推荐系统
小组成员:孙家宜,李彦欣,郝旭
一、实验相关统计信息
用户数量: 19835 物品数量: 624961 打分数量: 5002419
打分平均值: 49.65618273879098
实验原理
二、基本实验思路
处理数据:根据 train.txt 中的数据得到[userid, itemid, rating]形式的 list,构建出 user 对 item 打分的矩阵。
由于以上矩阵是稀疏的,因此定义聚类对未打分项进行填充,降低矩阵的稀疏程度。具体做法是:选取 itemAtribute.txt 中所给的每个 item 的属性值对 item 聚类。
开始训练:将数据集分为 trainset 和 testset,然后用 trainset 进行训练,用 testset 评估算法的准确度,不断调整参数,提升算法的准确度。
最后用模型预测 test.txt 中数据的得分并按照要求存储到 result.txt 中,再算出 RMSE。
三、主要算法
本小组使用潜在因子模型 SVD(奇异值分解)的方法构建推荐系统。
MiniBatchKmeans 聚类
此算法主要为了解决矩阵稀疏问题。
在统的 K-Means 算法中,要计算所有的样本点到所有的质心的距离。如果样本量非常大,比如达到 10 万以上,特征有 100 以上,此时用传统的 K-Means 算法非常的耗时,就算加上 elkan K-Means 优化也依旧。在大数据时代,这样的场景越来越多。此时 Mini Batch K-Means 应运而生。
顾名思义,Mini Batch,也就是用样本集中的一部分的样本来做传统的 K-
Means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是我们的聚类的精确度也会有一些降低。一般来说这个降低的幅度在可以接受的范围之内。
在 Mini Batch K-Means 中,我们会选择一个合适的批样本大小 batch size,
我们仅仅用 batch size 个样本来做 K-Means 聚类。batch size 个样本一般是通过无放回的随机采样得到的。
为了增加算法的准确性,我们一般会多跑几次 Mini Batch K-Means 算法,用得到不同的随机采样集来得到聚类簇,选择其中最优的聚类簇。
SVD 算法我们设 user 给 item 的评分的矩阵为 A,SVD 算法就是将矩阵 A 分解为成矩阵
和 V,其中 A,U,V 满足:
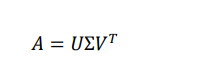
A:输入的矩阵
U:左奇异矩阵
V:右奇异矩阵
Σ:奇异值向量上述算法成立是在 A 中所有值都已知的情况下,但是实际上打分矩阵中有大量未知值。所以我们构建另一种分解。
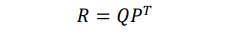
这里
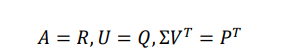
利用基于求函数最小值问题的方法:求出所有满足如下条件的向量


四、求解过程
梯度下降找近似解梯度下降是一种查找函数最小值的方法。这里我们使用随机梯度下降的方法,所以首先要构造损失函数:
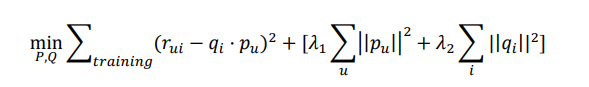
这里公式的后半部分为正则项,防止过拟合。接下来求出函数关于 p,q 的导数,就可以应用梯度下降。
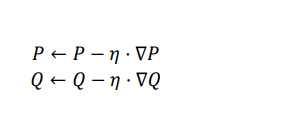
预测评分对未知 u,i 对的分数进行预测公式:
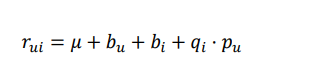
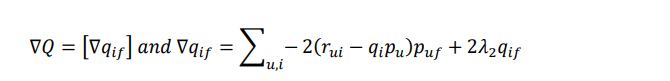

新的损失函数:
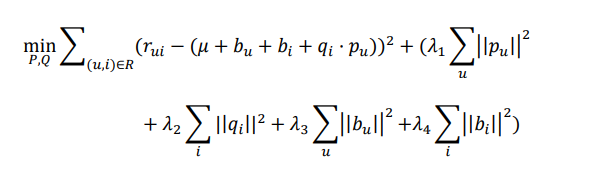
评估模型这里我们使用 RMSE(均方根误差)
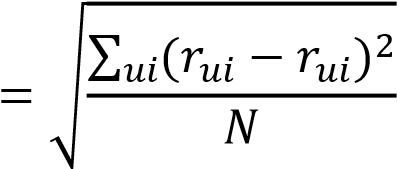
五、关键部分代码解析
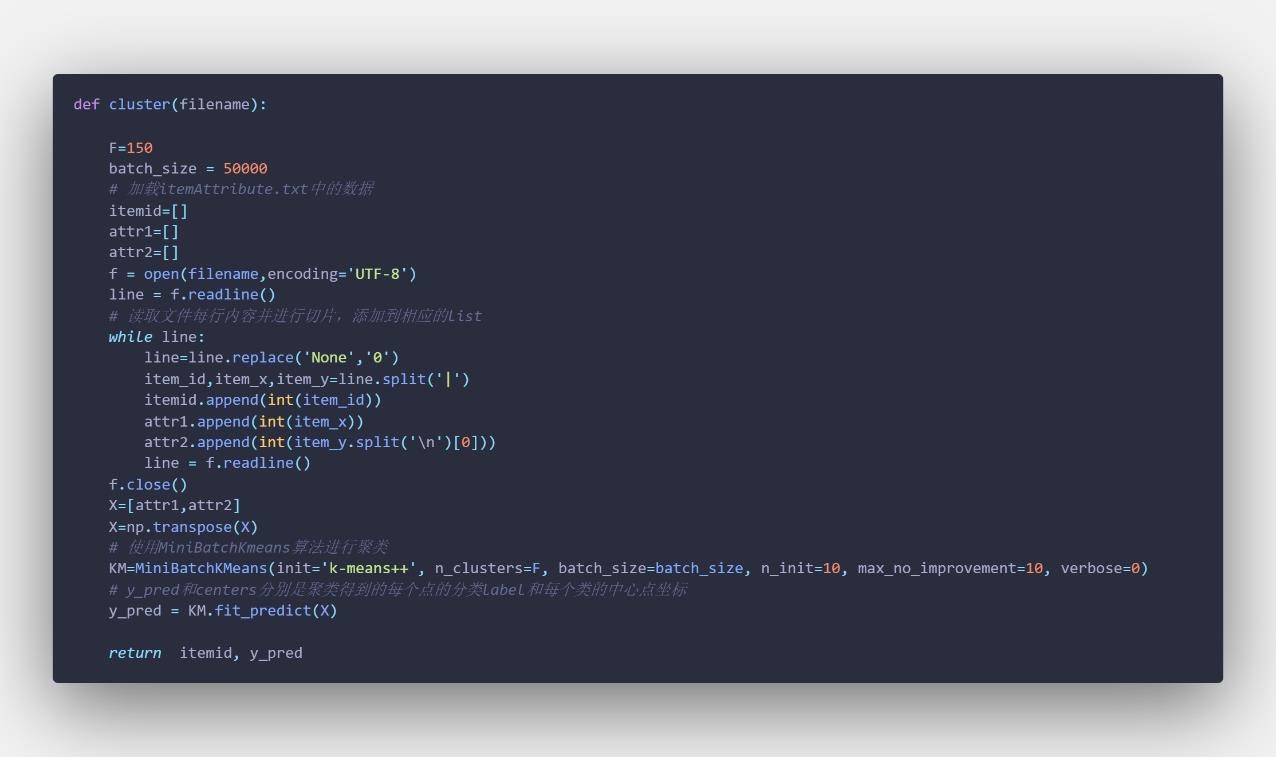
普通函数: myfind 函数:用来查找一个 list 里某个值的索引【关键】cluster 函数:(MiniBatchKmeans 聚类算法)根据 itemAttribute.txt 进行聚类,返回 itemid 的 list 和聚类得到的每个点的分类 label,代码如下
LoadTrainset 函数:加载训练集,主要两部分
根据 train.txt 生成元素为[userid, itemid, rate/10]的 rating_list 根据聚类结果,对评分数 <15 的 user 进行打分填充最后返回 rating_list,user 总数,item 总数LoadTestset 函数:加载测试集,根据 test.txt 生成元素为[userid, itemid]的test_list,返回 test_list
Trainset 类中的函数
get_all_ratings 函数:返回所有[userid, itemid, rate] list get_user_ratings 函数:返回某个 user 的所有[userid, itemid] listglobal_mean 函数:返回训练集所有打分平均值 construct_trainset 函数:从 train.txt 中加载数据并创建训练集,返回一个 Trainset 的对象。
SVD 类中的函数
InerProduct 函数:返回两个矩阵的内积。
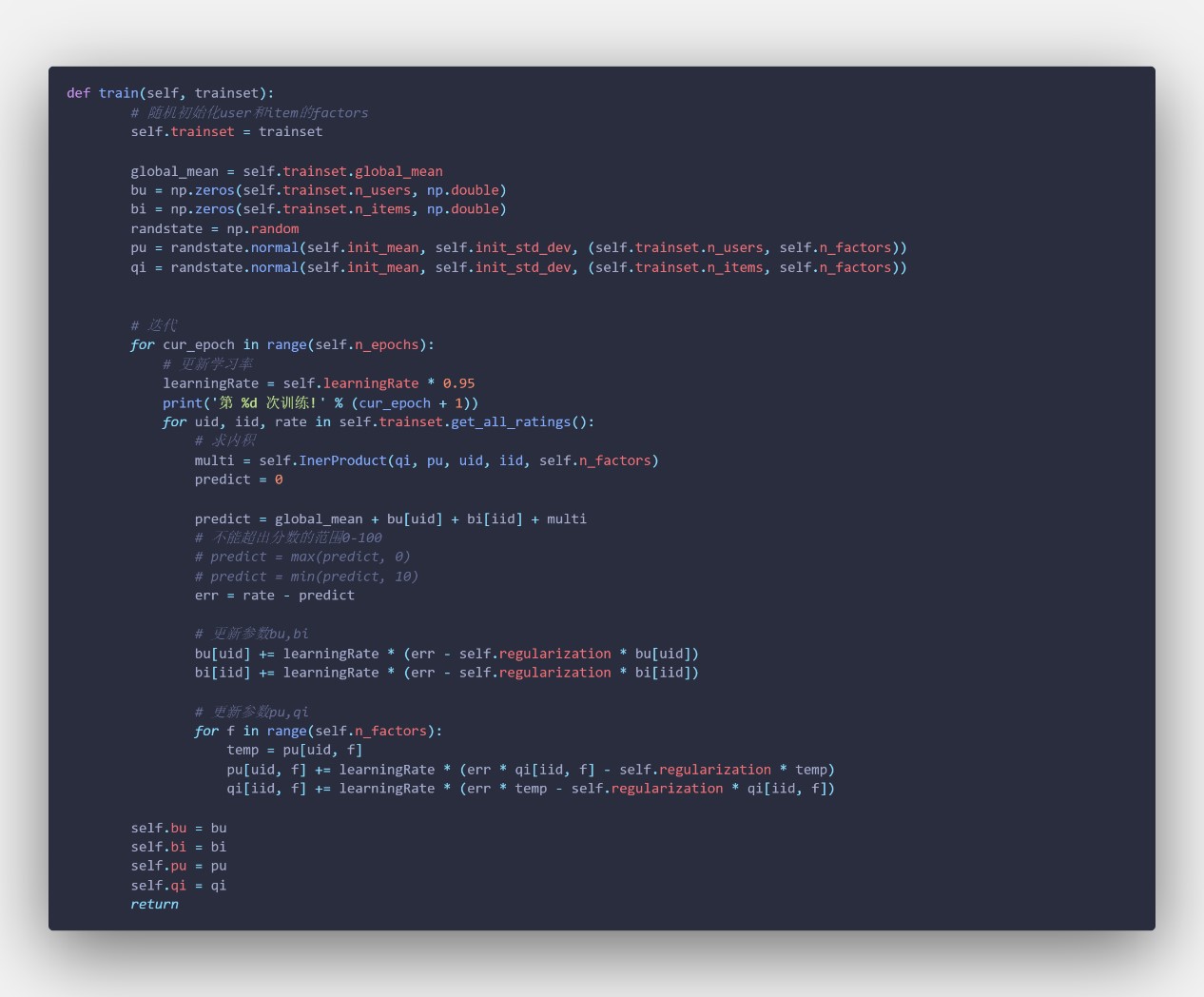
【关键】train 函数:SVD 算法,运用梯度下降进行训练,得到训练好的一系列参数值和矩阵,代码如下
【关键】predict 函数:对 test.txt 中未知的某对 u,i 对的打分进行预测(由于前面存储的已知打分值[rate/10],所以这里返回值要乘 10)返回打分值,代码如下
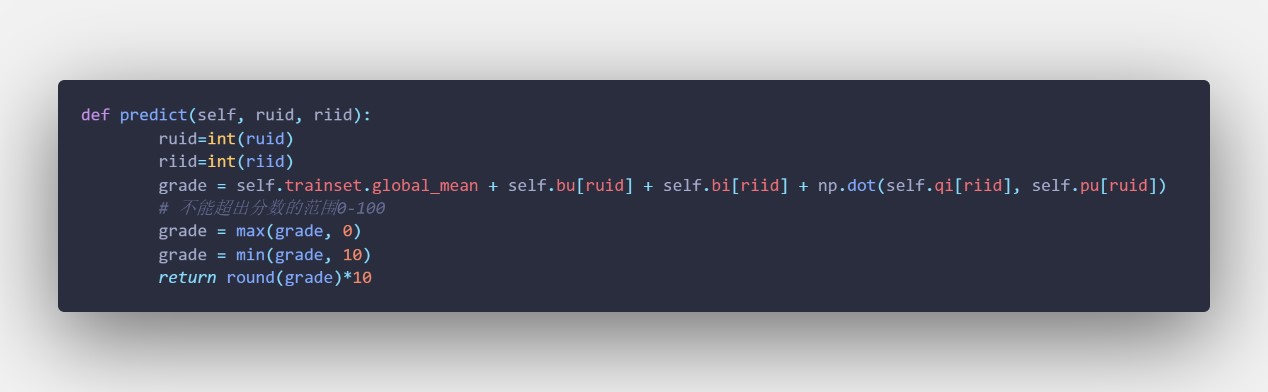
predict_all 函数:对 test.txt 中未知的所有 u,i 对进行打分预测,返回所有分值的 list
split_train_and_test 函数:根据 train.txt 分割出新的训练集和测试集,返回训练集 trainset 和测试集 testset。
RMSE 函数:计算均方根误差的函数
【关键】evaluation 函数:计算训练出的模型的均方根误差,返回均方根误差的值,代码如下
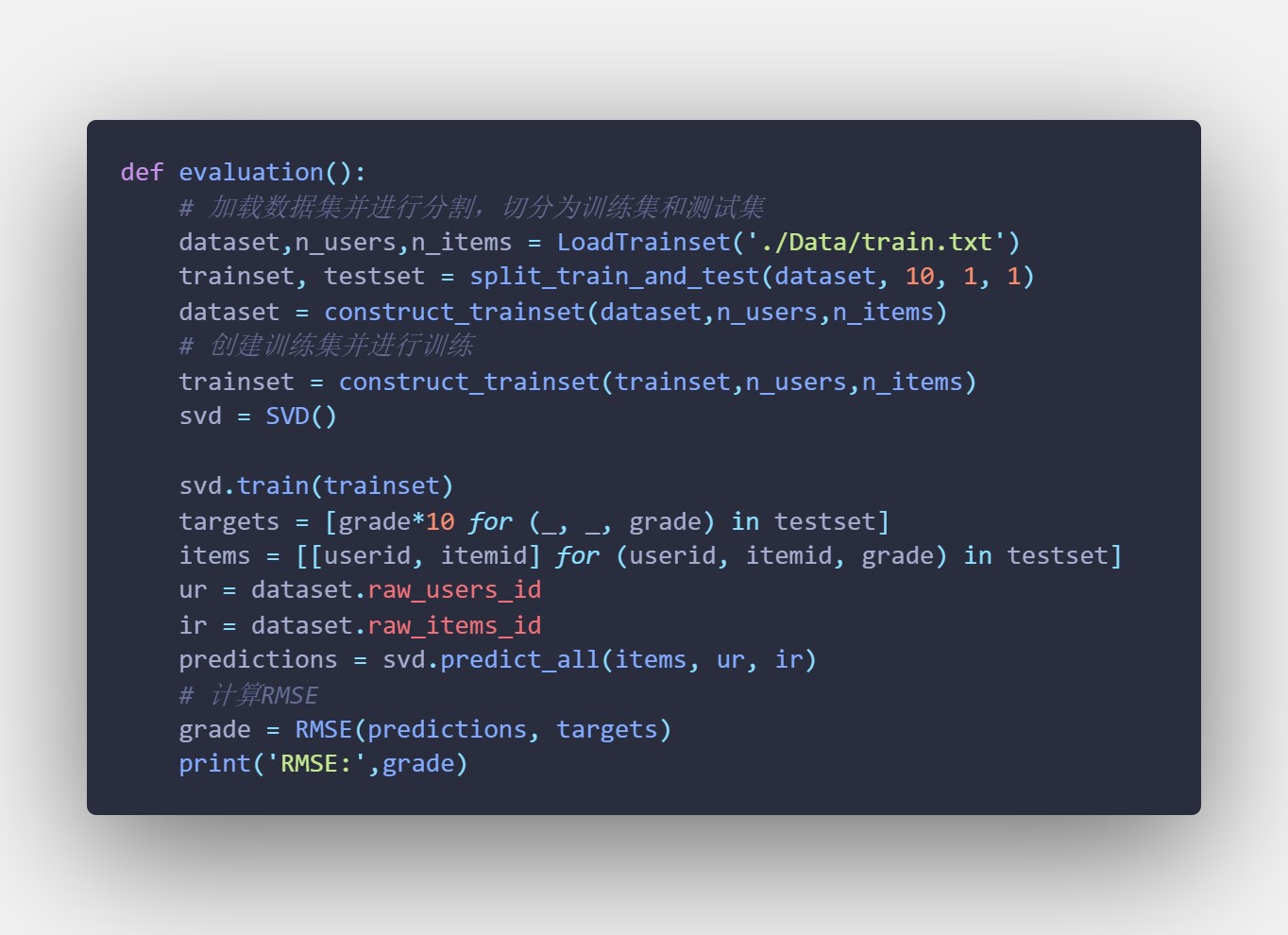
六、结果分析
我们将数据集随机分成训练集和测试集(训练集 9 成测试集 1 成),测试集上
RMSE 结果如下:

最后作为预测结果的 result 文档结构如下:
c++
<user id>|<numbers of rating items>
<item id> <score>
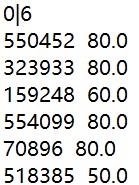
结果预览:(详情见 result.txt)
测试环境:

时间消耗:343s
空间消耗:2g
七、分析算法的改进与不足
初步测试中,由于参数设定的太大,消耗时间太长。
降低迭代次数,将评分范围缩小至【0,10】,同时引入 k-means 聚类,得以将时间缩短至 6min,rmse 也减小到 32。
考虑使用 tensorflow 来加速实现,但由于未知原因内存使用量太高而放弃。
参考文献
- 基于中小型电商平台的个性化推荐系统建模(华北电力大学(北京)·梁德祥)
- 个性化音乐推荐系统的设计和研究(武汉纺织大学·李丹丹)
- 基于Apache Spark的增强型奇异协同过滤推荐系统(北京交通大学·ADEM SEID AHMED)
- 基于中小型电商平台的个性化推荐系统建模(华北电力大学(北京)·梁德祥)
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- 面向软件知识学习平台的个性化推荐研究(山东大学·李琳)
- 基于短视频内容理解的用户偏好预测模型研究(北京交通大学·Muhammad Irbaz Siddique)
- 基于Hadoop的电子商务推荐系统的设计与实现(闽南师范大学·彭兴)
- 基于复杂网络的移动互联App应用推荐系统(复旦大学·汤浙斌)
- 基于Hadoop的电子商务推荐系统的设计与实现(闽南师范大学·彭兴)
- 融合多重注意力机制的深度推荐方法研究与应用(江苏科技大学·张宗海)
- 基于协同过滤的推荐算法比较研究(重庆大学·高寒)
- 基于混合模式的个性化推荐系统的研究与应用(武汉理工大学·梁洁)
- 基于组合算法的电子商务推荐系统的研究(西安工业大学·杨亚楠)
- 基于中小型电商平台的个性化推荐系统建模(华北电力大学(北京)·梁德祥)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码港湾 ,原文地址:https://m.bishedaima.com/yuanma/36034.html