Python 数据处理爬虫程序设计
一、摘要
随着计算机技术的不断发展,新的编程语言层出不穷,Python正是其中的佼佼者。相比较早期普及的高级语言(Java,C语言)等,Python有着更加实用的模块和库,虽然牺牲了底层性,但却更加方便用于开发小型项目。基于 python 的网络爬虫技术,相比于通用的搜索引擎更具有目的性和灵活性,它能根据选定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。本文以人民日报新闻爬取和爬取后的保存及查询为研究,实现了一个基于 python 的人民日报新闻文章爬取程序。本论文还阐述了一些网络爬虫实现的常见问题,包括常用的python的网络请求、如何解决网页的反爬问题、数据保存写入问题等。
本程序最终可以实现对人民日报(http://paper.people.com.cn/)新闻文章的下载。可以输入要爬取的日期以及结束日期,将这些日期内的文章全部爬取下来,以日期为名自动生成一个主存储目录,爬取到的文章保存写入 txt 文件中,每个文本的存储名字以日期加序号存储。
关键词:网络爬虫;Python;;网络请求;人民日报新闻。
二、绪论
随着科学技术的不断发展,信息流通日益方便,信息数据不断膨胀,充斥在各行各业。由于数据非常庞大,所以即使在搜索引擎存在的情况下,搜索结果的准确率也不高,这使得在网上查找关键有效信息也变为一项极具挑战性的复杂任务。我们可以通过基于python的网络爬虫技术很好的解决检索问题,首先我们通常使用的通用搜索引擎的目标是尽可能将网络覆盖率增大,其次在数据形式复杂的情况下,对于具有一定结构且信息含量密集的数据,往往不能被很好的搜索出来。而网络爬虫则更具有目的性,能根据选定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
将爬虫技术应用于文章的爬取并筛选有效信息,可以节省科研人员时间,提高资源利用率,将有限的时间发挥更大的价值。
相关技术介绍
网络爬虫技术
网络爬虫技术概述
网络爬虫技术是近些年来成熟并流行起来的一项技术。现阶段研究通常集中在各种不同领域下的运用。其通俗的来说就是通过模拟客户端(各种浏览器)发送网络请求,以获取服务端的响应,并按照规则提取指定数据的程序。
python 的网络请求
python中常用的HTTP网络请求通常有3种方式:urllib、urllib3以及本论文使用的 requests。下面将介绍requests模块的使用。
requests模块是python的第三方模块,该模块在实现HTTP请求时要比其他2种方式简单,在使用前需要先在cmd命令行里执行pip install requests。
requests模块中使用最多的就是GET和POST请求方式,2者的主要区别在于GET请求没有请求体,它把数据放在url地址中,而POST有请求体,常用于登录注册,且它携带的数据量比GET请求方式大,所以常用于传输大文本。
本文中使用的是GET请求方式,它的请求方式为:
c++
response=requests.get(url,params=params,headers=headers)
url为基准的url地址,不包含查询参数。
该方法会自动对params字典编码,然后和url拼接。
如何解决网页的反爬问题
通常我们在请求一个网页时,无论是通过哪种请求,发现如果不带headers参数一般会出现403错误,这种错误的原因是通常网页为了防止恶意的采集数据信息会设置一些反爬措施,从而拒绝爬虫程序的访问。因而通过携带headers参数,可以达到模仿浏览器的头部信息进行访问。具体反爬策略:第一遍,先爬取版面目录,将每一个版面的链接保存下来;第二遍,依次访问每一个版面的链接,将该版面的文章链接保存下来;第三遍,依次访问每一个文章链接,将文章的标题和正文保存到本地。
3设计目的与要求
三、程序设计的目的与要求
实现对人民日报(http://paper.people.com.cn/)新闻文章的下载。可以输入要爬取的日期以及结束日期,将这些日期内的文章全部爬取下来,以日期为名自动生成一个主存储目录,爬取到的文章保存写入txt文件中,每个文本的存储名字以日期加序号存储。
本程序需要在python下,并且需要下载程序依赖的包才能运行。本程序需要用到的包主要有:requests、bs4、os、datetime。
总体设计
程序目录结构设计
程序项目结构非常简单,一个主程序(paweb.py),还有是根据日期分类的资源总目录,总目录下自动根据日期生成存储文章的目录,再下面是是具体文章的txt文本,每个txt存储一篇文章。
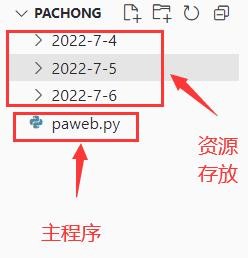
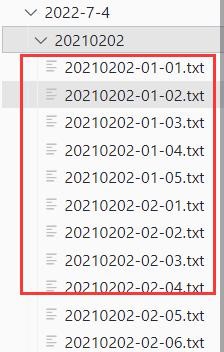
图4.1程序结构
程序总体结构设计
该爬虫程序没有用户界面,基于python环境,运行在Windows PowerShell窗口中,使用流程为:输入需要爬取的开始日期,结束日期、回车后等待爬取即可,爬取完成后会有提示。工作流程为:根据输入的日期拼接URL,获取当天报纸的各版面的链接列表,再获取报纸版面的文章链接列表,然后解析 HTML 网页,获取新闻的文章内容,获取到文章标题和正文信息后写入到对用的文件中,最后程序结束运行并提示已经爬取完成。
5详细设计
分析目标网站
URL 组成结构
人民日报网站的URL的结构比较直观,基本上什么重要的参数,比如日期,版面号,文章编号什么的,都在 URL 中有所体现,构成的规则也很简单,像这样:
版面目录:
文章内容:
在版面目录的链接中,“/2022-07/06/”表示日期,后面的 “_01” 表示这是第一版面的链接。在文章内容的链接中,“/2022-07/06/”表示日期,后面的 “_20220706_5_01”表示这是2019年5月6日报纸的第1版第5篇文章,需要注意的是,在日期的“月”和“日” 以及 “版面号”的数字,若小于 10,需在前面补“0”,而文章的篇号则不必。
了解到这个之后,我们可以按照这个规则,构造出任意一天报纸中人一个版面的链接,以及任意一篇文章的链接。
如:2022年7月3日第4版的目录链接为:
分析网页 HTML 结构
在URL分析中,通过实验发现了网站的页面跳转是通过URL的改变完成的,不涉及到Ajax 这样的动态加载方法。它的所有数据是一开始就加载好的,我们只需要去 html 中提取相应得数据即可。
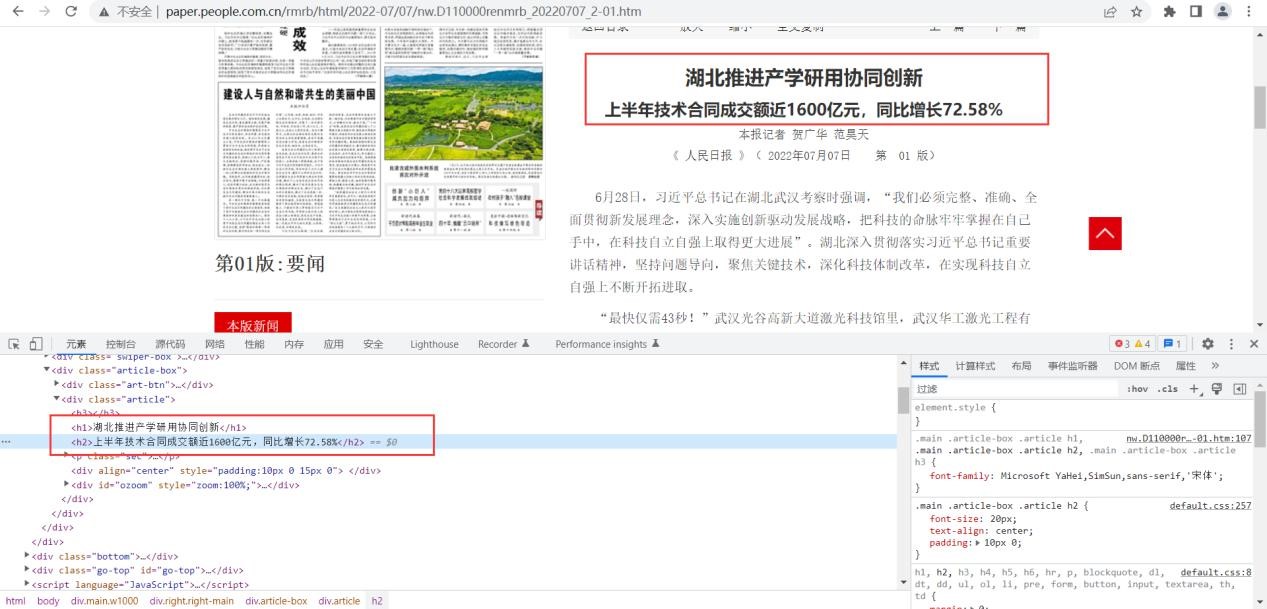
图5.1标题示例
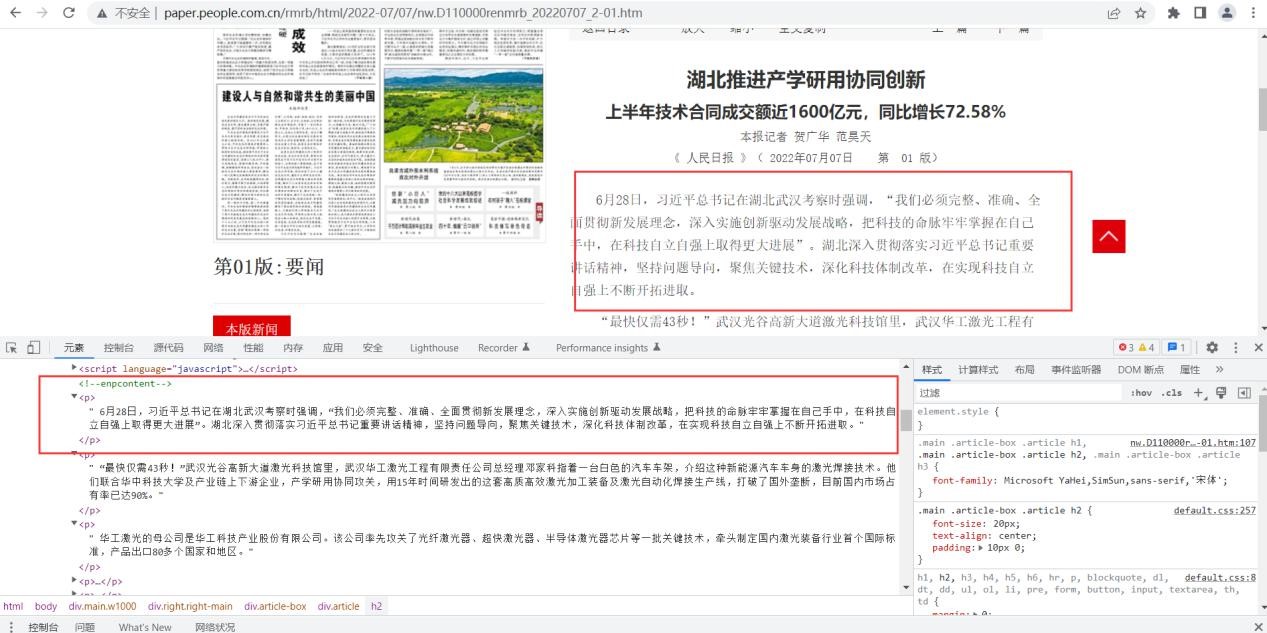
图5.2新闻正文示例

图5.3文章具体存放位置
由上图分析后发现,进入文章内容页面之后,文章标题存放在h1,h2,h3标签中(有的文章标题只用到了h1标签,而有的文章有副标题可能会用到h2或h3标签),正文部分存放在id= “ozoom”的div 标签下的p标签里。至此,目标网站的 HTML 页面分析完成。具体爬虫程序分析流程图如下:
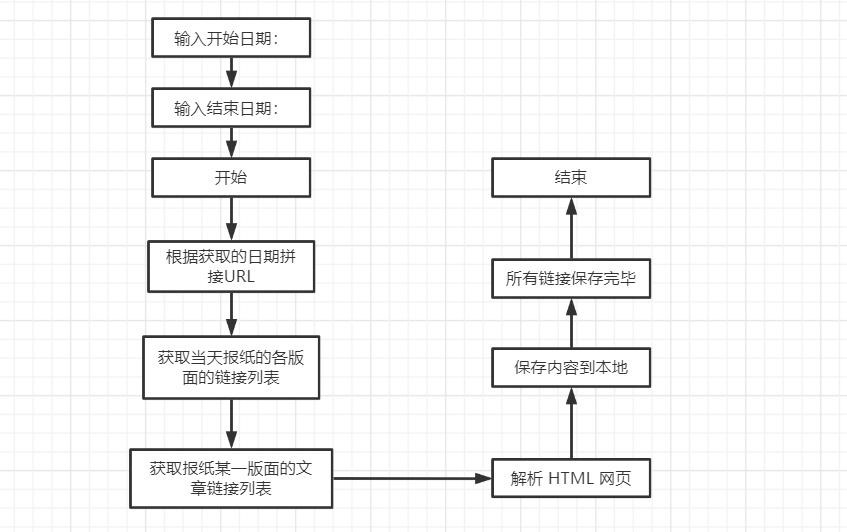
图5.4 爬虫程序分析流程图
6数据结构设计描述,各模块(函数)的功能介绍
数据结构设计描述
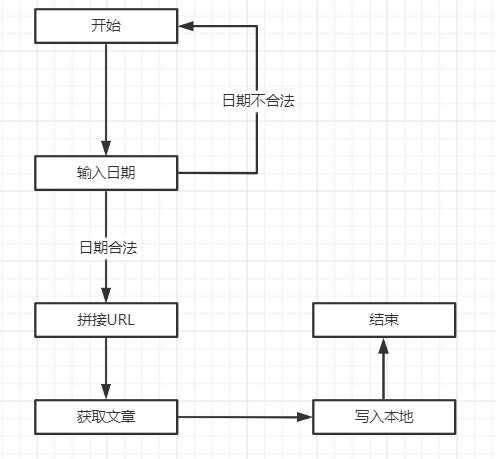
程序由输入的开始时间和结束时间来获取要爬取的新闻,由于时间拼接URL,获取到文章列表后解析HTML,然后获取到需要的文章标题、文章正文等信息后写入本地。流图如下:
图 6.1 数据结构流图
主要函数的功能介绍
c++
def fetchUrl(url):
headers = {
'accept':
'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q= 0.8',
'user-agent':'Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding return r.text
功能:访问 url 的网页,获取网页内容并返回参数:目标网页的 url
返回:目标网页的 html 内容
python
def getPageList(year, month, day):
功能:获取当天报纸的各版面的链接列表参数:年,月,日,改变年月日拼接成需要爬取的url 返回当天报纸的各版面的链接列表
python
def getTitleList(year, month, day, pageUrl):
功能:获取报纸某一版面的文章链接列表参数:年,月,日,该版面的链接返回文章链接列表
python
def getContent(html):
功能:解析 HTML 网页,获取新闻的文章内容
参数:html 网页内容返回结果 标题+内容
python
def saveFile(content, path, filename):
功能:将文章内容 content 保存到本地文件中参数:要保存的内容,路径,文件名如果没有该文件夹,则自动生成
python
def download_rmrb(year, month, day, destdir):
功能:爬取《人民日报》网站的新闻内容,并保存在指定目录下参数:年,月,日,文件保存的根目录然后保存文件到本地
python
def get_date_list(beginDate, endDate):
获取日期列表
param start: 开始日期 param end: 结束日期
```c++ if name == ' main ':
输入起止日期,爬取之间的新闻
print('---文章爬取系统---') beginDate = input('请输入开始日期(格式如20220706):') endDate = input('请输入结束日期(格式如20220706):') data = get_date_list(beginDate, endDate) for d in data: year = str(d.year) ```
```python month = str(d.month) if d.month >=10 else '0' + str(d.month) day = str(d.day) if d.day >=10 else '0' + str(d.day)
爬取后文章统一存到这个文件夹下,没有会自动创建
destdir = "./2022-7-6" ```
c++
download_rmrb(year, month, day, destdir) print('---文章爬取系统---') print("爬取文章完成!")
print('爬取文章时间为:' + year + '/' + month + '/' + day + '的文章已成功写入文
件!')
print('---文章爬取系统---')
主函数:程序入口
7结果分析
运行结果及分析
开始运行程序,输入爬取文章的开始日期,如图:
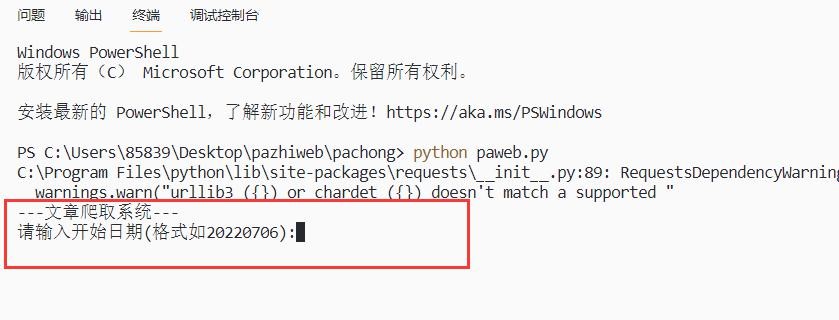
图 7.1 输入开始日期
输入爬取文章的结束日期如图

图 7.2 输入结束日期
回车后开始运行程序,如图:
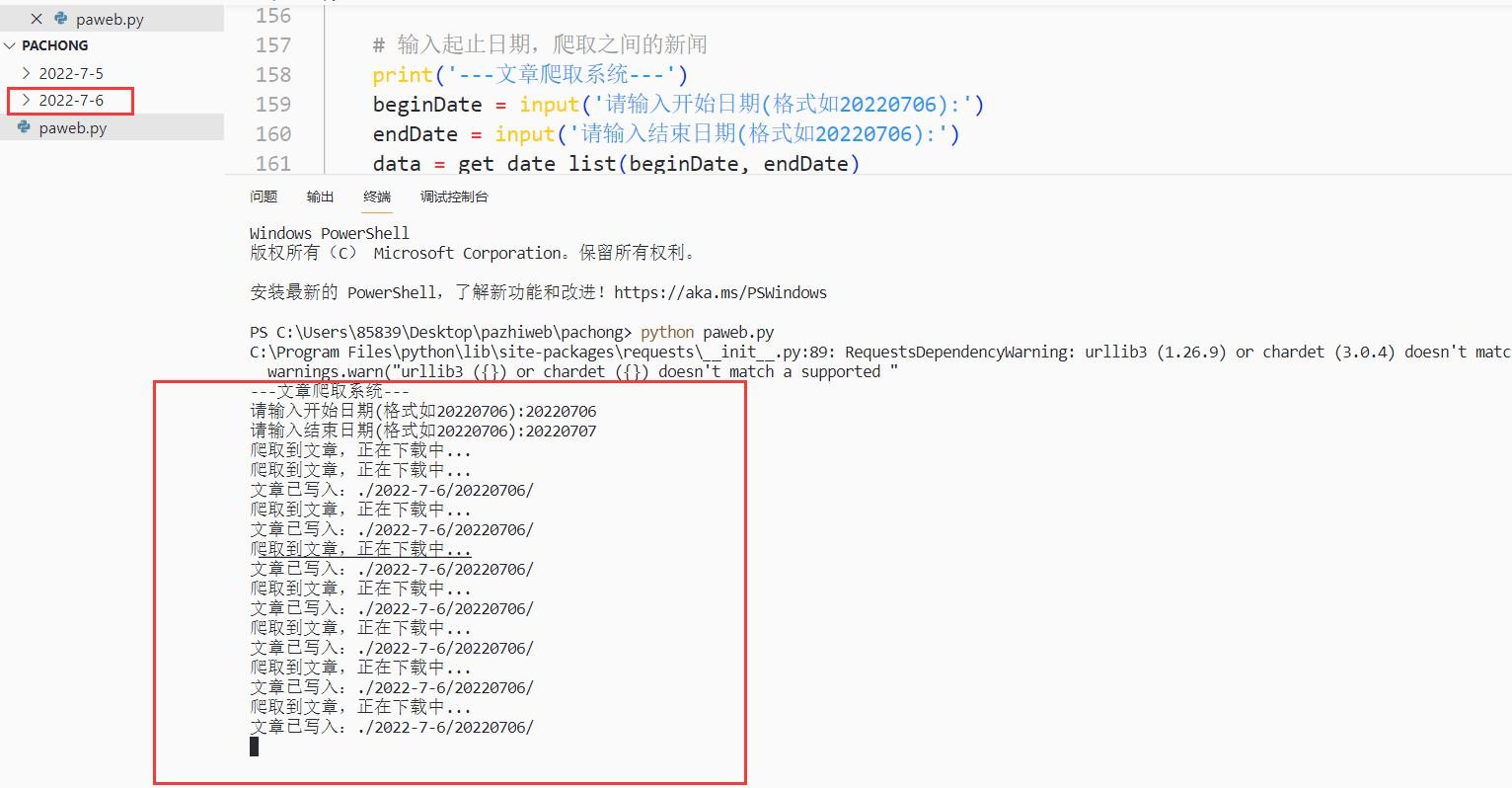
图 7.3 运行图
爬取文章完成后,写入本地,然后会自动结束程序:

图 7.4 运行结束图
爬取完成后成功写入本地中,每个文章一个 txt:

图 7.5 本地 txt
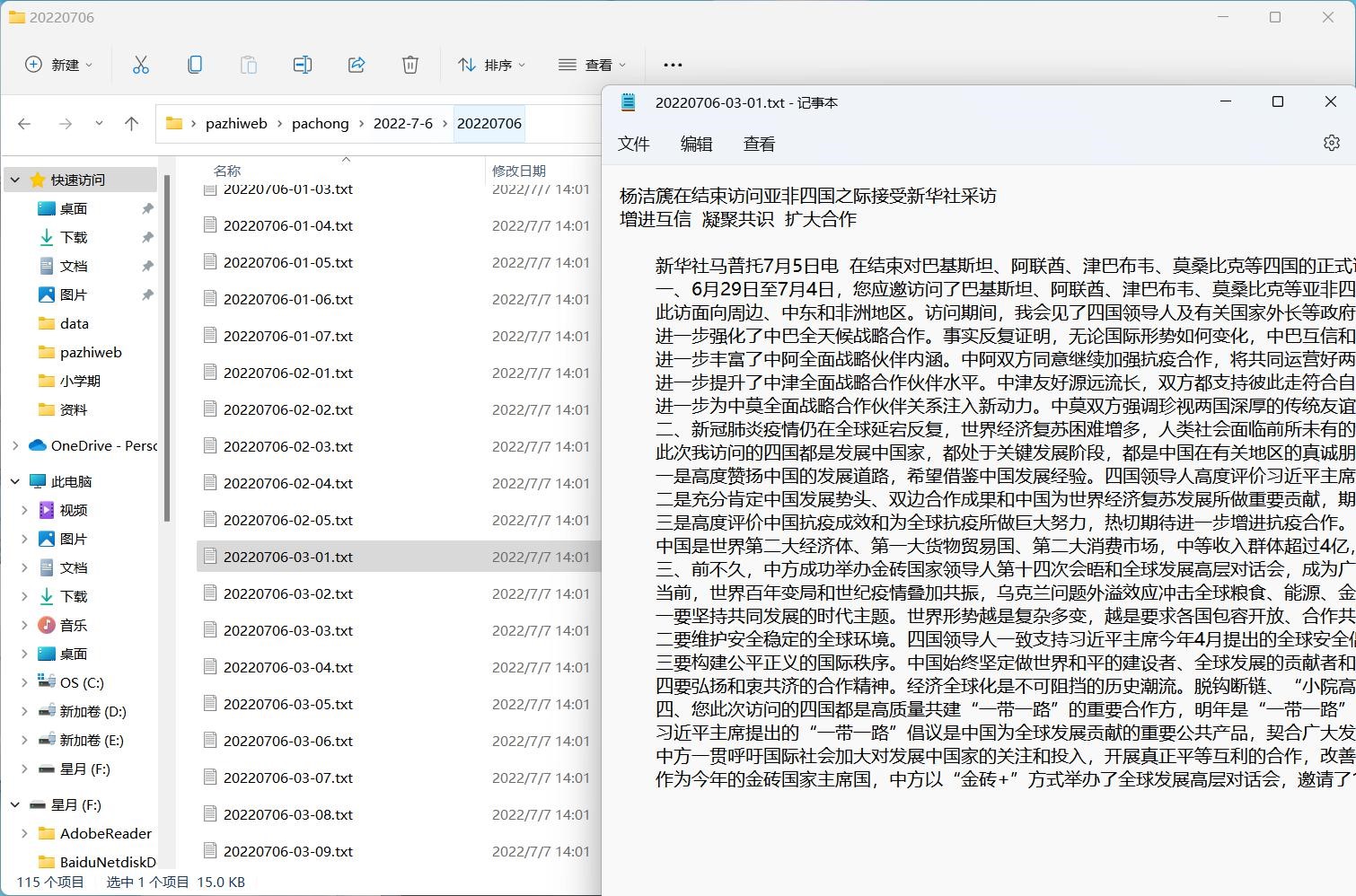
图 7.6 本地 txt 查看
四、总结
从开始这次小学期课程设计到完成这次课程设计一共经历了一周时间。在这一周时间里,一边写程序一边学习,晚上基本都学到半夜,但是当程序功能一点一点距离自己的预期时,就会觉得所有的付出都值了,学到了很多东西,我从对网络爬虫技术一无所知,到能成功的编写出简单的网络爬虫程序,并对网络爬虫中的一些基本技术有了一定的理解。
这次小学期课程设计我完成的是一个基于python的爬虫程序,能根据输入的日期来爬取对于日期的《人民日报》的新闻文章,并存到本地,每个文章一个txt,文件名以日期加序号来命名,文章爬下来结构清晰。
在编写程序过程中,因为之前学过一点python基础,但是对于爬虫没有接触,遇到了很多问题,比如怎么爬、爬取后怎么解析、怎么存储数据等。通过百度、csdn、b站、问同学等,一边学习一边编写,经过4天时间终于简单完成了爬取人民日报的文章并存储功能。这些问题的解决都让我受益匪浅。
本次程序的局限性在于没有可视化的操作以及没有用户操作界面,还没有打包让用户能使用,对于这方面的知识还有待学习,本次爬虫选取《人民日报》的一个原因是因为这个网站数据返回是直接到HTML页面中,容易解析和获取数据,其他稍微困难的还有点学习,以后往这方面学习研究。最后是在数据存储端方面,我只将数据进行了轻量提取后存了txt的文本文件中,并未将数据存入数据库。在数据的处理中,也没有涉及到一些没有用文章的去除以及多次存储后的去重工作等。
五、参考文献
csdn(,《python爬虫的基本原理》
c++
Csdn(何极光)https://blog.csdn.net/qq_44034384/article/details/107854112
Csdn:https://www.liaoxuefeng.com/wiki/1016959663602400/1017648783851616
崔庆才,《python3网络爬虫开发实战》
卢杨,《python从入门到精通》
哔哩哔哩,《黑马程序员爬虫视频》
参考文献
- 搜索引擎中网络爬虫技术研究(西安电子科技大学·郭海燕)
- 分布式网络爬虫在农产品搜索系统中的应用与研究(南昌大学·袁龙涛)
- 搜索引擎中通用爬虫系统的研究与设计(吉林大学·高龙)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 面向应用商店的主题爬虫设计与实现(东南大学·韩进宾)
- 面向主题的爬行搜索策略研究与实现(陕西师范大学·王敏翔)
- 主题爬虫的设计与实现(北京邮电大学·彭小明)
- 基于WEB的爬虫系统的设计与实现(西安电子科技大学·卢哲辉)
- 基于微服务架构的通用爬虫系统的设计与实现(北京交通大学·杨红光)
- 面向多爬虫的监控系统的设计与实现(北京邮电大学·张军强)
- 分布式网络爬虫在农产品搜索系统中的应用与研究(南昌大学·袁龙涛)
- 分布式在线旅游搜索爬虫系统设计与实现(北京邮电大学·徐显炼)
- 基于微服务架构的通用爬虫系统的设计与实现(北京交通大学·杨红光)
- 面向应用商店的主题爬虫设计与实现(东南大学·韩进宾)
- 网络爬虫技术在云平台上的研究与实现(电子科技大学·刘小云)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码码头网 ,原文地址:https://m.bishedaima.com/yuanma/36190.html