Python 网络爬虫
实验目的及实验内容
实验目的:
使用 requests-BeautifulSoup-re 技术路线,编写程序爬取网页。
实验内容:
参考实例 4,爬取百度搜索风云榜 任一榜单,搜索结果按顺序逐行输出(含编号),榜单自选。
本次实验选取的目标榜单为“百度搜索风云榜-娱乐-电影榜”,结果将输出并保存该页面的六个榜单:全部电影榜单、爱情榜单、喜剧榜单、惊悚榜单、科幻榜单、剧情榜单这六个板块的搜索指数排名前 50 的电影名称及其搜索指数。
结果将额外被保存在 data 目录下的 txt 文本文档中。
爬取当当图书排行榜(榜单自选),格式:爬取结果包含但不限于[排名 书名 作者],注意输出格式对齐。
本次实验选取的目标榜单为“当当网-图书榜-好评榜(top 500)-哲学/宗教”(,结果将输出并保存宗教/哲学系列的累计好评榜排行前 500 本书的排名、书名、作者及出品方、出版社、出版年份、现价、原价、折扣信息。
结果将额外被保存在 data 目录下的 CSV 文件中。
原理分析:
使用 python 的 request 库的 get 方法可以很方便地完成对网页的访问请求并获取网页的 HTML 源码;
使用 python 的 BeaustifulSoup 方法可以很方便、灵活地选择对 HTML 的解析方式(如 find 方法、select 方法等),进而获取每个节点的属性、内容,为爬虫爬取爬取者关注的、存储在网页上的数据创造条件;
使用 python 的 lxml 库的 etree 方法也可以对 HTML 源码进行解析,其原理与 BeaustifulSoup 方法的 find 方法、select 方法原理差不多,但更为灵活,我个人更喜欢用这种方法。鉴于实验要求使用 requests-BeautifulSoup-re 技术路线,因此 etree 方法在本实验中仅作为辅助方法被使用一次;
使用 python 的 re 库可以将正则表达式应用于对结果的过滤,从而从 HTML 节点中过滤并提取到自己想要的结构化数据,进而进行存储。
实验环境
(本次实验所使用的器件、仪器设备等的情况)
处理器:Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz 2.40 GHz
操作系统环境:Windows 10 家庭中文版 x64 19042.867
编程语言:Python 3.8
其他环境:16 GB 运行内存
IDE 及包管理器:JetBrains PyCharm 2020.1 x64, anaconda 3 for Windows(conda 4.9.0)
借助的第三方库及使用目的:
BeautifulSoup:解析 HTML 网页结构并从中提取指定数据; CSV:用于结构化保存结果; lxml:解析 HTML 网页结构并从中提取指定数据;
os:用于判断文件是否存在、创建文件路径; random:创建随机选择; re:正则,用于网址过滤;
requests:模拟浏览器行为,发送 GET 请求以获取目标网站的数据; time:用于停止等待,避免因为访问过于频繁而被目标网页所在服务器限制访问。
实验步骤及实验过程分析
(详细记录实验过程中发生的故障和问题,进行故障分析,说明故障排除的过程及方法。根据具体实验,记录、整理相应的数据表格、绘制曲线、波形等)
说明:
由于网页时刻在更新,本篇实验报告所记录的内容仅为写报告时(2021/04/07)的情况,可能与实际实验时(2021/04/04)结果有出入。
一切以运行时所得到的结果为准。
百度搜索风云榜爬取过程:
“百度搜索风云榜-娱乐-电影榜”的页面布局如下图所示:
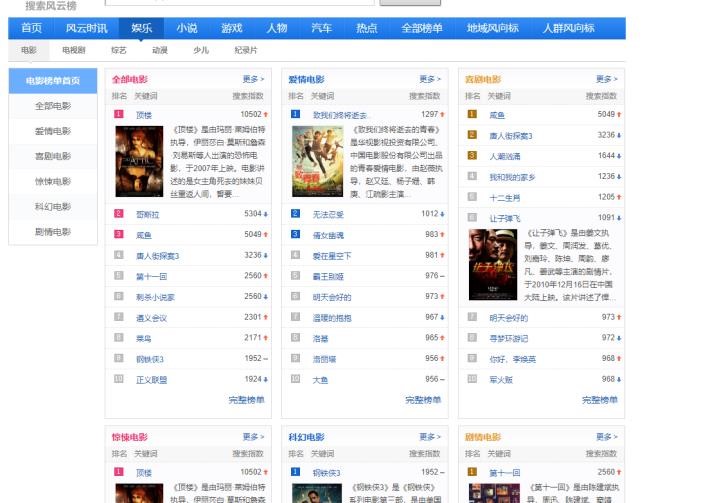
图 1 页面布局
可以看到,榜单分为六个部分:全部电影榜单、爱情榜单、喜剧榜单、惊悚榜单、科幻榜单、剧情榜单。由于每个榜单在这个页面所展现的仅仅是排名前十的结果,要想获取对应的榜单下的排名前 50 的结果,需要在该页面中提取每个榜单的链接。
首先通过 request 库的 get 方法获取该页面的 HTML 源码,并用 BeaustifulSoup 创建一个 BeautifulSoup 对象。
在该页面对元素“全部电影”进行“右键-检查”的操作,可以看到该部分元素对应的 HTML 代码为 a href=" http://top.baidu.com/buzz?b=26&c=1&fr=topcategory_c1 全部电影/a。
该 HTML 代码包含了类别名字以及其链接,只要能获取这六个板块的链接,就能访问这六 个板块所在的页面,进而获取排名前 50 的电影榜单。
因此接下来的工作就是获取这六个板块的链接。
右键该元素对应的 HTML 代码,在“复制”标签下可以看到多个选项,本次实验中会用到 的有“复制 selector”选项和“复制 Xpath”选项。其中“复制 selector”选项将配合 BeaustifulSoup 的 select 方法使用,“复制 Xpath”选项将配合 lxml 的 etree 方法使用。这里选择复制 selector, 会得到一个路径,该路径即为该节点在 HTML 的 DOM 树上的路径,通过该路径即可在 HTML 的 DOM 树上访问该节点的内容。
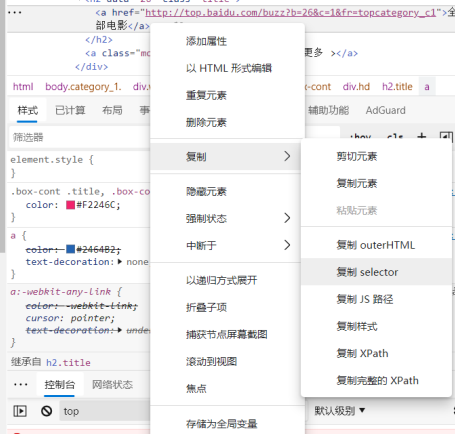
下图 3 中的 path_1 即为上述元素的路径。其中“div: nth-child(1)”说明它在该页面的布局 中占据了第一个板块的位置(事实上也是如此)。实际上,“nth-child(1)”是该元素所对应板块 的属性,对于这六个板块而言,他们仅仅在这个属性上有区别,而在其他的路径、属性上毫无 区别。事实上也是如此,如果检查元素“喜剧电影”,就会发现喜剧电影的路径如下图 3 的 path_2 所示,它的 div 属性为“nth-child(4)”。
因此,如果想获取全部的 6 个榜单及其对应的链接,只需要将这些能唯一标识其身份的“属 性”去掉即可。因此,实际上要查找的路径为“#main > div > div.hd > h2 > a”,即下图 3 中 cla_path 所示。
将 cla_path 传入 BeaustifulSoup 的 select 方法,即可获取结果如下图 3 所示:
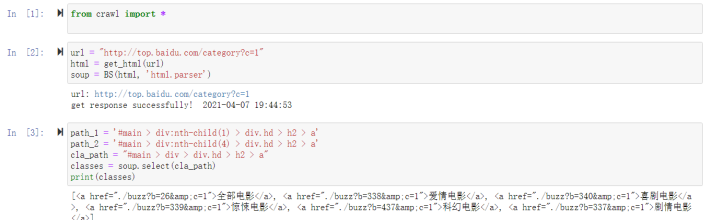
图 3 获取单个榜单页面链接
可以看到,结果列表中确实返回了这六个榜单的名字及其链接,然而其链接并不是直接指 向其所在页面的链接,而是相对于当前页面的相对路径。当前页面的 url 为 http://top.baidu.co m/category?c=1,其中“?c=1”为尾缀参数,真正的 url 应为 http://top.baidu.com/category ,而当 前页面所在的路径应为 http://top.baidu.com ;再加上图 3 中获取到的结果显示“./”为当前路径, 因此单个榜单对应的真正的 url 应为 http://top.baidu.com/buzz?b=&id ,其中&id 为每个页面对应 的 id,如“全部电影”对应的 id 即为 26、爱情电影对应的 id 为 338,以此类推。
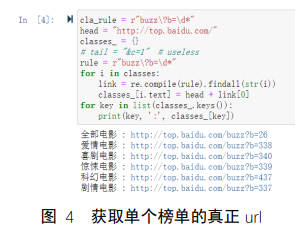
通过构造合适的正则表达式可获取单个榜单的相对路径,然后再使用字符串拼接即可获取 6 个榜单对应的真正的 url。实际实验时发现,参数“c=1”对结果不产生实质性影响,因此不 将其纳入拼接范围。构造正则表达式如图 4 中 cla_rule 所示,该表达式会返回字串“buzz?b=\d ”, 其中“\d ”表示任意长度的数字。
随后分别对每个 url 进行访问、数据获取。考虑到这六个网页的布局是完全一样的,因此 仅以今日喜剧电影排行榜( http://top.baidu.com/buzz?b=340 )为例进行说明。
先看页面布局如图 4 所示:
首先检查“今日喜剧电影排行榜”获取标题的元素路径并使用 select 方法获取标题内容如图 6 所示;

图 6 获取榜单标题
由于在榜单页面上所有内容一字排开、平铺直叙,因此 find_all 方法能很方便地获取该页面上所有的电影的排名、名称、搜索指数信息。
获取电影名称的信息过程如图 7 所示,任选一部电影的名称进行检查,可以发现电影名称被保存在标签为 a、属性为“list-title”的节点。

图 7 电影标题信息
使用 find_all 对其进行查找,可获取全部的前 50 的信息。其中前三分别为《咸鱼》、《唐人街探案 3》、《人潮汹涌》。如图 8 所示。
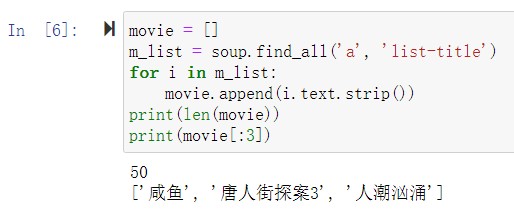
图 8 获取电影名称
获取电影搜索指数的过程类似,搜索指数的标签为 td、属性为“last”,其结果如图 9 所示。
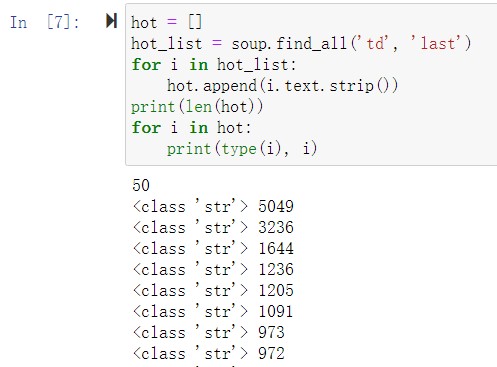
图 9 获取搜索指数
最终的百度搜索风云榜-娱乐-电影榜爬取结果(节选)(2021 年 4 月 4 日,00:30:14)如图 10 所示:
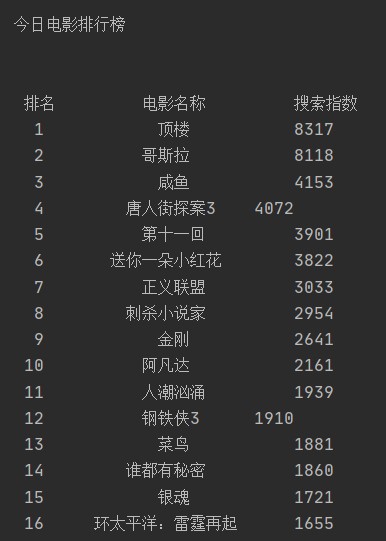
图 10 格式化输出爬取结果
当当网图书榜爬取过程:
“当当网-图书榜-好评榜(top 500)-哲学/宗教”(的页面布局如下图 11 所示:

图 11 页面布局(列表视图)
通过多翻几页可以看到,该网页网址的最后一个“-”后的数字代表了页数,爬虫工作时只需更换这个数字就可以遍历 25 页*20 条共计 500 条内容。
事实上,当当网的图书榜单有两种视图,一种是大图平铺视图,另一种是列表视图。选择后者而非前者的原因是,列表视图的信息及页面结构更为清晰,方便爬取。(实际上,大图平铺视图和列表视图的参数由网址倒数第二个“-”及其后的数字控制,若倒数第二个数字为 1 则为大图平铺视图;若为 2 则为列表视图)检查任意一本书的名字,得书名的通用路径为“ body > div.bang_wrapper > div.bang_content > div.bang_list_box > ul > li > div.name > a”,由于当当网在某些图书的书名后会用括弧的形式做简介,因此选择用正则去掉简介。构造正则式如图 12 中 split_所示。split_ 是一个正先行断言,将保留“(”前的内容,即对于有简介的书而言将保留其简介前的部分;对于无简介的书而言将什么都匹配不到。因此还需加入一次判断,即若正则结果为空则用原始字串作为结果,若正则结果不为空则以正则结果为准。获取图书标题的结果如图 12 所示。
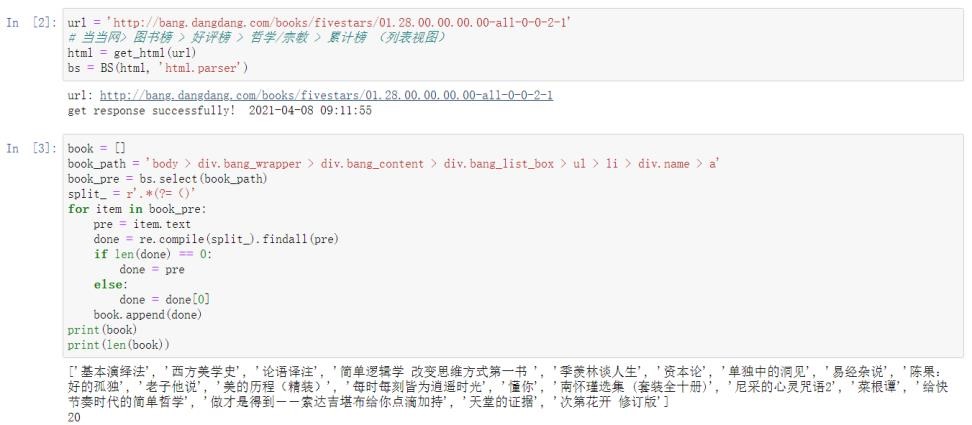
图 12 获取图书标题
检查任意一本书的作者名字可以看到出版社信息的通用路径为“body > div.bang_wrapper > div.bang_content > div.bang_list_box > ul > li > div.publisher_info”,通过简单分割可以发现该标签下包含了一本书的作者、出版时间、出版社信息。
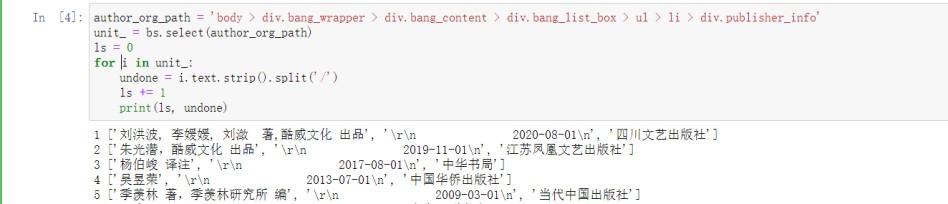
图 13 获取出版社信息
由于字串中多了一些转义字符及空格,因此需要通过清洗字串将其去掉;考虑到有些书的作者、出版时间、出版社信息可能会有空缺,因此需要对清洗结果中相关缺失项用字串“None” 补位缺省值。清洗及补充结果如图 14 所示(’\u300’为):
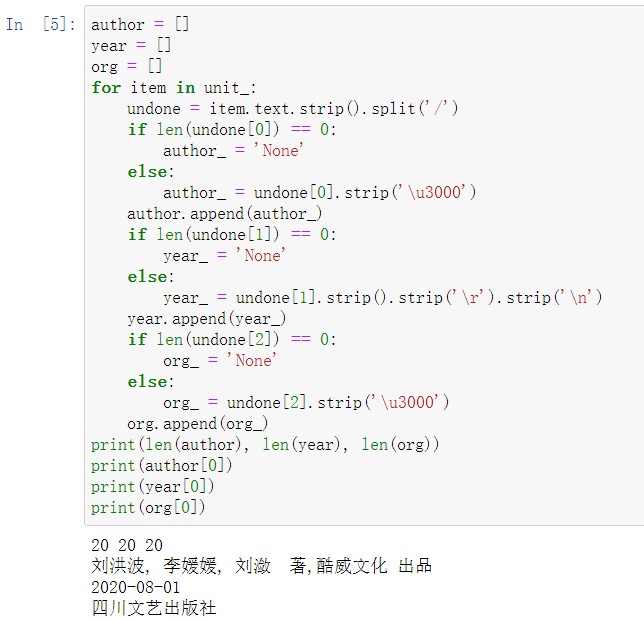
图 14 对出版信息的清洗
在获取书本的价格时,通过观察发现,所有书都有纸质版的价格,但仅有部分书有电子版的价格。为方便起见,实际爬取时将仅爬取纸质版价格的结果。通过观察网页的 HTML 源码发现,价格所在的路径为“body > div.bang_wrapper > div.bang_content > div.bang_list_box > ul > li > div.price > p > span.price_n”,而电子书价格的路径为“body > div.bang_wrapper > div.bang_content > div.bang_list_box > ul > li > div.price > p.ebook_line > span.price_n”,不论是BeautifulSoup 的 find_all 方法还是 select 方法都没办法简单地区分一个价格是纸质书的价格还是电子书的价格,因此考虑用 lxml 的 etree,通过 xpath 方法的 not 命令就可以获取属性值不是 “ebook_line”的 p 节点的子节点数据,这样就可以方便地获取一本书的纸质版价格。相关结果如图 15 所示:
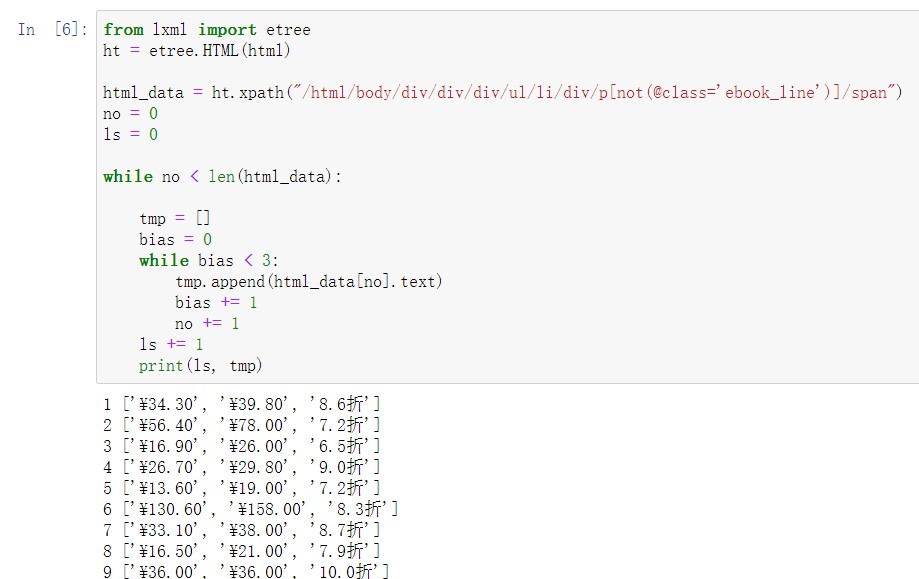
图 15 获取价格信息
最终的当当网-图书榜-好评榜(top 500)-哲学/宗教爬取结果(节选)(2021 年 4 月 4 日,:38:24)如图 16 所示:

图 16 当当网爬取结果
保存的 CSV 内容(节选)如图 17 所示:
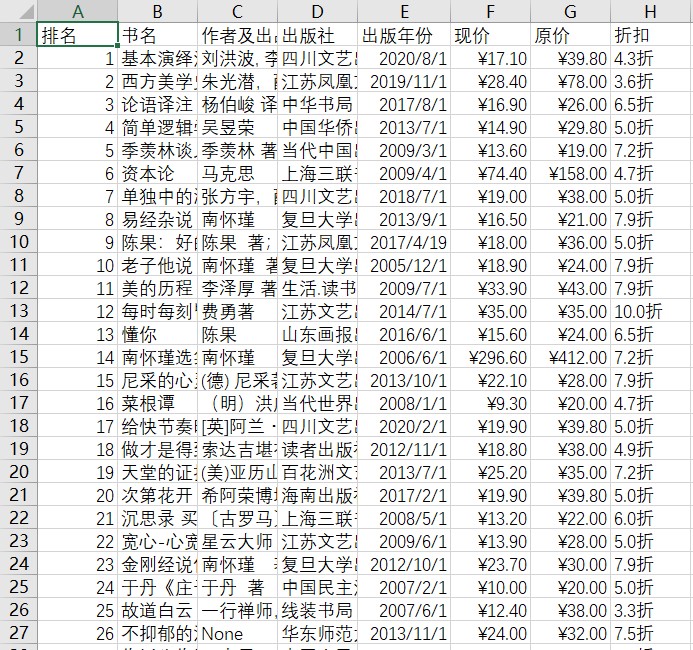
图 17 保存的 CSV 内容
实验结果总结
(对实验结果进行分析,完成思考题目,总结实验的新的体会,并提出实验的改进意见)
本次爬虫实验相对来讲比较简单,信息几乎都被存储在静态页面上,爬虫实际工作的时候也没有遇到反爬措施的限制。事实上,编写爬虫时其实应当考虑 robot 协议;有些网页会采用异步加载的形式,并不会直接将信息写在网页源码中;有的网页会检查一个访问请求是否来自爬虫,并对频繁访问的请求进行一定的限制和验证措施,因此很多时候要考虑采用反反爬措施,包括但不限于随机 UA、停等时间、设置 cookie 等。
页面的选取对爬虫的编写成本及工作效率影响较大。很多购物网页往往会采用大图模式为消费者提供更多的信息,然而这对于爬虫来讲有时会造成一定的不便。页面的 URL 中往往会带有很多参数,有些参数是必要的而有些是不必要的,因此,选择合适的页面、合适的参数将大大提高爬虫的工作效率、简化工作流程。
在从 HTML 源码中提取目标元素时有多种方法可以使用,虽然原理大差不差,但合适的方法可以为工作提供更多的便利,实际工作中可以考虑多种方法联合使用。
正则表达式在对提取到的数据进行过滤清洗的时候会起到至关重要的作用,编写合适的正则表达式可以更有效地得到结构化数据。
参考文献
- 恶意URL检测项目中基于PageRank算法的网络爬虫的设计和实现(北京邮电大学·王晓梅)
- 分布式网络爬虫技术研究与实现(电子科技大学·王毅桐)
- 过滤型网络爬虫的研究与设计(厦门大学·陈奋)
- 搜索引擎中网络爬虫技术研究(西安电子科技大学·郭海燕)
- 基于领域的网络爬虫技术的研究与实现(武汉理工大学·谭龙远)
- 网络爬虫技术在云平台上的研究与实现(电子科技大学·刘小云)
- Inar网络爬虫的设计与实现(哈尔滨工业大学·林乐彬)
- 基于页面分析的网络爬虫系统的设计与实现(华中科技大学·郝以珍)
- 面向多爬虫的监控系统的设计与实现(北京邮电大学·张军强)
- 基于关键词的微博爬虫系统的设计与实现(浙江工业大学·叶婷)
- 基于P2P的被动式网络爬虫系统(哈尔滨工业大学·马天明)
- 基于标记模板的分布式网络爬虫系统的设计与实现(华中科技大学·杨林)
- 过滤型网络爬虫的研究与设计(厦门大学·陈奋)
- 基于redis的分布式自动化爬虫的设计与实现(华中科技大学·曾胜)
- 过滤型网络爬虫的研究与设计(厦门大学·陈奋)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码货栈 ,原文地址:https://m.bishedaima.com/yuanma/36167.html