分布式爬虫系统
Mi 项目文档
整体描述
Mi(迷)是一个分布式爬虫系统,由分布式爬虫管理系统(mi_manager)和支持分布式的智能爬虫(mi)两个子项目组成。
系统部署在稳定高效的分布式底层框架上。
借助多种算法提高分布式系统稳定性和数据挖掘能力。
系统实现
系统部署
系统部署在云服务器中。管理系统(mi_manager)、智能爬虫(mi)、各类数据库服务,均已 docker 容器的形式存在。

图1 分布式爬虫系统部署图
管理平台
平台地址 http://122.114.62.116
管理员账号: admin
管理员密码: 123456
使用帮助: http://www.mengzicheng.cn/wordpress/?p=1178
分布式底层框架(zookeeper+mesos+marathon+docker)
介绍
- ZooKeeper:ZooKeeper 是一个开源的分布式应用程序协调服务。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
- Mesos:Mesos 是 Apache 下的开源分布式资源管理框架,它被称为是分布式系统的内核。Mesos 能够在集群机器上运行多种分布式系统类型,动态有效率地共享资源。提供失败侦测,任务发布,任务跟踪,任务监控,低层次资源管理和细粒度的资源共享,可以扩展伸缩到数千个节点。
- Marathon:Marathon 是一个成熟的,轻量级的,扩展性很强的 Apache Mesos 的容器编排框架,能够支持运行长服务,比如 Web 应用等。能够在集群中原样运行任何 Linux 二进制发布版本,进行集群的多进程管理。在本系统中,Marathon 主要负责调度 docker 容器。
- Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。它彻底释放了计算虚拟化的威力,极大提高了应用的运行效率,降低了云计算资源供应的成本,使用 Docker,可以让应用的部署、测试和分发都变得前所未有的高效和轻松
设计
利用 Docker,快速地配置环境、数据库服务、部署项目。
项目中使用了如下三类镜像:
-
基础镜像与服务镜像
-
daocloud.io/library/python:2.7.7
- redis:3.2.8
- daocloud.io/library/mysql:5.7
-
daocloud.io/library/mongo:3.4.2
-
项目环境镜像
-
mi_environment:v6
根据 python2.7 的基础镜像,安装系统需要的 python 依赖包,生成 mi_environment 镜像,随着项目的进展,迭代六次,持续提供可靠地的运行和测试环境。
-
项目镜像
-
mi_manager:v6
由 mi_manager(python 程序源码)在 mi_environment 上打包而成,。运行容器可开启 Web 端管理应用和与任务调度相关的守护进程。
- mi:v12
由 mi(python 程序源码)在 mi_environment 上打包而成。运行容器自动获取 mi_manager 发布的任务,并开始爬虫任务。
在容器化的基础上,寻找管理和调度容器的方法。最终采用 zookeeper+meos+marathon 来进行容器的调度,其中 zookeeper 维持框架中服务的持久运行,mesos 来管理分布式系统中各个节点上的资源,marathon 来调度任务、管理 docker 容器。
系统结构图如下所示:
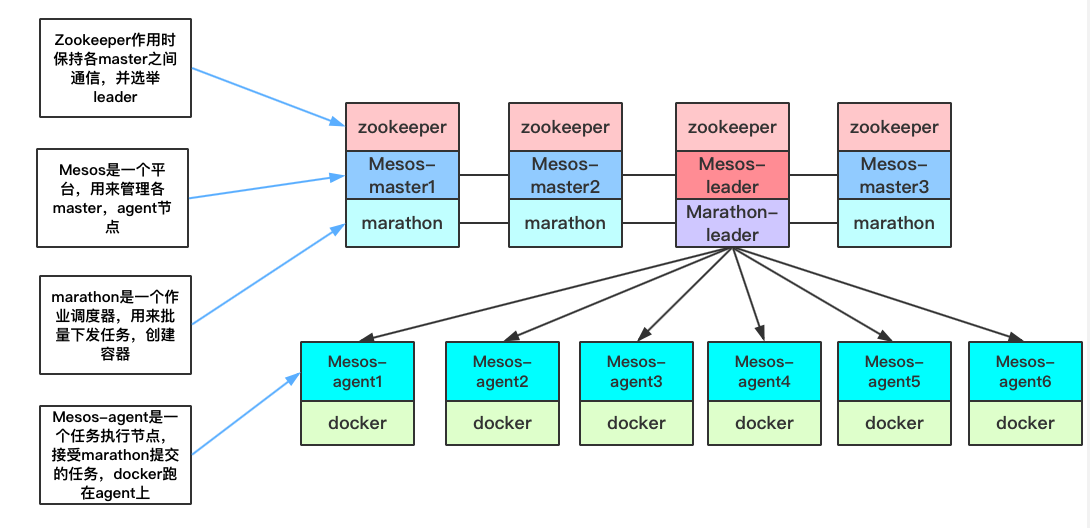
图2 系统结构图
测试
校内网环境: 测试环境采用一台 master,一台 agent,在两台服务器上安装了 Zookeeper、Mesos、Marathon、Docker 服务。整合两台服务器的资源。在测试时可同时稳定运行 30 个的容器,容器间相互隔离,独自占用指定数量的 CPU、内存、硬盘资源。
外网环境: 仅有一台服务器, 同时运行 mesos-master 服务和 mesos-agent 服务, 同样安装了 Zookeeper、Marathon、Docker 服务。 Mesos 控制台 : 122.114.62.116:5050 Marathon 控制台 :122.114.62.116:18082
安装帮助
ZooKeeper 安装: http://www.mengzicheng.cn/wordpress/?p=1221
Mesos 安装: http://www.mengzicheng.cn/wordpress/?p=1125
Marathon 安装: http://www.mengzicheng.cn/wordpress/?p=1023
Docker 安装: http://www.mengzicheng.cn/wordpress/?p=1291
辅助脚本
开发过程中总结了一些脚本,并开源到 github:
https://github.com/724686158/MYSHELLLS
可提供服务安装、服务启动、docker 镜像管理、docker 容器创建等方面的帮助。
注意
分布式系统的稳定运行除了需要安装服务软件外,还需要专业的运维人员进行维护,此外还需要注意访问控制、用户认证等安全问题。
分布式爬虫管理系统(mi_manager)
模块划分
- 进行系统管理的 monitor 模块
- 进行任务调度与分布式框架管理的 deamon 模块。
工作流程

图3 mi_manager工作流程图
monitor 模块
前端使用 AdminLTE 模板,后端使用 Flask 框架搭建的分布式系统管理平台。
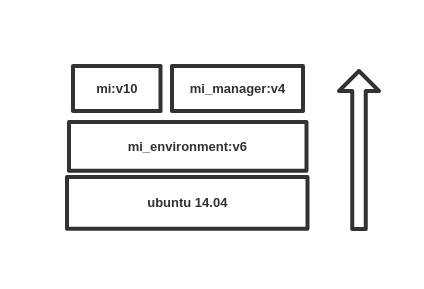

图4 Web服务功能模块图
模块功能
- 任务管理
- 即时爬取
- 精准爬虫管理
- 设置管理
- 资源管理
daemon 模块
与 monitor 模块协同工作的守护进程。
模块功能
- 任务调度
- 部署和管理任务容器
技术细节
模块间协作
mi_manager 使用具有持久化功能的 Redis 数据库作为核心数据库,并借助核心数据库协调 monitor 模块和 daemon 模块的工作,使其紧密配合。例如当用户创建新任务时,monitor 模块在响应用户请求的同时要向核心数据库中写入一个标志数据。当 daemon 模块发现这个标志时,就会重新加载核心数据库中的任务信息,更新任务列表,对新任务进行调度。
容器调度的原理
daemon 模块是通过向 marathon 的 API 发送 JSON 文件来管理容器的。而这些 JSON 文件是 daemon 调度任务时,结合文件模板与任务信息动态生成的。这些 JSON 文件发送个 marathon 控制台之后,marathon 会将他们转化成 Applications,之后 mesos 会在将其作为 task 部署到节点上。
支持分布式的智能爬虫(mi)
分布式爬虫系统中全部的爬取任务均由智能爬虫执行。
设计思路
结合精准爬取与模糊爬取
任务在创建阶段会要求用户提供入口 URL,这些 URL 可能是新闻类的,也可能是店商类的。智能爬虫必须要具有这两类网站的爬取能力,才能满足需求。
这两类网站具有不同的特点。
- 新闻网站包含政府网站、地方新闻、高校新闻、个人博客等,这类网站数量众多而但结构相对简单。
- 电商网站的数量相对较少、但网站结构极为复杂。
为应对复杂的实际情况, 在设计智能爬虫时采用了精准爬取与模糊爬取并存的解决方案。
- 精准爬取是指用人工方法分析网站,定位到实际所需的数据。对于分析过的网站,可以快速准确地提取数据。
- 模糊爬取是指程序在遇到未知的网站时自动分析网站结构,自动提取数据。
如果仅使用两者之一,都会遇到瓶颈。
- 对于精准爬取,对各大门户网站的人工分析,能用较少的人工成本,换取较大的覆盖率。如果一味得通过人工编写爬虫业务来提高覆盖率,工作的回报就会逐渐变小。而且当遇到未知网站时,无法开展任何爬取工作。系统变得不可扩展,无法满足用户变化的需求。
- 对于模糊爬取,一定水平的算法与技术是易于掌握的,比如:优秀的开源项目如 jieba、Goose,数据挖掘方面成熟的算法如支持向量机、朴素贝叶斯,常用的页面分析算法如加分算法,锚链接分析。对成熟的算法与技术进行整合能够满足一定的需求。如果只使用模糊爬取,系统的运行速度、提取准确率都完全依赖于算法的性能,系统就会进入一个不可控的状态,算法中任何一个模块的微调,都可能造成系统效率的巨大波动。
结合精准爬取与模糊爬取,用精准爬取处理重要门户网站,保证系统的的覆盖率。对于覆盖不到的网站,再用模糊爬取进行处理。
工作方向:
- 分析更多网站,获得更高的覆盖率。
- 对分析网站的方式做出优化,降低人工分析的难度,提高人工分析的效率和准确率。
- 研究有关算法和技术,提高模糊爬取的速度和准确率。
成果:
- 实现了对 6 个主要电商网站,162 个新闻网站的覆盖。
- 实现了 Web 端的精准爬虫管理,开发人员可以快速的编写新爬虫,用户也可以自行扩展系统的覆盖范围。
- 整合支持向量机、加分算法、jieba、Goose,实现了一个性能优秀的模糊爬取算法。
工作流程

图5 mi工作流程图
基础框架
基于 Scrapy 框架和 Scrapy-redis 框架
Scrapy 框架
- Scrapy 是用纯 Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- Scrapy 使用了 Twisted 异步网络框架来处理网络通讯,可以加快下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
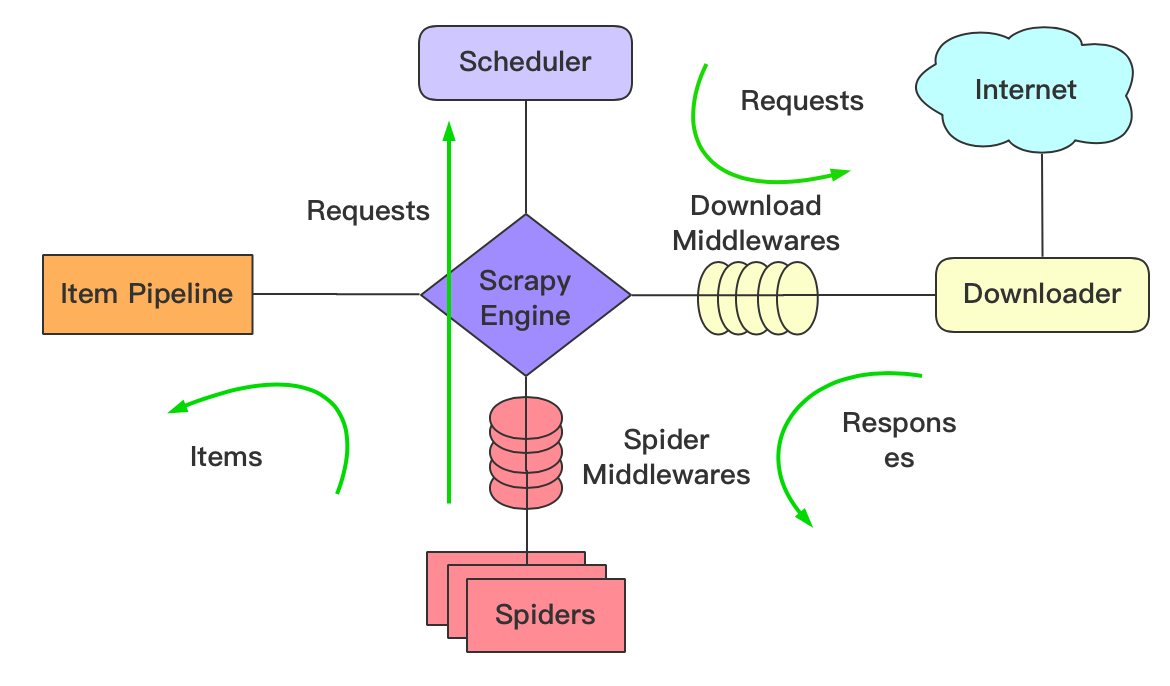
图6 scrapy框架图
- Scrapy Engine(引擎): 负责 Spider、ItemPipeline、Downloader、Scheduler 中间的通讯,信号、数据传递等。
- Scheduler(调度器): 负责接受引擎发送过来的 Request 请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载 Scrapy Engine(引擎)发送的所有 Requests 请求,并将其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 Spider 来处理,
- Spider(爬虫):负责处理所有 Responses,从中分析提取数据,获取 Item 字段需要的数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器),
- Item Pipeline(管道):负责处理 Spider 中获取到的 Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider 中间件):是一个可以自定扩展和操作引擎和 Spider 中间通信的功能组件(比如进入 Spider 的 Responses;和从 Spider 出去的 Requests)
scrapy 任务调度是基于文件系统,只能本地执行,不支持分布式。
Scrapy-redis 框架
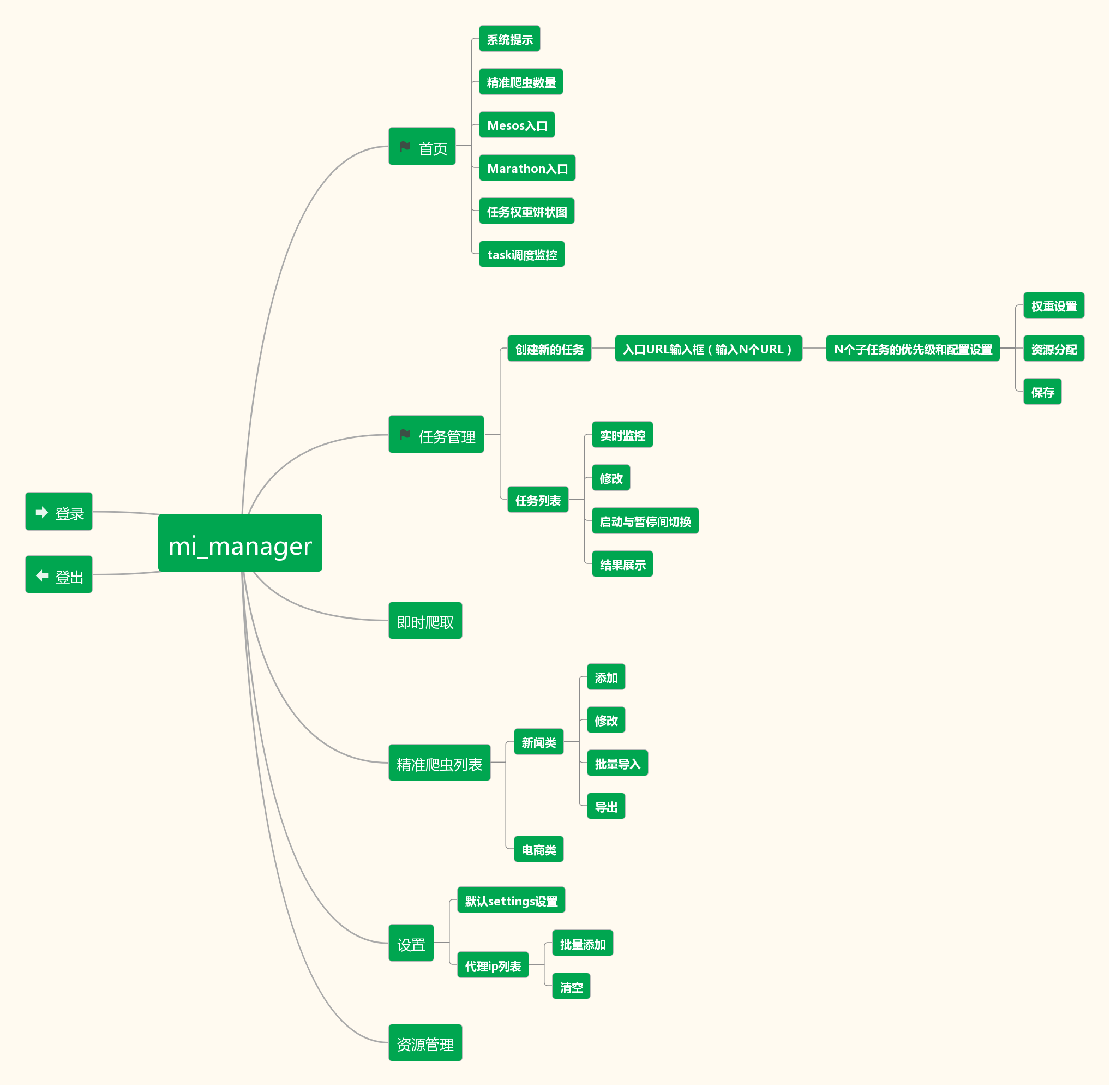
图7 Scrapy-redis框架图
上图中的过程 1~5 分别代表:
- 调度器从待下载 request 队列中获取 request
- 调度器将 request 按照调度算法分发给相对应的 Spider
- 下载器根据 request 下载网页, 并发送给采集模块
- 在采集模块中,从下载的网页发现 URL,完成 URL 增量,将其加入待下载的 request 队列
- 在采集模块中,提取目标数据,保存对象,交由 pipeline 完成数据存储
scrapy-redis 将待抓取 request 请求信息和数据 items 信息的存取放到 Redis queue 里,使多台服务器可以同时执行 crawl 和 items process,大大提升了数据爬取和处理的效率。
scrapy-redis 是基于 Redis 的 scrapy 组件,主要功能如下:
- 分布式爬虫
多个爬虫实例分享一个 Redis request 队列,非常适合大范围多域名的爬虫集群
- 分布式后处理
爬虫抓取到的 items push 到一个 Redis items 队列,这就意味着可以开启多个 items processes 来处理抓取到的数据,比如存储到 MongoDB、MySQL
- 基于 scrapy 即插即用组件
Scheduler + Duplication Filter, Item Pipeline, Base Spiders.
如上图所示,scrapy-redis 在 scrapy 的框架上增加了 Redis,基于 Redis 的特性拓展了如下组件:
- 调度器(Scheduler)
scrapy-redis 调度器通过 Redis 的 set 不重复的特性,巧妙的实现了 Duplication Filter 去重(DupeFilter set 存放爬取过的 request)。 Spider 新生成的 request,将 request 的指纹到 Redis 的 DupeFilter set 检查是否重复,并将不重复的 request push 写入 Redis 的 request 队列。 调度器每次从 Redis 的 request 队列里根据优先级 pop 出一个 request, 将此 request 发给 spider 处理。
- Item Pipeline
将 Spider 爬取到的 Item 给 scrapy-redis 的 Item Pipeline,将爬取到的 Item 存入 Redis 的 items 队列。可以很方便的从 items 队列中提取 item,从而实现 items processes 集群
技术细节
任务信息自动加载
在启动阶段,智能爬虫会从核心数据中获取一个 task,其中包含了智能爬虫工作需要的全部信息,智能爬虫根据 task 开展工作。此后,智能爬虫只会向系统回传监控数据,而不再需要从系统中获取任何数据,直到容器销毁。这种设计保证了智能爬虫可以运行在系统内的任何一个节点上,用户不用对其进行任何干预。
配置文件的自动化
在整合智能爬虫程序与基础框架后,对全部设置项进行整理,并测试不同的设置对性能的影响。
当默认设置为最优值时,如果此设置同时具有难以被用户理解和对系统影响较小两个特点时,就将它的配置信息从主配置文件中去除。当人工设置的值比默认值能够带来更好的性能时,就像它写入主配置文件,同时代替使用者为其付最优值。当某项设置能够对爬虫运行产生较大影响时,就将它写入主配置文件,并引导用户进行设置。此外还有一些设置与框架无关,是智能爬虫在工作时需使用的设置,比如数据库的地址,端口等。这些参数由分布式系统进行调度。在 mi 的运行启动阶段,会从核心 Redis 数据库中获取这些参数的值。并进行自动设置。
最终主配置文件中的设置可分为如下三类:
- 用户自定义的配置--用户可根据使用需求主动配置
- 分布式系统自动分配的设置--从核心数据库中自动加载
- 向用户隐藏的设置--这些配置信息是为了保证爬虫可以正常运行所必要的配置文件,用户若进行更改可能会引起爬虫出现异常或错误
在 mi 启动阶段,从核心数据库获取一个 task,这个 task 中就包含有上述配置需要的全部信息,mi 结合配置文件模板与获取到的信息,在正确路径下生成出爬虫运行所需的 settings 文件,等待 Scrapy 框架配置。
下面对配置信息进行详细介绍:
-
用户自定义的配置
-
任务名,Scrapy 项目实现的 bot 的名字(也未项目名称)。 这将用来构造默认 User-Agent,同时也用来 log。当您使用 startproject 命令创建项目时其也被自动赋值。
BOT_NAME
- 用户是否选择遵守网站的 robots 协议,如果选择遵守 robots 协议,将 ROBOTSTXT_OBEY 设置为 True,这一举动可能会造成爬虫出现异常或错误,如果选择不遵守 robots 协议,将 ROBOTSTXT_OBEY 设置为 False。
ROBOTSTXT_OBEY
- 是否启用 COOKIES,是否启用 cookies middleware。如果关闭,cookies 将不会发送给 Web server。,如果启用了 COOKIES,将 COOKIES_ENABLED 设置为 True,则在生成 request 请求时会自动添加 COOKIE 信息,如果不启动 COOKIES,则将 COOKIES_ENABLED 设置为 False
COOKIES_ENABLED
- 是否启用 HTTP 代理(取值为 None 或 400 )
HTTP_PROXY_ENABLED
- 是否启用重试,即如果发生服务器在默认的 TIMEOUT 时间内没有对爬虫的请求进行处理,爬虫是否重新发送这一请求。默认为 False,因为对失败的 HTTP 请求进行重试会减慢爬取的效率,尤其是当站点响应很慢(甚至失败)时,访问这样的站点会造成超时并重试多次。这是不必要的,同时也占用了爬虫爬取其他站点的能力。
RETRY_ENABLED
- 是否启用自动限速(启用会牺牲一定的爬取速度,但会照顾到目标网站的负载能力)
AUTOTHROTTLE_ENABLED
- 初始下载延迟(单位:秒)
AUTOTHROTTLE_START_DELAY
- 最大下载延迟(单位:秒)
AUTOTHROTTLE_MAX_DELAY
- 此类容器负责的具体子任务
SUB_MISSION
- 间隔时间下限(任何情况下不会小于此值)下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压。该设定影响(默认启用的) RANDOMIZE_DOWNLOAD_DELAY 设定。 默认情况下,Scrapy 在两个请求间不等待一个固定的值, 而是使用 0.5 到 1.5 之间的一个随机值 * DOWNLOAD_DELAY 的结果作为等待间隔。在 Scrapy 文档中,对此默认为 0,是为了最大提高爬虫效率。 当 CONCURRENT_REQUESTS_PER_IP 非 0 时,延迟针对的是每个 ip 而不是网站。
DOWNLOAD_DELAY
- 对单个域名并发量的上限(任何情况下不会高于此值),对单个网站进行并发请求的最大值。
CONCURRENT_REQUESTS_PER_DOMAIN
- 超时时限,下载器超时时间,单位是秒
DOWNLOAD_TIMEOUT
-
分布式系统自动分配的设置
-
Redis —— url 存储,redis 数据库的地址,包括 host 与 port
REDIS_HOST REDIS_PORT
- Redis —— 去重队列,存储 request 去重队列的 Redis 数据库,包括 host 和 port
FILTER_HOST FILTER_PORT
- MySQL 数据库的配置信息
MYSQL_HOST MYSQL_PORT MYSQL_DBNAME MYSQL_USER MYSQL_PASSWD
- MongoDB 数据库的配置信息
MONGO_HOST MONGO_PORT MONGO_DATABASE
-
向用户隐藏的设置
-
项目各个子模块的名字
SPIDER_MODULES = ['mi.spiders_of_eCommerce', 'mi.spiders_of_news_in_whiteList', 'mi.spiders_of_news_need_fuzzymatching']
- 爬虫在每一个网站的爬取深度,推荐设置为 20,是为了避免那些动态生成链接的网站造成的死循环,暂时没遇到这种网站,先禁用了
DEPTH_LIMIT = 20
- 是否显示 COOKIES_DEBUG,如果启用,Scrapy 将记录所有在 request(Cookie 请求头)发送的 cookies 及 response 接收到的 cookies(Set-Cookie 接收头)
COOKIES_DEBUG = False
- 用于存储调度队列的 Redis 数据据库编号
ILTER_DB = 0
- 用于存储记号变量的 Redis 数据据库编号
SYMBOL_DB = 1
- 用于存储 task 的 Redis 数据据库编号
TASK_DB = 2
- 用于进行 task 调度的有序集合的 Redis 数据据库编号
DISPATCH_DB = 3
- 用于存储主任务的 Redis 数据据库编号
MISSION_DB = 4
- 用于存储子任务的 Redis 数据据库编号
SUBMISSION_DB = 5
- 用于存储爬虫配置信息的 Redis 数据据库编号
SETTINGS_DB = 6
- 用于存储資源(REDIS 服务器)的信息 Redis 数据据库编号
RESOURCES_REDIS_DB = 7
- 用于存储資源(MYSQL 服务器)的信息的 Redis 数据据库编号
RESOURCES_MYSQL_DB = 8
- 用于存储資源(MONGO 服务器)的信息的 Redis 数据据库编号
RESOURCES_MONGO_DB = 9
- 用于存储代理 ip 的 Redis 数据据库编号
PROXY_DB = 10
- 用于暂存爬虫运行时数据的 Redis 数据据库编号
RUNNINGDATA_DB = 11
- 用于存储 Cookie 数据的 Redis 数据据库编号
COOKIES_DB = 12
- 用于存储新闻类爬虫配置参数的 Redis 数据据库编号
SPIDERS_DB = 13
- 用于分类爬虫的 Redis 数据据库编号
CLASSIFIER_DB = 14
- 用于存储 Monitor 数据的 Redis 数据据库编号
MONITOR_DB = 15
- 存储爬虫运行数据的四个队列,需要与 monitor.monitor_settings 中的一致
STATS_KEYS = ["downloader/request_count", "downloader/response_count", "downloader/response_status_count/200", "item_scraped_count"]
- 日志设置,禁用“LOG_STDOUT=True”,如果为 True,进程所有的标准输出(及错误)将会被重定向到 log 中。例如, 执行 print 'hello' ,其将会在 Scrapy log 中显示。
LOG_FILE='mi.log' LOG_LEVEL='INFO'
- 是否显示 AUTOTHROTTLE_DEBUG
AUTOTHROTTLE_DEBUG
- pipelines 从 300 累加,从 Spider 中抛出的 Item 首先会被 MonogPipeline 处理,然后被 MysqlPipeline 处理
ITEM_PIPELINES = { 'mi.pipelines.pipeline_mongo.MongoPipeline':300, 'mi.pipelines.pipeline_mysql.MysqlPipeline':301, }
- 下载中间件,其中包括与代理有关的 RandomProxyMiddleware,与 UserAgent 有关的 RotateUserAgentMiddleware,与可视化有关的 StatcollectorMiddleware,与 COOKIE 有关的 CookieMiddleware,CookieMiddleware 中间件将重试可能由于临时的问题,例如连接超时或者 HTTP 500 错误导致失败的页面。尝试加上 cookie 重新访问
DOWNLOADER_MIDDLEWARES = { 'mi.middlewares.middleware_proxy.RandomProxyMiddleware':HTTP_PROXY_ENABLED, 'mi.middlewares.middleware_rotateUserAgent.RotateUserAgentMiddleware': 401, 'mi.middlewares.middleware_monitor.StatcollectorMiddleware': 402, 'mi.middlewares.middleware_cookie.CookieMiddleware': None, }
- 请求连接失败重试次数
RETRY_TIMES = 6
- proxy 失败重试次数
PROXY_USED_TIMES = 2
27, 重试返回码
RETRY_HTTP_CODES = [500, 503, 504, 599, 403]
- 选择 scrapy_redis 框架中的调度器
SCHEDULER = 'mi.scrapy_redis.scheduler.Scheduler'
- 允许调度器持久化,即允许将 Redis 中的所有操作均进行持久化,以实现暂停重启爬虫的工作,从上一次暂停或者崩溃的处继续进行,但带来的缺点时是会占用较大部分的硬盘空间。
SCHEDULER_PERSIST = True
- 请求调度使用优先队列(默认)
SCHEDULER_QUEUE_CLASS = 'mi.scrapy_redis.queue.SpiderPriorityQueue'
- 这是对下载处理器进行设置,不使用其中的 s3 处理器,若使用 s3 处理器则有可能出现异常
DOWNLOAD_HANDLERS = {'s3': None,}
爬虫工作原理
新闻博客类和电商类的网站构造以及网页之间的关系差别较大,因此制定的爬虫策略是截然不同的,相比较而言,电商类因为涉及到大量的 AJAX 技术,需要处理更多的动态问题,复杂性更高
新闻博客类爬虫逻辑
对新闻博客类网站,选择全站爬取。这类网站的各个界面之间的关系是较为简明的,而且由于只抓取正文页,因此,只需在 URl 增量的过程中找到符合每个新闻网站中的正文页 url 格式的网页,然后交给下载中间件下载,再进一步对标题与正文解析即可。
-
以财经网的爬虫为例
-
首先配置爬虫的基本信息;爬虫的名字,限定访问域以及此爬虫在 Redis 数据库中的键名
name = 'caijing'
redis_key = settings.caijing_start_urls
allowed_domains = ['caijing.com.cn']
- 接下来设置财经网(新闻博客类网站)正文页的 URL 增量与找到符合要求的正文页后要传递的回调函数。 使用 Scrapy 中 Rule 规则来实现目的。在 rules 中编写符合要求的 Rule,每一个 Rule 有一个 LinkExtractor 函数参数,在此函数中用正则表达式作为从已下载的网页中提取正文 URL 的方法。提取到的 URL 在 Scrapy 框架中交由 Scrapy Engine,由 Scrapy Engine 传递给 Scheduler(调度器),调度器选择适合的时候交给下载中间件下载网页,即想要的正文页面。在 Rule 的第二个参数中设置回调函数,回调函数进一步解析已下载的正文页面。 当这个环上的所有点都被搜索完后,就实现了对此新闻博客类网站的全站爬取。事实上这是很难实现的,因为每天都会有新的内容加入到这个网站中来。
rules = [
Rule(LinkExtractor(allow=('caijing.com.cn/\d{8}/\d*')),callback='processArticle',follow=True)
]
-
下面是对正文页进行标题与正文的提取,此过程使用 XPath 表达式完成提取。XPath 是用于选择 XML 文档中的节点的语言,其也可以与 HTML 一起使用。XPpath 是 Scrapy 内建的选择器,Scrapy 选择器构建在 lxml 库之上,这意味着它们的速度和解析精度非常相似。选择 XPath 而不是流行的 BeautifulSoup 或者使用正则表达式有以下几点原因:
-
XPath 是 Scrapy 内建的选择器,它与 Scrapy 有天然的默契,更为简便且不需要考虑出了语法本身外别的任何问题。
- XPath 的提取效率更高,提取速度比 BeautifulSoup 更快。
3. XPath表达式是基于XML的文档层次结构的,而正则表达式是基于文本特征的,由于只需要确定内容的位置,所以选用XPath表达式。
title = response.xpath("/html/body/div[@class='center']/div[@class='content']/div[@class='main']/div[@class='main_lt article_lt']/div[@id='article']/h2[@id='cont_title']/text()").extract()[0]
content = ''.join(response.xpath('//div[@class="e43_8426_268d511 article-content"]//p/text()').extract())
电商类爬虫逻辑
电商类爬虫的基本步骤与新闻博客类类似,明显的区别在于:
- 更复杂的网页结构
- 动态加载问题
- COOKIE,IP 等有关的身份验证
而由此带来的困难有:
- URL 增量受到影响,动态网页中可能没有可以提取的有用的 URl
- 数据抓取不到
- 访问频率受限,很容易被 BAN
针对以上问题,做出如下解决方案:
- 网页结构与数据问题
在新闻博客类网站中,抓取的数据,标题和正文都在同一个页面中,而电商类,抓取的数据往往需要从不同页面中抓取,还要装在同一个数据类型中进行封装。 商品和店铺是电商类网站的最核心部分,也是爬虫要爬取的核心部分。主要分为对商品页面进行处理和对店铺页面进行处理,使用两个回调函数 processGood 和 processShop 对商品和店铺页面分开处理,提取数据,并进行封装。 * URL 增量问题
在编写部分电商网站的爬虫时发现,各个网站的动态加载深度是不一样的,部分网站是可以完成 URL 增量的,比如京东:
rules = {
Rule(LinkExtractor(allow=('https://item.jd.com/\d+.html'), deny=()),callback='processGood',follow=True),
Rule(LinkExtractor(allow=('https://mall.jd.com/shopLevel-\d+.html'), deny=()) ,callback= 'processShop',follow=True),
}
可以做到类似新闻博客类网站的 URl 增量过程。 而对于另外的电商类网站,比如淘宝,天猫,它们的动态加载是非常完善的,并没有办法从它的商品和店铺界面中进行 URL 增量。但是在实践中发现,可以在它的搜索页面上获取到相关的 URl,因此只能牺牲一部分的效率,先对对大量的搜索页面进行增量处理,然后在此过程中获取到商品和店铺的 URL。 * 数据抓取不到
对于因动态加载而无法直接获取的数据,一般有两种方法:
- 在本地模型浏览器访问,进行 JavaScript 渲染从而获取到有完整数据的界面,然后在从中进行提取数据的操作。
- 模拟 JavaScript 动态发请求的操作,对同一动态数据来源的 URl 进行申请,以获得相应的数据。
由于本地渲染的方法速度太慢,不适合完成大规模爬取的爬虫,因此最终选择方法 2。 * 访问频率受限 这是因为电商类网站对 COOKIE 和 IP 的访问限制导致的,所以只要解决 COOKIE 和 IP 的问题即可。 在 Scrapy 框架的下载中间件的基础上进行扩展,编写了 middleware_rotateUserAgent.py,middleware_cookie.py 和 middlwware_proxy.py ,并在 scrapy 的关于下载中间件的配置文件中启用并调整每一个对网页的下载请求的经历中间件的顺序,使得每一个下载网页的请求都具有符合要求的 UserAgent,COOKIE 和 Ip,从而是爬虫可以连续不断的进行爬取。
新闻博客类数据结构化与存储
因为电商网站和新闻博客类网站抓取数据的不同,因此根据其特点设计不同的结构化数据类型,并使用不同的数据库进行存储
- 新闻博客类
因为新闻博客类抓去的数据是文章标题和文章正文,因此设计了如下的数据类型
class ArticleItem(scrapy.Item):
文章标题
articleTitle = scrapy.Field()
文章url
articleUrl = scrapy.Field()
文章内容
articleContent = scrapy.Field()
文章关键词1
articleFirstTag = scrapy.Field()
文章关键词2
articleSecondTag = scrapy.Field()
文章关键词3
articleThirdTag = scrapy.Field()
这是可以覆盖绝大部分新闻博客类网站数据共性的数据类型
在获得结构化数据后,因为文章的结构化数据较容易存储,且为了存储效率,选用了 MongoDB 来存储新闻博客类的结构化数据
MongoDB 是一个非关系型数据库,与传统的关系型数据库不,以下特性
- 弱一致性,更能保证用户的访问速度
- 文档结构的存储方式,能够更便捷的获取数据
- 内置 GridFS,支持大容量的存储
- 第三方支持丰富
- 对 JSON 和 bson 支持优异
- 适合搭建集群
MongoDB 的这些特性,很适合分布式爬虫搭建集群存储数据的需求
以下是使用 MongoDB 存储新闻博客类数据的步骤(在 scrapy 的 pipeline 上进行扩展,编写了 pipeline_mongo.py)
- 首先初始化 MongoDB
def __init__(self, mongo_host, mongo_port, mongo_db):
self.mongo_host = mongo_host
self.mongo_port = mongo_port
self.mongo_db = mongo_db
2. 创建 MongoDB 数据库的连接
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_host, self.mongo_port)
self.db = self.client[self.mongo_db]
3. 将数据存储到 MongoDB 中
def process_item(self, item, spider):
if isinstance(item, ArticleItem):
self.hp_collection_name = settings.MONGO_COLLECTION_NAME
self.db[self.hp_collection_name + '_' + 'ArticleItem'].insert(dict(item)) # 存入数据库原始数据
if isinstance(item, DomTreeItem):
self.hp_collection_name = settings.MONGO_COLLECTION_NAME
self.db[self.hp_collection_name + '_' + "DomTreeItem"].insert(dict(item)) # 存入数据库原始数据
return item
4. 关闭数据库的连接
def close_spider(self, spider):
self.client.close()
```
至此,新闻博客类的结构化数据存储就完成了。
电商类数据结构化与存储
与新闻博客类不同,电商类数据之间关系要复杂的多,各个电商之间存在着较大的差异,较为共性的是商品信息,商品名字和商品价格是在抓取电商类数据时最为重要的部分,因此对商品设计了如下的数据类型
不同电商网站中的商品数据具有相似的结构
- 电商商品结构化数据格式
```
class ECommerceGoodItem(scrapy.Item):
电商网站 Id
eCommerceId = scrapy.Field()
商品 id
goodId = scrapy.Field()
店家 id
shopId = scrapy.Field()
商品名字
goodName=scrapy.Field()
商品链接
goodUrl = scrapy.Field()
商品价格
goodPrice=scrapy.Field()
```
不同的电商网站在商品评价数据、店铺数据、店铺评论数据上具有较大的差异。有些电商网站缺少店铺的详细信息,有的网站没有店铺评分详细数据。此外还有对同一类数据的表现形式的差异,在抓取过程中难以将其转换为同一类型,因为,为了覆盖尽可能多的电商网站,设计了以下三种结构化数据格式 分别是
- 电商商品评论结构化数据格式
```
class ECommerceGoodCommentItem(scrapy.Item):
电商网站 Id
eCommerceId = scrapy.Field()
商品的 id
goodId=scrapy.Field()
商品评论页的链接
goodCommentsUrl=scrapy.Field()
商品评论数据
goodCommentsData=scrapy.Field()
```
- 电商店铺结构化数据格式
```
class ECommerceShopItem(scrapy.Field):
电商网站 Id
eCommerceId = scrapy.Field()
店家 id
shopId = scrapy.Field()
店家名字
shopName = scrapy.Field()
店家链接
shopUrl = scrapy.Field()
店家所在地
shopLocation=scrapy.Field()
店家电话
shopPhoneNumber=scrapy.Field()
```
电商店铺评论结构化数据格式
```
``` class ECommerceShopCommentItem(scrapy.Field):
电商网站Id
eCommerceId = scrapy.Field()
店家id
shopId = scrapy.Field()
店家评论页的链接
shopCommentsUrl = scrapy.Field()
店家评论数据
shopCommentsData=scrapy.Field() ```
```
电商网站的结构不尽相同,爬虫的抓取逻辑差异也较为明显,造成了数据之间较为复杂的数据关系,因此选择了传统的关系型数据库 Mysql 来存储电商类的结构化数据,使用关系型数据库的较为优异的条件还有:
- 电商类的数据会涉及到很多的较为复杂的查询操作,使用 sql 语句可以很好的完成
- 电商类数据往往会用到事务操作
而使用 Mysql 的优点有:
- Mysql 是一个成熟的,稳定的关系型数据库,支持很完善的 sql 语句操作规范
- Mysql 可以处理大数据量的操作
- 可移植行高,安装简单小巧
- 良好的运行效率
数据库设计:
以下是使用Mysql存储电商类数据的过程(对scrapy的pipeline的基础上进行扩展,编写pipeline_mysql.py)
- 初始化数据库 ```
def __init__(self, dbpool):
self.dbpool = dbpool
2. 获取数据库的配置信息完成实例化
def from_settings(cls, settings): try: dbparams = dict( host=settings['MYSQL_HOST'], user=settings['MYSQL_USER'], passwd=settings['MYSQL_PASSWD'], db=settings['MYSQL_DBNAME'], charset='utf8', cursorclass=pymysql.cursors.DictCursor) dbpool = adbapi.ConnectionPool('pymysql', **dbparams) return cls(dbpool) except: print '获取配置信息出错'
```
- 判断获取到的是商品结构化数据类型,商品评论结构化数据类型,店铺结构化数据类型,店铺评论结构化数据类型,电商网站结构化数据类型中的哪一种,选择相对应的方法完成存储操作
```
def process_item(self, item, spider): if isinstance(item, ECommerceItem): query = self.dbpool.runInteraction(self._conditional_insert_ECommerce, item) # 调用插入的方法 query.addErrback(self._handle_error, item, spider) # 调用异常处理方法
``` if isinstance(item, ECommerceShopItem): query = self.dbpool.runInteraction(self._conditional_insert_ECommerceShop, item) # 调用插入的方法 query.addErrback(self._handle_error, item, spider) # 调用异常处理方法
if isinstance(item, ECommerceShopCommentItem):
query = self.dbpool.runInteraction(self._conditional_insert_ECommerceShopComment, item) # 调用插入的方法
query.addErrback(self._handle_error, item, spider) # 调用异常处理方法
if isinstance(item, ECommerceGoodItem):
query = self.dbpool.runInteraction(self._conditional_insert_ECommerceGood, item) # 调用插入的方法
query.addErrback(self._handle_error, item, spider) # 调用异常处理方法
if isinstance(item, ECommerceGoodCommentItem):
query = self.dbpool.runInteraction(self._conditional_insert_ECommerceGoodComment, item) # 调用插入的方法
query.addErrback(self._handle_error, item, spider) # 调用异常处理方法
return item
```
```
- 各个类型的具体存储操作
-
若是电商网站结构化数据类型,则向ECommerce表插入数据
def _conditional_insert_ECommerce(self, tx, item): # 这个要根据item里的内容,以及表的结构来写 sql = "insert into ECommerce(eCommerceName, eCommerceUrl) values(%s,%s)".encode( encoding='utf-8') params = (item["eCommerceName"], item["eCommerceUrl"]) tx.execute(sql, params) try: print "插入电商网站数据成功" except: print "插入电商网站数据失败" -
如果是商品结构化数据类型,则向ECommerceGood表插入数据
def _conditional_insert_ECommerceGood(self, tx, item): # 这个要根据item里的内容,以及表的结构来写 sql = "insert into ECommerceGood(eCommerceName, goodId, shopId, goodName, goodUrl, goodPrice) values(%s,%s,%s,%s,%s,%s)".encode( encoding='utf-8') params = ( item["eCommerceName"], item["goodId"], item["shopId"], item["goodName"], item["goodUrl"], item["goodPrice"]) tx.execute(sql, params) try: print "插入商品数据成功" except: print "插入商品数据失败" -
若是商品评论结构化数据类型,则向ECommerceComment表插入数据
def _conditional_insert_ECommerceGoodComment(self, tx, item): # 这个要根据item里的内容,以及表的结构来写 sql = "insert into ECommerceGoodComment(eCommerceName, goodId, goodCommentsUrl, goodCommentsData) values(%s,%s,%s,%s)".encode( encoding='utf-8') params = (item["eCommerceName"], item["goodId"], item["goodCommentsUrl"], item["goodCommentsData"]) tx.execute(sql, params) try: print "插入商品评价数据成功" except: print "插入商品评价数据失败" -
若是店铺结构化数据类型,则向ECommerceShop表插入数据
def _conditional_insert_ECommerceShop(self, tx, item): # 这个要根据item里的内容,以及表的结构来写 sql = "insert into ECommerceShop(eCommerceName, shopId, shopName, shopUrl, shopLocation, shopPhoneNumber) values(%s,%s,%s,%s,%s,%s)".encode( encoding='utf-8') params = (item["eCommerceName"], item["shopId"], item["shopName"], item["shopUrl"], item["shopLocation"], item["shopPhoneNumber"]) tx.execute(sql, params) try: print "插入店家数据成功" except: print "插入店家数据失败" -
若是店铺评论结构化数据类型,则向ECommerceShopComment表插入数据
def _conditional_insert_ECommerceShopComment(self, tx, item): # 这个要根据item里的内容,以及表的结构来写 sql = "insert into ECommerceShopComment(eCommerceName, shopId, shopCommentsUrl, shopCommentsData) values(%s,%s,%s,%s)".encode( encoding='utf-8') params = (item["eCommerceName"], item["shopId"], item["shopCommentsUrl"], item["shopCommentsData"]) tx.execute(sql, params) try: print "插入店家评价数据成功" except: print "插入店家评价数据失败" -
若插入数据数据存在错误,则调用异常处理
def _handle_error(self, failue, item, spider): print failue
算法部分
BloomFilter 算法
使用 BloomFilter 数据结构及有关算法实现 url 去重。
介绍
由于网站的链接之间的关系错综复杂,因此爬虫在爬去的过程中很容易遇到相同的要申请下载的 url,很容易因此形成闭合的环,所以要对 url 进行判重操作,只有没有被爬取过的 url 才会被提交给 scrapy 的下载中间件进行下载
- 在 scrapy 框架中,scrapy 首先计算一个 request 的 fingerprint,这个 fingerprint 相当于一个 request 独有的标记,然后将这个 fingerprint 放在一个 set 中,通过 set 来对 fingerprint 以至于 request 和 url 判重。 代码如下:
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
* 在 scrapy-redis 框架中,使用同样的方法计算 request 的 fingerprint,同样使用一个 set 用来判重,只不过这个 set 是在 Redis 数据库中。代码如下:
def request_seen(self, request):
fp = request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return not added
这两种使用 set 的方法在数据量比较小时是很有效的,但是当数据量比较大时,因为这两种方法的 set 都是在内存中,set 占用的内存空间会急剧上升。那使用持久化方法,将 url 存进数据库中,是不是一种好方法呢?当然不是。如果将 url 保存在数据库中,那么每一次判重操作都需要完成一次数据库查询,那带来的效率是极低的。
为了解决以上两种问题,选择使用 Bloomfilter 算法来完成 url 判重。
原理
- 建一个 m 位 BitSet,先将所有位初始化为 0,然后选择 k 个不同的哈希函数。第 i 个哈希函数对字符串 str 哈希的结果记为 h(i,str),且 h(i,str)的范围是 0 到 m-1 。
- 加入字符串过程下面是每个字符串处理的过程,首先是将字符串 str“记录”到 BitSet 中的过程:对于字符串 str,分别计算 h(1,str),h(2,str)…… h(k,str)。然后将 BitSet 的第 h(1,str)、h(2,str)…… h(k,str)位设为 1。
- 检查字符串是否存在的过程。下面是检查字符串 str 是否被 BitSet 记录过的过程:对于字符串 str,分别计算 h(1,str),h(2,str)…… h(k,str)。然后检查 BitSet 的第 h(1,str)、h(2,str)…… h(k,str)位是否为 1,若其中任何一位不为 1 则可以判定 str 一定没有被记录过。若全部位都是 1,则“认为”字符串 str 存在。若一个字符串对应的 Bit 不全为 1,则可以肯定该字符串一定没有被 BloomFilter 记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为 1 了)但是若一个字符串对应的 Bit 全为 1,实际上是不能 100% 的肯定该字符串被 BloomFilter 记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为 false positive 。
实现
-
首先实现一个 BloomFilter 算法:
-
设计一个可以调整参数的 hash 类
``` class SimpleHash(object): def init (self, cap, seed): self.cap = cap self.seed = seed
def hash(self, value): ret = 0 for i in range(len(value)): ret += self.seed * ret + ord(value[i]) return (self.cap - 1) & ret ``` * 在 BloomFilter 类中分发不同的 seed 以创建不同的 hash 类,然后按照 BloomFilter 算法实现判重操作
```
class BloomFilter(object):
def
init
(self, server, key, blockNum=1):
self.bit_size = 1 << 31
self.seeds = [5, 7, 11, 13, 31, 37, 61]
self.server = server
self.key = key
self.blockNum = blockNum
self.hashfunc = []
for seed in self.seeds:
self.hashfunc.append(SimpleHash(self.bit_size, seed))
def isContains(self, str_input): if not str_input: return False ret = True
name = self.key + str(int(str_input[0:2], 16) % self.blockNum)
for f in self.hashfunc:
loc = f.hash(str_input)
ret = ret & self.server.getbit(name, loc)
return ret
def insert(self, str_input): name = self.key + str(int(str_input[0:2], 16) % self.blockNum) for f in self.hashfunc: loc = f.hash(str_input) self.server.setbit(name, loc, 1) ```
-
重写 scrapy-redis 框架中的 dupefilter.py 文件,将 scrapy-redis 的判重由原来的借助 Redis 数据库中的 set 集合改为 BloomFilter 算法实现
-
初始化 RFPDupeFilter 过滤器
def __init__(self, server, key):
self.server = server
self.key = key
self.bf = BloomFilter(server, key, blockNum=1)
* 重写 request_seen 方法,将原操作改为 BloomFilter 操作
def request_seen(self, request):
fp = request_fingerprint(request)
if self.bf.isContains(fp):
return True
else:
self.bf.insert(fp)
return False
应用
通过实现 BloomFilter 算法并在对 scrapy-redis 框架进行改进,使 scrapy-redis 框架支持 BloomFilter 去重。
本系统设计的智能爬虫,均工作在经过改进的 scrapy-redis 框架上,相较于改进之前能够有效减少内存占用,降低对 Redis 数据库资源的消耗。在硬件资源有限,尤其是内存资源短缺的情况下,能够有效提高爬虫运行的稳定性。
加分算法
本系统设计的模糊新闻爬虫适应性较强,能够对大量随机的新闻博客类网站进行内容爬取,而每一个新闻博客类网站的新闻页 URl 格式是存在较大差异的,因此在爬取新闻内容前需要对 URL 进行判断,区分新闻页面与无关页面。
本系统设计设计了一套针对 URL 的加分算法,以此判断一个 URL 是否是正文页面。
原理
算法通过一系列正则表达式判断 URL 的特征,例如判其中是否含有关键字,是否含有日期信息,是否有特殊字段排列顺序,每满足一个特征就对 URL 进行加分,当一个 URL 获得的分数达到设定的分值时(此分值下文中称之为置信分值),就认为此 URL 是一个正文页的 URL。之后运用 Goose 进行提取。
实现
加分算法在原理上相对简单,但为达到系统要求的准确率需要做大量的测试工作,不断修正算法中规则。下面简述开发过程
- 以人工的方式整理大量新闻站点的正文页 URL 规则,以正则表达式的形式写入到 Scrapy 框架的链接发现规则中。并运行爬虫,对这些新闻站点进行增量爬取。 (实际处理了 200 个网站)
- 收集新增的 URL,根据爬取结果验证他们确实是正文页的 URL。(实际收集了 20000 余条正文 URL)
- 分析这些 URL 的特征。编写并优化加分算法。
部分加分代码:
``` # 文章关键词 PAT = ('news', 'article', 'story', 'content', 'xinwen', 'detail', 'view', 'edition', 'essay', '/a/', 'p=', 'id=', 'archives', 'newsshow', '/a-') for i in PAT: if i in url: score += 2 # 类似 news_xxxx_110 a = re.findall(i + r'[- /]?\w*[- /]?\d+', url) if len(a) > 0: score += 2
# 日期,年月
a = re.findall(r'20[01]\d[-/_]?\d\d', url)
if len(a) > 0:
score += 2
``` 4. 利用算法对全部 URL 进行打分,排序获得得分较少的 URL,在对其进行分析,尝试寻找遗漏的特征,并优化加分算法。(最终的算法中包含 12 种特征,置信分值为 3 分) 5. 应用算法进行实际爬取活动,结合人工判断,调整置信分值, 以提高判断的准确性。(最终置信分值定为 3 分)
应用
利用此算法为模糊爬取任务提供 URL 判别服务,能够在 1 秒内判断 20000 个以上的 url。对 200 余个新闻站点进行测试,能够达到与精准爬取近似的运行速度和结果准确率,有效扩展了智能爬虫(mi)的适用范围。
支持向量机
介绍
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
支持向量机(SVM)算法是根据有限的样本信息,在模型的复杂性与学习能力之间寻求最佳折中,以求获得最好的推广能力支持向量机算法的主要优点有:
(1)专门针对有限样本情况,其目标是得到现有信息下的最优解而不仅仅是样本数量趋于无穷大时的最优值。
(2)算法最终转化为一个二次型寻优问题,理论上得到的是全局最优点,解决了在神经网络方法中无法避免的局部极值问题。
(3)支持向量机算法能同时适用于稠密特征矢量与稀疏特征矢量两种情况,而其他一些文本分类算法不能同时满足两种情况。
(4)支持向量机算法能够找出包含重要分类信息的支持向量,是强有力的增量学习和主动学习工具,在文本分类中具有很大的应用潜力。
实现
- 训练与测试数据收集,利用前期测试爬虫爬取到的新闻数据,拿一部分作为训练数据,一部分作为测试数据,将新闻分类为 politics(政治)、business(商业)、health(健康)、entertainment(娱乐)、finance(金融)、technology(教育)、law(法律)、military(军事)、sport(体育),并将其存储为 JSON 文件。
-
数据的预处理
-
预处理是因为获得的原始数据中有大量的标点符号是训练模型不需要的,如果不去除这些标点符号会对生成的训练模型造成影响,而且获得的原始数据是字符串的类型,需要对其进行分词处理,将连续的句子处理成一个个单独的单词。
-
预处理过程,对获得的数据类型是字符串,对字符串进行利用 jieba 进行分词处理,然后对通过 jieba 处理的字符串进行逐单词的扫描,如果扫描到的单词是标点符号,则舍弃,如果是英文或中文单词,则保留经过预处理的数据便是没有标点符号并且是一个个单独的单词,将最终得到的数据按类型存储为 JSON 格式
-
构建训练模型,支持向量机算法是处理文本分类中较为优秀的一种方法,并且线性向量机更适合处理文本分类。
-
首先按照类别读取上一步预处理的 JSON 数据。
- 利用 sklearn.feature_extraction.text 的 TfidfVectorizer 对读取的数据创建 TD-IDF 的词频矩阵。
- 计算词频矩阵的权重。
- 完成特征提取。
-
利用支持向量机的方法,调用 sklearn.svm 的 LinearSVC 对之前通过计算权重的得到的数据进行训练,并保存训练模型,生成 pkl 文件。
-
测试,获得 JSON 类型的测试数据,将其转换为词频矩阵,调用上一步构建出的训练模型 pkl 文件对其进行分类。
应用
利用训练结果,能够快速的根据新闻正文将新闻归类为如下类别中的一类。
- politics(政治)
- business(商业)
- health(健康)
- entertainment(娱乐)
- finance(金融)
- technology(教育)
- law(法律)
- military(军事)
- sport(体育)
将此功能整合到 mi_manager 的 monitor 模块中,为前端即时爬取功能提供新闻分类服务。
参考文献
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
- 基于P2P的被动式网络爬虫系统(哈尔滨工业大学·马天明)
- 基于网络爬虫的排行榜系统设计与实现(北京邮电大学·刘全伟)
- 基于WEB的爬虫系统的设计与实现(西安电子科技大学·卢哲辉)
- 基于标记模板的分布式网络爬虫系统的设计与实现(华中科技大学·杨林)
- 基于WEB信息采集的分布式网络爬虫搜索引擎的研究(吉林大学·李春生)
- 一个分布式动态网页爬虫系统设计与实现(华中科技大学·胡文涛)
- 一种面向主题的分布式爬虫系统的研究与实现(东北大学·高景生)
- 基于redis的分布式自动化爬虫的设计与实现(华中科技大学·曾胜)
- 分布式在线旅游搜索爬虫系统设计与实现(北京邮电大学·徐显炼)
- 分布式在线旅游搜索爬虫系统设计与实现(北京邮电大学·徐显炼)
- 分布式在线旅游搜索爬虫系统设计与实现(北京邮电大学·徐显炼)
- 基于微服务架构的通用爬虫系统的设计与实现(北京交通大学·杨红光)
- 基于Docker集群的分布式爬虫系统设计与实现(哈尔滨工业大学·闵江松)
- 基于网络爬虫的计量数据分析系统开发(吉林大学·邹思宇)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码海岸 ,原文地址:https://m.bishedaima.com/yuanma/35907.html