基于 word2vec 使用 wiki 中文语料库实现词向量训练模型
之前做过一些自然语言处理的工作,主要是根据一些企业在互联网上的相关新闻进行分析,对其倾向性进行判断,最终目的是辅助国内某单位更好地对其管辖的企业进行监管工作。现在总结整理一下。这篇文章主要对 词向量训练阶段 进行阐述。
数据获取
使用的语料库是 wiki 百科的中文语料库,下载地址: https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2 。另外,提供百度网盘下载链接: https://pan.baidu.com/s/1eLkybiYOE_aVxsN0pALATg ,提取码为:hmtn。
下载之后如下图(PyCharm 截图),大小为 1.16GB。

将 XML 格式数据转为 txt
因为原始文件是 XML 格式,并且是压缩文件,所以做了一步数据解压并进行格式转换的工作。 具体使用了 gensim 库中的维基百科处理类 WikiCorpus,该类中的 get_texts 方法原文件中的文章转化为一个数组,其中每一个元素对应着原文件中的一篇文章。然后通过 for 循环便可以将其中的每一篇文章读出,然后进行保存。
```
coding; utf-8
""" 这个代码是将从网络上下载的xml格式的wiki百科训练语料转为txt格式 wiki百科训练语料 链接:https://pan.baidu.com/s/1eLkybiYOE_aVxsN0pALATg 密码:hmtn """
from gensim.corpora import WikiCorpus
if name == ' main ':
print('主程序开始...')
input_file_name = 'zhwiki-latest-pages-articles.xml.bz2'
output_file_name = 'wiki.cn.txt'
print('开始读入wiki数据...')
input_file = WikiCorpus(input_file_name, lemmatize=False, dictionary={})
print('wiki数据读入完成!')
output_file = open(output_file_name, 'w', encoding="utf-8")
print('处理程序开始...')
count = 0
for text in input_file.get_texts():
output_file.write(' '.join(text) + '\n')
count = count + 1
if count % 10000 == 0:
print('目前已处理%d条数据' % count)
print('处理程序结束!')
output_file.close()
print('主程序结束!')
```
结果文件截图:
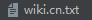

繁体转为简体
为了方便后期处理,接下来对上面的结果进行简体化处理,将所有的繁体全部转化为简体。在这里,使用了另外一个库 zhconv。对上面结果的每一行调用 convert 函数即可。
```
coding:utf-8
import zhconv
print('主程序执行开始...')
input_file_name = 'wiki.cn.txt' output_file_name = 'wiki.cn.simple.txt' input_file = open(input_file_name, 'r', encoding='utf-8') output_file = open(output_file_name, 'w', encoding='utf-8')
print('开始读入繁体文件...') lines = input_file.readlines() print('读入繁体文件结束!')
print('转换程序执行开始...') count = 1 for line in lines: output_file.write(zhconv.convert(line, 'zh-hans')) count += 1 if count % 10000 == 0: print('目前已转换%d条数据' % count) print('转换程序执行结束!')
print('主程序执行结束!') ```
结果截图:


分词
对于中文来说,分词是必须要经过的一步处理,下面就需要进行分词操作。在这里使用了大名鼎鼎的 jieba 库。调用其中的 cut 方法即可。
```
coding:utf-8
import jieba
print('主程序执行开始...')
input_file_name = 'wiki.cn.simple.txt' output_file_name = 'wiki.cn.simple.separate.txt' input_file = open(input_file_name, 'r', encoding='utf-8') output_file = open(output_file_name, 'w', encoding='utf-8')
print('开始读入数据文件...') lines = input_file.readlines() print('读入数据文件结束!')
print('分词程序执行开始...') count = 1 for line in lines: # jieba分词的结果是一个list,需要拼接,但是jieba把空格回车都当成一个字符处理 output_file.write(' '.join(jieba.cut(line.split('\n')[0].replace(' ', ''))) + '\n') count += 1 if count % 10000 == 0: print('目前已分词%d条数据' % count) print('分词程序执行结束!')
print('主程序执行结束!') ```
结果截图:

去除非中文词
可以看到,经过上面的处理之后,现在的结果已经差不多了,但是还存在着一些非中文词,所以下一步便将这些词去除。具体做法是通过正则表达式判断每一个词是不是符合汉字开头、汉字结尾、中间全是汉字,即“ ^[\u4e00-\u9fa5]+$ ”。

```
coding:utf-8
import re
print('主程序执行开始...')
input_file_name = 'wiki.cn.simple.separate.txt' output_file_name = 'wiki.txt' input_file = open(input_file_name, 'r', encoding='utf-8') output_file = open(output_file_name, 'w', encoding='utf-8')
print('开始读入数据文件...') lines = input_file.readlines() print('读入数据文件结束!')
print('分词程序执行开始...') count = 1 cn_reg = '^[\u4e00-\u9fa5]+$'
for line in lines: line_list = line.split('\n')[0].split(' ') line_list_new = [] for word in line_list: if re.search(cn_reg, word): line_list_new.append(word) print(line_list_new) output_file.write(' '.join(line_list_new) + '\n') count += 1 if count % 10000 == 0: print('目前已分词%d条数据' % count) print('分词程序执行结束!')
print('主程序执行结束!') ```
结果截图:


词向量训练
上面的工作主要是对 wiki 语料库进行数据预处理,接下来才真正的词向量训练。

```
coding:utf-8
import multiprocessing from gensim.models import Word2Vec from gensim.models.word2vec import LineSentence
if name == " main ": print('主程序开始执行...')
input_file_name = 'wiki.txt'
model_file_name = 'wiki.model'
print('转换过程开始...')
model = Word2Vec(LineSentence(input_file_name),
size=400, # 词向量长度为400
window=5,
min_count=5,
workers=multiprocessing.cpu_count())
print('转换过程结束!')
print('开始保存模型...')
model.save(model_file_name)
print('模型保存结束!')
print('主程序执行结束!')
```
也是使用了 gensim 库,通过其中的 Word2Vec 类进行了模型训练,并将最终的词向量保存起来。
参考文献: [1]. wiki 中文语料库, https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2 . [2]. 使用 word2vec 训练 wiki 中英文语料库, https://www.jianshu.com/p/05800a28c5e4 . [3]. 中英文维基百科语料上的 Word2Vec 实验, http://www.52nlp.cn/%E4%B8%AD%E8%8B%B1%E6%96%87%E7%BB%B4%E5%9F%BA%E7%99%BE%E7%A7%91%E8%AF%AD%E6%96%99%E4%B8%8A%E7%9A%84word2vec%E5%AE%9E%E9%AA%8C .
参考文献
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 基于图谱实体表示与排序学习的文本检索方法研究(吉林大学·毕磊)
- 汉语词法分析平台的构建(大连理工大学·叶子语)
- 基于知识图谱的跨语言实体链接与语义查询(华东师范大学·苏永浩)
- 汉语词法分析平台的构建(大连理工大学·叶子语)
- 词向量语义模型研究及在主题爬虫系统中的应用(中国地质大学(北京)·孟竹)
- 面向实体知识的表示学习研究(华中师范大学·朱建平)
- 财经领域事件抽取技术的研究与应用(北京理工大学·陈贺)
- 面向实体知识的表示学习研究(华中师范大学·朱建平)
- 用户兴趣自适应的个性化推荐系统的设计与实现(北京交通大学·李妮燕)
- Blog论坛搜索与排名技术(扬州大学·朱燕)
- 用户兴趣自适应的个性化推荐系统的设计与实现(北京交通大学·李妮燕)
- 《宋词三百首》标注语料库的构建及计量研究(南京师范大学·郝星月)
- 成语电子词典系统的设计与实现(电子科技大学·刘健)
- 面向中文产品评论的情感分析研究(西南大学·孙雪峰)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕业设计客栈 ,原文地址:https://m.bishedaima.com/yuanma/35908.html