
爬虫
设计文档
环境与版本
- python 版本:3.8.5
- Django 版本:3.0.3
- 网站已在 Safari、Opera、Chrome 浏览器中测试兼容
爬虫
爬虫以豆瓣电影为源网站爬取影视、演员和影评数据,共爬到 1066 部影视、5327 条影评以及 6596 位相关演员。
数据与存储
对于每部影视,从豆瓣网中爬取了影视标题、海报图片、影视简介、演员列表、5 条短评以及包括语言、发行时间等在内的其他信息。爬取下来的文字图片分别以 JSON 和 jpg 的格式保存在文件夹中。文件标题为影视的题目。以下文件为例,title、actors、brief、other、comment 分别储存了影视的标题、爬取的相关演员、影视简介、其他信息以及 5 条评论。
json
{
"title": "2001太空漫游 2001: A Space Odyssey",
"actors": [
"凯尔·杜拉",
"加里·洛克伍德",
"威廉姆·西尔维斯特",
"丹尼尔·里希特",
"雷纳德·洛塞特",
"罗伯特·比提",
"肖恩·沙利文",
"艾德·毕肖普",
"格伦·贝克",
"艾伦·吉福德"
],
"brief": "\n 这部影片是库布里克花了四年时间制作的充满哲学命题的鸿篇巨制。一块大黑石树立在史前人类的面前,他们刚刚开始认识工具,进入到进化的里程碑。同样的黑石还在宇宙多处出现,它们矗立在月球上,漂浮在太空中,带着某种神秘的寓意。\n \n 现在的时间是2001年,为了寻找黑石的根源,人类开展一项木星登陆计划。飞船上有冬眠的三名宇航员,大卫船长(凯尔·杜拉 Keir Dullea饰)、富兰克飞行员(加里·洛克伍德 Gary Lockwood饰),还有一部叫“HAL9000”的高智能电脑。HAL在宇宙飞行过程中发生错乱,令到富兰克和三名冬眠人员相继丧命,剩下波曼和这台电脑作战。\n \n 从死亡线上回来的大卫一气之下关掉主脑系统,HAL彻底失效。现在,茫茫宇宙中只剩大卫一人,向木星进发。穿越瑰异壮观的星门,大卫仿佛去到一个奇特的时空,那里有人类无尽的生死轮回和宇宙的终极知识……\n ",
"other": "\n导演: 斯坦利·库布里克\n编剧: 亚瑟·克拉克 / 斯坦利·库布里克\n主演: 凯尔·杜拉 / 加里·洛克伍德 / 威廉姆·西尔维斯特 / 丹尼尔·里希特 / 雷纳德·洛塞特 / 罗伯特·比提 / 肖恩·沙利文 / 艾德·毕肖普 / 格伦·贝克 / 艾伦·吉福德 / 安·吉利斯\n类型: 科幻 / 惊悚 / 冒险\n制片国家/地区: 英国 / 美国\n语言: 英语 / 俄语\n上映日期: 1968-04-02(华盛顿首映) / 1968-05-12(英国)\n片长: 149分钟\n又名: 2001:星际漫游 / 2001:太空奥德赛\nIMDb链接: tt0062622\n",
"comment": [
"原作作者克拉克:“如果有人觉得完全弄懂了《太空漫游2001》在讲些什么,那一定是我和库布里克弄错了。”",
"这不是照着剧本拍的,而是曲谱",
"现在这个年代没人敢如此玩观众了。\r\n",
"牺牲了部分叙事节奏,但构筑起来的完整世界让人目瞪口呆。我觉得我要暴走了:这怎么可能是1968年的电影!!!这怎么可能是1968年的电影!!!它反科学反伦理啊!!!",
"史上最伟大的装逼片,就连作者克拉克和导演斯坦利都看不懂剧情……不过这丝毫不影响它的伟大,首先在视觉上它领先了同一时代数十年不止,很多星际旅行片都没有给我一种“星际旅行”的感觉,但这部有,关键就在于细节处理细致。还有就是,这部讲述星际旅行的片子拍摄于1968年,而美国登月则在1969"
]
}
从每部电影中选取演员表的前 10 位演员进行爬取,获取演员的姓名、简介及其他信息,并下载页面中的图片,文件名均为演员的姓名。文字信息储存方式如下文件
json
{
"name": "新垣结衣 Yui Aragaki",
"info": "\n\n\n性别: \n 女\n \n\n星座: \n 双子座\n \n\n出生日期: \n 1988-06-11\n \n\n出生地: \n 日本,冲绳县,那霸市\n \n\n职业: \n 演员 / 配音\n \n\n更多外文名: \n 新垣結衣 / あらがき ゆい / ガッキー / Aragaki-Yui (本名) / Yuibo (昵称) / Yui (昵称) / Gakki(昵称) / Gakky (昵称)\n \n\nimdb编号: \n nm2201753\n\n\n官方网站: \n https://www.lespros.co.jp/artists/yui-aragaki/\n\n\n",
"brief": " 新垣结衣(1988年6月11日-)是出身于日本冲绳县那霸市的演员、歌手及模特儿,官方身高168厘米,现为日本LesPros Entertainment旗下的艺人。2001年代替姊姊参加当时《Nicola》举办的模特儿比赛,获得最优秀奖。作为杂志模特儿,主要为少年杂志拍摄平面照片。2005年因在电视剧《龙樱》中的演出开始受到关注。2006年出版第一本写真集《水漾青春》。2007年毕业于日出高等学校后专注于演艺圈发展。同年出演电视剧《父女七日变》,发表个人首张音乐专辑《天空》,并参与专辑封面设计与作词。2008年因主演电影《恋空》接连获得电影新人奖。新垣结衣是家中三姊妹中最小的一个,小时候是个很害羞的女孩,到现在还很怕生。中学时参加了一个月的羽毛球俱乐部。虽然是冲绳人,但还是很怕热,腿长80cm。她对自己的称呼一直换,最常用“WATASHI”,但是日记里她喜欢用“BOKU”、“YUIBO”、“YUI”、“ARAGAKI”、“GAKKI”等等(在冲绳和她同龄的人很少用“WATASHI”)。她的昵称“GAKKI”成为“nicomo”后榎本亜弥子给她取的,中学同学叫她 “YUIBO”。很敬佩身边沉着冷静的人,还说自己2006年的目标就是“在心理上长大5岁”。兴趣是卡拉OK,是DA PUMP的FAN。很喜欢漫画,也擅长画画,最擅长的料理是冲绳特色料理“苦瓜炒什锦”,在和小出的约会中就做了这道菜。很喜欢吃冰淇淋,甚至冬天也吃。酷爱牛奶,以至于在吃披萨和拉面的时候都要喝。很讨厌打针,有惧高症,不喜欢灵异鬼怪类的故事。演了很多辣妹角色。在她还是nicomo的时候就有很多FANS喜欢她了,早安少女的新垣里沙和她同年生,但是名字的读法不一样。石田未来和她也是同年生,两人同一个事务所,搬到东京后还一起住。和佐津川爱美,就是辣妹里演SHIZUKA的女生,读同一所学校。在初中的时候,参加了羽毛球队。运动细胞不好,朋友形容她“没办法把手抬到肩膀以上”。"
}
爬虫性能
爬虫主要使用 requests 与 BeautifulSoup 来发送请求并解析网页。在获得网页后,通过 BeautifulSoup 定位至需要的信息并记录,最终生成.json 文件;
同时,为了解决网站反爬问题,爬虫中采用了设置 Headers、采用 API 调用 IP 代理池、设置 cookie 等多种方法来绕过反爬机制;
爬虫选取了豆瓣中
https://movie.douban.com/j/search_subjects?type=movie&tag=欧美&sort=recommend&page_limit=500&page_start=0
网页中的电影,并同时对包括华语、豆瓣高分、日本等不同 tag 下的电影进行了爬取;
由于不同电影的所需的爬取量、网速快慢等等因素,爬虫的运行速率(部/秒)无法准确确定,最终估算在 350-400 分钟左右可以爬取完所有的数据
网站
网站采用 Django 架构
数据库模型
网站为演员、影视以及影评分别建立了模型:
```python class Actor(models.Model): name = models.CharField(max_length=20) brief = models.CharField(max_length=150) info = models.CharField(max_length=150) collaborate = models.ManyToManyField(to='self')
def __str__(self):
return self.name
```
在演员类中,定义了名字、简介、其他信息三个字符串类,和到自身的多对多关系,用以储存不同演员间的合作。
```python class Movie(models.Model): title = models.CharField(max_length=20) brief = models.CharField(max_length=150) other_info = models.CharField(max_length=100) actors = models.ManyToManyField(Actor)
def __str__(self):
return self.title
```
在电影类中,同样定义了名字、简介、其他信息,并同时定义了电影到演员的多对多关系,来代表这个电影在系统中收录的演员表;同时通过反向查询
actor.moive_set
也可以获得代表演员参演的电影。
```python class Comment(models.Model): content = models.CharField(max_length=100) movie = models.ForeignKey(Movie, on_delete=models.CASCADE)
def __str__(self):
return self.content
```
在评论类中,定义了内容的字符串类和到电影的多对一关系,用以代表此评论是哪一个电影的;同时反向查询可以获得某个电影的所有影评
搜索与导航栏
网站的搜索功能通过在每个界面导航栏中的搜索框、搜索按钮和选择框实现。当搜索框中填写了字符后,将在选择的对应领域中进行搜索;如果是空的话,将跳转到对应的列表页面(影评的话将在结果页)。
在导航栏的最左边有一个图标,也可以点击,将会转到主页(影视列表页)
列表页面
列表页面包括影视列表以及演员列表,其中影视列表是主页。
网页展示
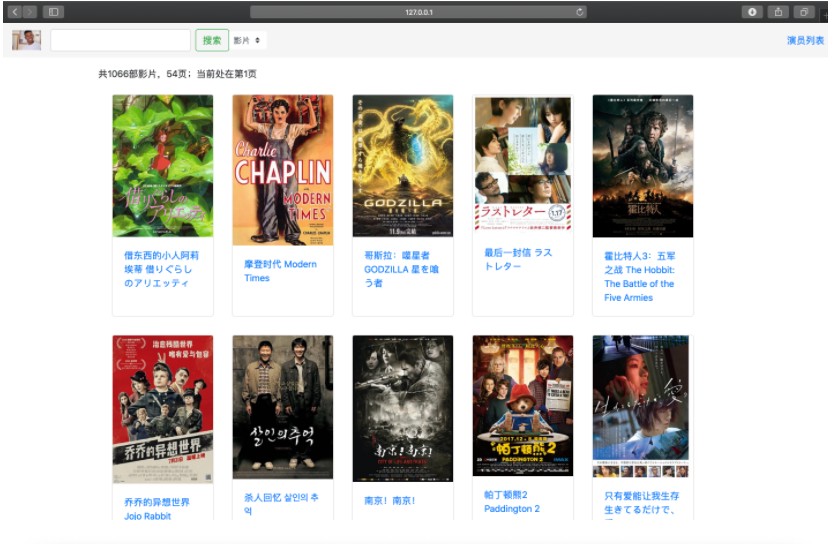
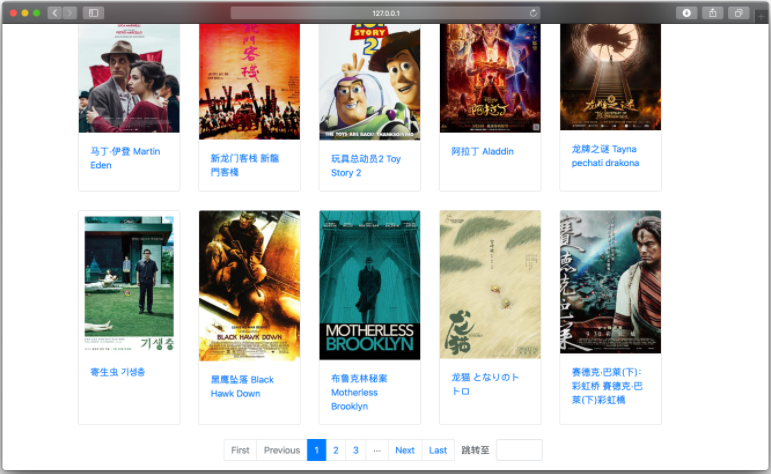
 两种列表以卡片形式展现了所有的影视和演员,并以每页 20 页实现了分页。同时在导航栏最右侧增加按钮,支持影视列表和演员列表之间的切换。
两种列表以卡片形式展现了所有的影视和演员,并以每页 20 页实现了分页。同时在导航栏最右侧增加按钮,支持影视列表和演员列表之间的切换。
分页的实现利用了 django.core 中的 paginator 以及前端的链接等方法实现。卡片的外观通过 CSS 中的 card 类实现。
python
movieList = list(Movie.objects.all())
# 进行分页
pages = Paginator(movieList, 20)
current_page = int(request.GET.get('page', default=1))
display_list = pages.get_page(current_page)
if current_page > pages.num_pages:
current_page = pages.num_pages
# get page range,获得分页栏中展示的数字,其他的用省略号省略
page_range = range(max(1, current_page - 2), min(pages.num_pages, current_page + 2) + 1)
path_dict = dict()
base = '../static/pic/'
return render(request, 'main.html', {
'display_list': display_list,
'current_page': current_page,
'total': pages.num_pages,
'movie_total': len(movieList),
'end': pages.num_pages - 3,
'page_range': page_range,
})
两个界面的 view 函数分别为 views.py 中的 main_view 和 actor_lists,对应的 HTML 文件分别为 main.html 和 actorlist.html;影视列表的网址为主网站,演员列表的网址为
/actors
影视信息
每个影片都具有自己的详情页,详情页展示了影视的信息,包括海报、基本信息、简介、演员表以及影评等。演员表以卡片的形式展示,可以通过点击名字/图片跳转到该演员的详情页;影评以单独设计的形式展示。
影视页对应的网址为
movie/<int:movie_id>
,影视对应的 id 为其在数据库中的序号。网站通过序号获得对应的数据,传递到前端文件进行展示。对应的 views 函数为
movie_detail
,HTML 文件为 moviewdetail.html
网页展示
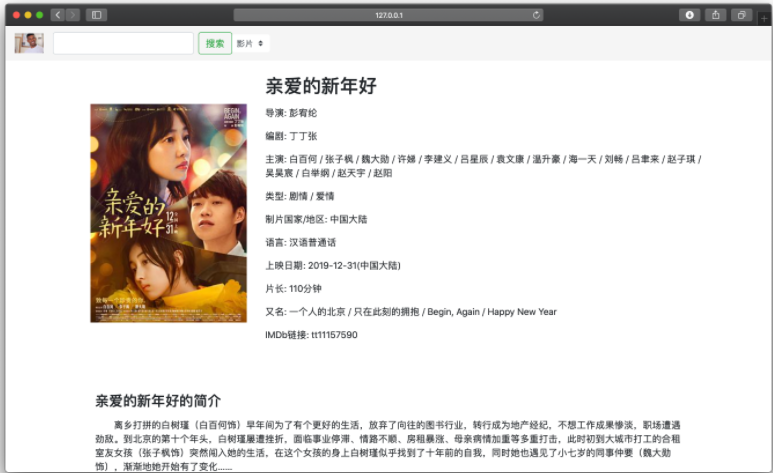
海报、标题、其他信息与简介
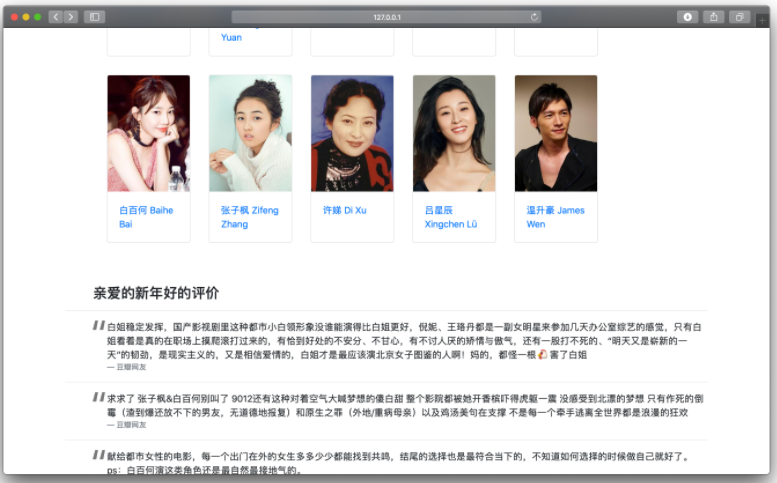
演员表与影评,可以通过点击演员进入演员详情页
演员信息
每位演员都具有自己的详情页,详情页展示了演员的海报、基本信息、简介、参演电影以及合作演员等。参演电影、合作演员均以卡片的形式展示,可以通过点击名字/图片跳转到该电影/演员的详情页。合作演员选取了 10 个与当前演员合作次数最多的演员,并标注了合作的次数。
影视页对应的网址为
movie/<int:actor_id>
,对应的 id 为其在数据库中的序号。网站通过序号获得对应的数据,传递到前端文件进行展示。对应的 views 函数为
actor_detail
,HTML 源文件为 actordetail.html。
网页展示

照片、姓名、简介
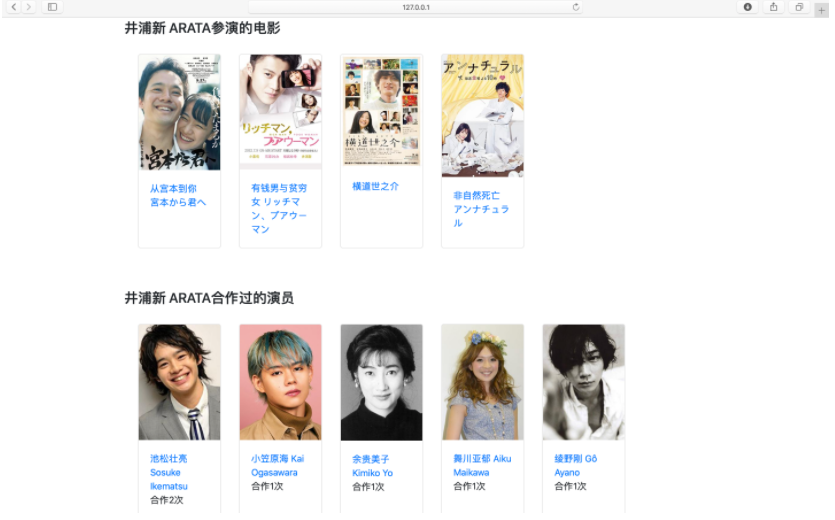
参演电影与合作演员
合作演员的计算方法:首先通过演员反向查询到演员参与的影视列表,再从参演的影视列表中获得所有与该演员合作过的演员;再通过求两个演员参演电影交集的个数来判断他们合作的次数,从而得到与该演员合作次数最多的十个演员。
源代码:
python
def getActorsCollaboration(actor):
movie_set = set(actor.movie_set.all())
actor_all = set()
for movie in movie_set:
actors = set(movie.actors.all())
for actor in actors:
actor_all.add(actor)
dic = dict()
for other_actor in actor_all:
if other_actor != actor:
dic[other_actor] = getCommon(actor, other_actor)
dic = sorted(dic.items(), key=lambda d: d[1], reverse=True)
return dic[0:10]
搜索结果页面
搜索功能可根据单选框,分别在影视、演员、影评中搜索相关的信息;同时在搜索结果页面支持记录上次的搜索关键字和搜索类型。
搜索结果页面对应的 views 函数为
search
,对应 HTML 文件为 results.html,对应的 url 为
/search
。
网页展示
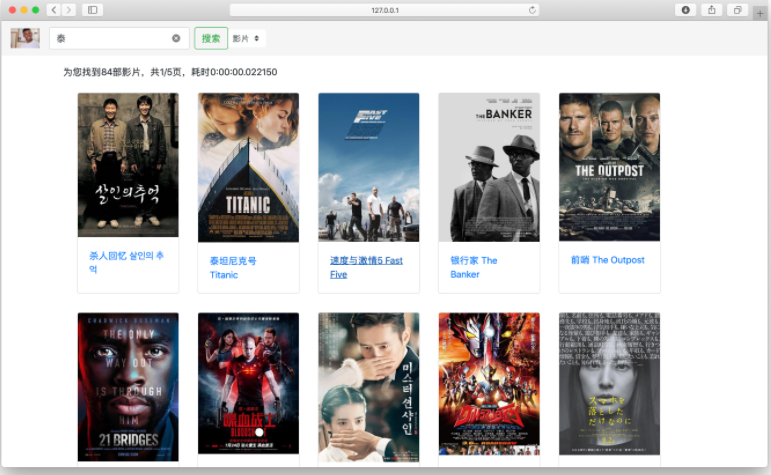
通过查询影片名字可以查询到泰坦尼克号
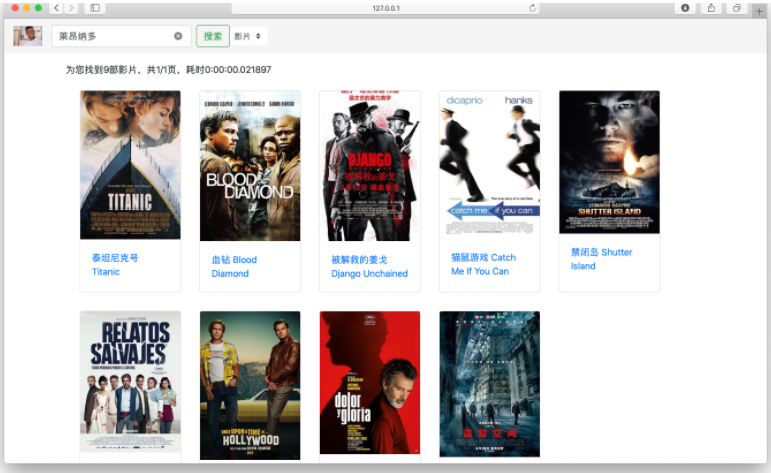
通过查询演员名字也可以查询到泰坦尼克号;电影搜索支持影片名搜索和演员搜索;
演员搜索与影视搜索类似。
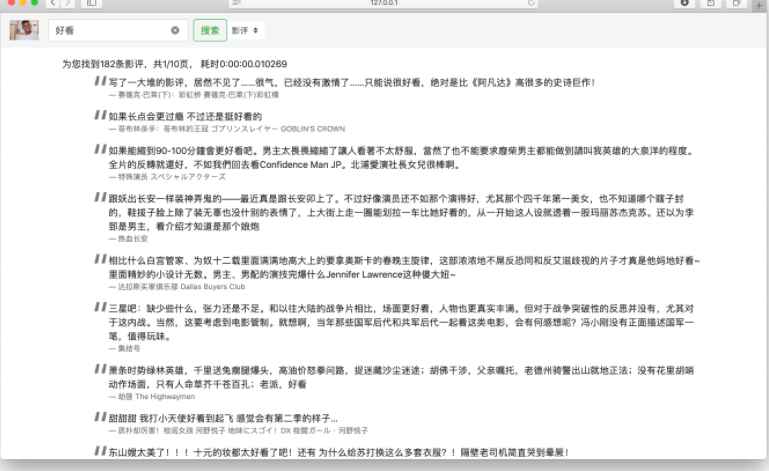
影评搜索结果页,可以点击影视下方的来源跳转到相应电影的详情页。
搜索功能的实现
搜索的参数传递和类型选择通过 GET 类型向
search
发送请求,包括三个参数:keyword 关键词、type 查询类型和 pages 页数,默认为 1。
在通过 request.GET 获得参数后,搜索功能实现的主要方法是数据库中的 filter 方法,从数据库中获得包含关键词的演员、影视或影评,再通过 HTML 展示。
搜索部分源码
python
if typeSelected == 'movies':
if keyword == '':
return HttpResponseRedirect(reverse('home'))
query = Q(title__contains=keyword) | Q(actors__name__contains=keyword)
movie_list = Movie.objects.filter(query).all().distinct()
result = list(movie_list)
elif typeSelected == 'actors':
if keyword == '':
return HttpResponseRedirect(reverse('actors'))
query = Q(name__contains=keyword) | Q(movie__title__contains=keyword)
actor_list = Actor.objects.filter(query).all().distinct()
result = list(actor_list)
else:
comments = list(Comment.objects.filter(content__contains=keyword).all())
result = comments
查询的时间大约在 20ms 左右,主要为将惰性的查询集 QuerySet 转化为 list 所需的时间。
数据导入
在通过爬虫获取数据后,需要将数据导入 Django 的数据库中。为实现这一功能,编写了 initialize.py 文件,用以读取全部 JSON 数据。首先读取 actor 的 JSON 并保存;然后再读取所有的 movie 及其评论,并根据其演员表将影视与演员关联。在导入所有影视后,在开始统计不同演员之间的合作关系,并建立演员到演员自己的
ManyToManyField
,实现合作关系的统计
```python import json, os, sys from engine.models import Actor, Movie, Comment
dirMovies = 'src/movies/json' dirActor = 'src/actors/json' dirTry = 'src/trial/json'
def main(): actors() movie() finishActors() pass
读入演员并保存
def actors(): files = os.listdir(dirActor) for file in files: path = os.path.join(dirActor, file) f = open(path).read() dic = json.loads(f) a = Actor(name=dic['name'], brief=dic['brief'], info=dic['info']) a.save()
读入电影并保存
def movie(): files = os.listdir(dirMovies) for file in files: path = os.path.join(dirMovies, file) f = open(path).read() dic = json.loads(f) q = Movie(title=dic['title'], brief=dic['brief'], other_info=dic['other']) q.save() for actor_name in dic['actors']:#根据演员表建立电影到演员的关系 actor = Actor.objects.filter(name__contains=actor_name) if list(actor). len (): q.actors.add(list(actor)[0]) for comment in dic['comment']:#读取每个电影的评论 c = Comment(content=str(comment), movie=q) c.save()
获取一个演员的合作对象
def getActorsCollaboration(actor): movie_set = set(actor.movie_set.all()) actor_all = set() for movie in movie_set: actors = set(movie.actors.all()) for actor in actors: actor_all.add(actor) dic = dict() for other_actor in actor_all: if other_actor != actor: dic[other_actor] = getCommon(actor, other_actor) dic = sorted(dic.items(), key=lambda d: d[1], reverse=True) return dic[0:10]
根据演员的合作对象建立Actor之间的关系
def finishActors(): for actor in Actor.objects.all(): tmp = getActorsCollaboration(actor) count = 0 for other_actor in tmp: if count == 10: continue if other_actor[0].name != actor.name: count += 1 actor.collaborate.add(other_actor[0])
统计两个演员合作的次数
def getCommon(actor1, actor2): mov_set1 = set(actor1.movie_set.all()) mov_set2 = set(actor2.movie_set.all()) return len(mov_set1 & mov_set2)
```
参考文献
- 恶意URL检测项目中基于PageRank算法的网络爬虫的设计和实现(北京邮电大学·王晓梅)
- 主题搜索引擎搜索策略的研究及算法设计(兰州大学·高庆芳)
- 基于增量反馈和自适应机制的主题爬虫系统的设计与实现(南京理工大学·王斐)
- 搜索引擎中通用爬虫系统的研究与设计(吉林大学·高龙)
- 基于Hadoop的分布式网络爬虫的设计与研究(成都理工大学·程泽)
- 基于Scrapy技术的数据采集系统的设计与实现(南京邮电大学·杨君)
- 网络爬虫技术在云平台上的研究与实现(电子科技大学·刘小云)
- 支持AJAX的定址网络爬虫系统的研究与实现(北京邮电大学·刘凡凡)
- 搜索引擎中网络爬虫技术研究(西安电子科技大学·郭海燕)
- 主题微博爬虫的设计与实现(中原工学院·王艳阁)
- 基于标记模板的分布式网络爬虫系统的设计与实现(华中科技大学·杨林)
- 面向主题的爬行搜索策略研究与实现(陕西师范大学·王敏翔)
- 主题网络爬虫关键技术研究(哈尔滨工业大学·王桂梅)
- 主题网络爬虫关键技术研究(哈尔滨工业大学·王桂梅)
- 基于Hadoop的分布式网络爬虫的设计与研究(成都理工大学·程泽)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码驿站 ,原文地址:https://m.bishedaima.com/yuanma/35984.html









