
影视爬虫与检索系统设计文档
一、功能介绍展示
影视列表页
为系统主页,通过分页方式列出系统中的所有影视,并显示影视的总数量(1002 部)。列表页中的每个条目展示电影名称和海报,点击列表页中的条目可以跳转到对应的影视信息页。页面底部有脚注。顶层有导航栏可跳转搜索等页面。

演员列表页
通过分页方式列出系统中的所有演员,并显示演员的总数量(4092 位)。列表页中的每个条目展示演员名字和照片,点击列表页中的条目可以跳转到对应的演员信息页。页面底部有脚注,顶层有导航栏。

影视信息页
展示电影名称、海报、简介、导演、编剧、类型和五条短评。
展示参演演员列表,以条目形式展示,显示演员姓名和照片,点击姓名或照片可跳转至演员信息页。页面底部有脚注,顶层有导航栏。

演员信息页
显示演员姓名、简介、照片、性别等信息。列出该演员参演影视,以条目形式展示,显示影视名称和图片,点击名称或图片可跳转至影视信息页。列出该演员合作演员次数最多的十位,以条目形式展示,显示演员名、图片和合作作品数量,点击演员姓名或图片可跳转至其信息页。页面顶层有导航栏。

搜索
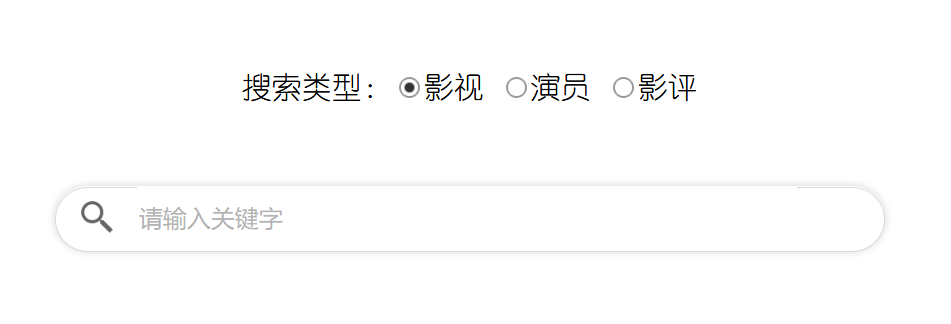
搜索是一个单独的页面。搜索栏搜索功能包括一个搜索栏、一个单选组(影视、演员、影评),回车即可搜索。输入一个关键词或一段文本(20 字以内),根据单选组选项,搜索系统中存在的影视、演员和影评,搜索后跳转到搜索结果页。页面底部有脚注,顶层有导航栏。

搜索结果页
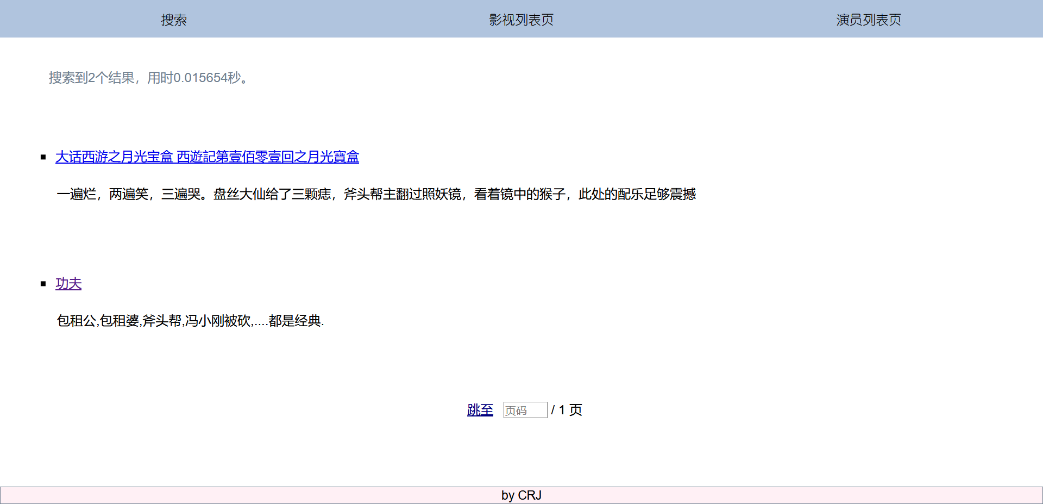
搜索结果页包含所有的搜索结果列表,以分页形式展示。搜索结果页中的每个条目设计为超链接格式,点击可跳转到相应信息页。点击影评的搜索结果跳转到该影评所在的影视信息页。页面底部有脚注,顶层有导航栏。
搜索结果页最上方显示搜索条目数量和搜索花费的时间。
二、性能统计信息
爬虫数据量统计
共爬取豆瓣华语电影 500 部,日韩电影 502 部,总计 1002 部。
电影信息包括名称、演员、简介、图片、五条短影评和导演、编剧、类型。
共爬取电影相关演员 4092 位。
演员信息包括姓名、简介、个人照片和性别。


查询时间统计
影评搜索:以搜索“陈凯歌”为例,搜索到 14 个结果(包括霸王别姬等电影),用时 0.015654 秒。

- 影视搜索:以搜索“霸王”为例,搜索到 2 个结果(包括霸王别姬等电影),用时 0.568432 秒。

- 演员搜索:以搜索“张”为例,搜索到 114 个结果(包括张国荣等演员),用时 0.593827 秒。

三、各个功能涉及的技术和实现方式
爬虫
利用 requests 库获取网页内容,利用浏览器信息伪装头部,同时每爬一次间隔 2-5 秒。尽管如此,还是被 ban 了 n 个 ip。最后在开飞行换 ip/开代理/开热点/借用舍友电脑等操作下,爬完了 1002 部电影信息。
利用 lxml 库中的 etree 解析 HTML 内容。通过 xpath 定位,获得想要的信息。将每部电影信息存入一个 dict,通过 pickle 库存入 pkl 文件。
django
建立 app。在 model 中建立“Actor”“Movie”和代表电影、演员关系的类“Membership”。将 pkl 中存储的数据导入 sqlite3 数据库,存在这 3 个 model 中建立表格,方便索引查询。通过查找每个演员参演的电影,再查找该电影的参演演员,计算合作次数。最后将这些信息以变量形式传入 HTML 进行展示。
html
如何在 HTML 中使用变量和传回单选框及关键字是两个难题。HTML 不支持[]调用变量,所以要使用数字索引需要 movie.0 的格式。通过 request.GET.get('keyword')等函数获得用户输入的关键字和单选选项,传回后端进行操作。
css
为了让页面看起来美观,通过 CSS 的盒模型等进行美化。
其中最满意的外观效果是搜索栏。
参考文献
- 音视频数据获取与同源性分析关键技术研究(电子科技大学·范清宇)
- 视频处理平台的设计与实现(北京交通大学·时月月)
- 基于分布式爬虫的用户评论分析系统(南京邮电大学·罗骁)
- 高职院校教学资源库的设计与实现(湖北工业大学·蒋莉)
- 面向视频网站的自感知通用爬虫系统的设计与实现(北京邮电大学·黄国锴)
- 基于网络爬虫的电影集成搜索系统设计与实现(江西农业大学·江沛)
- 基于领域的网络爬虫技术的研究与实现(武汉理工大学·谭龙远)
- Web对象提取检索系统的设计与实现(北京大学·刘冠军)
- 具有反爬虫机制的影评系统的设计与实现(北京交通大学·高萍)
- 音视频数据获取与同源性分析关键技术研究(电子科技大学·范清宇)
- 具有反爬虫机制的影评系统的设计与实现(北京交通大学·高萍)
- 恶意URL检测项目中基于PageRank算法的网络爬虫的设计和实现(北京邮电大学·王晓梅)
- 复合规则驱动聚焦爬虫系统的设计与实现(哈尔滨工业大学·刘强)
- 基于数据挖掘的电视节目个性化推荐研究及实现(曲阜师范大学·徐晟杰)
- 基于领域的网络爬虫技术的研究与实现(武汉理工大学·谭龙远)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码港湾 ,原文地址:https://m.bishedaima.com/yuanma/35753.html









