
实现一个简单的分层实验系统
前言
所谓一次实验(这里都是指网络实验),即是在一次请求中,应用若干参数,产生某种结果的过程。
而一组实验,即是在若干次请求(流量),进行若干次实验。
而一组对照实验,一般包括一个对照组实验(或控制组 control)和若干处理组实验(treatment)。
所以,常见的实验,包括这样一些要素:
- 流量,其实就是样本
- 参数,通常是策略优化的对象
- 结果,映射到用户的行为,我们需分析的日志
当创建一个实验,我们一般会考虑这些问题:
- 起止时间,实验应该开启多长时间,某些实验是否有周期性,这是个权衡
- 流量大小,这个和我们关注的指标敏感度以及置信区间有关,这也是个权衡
- 分配方式(diversion),就是采样方式,按 uuid、userid 还是随机分配
- 分配条件(condition),只采用一部分流量,可能按地域、按浏览器类型
- 流量偏置,会和哪些模块有耦合关系,应该如何分配参数
针对这些问题,分散的实验常常会踩到一些坑:
- 流量饥渴,这是最容易碰到的。因为我们是在用样本估计,那么显然样本越多越好,我们做 ab test,各取 50% 流量是理想情况。
- 条件偏置,已经经过一部分条件过滤的流量不应该再分配其他实验,因为这部分样本是有偏的。
- 参数耦合导致结果有偏。比如,实验 A 和实验 B 流量重叠,如果 A 的参数会影响到 B,那么就会导致 B 的结果有偏。
如果我们各自为战的做对照实验,虽然在共用同一份流量,但互相其实并不清楚各自的影响,那实验结果可想而知。所以,这是分层实验系统要解决的问题。
设计
这里的分层实验系统和上面罗列的概念,主参考了 Google 的 Overlapping Experiment Infrastructure, kdd2010 这篇论文,但是做了一些简化,主要是在层和域的嵌套上,这里的设计是域可以嵌套层,但层不能嵌套域。
说明一下论文里关于系统的基本概念:
- 域(domain) 即流量的划分,一部分流量
- 层(layer)即参数的集合,不能耦合的参数会在同一层,可以耦合的参数在不同层,所以一般实验中是按业务模块来划分层比较合理
- 实验(experiment)见上文
在具体实现里数据结构上新增的概念:
- 块(bucket)为了简化流量划分,把整个网站流量划分了若干块,比如 1000 块
一个完整实验系统分成如下几部分:
- 实验分配系统:Python 实现的后台服务,实时获取数据库里的配置信息,构建实验空间,并序列化到一个 JSON 配置文件,同时推送到线上服务器
- 实验客户端:实现为一个 PHP 库,读取 JSON 配置文件,恢复实验空间,同时为每次请求进行流量划分
- 实验管理系统:面向产品和实验人员,可以创建并管理各自的实验和参数,同时可以进行实验的审批和上线
- 数据收集系统:复用已有的日志收集平台,比如给已有的日志增加 experiment 字段的记录,保存每次生效的参数和值,这样就可以在集群上实时或离线的统计预订指标并写入统计数据库
- 数据展示平台:复用已有的数据展示平台,从统计数据库读取统计报表并可视化
实验分配系统和实验客户端之间的通信其实有很多种方法,之前在腾讯 GDT 我们是基于 Protobuf RPC。这里一切从简,使用 JSON 配置文件,好处是解耦,不会因为后端服务的异常影响到线上服务。
具体的部署是侵入式的,就是需要在具体的业务代码里根据参数值实现 if-else 逻辑。
据说百度和 Google 的实验部署是非侵入式的,但这需要开发流程是分支开发模式,并且需要实现额外的分流服务,同时代码部署需要和分流服务联动。这种适合大规模服务节点的情况,只有几台服务器就没法这么操作了。
这里所描述的只是系统设计方面,至于如何创建实现,根据要观察的效果改变大小,去选择合适的流量大小和实验时长,这也是个很复杂的话题。
实现
示例,一个 buckets_num=1000 的实验空间的框架如图:
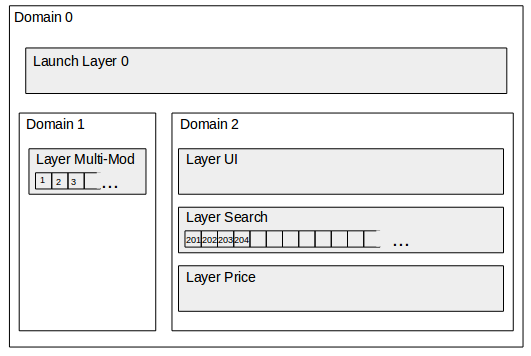
下面用一个具体的例子来大概说明一下实验系统的工作流程。
类似 Airbnb 改版搜索页面 ,我们通常会页面重构,但真正上线前肯定要经过 ab test,评估新设计对最终成单率的影响。
假设目前有一些参数:
-
search_modern_design搜索列表是否使用新设计 -
search_thumb_size搜索列表中缩略图大小 -
price_base_proportion价格浮动系数,默认为 1.0
现在我想创建一个实验,在北京范围内进行新的搜索页面实验,对比一下与旧页面的设计成单率的变化。于是我们创建了这样一组处理实验:
-
参数:
search_modern_design=true -
流量:
buckets_num=50 -
层:
layer='search' -
采样:
diversion='uuid' -
条件:
city='beijing' -
起止时间:
time_range=['2015-12-20 00:00:00', '2015-12-30 00:00:00']
相应另外一组对照实验:
-
参数:
search_modern_design=false
其他参数都一样。
实验分配系统会从数据库获取这些信息,一看总流量一共 1000 份,search layer 属于 domain 2 流量在 200~1000 这个区间,于是就在是在这个区间上分配流量;但紧接着发现 200~250 已经被其他实验占了,于是最终把这个实验分配到了 250~260 和 300~340 这两个区间。
实验管理系统审批通过后(设置
status='deploy'
),当达到时间(设置
status='publish'
),此时实验在线上生效。
实验客户端开始工作,它首先重新构建实验空间,得到层和流量划分的对应信息。对于某一份对实验生效的流量,会逐层分配,每层会依次按照 uuid/userid/random 方式采样,实际就是计算
hash(diversion_id, layer_id) % 1000
的值,对于这个生效实验
diversion='uuid'
,
layer_id='search'
,假设
hash%1000=301
,那么就可以继续判断实验条件,如果恰好该流量是北京的,则该实验对应的参数生效。
具体在 PHP 里就一句调用:
$value = ExpSys::get(“search_modern_design”);
可以得到参数值为
true
,当请求结束后,日志库会把此次请求应用的所有参数和值写到日志。然后,log agent 会把该日志上报到 kafka,最终变成 Hive 里的离线日志表,或者到 storm 之类的实时系统计算。
这里是怎么解决流量饥渴、条件偏置和参数耦合这几个坑的呢?关键就是分层实验系统把参数进行了分层,实际就是同一模块互相耦合的参数分配在同一层,而互不影响的参数分配在不同层,这样层和层之间的流量是正交的。每一份流量经过每一层会由均匀分布的 hash 函数重新随机分配到下一层的 bucket,这样保证了每个实验进入的流量是 同质 的,那么对照实验的对比结果就是不会有偏置的。同时每个层上的流量基本是 100% 复用的,这就解决了流量饥渴问题。然后,由于实验统一管理,上游已经分配过但条件不满足的流量,可以标识不再分配给下游,这样就能解决条件偏置问题。而且统一实验系统可以复用日志收集系统和数据展示系统,可以预先计算常用的 pv、uv、成单率等指标,这样就能更多、更快、更好的做实验了。
参考
- Overlapping Experiment Infrastructure (KDD 2010)
- Controlled experiments on the web: Survey and practical guide (DMKD 2008)
- Experiments at Airbnb
参考文献
- 基于.NET技术的实验教学管理系统设计与实现(吉林大学·刘静)
- 高校实验教学管理平台的设计与实现(云南大学·舒家赋)
- 分布式应用系统的研究与开发(武汉理工大学·廖斌)
- 基于WEB环境的实验室管理系统(电子科技大学·孙立伟)
- 基于.NET技术的实验教学管理系统设计与实现(吉林大学·刘静)
- 基于JAVA技术的实验室管理系统的设计与实现(电子科技大学·姜雷)
- 基于B/S架构的实验教学管理系统的设计与实现(山东大学·杨公博)
- 基于.NET技术的实验教学管理系统设计与实现(吉林大学·刘静)
- 山东英才学院实验室管理系统的设计与实现(山东大学·楚振龙)
- 独立学院实验室管理系统的设计与实现(电子科技大学·朱镕申)
- 实验室管理信息系统的设计与实现(电子科技大学·钟仙)
- 高校设计型实验管理平台的设计与实现(厦门大学·杰恩斯·玉素甫)
- 基于J2EE轻量级框架的实验室管理系统的设计与实现(华南理工大学·黄柳红)
- 高校实验教学管理系统的设计与实现(电子科技大学·陈爱霞)
- 成都大学城乡建设学院实验教学系统设计(电子科技大学·许强)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码货栈 ,原文地址:https://m.bishedaima.com/yuanma/35905.html









