build_co_network(seg_list):
co_net = defaultdict(lambda: defaultdict(int))
for i in range(len(seg_list)-1):
for j in range(i+1, i+2):
w1 = seg_list[i]
w2 = seg_list[j]
if w1 != w2:
co_net[w1][w2] += 1
return co_net
“同现词”统计之后,我们将统计的结果(Top 100)返回到“terms_max”中
def get_co_terms(co_net): com_max = [] for t1 in co_net: t1_max_terms = sorted(co_net[t1].items(), key=operator.itemgetter(1), reverse=True) for t2, t2_count in t1_max_terms: com_max.append(((t1, t2), t2_count)) terms_max = sorted(com_max, key=operator.itemgetter(1), reverse=True) return terms_max
针对terms_max,将s2,s3,s4写入CSV文件中
def get_co_network(): for (year, link) in Report_Links.items(): #year = str(year) text = extract_text(link) seg_list = jiebait(text) co_net = build_co_network(seg_list) terms_max = get_co_terms(co_net) for s1 in terms_max: s2 = s1[0][0] s3 = s1[0][1] s4 = s1[1] s2 = s2.encode('utf-8') #s2和s3以Unicode编码存在,故转码为‘utf8’ s3 = s3.encode('utf-8') s4 = str(s4) print year, s4 terms = open('terms5.csv', 'ab') terms.write(year + '\t') terms.write(s2 + '\t') terms.write(s3 + '\t') terms.write(s4 + '\n') terms.close()
get_co_network() ```
运行上述代码,本文对语料库分词之后得到的自定义字典进行同现词组的频率统计,得到了 1954 至 2016 年语料库中总计 273592 组共现词组的频率统计数据,包含 19468 个网络节点和 170889 条边。表 1 截取了统计数据中 1954 年和 2016 年的前 5 行数据,其中 Frequency 表示某年(Year)中词 1(Word1)与词 2(Word2)在字典中前后相邻的次数统计,比如 2016 年政府工作报告中,“经济”和“发展”两个词前后相邻的频率为 11 次,“国内”和“生产总值”前后相邻出现的频率为 10 次。
| Year | Word1 | Word2 | Frequency |
|---|---|---|---|
| 1954 | 等于 | 一九四九年 | 14 |
| 1954 | 我们 | 国家 | 14 |
| 1954 | 经济 | 建设 | 13 |
| 1954 | 全国 | 人民 | 10 |
| 1954 | 日内瓦 | 会议 | 10 |
| … | … | … | … |
| 2016 | 经济 | 发展 | 11 |
| 2016 | 深入 | 推进 | 10 |
| 2016 | 国内 | 生产总值 | 10 |
| 2016 | 结构性 | 改革 | 10 |
| 2016 | 中国 | 特色 | 9 |
可视化分析
在这一节里,我们主要围绕“农业”、“农村”、“农民”三个主题词进行文本挖掘的统计指标分析、可视化展示等工作。
主题词词频分析
词频分析法是利用能够揭示或表达文本核心内容的关键词或主题词在某一研究领域文献中出现的频次高低来确定该领域研究热点和发展动向的文献计量方法,广泛应用于各学科领域。我们在语料库中选取“农业”、“农村”、“农民”3 个主题词并对其进行词频统计分析,统计各年政府工作报告中主题词出现频率,具体见图 1。
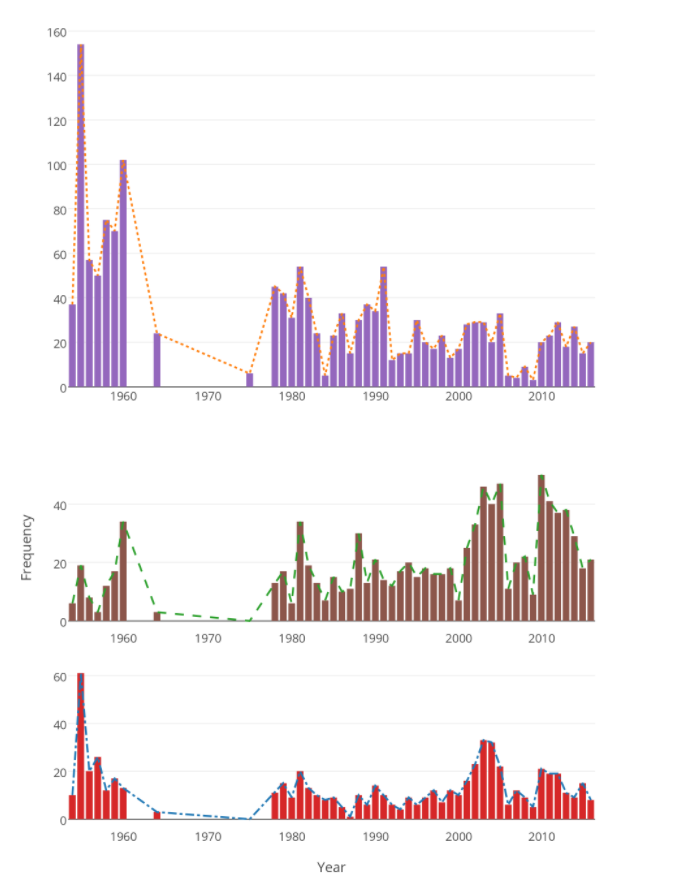
可以发现词频统计图的起伏涨落对应着同时期的国家对于三农战略或政策的变化:由于国内阶级斗争,政府工作会议曾停滞达 10 之久,从而 20 世纪 60 年代至 80 年代期间统计数据存在一个明显的缺口;在建国之初制定了“一化三改”过渡时期总路线,国家对重视农业十分重视,如在 1954 年政府工作报告的文本中,“农业”一词出现的频率就达 154 次,“农村”一词出现频率为 19 次,“农民”一词出现频率为 61 次;1990 年至 2000 年国家对“三农”的重视程度处于比较平稳的状态,而 2008 年至 2009 年间爆发的全球金融危机使得政府在“三农”问题上的关注有所降低,在 2009 年的政府工作报告文本中,“农业”、“农村”、“农民”三个主题词出现频率分别只有 3 次、9 次和 5 次,为改革开放以来的最低水平。
主题词网络统计特性分析
平均路径长度、聚集系数和度分布为复杂网络的三大统计特性[29],它们比较系统地反映了网络中的节点位置、连接状况、密度、节点间路径远近等各类结构特征。
Gephi 是一款优秀的开源网络分析领域的数据可视化处理软件,本文主要通过 Gephi 0.9.1 软件对共现网络进行可视化及主要参数的计算工作。
Gephi 软件有几个重要的计算参数,分别是度中心性(Degree centrality)、紧密中心性(Closeness centrality)、平均聚合系数(Average clustering coefficient)。度中心性指节点的度数, 适用于对局部网络节点的中心地位和影响力进行刻画,度中心性关注单个节点;紧密中心性用于度量网络中节点对于中心的紧密程度,是刻画节点通过网络到达其他节点难易程度的指标,节点的紧密度越高,则离其他节点越近,传递信息的难度也就越低,相比节点度指标更能反映网络的全局结构。
| 网络 | 节点数 | 边数 | 网络直径 | 平均度 | 平均最短路径 | 平均聚合系数 | |::|::|::|::||||| | 共现词组 |19468 |170889|16| 17.566| 3.278| 0.210|
- 小世界特性。节点网络平均最短路径为 3.278,这说明在该词同现网络中的任意两个节点,只用少于 4 个节点就可以将他们连接起来,具有明显的小世界效应。也就是说,虽然汉语中有大量的词汇,但是人们在语言网络中,只需经过有限路径就可以从一个词迅速跳到另外一个词,并确保语义的完整,从而保证了交流表达的速度。
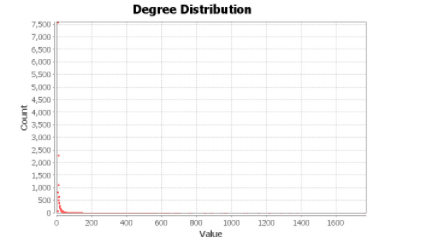
- 节点度分布。节点网络的度分布满足幂率分布,显示了无标度特性。节点度分布如图 1 所示,少数节点出现频繁,多数节点出现频率较低。
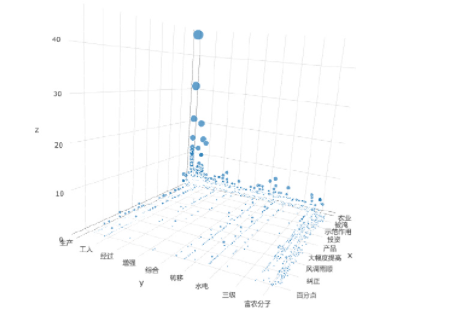
在共现词组列表中,以包含“农”字符串为检索条件,筛选出字段中含有“农”的词组,如“工农业”、“农村居民”、“农产品”等字段也统计在内,共计 5990 对。为了便于观察,将年份(Year)一列剔除,X 轴设为 Word1 列,Y 轴设为 Word2 列,Z 轴设为 Frequency 列,得散点图如图 2 所示,可以看出,频率计数最高的共现词组为“农业—生产”、“农业—发展”,其余大多数共现词组的频率低于 2 次。
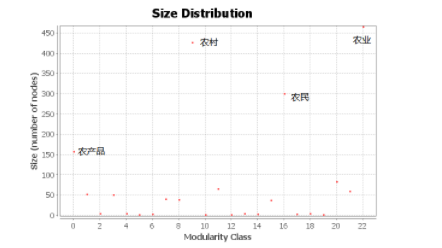
我们将筛选出来的字段数据导入 Gephi 软件中,并利用 Convert Excel and CSV files to networks 插件进行网络中心度计算。经计算,该网络中一共包含 1832 个节点和 3098 条边,网络的平均聚集系数为 0.302,模块化系数为 0.475(系数大于 0.4 则表明网络有良好的模块化结构),各节点模块化系数分布如图 3 所示,
然后,我们选取“农业”、“农村”、“农民”三个主题词,选取度、紧密中心性、平均聚集系数三个指标,计算结果如 表 3 所示,三个主题词节点的紧密中心性均在 0.5 左右,节点连接很紧密,说明主题词节点之间沟通良好,信息可以快速在节点之间传播。
| 主题词 | 度 | 紧密中心性 | 平均聚集系数 | |::| | 农业 |685 |0.552 |0.002| | 农村 |591 |0.519 |0.002| | 农民 |418 |0.493 |0.003|
基于 Force Atlas 算法生成的三农主题词关系图谱如图 4 所示,可以看出关于主题词群体间界限十分明晰,在这些群体中,“农业”、“农村”、“农民”三个群体占据了核心位置,“农民工”、“农产品”、“农民收入”等分别占据次核心位置,并充当三个群体沟通连接的介中心(Between centrality),进一步印证了共现网络具有良好模块化的结论。

结论
本文从共生模式角度切入,构建词同现网络以分析农业、农村、农民三者之间的共生关系。共生模式主要有寄生、偏利共生、非对称性互惠共生和对称互惠共生几种,关于共生模式的判别,国内外的学者主要通过 Logistic 方程、共生度、共生界面等方法进行分析。
我们以连通主题词节点个数作为判别共生模式的主要指标,即共生度。如三个主题词分别通过“收入”、“经济”、“改革”、“城市”等中间节点充当物质、信息和能量传导的媒介、通道或载体,建立共生关系,节点数目的多少可以反映主题词之间的共生强度,从而判断共生模式就具备了逻辑上的可能性。从“农业-农村”、“农村-农民”和“农业-农民”三组主题词词组的共生关系的可视化图(见图 5、图 6、图 7)可以看出,大量中间点如发展、经济、城镇等充当沟通媒介,主题词之间联系相当紧密,由此我们可以判断农业、农村、农民三个主题词之间存在互惠共生的关系。但是紧密的程度却存在差别,农业和农村的沟通最为密切,共计有 265 个节点,与此同时,农业与农民之间有 195 个节点,农民与农村次之,有 114 个节点。由此可以进一步判断主题词之间处于非对称性互惠共生关系。
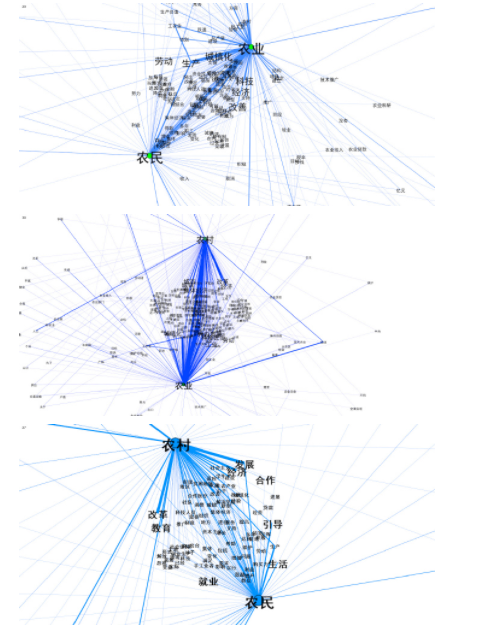
综上,根据模块化系数、紧密中心度和主题词关系图谱以及主题词关系子图谱,我们可以发现三农问题的组成部分之间存在非对称互惠共生的模式。# report_analysis
参考文献
- 网络信息采集技术及中文未登录词算法研究(北京邮电大学·陈浩)
- 文本搜索引擎的探究与设计(华南理工大学·张立)
- 轻量级分布式虚假信息爬虫的设计与实现(辽宁大学·韩昱)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 个性化资讯推荐系统的设计与实现(山东大学·仵贇)
- 短文本分析系统中管理子系统的设计与实现(北京邮电大学·陈盼利)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 财经领域事件抽取技术的研究与应用(北京理工大学·陈贺)
- 基于网络爬虫技术的内容探测系统设计与实现(北京邮电大学·黄晓鹏)
- 搜索引擎中网络爬虫及结果聚类的研究与实现(中国科学技术大学·梁萍)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 复合规则驱动聚焦爬虫系统的设计与实现(哈尔滨工业大学·刘强)
- 基于K-Means的分布式文本聚类系统的设计与实现(西安电子科技大学·马婵媛)
- 基于网络爬虫的信息采集分类系统设计与实现(厦门大学·周茜)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设工坊 ,原文地址:https://m.bishedaima.com/yuanma/35902.html









