
基于Python的房价问题分析
实验报告
源码运行环境
Win10 系统下 Python3.5,需安装 tensorflow,matplotlib,numpy,pandas,sklearn
等库。
任务定义
波士顿房价 线性回归(20 分)
波士顿房价 SVM 回归(30 分)
手写数字识别 前馈神经网络(30 分)
手写数字识别 卷积神经网络(30 分)
波士顿房价问题
输入输出:输入数据包括 506 个样本,每个样本包括 12 个特征变量和该地区的平均房价。输出的是在某特征下的对房价的预测。
线性回归
方法描述
由于房价和多个特征变量相关,所以使用多元线性回归建模。其公式如下:

房价预测结果由不同特征的输入值和对应的权重相乘求和,加上偏置项计算求解。
具体步骤:
读取数据
数据预处理:归一化,打乱数据顺序
考虑到不同特征值取值范围大小不同,会有影响,所以要对数据进行归一化。记特征值为 x,最小特征值为
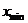
,最大特征值为
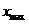
,归一化后的结果为
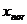
,则归一化公式为:

打乱数据顺序是为了防止过拟合。
定义模型:包括定义输入输出,模型结构与命名空间等。
模型训练:这里设置训练轮次为 50,学习率为 0.01,定义均方差损失函数,选择梯度下降优化器。
模型应用:可视化损失函数,对房价进行预测。
结果分析
训练过程中损失函数图像如下所示:
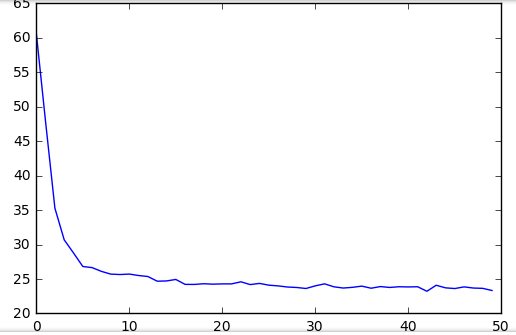
随机测试一个数据,其结果如下:

随训练的进行,损失不断减小,最后收敛至 25 左右。
SVM 回归
方法描述
数据预处理
先用 train_test_split 切割出 70% 的训练集和 30% 的测试集。由于该数据集各样本取值范围差异很大,直接将数据输入到 SVM 中的话,学习将会变得困难且容易被噪声干扰。解决方法是对每个特征做标准化或归一化或正则化,本次采用 sklearn 库自带的 z_值标准化。
模型训练和评估
分别使用线性核,高斯核,sigmod 核,多项式核进行训练。
结果分析
线性核函数:
训练集评分: 0.748439055371
测试集评分: 0.602628182275
测试集均方差: 0.351696191687
测试集 R2 分: 0.602628182275
高斯核函数:
训练集评分: 0.968482433896
测试集评分: 0.845455687936
测试集均方差: 0.136780324058
测试集 R2 分: 0.845455687936
sigmoid 核函数:
训练集评分: -57.7870855639
测试集评分: -62.8185590217
测试集均方差: 56.48297933
测试集 R2 分: -62.8185590217
多项式核函数:
训练集评分: 0.91701495815
测试集评分: 0.790786837991
测试集均方差: 0.18516530123
测试集 R2 分: 0.790786837991
从结果上看,模型评分:高斯 > 多项式 > 线性 >sigmoid
Mnist 手写数字识别
输入输出:输入的是一张图片,利用模型进行预测,输出的是图片上的数字。
前馈神经网络(FNN)
方法描述
在网络中,输出层上节点的值(输出值)通过输入值乘以权重值直接得到。取出其中一个元进行讨论,其输入到输出的变换关系为
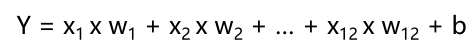
对单张图片而言,这里 x 是[1,784]的数组,w 是[784,10]的数组,b 是[1,10]的数组,预测值的输出是[1,10]的数组,用 one-hot 编码表示,即 index 为对应数字时该值为 1,其余值为 0.如 9 的 one-hot 编码为[0, 0, 0, 0, 0, 0, 0, 0, 0,1].
用梯度下降法对网络进行训练,是交叉熵损失函数达到最小,通过反向传播更新网络参数。
结果分析
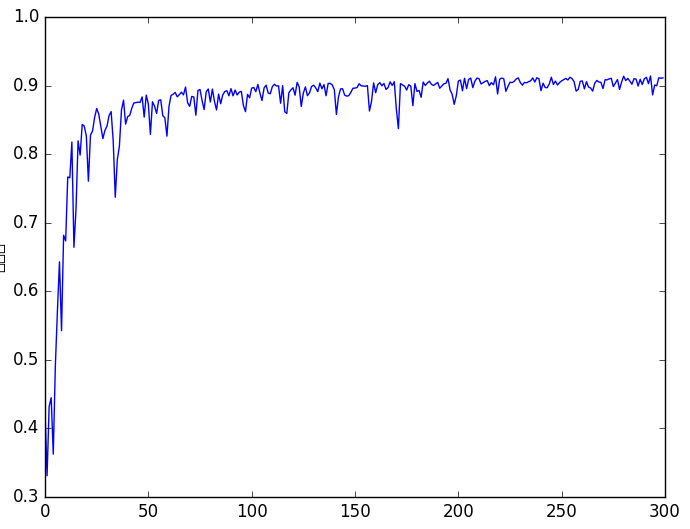
网络训练过程中准确率如上图所示,可以看到,准确率最终收敛到 0.9 左右.
网络训练过程中交叉熵损失函数如下图所示,可以看到,损失最终收敛到 40 左右.

卷积神经网络(FNN)
方法描述
卷积神经网络模型采用两个卷积层和全连接层构成,第一卷积层为 32 个大小为 5 5 1 的卷积核,然后通过 2 2 的最大值池化下采样。第二个卷积层为 64 个 5 5 32 的卷积核,2 2 最大值池化下采样。最后连接到全连接层,通过 softmax 输出分类。
为了避免模型过拟合,加入 dropout。dropout 给隐藏层的神经元加上概率为 keep_prob 的失活率,从而同时训练出指数规模个共享权值的子网络用于分类,增加模型的鲁棒性。
采用随机批梯度下降法使损失函数达到最小,取每 100 个训练数据的均值来迭代更新一次权值,有利于模型更好的收敛到最小值。
结果分析

最终在测试集识别准确率达到 0.977,效果较好。
参考文献
- 基于EDSH框架的房地产交易核价系统的研究与实现(杭州电子科技大学·黄玲龙)
- 房地产销售管理系统设计与实现(电子科技大学·刮代玉)
- 区域房产信息统计系统设计与实现(大连理工大学·张玉梅)
- 基于Mpvue和Spring Boot的线上选房平台的设计与实现(北京交通大学·陶文杰)
- 基于J2EE架构MVC模式的房地产销售管理信息系统的设计与实现(吉林大学·杨丽辉)
- 基于B/S结构的房产管理信息系统(内蒙古大学·蒙君)
- 基于用户意向分析的房屋租赁系统的设计与实现(大连海事大学·董莹)
- 北京兆泰置地房产营销管理系统的设计与实现(山东大学·姚鑫)
- 房产信息管理系统设计与实现(吉林大学·王子尼)
- 基于Java EE构架的房产公司销售管理系统设计与实现(电子科技大学·宗良平)
- 基于股票数据流和投资者情绪的股价预测系统的设计与实现(华南理工大学·陈泽铭)
- 房产信息管理系统设计与实现(吉林大学·王子尼)
- 基于SpringMVC房屋销售管理系统的设计与实现(电子科技大学·李先耀)
- 基于EDSH框架的房地产交易核价系统的研究与实现(杭州电子科技大学·黄玲龙)
- 基于股票数据流和投资者情绪的股价预测系统的设计与实现(华南理工大学·陈泽铭)
本文内容包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主题。发布者:代码工坊 ,原文地址:https://m.bishedaima.com/yuanma/36117.html









