开发过程文档-DHT 嗅探器
运行及测试
参数设置:
```python
线程数
THREAD_NUMBER = 3
线程持续时间
SLEEP_TIME2 = 60*10
```
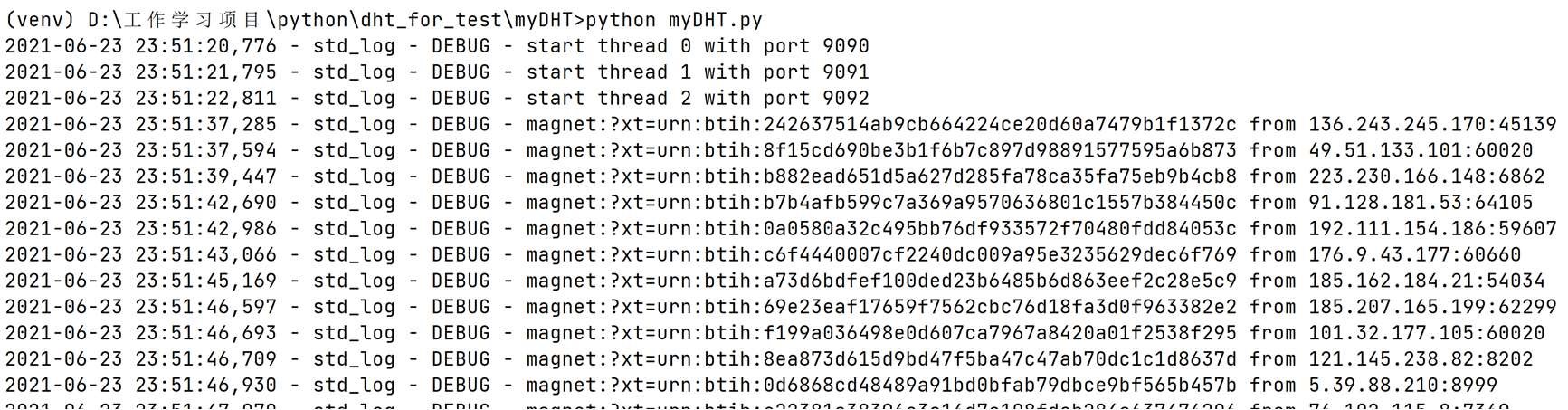
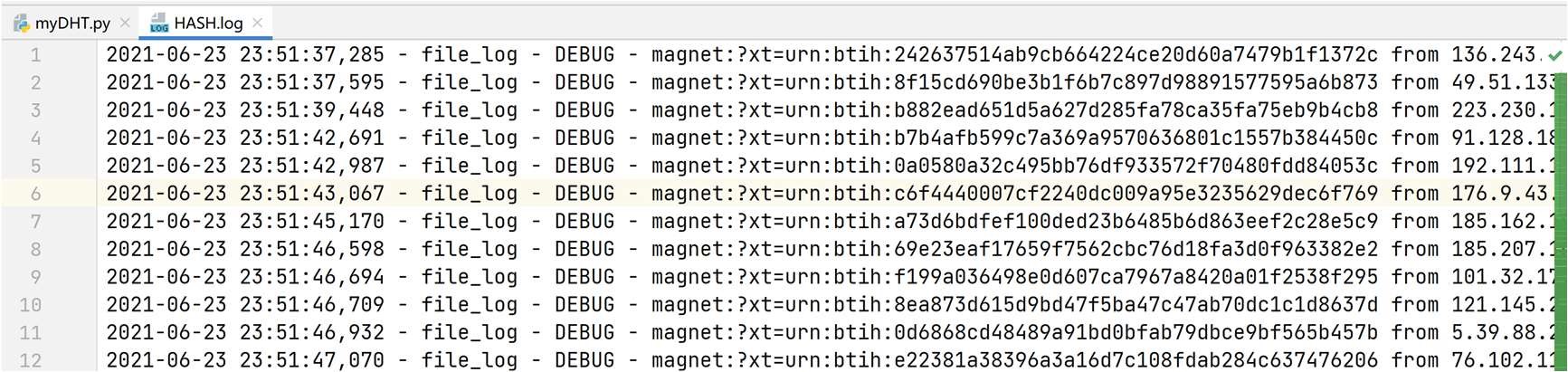
可正常运行,并生成相应 HASH.log 文件。
问题与解决
问题-1:参考的代码为数据库方式保存数据,不论是 MySQL 还是 Redis 等数据库都需要额外配置与安装,不方便。
解决:采用 log 模块,考虑到实际上长期保存 node 并不合适,同时数据库也不便于老师检阅,采用简单方便易管理的 log 更符合需求,具体实现如下:
python
stdger = logging.getLogger("std_log") 2. fileger = logging.getLogger("file_log")
3.
def initialLog():
stdLogLevel = logging.DEBUG
fileLogLevel = logging.DEBUG
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
stdout_handler = logging.StreamHandler()
stdout_handler.setFormatter(formatter)
file_handler = logging.FileHandler("HASH.log")
file_handler.setFormatter(formatter)
logging.getLogger("file_log").setLevel(fileLogLevel)
logging.getLogger("file_log").addHandler(file_handler)
logging.getLogger("std_log").setLevel(stdLogLevel)
logging.getLogger("std_log").addHandler(stdout_handler)
问 题 -2 : Becoding 编 码 的 库 选 取 from bencode import
bencode,bdecode,BTL,报错解决:采用 import bencoder
问题-3:导入 bencoder 库后,bencode 与 bdecode 仍提示报错
解决:导包时要导 pip install bencoder.pyx 下的 bencoder
问题-4:单独定义路由表
``` class KTable(): def init (self): self.nodes = deque(maxlen=MAX_NODE_QSIZE)
```
在 DHT 里引用时报错
解决:将其改为 DHT 里的 self.nodes
问题-5:进程开始后,嗅探一直没有结果,尝试加减线程调整网络环境无果 解决:发现问题在于
中 time.sleep(SLEEP_TIME)处在前文参数设置中为 SLEEP_TIME = 60*10 与后面的线程持续时间重名,遂改为 SLEEP_TIME1 = 1e-5 即 0.00001 秒加以区分。
``` def receive_response_forever(self): self.bootstrap() while self.isWorking: try: data, address = self.udp.recvfrom(UDP_RECV_BUFFSIZE) msg = bencoder.bdecode(data) self.on_message(msg, address) time.sleep(SLEEP_TIME) except Exception: pass
```
问题-6:当线程持续时间 SLEEP_TIME2 = 20,无结果

解决:线程持续时间太短,经尝试 1min 以上可以保证获取 infohash。
问题-7:如何保证速度,是否可以提升速度? 解决:采用了多线程的方式,更快更高效,具体实现如下
``` class DHT(Thread): def init (self, bind_ip, bind_port, process_id, master): Thread. init (self) self.isWorking = True self.sfnf_thread = Thread(target=self.send_find_node_forever) self.rrf_thread = Thread(target=self.receive_response_forever) self.bst_thread = Thread(target=self.bs_timer) self.master = master def start(self): self.sfnf_thread.start() self.rrf_thread.start() self.bst_thread.start() Thread.start(self) return self def stop(self): self.isWorking = False
if name == " main ": initialLog() threads = [] for i in range(THREAD_NUMBER): port = i + SERVER_PORT stdger.debug("start thread %d with port %d" % (i, port)) dht=DHT(SERVER_HOST, port, "thread-%d" % i, Master()) dht.start() threads.append(dht) sleep(1) sleep(SLEEP_TIME2) k = 0 for i in threads: stdger.debug("stop thread %d" % k) i.stop() i.join() k=k+1
```
其他-1:完整的 DHT 实现思路?
答: https://github.com/bmuller/kademlia 是 DHT 完整规范的实现,在诸如 IPFS 协议的 Python 实现 https://github.com/libp2p/py-libp2p 也是采用的 bmuller 的 kademlia。同时针对 DHT 嗅探器来说, https://github.com/wuzhenda/simDHT 是比较完整的实现,它具体包含了 kdht.py/ktable.py/krpc.py,基本实现了 DHT 网络的要素,遗憾的是我并没有完全掌握它也并不能成功复现。其中对 ktable.py 的定义如下,注释由我个人添加
```
整个 DHT 是一个哈希表,它把自己的数据化整为零分散在不同的节点里。KTable 里有 KBucket,KBucket 里有 KNode,每个 KBucket 有 K 个 KNode,在
Bittorrent(Mainline DHT)中 K=8。KTable 可以容纳 2^160 个节点,最多有 2^160/K 个 KBucket
KNode
class KNode(object): def init (self, nid, ip, port): self.nid = nid self.ip = ip self.port = port def eq (self, other): #== return self.nid == other.nid def ne (self, other): #!= return self.nid != other.nid
#KBucket:K 桶可以看作结点的路由表,每个桶包含一部分的 Node ID 空间.空的路由表只有一个桶,它的 Node ID 范围从 min=0 到 max=2^160。当 Node ID 为 N 的节点插 入到表中时,它将被放到 Node ID 范围在 min<=N<max 的 K 桶中.每个桶最多只能保存 K 个节点,K=8。用 KBucket 来保存与当前节点距离在某个范围内的所有节点列表比如 bucket0,bucket1,bucket2...bucketN 分别记录[1, 2), [2, 4), [4, 8), ... [2^i, 2^(i+1))范围内的节点列表。如果初始 KBucket 数量不够,则需要分裂,实现 基于 BEP5 的 DHT 协议。KBucket 会进行自我组织和维护,满了将基于结点活跃性和 ping 去替换不新鲜的结点,以 15min 为 1 周期。 class KBucket(object): def init (self, min, max): self.min = min self.max = max self.nodes = [] #node 列表 self.lastAccessed = time() #最后访问时间,即协议中的 lastchange def append(self, node):#添加 node,参数 node 是 KNode 实例
如果新插入的 node 的 nid 属性长度不等于 20byte,终止
if len(node.nid) != 20: return if node in self:#如果已在该 bucket 里,替换掉 self.remove(node) self.nodes.append(node) else: #不在该 bucket 并且未满,插入 if len(self) < K: self.nodes.append(node) else: #满了,抛出异常,通知上层进行拆表 raise BucketFull
替换/添加 node 都要更改 bucket 最后访问时间,更新新鲜程度
self.touch() def remove(self, node):#删除节点 self.nodes.remove(node) def touch(self):#更新 bucket 最后访问时间 self.lastAccessed = time() def random(self):#随机选择一个 node if len(self.nodes) == 0: return None return self.nodes[randint(0, len(self.nodes) - 1)] def isFresh(self):#bucket 是否新鲜 return (time() - self.lastAccessed) > BUCKET_LIFETIME def inRange(self, target):#目标 node ID 是否在该范围里 return self.min <= intify(target) < self.max def len (self): return len(self.nodes) def contains (self, node): return node in self.nodes def iter (self):#return 返回值,记住位置,下次迭代从此开始 for node in self.nodes: yield node def lt (self, target):#帮助 bisect 有序序列插入,快速定位 bucket 的所在索引 return self.max <= target
K 桶满,要拆表
class BucketFull(Exception): pass
路由表
class KTable(object): def init (self, nid): self.nid = nid #自身 node ID self.buckets = [KBucket(0, 2 ** 160)] #存储 Kbucket 的表,协议规定第一个 bucket 的 min=0max=2^160 def bucketIndex(self, target): #定位指定 node ID 所在的 bucket 的索引 return bisect_left(self.buckets, intify(target)) def touchBucket(self, target):#更新指定 node 所在 bucket 最后访问时间 try: self.buckets[self.bucketIndex(target)].touch() except IndexError: pass def append(self, node):#插入 node if self.nid == node.nid: return #不存储自己
定位待插入的 node 属于哪个 bucket,若所归属的 bucket 满了又都是活跃的结点,需要拆表(拆表即算法中的拆子树)
index = self.bucketIndex(node.nid) try: bucket = self.buckets[index] bucket.append(node) except IndexError: return except BucketFull:
拆表前,先确认自身 node ID 是否也在该 bucket 里,如果不在则终止
if not bucket.inRange(self.nid): return
如果在 bucket 里,把 bucket 拆分成两个 bucket,平分结点
self.splitBucket(index) self.append(node) def findCloseNodes(self, target, n=K):#找出离目标 node ID 最近的 K 个 node nodes = []
定位出目标 node ID 所在的 bucket
if len(self.buckets) == 0: return nodes index = self.bucketIndex(target) try: nodes = self.buckets[index].nodes min = index - 1 max = index + 1 while len(nodes) < n and ((min >= 0) or (max < len(self.buckets))):
如果还能往前走
if min >= 0: nodes.extend(self.buckets[min].nodes) #如果还能往后走 if max < len(self.buckets): nodes.extend(self.buckets[max].nodes) min = min-1 max = max+1 num = intify(target) nodes.sort(lambda a, b, num=num: cmp_to_key(num ^ intify(a.nid), num ^ intify(b.nid)))#按异或值从小到大排序 return nodes[:n] #n=K=8 except IndexError: return nodes #拆桶,桶将被分裂为 2 个新的桶,每个新桶的范围都是原来旧桶的一半,原来旧桶中的节点将被重新分配到这两个新的桶中。如果一个新表只有一个桶,这个包含整个范围的桶 将总被分裂为 2 个新的桶,每个桶的覆盖范围从 0..2^159 和 2^159..2^160。index 是待拆分的 bucket 即旧桶的索引值。假设 old bucket 的 min:0,max:8.拆分该 old bucket,分界点是 4,改 old bucket 的 max=4,min 仍为 0。创建一个新的 bucket,new bucket 的 min=4max=8。根据的 old bucket 中的各个 node 的 nid,判断在哪 个 bucket 的范围里,装到对应 bucket 里。new bucket 的索引值在 old bucket 后面即 index+1,把新的 bucket 插入到路由表。 def splitBucket(self, index): old = self.buckets[index] point = old.max - (old.max - old.min) / 2 #分界点为一半 new = KBucket(point, old.max) old.max = point self.buckets.insert(index + 1, new) #index+1 for node in old.nodes[:]: if new.inRange(node.nid): #在新桶的结点移过去 new.append(node) old.remove(node) def iter (self): for bucket in self.buckets: yield bucket def len (self): length = 0 for bucket in self: length += len(bucket) return length def contains (self, node): try: index = self.bucketIndex(node.nid) return node in self.buckets[index] except IndexError: return False
```
其他-2:在优化上有没有更好的思路?
答:如果说最原始的嗅探器是单线程的,那么多线程与异步可以对其进行优化。异步和多线程两者都可以达到避免调用线程阻塞的目的,从而提高软件的可响应性。在我的作业中我采用了多线程并成功实现了提速,但可惜的是在尝试使用异步时出现了错误,完全仿照他人的代码也无法正常获取 infohash。对于 Python 来说不像 JS 天然带有异步,需要额外的模块辅助,如 asyncio、Twisted、Gevent。在 https://github.com/whtsky/maga 采 用 的 就 是 asyncio , 在
https://github.com/wuzhenda/simDHT 则采用了 twisted。但是,由于 Twisted、
Gevent 实际上是 Python 2 时代的产物,且太重回调太多,基于的协程的 asyncio 在 Python 3.4 被引入到标准库后已经不太适用 Python3 时代了。在我的个人尝试中可能也是由于 Python3 与 Gevent 和 Twisted 不兼容所导致的失败。
其他-3:获取的 infohash 并非是可用的,原因? 答:在说明文档中提到,get_peers 和 announce_peer 请求包含了所需的 infohash 信息,我们也是通过 get_peers 和 announce_peer 来获取 infohash。但是, get_peers 中包含的 infohash 对应的种子可能已经失效或者难连接上,事实上此时对方也是在查找对应 infohash 的种子文件,这里获取的 infohash 质量较差。当收到 announce_peer 消息时,这里携带的 infohash 的质量更高,因为它表示控制该节点的下载者开始下载资源了,当前对方正在指定端口下载该种子文件的 metadata 信息。
其他-4:如何利用 infohash 真正意义上的下载资源?
答:只要找到一个种子的下载者(peer)就可以使用 BEP-9: Extension for Peers to
Send Metadata Files 拓展协议从该下载者(peer)处下载种子元信息(info),同样可以使用元信息(metadata)的 infohash 来验证该信息的真实性,当然也可以从它那下载资源。
参考文献
- 网络新闻语料库建设及其分布式检索系统研究(华中师范大学·鲁松)
- 基于J2EE的网络舆情分析系统的设计与实现(南京大学·李伟)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 面向特定网页的Web爬虫的设计与实现(吉林大学·马慧)
- 主题爬虫关键技术研究(哈尔滨工程大学·黄正德)
- 网络安全中入侵检测系统的设计与实现(大庆石油学院·卢广)
- 移动环境下基于内容的恶意网站分析模型研究与实现(北京邮电大学·张家桦)
- 基于Python的非结构化数据检索系统的设计与实现(南京邮电大学·董海兰)
- 基于聚焦爬虫技术的Web本体采集系统的设计与实现(吉林大学·付欣)
- 互联网舆情监控系统的设计与实现(湖南师范大学·夏岩)
- 金融信息实时发布系统的设计与实现(东北大学·伦健)
- 基于页面分析的网络爬虫系统的设计与实现(华中科技大学·郝以珍)
- 基于爬虫的小企业搜索系统的设计与实现(大连理工大学·范能科)
- 分布式智能网络爬虫的设计与实现(中国科学院大学(工程管理与信息技术学院)·何国正)
- 基于聚焦爬虫技术的Web本体采集系统的设计与实现(吉林大学·付欣)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:毕设项目助手 ,原文地址:https://m.bishedaima.com/yuanma/36106.html