
1. 问题描述
结合“Lecture 7 Segmentation”内容及参考文献[1],实现基于 Graph-based image segmentation 方法(可以参考开源代码,建议自己实现) ,通过设定恰当的阈值将每张图分割为 50~70 个区域,同时修改算法要求任一分割区域的像素个数不能少于 50 个(即面积太小的区域需与周围相近区域合并) 。结合GT 中给定的前景 mask,将每一个分割区域标记为前景(区域 50%以上的像素 在 GT 中标为 255)或背景(50%以上的像素被标为 0) 。区域标记的意思为将该区域内所有像素置为 0 或 255。要求对测试图像子集生成相应处理图像的前景标注并计算生成的前景 mask 和 GT 前景 mask 的 IOU 比例。假设生成的前景区域为 R1, 该图像的 GT 前景区域为 R2, 则IOU = (𝑅1∩𝑅2)/(𝑅1∪𝑅2)
2. 求解过程与算法
假设有无向图$G=(V,E)$,每条边有权重$w(v_i,v_j)$表示距离,$S$是原图的子图,有:$S=G'=(V,E')\quad E'\sub E$,且将$G$分到成了不同的集群。使用谓词$D$决定是否存在分段边界,也就是说,使用$D$作为标准判断不同集群的相似性,如果两个集群的集群间相似性小于集群内的相似性,则进行合并: $$ Merge(C_1,C_2)=\left{\begin{matrix} True,dif(C_1,C_2)<in(C_1,C_2)\ False,otherwise \end{matrix}\right.\ dif(C_1,C_2)=\min_{v_i\in C_1,v_j\in C_2,(C_1,C_2)\in E}w(v_i,v_j)\ in(C_1,C_2)=\min_{C\in{C_1,C_2}}[\max_{v_i,v_j\in C}[w(v_i,v_j)+\frac k{|C|}]] $$ 也就是说,如果两个集群中点的距离的最小值小于两个集群内的点的距离最大值更小的那一个则进行合并。其中$k/|C|$设置了内部节点的差异性。如果$k$较大,则集群规模往往更大,否则更小。
对于一张图像,我们可以将每个像素投影到特征空间$(x,y,r,g,b)$上,也就是坐标和颜色通道组成的特征空间。每个像素在八领域内与八个像素相邻,即具有边。边的距离由特征向量计算得出,一般用欧氏距离。
由此,我实现基于图的图像分割方法流程如下:
- 将图片的每个像素按照坐标和颜色投影到$(x,y,r,g,b)$特征空间上,初始时每个像素自身属于单独一个区域
- 计算所有边的权重大小,即八领域内像素的特征向量的欧式距离,并按照距离大小排序
- 按距离从小到大的顺序,依次将这些边两端的像素合并到同一个区域。能否合并依据上述的$Merge(C_1,C_2)$的公式判断
- 重复第3步,直到剩余区域数到达设置的下界
- 遍历剩下的区域,将像素数少于50个的区域和相邻的区域直接合并
由此就能得到划分好区域的图片。我们只需要记录每个区域所含的全部像素的坐标,由这些坐标找到前景图的相应位置,统计前景像素数和背景像素数就能确定该区域应该被判定为前景还是背景。
3. 代码实现与说明
该部分的代码全部由自己实现。
3.1 一些功能模块的实现
在实现算法主体流程前,可以预见到,程序需要用多种方式刻画像素和像素、像素和区域之间的关系。为了之后代码的简洁性,我先实现了部分功能模块方便多次调用。首先需要两个全局变量:
```python
用于查询某个片段内部的所有像素
SEG_GROUP = dict()
每个片段内的最大距离
INNER_WEIGHT = dict() ```
其中
SEG_GROUP
是字典,用于表示区域以及查询区域内的全部像素。如果像素坐标为
[x,y]
,则表示某个区域时,使用该区域中所有像素的
x
值最小的那个作为“代表”表示该区域。如果有多个
x
相同的像素,则找
y
值最小的。因此,
SEG_GROUP[(x1,y1)]=[(x1,y1),(x2,y2),...]
表示以
(x1,y1)
这个像素点为代表的区域中包含着
(x1,y1)
、
(x2,y2)
......这些像素点。该区域的键值只能用
(x1,y1)
表示,而不能用
(x2,y2)
等其他的像素点表示。因此
SEG_GROUP
的键值数量就表示了区域的数量。初始化时,该字典中包含所有像素坐标,且每个像素坐标对应的区域中只含有自己这一个像素。
而每个集合中需要计算集合内部的最大距离,即上述的$in(C_1,C_2)$中的$max(w(v_i,v_j))$,该值用
INNER_WEIGHT
表示,其键值也和上述的一样,用该区域的坐标最小的像素表示。实际的$in(C_1,C_2)$通过下面的函数实现:
```python
计算两个片段的片段内距离
def internalDif(coord1, coord2, img_array, segment_coord): global INNER_WEIGHT, SEG_GROUP coord1 = getSegment(coord1, segment_coord) coord2 = getSegment(coord2, segment_coord) k = 100 dist1 = INNER_WEIGHT[(coord1[0],coord1[1])] + k/len(SEG_GROUP[(coord1[0],coord1[1])]) dist2 = INNER_WEIGHT[(coord2[0],coord2[1])] + k/len(SEG_GROUP[(coord2[0],coord2[1])]) return min(dist1, dist2) ```
上述关系描述了如何用一个“代表像素”找到其对应的区域,然后区域就能用
SEG_GROUP
来查询该区域中所有的像素了。然而这只能由区域查询到像素,并不能直接知道某个像素属于哪个区域,因此我们还需要另一个字典
segment_coord
表示像素的所属区域。
segment_coord[(x1,y1)]=(x2,y2)
表示像素
(x1,y1)
的区域和
(x2,y2)
相同。每个像素的
segment_coord
初始化为自己,当两个区域合并时,只需要将一个区域的代表像素的
segment_coord
指向另一个区域的任一像素即可。这样一来,对于合并的两个区域,总有一个区域的代表像素是不变的,因此其
segment_coord
值总是指向自身。如此一来,当一个像素满足
segment_coord[(xi,yi)]=(xi,yi)
时,我们就能知道:该像素为代表像素,从而找到了该区域。如果不是,则可以查询上一个像素的
segment_coord
,直到键值和所指向的值相同。通过上述的合并规则不难发现,像素查询其实是一个树状结构,我们总能通过
segment_coord
查询到一个像素所在区域的代表像素,即:
```python
查询一个像素所属的区域
def getSegment(coord, segment_coord):
coord = np.array(coord)
tmp = coord.copy()
# 一直向上查询,直到找到代表像素
while (segment_coord[coord[0]][coord[1]] != coord).any():
coord = segment_coord[coord[0]][coord[1]]
# 直接将上一个像素指向代表像素以加速之后查找
segment_coord[tmp[0]][tmp[1]] = coord
return np.array((coord[0], coord[1]))
```
合并的代码如下,需要提供合并的两个区域分别的任一像素。
flag
用于控制是否更新区域内最大距离。在合并不足50个像素的区域时,因为之后不需要用到区域内最大距离,因此不进行计算,可以进行一定的加速。
```python
合并两个区域
def mergeSegment(coord1, coord2, img_array, segment_coord, flag=True): global INNER_WEIGHT, SEG_GROUP # 查询这两个像素所在区域的代表像素 coord1 = getSegment(coord1, segment_coord) coord2 = getSegment(coord2, segment_coord) # 更新区域代表 segment_coord[coord2[0]][coord2[1]] = coord1 # 更新区域内部最大距离 if flag: if (coord2[0],coord2[1]) in INNER_WEIGHT.keys(): del INNER_WEIGHT[(coord2[0],coord2[1])] for vi in SEG_GROUP[(coord1[0],coord1[1])]: for vj in SEG_GROUP[(coord2[0],coord2[1])]: tmp = distance(vi,vj,img_array) if tmp > INNER_WEIGHT[(coord1[0],coord1[1])]: INNER_WEIGHT[(coord1[0],coord1[1])] = tmp # 合并区域,删除原来的区域 SEG_GROUP[(coord1[0],coord1[1])] += SEG_GROUP[(coord2[0],coord2[1])] del SEG_GROUP[(coord2[0],coord2[1])] return ```
有了上述操作后,我们可以通过查询两个像素所属区域的代表像素,通过二者的代表像素是否相同,来判断二者是否在同一个区域中。如果当前检索到的两个顶点属于同一个区域,则不需要进行合并操作。判断像素是否属于同一区域的代码如下:
```python
判断两个像素是否属于同一个区域
def isSameSegment(coord1, coord2, segment_coord): coord1 = getSegment(coord1, segment_coord) coord2 = getSegment(coord2, segment_coord) return (coord1 == coord2).all() ```
除此之外,还需要计算任意两个像素距离的函数。依据这两个像素的坐标和RGB颜色值,将二者转换到$(x,y,r,g,b)$空间,再计算欧氏距离,即特征向量各个分量相减后求平方和再开根即可,可以通过调用
numpy
模块中的范式功能实现,代码如下:
```python
计算两个相邻像素在特征空间(x,y,r,g,b)的欧式距离
def distance(coord1,coord2,img_array): vec1 = np.array([coord1[0],coord1[1],img_array[coord1[0]][coord1[1]][0], img_array[coord1[0]][coord1[1]][1],img_array[coord1[0]][coord1[1]][2]]) vec2 = np.array([coord2[0],coord2[1],img_array[coord2[0]][coord2[1]][0], img_array[coord2[0]][coord2[1]][1],img_array[coord2[0]][coord2[1]][2]]) return np.linalg.norm(vec1-vec2) ```
3.2 分区算法实现的主体部分
算法实现的主体部分由函数
segment
实现。首先,对各个变量进行初始化操作,包括将区域数量初始化为总的像素数、将
segment_coord
字典初始化为各个像素自身的坐标、每个区域内部的距离为0:
```python
初始时,区域数等于像素数
segment_num = img.size[0] * img.size[1]
segment_coord[i][j]表示i,j位置的像素属于的区域,用一个统一的坐标表示
segment_coord = np.zeros((img_array.shape[0], img_array.shape[1],2)).astype(np.int16) for i in range(img_array.shape[0]): for j in range(img_array.shape[1]): # 初始时,每个像素属于自己所在的区域 segment_coord[i][j] = [i,j] SEG_GROUP[(i,j)] = [(i,j)] INNER_WEIGHT[(i,j)] = 0 ```
每次合并时,我们需要找到权值最小的边,将边两边的像素所属的区域进行合并。为了防止繁琐的权重计算和排序,我考虑一开始将所有的边的权重都计算出来,并且进行从小到大的排序,从而就能由小到大的权值依次遍历各个边,对像素区域进行合并:
```python
计算所有边的权重并按大小排序
weight = [] for i in range(img_array.shape[0]): for j in range(img_array.shape[1]): # 每个像素只计算四个方向的边,防止重复 if j < img_array.shape[1]-1: # 右边的邻居 weight.append([(i,j),(i,j+1),distance((i,j),(i,j+1),img_array)]) if i < img_array.shape[0]-1:# 右下的邻居 weight.append([(i,j),(i+1,j+1),distance((i,j),(i+1,j+1),img_array)]) if i < img_array.shape[0]-1: # 下边的邻居 weight.append([(i,j),(i+1,j),distance((i,j),(i+1,j),img_array)]) if j > 0: weight.append([(i,j),(i+1,j-1),distance((i,j),(i+1,j-1),img_array)]) weight.sort(key = lambda x:x[2]) ```
需要注意的是,所谓的“边”只能出现在某个像素的八邻域内,也就是说,如果不出界的话,每个像素只能和它左上、上、右上、左、右、左下、下、右下这八个相邻的像素连接。当遍历每个像素,将像素延伸出去的这八条边都考虑进去的话,每条边会计算两次,从而产生重复。考虑到每个条的表示方法为
[(顶点1坐标),(顶点2坐标),边的权重]
,遍历每个像素时只考虑它右边的和下面一排的共四个像素产生的边,这样可以保证每条边只计入一次,且顶点1和顶点2的坐标是按照升序顺序排列的。当然,边界情况要另外讨论。
然后就能开始进行图片的区域合并了。因为事先实现了上面的功能模块,这里基本只需要进行简单的调用即可。从小到大依次遍历各个边,如果该边的两端的顶点像素不属于同一个区域,且满足在理论部分提及的$Merge(C_1,C_2)$条件的话,就对二者进行合并。因为之后还要合并像素少于50个的区域,所以这里是对整个图片区域的初步划分,当区域数量小于一定值就退出循环。该值我对不同的图片进行了不同的设置,即代码中的
SEGMENT_NUM
变量:
```python t = 0
当分割区域小于等于某个值则退出(初步划分保证区域小于该值)
while segment_num > SEGMENT_NUM[pid]: # 每次挑选一条距离最小的边 if t>=len(weight): break coord1 = weight[t][0] coord2 = weight[t][1] # 如果该边的两个顶点属于同一区域则跳过 if isSameSegment(coord1, coord2, segment_coord): t += 1 continue # 如果两个顶点属于两个不同的区域则依据条件合并 if weight[t][2] < internalDif(coord1, coord2, img_array, segment_coord): mergeSegment(coord1, coord2, img_array, segment_coord) segment_num -= 1 t += 1 ```
如此一来,就实现了区域的初步划分。然后需要将小于50个像素的区域进行合并操作。考虑到50个像素对于原图来说相当小,我选择将这类像素与相邻的区域进行随机合并。具体做法是,遍历该区域内的全部像素,如果当前像素的上、下、左、右相邻的像素与当前像素不属于同一个区域,则将二者的区域进行合并。具体实现如下:
```python
清除所有像素少于50个的区域(第二次划分去除小区域)
flag = False flag2 = True while flag or flag2: flag = False flag2 = False for seg in SEG_GROUP.keys(): if len(SEG_GROUP[seg]) < 50: flag = True for pixel in SEG_GROUP[seg]: if pixel[0]!=0 and (not isSameSegment(pixel,(pixel[0]-1,pixel[1]), segment_coord)): mergeSegment(pixel,(pixel[0]-1,pixel[1]), img_array, segment_coord, False) break if pixel[1]!=0 and (not isSameSegment(pixel,(pixel[0],pixel[1]-1), segment_coord)): mergeSegment(pixel,(pixel[0],pixel[1]-1), img_array, segment_coord, False) break if pixel[0]!=img_array.shape[0]-1 and (not isSameSegment(pixel,(pixel[0]+1,pixel[1]), segment_coord)): mergeSegment(pixel,(pixel[0]+1,pixel[1]), img_array, segment_coord, False) break if pixel[1]!=img_array.shape[1]-1 and (not isSameSegment(pixel,(pixel[0],pixel[1]+1), segment_coord)): mergeSegment(pixel,(pixel[0],pixel[1]+1), img_array, segment_coord, False) break break ```
这里
flag
和
flag2
变量分别用于表示当前是否有小于50个像素的区域和循环是否是第一次启动。当像素所属区域合并时,遍历的字典
SEG_GROUP
的键值会改变,继续迭代访问键值会报错,因此合并后不能继续找下一个区域,而是需要重新遍历全部的区域。
到目前为止,整张图片的区域就已经划分完成了。在字典
SEG_GROUP
里记录了所有的区域(用代表像素表示),通过代表像素,也可以查询到每个区域内全部的像素。我将不同区域上了不同的颜色作为中间结果输出,此部分比较简单且与算法无关,就不在报告中赘述。
3.3 依据分区和前景图给区域打标签
标记部分由下面的
segmentGround
函数实现。通过
SEG_GROUP
遍历每个区域,对于每个区域,遍历每个像素,查找这个像素在给出的前景图中的位置,为黑则
black
加一,为白则
white
加一,如果黑色更多则该区域全部划为黑色,否则为白色:
```python
标记前景背景
def segmentGround(ground): ground_array = np.array(ground).astype(np.int8) result = np.zeros(ground_array.shape).astype(np.int8) # 遍历每个区域 for seg in SEG_GROUP.keys(): black = 0 white = 0 # 统计该区域像素在前景图中的颜色 for pixel in SEG_GROUP[seg]: if ground_array[pixel[0],pixel[1]] == 1: white += 1 else: black += 1 if white > black: for pixel in SEG_GROUP[seg]: result[pixel[0],pixel[1]] = 255 return result ```
3.4 计算IOU
该部分的代码被我在
IOUcalc.py
文件中实现了,和上面的代码不在同一份代码中。计算IOU,即利用上面的代码得到的前景图和实际的前景图,计算二者前景的交集和并集,再用交集大小除以并集大小。只需要遍历整张图片的全部位置,如果当前像素在两张图中全为白,则交集大小加一;如果当前像素在两张图中至少有一个为白,则并集大小加一,最终计算二者的商即可。代码实现如下:
python
def IOU(ground, output):
ground_array = np.array(ground)
output_array = np.array(output)
intersection = 0 # 前景交集
union = 0 # 前景并集
for i in range(ground_array.shape[0]):
for j in range(ground_array.shape[1]):
if ground_array[i,j] == 1 and output_array[i,j] == 1:
intersection += 1
if ground_array[i,j] == 1 or output_array[i,j] == 1:
union += 1
return intersection / union
4. 结果展示与分析
本题的IOU结果可以运行
IOUcalc.py
得到,图片结果放在下面的文件夹中:
output\ImageSegmentation
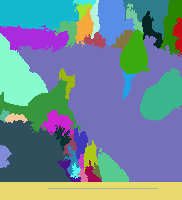
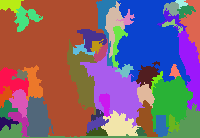
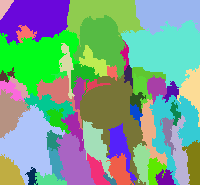
结果展示如下,分别为原图、区域图、最终的前景图:



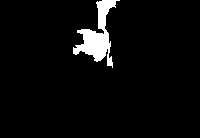





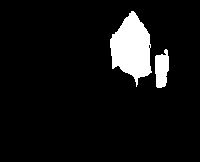


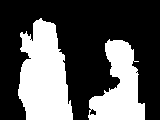


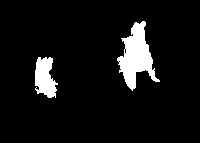




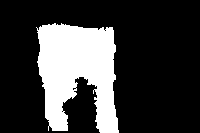




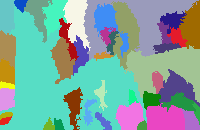
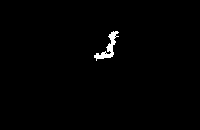
最终计算得到的IOU结果如下:

总的来说,结果有好有坏。对于较好的结果,如下图所示(编号657的图片),可以看出,前景部分,即图片中的主体,拥有大块的相同颜色的区域,且能够和背景区分开来。消防栓为大片的白色,两边的手套为天蓝色,而背景确实大片的绿地和后面的灰色地板:
而对于下面的效果较差的图片(编号957的图),图中的动物和所在的树枝颜色极为相近,很容易混淆。相对来说,右下的树叶和右上的墙体颜色区分更加明显,也就更容易被划分出来:
而对于下面的图(编号为57的图),还可以发现一点:图中左边的黑猫、两只鹅因为全身颜色相近,猫为黑,鹅为白,且与背景有明显区别,因此被区分出来,效果较好。而下方的花猫,身上的花纹颜色多变,容易在分区时被分成许多小块,然后在像素数少于50个的区域进行合并时,合并到背景所属的区域中,因此效果较差。
从上面三张图片的分析,不难看出,该基于图的图片分区算法的确能有效对图片内容进行划分,但总的来说,更加适合图片主体颜色较为单一、且主体与背景颜色有明显不同的情况。
参考文献
- 基于深度学习的字符验证码识别研究(青岛科技大学·张敬勋)
- 基于生成对抗网络的声纳图像分割技术研究(中国舰船研究院·淦智权)
- 基于深度学习的抽象画推荐系统(北方民族大学·唐延辉)
- 基于颜色特征的图像检索系统设计与实现(沈阳工业大学·邸洪波)
- 基于知识图谱的图像分割算法研究(福建农林大学·净淏泽)
- 基于视觉特征与机器学习的图像分类和图像检索方法研究(西安电子科技大学·王博)
- 基于深度学习的图像纹理分类在三维重建中的应用(内蒙古大学·王琳璇)
- 基于文本挖掘的视频标签生成及视频分类研究(上海交通大学·吴雨希)
- 基于深度学习的脑部肿瘤医学图像分割模型研究(广东技术师范大学·潘陆海)
- 面向计算摄影的图像源取证系统的设计与实现(北京邮电大学·李淼琛)
- 基于改进U型网络的皮肤病变图像分割算法研究(河北大学·宋子安)
- 基于手机的分布式图片检索技术研究(电子科技大学·冯喆)
- 基于深度学习的医学图像分割算法研究(云南大学·张伋)
- 模型可视化技术在腰椎影像分割中的应用研究(华南理工大学·吴梦林)
- 深度学习在肖像分割中的研究与应用(北京化工大学·张树恒)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码向导 ,原文地址:https://m.bishedaima.com/yuanma/36073.html









