
基于文字检测识别的技术研究
摘要
文字是人类交流信息的重要工具,在科技和网络不断发展的今天,文本的方式或者说载体发生了很大的变化,文字不再只停留在书面,更以标识牌,横幅,广告牌等等方式出现我们的生活中,或者说,它们是一张张图片中的文本信息。用计算机检测识别这些信息将给我们的生活带来极大的便利。比如说,自动驾驶技术识别路边的各种指示牌,停车场的车牌识别,扫描录入身份证信息等等。
本毕设课题是属于计算机视觉下的目标检测与识别,对象为自然场景下的各种文本信息,通俗的说就是检测识别图片中的文本信息。由于文本的特殊性,本毕设将整个提取信息的过程可以分为检测、识别两个部分。
论文对用到的相关技术概念有一定的介绍分析,如机器学习,深度学习,以及各种的网络模型及其工作原理过程。
检测部分采用水平检测文本线方式进行文本检测,主要参考了乔宇老师团队的 CTPN 方法,并在正文部分从模型的制作到神经网络的设计实现对系统进行了较为详细的分析介绍。
识别部分则采用的是 Densenet + CTC,对于印刷体的文字有较好的识别。
关键词:深度学习;文本检测;文本识别;CTPN;Densenet;CTC
ABATRACT
The words is an important tool for human beings to exchange information. Today, with the continuous development of science, technology and the Internet, great changes have taken place in the way or carrier of text. The text is no longer confined to writing, but is even more marked with signs and banners. Billboards and so forth appear in our lives, or rather, they are text messages in pictures. Using computer to detect and recognize these information will bring great convenience to our life. For example, autopilot technology recognizes roadside signs, license plate recognition in parking lots, scanning for ID information, and so on. This topic belongs to the computer vision target detection and recognition, the object is the natural scene of a variety of text information, commonly said is to detect and recognize the text information in the picture. Because of the particularity of the text, the whole process of extracting information can be divided into two parts: detection and recognition. The paper introduces and analyzes the relevant technical concepts, such as machine learning, in-depth learning, and a variety of network models and their working principles. The detection part uses horizontal detection text line for text detection, mainly referring to the CTPN method of teacher Qiaoyu team, and in the text part, from the model making to the design and implementation of neural network, the system is analyzed and introduced in detail. In the part of recognition, Densenet + CTC is used, which has a good recognition of printed text. Keywords: deep learning; text detection; character recognition; CTPN; Densenet; CTC
一、绪论
1.1 选题背景依据
人类接收外界信息主要通过各种感觉器官,比如说视觉、听觉、嗅觉、味觉、触觉等等。但是其中最重要的莫过于视觉,因为我们总习惯于用眼镜去发现感知获取外界信息。文字的产生对于人类有着特别意义,在此不特别赘述。而本次毕业设计课题的目的就是提取自然场景下的文本信息。
在这个互联网高度发展下的信息时代,手动记录文本信息不能说它已经过时,但是说它不够效率跟不上时代却是没什么问题的。例如停车场记录车牌号,要是人工的这么一个个的去记录,不但浪费人力,更重要的是导致后面停车的人会等很久,浪费停车人的时间。又如学校老师上课的时候写的板书,来不及记录的时候基本都会直接用手机拍照记录。再比如我们用过的手写输入法,有道词典百度词典的拍照翻译等等,都是基于计算机视觉中的文本识别。
但随着各类技术的发展,我们不仅仅局限于那种简单的,容易实现的文本识别,我们更希望进一步的去提取自然场景下的各种文本信息。比如说我们生活中随处可见的交通标识牌、各类商铺的招牌、各类宣传横幅、布告栏、警示标语等。这些文本信息不同于我们平时书面上的文本,因为处于自然环境中,所以各种灯光,不同的角度,雨雾天气等各种自然环境现象都对检测造成很大的干扰,就目前来看,现有方法识别这类的文本信息仍有不小的问题,文本检测与识别仍是具有挑战的研究课题。
1.2 目前的研究现状
国际文档分析与识别大会(ICDAR)是全球文档分析以及模式识别领域最重要的国际学术会议之一,由国际模式识别协会(International Association of Pattern Recognition, IAPR)主办。该会议每两年举办 1 次,从 1991 年第 1 届开始,到 2017 年已成功举办 14 届。其中去年的大赛由腾讯云 OCR 斩获四项冠军。
文本检测与识别可以基本的分为文本位置检测和文本字符识别两个部分。
文本检测的算法近来发展较快,大致的可以分为水平文本检测和倾斜文本检测两类,水平文本检测个人认为做的比较好的是 2016EVCC 乔宇团队的 CTPN,而倾斜文本检测较好的则是 2017CVPR 的 EAST 和 Seglink。
文本识别个人认为的比较好的算法也有两种,一种是 CNN+RNN+CTC,另一种是基于 Attention 的 CNN+RNN。
二、技术相关
2.1 tensorflow 框架
TensorFlow 是谷歌基于 DistBelief 进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着 N 维数组,Flow(流)意味着基于数据流图的计算,TensorFlow 为张量从流图的一端流动到另一端计算过程。TensorFlow 是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
TensorFlow 可被用于语音识别或图像识别等多项机器学习和深度学习领域,对 2011 年开发的深度学习基础架构 DistBelief 进行了各方面的改进,它可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。TensorFlow 完全开源,任何人都可以用。
目前 TensorFlow 框架在 Linux 操作系统下的安装已经十分简单,python 语言可以很方便的安装与使用 tensorflow,可根据自己电脑的配置进行具体的安装,如果电脑配有 GPU,推荐安装 GPU 版本,这将大大的提升模型的训练速度,以及使用模型时的检测识别速度。
关于 tensorflow 的各种知识以及安装的教程,网上的介绍已经十分的全面,在此不做进一步的赘述。
2.2 OpenCV
OpenCV 于 1999 年由 Intel 建立,如今由 Willow Garage 提供支持。OpenCV 是一个基于 BSD 许可(开源)发行的跨平台计算机视觉库,可以运行在 Linux、Windows 和 Mac OS 操作系统上。它轻量级而且高效,由一系列 C 函数和少量 C++ 类构成,同时提供了 Python、Ruby、MATLAB 等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。最新版本是 3.4.1 ,2018 年 2 月 27 日发布。
OpenCV 拥有包括 500 多个 C 函数的跨平台的中、高层 API。它不依赖于其它的外部库——尽管也可以使用某些外部库。
OpenCV 为 Intel Integrated Performance Primitives(IPP)提供了透明接口。这意味着如果有为特定处理器优化的 IPP 库,OpenCV 将在运行时自动加载这些库。
简言之,OpenCV 库就是用来对图片或视频进行一个初步的处理,例如把图像变为灰度图,给图像进行边缘检测,给图像进行 SVM 分类等等,这些功能都在 OpenCV 库里有着很好的集成。
2.3 DenseNet(Dense Convolutional Network,连接时序分类)
DenseNet 的概念来源于 CVPR 2017 上,康奈尔大学博士后黄高博士(Gao Huang)、清华大学本科生刘壮(Zhuang Liu)、Facebook 人工智能研究院研究科学家 Laurens van der Maaten 及康奈尔大学计算机系教授 Kilian Q. Weinberger 所作论文《Densely Connected Convolutional Networks》
它是一种具有密集连接的卷积神经网络。在该网络中,任意两层之间都有直接的连接,换句话说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。
图 2.3 是 DenseNet 的一个示意图。
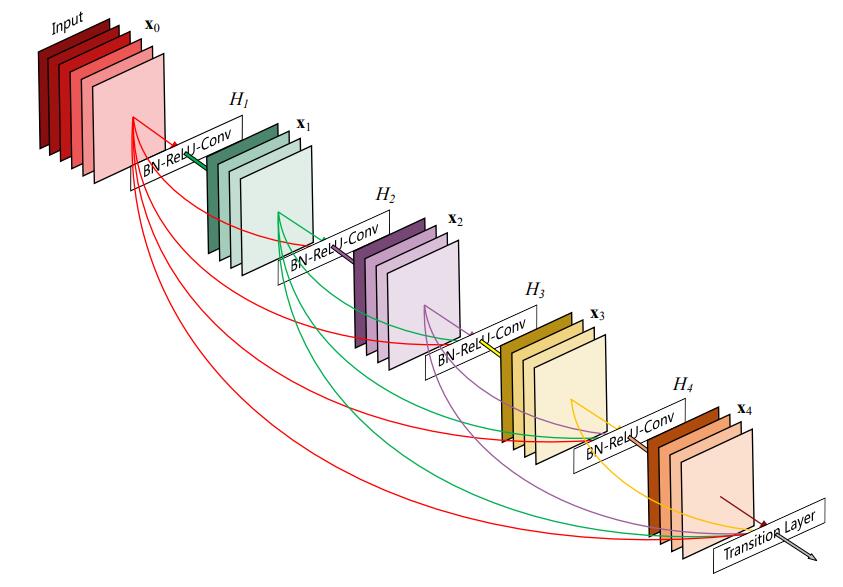
图 2.3 densenet 结构图
如图 2.3,这是一种稠密连接,每层以之前层的输出为输入,对于有 L 层的传统网络,一共有 L 个连接,对于 DenseNet,则有 L(L+1)2。
这篇论文的作者灵感来源于 ResNet 和 GoogleNet,但是不同于 ResNet(从深度方向解决网络深时候的梯度消失问题)和 GooleNet(宽度方向),该作者从 feature(特征)着手,追求对 feature 更加充分的利用以达到更加优秀效果的同时减少参数。
总结下它的几个优点:
- 减轻了 vanishing-gradient(梯度消失)
- 加强了 feature 的传递
- 更有效地利用了 feature
- 定程度上较少了参数数量
2.4 CTC(Connectionist temporal classification)
CTC 是由 Graves 等人于 2006 年提出来的一种时序分类算法,重点要解决的问题是:在时序分类任务中,传统的做法是输入数据与给定标签必须要在时间上一一对齐,只有这样才能采取交叉熵按帧训练来进行分类,而 CTC 的做法是不需要标签在时间上一一对齐就可以进行训练,在对输入数据的任一时刻做出的预测不是很关心,而关心的是整体上输出是否与标签一致,从而减少了标签预划定的冗杂工作。
CTC 与传统的 framewise 还有一个很重要的不同之处就是:CTC 输出的是整体序列的概率,而 framewise 输出的是单帧的概率,而对于时序问题来说,输出序列的概率远比输出单帧的概率重要得多,因此 framewise 训练需要做额外的时序工作,而 CTC 就不需要额外的工作。因此,CTC 很善于处理时序分类问题。
2.5 faster-rcnn 框架
fster-rcnn 算法由两大模块组成:
- PRN 候选框提取模块;
- Fast R-CNN 检测模块。
- 其中,RPN 是用来提取候选框的全卷积神经网络;Fast R-CNN 在 RPN 提取的 proposal 基础上检测并识别框内目标。
2.5.1 RPN
RPN 的核心思想是使用 CNN 卷积神经网络直接产生 Regin Proposal,使用的方法本质上就是滑动窗口(只需在最后的卷积层上滑动一遍),因为 anchor 机制和边框回归可以得到多尺度多长宽比的 Region Proposal。
RPN 网络也是全卷积网络(FCN,fully-convolutional network),可以针对生成检测建议框的任务端到端地训练,能够同时预测出 object 的边界和分数。只是在 CNN 上额外增加了 2 个卷积层(全卷积层 cls 和 reg)。
① 将每个特征图的位置编码成一个特征向量(256dfor ZF and 512d for VGG)。
② 对每一个位置输出一个 objectness score 和 regressedbounds for k 个 region proposal,即在每个卷积映射位置输出这个位置上多种尺度(3 种)和长宽比(3 种)的 k 个(3*3=9)区域建议的物体得分和回归边界。
RPN 网络的输入可以是任意大小(但还是有最小分辨率要求的,例如 VGG 是 228*228)的图片。如果用 VGG16 进行特征提取,那么 RPN 网络的组成形式可以表示为 VGG16+RPN。
2.5.2 Fast R-CNN
图 2.5.2 faster–rcnn 流程图
三、深度学习基础概念
深度学习是指多层神经网络上运用各种机器学习算法解决图像,文本等各种问题的算法集合。深度学习从大类上可以归入神经网络,不过在具体实现上有许多变化。深度学习的核心是特征学习,旨在通过分层网络获取分层次的特征信息,从而解决以往需要人工设计特征的重要难题。深度学习是一个框架,包含多个重要算法:
- Convolutional Neural Networks(CNN)卷积神经网络
- AutoEncoder 自动编码器
- Sparse Coding 稀疏编码
- Restricted Boltzmann Machine(RBM)限制波尔兹曼机
- Deep Belief Networks(DBN)深信度网络
- Recurrent neural Network(RNN)多层反馈循环神经网络神经网络
- 对于不同问题(图像,语音,文本),需要选用不同网络模型才能达到更好效果。
3.1 卷积

图 3.1 卷积过程图
如图 3.1 所示,我们知道图片在计算机中其实就是一个个的像素点,保存形式就可以看作是一个二维矩阵,图中的 5 5 绿色矩阵可以看作一个 5 5 的图像,而黄色的 3 3 矩阵我们称之为卷积核,通俗的来说可以把他看作一个过滤器,或者说是一个特征提取器。实际使用过程中这个卷积核中的值为整个神经系统自主学习调整,不用手动去调。我们利用这个卷积核在一张图像上按照一定的规则扫过,每次卷积核停留的时候,卷积核里的每个元素都与卷积核停留图像对应位置的元素相乘后,全部相加,所得到的值保存在一个新的矩阵中,这个相乘相加的过程我们称之为卷积。如图中所示,黄色卷积核与对应绿色图像元素位置的值相乘相加后得到 4 保存于粉色矩阵中,当卷积核按照步长单位 1 长度的方式扫过整张图像后我们将得到一个 3 3 的矩阵,这个矩阵就是就是我们所说的卷积核对应的特征图。
不难发现特征图的大小并不是固定不变的,而是由卷积核,原图大小,步长 3 个元素来决定的,假设原图大小 m n,卷积核大小为 i j(一般情况下均为 3 3),步长为 k(一般情况为 1)时,特征图大小 p q。
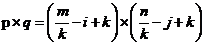
(3.1)
3.2 池化
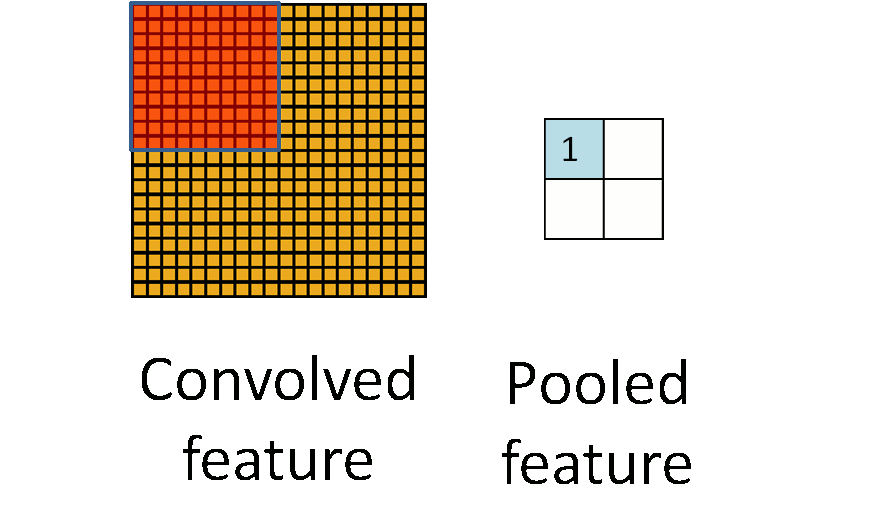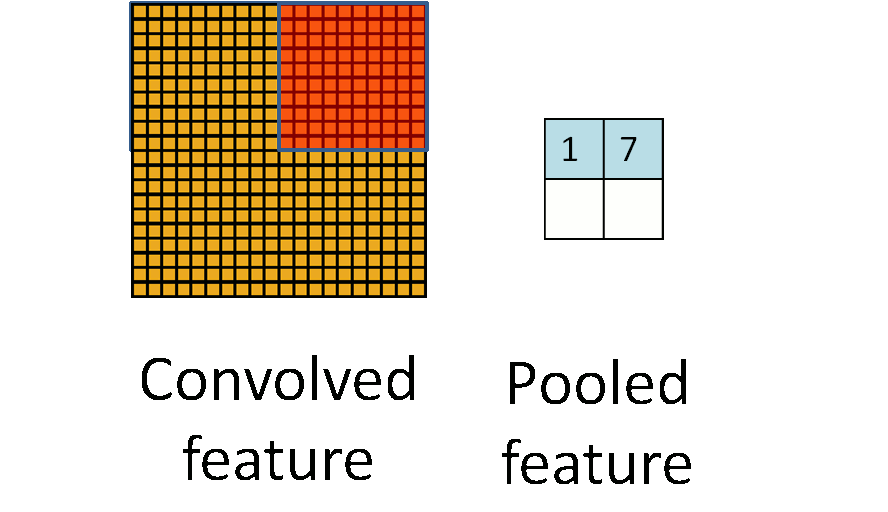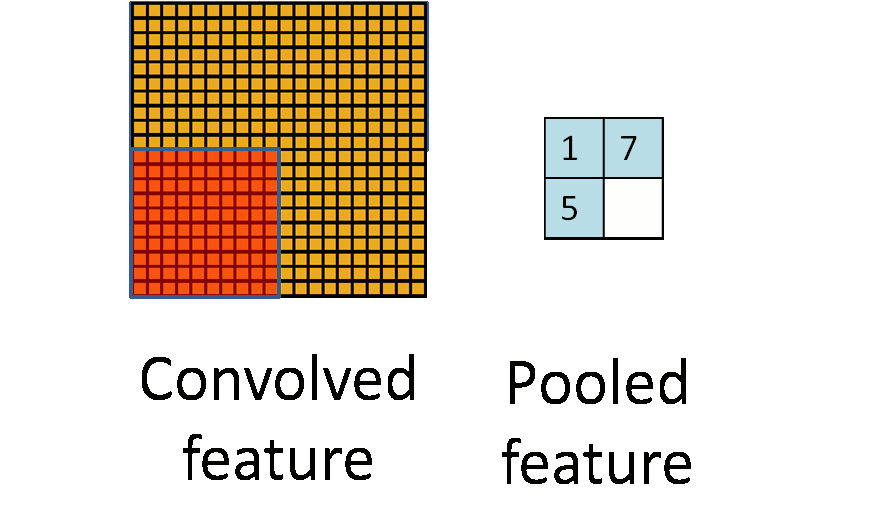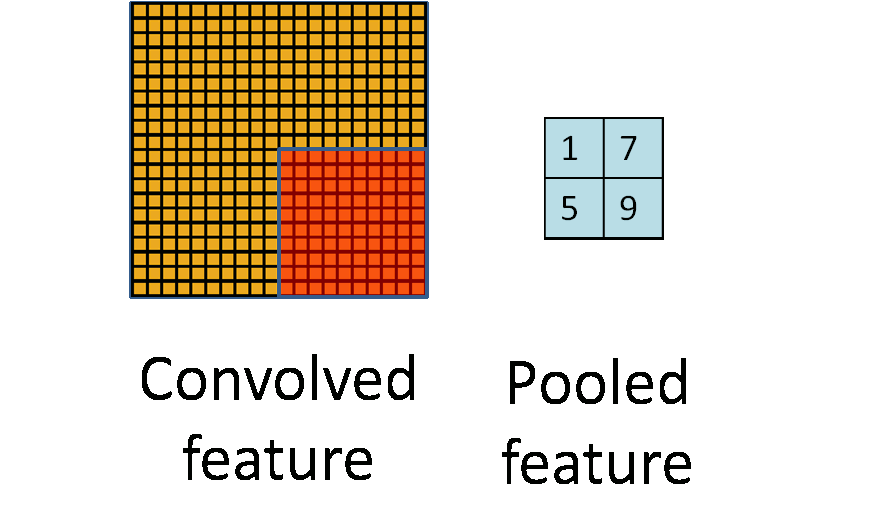
图 3.2 池化过程图
通俗的来说池化就是采样,因为从上面的卷积过程我们可以看到即使做了卷积之后,图像依旧很大,比如说 m=1000,此时卷积过后 n=998,我们需要降低数据维度以便之后的操作。通过上面卷积的概念,我们可以把池化当作步长等于卷积核长度,卷积核等于采样窗口的卷积操作。如图 3.2 中所示,当 m n=20 20,i j=10 10 时,根据上面卷积的公式 p q=2 2。图像成功缩小了 100 倍,之所以能这么做,是因为即便在这个过程中丢失了大量数据,特征的统计属性依然能够描述图像,并且由于我们降低了数据维度,可以有效的降低或者避免过拟合。实际的使用中,池化主要根据需求的不同采用最大值下采样(Max-Pooling)或者平均值下采样(Mean-Pooling)。
3.3 Padding(填充)
我们知道当不管是卷积还是池化过程中,都会由于步长的影响导致某些图像数据不能顺利的完成卷积或池化,这时,我们可以尝试在原图边缘填充 0 来完成卷积或者池化,比如说当图像大小为 19 19 而采样窗口为 10 10 时,此时可以在图像矩阵的右边缘与下边缘补上一层 0 来保证图像信息被完全使用。
3.4 卷积神经网络
卷积神经网络是由一层层的单元层组成,数据则在层与层之间传递,在做图像处理的时候,初始输入层是一张图像(为了更好的达到检测识别目的,通常这张图像根据需求经过一个预处理过程),输出层则是目标信息,比如说,当做图像分割处理时,输出的是分类的类别,并且输出层的大小和输入层相同;当做图像分类时,输出的时图像属于某一类别的概率,输出大小则是类别的总数。最最重要是介于输入与输出间的隐藏层,如卷积层、池化层、归一化层、激励函数层、全连接层和损失函数层,每一个层对应的作用不同。
神经网络中的每一个层都包含了若干个不同类型的神经元,如卷积神经元,池化神经元和激活神经元等等。这些个组成单元用以完成对输入信息的编码、组合等操作,都有各自不同的作用。类似于生物神经元,它接受了一堆信息并对信息进行处理之后,又产生一个输出。假设某一层的神经元接受的信息个数为 n,x=(x1,x2,...,xn),用 z 来表示输出的话,那么这个输入与输出的关系可以表示为
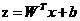
(3.2)
其中的 W 代表 n 维的权值向量,b 代表偏置。这是一种线性的变换,通常在表达能力上会有一定局限性。
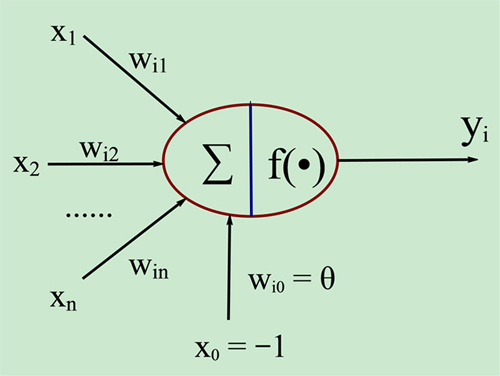
图 3.4.1 神经元模型图
采用非线性激活函数,对 z 进行处理,得到一个激活值 y,可以得到非线性的输入输出映射关系。比较常用的激活函数包括 Sigmoid 函数、tanh 函数、ReLU 函数等。
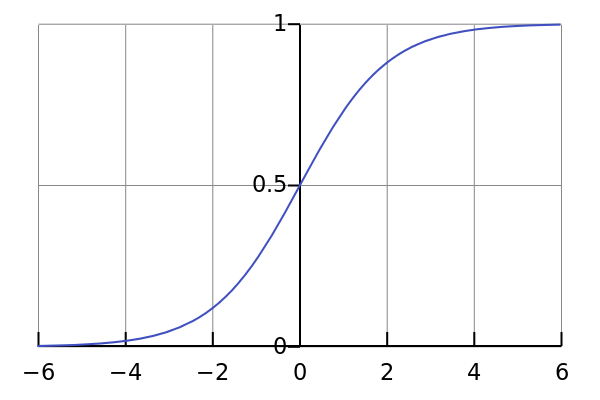

图 3.4.2 自左向右依次为 Sigmoid、tanh、ReLu 激活函数图
卷积神经网络具有自主学习的能力,可以根据误差值反复的对每个权值更正,使其更加接近正确结果。这个过程分为两步:前向运算与反向运算。前向运算指的是当前神经元接受上一层神经元的输入,处理产生新的输出作为下一层的输入。一个 N 层结构的神经网络前馈运算,它的输入值 Y 与输入的关系式为
c++
y=f(x0; w1,...,wn)(3.3)
反向运算是根据训练损失值再反向传播到网络层中的每一层,根据这个损失值对这些权值进行改进,常用方法为梯度下降法(Gradient Descent,GD)
3.5 VGG16 模型
如表 3.5.1 中所示,VGG16 网络模型包括了 13 个卷积层(Convolutional Layer,Conv Layer),3 个全连接层(Fully Connected Layer,FC layer)和 5 个池化层,卷积层分为 5 组,每组由 Pooling 层分开。每个卷积层的配置方式为:“filter”卷积核信息,包含卷积核数量和相应尺寸,形式为“数量 长 宽”;“stride”表示步长,就是每次卷积核移动的像素点个数;“pad”表示填充数量,具体信息在论文其他部分有说明;“ReLU”是一种修正线性激活函数(Recification Linear Unit,RELU)。“pooling”表示池化操作以及相应尺寸。FC6 和 FC7 全连接层的神经元数量为 4096,且全连接层采用 dropout 的方式来防止过拟合,FC8 全连接层为输出结果,共分为 1000 个类别。
表 3.5.1 VGG16 结构表
| Layer | 配置方式 |
|---|---|
| Conv1_1;Conv1_2 | filter 64 3 3,stride 1,pad 1,Relu;filter 64 3 3,stride 1,pad 1,Relu |
| Pooling1 | Max,filter 2*2,stride 2 |
| Conv2_1;Conv2_2 | filter 128 3 3,stride 1,pad 1,Relu;filter 128 3 3,stride 1,pad 1,Relu |
| Pooling2 | Max,filter 2*2,stride 2 |
| Conv3_1;Conv3_2;Conv3_3 | filter 256 3 3,stride 1,pad 1,Relu;filter 256 3 3,stride 1,pad 1,Relu;filter 256 3 3,stride 1,pad 1,Relu |
| Pooling3 | Max,filter 2*2,stride 2 |
| Conv4_1;Conv4_2;Conv4_3 | filter 512 3 3,stride 1,pad 1,Relu;filter 512 3 3,stride 1,pad 1,Relu;filter 512 3 3,stride 1,pad 1,Relu |
| Pooling4 | Max,filter 2*2,stride 2 |
| Conv5_1;Conv5_2;Conv5_3 | filter 512 3 3,stride 1,pad 1,Relu;filter 512 3 3,stride 1,pad 1,Relu;filter 512 3 3,stride 1,pad 1,Relu |
| Pooling5 | Max,filter 2*2,stride 2 |
| FC6;FC7;FC8 | 4096,Relu,dropout;4096,Relu,dropout;1000 |
3.6 LSTM 模型
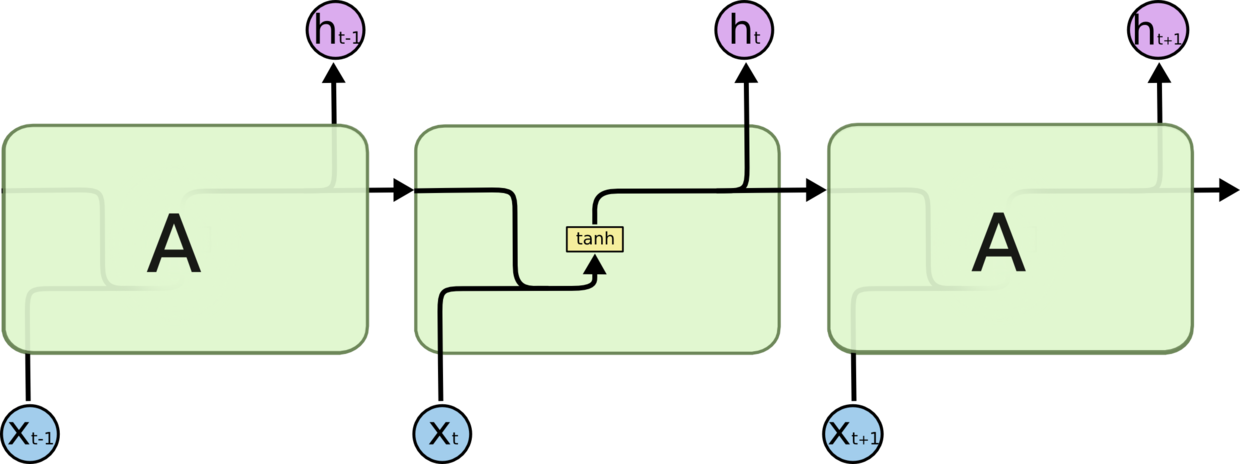
LSTM 是一种特殊的 RNN(循环神经网络)。在标准的 RNN 中重复模块只有一个非常简单的层结构,比如一个 tanh 层。LSTM 同样是这样的结构,但与之同的是,重复模块不是单一神经网络层而是四个,并以一种特别的方式来进行交互。
图 3.6.1 普通 RNN 重复模块结构图
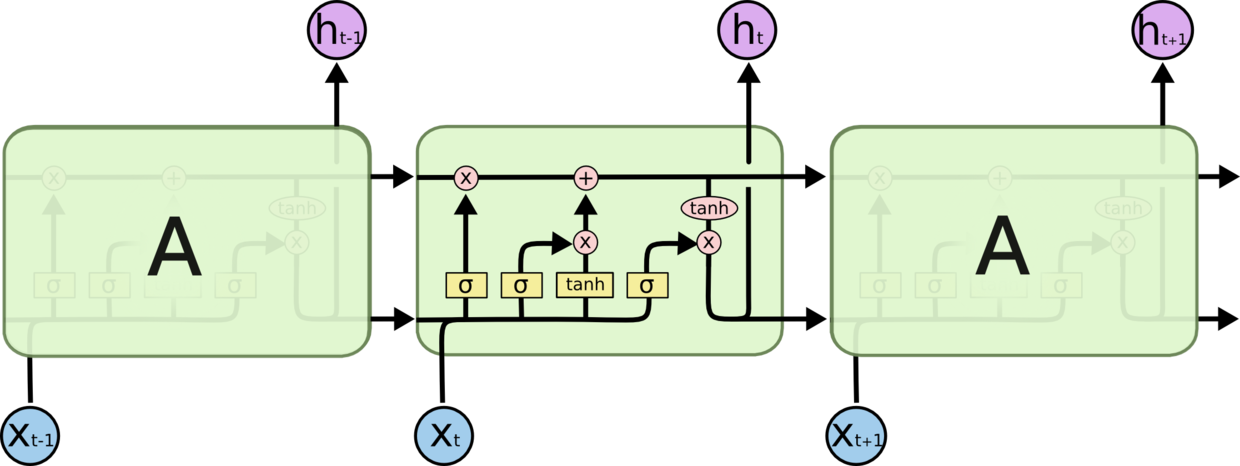
图 3.6.2 LSTM 重复模块结构图
LSTM 的关键在于细胞状态,这个状态类似于传送带。并且设计了一种“门”结构来增加或去除到细胞状态的信息。门是一种让信息选择通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。图 3.6.2 中黑线传输整个向量,表示一个节点的输出到其他节点的输入。粉色圈代表 pointwise 的操作,诸如向量的和,黄色矩阵代表学习得到的神经网络层。黑线合并表示向量连接,黑线分开表示向量内容复制发送到不同位置。
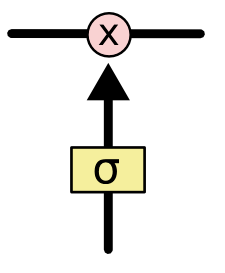
图 3.6.3 细胞状态图
LSTM 拥有三个门,来保护和控制细胞状态。第一个门为忘记门,决定从细胞状态丢弃哪些信息。该门读取
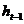
和

,输出一个在 0 到 1 间的数值给每个在细胞状态
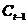
中的数字。1 表示“完全保留”,0 表示“完全丢弃”。
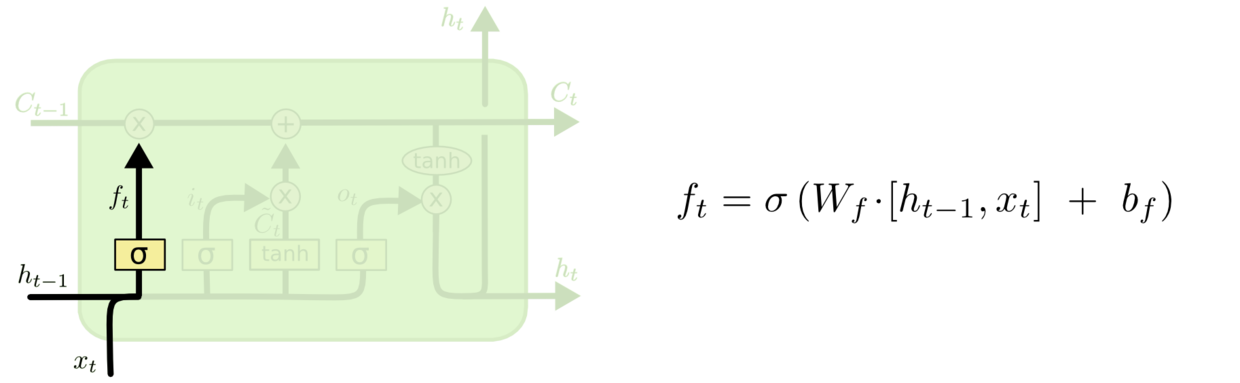
图 3.6.4 LSTM“忘记门”图
第二个门为输入门,决定什么值将被更新。具体值操作如图 3.6.5 中所示。
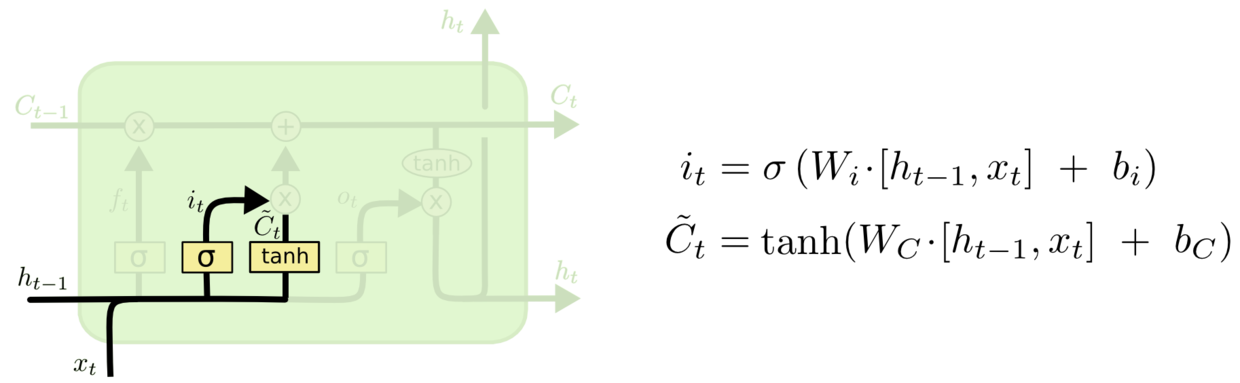
图 3.6.5_a LSTM“输入门”图 a
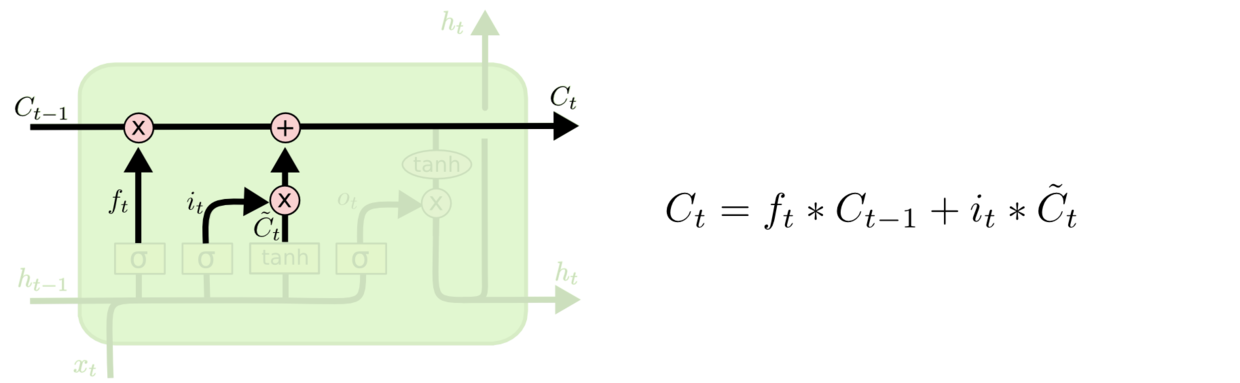
图 3.6.5_b LSTM“输入门”图 b
第三个为输出门,决定输出的信息。首先会运行一个 sigmoid 层来确定细胞状态的哪个部分将被输出。然后将细胞状态通过 tanh 进行处理并和 sigmoid 门输出相乘,最终输出。具体操作如图所示
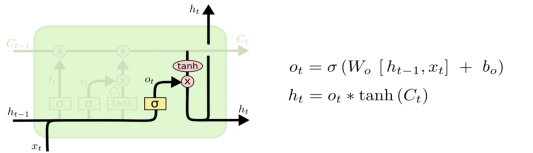
图 3.6.6 LSTM“输出门“图
四、系统详细设计
4.1 基本流程概述
- 流程分为两个部分,一是文本检测,二是文本识别。
- 文字检测的主要功能为:从图像中找到文字区域,并将文字区域从原始图像中分离出来。
- 文字识别的主要功能为:从分离出来的图像上,进行文字识别。
文字识别流程:
- 预处理:去噪(滤波算法)、图像增强、缩放,其目的是去除背景或者噪点,突出文字部分,并缩放图片为适于处理的大小
- 特征抽取:常用特征:边缘特征、笔画特征、结构特征、纹理特征。
- 识别:分类器,随机森林 、SVM、NN、CNN 等神经网络。
- 图 4.1 检测识别流程图
4.2 图像预处理
不管是在训练模型前,还是实际使用模型检测识别图片之前,对图像进行一个预处理是十分有必要的。比如说,因为我们并不可能控制每次检测都是理想情况,图片清晰,文本行水平,无遮挡物等等理想条件,这时候通过一个预处理一张图片,人为的去加上这些条件,那么在实际使用模型的时候就会有很好的鲁棒性。
4.3 模型训练
机器学习的核心就是让机器按照自己的需求,提取需要检测的物体对应的特征,找到这种物体与其他物体的区别,不断的去学习,从而产生一个模型,然后用这个模型去对你需要检测的物体来进行检测。
所以首要的就是去训练一个模型,而模型是需要通过人工的去标定大量的图片样本来找到需要检测的物体。通俗的说,就是给每张样本图片的目标物体进行一个定位,一般的我们采用一个矩形框来定位(矩形框定位只需要对角线上的两个点就能完成,方便快捷易操作),然后对应的给这个矩形框打上对应的标签,比如说我们现在的目标是检测文本,那么我们就用矩形框将样本图片内的文字框起来然后打上标签 text。一般说来样本越多那么识别结果就会更准确。
4.3.1 数据集制作
本次文本检测所使用的训练集是基于 VOC 格式经过转化而成 tensorflow 专用的 record 文件。具体过程如下。
首先,我们需要获得大量的包含文本的图片,然后借助于一些脚本工具辅助下(网上已经有很多成熟工具,个人用的 GitHub 上 EddyGao 的 make_voc2007),我们人工的去标定出文本的位置,并且为其打上 text 标签。此时工具会为对应的为你所标记的图片生成一个 XML 文件。然后将你的数据集分为训练集和测试集,一般情况下当数据集较小的时候训练集测试集的比例大概为 7:3,当数据集扩大到百万级别时,此时不需要那么多的测试集,我们可以调整比例为 99:1。由于此次我的文本检测模型准备的图片为 6000 张所以比例设置为 5:1,而文本识别模型约 340 万张图片样本,所以比例设置为 99:1。将分配好的数据集以保存图片名的方式保存在两个 txt 文档中。利用 tensorflow 框架将图片文件、XML 文件、txt 文件的信息转化为两个 record 文件。最后的这两个 record 文件就是我们所需要的数据集。也许笔者在此写的不是很明白,但是网上已经有很多资料教程可以参考,不明白的地方可以很容易的查到。
4.3.2 模型制作
Tensorflow 目标检测的模型制作 Goole 现在已经做的十分容易制作了,GitHub 有许多可用的源码,在训练之前,为了得到适合自己目标的模型,我们需要对模型的配置进行调参。
调参的最终目的是要使训练之后的模型检测物体更精确,向程序的方向更靠近一步的话,就是使得损失函数(例如 SSD 中的 loss)尽量小(因为利用训练集训练出来的模型质量在训练过程中只能靠验证集来检测)。
因此,调参可以看做一个多元函数优化问题。
需要我们去调的参数指的并不是我们通过训练得到的参数数据(例如我们机器学习中的 b,w),而是在模型开始学习过程之前就已经人为设置值的参数,深度学习里称之为超参数。例如树的数量或深度、学习率、深层神经网络隐藏层数、k 均值聚类中的簇数等等。
深度学习中常用的调节参数如下:
学习率(learning rate)
学习率的调整应该是一个很常见的操作。一般随着迭代次数的提高,当 loss 下不去的时候会先暂停训练模型,然后将 learning rate 调整至原来的 1/10 再继续进行训练。
原因是,梯度下降过程中的学习率可以看做下山过程中的步长,假设你的一步很大可以跨过山谷直接踩到对面的山上的话,就很难得到局部最优解。此时,减小步长会提高你走到地面的概率。
有关过拟合
利用 drop out、batch normalization、data argument 等方法可以有效防止过拟合,通过调整 drop out 中每个神经元被抛弃的概率可以调整模型的泛化能力。
- 网络层数
- 一般来说,网络层数越多,模型的性能(包括灵敏度、收敛等)就会越好(这也是为什么深度神经网络最近这么火的原因之一)。相应地,对计算能力的要求就会更高。
- 而且,层数越多,神经元节点数越多,过拟合的概率就会越高。利用 2 中的各种方法防止过拟合。
c++
Batch_Size
- 可以适当增大 batch_size,但这种方法可能会对计算机性能有所影响,
- batch_size 增大到某个时候,可以达到时间上最优;
- batch_size 增大到某些时候,可以达到最终收敛精度上最优。
4.4 文本检测
文本检测主要参照的是 2016 乔宇老师团队的 CTPN,本人在检测过程发现,如果只是单纯的标记出文本框来制作模型检测文本的话,检测出的文本框位置很大可能是不准确的,因为我们标记时是以行为单位,但是每行的长度在不同的图片样本中并不是确定的,甚至可以说变化很大,所以这么标记检测的结果很可能就是一行检测出多个文本框,而实际上我们需要的只是最大的那个刚好包住该行所有文本的框。

图 4.4.1 faster-rcnn 检测结果图
显然上图的结果并不是我们想要的,CPTN 中提出另外一个思路,把每个检测框改为一个个小的定长的框,然后把一个个小框串联起来,最后获得我们所需的文本框。

图 4.4.2 CTPN 检测结果图
具体的做法为:大胆的预测竖直方向上的位置。使用一个与 faster rcnn 中 anchor 方法类似的 vertical anchor 方法,区别在于 vertical anchor 方法中我们将框的宽度固定,CPTN 中使用的固定宽度为 16 个像素,高度则在 11 像素到 273 像素之间变化,一共 10 个 anchor。但是这也造成了小于 11 个像素或者大于的文本 273 像素的文本无法本检测出。
因为水平的文本框之间是有联系的,为了使检测的结果更具鲁棒性,这里将采用 CNN+RNN 的一种网络结构。
4.4.1 检测过程综述
检测过程大致分为 6 个步骤:
- 第一步,使用 VGG16 的前 5 个卷积块将图片转化为 feature map(特征图);
- 第二步,在第一步得到 feature map 上取 3 3 C 的滑动窗口特征;
- 第三步,将上一步的特征送到 RNN(BLSTM)中,得到 W*256 的输出。
- 第四步,将第三步的输出输入到 512 维的 fc 层。
- 第五步,将 fc 层特征输入到回归层得到 text proposals。
- 第六步,将上一步得到 text proposals 使用文本线构造算法,合并为最终的文本框。

图 4.4.3 CTPN 算法过程图
4.4.2 feature map(W H C)
检测方法是基于 faster-rcnn 来设计的,我们首先使用 VGG16 作为初始模型,将预处理过后的图像作为输入给到 VGG16 神经网络。
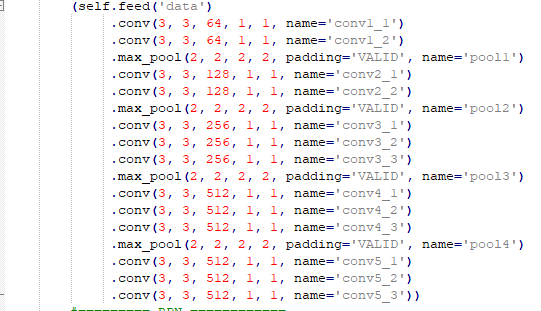
图 4.4.4 VGG16 配置代码图
如图 4.4.5,假设图像是一张 300*300 大小的 3 通道图由绿色方块表示,两个黄色方块表示 VGG16 的第一层(Conv1_1)和第二层(Conv1_2),两层合称 Conv1。
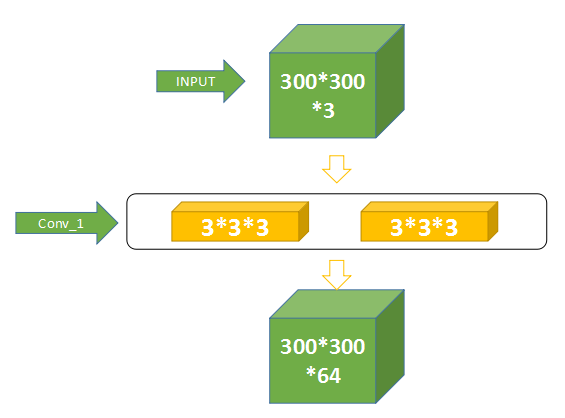
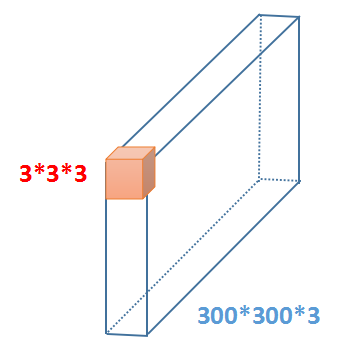
图 4.4.5 VGG16 Conv1 卷积过程图
假设蓝色框代表一个 RGB 图像,橙色代表一个 3 3 3 的卷积核,我们对一个三维的 27 个数求和,然后扫过去,由于我们做了 pad(填充操作),所以将会得到一个二维的 300 300 1 的矩阵,VGG 的第一层配置由 64 个卷积核,所以输出为 300 300 64 的矩阵。
Conv1 与 Conv2 之间有个 pooling(池化)层,这一层的配置为 2 2 64,步长为 2,根据之前所得公式,300 300 64 的输入经过该池化层后的输出为 150 150 64。然后输入到 Conv2_1,之后的操作原理与此相同,不再重复叙述。一个 300 300 3 的图像经过 VGG16 神经网络模型的 13 层卷积操作和 4 层池化操作后,将会变成 19 19 512 的 feature map

图 4.4.6 VGG16 中 Conv1 至 Conv2 过程图
4.4.3 滑窗
通过 VGG16 得到 Feature map,然后在这个 feature map 上做滑窗,窗口大小是 3×3。也就是每个窗口都能得到一个长度为 3×3×C 的特征向量。这个特征向量将用来预测和 10 个 anchor 之间的偏移距离,也就是说每一个窗口中心都会预测出 10 个 text propsoal。
4.4.4 BLSTM
BLSTM 指的是双向的 LSTM,LSTM 在论文第三部分有一定介绍。具体实现请参考网上的各种资料和代码。大概的作用就是通过目前已有信息去判断下一步的信息,有点类似于输入法的联想功能,只是这个“联想”更加的强大。
在 CTPN 中,每个 LSTM 包含 128 个隐藏层,双向则表示一共 256 个隐藏层,所以当我门将上一步滑动窗口得到的 3 3 C 特征输入,假设将 Conv5 展开后一共得到 W 3 3 C 的输出,我们将会得到一个对应的 W 256 维特征。
4.4.5 全连接
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为 1x1 的卷积;而前层是卷积层的全连接层可以转化为卷积核为 hxw 的全局卷积,h 和 w 分别为前层卷积结果的高和宽。
在 CTPN 中,将 BLSTM 的 W*256 维输出输入到 512 维的全连接层。
4.4.6 text proposals
将上一步得到的 fc 特征输入到输出层。输出层部分主要有三个输出。2k 个 vertical coordinate,因为一个 anchor 用的是中心位置的高(y 坐标)和矩形框的高度两个值表示的,所以一个用 2k 个输出。(注意这里输出的是相对 anchor 的偏移)。2k 个 score,因为预测了 k 个 text proposal,所以有 2k 个分数,text 和 non-text 各有一个分数。k 个 side-refinement,这部分主要是用来精修文本行的两个端点的,表示的是每个 proposal 的水平平移量。这是会得到密集预测的 text proposal,所以会使用一个标准的非极大值抑制算法来滤除多余的 box。
4.4.7 文本线构造
文本线构造算法(多个细长的 proposal 合并成一条文本线)
主要思想:每两个相近的 proposal 组成一个 pair,合并不同的 pair 直到无法再合并为止(没有公共元素)
判断两个 proposal,Bi 和 Bj 组成 pair 的条件:
c++
Bj->Bi, 且Bi->Bj。(Bj->Bi表示Bj是Bi的最好邻居)
Bj->Bi条件1:Bj是Bi的邻居中距离Bi最近的,且该距离小于50个像素
Bj->Bi条件2:Bj和Bi的vertical overlap大于0.7
但是这样导致的一个问题是,虽然中间没有关系,但是 text line 的两边是不是会出现误差,所以引入了 side-refinement 机制。它的核心就是在预测 k 个 scores 和 2k 个垂直方向的坐标偏移量的同时,还要预测 k 个边缘偏移量,用来计算 proposal 和 text line 最左边和最右面的位置偏移,边缘偏移量的计算公式和竖直方向的偏移量计算有一点相似,具体可以参考论文。另外要注意这个边缘偏移量是只计算当前 proposals 到最近的那一边(比如离左边 text side 近就是算到左边缘的偏移位置),因此只有 k 个边缘偏移量而不是 2k 个。
4.5 文本识别
通过文本检测之后我们就能定位出文本的位置,从而更加方便的进行文本识别。本次文本识别是基于 keras 框架下使用 densenet + ctc 网络模型来进行识别的。
4.5.1 densenet
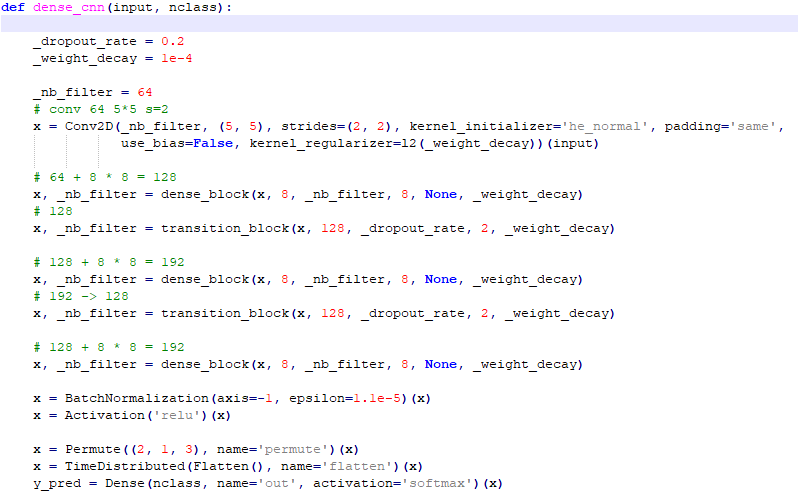
图 4.5.1 densenet 网络配置代码图
Densenet 对文本检测所称所得的文本进行预测,本次识别一共 5990 个字符,所以包含 5990 个类别,具体配置如图,更多的详细配置请参考代码。
4.5.2 CTC
CTC 模型(Connectionist temporal classification,连接时序分类)接在 RNN 网络的最后一层用于序列学习所用;对于一段长度为 T 的序列来说,每个样本点 t 在 RNN 网络的最后一层都会输出一个 softmax 向量,表示预测概率;接上 CTC 模型之后,就可以正确预测出序列的标签。
五、实验结果
5.1 数据来源
检测模型制作所用数据来源于 GitHub 作者 eragonruan,格式为 VOC2007,其中主要包括了 6000 张包含文本信息的图片以及图片对应制作生成的 XML 文件。
识别模型制作来源于 GitHub 作者 senlinuc,其中包括约 364 万张图片,并按照 99:1 生成训练集和验证集,图片利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成,包括汉字、英文字母、数字和标点共 5990 个字符。每张图片样本固定包含 10 个字符,字符为随机截取语料库中句子。分辨率统一为 280*32。
其他验证测试则来源于 ICDAR2013,随机的街景拍照,随机截图文档。
5.2 软件硬件环境
- 本次设计的环境如下
- 软件环境
- 操作系统 ubantu 16.04
c++
Tensorflow tensorflow1.3.0-gpu
Python python2.7
硬件环境
c++
CPU Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz
GPU TITAN X (Pascal)
5.3 判断标准
表 5.3 分类标准
| 正类 | 负类 | |
|---|---|---|
| 预测为正类 | TP | FP |
| 预测为负类 | FN | TN |
如表 5.3 所示,通过 TP,FN,FP,TN 四个属性的定义,我们可以计算出几个机器学习分类效果的指标:
Accuracy,准确率)
如字面意思,准确率为所有预测正确标签数量除以所有标签数量,可以反映分类模型的整体识别效果。
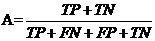
- (5.3.1)
- Precision,精确率)
- 精确率的计算方法为正类样本的预测正确数量除以所有预测为正类的样本量,反映了分类模型对正类的预测精确度。
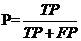
- (5.3.2)
- Recall,召回率)
- 召回率的计算方法为正类预测正确的样本除以所有正类样本数量,反映了对正类样本的识别率。
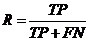
- (5.3.3)
- -Measure,综合评价指标)
- 在某些情况下,P 和 R 的值会出现矛盾,需要综合考虑才能完整评价一个分类模型的分类性能,所以这时候一般会采用综合评价指标这一属性。F 为 P 和 R 的加权平均值。
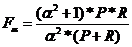
(5.3.4)
在本文次实验中,取
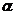
c++
= 1

(5.3.5)
5.4 CTPN 在 ICDAR 2011、ICDAR 2013、ICDAR 2015 库的检测结果
表 5.4.1 各类方法检测结果对比表
| ICDAR 2011 | ICDAR 2011 | ICDAR 2011 | ICDAR 2011 | ICDAR 2013 | ICDAR 2013 | ICDAR 2013 | ICDAR 2013 |
|---|---|---|---|---|---|---|---|
| Method | P | R | F | Method | P | R | F |
| Huang[11];Yao[12];Huang[13];Yin[14];Zhang[21];TextFlow[16];Text-CNN[17];Gupta[18] | 0.82;0.82;0.88;0.86;0.84;0.86;0.91;0.92 | 0.75;0.66;0.71;0.68;0.76;0.76;0.74;0.75 | 0.73;0.73;0.78;0.76;0.80;0.81;0.82;0.82 | Yin[14];Neumann[19];Neumann[20];FASText[15];Zhang[21];TextFlow[16];Text-CNN[17];Gupta[18] | 0.88;0.82;0.82;0.84;0.88;0.85;0.93;0.92 | 0.66;0.72;0.71;0.69;0.74;0.76;0.73;0.76 | 0.76;0.77;0.76;0.77;0.80;0.80;0.82;0.83 |
| CTPN | 0.89 | 0.79 | 0.84 | CTPN | 0.93 | 0.83 | 0.88 |
| ICDAR 2015 | ICDAR 2015 | ICDAR 2015 | ICDAR 2015 |
|---|---|---|---|
| Method | P | R | F |
| CNN Pro.;Deep2Text;HUST;AJOU;NJU-Text;StradVision1;StradVision2;Zhang[22] | 0.35;0.50;0.44;0.47;0.70;0.53;0.77;0.71 | 0.34;0.32;0.38;0.47;0.36;0.46;0.37;0.43 | 0.35;0.39;0.41;0.47;0.47;0.50;0.50;0.54 |
| CTPN | 0.74 | 0.52 | 0.61 |
5.5 检测识别结果样例



图 5.5.1 检测效果图
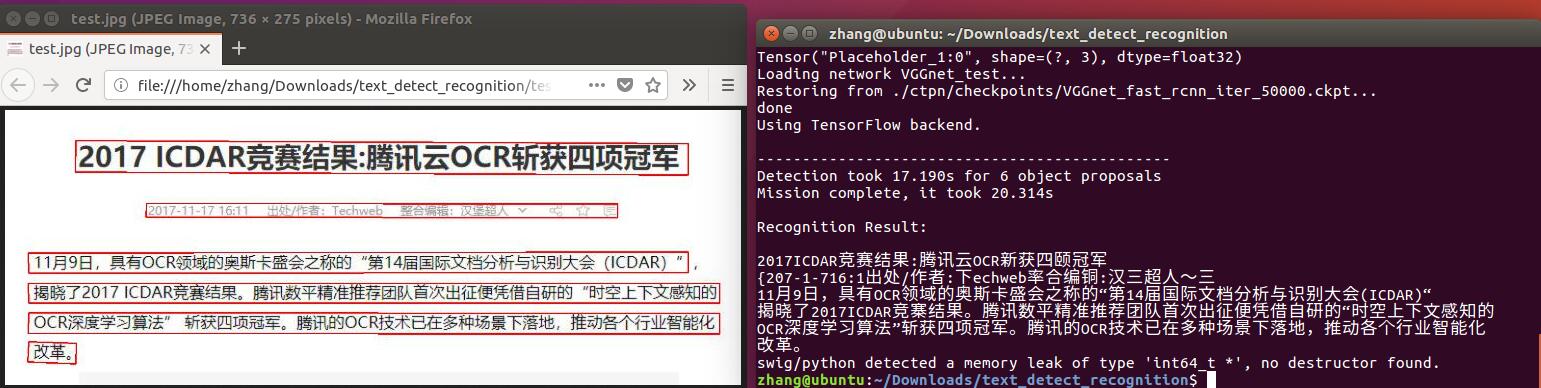
图 5.5.2_a 检测识别效果图

图 5.5.2_b 检测识别效果图
5.6 检测识别结果分析
从图 5.5.1 和 5.5.2 中可以看出,文本检测在识别水平文本的时候,如果图像拍摄的角度水平正对,图片清晰,则识别效果较好,若是文字倾斜较大或是文字竖直方向排列,则有可能会发生漏检,另外如果有一些和文字比较像的符号,则在检测过程中会发生误检。漏检的原因是因为本身方法和串联文本线的局限性所引起,而误检问题,个人认为纯属正常,因为中文本身就是由象形文字发展而来,而日常生活中的很多时候,各种追求艺术美的情况下,也会把文字改成一些艺术字,或者与其它物体相结合,这种误检也从侧面的反应出该方法具有不错的鲁棒性。
在识别方面,可以看到当识别一些打印出来的标准字体时,识别的效果还是比较明显的,但是在识别一些经过变形的艺术字,或者字形本来长的就比较像的字的时候,识别率就会大大的下降。这是由于在模型制作的时候,数据集来源于 GitHub 作者 senlinuc,其中的图片都是截取的新闻、文言文的标准字体。换句话说就是模型训练所用的数据还太少,理论上如果数据源足够全的情况下识别效果是可以大大提升的。另外一个比较可靠的方法就是在识别的基础上,再利用中文语义的相关性再次进行一个矫正,也能大大的提升效果。
六、总结
6.1 总结
自然场景文本检测与识别对于日常生活有着很高的实际价值,无数学者为此努力,并做出自己的贡献。目前已经在许多方面得到了应用,但是这个方向上努力进步的空间依旧很大,比如对有遮挡的文本识别,艺术字,模糊图像上文字的识别等等。目前对于这些仍未有比较好的算法。
本论文此次设计并未进行创新,而是对已有的方法进行学习整合,并加以运用,此次设计的具体内容有:
- 学习并初步的理解机器学习、深度学习的原理,以及一些相关的分类算法,比如决策树、SVM 分类、K 近邻等等。
- 学习理解一些网络模型并加以运用,如 RNN(循环神经网络)、CNN(卷积神经网络)、VGG16 等神经网络模型。
- 利用数据集,基于 tensorflow 框架训练制作相关的检测识别模型。
- 对模型达到的检测识别效果进行了一定问题总结和分析。
6.2 展望
本次设计的原本目标是要实时的去检测自然场下,日常生活中所含有的各种文本息。由于本人能力有限,虽然有一定的想法,但是自己无法实现,所以本次设计达到的效果很一般。在此说明提出一些需要改进的地方:
图像的预处理:在本次设计中,对于图像的预处理只有简单的放大缩小使输入图像大小相同。但是我在构思借鉴过程中,学习到 MSER(最大稳定极值区域)对图像做预处理可以将文本区域连通,以便于接下来的检测。
SWT(笔画宽度变换):在开始设计的时候,看到了 Epshtein 关于 SWT 做文本检测的论文,在找到的一些别人实现样例中发现效果不是很好。但是用来和本次设计做一个结合应该能提升检测效果。
数据源:在制作模型的时候,最终要的就是数据源的好坏,在深度学习中,好的数据源比好的方法更重要。本次设计中,检测模型只有 6000 张图片,数据较少,各种文本的类型也不是很全;识别模型虽然数据源数量足够,但是文本类型上做的不好,所以对于非打印文本效果不佳。
检测识别方法:无论如何,检测识别的方法上各类方法都有着一定的局限性,如果能找到一种对于所有文本都有很好检测识别效果的方法,将会减少对硬件性能的要求,以及计算量和数据源数量。
自身能力:自己的各种学习迁移能力一般,想到了也无法实现,对已有的各种方法也用的不好。需要继续的学习各种知识,提高动手能力和设计能力,才能更好的理解实现借鉴别人的思想继而做出真正自己的东西。
七、致谢
- 毕业设计经过和老师同学的几个月努力终于完成,从最初课题的选取,到收集各种资料,再到借用设备,编写论文每一步都离不开大家对我的帮助。
- 第一个要感谢的是指导老师李建军,李老师给我推荐了这个课题,并找了自己带的研究生王沉燕,给我进行指导帮助,在我自己电脑设备训练不了模型时,提供给我服务器完成模型训练。
- 还要感谢身边的同学,给了我设计实现的思路,帮我寻找相关的资料,并在论文编写时给了一定的建议和指导。
- 再次感谢李老师两年机器学习相关知识的传授和培养
- 感谢学校老师们对我各项能力的培养。
八、参考文献
Detecting Text in Natural Scenes with Stroke Width Transform Boris Epshtein Eyal Ofek Yonatan Wexler 978-1-4244-6985-7/10/$26.00 2010 IEEE
c++
TextBoxes++:
A Single-Shot Oriented Scene Text Detector .2018-arxiv
FOTS:
Fast OrientedText Spotting with a Unified Network .2018-arxiv
PixelLink:
Detecting Scene Text via Instance Segmentation .2018-AAAI
WeText:
Scene Text Detection under Weak Supervision .2017-arXiv
Single Shot Text Detector with Regional Attention .2017-ICCV
EAST:
An Efficient and Accurate Scene Text Detector .2017-CVPR
Deep Direct Regression for Multi-Oriented Scene Text Detection .2017-arXiv
Detecting oriented text in natural images by linking segments .2017-CVPR
Arbitrary-Oriented Scene Text Detection via Rotation Proposals .2017-arXiv
Huang, W., Lin, Z., Yang, J., Wang, J.:
Text localization in natural images using stroke feature transform and text covariance descriptors (2013), in IEEE International Conference on Computer Vision (ICCV)
Yao, C., Bai, X., Liu, W.: A unified framework for multioriented text detection and recognition. IEEE Trans. Image Processing (TIP) 23(11), 4737–4749 (2014)
c++
Huang, W., Qiao, Y., Tang, X.:Robust scene text detection with convolutional neural networks induced mser trees (2014), in European Conference on Computer Vision (ECCV)
Yin, X.C., Yin, X., Huang, K., Hao, H.W.: Robust text detection in natural scene images. IEEE Trans. Pattern Analysis and Machine Intelligence (TPAMI) 36, 970– 983 (2014)
c++
Busta, M., Neumann, L., Matas, J.:
Fastext:
Efficient unconstrained scene text detector (2015), in IEEE International Conference on Computer Vision (ICCV)
Tian, S., Pan, Y., Huang, C., Lu, S., Yu, K., Tan, C.L.:
Text flow:
A unified text detection system in natural scene images (2015), in IEEE International Conference on Computer Vision (ICCV)
He, T., Huang, W., Qiao, Y., Yao, J.: Text-attentional convolutional neural networks for scene text detection. IEEE Trans. Image Processing (TIP) 25, 2529–2541 (2016)
c++
Gupta, A., Vedaldi, A., Zisserman, A.:
Synthetic data for text localisation in natural images (2016), in IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Neumann, L., Matas, J.:
Efficient scene text localization and recognition with local character refinement (2015), in International Conference on Document Analysis and Recognition (ICDAR)
Neumann, L., Matas, J.:
Real-time lexicon-free scene text localization and recognition. In IEEE Trans. Pattern Analysis and Machine Intelligence (TPAMI) (2015)
Zhang, Z., Shen, W., Yao, C., Bai, X.:
Symmetry-based text line detection in natural scenes (2015), in IEEE Computer Vision and Pattern Recognition (CVPR)
Zhang, Z., Zhang, C., Shen, W., Yao, C., Liu, W., Bai, X.:
Multi-oriented text detection with fully convolutional networks (2016), in IEEE Conference on Computer
Vision and Pattern Recognition (CVPR)
参考文献
- 面向自然场景中商户门店名称识别的深度学习算法研究(山东大学·张雯)
- 深度学习在社交网络文本分类中的应用研究(大连交通大学·方金朋)
- 基于深度学习的汉字书法风格识别方法研究(哈尔滨理工大学·陈国栋)
- 基于深度学习的OCR检测与识别技术研究(北方工业大学·冯少贤)
- 基于图谱实体表示与排序学习的文本检索方法研究(吉林大学·毕磊)
- 面向不同错误类型的中文文本纠错方法研究(湘潭大学·龙广玉)
- 基于深度学习的验证码识别技术(大连交通大学·慕亚东)
- 面向网络敏感信息的主题检测和情感分析研究与实现(东华大学·许成)
- 企业知识文档检索管理系统的设计与实现(哈尔滨工业大学·王明月)
- 论文复制检测管理系统的设计与实现(北京邮电大学·李志斌)
- 基于图谱实体表示与排序学习的文本检索方法研究(吉林大学·毕磊)
- 基于图谱实体表示与排序学习的文本检索方法研究(吉林大学·毕磊)
- 深度学习在社交网络文本分类中的应用研究(大连交通大学·方金朋)
- 中文文本自动校对系统设计与实现(西南交通大学·张涛)
- 中文文本自动校对系统设计与实现(西南交通大学·张涛)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码工坊 ,原文地址:https://m.bishedaima.com/yuanma/36077.html









