从零开始写高性能的人脸识别服务器
一、项目介绍
如今AI的应用越来越广,但是对于AI产品技术的部署落地是一个很多人都会忽视的地方,因为大部分的AI服务都是基于Python的,将基于Python的AI程序如何部署到Web或者其他平台是一个问题,本专栏将从零开始写一个高性能支持高并发的人脸识别服务器。因为本人的技术栈是Java,所以使用Java的高性能网络IO模型库Netty进行服务器的开发,AI的模型大部分都是Python进行开发的,所以也使用了基于Python的人脸识别框架**face_recoginize**用来开发人脸识别的微服务。由于AI模型的加载一般都很耗时,所以把Python的AI程序做成微服务,服务器和AI微服务之间通过redis队列进行通信。
1 技术选型
Java 高性能网络模型框架首选 Netty。人脸识别程序选用基于 Python 的人脸识别库 face_recoginize .选用 Redis 做消息队列。因为模型在预加载是会很耗时,所以将 Python 人脸识别程序包装成微服务。
由于 Python 全局解释器锁(GIL)的存在,解释器解释执行任何 Python 代码时,都需要先获得这把锁才行,在遇到 I/O 操作时会释放这把锁。如果是纯计算的程序,没有 I/O 操作,解释器会每隔 100 次操作就释放这把锁,让别的线程有机会执行(这个次数可以通过 sys.setcheckinterval 来调整)。所以虽然 CPython 的线程库直接封装操作系统的原生线程,但 CPython 进程做为一个整体,同一时间只会有一个获得了 GIL 的线程在跑,其它的线程都处于等待状态等着 GIL 的释放。也就是说,对 Python 而言,计算密集型的多线程,其实性能和单线程是一样的。解决方法就是同时运行多个 Python 程序,也就是采用多进程的方式。
Java 服务器收到数据之后,将数据存储在 Redis 的 key1 中,此时产生一个 key2(存储 Python 程序的处理结果)。Java 使用随机数获取随机的处理进程。将 key1 存储到该进程监听的队列中,然后 Java 监听 key2 获取 Python 进程的处理结果,拿到结果之后返回给客户端。
客户端我写了 C 的和 HTML 的。C 的程序使用的是 Qt5.9.9 + opencv-2.4.11 + protobuf-3.1.0 , 之所以这样选,是因为之前是基于 QT5.14 开发的,后面发现程序写完之后发给导师,导师的电脑是 win7,程序打开就崩溃,这也是为啥都说华为现在还在用 VS2013 的原因,因为只有 MSVC2013 版本的才可以兼容 win7 和 win10。然后选择 MSVC2013 之后,Protobuf 的版本就不能太高,因为高版本的 Protobuf 都是基于 C++11 的高级特征,MSVC 只支持一小部分的 C++11 特征,所以使用高版本的会因为不兼容而出错。
因为本菜鸡还不懂架构的一些东西,所以这里的 Redis 做消息队列处理的比较垃圾,架构很垃圾。基本结构如下:

2 环境准备
技术选型定好之后,我们接下来准备环境,Java的环境不用具体介绍了,编译环境我用的是idea,基于maven开发的。下面我们根据教程来做安装,如果不想做C客户端的可以绕过QT的那一部分。
2.1 安装 face_recoginize
需要注意的是 一定要用 Python3.6 版本 ,版本不符合会出现各种各样的问题,dlib 版本一定要选择 19.7.0 的,要不然会出现各种问题。下面介绍一下 win10 环境下的安装。Linux 下的 安装地址
(1)创建 anaconda python3.6 环境
shell
conda create --name your_env_name python==3.6.0
(2)安装 dlib
必须是 19.7.0 版本,不要直接写“pip install dlib”。这样会安装最新的版本。
shell
pip install dlib==19.7.0
(3)安装 face_recognition
shell
pip install face_recognition
至此就大功告成了。
2.2 安装 Redis
本项目中用到了 Redis,所以大家需要安装 Redis,Linux 环境下的直接百度搜安装教程一大堆。window 版本的 git: 下载地址 。安装完之后,Python 要安装 Redis 模块。
2.3 Qt5.9.9 的安装
这里是安装 C 客户端的程序,如果不需要客户端的程序,可以直接跳过。
Qt 安装直接去百度搜就可以搜到一大堆,在安装的时候选择 MSVC2013。需要注意的是,Qt 想开发 MSVC 环境下编译的程序, 必须要下载相应版本的 VS2013,要不然没法进行编译 ,Qt5.9.9 使用的是 MSVC2013,所以要下载 vs2013。
没用过 Qt 的小伙伴可能会遇到 Debug 不可以调试的错误,Qt 项目页选择 MinGW 编译器方式,编译 debug 和 release 版本运行后都可以正常运行,如果是 MSVC 编译器方式,release 版本编译后能正常运行,debug 版本编译正常,但是运行会异常退出,调试弹出 The CDB process terminated 提示框。
解决方法是安装安装 CDB 调试器时,下载 Windows SDK 安装包 ,只需要安装其中的"Debugging Tools for Windows“。如果在遇到其他问题,就百度一下解决方案,这个项目是半年前写的,这段时间有时间我就开源,一些细节啥的忘记了。只记得 这篇博客 帮了我很多。
3 效果演示
前端写的比较简陋粗糙,因为重心不在前端页面上。注意 Web 展示的时候我用的本地的 HTML。如果想要在网络地址中使用电脑摄像头,网络地址得支持 Https 协议。
3.1 Web 端展示
由于 CSDN 上传 Gif 文件有大小限制,所以我这里直接上截图了
(1)请求摄像头权限
 (2)点击拍照,截取图像
(2)点击拍照,截取图像
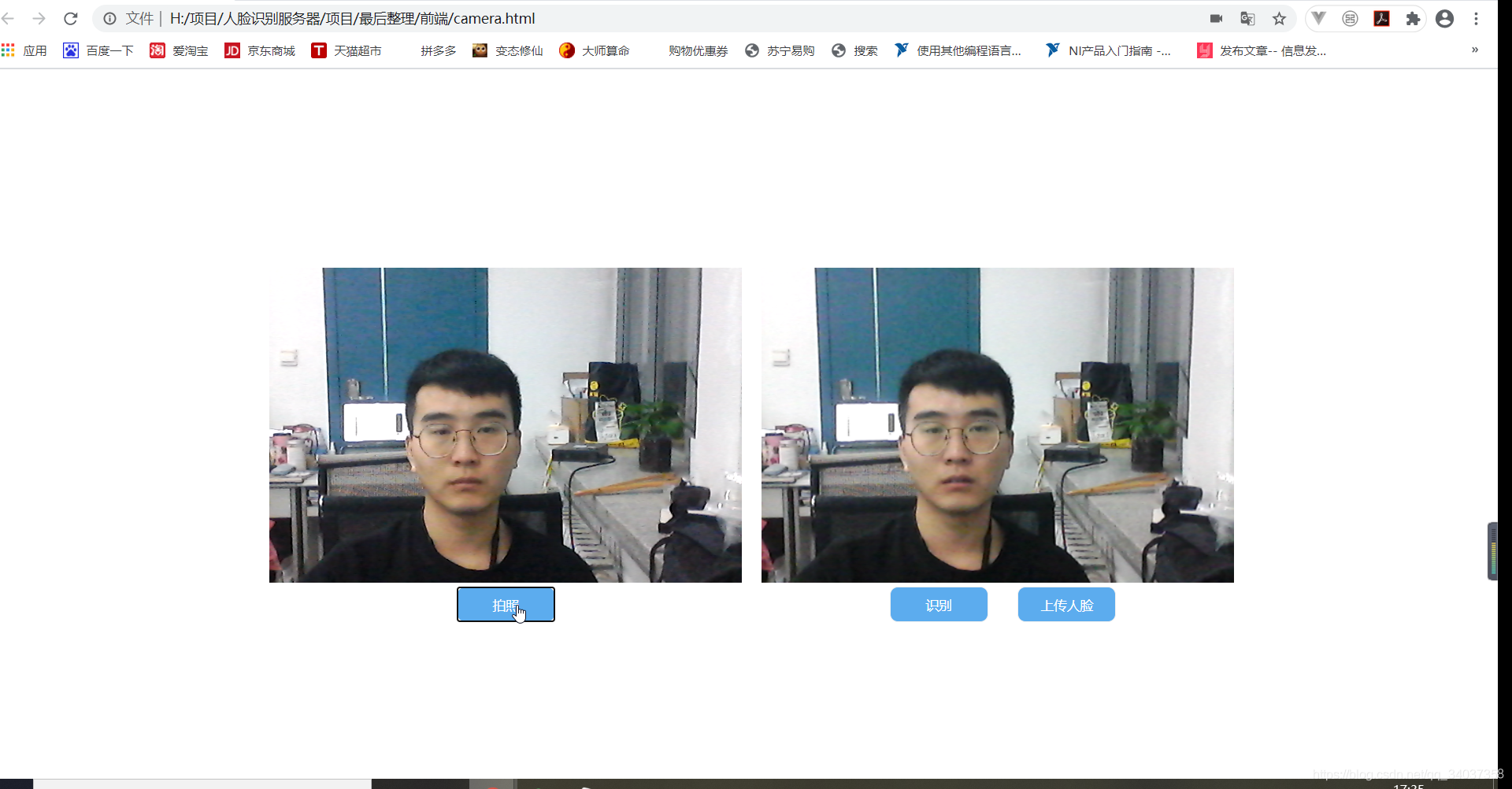 (3)上传人脸
(3)上传人脸
点击上传人脸,在弹出的对话框里面输入自己的姓名
 (4)点击确定显示上传成功
(4)点击确定显示上传成功

(5)点击识别,进行人脸识别

3.2 Qt 客户端展示
Qt 客户端使用了 OpenCv 调取电脑摄像头。
(1)上传人脸

(2)人脸识别

二、高并发高负载解决
在这一章,我将带领大家从以下三个方面了解一下项目是如何承载高并发与高负载的,分别是高性能的网络 IO 模型、Protobuf 序列化协议以及 AI 模型多进程微服务。Netty 据说可以承受百万级的并发,使用 Protobuf 序列化传输数据,提升数据的传输效率。
1 高性能服务器架构
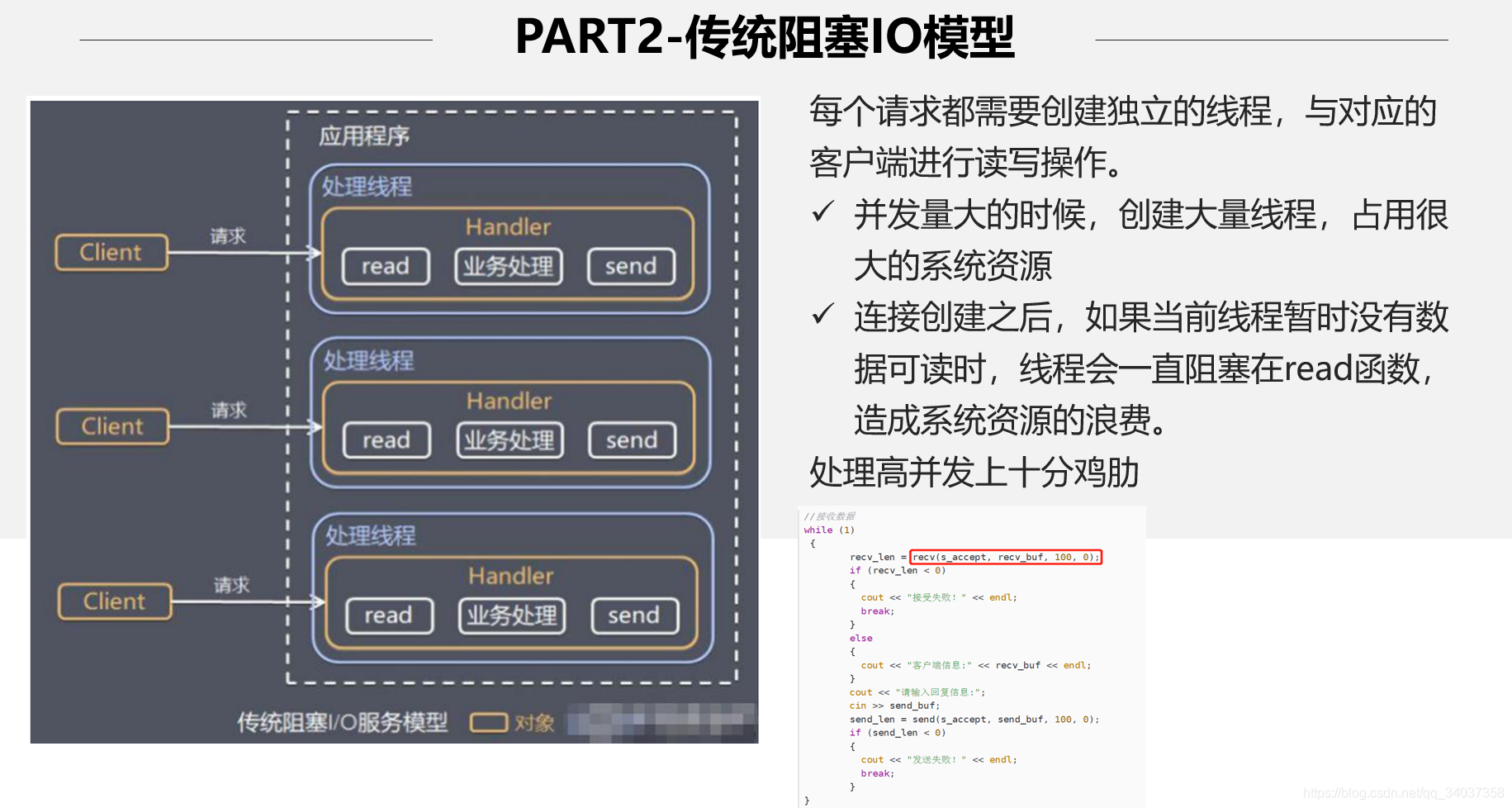
Java 服务器架构的发展从一开始的 BIO,发展到 NIO,再发展到如今基于 NIO 的 Netty。相信大家如果不理解 Netty 的话,应该也写过 socket 通信(没写过 socket 通信的,麻烦去学习一下谢谢),如果一次性有上万个请求过来,你启动了上万个线程去处理请求,此时你的机器就炸了,Linux 最大支持两千个线程,想支持更多,就得去改配置文件。而且一台机器能承受的线程数是有限的,当线程数量超过一定数量时,系统就会崩溃。
1.1 BIO
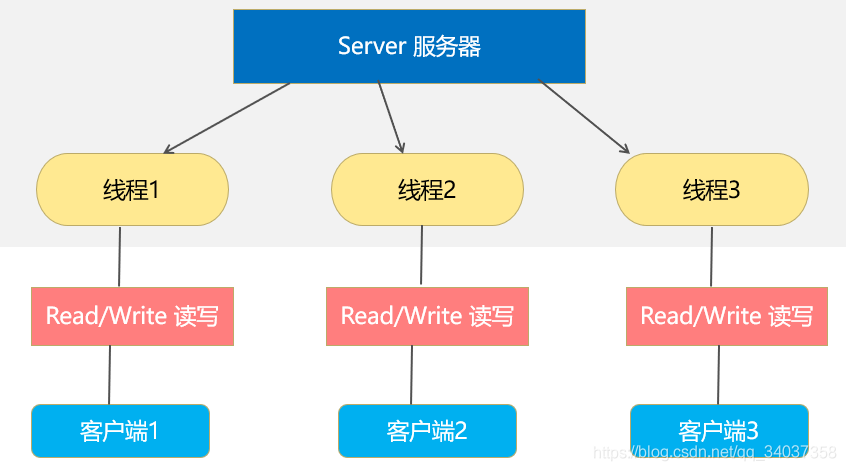
同步并阻塞式(传统阻塞式);服务器实现为一个连接一个线程,即客户端有连接请求时,服务器就启动一个线程进行处理,如果连接不做任何事情,就会造成不必要的开销。
1.2 NIO
同步非阻塞式(传统阻塞式);服务器实现为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到 多路复用器 上,多路复用器轮询到连接有 I/O 请求就进行处理
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

1.3 架构发展

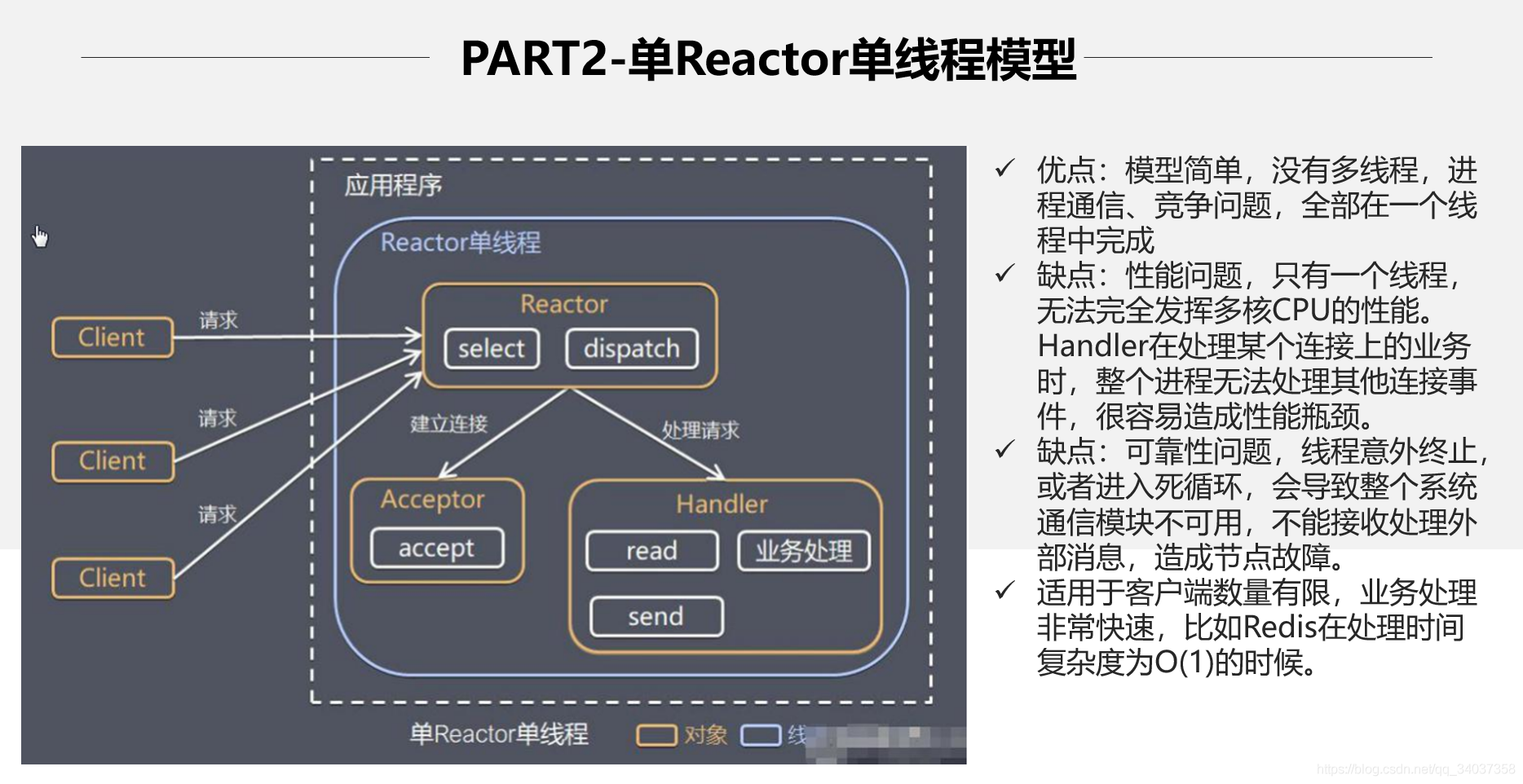

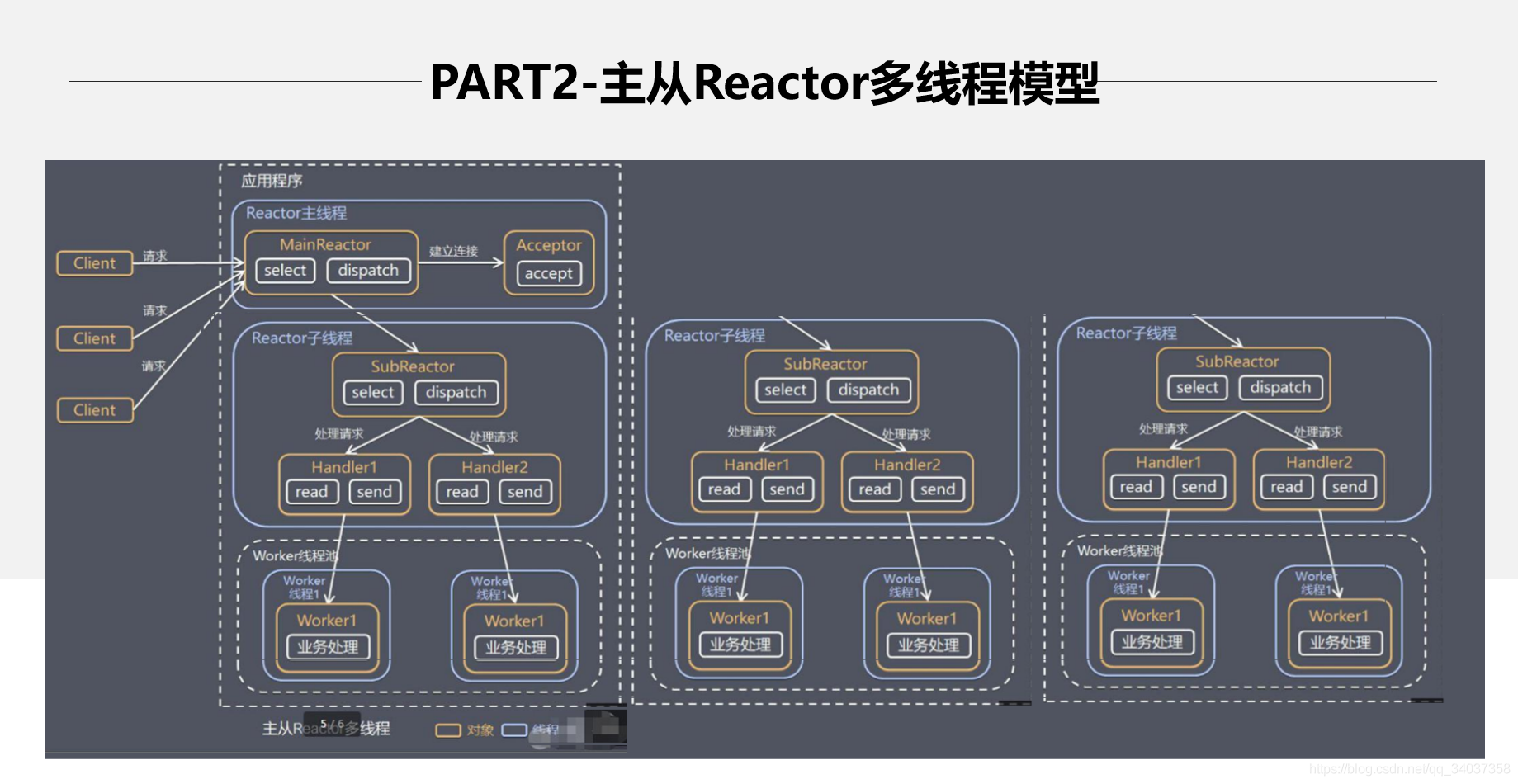
主从 Reactor 多线程模型,将使用两个 selector,一个主 selector 专门维护 accept 事件,当接收到 accept 事件,将该连接交给从 selector,从 selector 维护该连接的 read 和 write 事件。主从 selector 的方式,将连接和数据处理完全分开维护,将大大提高并发量 Netty 就是使用的这种网络模型。
1.4 网络 IO 模型对比

因为连接请求的处理速度很快,所以前台一般留一个线程负责处理 accept 请求。剩下的前台负责接受 read/write 请求,然后根据请求的内容去交给指定的服务员处理。当然主从模型的数量都是可以自己指定的。
2 Protobuf 序列化协议
上面看完了高性能的网络模型架构。我们接下来看如何在消息传输上提高效率。本小节的主人公便是 Protobuf。下面我们一步步的解开她的面纱。首先我们来看什么是序列化与反序列化。
2.1 什么是序列化与反序列化
从广义上来说,序列化就是将结构化数据(对象)转换为一种中间格式,利用这种中间格式进行数据的存储与传输,反序列化则是将这种中间格式转换为结构化数据(对象),常见的跨语言的序列化协议有 XML, JSON 等,以及一些语言内部私有的序列化协议, 如 IAVA 的 Serialiable 序列化。
2.2 传统的序列化方法的优缺点
XML. JSON 等传统序列化方式能够流行起来自然有它们优秀的一面,比如说跨语言,易于阅读(人类直接可读),学习成本低等等。但是它们的缺点也是显而易见的,那就是体积过于庞大,有很多冗余字段,以 JSON 为例子,序列化后的大括号,双引号等都简要进行传输,存在极大的空间浪费。尤其是在对性能与带宽要求比较苛刻的场景下是不能够被接受的,比如游戏,即时通讯等领域。再比如某些语言内部私有序列化协议,序列化后也存在体积过大井且不能夺语言通信等问题,比如 Java 语言的序列化。
<person>
<name>马善涛</name>
<age>24</age>
<tellphone>110120114</tellphone>
</person>
{
"name":"马善涛",
"age":"24",
"tellphone":"110120114"
}
2.3 何为 Protobuf
是谷歌开源的,官方在此,要翻墙,一种与语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10 倍)、更快(20 ~ 100 倍)、更为简单。你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
说白了,Protobuf 就是消息序列化工具,与语言无关、可以跨语言,可以由 Java 或者 C++ 语言序列化,交由 C++ 或者 Python 进行反序列化。比 XML、JSON 等常见的序列化工具效率都高,当然 XML 和 JSON 的效率不高是人尽皆知的事情了!!Protobuf 现在也是大部分 RPC 框架的序列化格式,因为效率高嘛!但是,在 IPC 摄像头上面,Onvif 的私有协议的远程 RPC 传输格式竟然还是 XML!所以说控制摄像头的云台移动,摄像头会很卡。Protobuf 的工作原理如下图所示
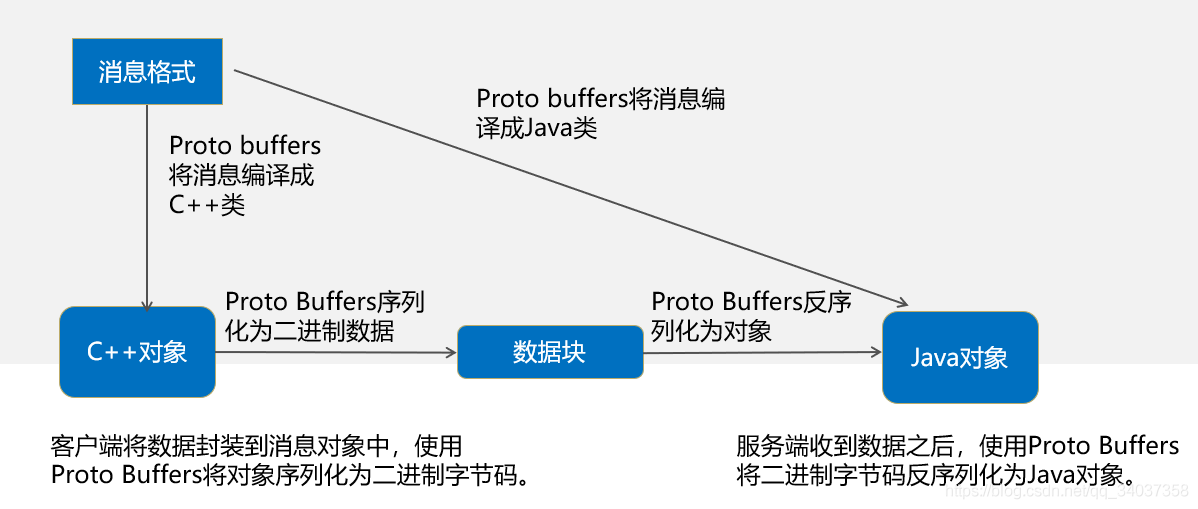
2.4 Protobuf 效率对比
下面通过几个例子比较一下各个序列化方式。
2.4.1 JSON 序列化
(1)定义 Student 类
``` public class Student {
String name;
int age;
String school;
String tellphone;
String email;
int weight;
String homeAddress;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSchool() {
return school;
}
public void setSchool(String school) {
this.school = school;
}
public String getTellphone() {
return tellphone;
}
public void setTellphone(String tellphone) {
this.tellphone = tellphone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
public String getHomeAddress() {
return homeAddress;
}
public void setHomeAddress(String homeAddress) {
this.homeAddress = homeAddress;
}
}
```
(2)序列化
``` public class Test {
public static void main(String[] args) {
Student student = new Student();
student.setAge(24);
student.setEmail("1205006751@qq.com");
student.setHomeAddress("山东省济南市");
student.setName("马善涛");
student.setSchool("哈尔滨理工大学");
student.setWeight(135);
student.setTellphone("110120114");
String json = JSON.toJSONString(student);
System.out.println(json);
// 数据在传输过程中是以二进制的方式传输
byte[] bytes = json.getBytes();
System.out.println(bytes.length);
}
} ```
{"age":24,"email":"1205006751@qq.com","homeAddress":"山东省济南市","name":"马善涛","school":"哈尔滨理工大学","tellphone":"110120114","weight":135}
162
可以看到 JSON 序列化之后的数据长度为 162 个字节。
2.4.2 Protobuf 序列化
(1)定义 Protobuf 消息
``` syntax = "proto3"; // proto3 必须加此注解 option java_package = "xin.marico.facerecogition.test"; option java_outer_classname = "StudentProto";
message Student { string name = 1; int32 age = 2; string tellphone = 3; string email = 4; int32 weight = 5; string homeAddress = 6; string school = 7; } ```
(2)编译成 proto 类
shell
protoc.exe --java_out=./ StudentProto.proto
(3)编译生成的 Protobuf 对象
``` // Generated by the protocol buffer compiler. DO NOT EDIT! // source: StudentProto.proto
package xin.marico.facerecogition.test;
public final class StudentProto { private StudentProto() {} public static void registerAllExtensions( com.google.protobuf.ExtensionRegistryLite registry) { } ........................................................ ```
(4)序列化
``` public class Test2 {
public static void main(String[] args) {
StudentProto.Student student = StudentProto.Student.
newBuilder().setAge(24)
.setEmail("1205006751@qq.com")
.setHomeAddress("山东省济南市")
.setName("马善涛")
.setSchool("哈尔滨理工大学")
.setWeight(135)
.setTellphone("120114110").build();
System.out.println(student);
// 数据在传输过程中是以二进制的方式传输
byte[] bytes = student.toByteArray();
System.out.println(bytes.length);
}
} ```
``` name: "\351\251\254\345\226\204\346\266\233" age: 24 tellphone: "120114110" email: "1205006751@qq.com" weight: 135 homeAddress: "\345\261\261\344\270\234\347\234\201\346\265\216\345\215\227\345\270\202" school: "\345\223\210\345\260\224\346\273\250\347\220\206\345\267\245\345\244\247\345\255\246"
89 ```
2.4.3 总结
JSON 的序列化得到的长度为 162 个字节,Protobuf 序列化之后的长度是 89 个字节,由此可见 Protobuf 的序列化是 JSON 空间效率的一倍。
2.5 Protobuf 原理
详细解释一下原理,自己也能好好学习一下。原理十分枯燥,如果之前没有 Protobuf 经验,看起来会非常吃力。
2.5.1 Protobuf 格式
Protobuf 消息由字段(field)构成,每个字段有其规则(rule)、数据类型(type)、字段名(name)、tag,以及选项(option)。比如下面这段代码描述了由 10 个字段构成的 Test 消息:

2.5.2 Protobuf 序列化规则
序列化时,消息字段会按照
tag 顺序
,以
key+val
的格式,编码成二进制数据。

Protobuf 消息序列化之后,会产生二进制数据。这些数据(精确到 bit)按照含义不同,可以划分为 6 个部分:MSB flag、tag、编码后数据类型(wire type)、长度(length)、字段值(value)、以及填充(padding)。后文会图解这些部分的具体含义,这里先约定好图中消息各部分使用的颜色:

前面说过,消息的每一个字段,都会以 key+val 的形式,序列化为二进制数据。val 比较好猜测,那么 key 具体是什么呢?答案是这样:key = tag << 3 | wire_type。也就是说,key 是 tag 左移 3 位得到的。如果 tag=2,那么 key 就等于 8。
后面 3 个比特是 wire type,其他的比特是 tag 值。Protobuf 支持丰富的数据类型,但是编码之后,只剩下 Varint(0)、64-bit(1)、 Length-delimited(2)和 32-bit(5) 这 4 种(还有两种已经废弃了,本文不讨论)类型,用 3 个比特来表示,足够了。下面举个例子:
byte[] data = Test.newBuilder()
.setA(3).setB(2).setC(1)
.build().toByteArray();
以上的数据序列化之后是:

2.5.3 Varint 编码规则
Varint 编码规则使用 7 个比特位存储数据,高位 1 个用来标记字节的连续性。0000 0001 高位为 0,表示当前字节是独立的存储一个值,取出后 7 个字节就是该值。1010 1100 ,0000 0010, 高位为 1,则继续读取后续字节,直到出现一个高位为 0 的结束,这些直接加一起来存储一个值首先进行小端序列转换为大端序列 1010 1100 ,0000 0010 转换序列 -> 0000 0010 , 1010 1100。0000 0010 , 1010 1100 把高位去掉, 000 0010, 010 1100 合并为 100101100 得到 300.
wire type 一共四种,所以用 3 个 bit 来表示 wire type 足够了。
但是 tag 是用剩下的 5 个 bit 来表示吗?tag 难道不能超过 32(2^5)吗?由上图已经知道,答案是否!为了用尽可能少的字节编码消息,Protobuf 在多处都使用了 Varint 这种格式。比如数据类型里的 int32、int64,以及 tag 值和后面将要解释的 length 值,都使用 Varint 类型存储。那么 Varint 到底有什么神奇之处呢?也没有,其实就是用每个字节的前 7 个 bit 来表示数据,而最高位的 bit(MSB,Most Significant Bit)则用作记号(flag)。文字不太好描述,看一个例子:
byte[] data2 = Test.newBuilder()
.setJ(1) // tag=16
.build().toByteArray();
由于 tag 是按 Varint 编码的,所以要扣掉一个 bit(MSB)。再减去 wire type 占用的 3 个比特,那么第一个字节里,留给 tag 值的,实际只剩下 4 个比特,只能表示 0 到 15。由于 Test 消息 j 字段的 tag 值是 16,所以需要两个字节才能表示 j 字段的 key。data2 如下图所示。

2.5.4 大数字的编码
前面说了,为了节省字节数,tag、length,以及 int32、int64 等数据类型都是用 Varint 编码的。那么这种编码方式有什么坏处吗?主要有 2 处。第一,不利于表示大数。对于比较小的数来说,以 0 到 127 为例,用 Varint 很划算。以浪费 1bit 和少量额外的计算为代价,只要 1 个字节就可以表示。但是对于比较大的数,就不划算了。以 int32 为例,大于 2^(4*7) - 1 的数,需要用 5 个字节来表示。看一个例子:
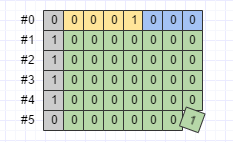
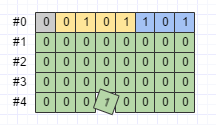
也就是说,如果某个消息的某个 int 字段大部分时候都会取比较大的数,那么这个字段使用 Varint 这种变长类型来编码就没什么好处。对于这种情况,Protobuf 定义了 64-bit 和 32-bit 两种定长编码类型。使用 64-bit 编码的数据类型包括 fixed64、sfixed64 和 double;使用 32-bit 编码的数据类型包括 fixed32、sfixed32 和 float。以 Test 消息 e 字段(fixed32)为例
byte[] data4 = Test.newBuilder()
.setE(268435456) // 2^28
.build()
.toByteArray();
序列化之后的数据如下图所示:
2.5.5 ZigZag 编码
Varint 编码格式的第二缺点是不适合表示负数,以 int32 和-1 为例:
byte[] data5 = Test.newBuilder()
.setA(-1)
.build()
.toByteArray();
Protobuf 想让 int32 和 int64 在编码格式上兼容,所以-1 需要占用 10 个字节,如下图所示:
负数需要占用更多的字节,为了克服这个缺陷,Protobuf 提供了 sint32 和 sint64 两种数据类型。如果某个消息的某个字段出现负数值的可能性比较大,那么应该使用 sint32 或 sint64。这两种数据类型在编码时,会先使用 ZigZig 编码将负数映射成正数,然后再使用 Varint 编码。ZigZag 编码规则如下图所示:
序列化之后的数据如下图所示:

2.5.6 Length-delimited
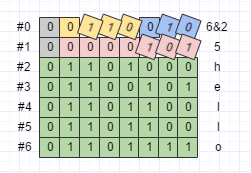
如前所述,64-bit 和 32-bit 是定长编码格式,长度固定。Varint 是变长编码格式,长度由字节的 MSB 决定。Length-delimited 编码格式则会将数据的 length 也编码进最终数据,使用 Length-delimited 编码格式的数据类型包括 string、bytes 和自定义消息。以 string 为例:
byte[] data7 = Test.newBuilder()
.setF("hello") // string
.build()
.toByteArray();
序列化之后的数据如下图所示:
2.5.7 repeated
前面讨论的字段都是 optional 类型,最多只有一个 val,但是 repeated 字段却可以有多个 val 。那么 repeated 字段是如何序列化的呢?以 Test 消息的 g 字段为例:
byte[] data9 = Test.newBuilder()
.addG(1).addG(2).addG(3)
.build()
.toByteArray();
序列化之后的数据如下图所示:

可见,repeated 字段就是简单的把每个字段值依次序列化而已,注意 key 也是每次都重复了。
2.5.8 packed
如果 repeated 字段包含的 val 比较多,那么每个 val 都带上 key 是不是比较浪费呢?是的,所以 Protobuf 提供了 packed 选项,以 Test 消息的 h 字段为例:
byte[] data10 = Test.newBuilder()
.addH(1).addH(2).addH(3) // packed
.build()
.toByteArray();
序列化之后的数据如下图所示:

可见,如果 repeated 字段设置了 packed 选项,则会使用 Length-delimited 格式来编码字段值.每个 val 的值分割用的 varint 编码的。
3 AI 模型微服务
上面看完了高性能网络模型和高性能的序列化机制,我们再来看一下 AI 模型的最优化处理。因为在实际使用中,机器学习/深度学习模型在初始化时,需要加载模型参数,十分耗时,如果每次执行 AI 服务都要先加载参数,那不就完犊子了。所以将 AI 模型做成微服务,微服务不断从消息队列里面取出数据进行处理,然后将处理结果存到 Redis 里面等待其他进程去获取。
我们使用的 face_recoginize 是基于 Python 开发的世界上最简洁的人脸识别库,你可以使用 Python 和命令行工具提取、识别、操作人脸。它人脸识别是基于业内领先的 C++ 开源库 dlib 中的深度学习模型,用 Labeled Faces in the Wild 人脸数据集进行测试,有高达 99.38% 的准确率。但对小孩和亚洲人脸的识别准确率尚待提升。具体的学习资料,下面给大家罗列一些,大家可以学习一下。
4 实际运行效果
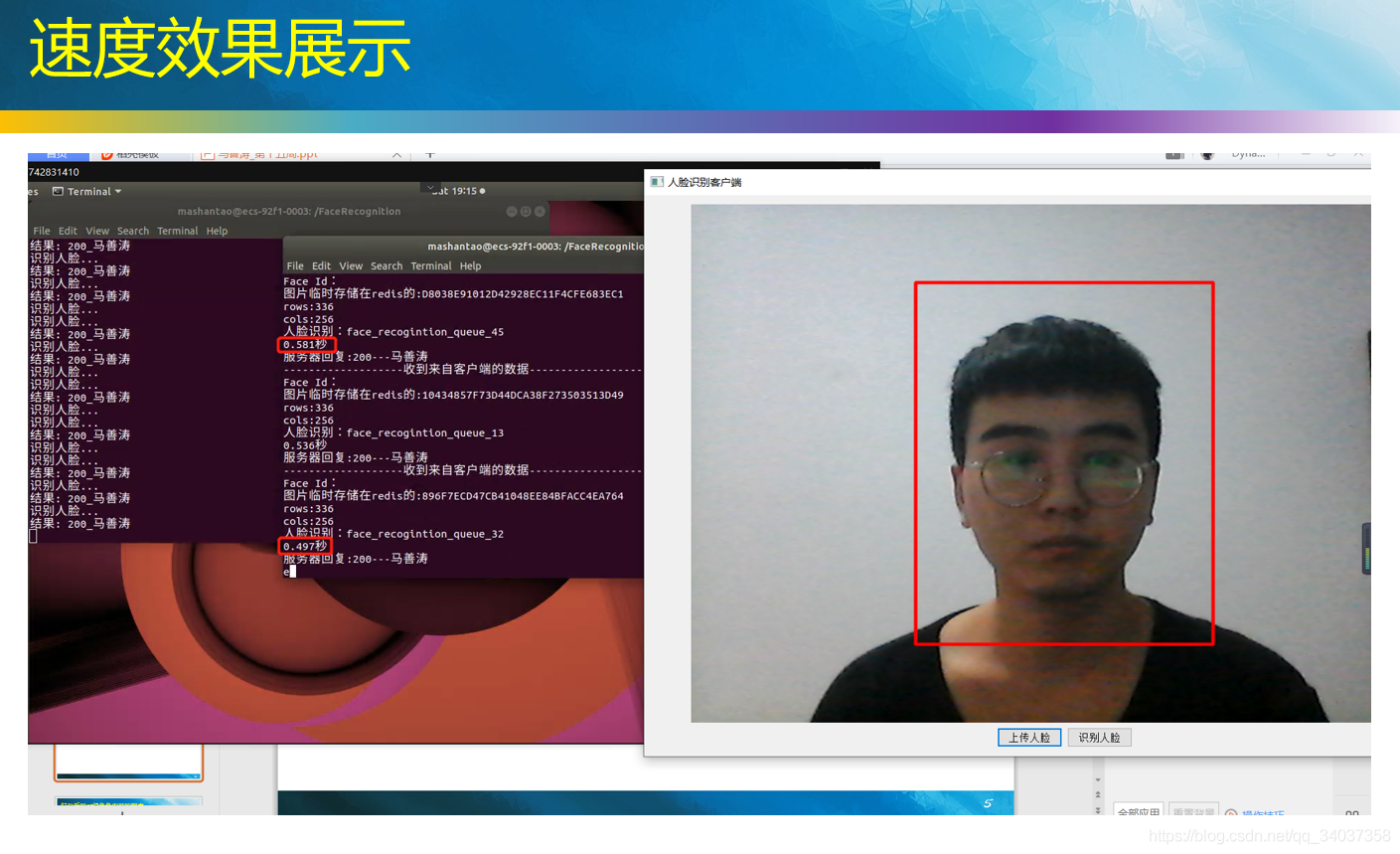
我 AI 人脸识别微服务启动了 50 个人脸识别进程和 10 个人脸上传进程,在华为云企业服务器上把 CPU 跑到了 90+%。


华为云服务器从收到图片到识别成功,耗时一般在 0.5s 左右,因为华为云性能还是比较低的,没有 GPU。算上网络传输 + 线程协调,C 客户端从点击上传到返回识别结果的时间在 1.5s 左右,Web 端识别一张图片在 2s 左右
三、Coding 阶段
前两章学习了高性能的服务器高性能在哪里,下面开始着手 Coding,其实 Coing 很简单,主要是学习和理解 Netty 和 Protobuf 比较难。
1 消息格式
消息序列化使用 Protobuf。在传输过程中为了极大的提高效率,直接传输的图像的像素点。服务器响应的数据格式参考的是 HTTP 的状态码。但是业务量比较少嘛,也没有啥提现。
1.1 定义 Proto
(1)图片的消息格式。ImageProto 消息,即客户端给服务端的消息
``` syntax = "proto3"; // proto3 必须加此注解 option java_package = "xin.marico.facerecogition.entity"; option java_outer_classname = "ImageProto";
message Image { string personName = 1; repeated int32 data = 2; //存储图像的像素数据,相当于int数组 int32 cols = 3; //图像的宽度 int32 rows = 4;//图像的高度 } ```
(2)相应消息格式,即服务端给客户端回复的消息
``` syntax = "proto3"; // proto3 必须加此注解 option java_package = "xin.marico.facerecogition.entity";
message ResultProto { int32 status = 1; //消息状态码 string message = 2;//消息体 } ```
1.2 编译
protoc.exe 对消息格式进行编译。
(1)编译成 Java 类
D:\protobuf-3.11.2\protoc-3.11.2-win64\bin>protoc.exe --java_out=./FaceRecoginition ImageProto.proto
(2)编译成 C++ 类
D:\protobuf-3.11.2\protoc-3.11.2-win64\bin>protoc.exe --cpp_out=./FaceRecoginition ImageProto.proto
2 人脸识别微服务
Python 人脸识别程序,不断监听 Redis 的队列,从 Redis 队列里面取出数据进行处理。数据格式为 imgKey_resultKey,imgKey 是图像存在 Redis 中存储的 key 值,resultKey 是 Netty 监听的 Redis 的 key。
人脸上传的原理是,将首先在图片中检测出人脸的位置,将人脸抠出来,进行编码,将编码存储在 Redis 数据库。
人脸识别的原理是对要识别的人脸进行编码,然后将得到的编码信息与人脸库中的信息进行比对,返回最符合的人脸信息。下面是具体代码。
```
- - coding: utf-8 - -
import face_recognition import sys import redis from datetime import datetime import time from PIL import Image import os import uuid import numpy as np from numpy import float64 import json from multiprocessing import Process from multiprocessing import Pool
def recognize_face(megQueueStr): print("开始人脸识别的进程,监听消息队列:",megQueueStr) redisCli = redis.StrictRedis(host='127.0.0.1', port=6379) while(True): queueMsg = redisCli.lpop(megQueueStr) time.sleep(0.001) if queueMsg is not None: print("识别人脸...") queueMsg = str(queueMsg, encoding='UTF-8') imgKey, resultKey = queueMsg.split(" ") result_status = 200 result_msg = "" # 1.加载未知人脸图片 redisCli = redis.Redis(host='127.0.0.1', port=6379) cols = int(redisCli.hget(imgKey, "cols")) rows = int(redisCli.hget(imgKey, "rows")) data = redisCli.hget(imgKey, "data") unknown_face = np.array(json.loads(data), dtype=np.uint8) unknown_face = unknown_face.reshape(rows, cols, 3) redisCli.delete(imgKey) # 2.对未知人脸图片进行编码 unknown_face_encodings = face_recognition.face_encodings(unknown_face) if len(unknown_face_encodings) == 0: redisCli.set(resultKey, str(500) + " " + "未检测到人脸") continue unknown_face_encoding = unknown_face_encodings[0] # 3.加载所有已知人脸 known_faces_encoding = [] face_infos = redisCli.lrange('face_infos', 0, -1) for face_info in face_infos: face_info = eval(str(face_info, encoding='utf-8')) face_encoding = np.array(json.loads(face_info[1])) known_faces_encoding.append(face_encoding); if len(known_faces_encoding)==0: redisCli.set(resultKey, str(500) + " " + "人脸库为空,先录入人脸") continue # 4.识别人脸 face_distances = face_recognition.face_distance(known_faces_encoding, unknown_face_encoding) min_index = np.argmin(face_distances) if face_distances[min_index] <= 0.4: result_msg = eval(str(face_infos[min_index], encoding='utf-8'))[0] else: result_msg = "未知人脸" # 5.返回结果 redisCli.set(resultKey, str(result_status) + " " + result_msg) print("结果:", str(result_status) + "_" + result_msg)
def upload_faceid(megQueueStr): print("开始上传人脸id的进程,监听消息队列:",megQueueStr) redisCli = redis.StrictRedis(host='127.0.0.1', port=6379) while(True): queueMsg = redisCli.lpop(megQueueStr) time.sleep(0.001) if queueMsg is not None: print("上传人脸...") queueMsg = str(queueMsg, encoding='UTF-8') imgKey,resultKey = queueMsg.split(" ") result_status = 200 result_msg = "人脸录入成功" personName = str(redisCli.hget(imgKey, "personName"), encoding='UTF-8') cols = int(redisCli.hget(imgKey, "cols")) rows = int(redisCli.hget(imgKey, "rows")) data = redisCli.hget(imgKey, "data") upload_image = np.array(json.loads(data), dtype=np.uint8) upload_image = upload_image.reshape(rows, cols, 3) # 将人脸删除 redisCli.delete(imgKey) # 2.对人脸图片进行编码,只要第一张人脸。 image_face_encodings = face_recognition.face_encodings(upload_image) if len(image_face_encodings) == 0: redisCli.set(resultKey, str(500) + " " + "未检测到人脸") continue image_face_encoding = image_face_encodings[0] # 3.将人脸图片截取保存到文件夹 top, right, bottom, left = face_recognition.face_locations(upload_image)[0] face_img = upload_image[top:bottom, left:right] pil_img = Image.fromarray(face_img) # 3.1 生成随机的文件名,拼接保存路径 save_name = str(uuid.uuid1()) save_path = "/FaceRecognition/pictures_of_people_i_know/" + personName; if not os.path.exists(save_path): os.makedirs(save_path) save_path += "/" + save_name + ".jpg" # 3.2保存人脸图片 pil_img.save(save_path); # 4.将人脸的128维编码信息存到redis中 face_info = [personName, str(image_face_encoding.tolist()), "save_path"] redisCli.rpush("face_infos", str(face_info)); redisCli.set(resultKey,str(result_status)+" "+result_msg) print("结果:",str(result_status)+" "+result_msg)
if name == ' main ': uploadProcessCount = 1 recognitionProcessCount = 2 processPool = Pool(uploadProcessCount+recognitionProcessCount) #创建人脸识别的线程池 for i in range(recognitionProcessCount): processPool.apply_async(recognize_face, ("face_recogintion_queue_"+str(i),)) #创建上传人脸的进程池 for i in range(uploadProcessCount): processPool.apply_async(upload_faceid, ("upload_faceid_queue_"+str(i),)) # 关闭子进程池 processPool.close() # 等待所有子进程结束 processPool.join() ```
3 Netty 服务器
人脸识别整完之后,开始开发 Netty 服务器。其实 Netty 服务器的开发不难,难在 Netty 的学习。Netty 这一端写了 HTTP 服务器和 TCP 的服务器。HTTP 用来处理 Web 端的请求。TCP 用来处理 Qt 客户端的请求。HTTP 端口为 8888,TCP 端口为 6666。在这里我不贴全部代码了,全部代码去 GitHub 下载,如果可以的话,给弟弟个 star 激励一下。
(1)Main 入口
``` package xin.marico.facerecogition.server;
import io.netty.bootstrap.ServerBootstrap; import io.netty.channel.Channel; import io.netty.channel.ChannelOption; import io.netty.channel.EventLoopGroup; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.nio.NioServerSocketChannel; import xin.marico.facerecogition.initializer.HttpInitializer; import xin.marico.facerecogition.initializer.SocketInitializer;
public class FaceRecognitionServer {
private static int SOCKET_POOR = 6666;
private static int HTTP_PORT = 8888;
public static void socketProcess() {
System.out.println("启动监听socket连接----");
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childHandler(new SocketInitializer());
Channel channel = bootstrap.bind(SOCKET_POOR).sync().channel();
channel.closeFuture().sync();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
public static void httpProcess() {
System.out.println("启动监听http连接----");
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childHandler(new HttpInitializer());
Channel channel = bootstrap.bind(HTTP_PORT).sync().channel();
channel.closeFuture().sync();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
public static void main(String[] args) {
System.out.println("---------------启动AI服务器-----------------");
Thread httpProcess = new Thread(() -> {
httpProcess();
});
Thread socketProcess = new Thread(() -> {
socketProcess();
});
httpProcess.start();
socketProcess.start();
}
} ```
(2)SocketInitializer
``` package xin.marico.facerecogition.initializer;
import io.netty.channel.ChannelInitializer; import io.netty.channel.socket.SocketChannel; import io.netty.handler.codec.protobuf.ProtobufDecoder; import io.netty.handler.codec.protobuf.ProtobufEncoder; import io.netty.handler.codec.protobuf.ProtobufVarint32FrameDecoder; import io.netty.handler.codec.protobuf.ProtobufVarint32LengthFieldPrepender; import io.netty.handler.timeout.IdleStateHandler; import xin.marico.facerecogition.vo.ImageProto; import xin.marico.facerecogition.handler.SocketHandler;
import java.util.concurrent.TimeUnit;
public class SocketInitializer extends ChannelInitializer
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
// 下面这一行是重点,Netty和protobuf一起使用的时候,要加上这个解码器
socketChannel.pipeline().addLast( new ProtobufVarint32FrameDecoder());
socketChannel.pipeline().addLast("decoder", new ProtobufDecoder(ImageProto.Image.getDefaultInstance()));
socketChannel.pipeline().addLast(new ProtobufVarint32LengthFieldPrepender());
socketChannel.pipeline().addLast("encoder", new ProtobufEncoder());
socketChannel.pipeline().addLast("heartJump",new IdleStateHandler(12,12,20, TimeUnit.SECONDS));
socketChannel.pipeline().addLast("imageHadler",new SocketHandler());
}
} ```
(2)HttpInitializer
``` package xin.marico.facerecogition.initializer;
import io.netty.channel.ChannelInitializer; import io.netty.channel.socket.SocketChannel; import io.netty.handler.codec.http.HttpObjectAggregator; import io.netty.handler.codec.http.HttpServerCodec; import io.netty.handler.codec.http.websocketx.WebSocketServerProtocolHandler; import io.netty.handler.stream.ChunkedWriteHandler; import xin.marico.facerecogition.handler.HttpHandler;
public class HttpInitializer extends ChannelInitializer
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast("httpcodec",new HttpServerCodec());
//对写大数据流的支持
ch.pipeline().addLast(new ChunkedWriteHandler());
//设置单次请求的文件大小上限
ch.pipeline().addLast(new HttpObjectAggregator(1024*1024*10));
//websocket 服务器处理的协议,用于指定给客户端连接访问的路由 : /ws
//ch.pipeline().addLast(new WebSocketServerProtocolHandler("/ws"));
ch.pipeline().addLast("httpHandler",new HttpHandler());
}
} ```
(3)Http 以及 Socket 的处理器代码比较多,需要的同学,下载代码跑一下就可以。
四、客户端代码
1 Web 客户端
Web 客户端需要注意的是,要想 HTML 调用摄像头,请求 URL 必须是本地或者 HTTPS 的。然后为了极大限度的提高传输速度,Web 前端直接传输截图的摄像头图像的像素值。交由 AI 微服务 去解析。比较难的 Web 调用摄像头的方法,这个网上的资料比较少。
代码如下:
```

```
2 Qt 客户端
Qt 客户端调用 Opencv 读取电脑摄像头,使用 Opencv 先做前端的人脸检测,前端人脸检测通过之后再将图片上传到服务器。这里说一下核心代码。
``` google::protobuf::uint32 UploadImageThread::readMessageSize(char byteCountbuf){ google::protobuf::uint32 size; google::protobuf::io::ArrayInputStream ais(byteCountbuf, 4); CodedInputStream coded_input(&ais); coded_input.ReadVarint32(&size); //解码数据头,并获取数据大小 return size; } //读取netty返回的数据主体 void UploadImageThread::readBody(QTcpSocket clientSocket,google::protobuf::uint32 size, ResultProto &result){ int bytecount; char *buffer = new char[size + 4]; // 读取整个缓冲区 try{ if ((bytecount =clientSocket->read(buffer, 4 + size)) == -1){ qDebug() << "接受数据失败 " << size << endl; } } catch (double e){ qDebug() << "捕获到异常 " << size << endl; } //为输入分配足够的内存 google::protobuf::io::ArrayInputStream ais(buffer, size + 4); CodedInputStream coded_input(&ais); //读取Varint编码的无符号整形数字。不超过32位 coded_input.ReadVarint32(&size); //在读取完消息的长度之后,设置读取数据的长度限制 google::protobuf::io::CodedInputStream::Limit msgLimit = coded_input.PushLimit(size); //反序列化 result.ParseFromCodedStream(&coded_input); //序列化完消息之后,调用PopLimit()来撤消限制 coded_input.PopLimit(msgLimit); }
//上传文件的线程
void UploadImageThread::run(){
ResultProto result;
QTcpSocket
clientSocket = new QTcpSocket();
clientSocket->connectToHost(host, port);
if(clientSocket->isValid()){
int size = imageProto.ByteSizeLong() + 4;
char
message = new char[size];
google::protobuf::io::ArrayOutputStream aos(message, size);
google::protobuf::io::CodedOutputStream *coded_output = new google::protobuf::io::CodedOutputStream(&aos);
// 首先写入序列化之后数据的长度
coded_output->WriteVarint32(imageProto.ByteSizeLong());
// 序列化
imageProto.SerializeToCodedStream(coded_output);
int sendRe = clientSocket->write(message, size);
clientSocket->waitForBytesWritten();
clientSocket->flush();
if( -1 == sendRe){
result.set_status(400);
result.set_message("客户端发送数据失败!");
}
clientSocket->waitForReadyRead(-1);
char countBuffer[4];
memset(countBuffer, '\0', 4);
int bytecount;
// 一直等待服务器回信
while (true){
// 读取服务器给回复信息,countBuffer存的是长度
// protobuf消息的前四个字节是数据包的长度
bytecount = clientSocket->peek(countBuffer, 4);
if (bytecount == 0){ break; }
if (bytecount == -1){
result.set_status(404);
result.set_message("未知服务器和端口");
qDebug()<<"读取数据出错:"<<result.status()<
参考文献
- 基于web的人脸识别登陆和管理系统设计与实现(郑州大学·王哲)
- 基于微服务架构的高性能服务调用系统的设计与实现(电子科技大学·徐浩杰)
- 视频中人脸表情识别关键技术与应用(电子科技大学·黄弋)
- 基于Web服务的客户智能研究(浙江工商大学·王可)
- 基于人脸识别的摄影协会综合管理系统设计与实现(哈尔滨工程大学·李世强)
- 基于JSF的Web-GIS研究与应用(武汉理工大学·周鼎)
- 提供人脸识别服务的计费管理系统设计与实现(大连理工大学·宋一凡)
- 基于.NET框架的企业应用集成研究和实现(浙江大学·蒋元星)
- 基于Caps-Net人脸识别的安防系统的研究与开发(新疆大学·张汉卿)
- 基于云的统一身份智能信息管理系统设计实现(华南理工大学·水凯凯)
- 视频中人脸表情识别关键技术与应用(电子科技大学·黄弋)
- 基于JSF的Web-GIS研究与应用(武汉理工大学·周鼎)
- 基于人脸跟踪的视频共享网站的设计与实现(中山大学·曾旭华)
- 基于人脸识别的摄影协会综合管理系统设计与实现(哈尔滨工程大学·李世强)
- 智慧社区人脸识别系统的设计与实现(华中科技大学·刘合鑫)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设客栈 ,原文地址:https://m.bishedaima.com/yuanma/35915.html