1.作业任务
编程实现 ID3 算法,针对下表数据,生成决策树。
| ID | color | size | act | age | inflated |
|---|---|---|---|---|---|
| 1 | YELLOW | SMALL | STRETCH | ADULT | T |
| 2 | YELLOW | SMALL | STRETCH | CHILD | T |
| 3 | YELLOW | SMALL | DIP | CHILD | F |
| 4 | YELLOW | LARGE | STRETCH | ADULT | T |
| 5 | YELLOW | LARGE | DIP | ADULT | T |
| 6 | YELLOW | LARGE | DIP | CHILD | F |
| 7 | PURPLE | SMALL | STRETCH | CHILD | T |
| 8 | PURPLE | SMALL | DIP | ADULT | T |
| 9 | PURPLE | SMALL | DIP | CHILD | F |
| 10 | PURPLE | LARGE | STRETCH | CHILD | T |
问题提示:可设计数据文件格式,如 color 属性取值 YELLOW:0,PURPLE:1 等,程序从指定数据文件中读取训练集数据。
问题拓展:要求将计算各属性信息增益过程及决策树生成过程演示出来。
2.运行环境
- 编程语言:Python
- 使用第三方库:Numpy,Matplotlib,Scikit-learn
- IDE:PyCharm
- 操作系统:WIndows10
3.算法介绍
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。引用《机器学习》(西瓜书)中的例子:
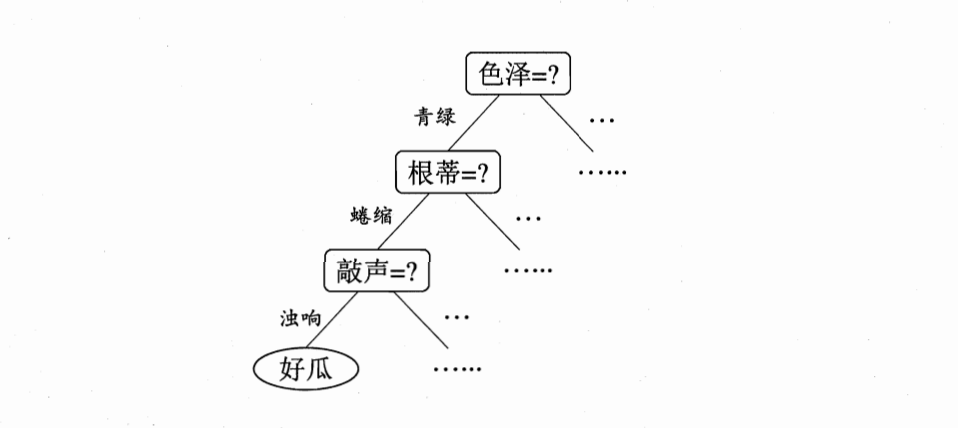
通过属性来逐渐地把西瓜分到对应的类别中去,决策树的学习过程就是在寻找最优决策方案的过程。
基本的算法流程:
- 输入:
``` 训练集 D={(x1,y1),(x2,y2),(x3,y3),(x4,y4), ... , (xm,ym)}
属性集 A={a1,a2,a3,a4, ... , a5} ```
- 过程:
函数TreeGenerate(D, A)
生成节点
if D 中样本全属于同一类别C then
将node标记为C类叶子节点;return
end if
从A中选择最优划分属性a*;
for a* 的每一个a’ do
为node生成一个分支;另Dv表示D中在a*上取值为a’的end样本子集;
if Dv为空 then
将分支结点标记为叶结点,其类别标记为D中样本最多的类;return
else
以TreeGenerate(Dv,A\{a*})为分支结点
end if
end for
- 输出:
以 node 为根结点的一棵决策树
ID3 是决策树算法的一种,它是以信息熵和信息增益作为衡量标准
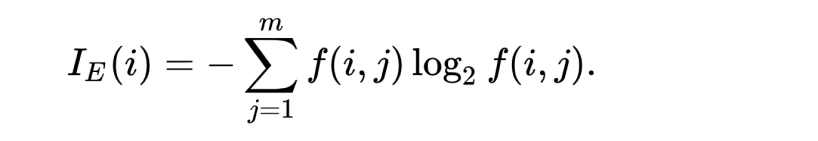
4.程序分析
4.1 制作数据集:
因为 ID 对于实际环境并没有什么参考价值,所以这次作业数据集我将 ID 这个属性去掉
c++
1.fr = open(r'data/text.txt')
2.listWm = [inst.strip().split(',')[1:] for inst in fr.readlines()[1:]]
通过 python 的切片功能,把每一行数据中的 id 去掉(通过 slide[1:]来实现)
数据集截图:
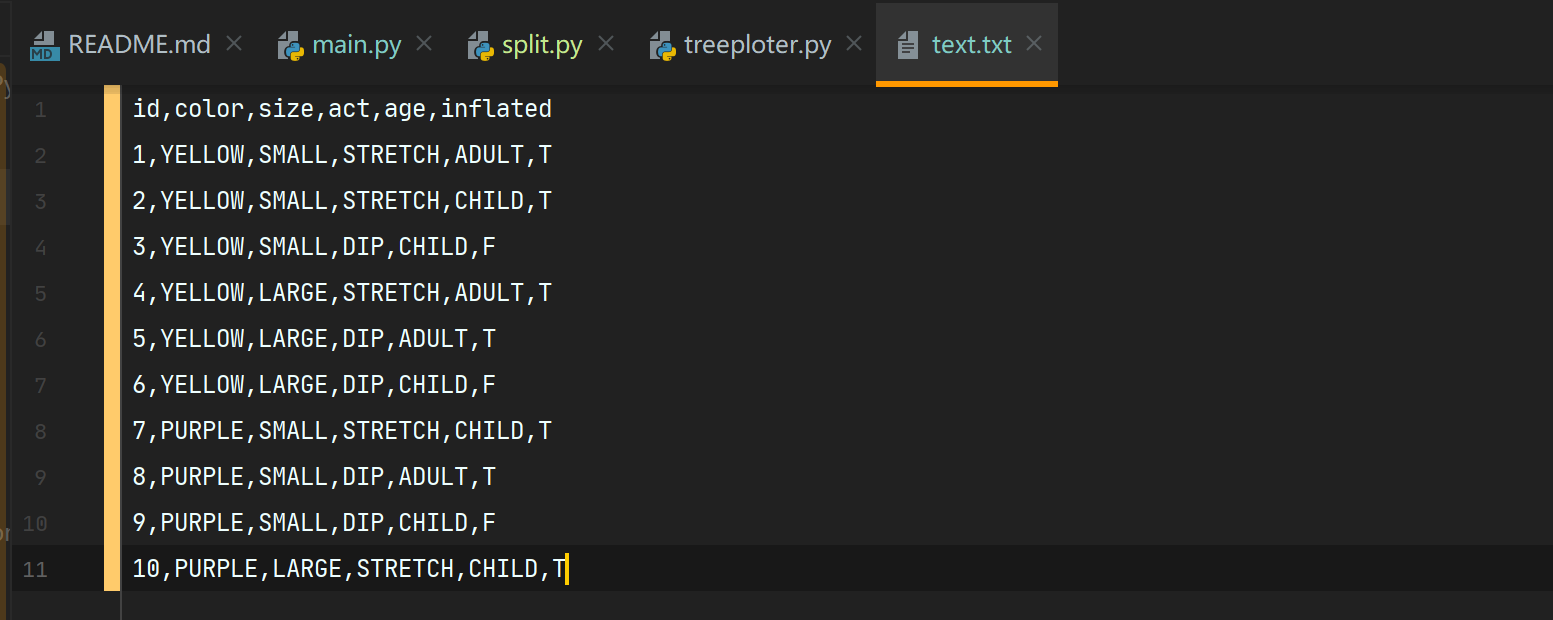
4.2 输出决策树结果
c++
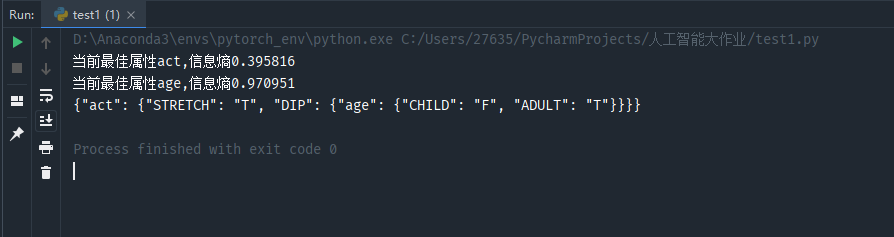
1.print(json.dumps(Trees, ensure_ascii=False))
Json格式 {
"act": {
"DIP": {
"age": {
"CHILD": "F",
"ADULT": "T"
}
},
"STRETCH": "T"
}
}
程序运行过程中得出 act 的决策能力大于 age(因为 act 的信息熵 <age 的信息熵)
1.def createTree(dataSet, labels):
2. classList = [example[-1] for example in dataSet] # 类别向量
3. if classList.count(classList[0]) == len(classList): # 如果只有一个类别,返回
4. return classList[0]
5. if len(dataSet[0]) == 1: # 如果所有特征都被遍历完了,返回出现次数最多的类别
6. return majorityCnt(classList)
7. bestFeat,bestGain = chooseBestFeatureToSplit(dataSet) # 最优划分属性的索引
8. bestFeatLabel = labels[bestFeat] # 最优划分属性的标签
9. print("当前最佳属性%s,信息熵%f" % (bestFeatLabel,bestGain))
10. myTree = {bestFeatLabel: {}}
11. del (labels[bestFeat]) # 已经选择的特征不再参与分类
12. featValues = [example[bestFeat] for example in dataSet]
13. uniqueValue = set(featValues) # 该属性所有可能取值,也就是节点的分支
14. for value in uniqueValue: # 对每个分支,递归构建树
15. subLabels = labels[:]
16. myTree[bestFeatLabel][value] = createTree(
17. splitDataSet(dataSet, bestFeat, value), subLabels)
18. return myTree
根据当前属性计算信息增益的值,并将结果输出出来
4.3 可视化决策树:
1.def plotTree(myTree, parentPt, nodeTxt):
2. numLeafs = getNumLeafs(myTree)
3. depth = getTreeDepth(myTree)
4. firstStr = list(myTree.keys())[0]
5. cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW,
6. plotTree.yOff)
7. plotMidText(cntrPt, parentPt, nodeTxt)
8. plotNode(firstStr, cntrPt, parentPt, decisionNode)
9. secondDict = myTree[firstStr]
10. plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
11. for key in secondDict.keys():
12. if type(secondDict[key]).__name__ == 'dict':
13. plotTree(secondDict[key], cntrPt, str(key))
14. else:
15. plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
16. plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff),
17. cntrPt, leafNode)
18. plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
19. plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
使用第三方库 matplotlib 画图
5.界面截图与分析
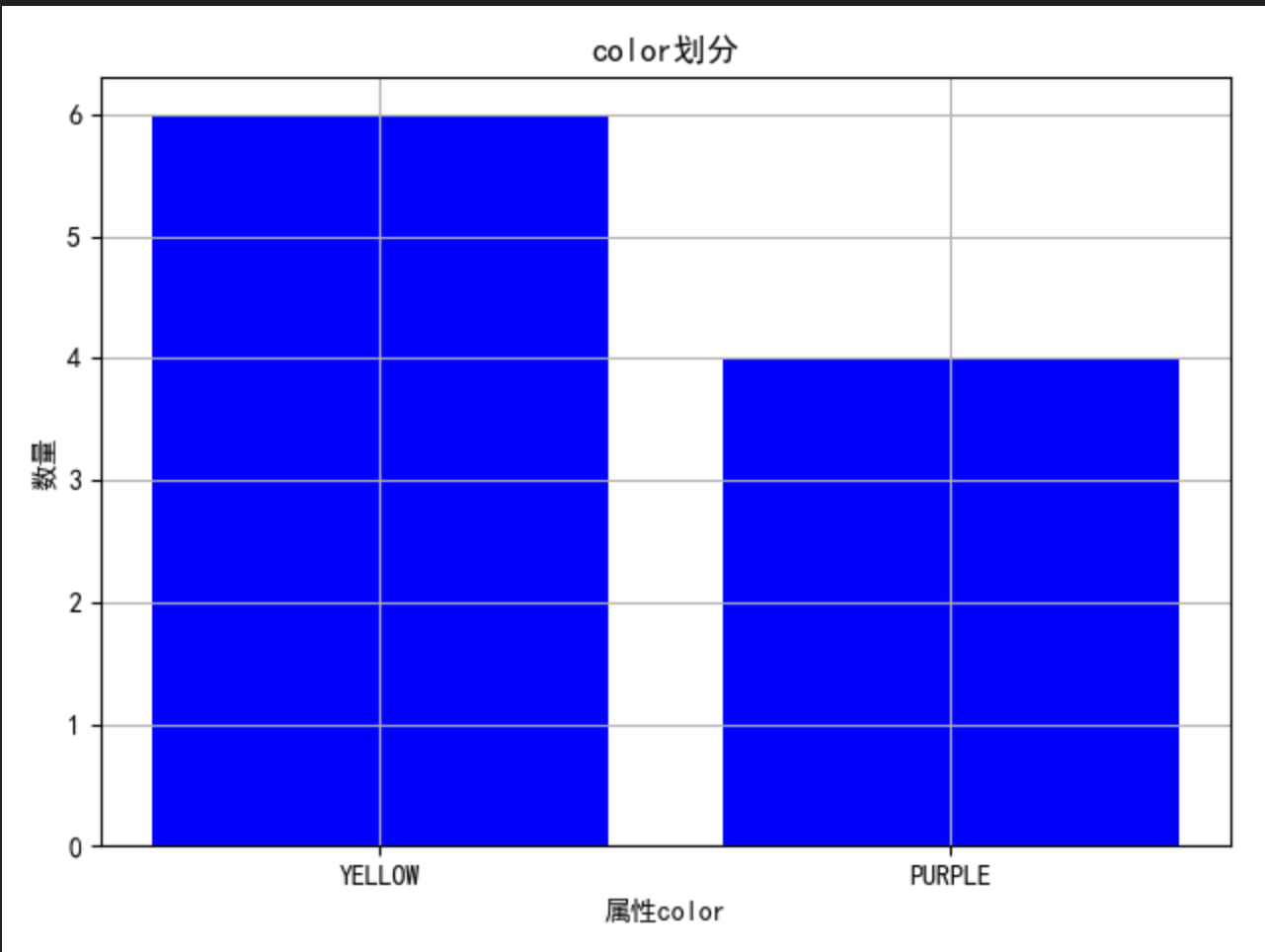
5.1 通过图来大致观察一下不同属性的划分情况:
color:
size:
act:
age:
5.2 查看属性对于结果的划分影响:
color:
此属性出现了四个柱,说明不能完全划分
size:
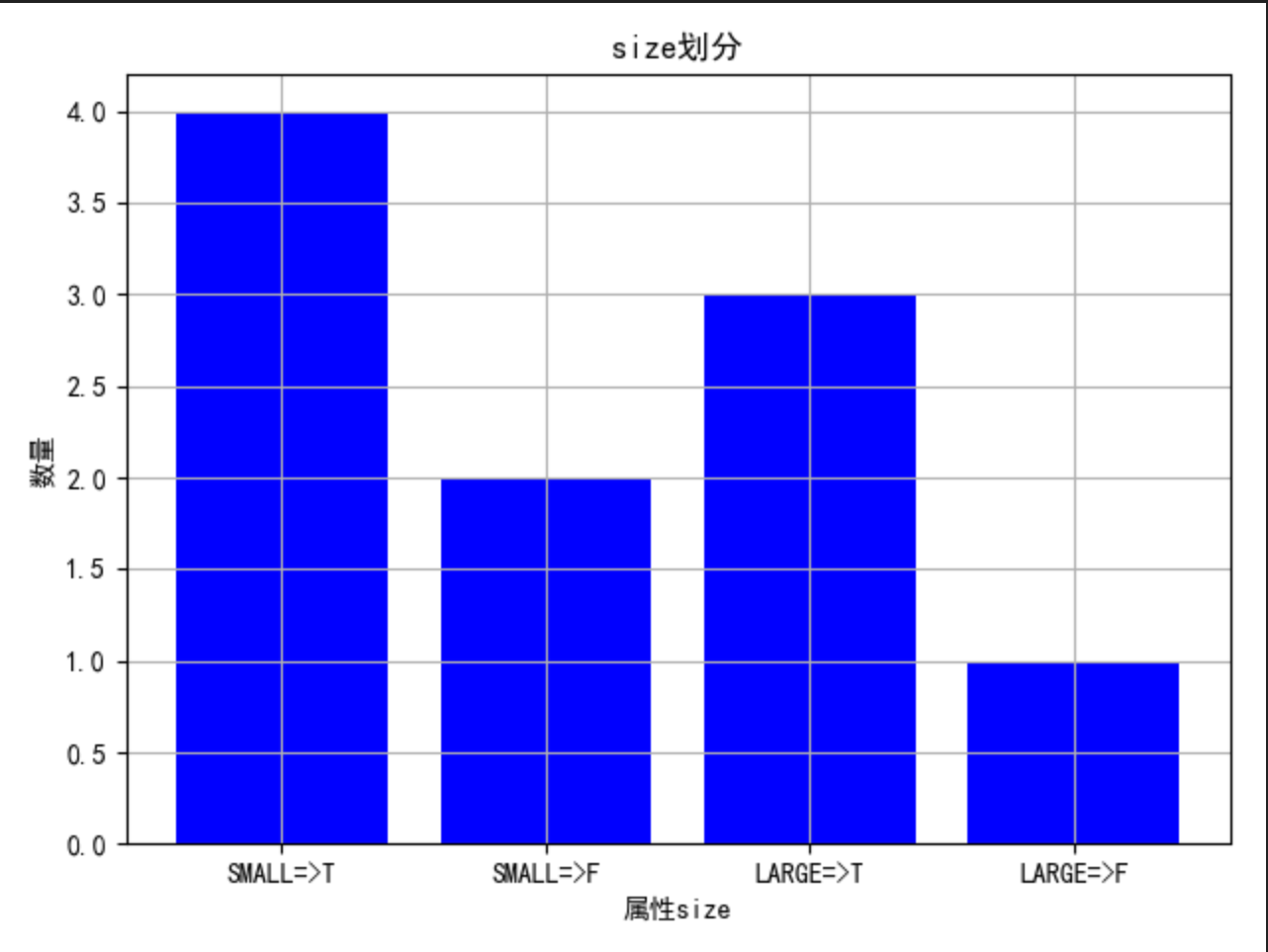
此属性同上,不能完全划分
act:
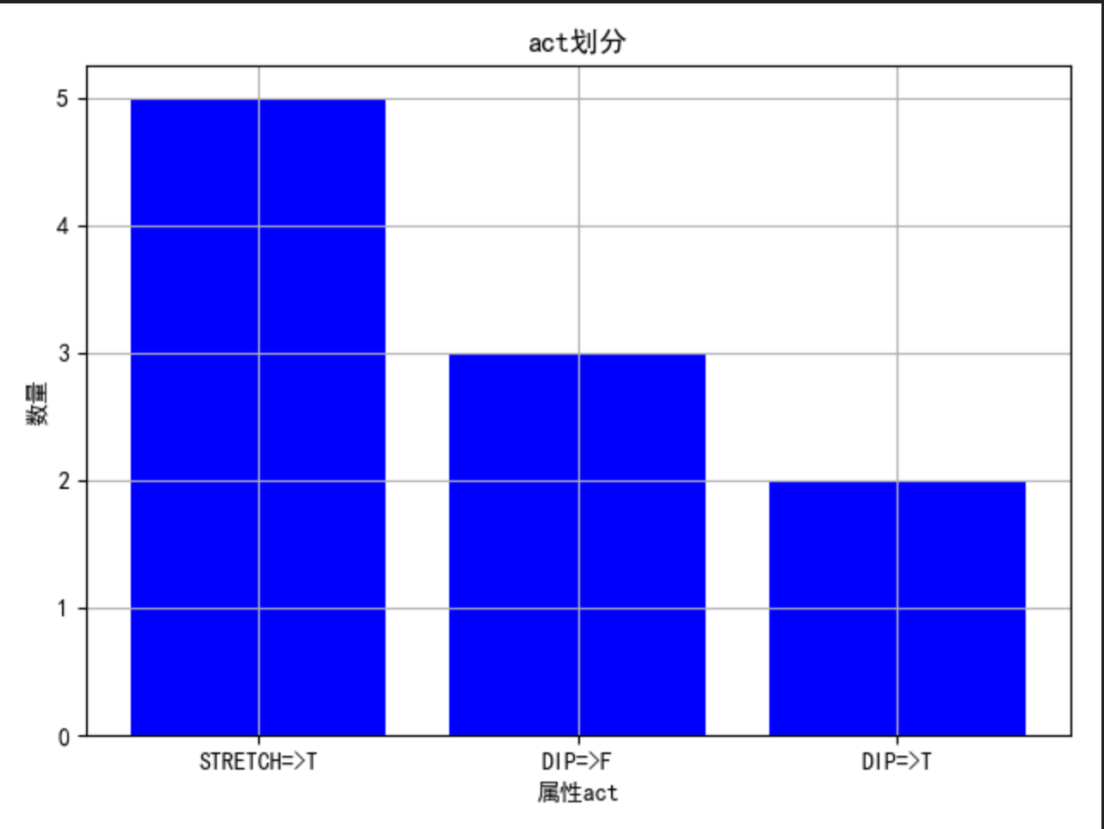
从图中可以看出,STRETCH 全部为 T,说明此属性可以连接叶子节点
age:
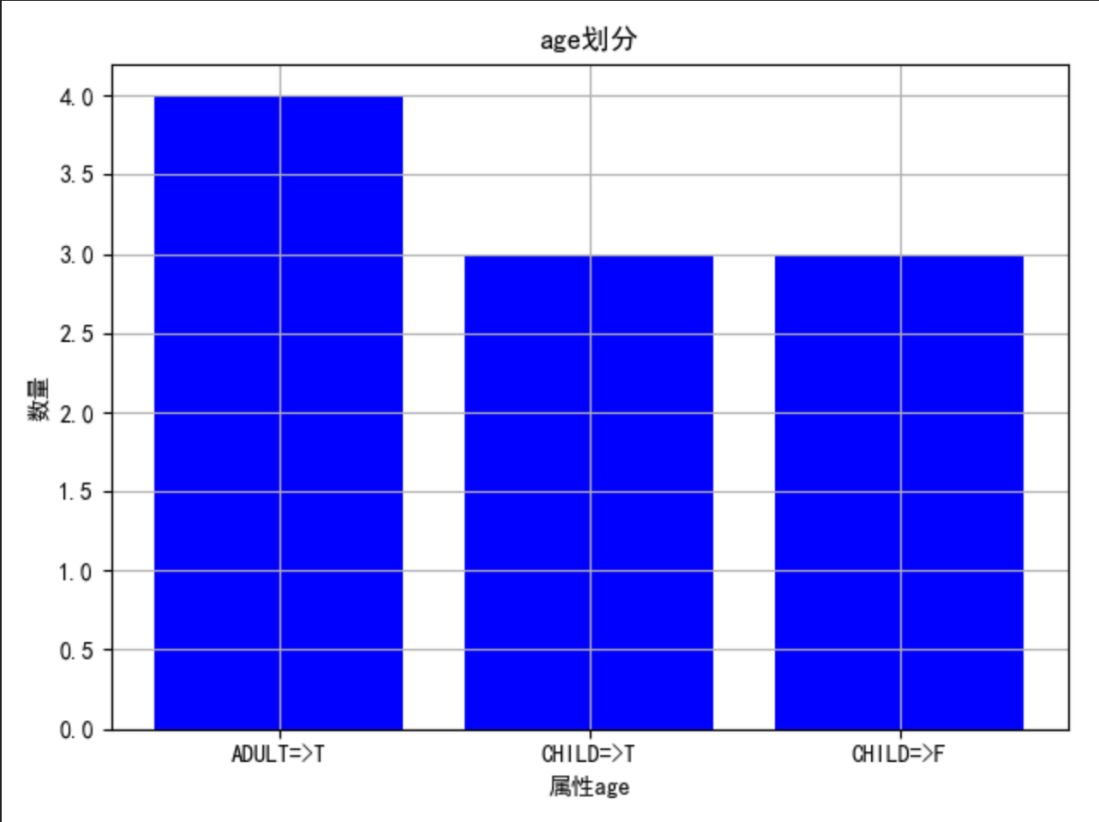
从图中可以看出,ADULT 全部为 T,说明此属性可以连接叶子节点
5.3 程序运行控制台输出结果:
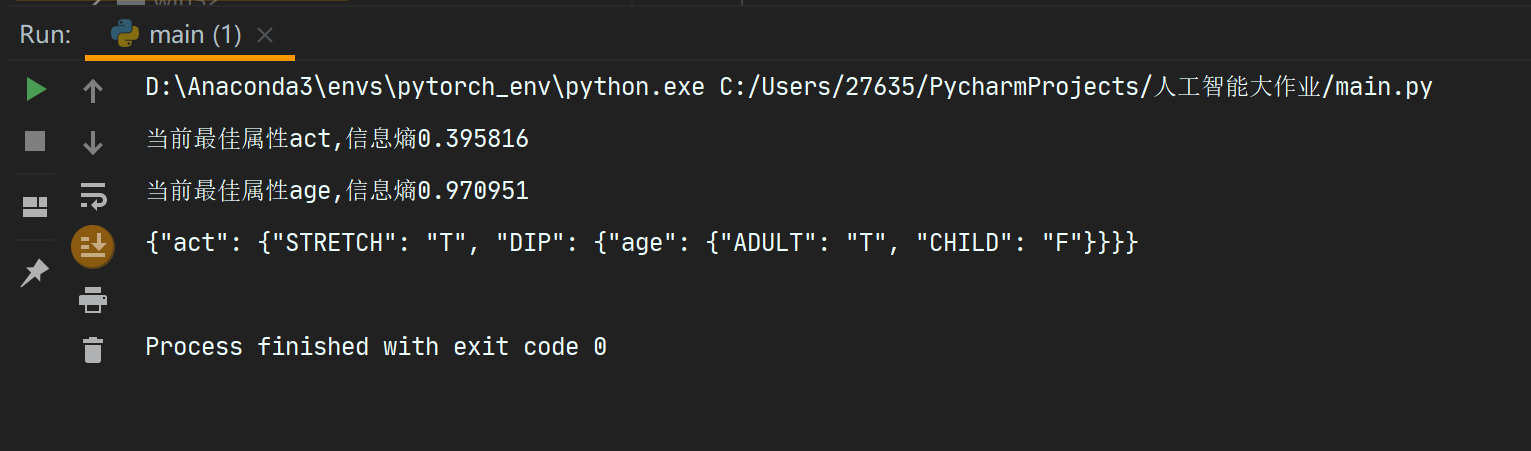
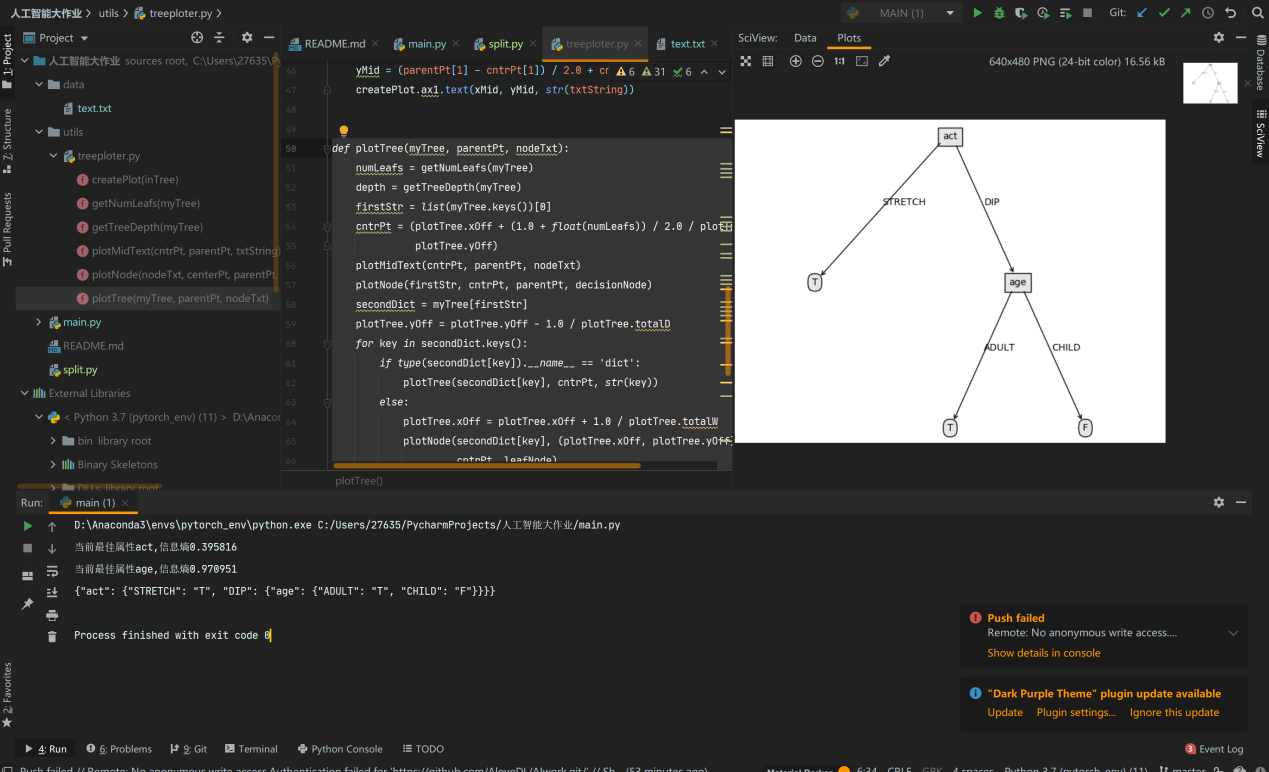
5.4 决策树可视化结果:
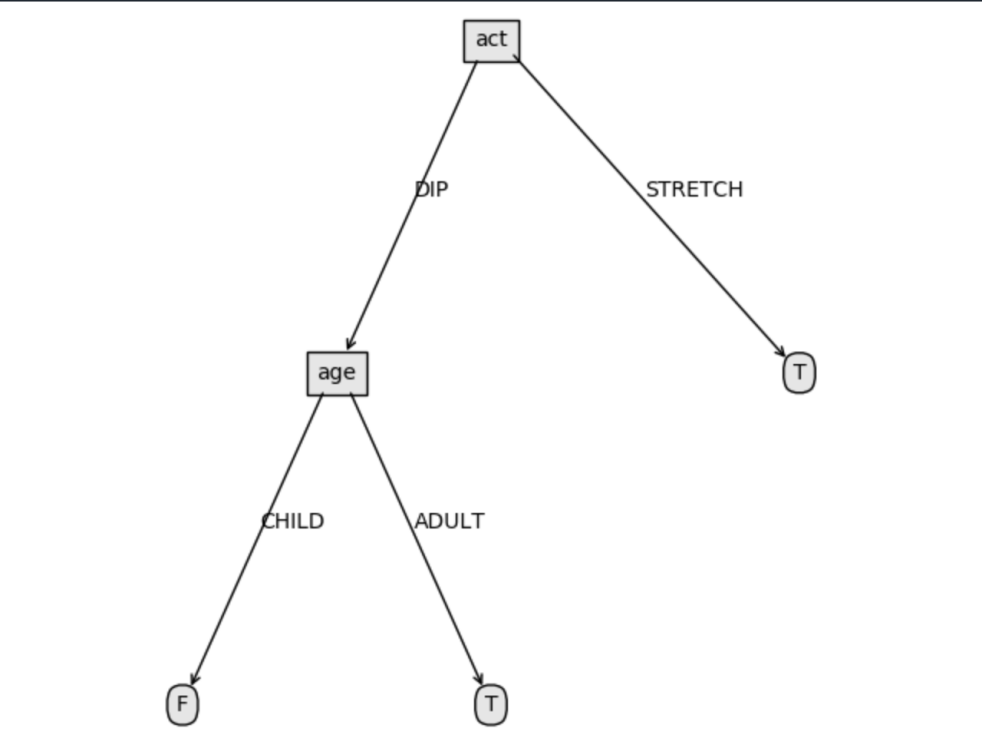
通过输出的结果可以知道,act 属性对于结果的划分最彻底,其次是 age 属性
根据可视化图可知
c++
act = STRETCH => T
act = DIP and age = CHILD => F
act = DIP and age = ADULT => T
6.心得体会
- 首先通过本次实验我学习了一下决策树的可视化的方式
- 通过这次试验,我将以前学习过的决策树相关的知识复习了一遍
- 这次实验的数据量有限,而且都是离散化数据,所以我并没有做整体的数据分布的分析
- 因为决策树算法与分析线性相关性分析联系不大,所以我并没有衡量不同属性间的相关性
- 通过这次实验,我对机器学习的相关项目的流程有了更加清晰的认识,这也对我日后做病理图像相关的机器学习打下了基础
7.参考资料
[1] 《DEEPLEARNING》,[美]lan Goodfellow [加]Yoshua Bengio [加]Aaron Courville 人民邮电出版社
[2] 《机器学习》,周志华,清华大学出版社
[3] 《Python数据可视化之matplotlib》,刘大成,电子工业出版社
[4] 《统计学习方法》,李航,清华大学出版社
[5] 《机器学习实战》,Peter Harrington,人民邮电出版社
[6] 《阿里云天池大赛赛题解析机器学习篇》,天池平台,电子工业出版社
[7] 《Python 袖珍指南》,Mark Lutz, 中国电力出版社
参考文献
- 理财论坛的设计与实现(吉林大学·王雷)
- 基于群体影响的深度对抗生成推荐算法(中国地质大学(北京)·宿永伟)
- 基于Web和数据挖掘的智能教学系统的研究与开发(首都师范大学·乔向杰)
- 基于Django的课程推荐系统的设计与实现(华中科技大学·羊雪玲)
- 基于网络爬虫的基金信息抽取与分析平台(华南理工大学·陈亮华)
- 理财论坛的设计与实现(吉林大学·王雷)
- 基于网络爬虫的基金信息抽取与分析平台(华南理工大学·陈亮华)
- 基于Web的人脸识别系统的研究与实现(中南民族大学·范忠)
- 基于J2EE的人力资源管理系统的设计与实现(大连海事大学·苑馨研)
- 基于数据仓库技术的油田生产经营管理系统研究(中国石油大学·邰伟民)
- 网络信息代理的设计与实现(广东工业大学·陈旨明)
- 基于项目语义的协同过滤推荐算法研究(浙江工业大学·张政)
- 个性化音乐推荐系统的设计与实现(华中科技大学·余梦琴)
- 基于J2EE的远程网络教育系统研究与实现(电子科技大学·陈南荪)
- 数据预测的图形化编程及应用(青海师范大学·林连海)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:源码导航 ,原文地址:https://m.bishedaima.com/yuanma/36145.html