
使用 python 进行音频处理
实验目的及实验内容
(本次实验所涉及并要求掌握的知识;实验内容;必要的原理分析)
实验目的:
使用 python 进行音频处理
实验内容:
学习音频相关知识点,掌握 MFCC 特征提取步骤,使用给定的 chew.wav 音频文件进行特征提取。音频文件在实验群里下载。
部署 KALDI,简要叙述部署步骤运行 yes/no 项目实例,简要解析发音词典内容,画出初步的 WFST 图(按 PPT 里图的形式)。
调整并运行 TIMIT 项目,将命令行输出的过程与 run.sh 各部分进行对应,叙述顶层脚本run.sh 的各部分功能(不需要解析各训练过程的详细原理)。
原理分析:
对 chew.wav 进行特征提取声音信号本是一维时域信号(声音信号随时间变化),我们可以通过傅里叶变换将其转换到频域上,但这样又失去了时域信息,无法看出频率分布随时间的变化。短时傅里叶(STFT)就是为了解决这个问题而发明的常用手段。
所谓的短时傅里叶变换,即把一段长信号分帧、加窗,再对每一帧做快速傅里叶变换(FFT),最后把每一帧的结果沿另一个维度堆叠起来,得到类似于一幅图的二维信号形式。
语音信号是不稳定的时变信号,但为了便于处理,我们假设在一个很短的时间内,如-40ms 内为一个稳定的系统,也就是 1 帧。但是我们不能简单平均分割语音,相邻的帧之间需要有一定的重合。我们通常以 25ms 为 1 帧,帧移为 10ms,因此 1 秒的信号会有 10 帧。
我们可以使用离散傅里叶变换(DFT)把每一帧信号变换到时域,公式是:
其中 s(n)表示时域信号;si(n)是第 i 帧的数据,其中 n 的范围是 1-400;当我们介绍 DFT的时候,Si(k)表示的是第 i 帧的第 k 个复系数。h(n)是一个 N 点的窗函数(比如 Hamming 窗),K是 DFT 的长度。有了 Si(k)我们就可以估计功率谱,Pi(k)是第 i 帧的功率谱:
这样,我们就得到了周期图的功率谱估计,即声谱图。它的横坐标是帧下标,纵坐标是不同频率。声谱图往往是很大的一张图,且依旧包含了大量无用的信息,所以我们需要通过梅尔标度滤波器组(mel-scale filter banks)将其变为梅尔频谱。
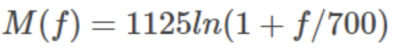

梅尔尺度(Mel Scale)是建立从人类的听觉感知的频率——Pitch 到声音实际频率直接的映射。频率的单位是赫兹(Hz),人耳能听到的频率范围是 20-20000Hz,但人耳对 Hz 这种标度单位并不是线性感知关系,例如,若把音调频率从 1000Hz 提高到 2000Hz,我们的耳朵只能觉察到频率似乎提高了一些而不是一倍。但是通过把频率转换成美尔尺度,我们的特征就能够更好的匹配人类的听觉感知效果。从频率到梅尔频率的转换公式如下:
为了模拟人耳对声音的感知,人们发明了梅尔滤波器组,一组大约 20 - 40(通常 26)个三角滤波器组,它会对上一步得到的周期图的功率谱估计进行滤波。而且区间的频率越高,滤波器就越宽(但是如果把它变换到梅尔尺度则是一样宽的)。为了计算方便,我们通常把 26 个滤波器用一个矩阵来表示,这个矩阵有 26 行,列数就是傅里叶变换的点数。保留这 26 个滤波器的能量。
将滤波器应用到能量谱后得到的就是梅尔频谱。具体地,以每个滤波器的频率范围内的输出作为权重,乘以能量谱中对应频率的对应能量,然后把这个滤波器范围内的能量加起来。(26个滤波器,则每一帧最后只有 26 个输出)。
在梅尔频谱上做倒谱分析(取对数 log,做离散余弦变换(DCT)变换)就得到了梅尔倒谱。这里取 log 也是源于人耳的听力系统,人对声音强度的感知也不是线性的,一般来说,要使声音的音量翻倍,我们需要投入 8 倍的能量,为了把能量进行压缩,所以取了 log;做 DCT是因为不同的 Mel滤波器是有交集的,因此它们是相关的,我们可以用 DCT 变换去掉这些相关性。
对上面得到的 26 个点的信号进行 DCT(对功率谱做 DCT 的目的就是为了提取信号的包络),得到 26 个倒谱系数(Cepstral Coefficents),最后我们保留 2-13 这 12 个数字,这 12 个数字就叫 MFCC 特征。只取 2-13 个数字是因为后面的能量(前面的能量)表示的是变化很快的高频信号(低频信号),在实践中发现它们会使识别的效果变差。
总结起来,梅尔倒谱系数(MFCC)特征提取包含以下几个步骤:
- 对语音信号进行分帧处理;
- 用周期图(periodogram)法来进行功率谱(power spectrum)估计;
- 对功率谱用 Mel 滤波器组进行滤波,计算每个滤波器里的能量;
- 对每个滤波器的能量取 log;
- 进行离散余弦变换(DCT)变换;
- 保留 DCT 的第 2-13 个系数,去掉其它。
其中第 1、2 步是做短时傅里叶变换,第 3 步做梅尔频谱,第 4 步对梅尔频谱取 log,第 5步得到梅尔倒谱,第 6 步得到 MFCC 特征。利用 librosa 库中已经封装好的函数可以很方便地得到一份音频文件的 MFCC 特征,相关代码如下所示:
KALDI 的部署与测试
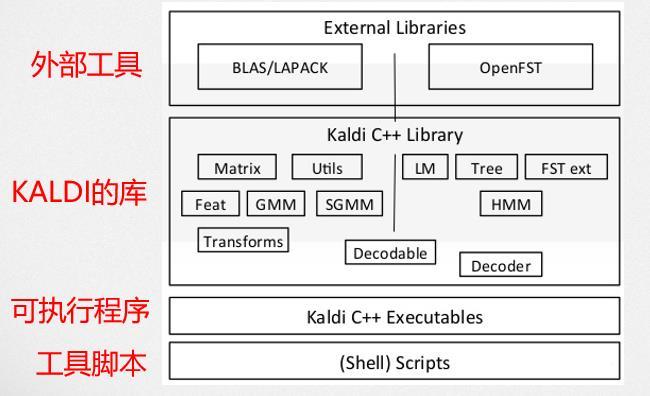
Kaldi 是当前最流行的开源语音识别工具(Toolkit),它使用 WFST 来实现解码算法。Kaldi的主要代码是 C++编写,在此之上使用 bash 和 python 脚本做了一些工具。
Kaldi 架构如下图所示:
大多数情况下,我们只需要使用 KALDI 脚本和配置文件就可以完成语音识别系统的训练和预测了。
TIMIT 程序是 Kaldi 中经典的语音识别处理程序。在该程序中包含了常见的语言特征提取步骤以及多个模型训练方法的运行。其中包括:常见的 mfcc 特征提取或者 CMVN 特征提取;LDA+MLLT(Linear Discriminant Analysis,线性判别分析 Maximum Likelihood LinearTransform ,最大似然线性变换)LDA + MLLT + SAT 变换以及 SGMM2(subspace GMM,子空间高斯混合模型)等;另外还包括(maximum mutual information)准则最大化观察序列分布和DNN(Deep Neural Network)深度神经网络结合的训练方法。
TIMIT 程序采用的数据集为 Kaldi 中一段常用的数据集,该数据集的名称即为 TIMIT。该数据集为 1993 年来自美国英语八个方言的录音,录制者为 SRI International (SRI) and Texas Instruments, Inc. (TI),收录于 Massachusetts Institute of Technology (MIT)。该数据集包含有男女录音共 630 小时,采样频率为 16kHz,采样精度为 16-bit。全称为:TIMIT Acoustic-Phonetic Continuous Speech Corpus.
TIMIT 文件目录结构如下图所示:
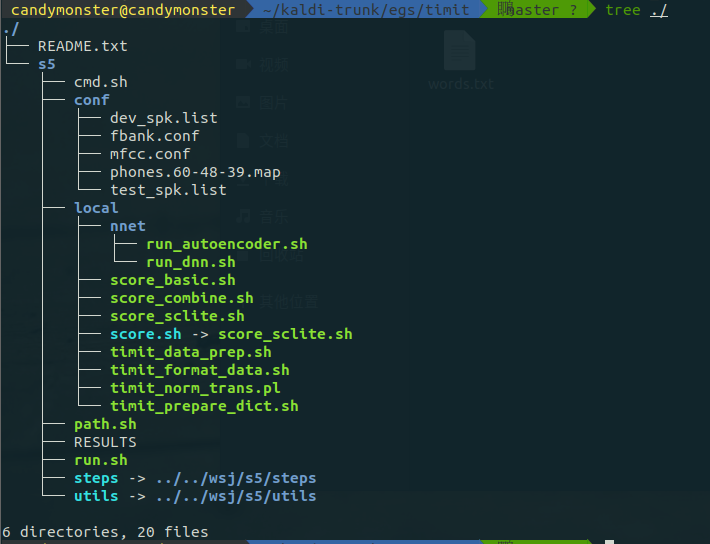
conf:主要配置文件,如提取 mfcc、fbank 等特征参数和解码时参数配置;
data:为储存数据集及测试集和训练集等;
exp:数据训练过程中产生的训练中间数据文件等;
lacal:存储数据准备阶段所需要的脚本文件;
mfcc:存储 mfcc 特征提取结果文件;
steps / utils:通用的模型训练中间步骤文件,如训练和解码脚本等。
cmd.sh:该脚本为运行模式的设置;Kaldi 的运行分为分布式的集群运行模式和个人本地
运行模式,一般的 pc 运行应该设置为 run 模式(local machine 模式);
path.sh:检查设置 Kaldi 命令和根目录下文件路径脚本;
RESULTS:保存训练测试结果的文本文件;
run.sh:程序运行训练操作的主要脚本。
该部分脚本文件主要为调用 Kaldi 工具包中的其他具体的模型处理脚本文件,达到对多个模型的融合。故对于单个程序来讲,本身的 run.sh并不复杂,均为调用其他需要的模型处理和训练解码脚本,相当于处理流程总目录的作用。因此,该 run 脚本文件对理解整个语音处理流程有简化作用,但当需要了解其中某一个模型的处理具体细节的时候,则需要追溯 run 脚本中的相关具体的脚本。
(dnn 就不强制要求了,exit 0 前面的跑完就行了)
实验环境
(本次实验所使用的器件、仪器设备等的情况)
处理器:Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz 2.40 GHz
操作系统环境:
-
MFCC 特征提取:Windows 10 家庭中文版 x64 19042.867
-
Kaldi 的部署及测试:Ubuntu 18.04.5 LTS
-
编程语言:Python 3.8
-
其他环境:16 GB 运行内存(物理机),3GB 运行内存(VMWare 虚拟机)
-
IDE 及包管理器:JetBrains PyCharm 2020.1 x64,anaconda 3 for Windows(conda 4.9.0)
实验步骤及实验过程分析
(详细记录实验过程中发生的故障和问题,进行故障分析,说明故障排除的过程及方法。根据具体实验,记录、整理相应的数据表格、绘制曲线、波形等)
说明:
由于网页时刻在更新,本篇实验报告所记录的内容仅为写报告时(2021/05/25)的情况,可能与实际实验时(2021/05/19)结果有出入。
一切以实际运行时所得到的结果为准。
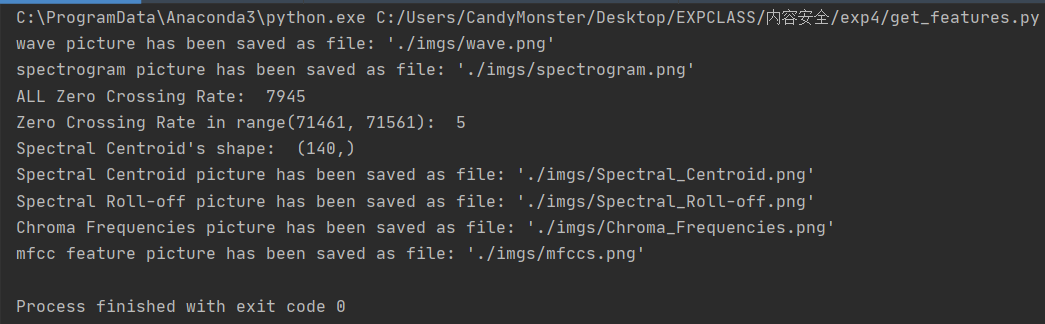
对 chew.wav 进行特征提取
运行情况:
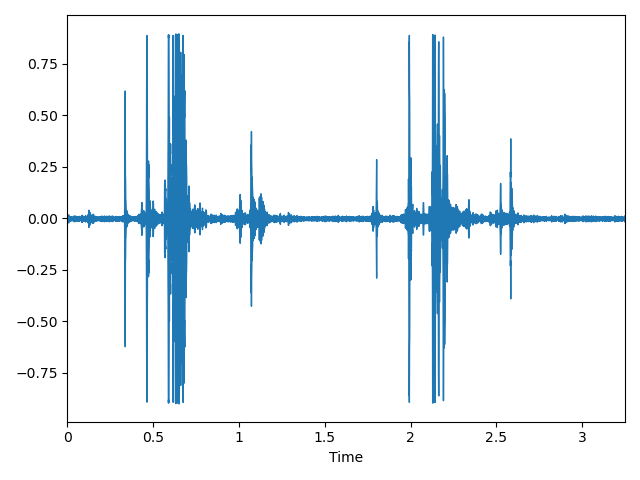
波形图 (Waveform):
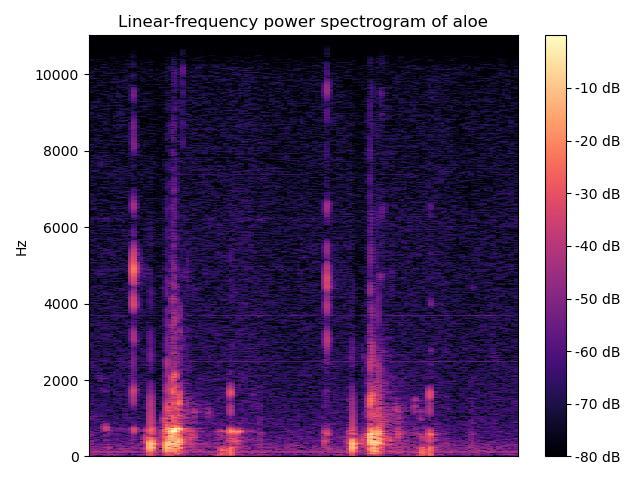
声谱图(spectrogram):
过零率 (Zero Crossing Rate)在运行情况中被打印出来了。
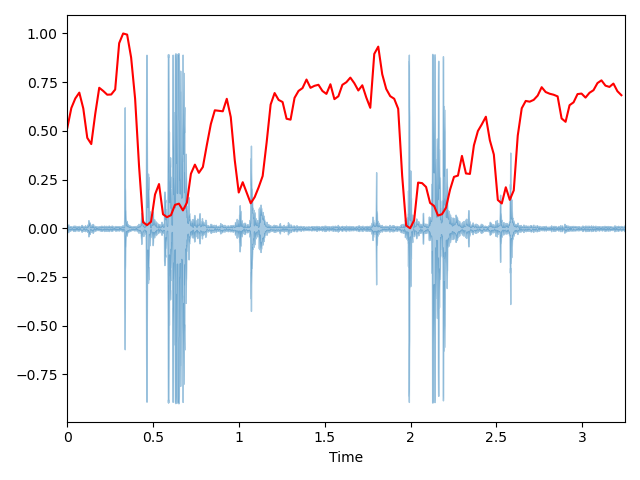
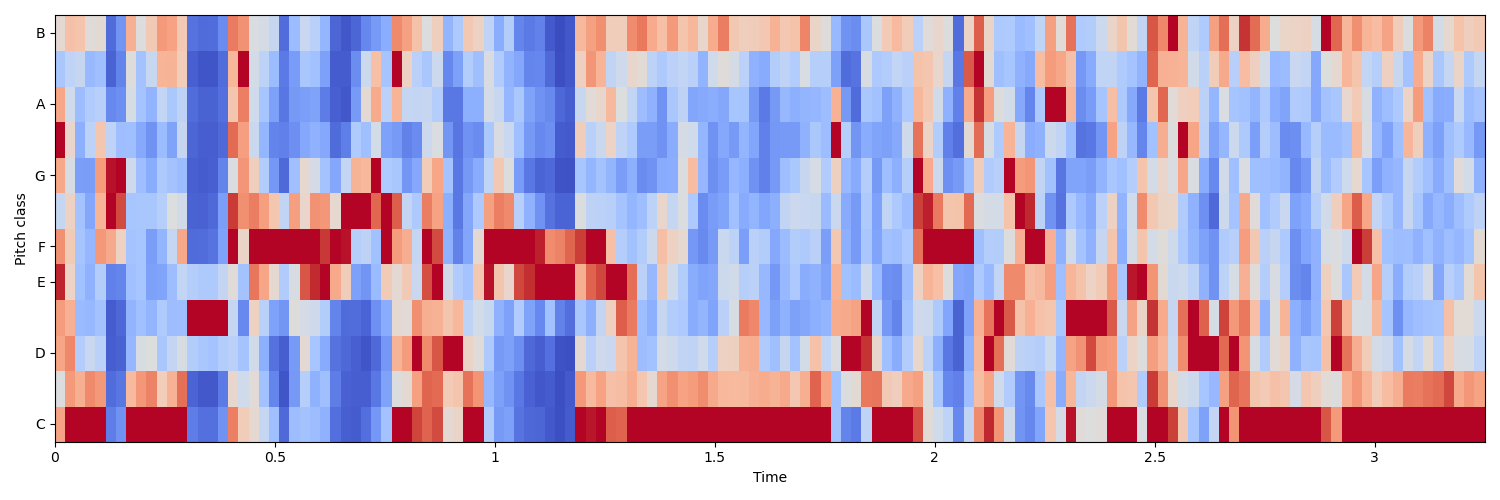
频谱质心 (Spectral Centroid):
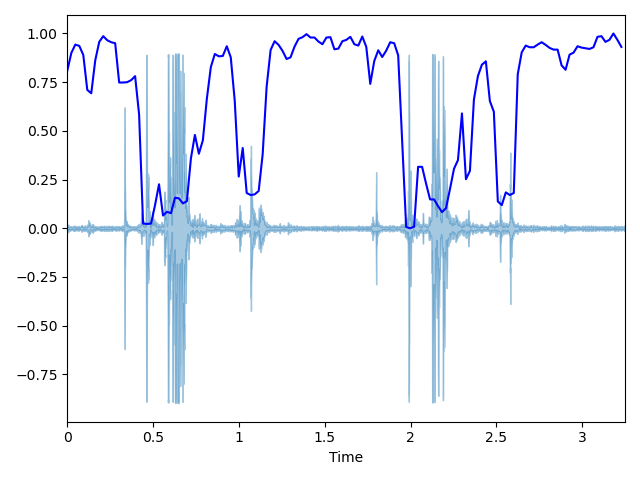
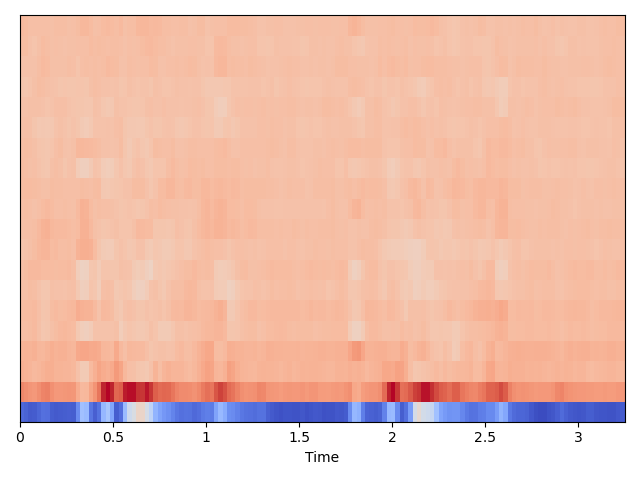
声谱衰减 (Spectral Roll-off):
色度频率 (Chroma Frequencies):
MFCC 特征提取 ( Mel Frequency Cepstral Coefficents ):
KALDI 的部署与测试:

部署过程:
首先把磁盘空间清理出来,按助教的说法得确保有 25G+的磁盘空间:
然后按照官网 http://kaldi-asr.org/doc/tutorial_setup.html 提示,将 Kaldi 项目克隆至本地:git clone https://github.com/kaldi-asr/kaldi.git kaldi-trunk --origin golden
克隆下来后查看各种安装说明后得知,需要到 kaldi-trunk/tools/extras/目录下运行脚本文件check_dependencies.sh 来检查各种依赖是否安装:
这里提示我需要执行命令 sudo apt-get install libtool,输入并执行:


其实这里发生了一点小插曲,在接下来的安装过程中还会有类似的情况发生,如下图所示:
它提示我没有可用的软件包,这里需要换源才能操作。一开始我用的是清华源,在这步之后我换成了 Ubuntu 在中国的主服务器。安装完成后再次运行 check_dependencies.sh,此时提示我没有 Intel MKL,要运行 extras 目录下的 install_mkl.sh 脚本来安装他。
运行脚本 install_mkl.sh:
中间还是有可能出现连接失败的提示,应该是网络的问题,等网络稳定一点或者换源 等
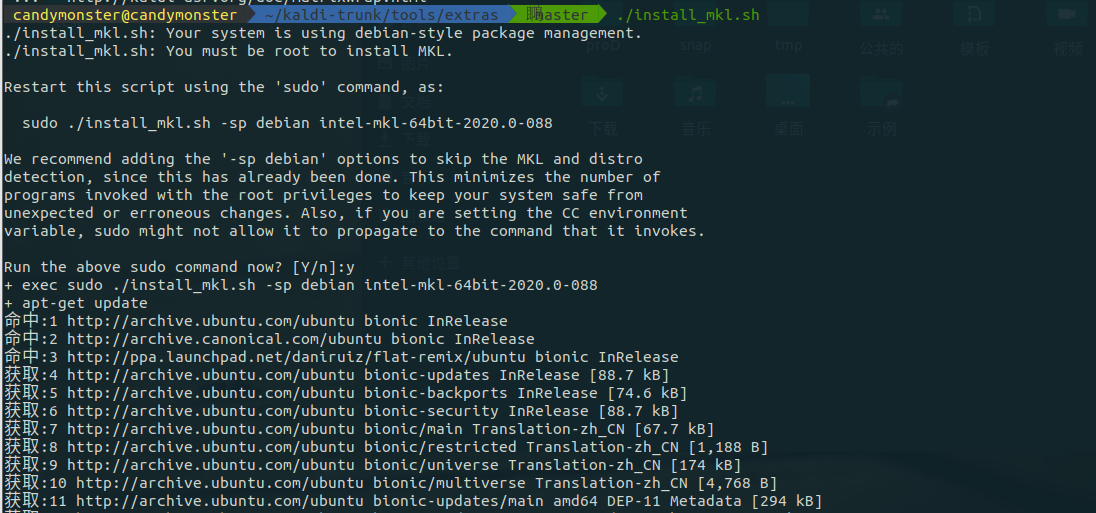
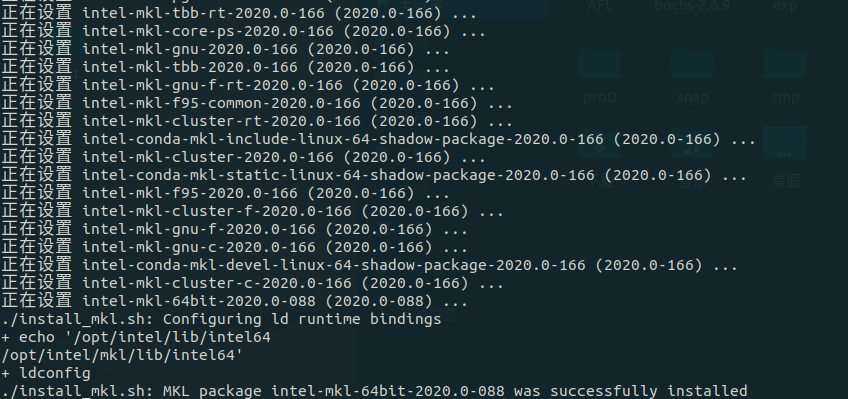

出现上图的提示就说明这个脚本执行成功了。之后再次运行 check_dependencies.sh,此时提示all OK.
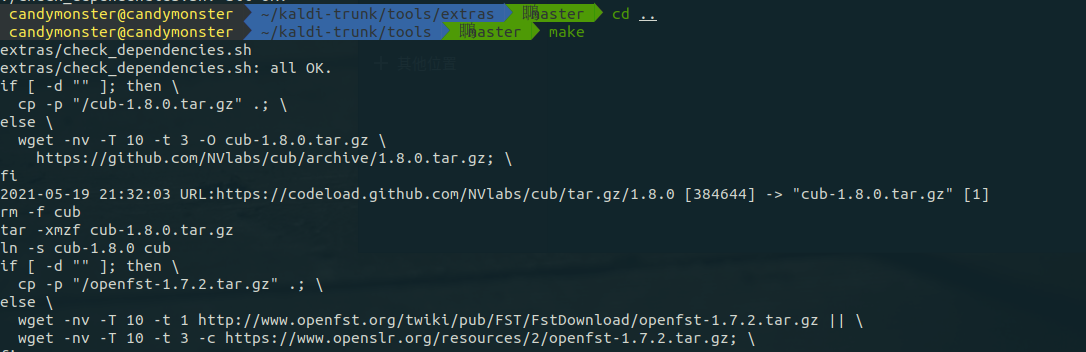
然后进入上一级,进行 make 编译。因为所有的操作都是在虚拟机上进行的,所以建议使用make 而非 make -j 4,否则很容易内存不够导致编译失败。make:
经过漫长的等待,屏幕滚过大量输出后,如上图最后一行所示出现 All done OK,这步就算完了。进入 src目录并查看 INSTALL:




进入 src目录运行 configure:
仔细阅读运行 configure 后显示的提示,它可能和上文所示的内容有所区别,其中提醒了你有哪些东西没安装好,并给出了指导,遵循那些执导完成相关依赖的安装,直到运行 configure
-
后出现的提示的最后显示“Successfully ”,此时才能进行后面的步骤,否则长时间的 make
-
后会报错。
-
执行最后的步骤,编译 kaldi 的源码。
make depend:
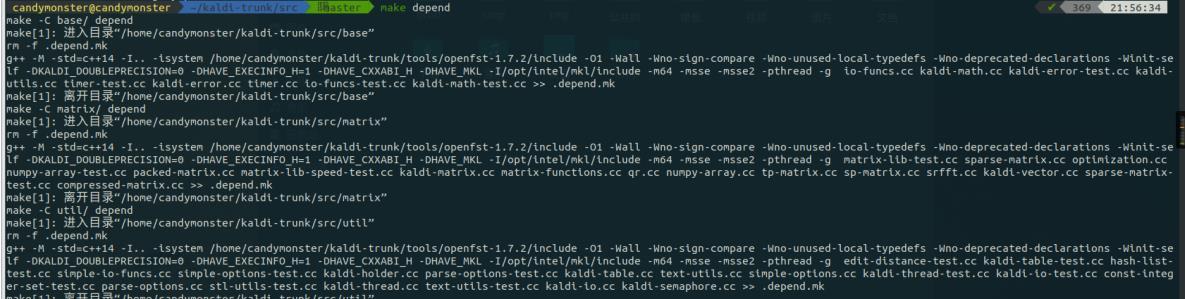
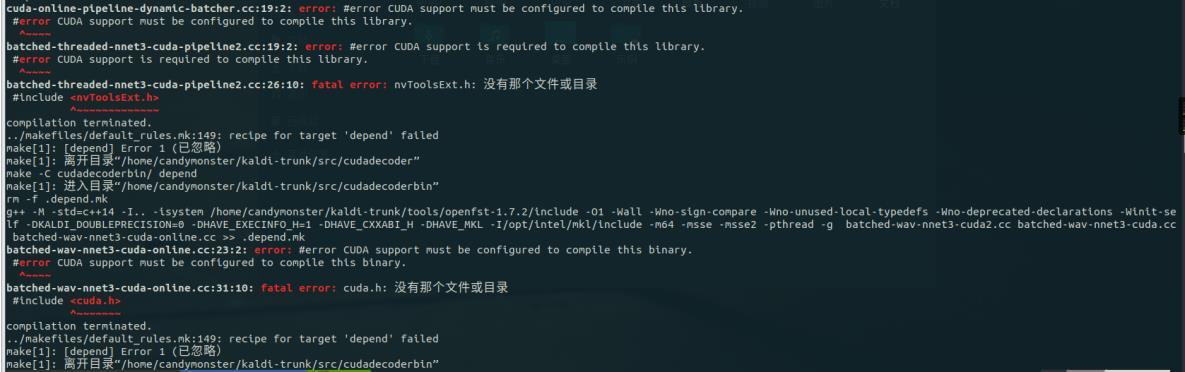
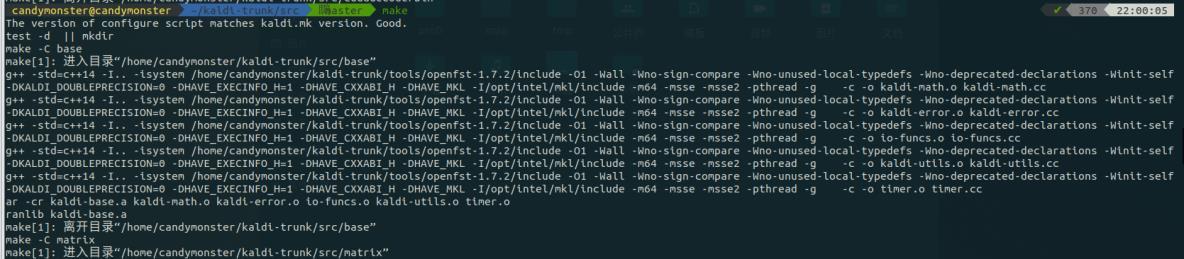


这里它报了一些跟 cuda 相关的错误如下图所示,先不用管,暂时用不到。
make:
经过漫长的等待,屏幕滚过大量输出后,如上图最后一行所示出现 Done,说明编译完成。
KALDI 的 yes/no 项目实例
运行一个例程来检验安装是否成功。运行 egs/yesno/s5 目录下的 run.sh:
运行后出现下图结果:
其中最后几行信息比较值得关注:WER 后跟着的 0.00 指字的错误率为 0,即准确率为100%;测试集一共 29 条音频,每条音频有 8 个字(单音素的字),一共 232 个字。


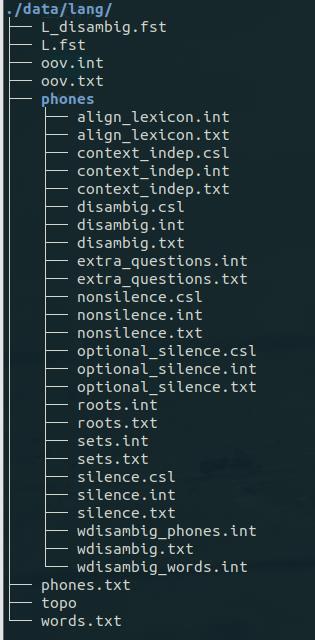
运行过程中会生成一些中间文件。如下图所示的 /kaldi-trunk/egs/yesno/s5/data/local/dict/目录:
其中有一个名为 lexicon.txt 的文件,这是一个发音词典。对于当前项目,我们只有两个词yes 和 no;然而在真实的语言中,词的数量更多,并且还有停顿和环境噪声。kaldi 将这些非语言的声音称作 slience(SIL),在本项目中,加上 SIL 一共需要三个词来表示当前这个 yes/no语言模型。发音词典 lexicon.txt 给出了 YES、NO 和
查看/kaldi-trunk/egs/yesno/s5/data/lang/文件夹:
其中有一个 phones.txt,这是一个音素集文件,包含上述 SIL、Y、N 三个音素,其内容如下图所示:


其中#0,#1 是空字,用来表示句子的开头和结尾。
c++
utils/prepare_lang.sh --position-dependent-phones false data/local/dict/ "<SIL>" data/local/lang/data/lang
为将语言模型转换成 G.fst格式并保存在 data/lang_test_tg 目录下,执行命令:
c++
local/prepare_lm.sh
这个脚本的核心内容是调用了 arpa2fst 和 fstisstochastic,再创建了 G.fst 之后检查是否有空字符(
,
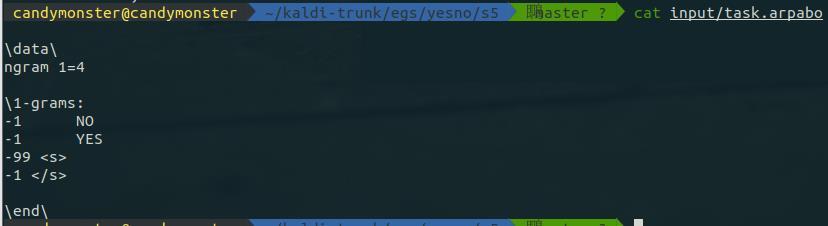
之类的)的循环。arpa 文件可以很容易地表示任意 n-gram语言模型,不过在实际中 n 通常等于 3、4 或者 5。arpa 文件的每一行表示一个文法项,它通常包含三部分内容:probability word(s) [backoff probability]。probability表示该词或词组发生的概率,word(s)表示具体的词或者词组。backoff probablitiy是可选项,表示回退概率。在 yes/no 这个 toy project 中只使用 1 元的语言模型。对应的 arpa 文件在 input/task.arpabo:
处理 FST 文件需要用到 openfst 工具,如果已经编译好了 kaldi,该工具应该在 kaldi/tools下。fstprint 和 fstdraw 是可视化用到的两个基本命令,先找这两个命令的位置:
fstprint 打印 fst 为文本格式,其参数有—isymbols 和—osymbols 分别表示输入符号表和输出符号表,这两个参数可以省略;fstdraw 可以将 fst 绘成图(需要配合 dot 命令)。
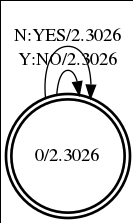
查看这个语言模型生成的 G.fst,将其用 fstprint 打印出来(symbols 选 words.txt)
上面是 G.fst 的打印结果。对于 fst,其打印结果,一行一般有 5 列。一行对应一个弧。第一列和第二列,表示这个弧的起始状态和终止状态。第三列和第四列,表示输入和输出。第五列是权重。要将其对应的图打印出来,就用 fstdraw命令得到.dot 文件,然后再用 dot 命令将.dot文件转换成.png 文件:
查看得到的图如下图所示:




run.sh 运行后会得到许多 fst,查看其他的 fst 文件:
一般而言,众多*.fst 的结果中,我们比较关心的有五个:分别是 H.fst、C.fst、L.fst、G.fst以及 HCLG.fst,其介绍依次如下所述:
-
fst:HMM模型;
-
fst:上下文环境;
-
fst:词典;
-
fst:语言模型;
-
HCLG.fst:由上述 4 个 fst经过一系列算法(组合、确定化和最小化等)组合而成的。分别查看 L.fst 和 HCLG.fst。查看词典对应的 L.fst:
查看词典对应的 WFST 图:
查看最终的 HCLG.fst(部分):
查看 HCLG.fst 对应的图:

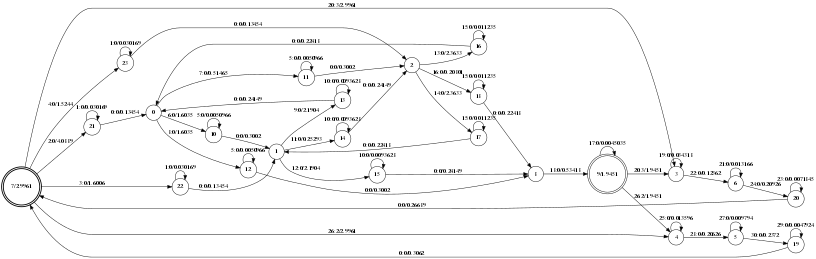
TIMIT 项目:
首先进入/kaldi-trunk/egs/timit/ 目录。再看一眼目录结构:
实验报告要求调整并运行 TIMIT 项目,将命令行输出的过程与 run.sh 各部分进行对应,叙述顶层脚本 run.sh 各部分的功能。运行 run.sh 前要先进入 kaldi 目录下的 tools/extras 目录,执行 install_irstlm.sh 脚本。安装完成以后,目录下出现 irstlim 目录。由于 timit 例程里面的引用irstlm工具的路径是 tools目录,所以把这个目录拷贝到 tools/目录下,然后再回到 egs/timit/s5目录执行./run.sh 脚本。否则会报错。


运行可能会报错“Output of qsub was: sh: 1: qsub: not found”,这是因为 TIMIT 部署在多机器上,想要在本地运行所有的任务,需要根据 cmd.sh 中的提示修改下配置,即将 cmd.sh 所有中的"queue.pl"改为“run.pl”。修改后的 cmd.sh 内容如下图:
逐行看一下 run.sh,其中前 14 行都是注释,写明了运行环境以及版权信息等,从第 15 行开始才是脚本的执行内容:
其中 15 - 32 行为参数设置,34 – 50 行为进行数据准备:39 行准备路径,41 行准备数据,43 行准备词典 47、48 两行准备语言文件,50 行准备训练集、开发集合测试集。
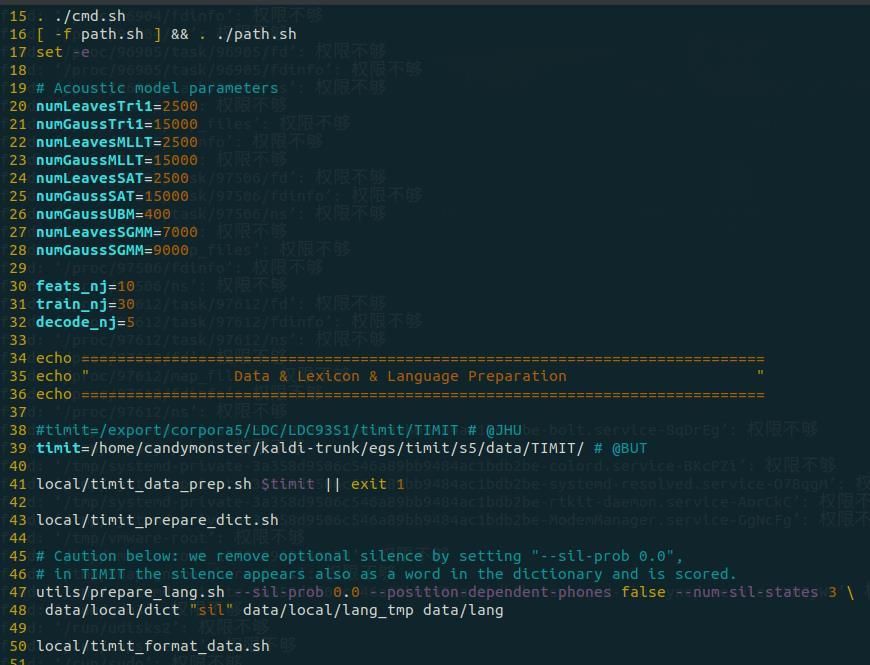

第 39 行 timit 对应的应该是数据集文件夹所在位置,即该文件夹路径:
其中 41 行 local/timit_data_prep.sh 为检查数据集完整性、对于 train、test 和 dev,分别生成相应:_sph.flist、_sph.scp、.uttids、.trans、.text(语音和语音编号之间的关系)、_wav.scp(原始语音的路径信息)、.utt2spk(语音编号和说话人编号之间的关系)、.spk2utt(说话人编号和说话人的语音编号的信息)、.spk2gender(包含说话人的性别信息)、.stm和.glm文件。
行 local/timit_prepare_dict.sh 为准备字典、生成对应的音素对应模型,生成的文件有:words.txt 和 phones.txt 等是 OpenFst 格式的符号表,表示音素到整数的映射。
行 prepare_lang.sh 主要的功能为根据之前的 prepare_dict 脚本生成的符号表进行进一步映射成 int 文件,完成音素符号表 int 格式的整理,为之后的处理做好准备具体的格式有待进一步研究理解。
该部分的执行结果如下图所示:
从输出信息可以看到,程序在进行一系列的检查。在执行完上面几行脚本之后,会出现一个data 目录,进入 data 目录会看到下面一些文件夹:
其对应关系为:



-
dev:开发集数据
-
lang:包含语言文件
-
lang_test_bg:用于测试的语言文件
-
local:包含了原始数据的信息,以及词典
-
test:测试集
-
train:训练集
随后的 52-63 行为特征提取(MFCC),通过调用 steps 文件夹下的 make_mfcc.sh 和compute_cmvn_stats.sh 来实现:
执行前面的代码,会生成两个文件夹:mfcc 和 exp/make_mfcc,其中 mfcc 里主要保存了提取的特征,而 exp/make_mfcc 里保存了日志,即 .log 文件。
在 steps/make_mfcc.sh 里用到的最主要的命令就是 compute-mfcc-feats 和 copy-feats,其在src 里编译好的。
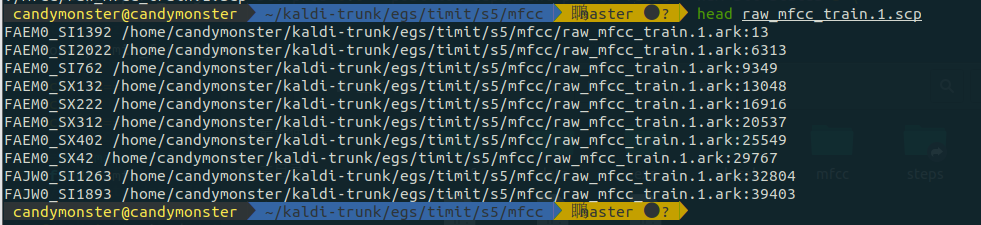
mfcc 目录里主要是 .ark 和 .scp 文件,其中 .scp 文件里的内容是语音段和特征对应,而真正的特征保存在 .ark 文件里。用 head 的命令可以看清楚:
scripts 和 archives 的底层是 Table 的概念。一个 Table 基本上是由唯一字符串(例如话语标识符)索引的项目(例如特征文件)的有序集合。.scp 格式是一个纯文本格式,每一行有一个 key,然后一个“扩展文件名”,告诉 Kaldi 在哪里可以找到数据。archive 格式可以是文本或二进制。格式是:key(例如 utterance id),然后一个空格,然后是对象数据。
除了 MFCC 特征以外,文件夹 mfcc 里还有 CMVN 特征。至于如何通过管道使用scripts 和 archives 两种格式的文件,可以参考下面的命令:
-78 行为单音素模型(monophone model)训练及解码部分:
单音素训练及解码是将之前生成的数据开始训练 GMM 模型,并进行相应的单音素解码,将解码之后的结果与标记的标签进行比较,从而得出该单音素的训练方法及 结合 GMM训练的准确(错误)率。具体的程序步骤如下:
第一步为将之前生成的 MFCC特征经过 delta-delta\CMVN等特征处理后成为 39维的特征量,为之后的模型训练提供更多的特征。delta 的目的是将原始的 MFCC 特征进行差分,由于MFCC 更多的是表征了语音信号的静态特性,故 delta 差分谱更注重于语音的动态特性。
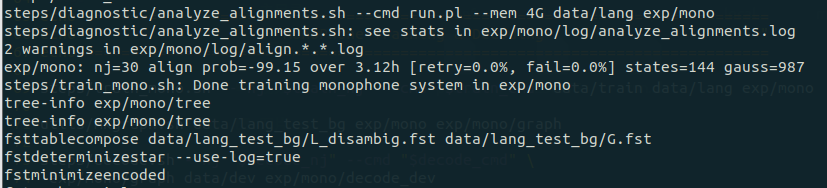
第二步为初始化单音素的 GMM模型,该命令首先在 exp/mono/目录生成 0.mdl 和 tree 文件,用于储存模型参数和模型结构。
第三步是编译训练图并进行迭代训练参数,在第二步的基础上进行迭代数据。
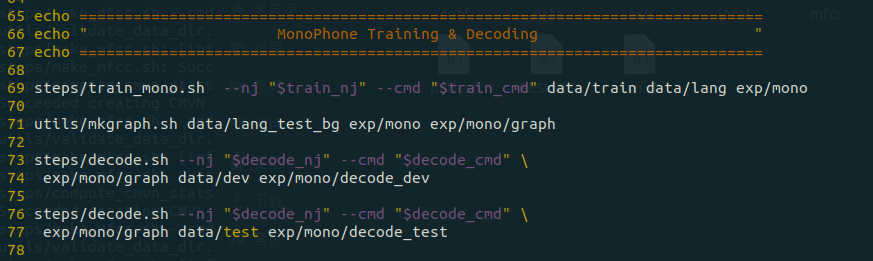
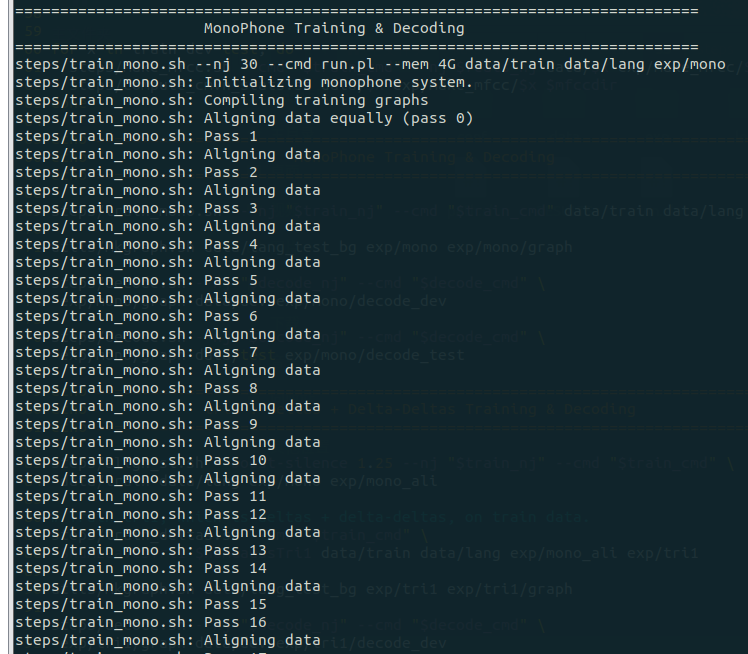
上图第 69 行执行了 steps目录下的 train_mono.sh,该脚本会执行单音素模型训练。训练过程的输出大致如下:
之后会在 exp 文件夹下产生一个 mono 的目录,里面以 .mdl 结尾的就保存了模型的参数。使用下面的命令可以查看模型的内容。
有关上下文的信息可以查看 tree 文件(部分):



查看训练数据 Veterbi 对齐,ali.*.gz 的每一行是对应于每一个训练文件的:
可以使用 show-transitions 命令来查看有关 transition-id 的信息:
第 71 行为构建解码图(HCLG),因为在解码之前需要先构建解码图。该命令通过输入之前得到的 tree等 model 文件来构建一系列的 fst 文件。此类 fst 文件包含表示语言模型、发音字典、上下文相关性和 HMM 结构。输出为 HCLG.fst 文件。构建解码图的过程部分如下图所示:
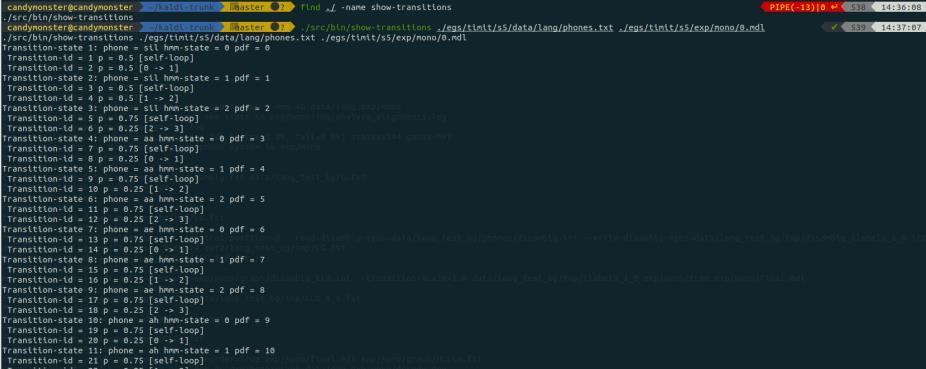


– 77 行为解码,分别针对开发集和测试集解码。解码的日志会保存在exp/mono/decode_dev/log 和 exp/mono/decode_test/log 里。解码部分的运行输出如下所示:
可以写一个如下内容的 bash 脚本文件来查看解码输出:
运行脚本文件查看解码输出:
该解码主要包含有两个主要的信息,第一个信息为该模型的检测结果中,词错率大约在31%;第二个信息为开发集的检测错误率比测试集的错误率要高一点。至此,单音素模型训练及解码过程完成。
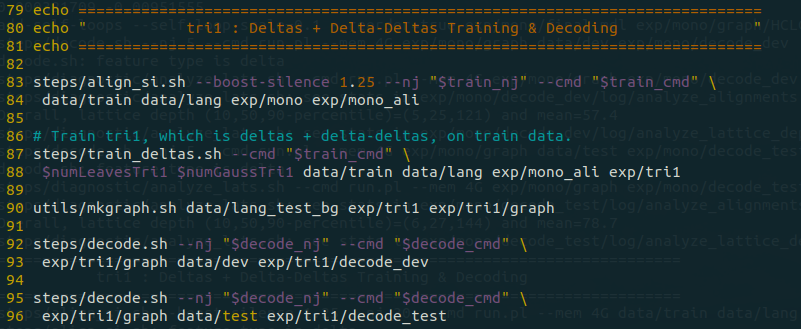
接下来的 79 - 96 行为 tri1 训练,三音素 deltas + delta-deltas 训练和解码:
流程与单音素训练流程类似,只是训练时采用的算法从单音素训练被替换成了三音素训练,之后是一样的构件图和解码过程。Delta + Delta-delta 算法计算特征的一阶和二阶导数,或者是动态参数以补充 MFCC 特征。训练(83 - 89)过程见下图:





构建图(90):
解码(92 - 96):
解码输出:
之后的 98 – 115 行进行 tri2,三音素训练及解码,训练算法用的是 LDA-MLLT(Linear Discriminant Analysis – Maximum Likelihood Linear Transform)。LDA 根据降维特征向量建立HMM 状态。MLLT 根据 LDA 降维后的特征空间获得每一个说话人的唯一变换。MLLT 实际上是说话人的归一化。依然是训练(102-107)、构建图(109)、解码(111 - 115):
训练过程输出如下图所示:
构建图(109):
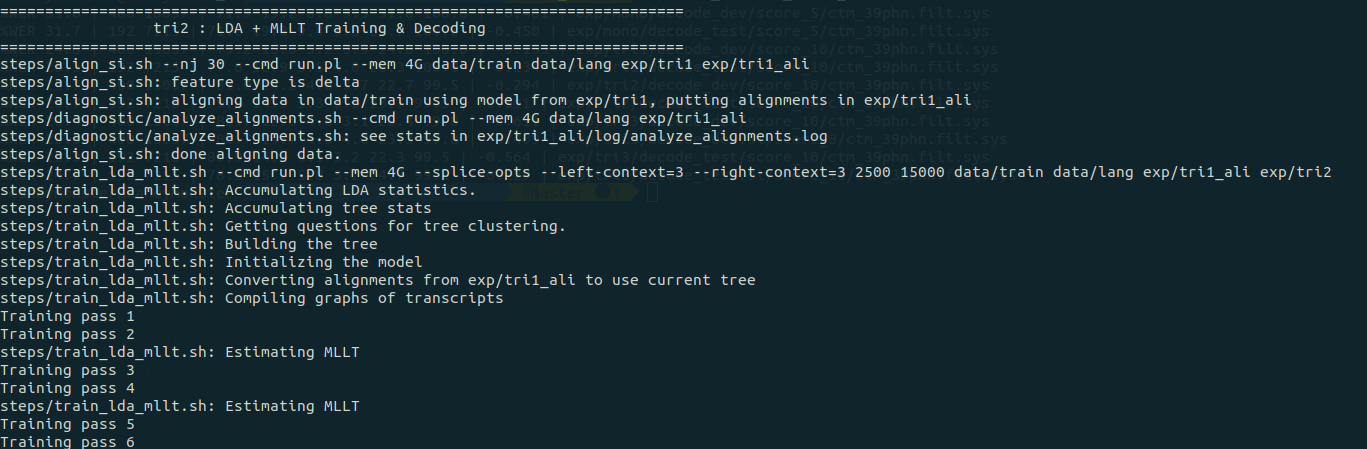




解码(111 – 115):
解码内容:
之后的 117 – 136 行进行 tri3 的训练,这部分仍是三音素训练,训练算法采用的是 LDA +MLLT + SAT,其中 LDA + MLLT 和 tri2 的一样,SAT 指的是 Speaker Adaptive Training,它同样对说话人和噪声进行归一化处理。
这部分内容依然是训练(122 – 127)、构建图(129)、解码(131 – 135),训练过程的输出依次如下图所示:
训练(122 – 127):
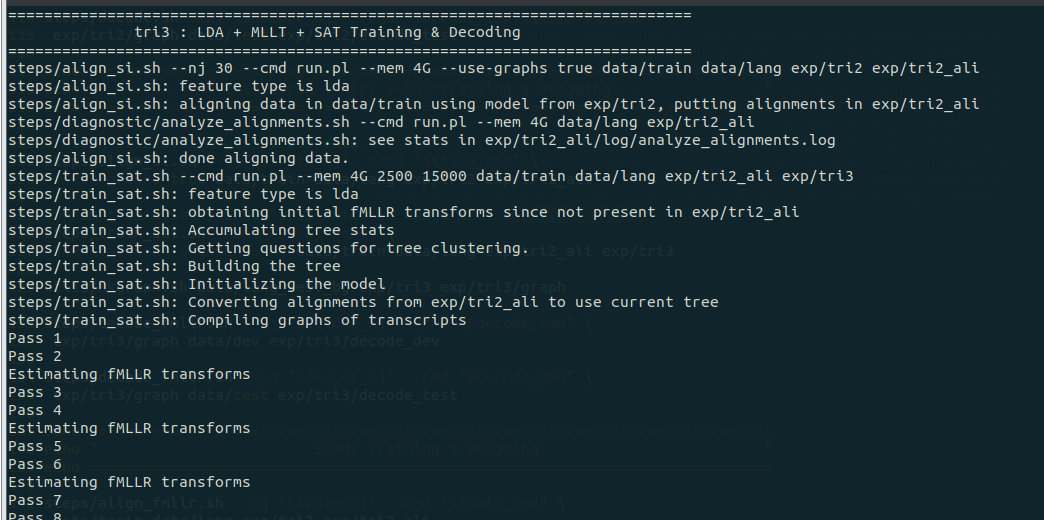


构建图(129):
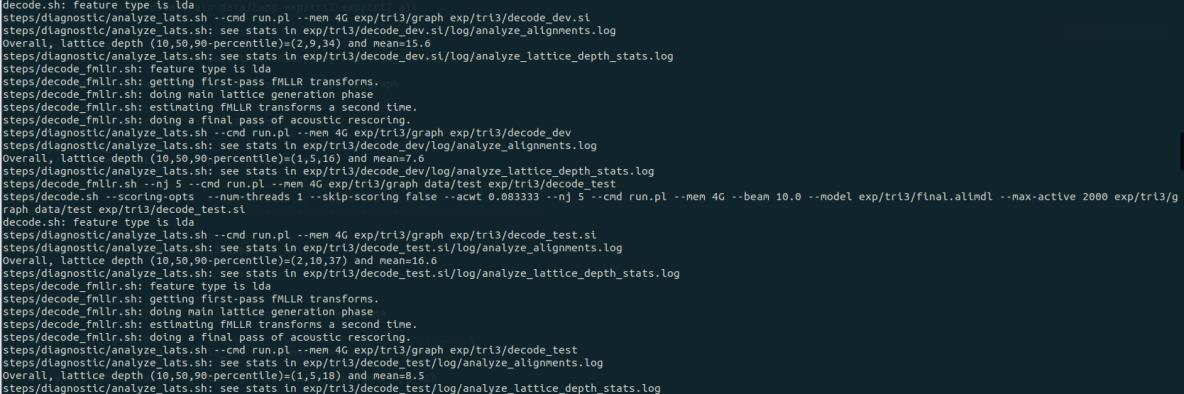
解码(131 – 135):
解码输出:
run.sh 运行到这里就退出了,因为 144 行有一句命令 exit 0 使其退出了。要想继续训练则需去掉这句话再运行。由于只分配给虚拟机 3G 的内存,虚拟机的资源跟不上了,之后的训练会变得非常非常慢。
之后的部分是 SGMM2 训练 ,SGMM2 首先训练了 UBM(通用背景模型),并在此基础上训练 SGMM(子空间高斯混合模型),其代码如下图所示,其中第 146 – 147 行训练 UBM,149 – 150 行训练 SGMM,152 行构建图,154 – 160 解码:
UBM 训练(146 - 147):
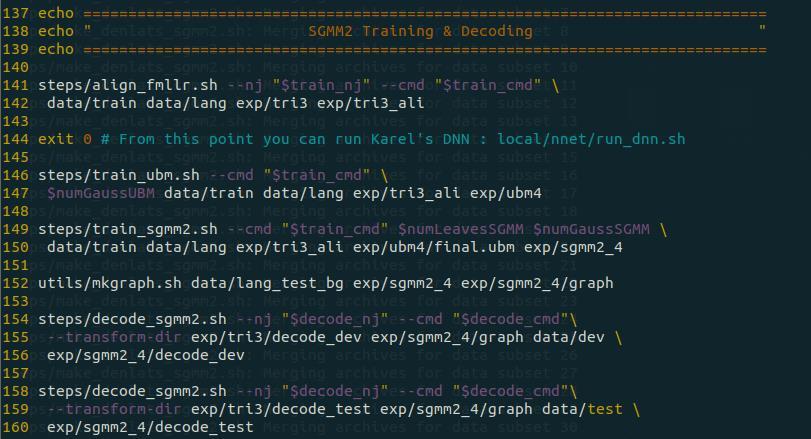



SGMM 训练(149 – 150):
构建图(152):
解码(154 – 160):
解码结果:





接下来的 162 – 188 行为 MMI + SGMM2 训练:
MMI,Maximum Mutual Information,最大互信息,是分类算法常用的区分性准则,在Interspeech 2013 的论文 Sequence-discriminative training of deep neural networks 中,被引入做语音识别深度模型训练。在 Interspeech 2016的论文Purely sequence-trained neural networks for ASR based on lattice-free MMI 中,发展为不使用 Lattice 的 MMI声学模型损失函数。在 2018 年的多篇论文中,又应用在半监督的声学模型训练中。MMI 的推导在此不再叙述。其他同上。该部分代码运行过程如下所述:
MMI计算(175 – 177 行):
SGMM 训练及解码:
解码结果(测试集和开发集分别进行了 4 轮训练,对应 tri1 – tri4):


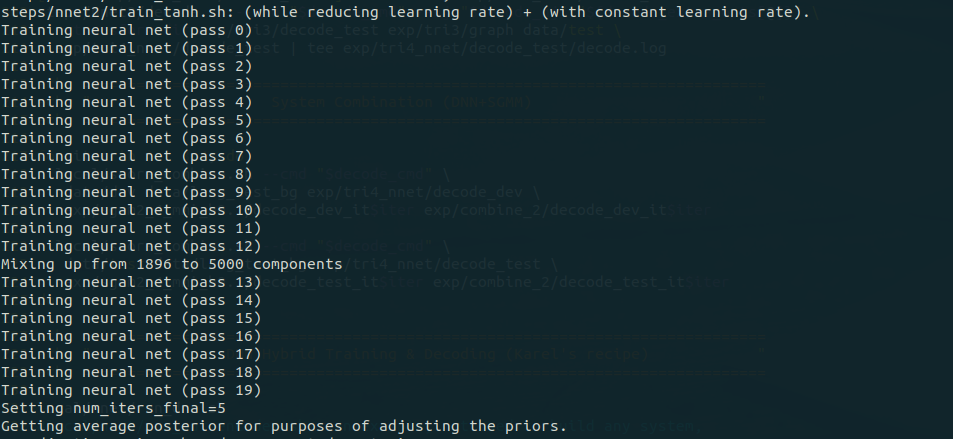


随后的 189 – 212 行为 DNN 训练:
DNN 指的是深度神经网络(deep neural network),其训练使用的 CE 准则是基于每一帧进行分类的优化,最小化帧错误率。DNN 的输入一般采用传统频谱特征及其改进特征 (如MFCC、PLP、Filterbank 等) 经过帧拼接得到,拼接长度一般选择 9-15 帧之间,时间上约 10ms左右。而输出则一般采用各种粒度的音素声学单元,常见的有单音子音素 (Monophone)、单音子音素的状态以及三音子音素 (Triphone) 绑定状态等。输出层的标注一般采用 GMM-HMM基线系统经强对齐(Forced-alignment)得到。
由于没有采用 GPU 训练,所以训练会异常耗时。部分输出信息如下:
解码结果:
再之后的 213 – 225 行为 DNN + SGMM2 模型训练及解码,
解码结果如下图所示,测试集和开发集分别进行了 4 轮训练,对应 tri1 – tri4:


最后剩下的 227 – 245 行是 DNN 的 Karel's nnet 版本,然后是对开发集和测试集做整体测
但是实际上程序运行到这里就退出了,并没有执行下去。退出时的输出信息如下图所示:
它说没有装 GPU 模块所以不能做,想做的话需要执行对应的指令。考虑到虚拟机中没有分配 cuda,同时实验也没做要求,所以就不做了。
总结一下,run.sh 脚本作为该程序处理的总脉络,处理流程主要包括有:
- 语音模型参数设定
- 数据准备及预分类
- MFCC 特征提取
- 单音素训练及解码
- 音素 Deltas 训练及解码
- LDA + MLLT 训练及解码
- LDA + MLLT + SAT 训练及解码
- SGMM2 训练及解码
- MMI + SGMM2 训练及解码
- DNN Hybrid 的训练及解码
- DNN + SGMM 的训练及解码
- 结果的输出
实验结果总结
(对实验结果进行分析,完成思考题目,总结实验的新的体会,并提出实验的改进意见)
librosa 是一个非常强大的 python 语音信号处理的第三方库,学会 librosa 后再也不用用python 去实现那些复杂的算法了,只需要一句语句就能轻松实现。虽然如此,还是应该看看相关的文章,理解算法背后的原理。做 MFCC 提取时主要遇到的问题是 librosa 库安装时出现的问题,仅仅使用 pip install librosa 是没办法让程序正常运行的,因为 librosa 实际上还依赖了scipy、audioread、resampy、soundfile 等包,所以在运行前要检查完备再开始动手。
Kaldi 遇到的问题主要是部署的时候出现的,如果能够正常部署,后续应该不会出什么大问题。遇到问题要善于搜索,很多问题都是前人已经踩过的坑。TIMIT 可用的脚本函数库、数据语料语音的组织都有清晰的文件结构,函数脚本调用逻辑清晰,方便学习使用者学习和检索调用;其包含有函数处理流程结果的日志,便于查阅和分析。
虽然实验没有对算法理解做出要求,但多看看相关的博客以及文档、了解一下算法原理还是很有必要的。
参考文献
- 基于机器学习优化用户音乐喜好个性化推荐的研究(广东工业大学·黄梓炜)
- 基于精彩评论的混合音乐推荐系统研究(云南财经大学·梁一敏)
- 基于深度学习的复杂环境声音识别研究(重庆交通大学·夏蒸富)
- 基于切割合并技术的音视频综合管理系统的研究(电子科技大学·张元利)
- 基于PHP的在线音乐网站的设计与实现(武汉理工大学·陈君)
- 音频广播搜索推荐系统的设计与实现(北京交通大学·刘艳平)
- CLARANS改进算法在音乐网站智能推荐系统中的应用(吉林大学·魏佳)
- 基于B/S架构的语料库管理系统(哈尔滨理工大学·于娜娜)
- 在线音乐管理系统设计与实现(华中科技大学·白爱)
- 个性化音乐推荐系统的设计与实现(华中科技大学·余梦琴)
- 音频广播搜索推荐系统的设计与实现(北京交通大学·刘艳平)
- 利用深度学习构建基于内容的音乐推荐系统(厦门大学·林雨辉)
- 基于用户行为的音乐推荐系统设计与实现(华中科技大学·郝陆风)
- 基于B/S架构的语料库管理系统(哈尔滨理工大学·于娜娜)
- 基于切割合并技术的音视频综合管理系统的研究(电子科技大学·张元利)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设货栈 ,原文地址:https://m.bishedaima.com/yuanma/36169.html









